
Scale AI Product Manager Interview Guide: Process, Questions & Preparation Tips (2026)


Introduction
As companies continue to invest in modern product strategy, demand for product managers continues to surge. Open roles for PMs are already up 11% since the start of the year, while the U.S. Bureau of Labor Statistics expects related product roles to grow by 10% through 2030. Scale AI is part of its trend, as product managers are valuable in shaping its production-ready artificial intelligence systems for enterprises and frontier-model customers.
Yet the Scale AI product manager role looks very different from traditional consumer PM work. Instead of optimizing surface-level features, they operate at the infrastructure layer and design platforms that can power high-stakes use cases where model quality, reliability, and scalability are critical. If you’re preparing for a Scale AI product manager interview, expect a high bar where you must transcend comfort with machine learning concepts and product judgment.
Throughout the interview process, you will use your analytical rigor to evaluate trade-offs and make decisions that balance speed, accuracy, and client needs. To help you align with this ownership-driven culture, this guide breaks down each stage of the Scale AI PM interview, covers the most common question types, and shares practical strategies for preparing with confidence using Interview Query.
Scale AI Product Manager Interview Process
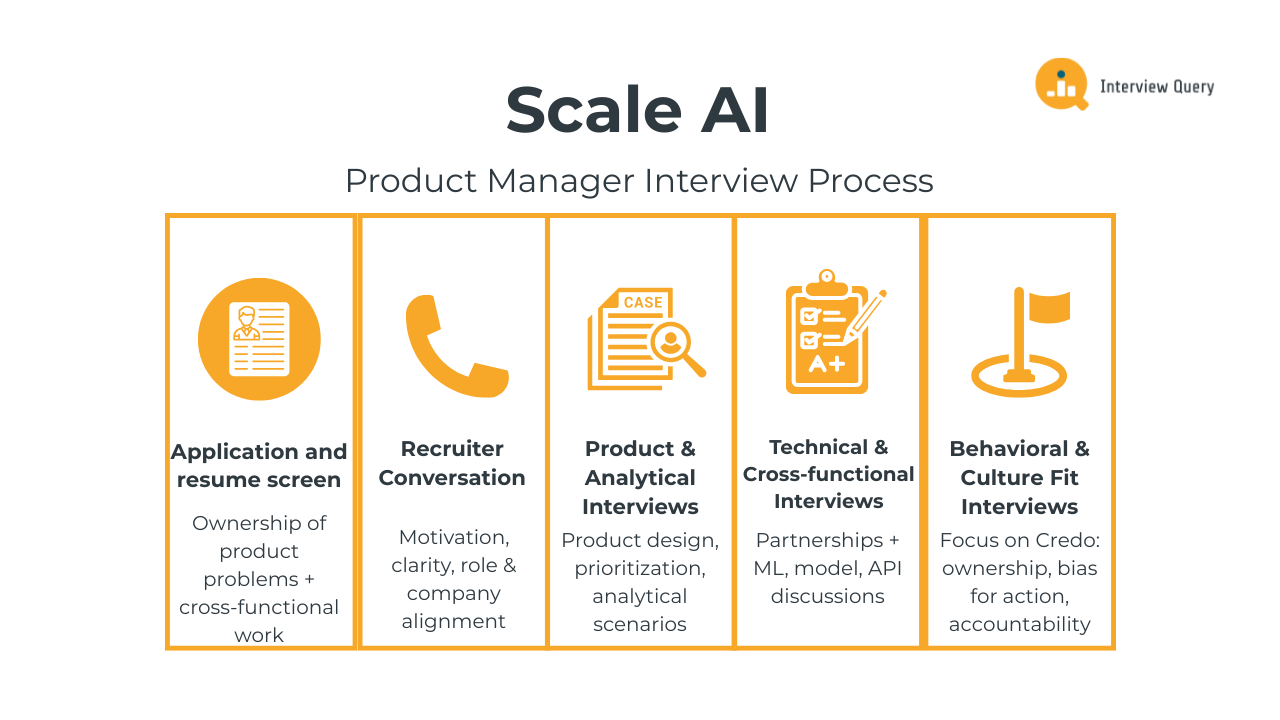
The Scale AI product manager interview process is built to uncover how you think in real-world AI product environments, not just what you’ve shipped in the past. The full loop usually runs three to five weeks and moves through multiple stages that test product sense, analytical decision-making, technical fluency with AI systems, and cultural alignment.
Throughout the process, interviewers look for PMs who can thrive in ambiguity, reason through complex trade-offs, and collaborate deeply with technical partners. Rather than isolated signal checks, each round compounds on the last, resulting in a holistic assessment of whether you can own high-impact AI infrastructure products end to end.
Application and resume screen
The resume screen at Scale AI goes beyond brand names and feature lists. Recruiters scan for clear evidence that you’ve owned complex, ambiguous product problems, especially in data-heavy, platform, or infrastructure environments. Strong candidates show how their decisions influenced system performance, customer outcomes, or operational scale.
Experience working closely with engineers, ML teams, or data operations is a strong signal, particularly if you can demonstrate accountability for outcomes rather than coordination alone. Metrics matter, but they should reflect meaningful leverage, such as improving data quality, reducing latency, or enabling new model capabilities.
Tip: Frame your impact around system-level outcomes. Instead of listing features, explicitly connect your work to improvements in data quality and reliability (“reduced labeling error by 25% through workflow changes”) or scale (“unblocked 3× model training volume by re-architecting ingestion constraints”).
Recruiter conversation
The recruiter screen focuses on motivation, clarity, and alignment with Scale AI’s mission. You’ll discuss your background, product experience, and what draws you to AI infrastructure work. Recruiters often test whether you understand the difference between consumer PM roles and platform-focused PM work, where success is measured by system health and downstream impact.
Expect questions about ambiguity, cross-functional collaboration, and how you evaluate trade-offs without perfect information. This conversation also sets expectations around role scope, team needs, and logistics, so clarity and honesty matter.
Tip: Be explicit about why infrastructure, data, and AI systems excite you, and how you’ve operated effectively in high-ambiguity environments. Book a session with one of Interview Query’s expert coaches with an AI-focused product background to make a strong impression at this stage.
Product and analytical interviews
These interviews form the backbone of the Scale AI PM loop. You’ll tackle product design prompts, prioritization scenarios, and analytical cases rooted in real AI workflows. Common themes include improving data quality, scaling labeling or evaluation systems, and defining success metrics for products where impact is indirect or delayed.
Interviewers value structured thinking, clear assumptions, and principled trade-offs over “perfect” answers. You’re expected to reason through uncertainty, connect decisions to customer value, and explain how your approach scales as model complexity and usage grow.
Tip: When practicing, push yourself beyond surface-level metrics to discuss customer value, operational realities, and long-term scalability. Use resources like Interview Query’s Product Analytics 50 to practice articulating why a metric matters, what it enables downstream, and how it operates at Scale-level volumes or complexity.
Technical and cross-functional interviews
This stage evaluates how well you partner with highly technical teams. While coding is not required, you must demonstrate comfort discussing machine learning systems, data pipelines, APIs, and model evaluation at a conceptual level.
Interviewers may explore how you’d balance model quality against latency, cost, or operational constraints, or how you’d unblock teams facing technical trade-offs. Clear communication and translation of technical inputs into product decisions are critical. Strong PMs show curiosity and judgment without pretending to be engineers.
Tip: Practice explaining ML and data workflows at the level of inputs, outputs, and failure points. Interview Query’s product-focused real-world challenges are useful for rehearsing how to discuss system trade-offs clearly and focus on product implications, not just algorithmic depth.
Behavioral and culture fit interviews
Behavioral interviews assess how you operate when stakes are high and clarity is low. Questions are often mapped to Scale AI’s Credo, emphasizing ownership, bias for action, and accountability. You’ll be asked to share examples of difficult decisions, conflicts with technical partners, and moments when outcomes didn’t go as planned. Interviewers look for reflection, decisiveness, and learning, so respond with specific, outcome-driven stories resonate instead of rehearsed, polished narratives.
Tip: When practicing behavioral questions on Interview Query, choose examples where you took responsibility in ambiguous situations and can clearly articulate what you learned and changed afterward.
To succeed in the Scale AI PM interview, don’t just rely on strong instincts; practice applying them to real AI infrastructure scenarios under pressure. Doing mock interviews on Interview Query is one of the fastest ways to sharpen that edge, especially when feedback comes from PMs who’ve been through similar loops.
Challenge
Check your skills...
How prepared are you for working as a Product Manager at Scale?
Scale AI Product Manager Interview Questions
Instead of optimizing for engagement or growth loops, Scale AI product manager interviews center on AI-first scenarios where data quality, system reliability, and operational scalability directly affect customer outcomes. You are tested on how you reason through ambiguous problems, define success when impact is indirect, and make trade-offs for enterprise customers building production machine learning systems. Interviewers look for structured thinking, comfort with technical constraints, and clear decision-making grounded in metrics rather than intuition.
Read more: Anthropic Product Manager Interview Guide (2025)
Product design and strategy interview questions
Product design interviews at Scale AI focus on building and evolving AI infrastructure products. Expect questions where you must reason about platforms that support labeling, evaluation, and human-in-the-loop workflows at scale, often with multiple enterprise customers and internal teams relying on the same systems.
-
Using your ML systems literacy, a strong approach is to evaluate encoding options such as target encoding, hashing, or learned embeddings based on model type, data volume, and update frequency. You should also discuss risks like information leakage, memory constraints, and how the choice affects downstream model performance and maintenance.
Tip: Explicitly discuss how your encoding choice minimizes operational overhead in Scale’s continuously updating data pipelines, e.g., how it handles long-tail categories without requiring frequent reprocessing or manual schema changes.
-
This prompt assesses understanding of model generalization and experimentation strategy. Regularization is useful when controlling overfitting within a fixed model by constraining complexity, while cross-validation helps evaluate how well a model will perform across different data splits. A good answer connects each technique to product goals like reliability, iteration speed, and confidence in model quality.
Tip: Frame the decision in terms of production risk. Explain how **regularization is often favored when retraining frequently at scale, while heavy cross-validation can slow iteration and delay customer-facing improvements.
Want to practice questions like this and see how your answer stacks up? Head to the Interview Query dashboard to solve more product-focused prompts like this, get AI-powered guidance from IQ Tutor, and learn from real candidate discussions in the comments section.
How would you prioritize features for an AI evaluation platform used by enterprise customers?
Guided by customer-centric prioritization, start by identifying the highest-impact customer pain points, such as trust in model outputs or visibility into performance regressions. From there, prioritize features that improve evaluation accuracy, scalability, and adoption, while balancing engineering effort and long-term platform flexibility.
Tip: Show you understand enterprise AI buying dynamics by prioritizing features that create trust and unblock deployment (audit trails, reproducibility, regression detection).
How do you define success metrics for human-in-the-loop AI systems?
This question tests metric design and understanding of AI workflows. First, define metrics across multiple layers, such as model quality, human efficiency, and system throughput. You should also explain how to track trade-offs between automation and human oversight while ensuring consistent, high-quality outputs over time.
Tip: Go beyond generic quality metrics by naming a metric that links annotator incentives to downstream model outcomes. For example, mention how the error discovery rate that correlates with evaluation catch rates, not just task speed.
How would you evolve a core AI platform product as customer use cases diverge?
Focusing on strategic thinking and platform mindset, identify common primitives that serve multiple use cases while enabling customization through modular components or APIs. You should also discuss how to avoid fragmentation by setting clear boundaries between core platform capabilities and customer-specific extensions.
Tip: Emphasize guardrails, such as opinionated defaults or reference implementations, that let Scale support divergent use cases without turning the platform into a bespoke services organization.
Analytical and problem-solving interview questions
Analytical interviews focus on metrics, trade-offs, and ambiguous data problems. You are expected to reason quantitatively, define success clearly, and make decisions with incomplete information.
How would you define and reconcile success metrics for a large-scale ML ranking system?
This question tests metric design, trade-off analysis, and comfort with ML-driven products. Start by defining a hierarchy of metrics, such as primary outcome metrics, guardrails, and diagnostic signals, and clarify which reflect long-term value versus short-term engagement. When metrics conflict, you would analyze segment-level behavior and align decisions with the system’s core objective.
Tip: Explicitly separate metrics used to train and evaluate models from those used to serve customers in production, since Scale often accepts slower offline optimization to protect online latency and stability.
To apply this thinking hands-on, explore the Interview Query dashboard. You can work through more ML and analytical product scenarios and refine your reasoning with AI-powered feedback from IQ Tutor.
-
You would start with metrics across demand (customer usage and retention), supply (annotator throughput and quality), and system performance (latency, cost, and accuracy). Together, these signals help identify whether issues stem from customer value, operational bottlenecks, or platform reliability.
Tip: Call out a metric that bridges supply and demand, such as quality-adjusted throughput. This is critical because Scale PMs are expected to optimize the system, not just annotator efficiency or customer usage in isolation.
-
Using statistical intuition and judgment in experimentation, an effective approach is to check whether the imbalance was intentional or random and confirm that assignment was unbiased. You would then assess statistical power, confidence intervals, and potential variance differences before deciding whether results are trustworthy or require re-running the experiment.
Tip: Show maturity by explaining how Scale teams rely on experiment instrumentation and pre-launch checks to prevent imbalance, since rerunning experiments at Scale volumes is often costly and slow.
How would you diagnose declining customer trust in model outputs?
This tests problem decomposition and the ability to connect qualitative and quantitative signals. You would combine usage data, error rates, and customer feedback to identify where trust is breaking down, such as inconsistent performance or unclear explanations. From there, segmenting by use case or customer type helps isolate whether the issue is systemic or localized.
Tip: Since Scale PMs are accountable for the full loop, trace trust issues back to data and evaluation gaps and recommend feeding customer-reported issues back into model evaluation or data labeling improvements.
How would you decide whether to invest in automation or manual review?
This question measures cost-benefit reasoning and understanding of human-in-the-loop systems. Make sure to compare accuracy, cost, latency, and risk at different automation thresholds. The decision should factor in error tolerance and long-term scalability, not just short-term efficiency gains.
Tip: Frame the decision around risk segmentation, noting that Scale frequently runs hybrid systems where automation thresholds vary by customer use case, error tolerance, and downstream impact.
Take your analytical skills further with Interview Query’s Product Metrics learning path, where you can practice structured problem-solving, work through real-world scenarios, and strengthen your ability to make data-driven product decisions.
Behavioral questions at Scale AI
Behavioral interviews are closely tied to Scale AI’s Credo and focus on ownership, resilience, and decision-making under uncertainty. Interviewers expect concrete examples with clear outcomes.
Watch next: Ace Your Next BEHAVIORAL INTERVIEW
Before diving into the behavioral questions, here’s a useful video to help you think about structuring your responses:
Although the title says data scientists, the video covers behavioral interview strategies that apply broadly to technical product roles. Interview Query co-founder and data scientist Jay Feng shows you how to answer common behavioral prompts, structure responses with clear examples, and communicate impact effectively. Since these are also useful for Scale AI interviews, explore our mock interview feature to practice articulating leadership, cross-functional collaboration, and problem-solving in past experiences.
-
This question is asked to assess communication, influence, and the ability to bridge technical depth with business needs. Anchor the story with the business or customer risk at stake and the measurable outcome of alignment (e.g., launch timing, quality thresholds, or risk reduction).
Sample answer: I was leading a model rollout where engineers prioritized accuracy while sales and legal were concerned about reliability and customer risk. I aligned everyone by reframing the discussion around customer impact and presenting clear trade-offs using concrete examples. We agreed on phased thresholds that balanced quality and safety, which allowed us to ship on time while keeping error rates under ~2% for our highest-risk customer workflows.
Tell me about a time you shipped a product with incomplete information.
The best answers show how candidates made assumptions explicit, managed risk, and adjusted quickly after launch. Quantify the scope of uncertainty and the impact of your phased approach, be it through early adoption, reduced rework, or speed to value.
Sample answer: I worked on a feature where customer requirements were still evolving, but timelines were fixed. I validated assumptions with 5–7 design partners and scoped a minimal version that reached production in 6 weeks. After launch, we closely monitored feedback and made fast follow-up improvements. This allowed us to drive early adoption from ~30% of the target customer set within the first month.
Tell me about a time you presented complex ML or data insights to a mixed audience.
This question evaluates clarity of communication and the ability to tailor insights to different audiences at Scale AI. When you explain how you simplified complexity while preserving decision-relevant detail, tie the presentation to the quantifiable impact of a decision made or change enabled, not just clarity of communication.
Sample answer: I presented model performance results to engineers, leadership, and customer-facing teams. I led with the key takeaway, then used visuals and plain language to explain what changed and why it mattered. For technical stakeholders, I provided deeper metrics in an appendix. This structure helped leadership quickly approve the rollout, and the updated model reduced false positives by ~15% without increasing latency.
Practice like a pro on the Interview Query dashboard, where solution walkthroughs guide you through both technical and behavioral prompts. Use features like IQ Tutor for step-by-step feedback, or review real candidate strategies to strengthen your storytelling and communication skills.
Tell me about a high-stakes decision you owned end to end.
Scale AI uses this to assess ownership, accountability, and decision-making under pressure. A strong response walks through framing the problem, the opportunity cost, and what was unlocked by your decision, e.g. engineering time, roadmap acceleration, or revenue impact.
Sample answer: I owned the decision to sunset a low-adoption feature that was consuming significant engineering resources. I analyzed usage data, customer impact, and opportunity cost, then aligned with leadership on the trade-offs. After communicating the plan to affected customers, we reallocated the team to higher-impact work. Sunsetting the feature freed up roughly 20% of the team’s quarterly capacity, which we redirected toward a core workflow that later drove a ~2× increase in active usage.
Describe a time you took ownership of a problem outside your formal role.
This question looks for initiative and a bias toward action, which are traits Scale AI values in fast-moving teams. When highlighting how you identified a gap and drove impact without being asked, make sure to quantify downstream impact on customers or internal teams through indicators like support volume, satisfaction, or adoption.
Sample answer: I noticed recurring customer confusion around model evaluation reports, even though it wasn’t in my scope. I partnered with design and engineering to clarify the outputs and improve documentation. I also worked with customer teams to test the changes. After the changes, support tickets related to evaluation reports dropped by ~35%, and customer teams reported noticeably faster onboarding conversations.
Together, these product design, analytical, and behavioral questions reflect the real challenges Scale AI product managers face, namely building ML-driven platforms, making decisions under uncertainty, and aligning deeply technical work with customer impact. To go deeper and practice with realistic, high-signal prompts, explore Interview Query’s question bank and simulate the kinds of interviews you’ll face at Scale AI and other top AI-first companies.
How to Prepare for a Scale AI Product Manager Interview
When preparing for a Scale AI product manager interview, you need a fundamentally different mindset compared to preparation for consumer apps or growth-focused PM roles. Instead of testing how cleanly you recite frameworks, Scale evaluates how you reason through complex AI systems, messy data pipelines, and operational trade-offs. It’s important to demonstrate applied product judgment, technical intuition, and the ability to communicate clearly when requirements are incomplete or evolving.
Begin with product design, prioritization, and metrics: Practice in the context of AI-driven platforms, starting with structuring ambiguous problems where the “user” may be a machine learning team or an enterprise customer, not an end consumer. Be comfortable with defining success when outcomes are indirect, such as improved model accuracy, reduced labeling latency, or higher evaluation reliability, and reasoning through trade-offs across quality, cost, and scalability.
Tip: Using Interview Query’s full set of case study questions, practice at least one product case where the primary metric is model performance (e.g., precision, recall, latency) rather than revenue or engagement.
Review machine learning concepts: You won’t be asked to derive algorithms, but you will be expected to understand how ML systems are trained, evaluated, and iterated on. Focus on concepts like data quality, feedback loops, human-in-the-loop workflows, and model evaluation. Be ready to explain how product decisions upstream like labeling guidelines or tooling affect downstream model performance and customer trust.
Tip: Read and summarize Scale AI’s public blog posts or case studies, then practice explaining the ML workflow in your own words as if briefing a non-technical stakeholder.
Study Scale AI’s data flows: Scale AI sits at the intersection of software, operations, and ML infrastructure, so review labeling pipelines, APIs, and evaluation platforms. Think critically about where failure modes or bottlenecks might emerge, and map your past experience to these problem spaces. Interviewers are looking for evidence that you can translate ambiguous customer needs into durable systems.
Tip: Draw a simple end-to-end diagram of a labeling or evaluation pipeline and annotate where product decisions influence quality, cost, and turnaround time.
Avoid common preparation traps: Over-indexing on generic PM frameworks or memorizing machine learning terminology without applying it to realistic product scenarios will not help. Behavioral interviews also matter more than many candidates expect, so your stories should be concrete and metrics-driven where possible.
Tip: Prepare behavioral stories specifically about operational ambiguity, such as shipping with incomplete data or balancing speed versus quality, rather than polished consumer launches.
Blend repetition with feedback: Timed product case drills build fluency and confidence, while mock interviews help sharpen how you articulate trade-offs and assumptions in real time. This is especially important for AI product roles, where how you reason is often more important than the final answer you land on.
Tip: Do mock interviews on Interview Query, and record yourself answering an AI product case. Review it for clarity, structure, and assumptions to maximize the feedback you receive.
If you want targeted feedback on exactly how you reason through AI product trade-offs, Interview Query’s 1:1 coaching sessions can help you close the gap between practice and performance. Working with an experienced interviewer allows you to pressure-test your thinking, refine your communication, and walk into the Scale AI interview with confidence.
Role Overview and Culture at Scale AI
Unlike consumer-focused roles hinged on surface-level features or growth metrics, Scale AI product managers are all about building the systems that make machine learning possible at scale. You own platforms that power data labeling, model evaluation, and human-in-the-loop workflows, essentially the tools used directly by ML engineers, researchers, and enterprise teams shipping models into production.
The work is deeply cross-functional and highly technical without being academic. You’ll partner closely with engineers, data scientists, operations leads, and customers to turn abstract ML requirements into reliable, repeatable products. Strong PMs at Scale are comfortable operating with incomplete information and making calls that affect downstream model performance and customer trust.
Day-to-day responsibilities typically include:
- Defining product strategy for shared AI platforms used across multiple customers and teams
- Translating ML and data constraints into clear product requirements and roadmaps
- Prioritizing features that balance labeling quality, system reliability, and operational efficiency
- Partnering with engineering and operations to scale workflows without sacrificing accuracy
- Working directly with enterprise customers to understand production ML needs and unblock adoption
- Monitoring system health, data quality metrics, and customer outcomes to guide iteration
Since Scale AI occupies a critical position in the modern AI stack, being a product manager means gaining exposure to advanced use cases like large-scale model evaluation, AI safety pipelines, and production-grade data systems. Scale also values first-principles thinking, bias for action, and accountability, enabling you to take end-to-end responsibility for the systems you ship and make an impact in the evolving AI landscape.
Tip: To better understand how the product manager role fits within Scale AI’s broader ecosystem, read Interview Query’s full Scale AI company guide and its breakdown of teams, workflows, and cross-functional dynamics.
Average Scale AI Product Manager Salary
Scale AI product managers earn competitive compensation across levels, reflecting the company’s position at the center of the AI infrastructure ecosystem. According to Levels.fyi data, total compensation varies meaningfully based on level, scope of ownership, and geographic location, with equity forming a substantial portion of overall pay. As with most high-growth AI companies, compensation tends to skew toward higher upside for senior product managers who own core platforms or enterprise-facing systems.
| Level | Total / Year | Base / Year | Stock / Year | Bonus / Year |
|---|---|---|---|---|
| Product Manager (L3) | ~$180K–$220K | ~$140K–$165K | ~$30K–$45K | ~$10K–$15K |
| Senior Product Manager (L4) | ~$220K–$280K | ~$160K–$190K | ~$45K–$70K | ~$15K–$20K |
| Principal Product Manager (L5–L6) | ~$280K–$350K+ | ~$180K–$210K | ~$80K–$120K | ~$20K–$25K |
Compensation increases meaningfully after equity vesting begins, typically in year two, making long-term impact and retention an important part of the overall package.
Regional salary comparison
| Region | Salary range | Notes |
|---|---|---|
| San Francisco Bay Area | Highest range | Strong equity weighting and higher base |
| New York City | Slightly lower than Bay Area | Comparable senior-level upside |
| Other U.S. hubs | Moderately adjusted | Base adjusted by cost of living |
Overall, the data shows that Scale AI product manager compensation closely tracks other top-tier AI and infrastructure companies, with equity playing a meaningful role in total earnings.
When benchmarking your offer and preparing for this stage of the hiring process, browse Interview Query’s salary guides to learn more about industry-wide and role-specific compensation insights.
FAQs
Is it difficult to become a product manager at Scale AI?
Yes, the interview process is intentionally rigorous, but you can ace it if you can operate in high-ambiguity environments, reason clearly about AI systems, and take ownership of complex, enterprise-facing platforms. Candidates who succeed also typically have experience shipping technically complex products, working closely with engineers or data scientists, and making high-stakes decisions with incomplete information.
How long does the Scale AI product manager interview process take?
The full process typically takes three to five weeks from initial recruiter contact to final decision. Timelines may vary depending on team needs and candidate availability, but feedback is usually shared quickly between stages.
Does Scale AI offer remote or hybrid roles for product managers?
Work arrangements vary by team and role. Some product manager positions offer hybrid flexibility, while others are more closely tied to core engineering hubs. Recruiters usually clarify expectations early in the process.
Can I reapply if I am not selected?
Yes. Candidates are generally encouraged to reapply after a cooldown period, often six to twelve months, especially if they have gained additional experience relevant to AI infrastructure or enterprise product management.
How does leveling work for product managers at Scale AI?
Leveling is based on scope, impact, and ownership rather than years of experience alone. Interviewers assess whether your past product ownership and decision-making align with expectations at each level.
Become a Scale AI Product Manager with Interview Query
Overall, the Scale AI product manager interview rewards candidates who demonstrate comfort with ambiguity, knowledge of production-ready AI systems, and ownership of complex, high-impact platforms. Success hinges less on polished frameworks and more on your ability to connect data quality, system constraints, and customer needs into durable product decisions.
For a more focused preparation strategy, explore Interview Query’s question bank, which contains questions grounded in realistic AI product scenarios and analytical problems. Then, round out your interview prep with honest feedback through mock interviews with peers and coaching sessions with industry experts. All of these provide a practical bridge between preparation and performance, helping you show you’re ready to build the infrastructure behind modern machine learning.
Scale Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Behavioral | Medium | |
When an interviewer asks a question along the lines of:
How would you respond? | ||
SQL | Easy | |
SQL | Easy | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences