
Scale AI Product Analyst Interview Guide (2026): Process, Take-Home & Questions


Introduction
With the global product analytics market expected to reach $27.01 billion by 2032, demand is accelerating for analysts who can do more than query data. The U.S. Bureau of Labor Statistics predicts a 23% job growth for product analysts and related roles, and Scale AI is part of this trend as it expands deeper into high-stakes enterprise and government use cases.
As a result, the Scale AI product analyst interview isn’t just about passing analytics screens. More than demonstrating clean SQL or statistical correctness, candidates are assessed on how they frame ambiguous problems, pressure-test assumptions, and connect data insights to product strategy. A defining part of the process is the take-home assignment, which mirrors real internal decision-making rather than textbook analysis.
This guide is designed to help you prepare with intention. We break down each interview stage, provide recurring questions for product analysts, and share practical strategies to sharpen your analytical thinking, product judgment, and AI fluency aligned with company culture.
Scale AI Product Analyst Interview Process
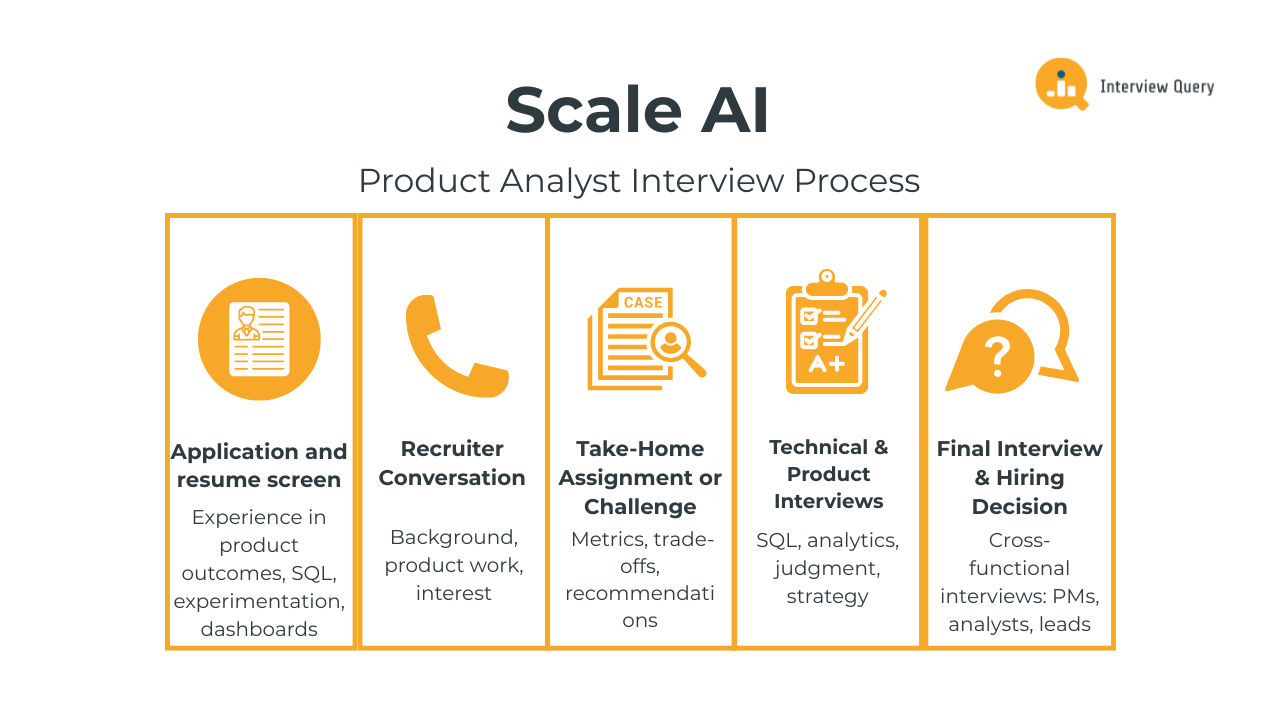
Scale AI’s product analyst interview process is intentionally designed to mirror the way analysts actually work at the company: navigating ambiguity, making tradeoffs, and communicating decisions that affect real AI systems in production. Most candidates go through four to five stages, starting with an application review and recruiter screen, followed by a take-home assignment and multiple interviews that blend analytics execution with product judgment. Compared to larger tech firms, the loop moves faster and places less weight on theoretical frameworks and more on practical decision-making, ownership, and clarity of thought.
Application and resume screen
The resume screen focuses on signal, not surface area. Hiring managers look for analysts who have influenced outcomes in both products and business impact. Beyond experience with SQL, experimentation, or dashboard, what stands out is evidence that your work changed a product direction, improved quality, or unlocked operational efficiency in messy, real-world environments.
Resumes that perform well clearly connect analysis to decisions. Rather than listing tools, strong candidates describe how their work influenced prioritization, improved model performance, reduced operational friction, or changed customer outcomes. At Scale, impact tied to quality, throughput, or customer trust is far more compelling than generic KPI ownership.
Tip: Frame each bullet as a decision narrative. For example, instead of “built dashboards to track labeling accuracy,” say “identified a 12% accuracy drop tied to edge-case prompts, leading to a revised labeling spec and a 20% reduction in downstream model errors.”
Recruiter call
The recruiter call evaluates alignment and intent. You’ll discuss your background, the types of products you’ve supported, and why you are interested in working at Scale AI specifically. This conversation also covers role scope, team fit, and logistics like location and compensation.
Because Scale AI operates as critical infrastructure for AI development, recruiters listen for candidates who understand that the work is as much operational and product-driven as it is analytical. Broad enthusiasm for AI isn’t enough; you should be able to explain why Scale’s position in training, evaluation, and deployment matters.
Tip: Explain where you think analytics adds the most value in Scale’s ecosystem, whether that’s improving model evaluation signals, identifying failure modes, or helping product teams evaluate trade-offs. When you connect with one of Interview Query’s coaches with an AI background, they can help you articulate how your skills and experience fit into enabling better models and AI workflows.
Take-home assignment or challenge
The take-home assignment is one of the strongest evaluation signals in the process. You’ll be given an open-ended dataset and asked to define metrics, analyze tradeoffs, and make a product recommendation based on your findings. The ambiguity is deliberate and closely reflects internal decision-making.
Interviewers prioritize structure, prioritization, and communication over advanced modeling. A clear recommendation, supported by well-chosen metrics and thoughtful assumptions, beats an exhaustive but unfocused analysis.
Tip: Instead of just reporting what happened, call out which slices of data you trust, which you don’t and how you’d validate them. Using Interview Query’s AI Take-home Review for real-time, detailed feedback can also help you identify metrics that would need further analysis.
Technical and product interviews
After the take-home, you’ll move into technical interviews, which typically center on SQL and analytical reasoning within realistic product contexts, such as diagnosing quality regressions, evaluating throughput, or interpreting noisy metrics. Clear logic and explanation matter as much as correctness.
Meanwhile, product interviews test judgment and how well you connect data to product strategy. You may be asked to define success metrics, reason about speed-versus-quality tradeoffs, or assess enterprise adoption challenges.
Tip: Explicitly state what you’d optimize for first, and what trade-offs must be considered instead of defaulting to abstract frameworks. Practicing real-world product challenges on Interview Query can help you be familiar with anchoring your answers in constraints.
Final interviews and hiring decision
The final stage usually involves cross-functional interviews with product managers, analysts, or team leads. These conversations assess collaboration, ownership, and how you operate in fast-moving environments. Like the previous interview rounds, you’re expect to perform consistently by demonstrating strong communication skills and comfort defending your recommendations. Note that feedback cycles are fast, reflecting Scale AI’s bias toward action.
Tip: If new constraints are introduced (customer SLA changes, labeling costs spike, model feedback lags), articulate how your decision boundary shifts and what you’d re-evaluate first.
For candidates preparing for this level of ambiguity and product-driven analysis, Interview Query’s mock interviews can help pressure-test your thinking for the types of analytical, product, and communication challenges you’ll face at Scale AI. Through realistic practice and feedback, you can communicate clearly under uncertainty and make decisions with conviction.
Challenge
Check your skills...
How prepared are you for working as a Product Analyst at Scale?
What Questions Are Asked in a Scale AI Product Analyst Interview?
Scale AI’s product analyst interviews are built to uncover how you think when the data is incomplete and the stakes are high. Rather than testing isolated skills, interviewers evaluate how you frame problems, choose the right metrics, and turn ambiguous inputs into clear product direction. Questions are typically grounded in real Scale AI contexts, such as model evaluation, enterprise customer workflows, and operational tradeoffs at scale.
Before diving into sample questions, it’s helpful to see how strong candidates structure their thinking and communicate under pressure.
Watch Next: 7 Types of Product Analyst Interview Questions!
In this video, Interview Query co-founder and data scientist Jay Feng provides a practical walkthrough of how to approach product and analytics interview questions, with an emphasis on structured thinking and clear communication—both critical in Scale AI interviews.
Now that you have an idea of how to clearly define the problem and tie your analysis to product impact and business goals, below are the core question categories you should expect for the Scale AI product analyst interview.
Product analytics and metrics questions
Scale AI uses analytics and metrics questions to assess how you define success, structure metrics, and interpret signals from complex systems. Strong candidates demonstrate a clear metric hierarchy and connect measurements directly to product and customer outcomes.
-
This tests experimentation intuition and how well you understand selection effects and metric validity. A strong answer explains why the observed lift may regress once exposed to the full user base due to differences between test and control populations, while also considering saturation, behavior shifts, and operational constraints. You’d outline how to validate the post-launch impact using holdouts or segmented analysis rather than assuming the lift persists.
Tip: Scale analysts stand out when they can predict which customer segments are most likely to invalidate an experiment’s result post-rollout. So, talk about where the lift might disappear first, e.g., large enterprise customers with custom workflows or accounts with strict review SLAs.
Practice more metrics-focused questions like this one by heading over to the Interview Query dashboard to solve additional product analytics and metrics problems. Get targeted feedback by checking your answers with IQ Tutor and step-by-step solutions walkthroughs to close your gaps faster.
Retention varies across different Scale AI products. How would you identify and explain the gap?
This evaluates metric definition, segmentation, and causal reasoning across complex product surfaces. Start by ensuring retention is consistently defined, then slicing by customer type, use case, and lifecycle stage to confirm the disparity is real. From there, you’d investigate drivers such as workflow friction, value realization timing, or differences in model performance and integration depth.
Tip: Anchor retention to time-to-value, not just usage frequency patterns. Analysts often uncover retention gaps by showing that some products deliver immediate model improvements while others only pay off after weeks of integration or data iteration.
A customer’s model accuracy improves but usage drops. How do you investigate?
This question tests your ability to debug conflicting signals and separate measurement issues from real behavior changes. Strong answers walk through validating the accuracy metric, segmenting usage by customer type, and examining friction points such as evaluation latency or workflow changes. You should also consider whether improvements benefit a narrow use case while hurting broader usability.
Tip: Ground your investigation in customer context by mentioning direct collaboration with solutions engineers or customer success teams. Considering whether the “accuracy” gain increased operational cost, e.g., longer evaluation cycles, also reflects how Scale analysts validate data insights in practice.
How would you measure the success of a new model evaluation product?
When defining success metrics aligned with product goals and customer outcomes, propose a metric hierarchy spanning adoption, evaluation reliability, and downstream decision impact, rather than a single vanity metric. You’d also explain how early leading indicators evolve into long-term measures as customers integrate the product into production workflows.
Tip: Go beyond adoption and accuracy by proposing a metric that captures decision confidence, such as how often evaluation results directly gate model deployment or rollback. This reflects how Scale customers actually use evaluation to de-risk production launches.
What metrics would you track to monitor labeling quality over time?
Here, Scale AI evaluates how well you balance operational and quality metrics. Candidates should discuss precision or agreement measures alongside throughput and rework rates. Make sure to explain how to detect silent degradation before customers notice, such as drift in annotator agreement or increased downstream model corrections.
Tip: Call out at least one leading indicator that surfaces problems before aggregate quality drops, such as disagreement variance within specific task types or annotator fatigue signals. At Scale, early detection matters more than post-hoc accuracy reporting.
SQL and data analysis questions
SQL and analysis questions test your ability to work with imperfect data under real constraints. Clean logic, correct assumptions, and the ability to explain your approach step by step matter far more than obscure syntax or optimization tricks.
Given an events table from a Scale AI workflow, write a query to group user actions into sessions.
This tests your ability to reason about time-based data and apply window functions correctly. A solid approach defines a session boundary using an inactivity threshold, then uses tools like
LAG()and a cumulative sum to assign session IDs. Clear handling of edge cases, such as the first event per user, demonstrates production-ready SQL thinking. Tip: When discussing sessionization, mention how different workflows or task types might require tailored thresholds, showing that you understand the nuances of real-world annotation pipelines at Scale AI.-
Here, interviewers assess grouping logic, conditional aggregation, and metric correctness. The solution typically groups by query, checks whether the maximum rating per query stays below the quality threshold, and then computes the proportion of such queries across the dataset. Explaining why this metric surfaces systemic relevance failures strengthens the answer.
Tip: Explicitly state why you’d compute this at the query level instead of aggregating result-level ratings. Scale analysts are expected to spot systemic failure modes, not just average quality degradation.
Write a query to compute average user response time to system prompts in an AI-driven workflow.
This question evaluates your ability to join events, sequence interactions, and calculate time deltas accurately. You’d align each user message with the immediately preceding system message, compute the timestamp difference, and then aggregate by user or overall. Careful ordering and filtering are essential to avoid mismatched responses.
Tip: Mention how you’d sanity-check the output by inspecting extreme values or distribution shifts, since response-time metrics at Scale are often skewed by retries, batching, or async workflows.
Jump into the Interview Query dashboard, where you can tackle more SQL and data analysis questions using the built-in SQL editor and get real-time guidance from IQ Tutor as you work through your approach.
How would you analyze a sudden spike in evaluation latency?
Using analytical debugging and your ability to isolate performance regressions in complex systems, break latency down by model version, customer segment, and pipeline stage to identify where the increase originates. Comparing pre- and post-spike distributions often reveals whether the issue is systemic, load-related, or driven by a specific workflow change.
Tip: When discussing how to isolate the sudden spike, determine whether the spike correlates with a specific model version or customer tier before diving into pipeline stages. This mirrors how Scale analysts quickly narrow the blast radius before deeper investigation.
How would you identify customers experiencing degraded evaluation performance?
Based on segmentation, metric selection, and customer-level analysis, you’d start by defining a baseline for “healthy” performance. Then, flag customers whose metrics deviate meaningfully over time. Pairing quantitative thresholds with trend analysis helps distinguish temporary noise from sustained degradation.
Tip: Go beyond static thresholds by describing how you’d compare each customer’s current metrics to their own historical baseline, which is how Scale avoids overreacting to customers with inherently different workloads.
Looking for a way to master SQL from basics to advanced interview-style problems? Check out the SQL Learning Path on Interview Query. The structured course guides you through beginner to hard levels with curated exercises and explanations designed to mirror real technical interviews.
Product sense and strategy questions
Product sense questions focus on judgment. You’ll be asked to reason through products where quality, speed, and cost often pull in different directions, and where decisions must be made without perfect information.
-
This question assesses product judgment, tradeoff analysis, and business impact thinking. A strong answer frames the decision around customer needs, timelines, and expected value, weighing factors like time-to-market, incremental accuracy gains, and engineering cost. It’s also important to discuss how experimentation or phased rollouts could de-risk the choice.
Tip: Anchor your decision to a concrete customer milestone, such as an upcoming model launch or contract renewal. Then, explain how shipping earlier could unlock learning or revenue that outweighs incremental accuracy gains.
Build stronger product judgment by exploring this and other product sense questions in the Interview Query dashboard. Check how other candidates reason through similar tradeoffs and learn from user comments that break down real-world decision-making approaches.
How would you prioritize features for an enterprise AI customer?
Here, the interviewer is testing customer empathy, structured prioritization, and strategic thinking. Explain how you’d balance customer impact, revenue potential, and implementation effort while accounting for enterprise-specific constraints like compliance and integration complexity. Referencing a clear framework, such as RICE or customer segmentation, helps anchor the decision-making process.
Tip: Show that you’d separate “must-haves to unblock adoption” from “nice-to-haves to deepen usage,” since Scale analysts frequently prioritize features that reduce integration friction over those that look impressive in isolation.
How would you decide whether to invest in faster evaluations or higher accuracy?
This question targets your ability to align technical metrics with customer and business outcomes. A thoughtful approach connects evaluation speed and accuracy to real-world use cases, such as iteration velocity or model performance requirements. Discussing how customer workflows and SLAs influence the tradeoff demonstrates practical product sense.
Tip: Tie the tradeoff to iteration velocity by explaining when faster feedback loops compound customer value more than marginal accuracy improvements, especially during early model development cycles.
How do you evaluate success when customers use Scale AI differently?
The goal here is to understand how you think about metrics in a heterogeneous customer environment. A solid answer highlights the importance of defining both core platform-level KPIs and customer-specific success metrics. Explaining how qualitative feedback complements quantitative signals shows a well-rounded evaluation approach.
Tip: Emphasize defining a small set of invariant platform metrics (e.g., reliability, consistency) while allowing customer-level success metrics to vary by use case, which is how Scale maintains comparability without oversimplifying outcomes.
How would you handle conflicting feedback from enterprise customers?
This question examines stakeholder management, prioritization, and decision-making under ambiguity. A strong response describes how you’d identify underlying customer goals, assess strategic fit, and quantify impact before making tradeoffs. Acknowledging the need for clear communication and expectation-setting reinforces mature product leadership.
Tip: Describe how you’d translate subjective feedback into measurable impact, such as changes in throughput, quality, or cost. Doing so helps avoid prioritizing the loudest customer over the most strategically aligned one.
Behavioral questions
Behavioral interviews center on how you operate day to day: taking ownership, communicating tradeoffs, and influencing decisions in fast-moving, ambiguous environments.
Tell me about a time your analysis changed a product decision.
Scale AI asks this to see how well you translate data into influence, not just insights. Quantify what the analysis revealed (segments, deltas, adoption gaps) and what decision changed as a result.
Sample answer: On a prior project, I analyzed customer usage data and found that a highly requested feature was rarely adopted by our largest enterprise users. I showed that adoption among our top 10 enterprise accounts was under 8%, compared to ~40% among smaller customers. This led the team to pause the feature and ship workflow changes that increased WAU for key accounts by ~15%.
Talk about a time you had trouble communicating with other stakeholders.
This question evaluates collaboration skills in cross-functional, often ambiguous environments like Scale AI’s. It’s important to not just identify the root of the misalignment, but to also tie improved communication to a measurable execution outcome, such as fewer revisions, faster delivery, or clearer requirements.
Sample answer: I once worked with an engineering team that felt my requirements were constantly shifting. After reframing updates around customer constraints, requirement churn dropped noticeably. The team hit its next two milestones without scope rework, saving roughly a sprint of engineering time.
Tell me about a project with unclear success metrics.
Interviewers use this to assess how you define success when it’s not handed to you upfront. A strong approach shows how you operationalized ambiguity by defining a proxy metric and tracking change over time.
Sample answer: I worked on a tooling project where success wasn’t clearly defined beyond “improve efficiency.” We tracked average task time per user and saw a ~20% reduction within the first month. This then gave the team confidence to invest further despite the initial lack of formal success criteria.
Describe a time you had to move fast with imperfect data.
Scale AI values decisiveness in fast-moving, data-constrained situations. When discussing risk mitigation, quantify the decision risk by explaining how quickly you validated or corrected course after launch.
Sample answer: During a tight launch window, I had to make a pricing recommendation with limited historical data. I combined directional trends with qualitative input from sales and flagged the key assumptions to leadership. We then launched with a conservative price point and reviewed performance weekly. Within 30 days, conversion held steady and revenue landed within ~10% of projections, allowing us to adjust with confidence.
Tell me about a failure involving a product decision and what you learned.
This prompt looks for self-awareness and growth rather than perfection. Be specific about what went wrong, e.g., low adoption, wasted effort, or missed signal, and how it changed your analytical approach going forward.
Sample answer: I once pushed for a feature based on vocal customer feedback without validating broader demand. Post-launch data showed adoption below 5% after six weeks, despite strong anecdotal demand. This finding led me to formalize a pre-launch usage threshold before recommending future investments.
The sample questions above reflect the kind of judgment, structure, and cross-functional thinking Scale AI looks for in product analysts. To go deeper and sharpen your responses, explore Interview Query’s question bank to practice role-specific product scenarios and build confidence for the interview.
How to Prepare for a Scale AI Product Analyst Interview
When preparing for a Scale AI product analyst interview, going beyond generic analytics prep to balance technical fundamentals and product judgment is key. Scale operates where AI infrastructure, enterprise customers, and human-in-the-loop systems collide, so interviewers look for analysts who can move comfortably between data, product context, and decision-making.
Master SQL that reflects real product questions: You should be comfortable with joins, window functions, CTEs, and cohort analysis, but execution alone isn’t enough. Practice narrating your analysis: what question you’re answering, what assumptions you’re making, and how the output would influence a roadmap or operational change. For example, be ready to explain why a metric moved, not just that it moved.
Tip: When answering product-focused SQL questions on Interview Query, practice rewriting your as a one-paragraph product insight summary, ending with a concrete decision you would recommend to a Scale PM or operations lead.
Sharpen your product metrics intuition: Scale AI interviews often present open-ended scenarios where there’s no obvious “right” KPI. Train yourself to define a clear north-star metric, supporting diagnostics, and guardrails, especially in contexts involving quality, latency, cost, and reliability. Explicitly discuss trade-offs, such as when faster throughput might degrade annotation quality or customer trust.
Tip: For each practice case you choose from Interview Query’s product challenges, force yourself to name one metric you would not optimize for and explain why deprioritizing it protects Scale’s long-term customer value.
Prepare a structured approach for the take-home: Interviewers are evaluating judgment as much as analysis, so treat the assignment as an internal decision document. Practice scoping ambiguous problems, choosing a minimal but meaningful metric set, and writing recommendations that a PM or operator could act on immediately. Clear structure, crisp assumptions, and prioritization matter more than complex modeling.
Tip: Use a consistent memo format, such as problem framing, assumptions, metrics, insights, recommendation, and limit yourself to one primary recommendation to demonstrate prioritization. Explore our AI Take-Home Review for more detailed feedback on structuring your take-home assignment.
Study Scale’s AI products and recent AI trends: Familiarize yourself with data labeling workflows, model evaluation, RLHF, and how enterprise teams deploy and validate AI systems in production. Reading recent product announcements and customer case studies from Scale’s blog will help you anchor answers in realistic constraints rather than abstract theory.
Tip: Pick one Scale product (e.g., model evaluation or data engine) and map out its end-to-end workflow, noting where data quality, cost, and latency trade-offs would require analyst input.
If you want feedback on your reasoning and communication before the interview, Interview Query’s mock interviews simulate real product analyst scenarios and help you refine your approach.
Role Overview and Culture at Scale AI
As Scale AI is among the pioneers of moving cutting-edge AI systems from experimentation to real-world deployment, the product analyst role is vital to this mission. Product analysts help define what “good” looks like for model performance, data quality, and customer workflows, then use data to determine whether Scale’s products are meeting that bar. The work directly shapes how enterprise and frontier-model customers trust, evaluate, and ship AI at scale.
Rather than functioning as passive reporters, Scale product analysts act as decision partners. A typical analysis may involve synthesizing signals from labeling accuracy, model evaluation metrics, and customer usage patterns into a clear recommendation.
Day-to-day responsibilities include:
- Defining and evolving success metrics for AI products, evaluation workflows, and customer integrations
- Analyzing model performance, data quality, and throughput trends to identify risks and opportunities
- Partnering with PMs to inform roadmap decisions and feature prioritization
- Translating complex technical outputs into clear, actionable insights for cross-functional teams
- Supporting high-stakes decisions such as production readiness, evaluation reliability, and customer-facing commitments
Culturally, Scale values ownership, velocity, and customer trust. Product analysts are thus expected to not wait for perfect data, and instead operate with autonomy when navigating ambiguous problems and driving decisions forward. The strongest analysts pair rigorous analysis with a practical understanding of how AI systems behave in production.
To build these skills, Interview Query’s product analytics learning paths provide structured practice in metrics, experimentation, and cross-functional decision-making.
Average Scale AI Product Analyst Salary
Scale AI product analysts earn competitive compensation across levels, reflecting the company’s position at the center of enterprise and frontier artificial intelligence development. According to Levels.fyi, total compensation varies based on scope, experience, and location, with a clear progression as analysts take on broader product ownership. In addition to base salary, equity is a meaningful component of compensation, especially as responsibilities expand across high-impact products and customers.
| Level | Total / Year | Base / Year | Stock / Year | Bonus / Year |
|---|---|---|---|---|
| Product Analyst | ~$165K | ~$135K | ~$25K | ~$5K |
| Senior Product Analyst | ~$205K | ~$160K | ~$40K | ~$5K |
| Lead / Staff Product Analyst | ~$245K | ~$185K | ~$55K | ~$5K |
Compensation tends to increase significantly after equity vesting begins in year two, particularly for senior and lead-level roles.
Regional salary comparison
| Region | Salary Range | Notes |
|---|---|---|
| San Francisco Bay Area | $180K–$260K | Highest compensation due to proximity to core teams |
| New York | $165K–$240K | Strong alignment with Bay Area roles |
| Seattle | $160K–$230K | Competitive for senior analytics talent |
| Remote (U.S.) | $150K–$215K | Varies by location and team scope |
Overall, the data shows that Scale AI rewards product analysts who take ownership of high-impact metrics and cross-functional decisions, with equity forming a meaningful share of long-term compensation.
Use Interview Query’s salary guides to benchmark your offer and prepare for every interview stage based on industry-wide insights.
FAQs
How long does the Scale AI interview process take?
Most candidates complete the Scale AI interview process within three to five weeks. Timelines can move faster than at larger technology companies, especially once the take-home assignment is submitted and reviewed. Scheduling availability and team needs can affect pacing, but feedback loops are generally quick.
How difficult is the Scale AI take-home challenge?
The take-home challenge is intentionally open-ended rather than technically complex. Candidates are evaluated on how they structure the problem, define metrics, and communicate a recommendation. The difficulty comes from ambiguity, not advanced modeling. Strong candidates focus on clarity, prioritization, and decision-making rather than exhaustive analysis.
Does Scale AI use HackerRank or coding platforms?
For product analyst roles, Scale AI typically does not rely on HackerRank or similar coding platforms. SQL and analytics skills are assessed through live interviews and practical scenarios instead of timed algorithmic tests.
How is feedback shared after interviews?
Feedback is usually consolidated by the recruiter after each stage. While detailed written feedback is not always provided, candidates can expect clear communication about next steps and decisions. Scale AI is known for relatively transparent and timely follow-ups compared to many fast-growing startups.
Jumpstart Your Product Analyst Journey with Interview Query
Breaking into a product analyst role at Scale AI doesn’t begin and end with being technically sharp. You’re more likely to stand out when you can connect analysis to product judgment, explain trade-offs with confidence, and ground your thinking in how AI systems are actually built, evaluated, and used in production. With the right preparation, each interview stage becomes an opportunity to demonstrate how you’d operate as a trusted decision partner, not just someone who works with data.
Interview Query can help you get there faster. Use our mock interviews to simulate real Scale-style product analytics scenarios, the product metrics learning path sharpens your intuition for ambiguous trade-offs, and take-home reviews help you refine structure, clarity, and recommendations before it matters most.
Scale Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Machine Learning | Easy | |
Let’s say you are tasked with building a spam classifier for emails. Assume that you’ve built a V1 of the model. What metrics would you use to track accuracy and validity of the model? | ||
Behavioral | Medium | |
SQL | Easy | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences