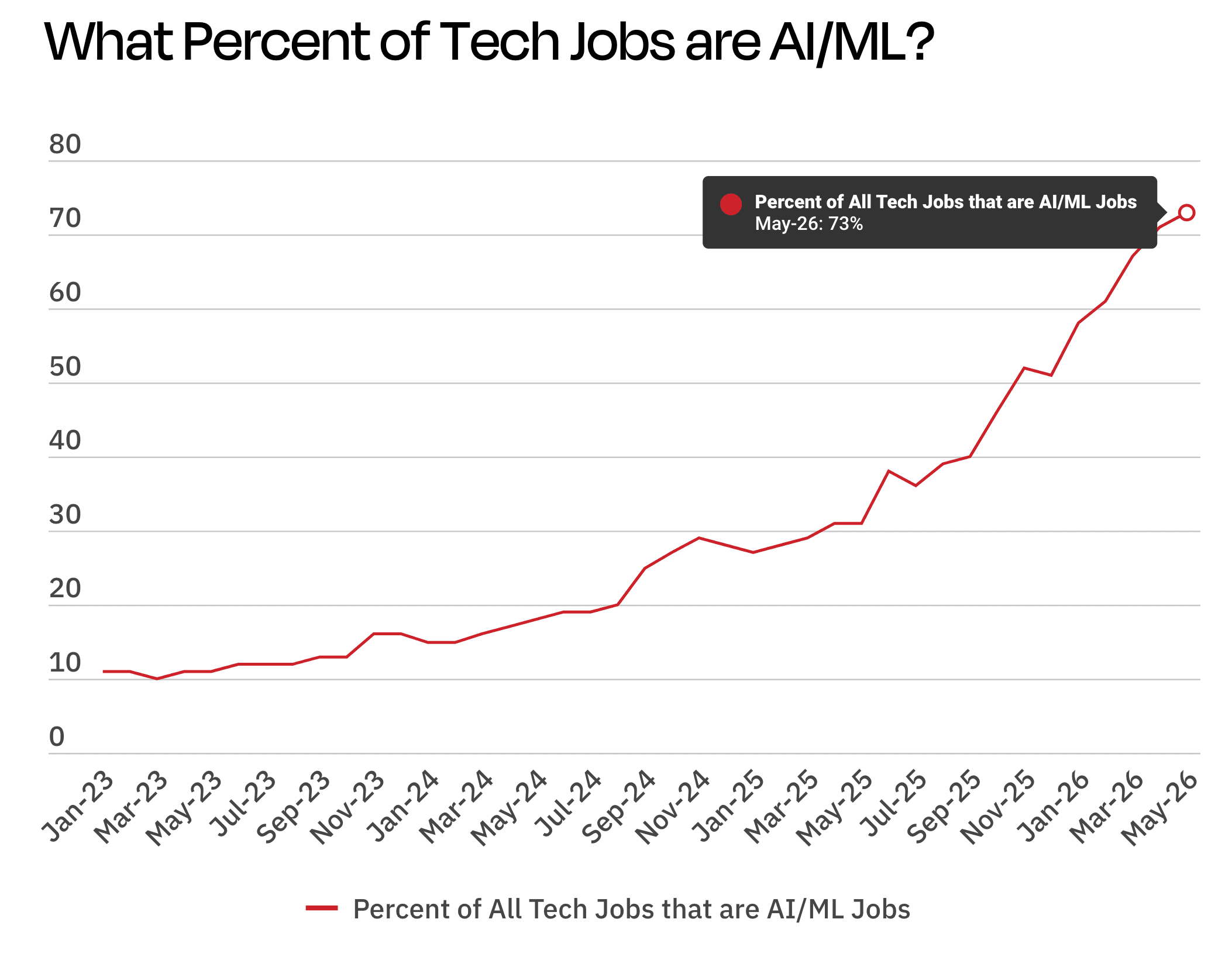
Dice: AI Skills Dominate 73% of Tech Job Posts, But Fundamentals Win Interviews
Despite rapid growth in AI-related hiring requirements, employers continue to use interviews to evaluate core analytical, technical, and communication skills.
CompTIA: Tech Job Postings Hit a Three-Year High, But Interviews Remain Tough
Despite a surge in tech job postings, employers remain cautious, leading to longer interview processes and higher standards for software, data, and analytics candidates.
NACE Says Communication Skills Still Beat AI Skills in Interviews
As AI becomes standard in hiring workflows, employers are increasingly using interviews to evaluate communication, judgment, and leadership rather than technical ability alone.
365 Data Science: 69.3% of Data Analyst Jobs Now Prefer Specialists
Data interviews are evolving from generic technical screens into domain-specific job simulations that test business judgment as much as analytical skill.
How to Pass an Analytics Engineer Interview (SQL, Modeling, Stakeholder Rounds)
A practical guide to analytics engineer interviews covering SQL, data modeling, and stakeholder communication with real-world preparation strategies.
Data Roles Now Average 24.9 Interview Hours Per Hire, The Highest Across Technical Roles
Data interview loops are expanding across more formats, forcing candidates to demonstrate technical, analytical, and communication skills over longer processes.
16 Best Fintech Machine Learning Projects with Code (Beginner to Advanced)
This guide helps you choose and build fintech ML projects that align with your skill level and demonstrate real financial problem-solving ability.
How to Pass a Business Intelligence Interview (SQL, Dashboards, Case Rounds)
Business intelligence interviews test your ability to combine SQL, metrics, and communication into clear, actionable recommendations.
Greenhouse Says 63% of Job Seekers Have Faced AI Interviews. Hiring Has A Transparency Problem.
AI interviews are scaling quickly, but unclear communication and lack of human visibility are reshaping how candidates experience hiring.
How to Pass a Data Analyst Excel Assessment (Step-by-Step Guide + Tips)
Excel assessments test how quickly you can structure messy data, calculate the right metrics, and communicate clear business insights under pressure.
Robert Half Says AI Fluency in Interviews Is Now Baseline, But It’s Also Slowing Hiring
AI is raising the floor for candidates, but forcing companies to redesign interviews to better test real judgment and decision-making.
How to Become a Business Intelligence Analyst in 2026: Skills and Roadmap
A practical guide to becoming a BI analyst, covering SQL, data modeling, dashboards, and the real-world skills needed to turn data into business decisions.