
Uber Data Engineer Interview Guide: Process, Questions & Preparation Tips (2026)


Introduction
Preparing for an Uber data engineer interview means stepping into one of the most demanding real-time data environments in technology. Uber operates a global marketplace where millions of trips, payments, and events flow through streaming and batch systems every day. From dynamic pricing and dispatch to fraud detection and marketplace health, data engineering sits at the foundation of how decisions are made. As Uber continues to scale across mobility, delivery, and logistics, data engineers are expected to design pipelines that are reliable under load, flexible for experimentation, and fast enough to support real-time use cases.
The Uber data engineering interview reflects this reality. You are evaluated on far more than writing correct SQL or designing a clean schema. Interviewers look for strong data modeling judgment, practical pipeline design, and the ability to reason about latency, correctness, and trade-offs at scale. Clear communication matters just as much as technical depth, especially when explaining how your systems support downstream analytics and machine learning teams. This guide outlines each stage of the Uber data engineer interview, highlights the most common Uber specific interview questions, and shares proven strategies to help you stand out and prepare effectively with Interview Query.
Uber Data Engineer Interview Process
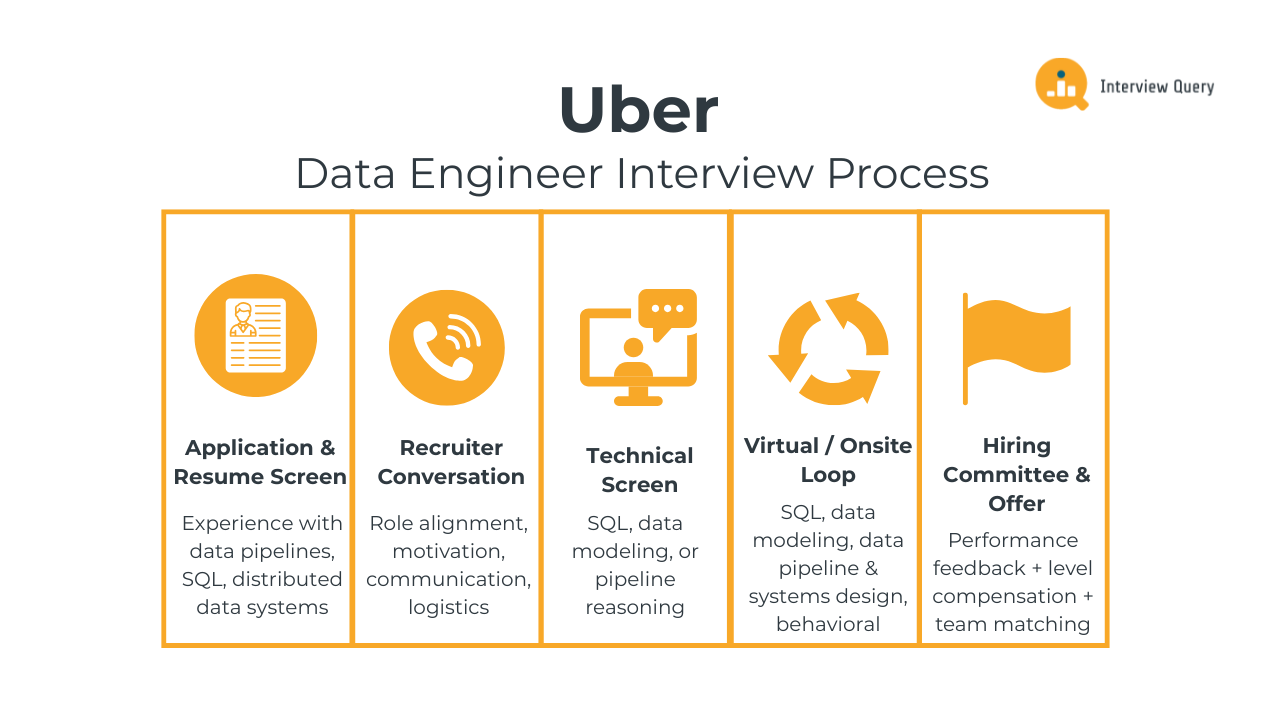
The Uber data engineer interview process evaluates how well you design, reason about, and operate data systems at real-world scale. At Uber, interviewers focus on SQL depth, data modeling judgment, pipeline and systems design, and how clearly you communicate trade-offs under realistic constraints. The process is structured to test both technical execution and decision-making, especially in environments with high data volume, low latency requirements, and downstream business impact. Most candidates complete the full loop within three to five weeks, depending on scheduling and team needs.
Below is a breakdown of each stage and what Uber interviewers consistently evaluate throughout the process.
Application and Resume Screen
During the initial screen, Uber recruiters look for hands-on experience building and owning data pipelines, strong SQL fundamentals, and familiarity with distributed data systems. Resumes that stand out clearly show end-to-end ownership, such as designing schemas, improving pipeline reliability, or supporting analytics and machine learning teams. Experience with streaming systems, experimentation platforms, or marketplace data is especially relevant. Impact-driven bullet points matter more than tool lists.
Tip: Quantify scale and outcomes clearly. Highlight metrics like data volume processed, latency reductions, cost savings, or reliability improvements to demonstrate ownership and production readiness.
Recruiter Phone Screen
The recruiter conversation focuses on role alignment, motivation, and communication. You will discuss your background, the types of data systems you have worked on, and why Uber’s marketplace problems interest you. Recruiters also confirm logistics such as location, level alignment, and compensation expectations. This stage is non-technical but filters for clarity of thought and genuine interest in Uber’s data challenges.
Tip: Prepare a concise narrative that connects your past data engineering work to real-time decision systems, showing you understand Uber’s business context, not just the role title.
Technical Phone Screen
The technical screen typically includes one live interview focused on SQL, data modeling, and pipeline reasoning. You may be asked to write complex queries, reason about schema design, or explain how you would build or debug a data pipeline. Interviewers pay close attention to how you think through edge cases, performance trade-offs, and data correctness, not just whether your final answer is correct.
Tip: Talk through your assumptions before writing code. Clear problem framing signals strong analytical discipline and reduces costly misinterpretations.
Virtual or Onsite Interview Loop
The virtual or onsite interview loop is the most comprehensive stage of the Uber data engineer interview. It usually consists of four to five interviews, each lasting around 45 to 60 minutes. These rounds assess SQL depth, data modeling, pipeline and systems design, and behavioral ownership in realistic Uber-style scenarios.
SQL and analytics round: You will work with large, event-driven datasets and write queries involving joins, aggregations, and window functions. Common tasks include computing marketplace metrics, identifying trends over time, or handling duplicate and late-arriving events. Interviewers evaluate correctness, readability, and performance awareness.
Tip: Explicitly explain how your query handles nulls, duplicates, and time boundaries. This demonstrates attention to data quality and analytical rigor.
Data modeling and schema design round: This round tests how you design schemas for trips, users, payments, or events. You may discuss normalization trade-offs, slowly changing dimensions, and how models support both batch and streaming consumers. Interviewers look for designs that scale cleanly and serve downstream analytics reliably.
Tip: Emphasize how your model supports experimentation and metric consistency, which signals strong empathy for analytics and product teams.
Data pipeline and systems design round: You will design a batch or near real-time pipeline end to end, covering ingestion, transformation, storage, monitoring, and failure recovery. Topics often include handling late data, backfills, schema evolution, and observability. The goal is to assess system thinking under production constraints.
Tip: Discuss failure modes explicitly and how you would detect and recover from them. Reliability awareness is a key bar for senior data engineers at Uber.
Behavioral and collaboration round: This interview focuses on ownership, communication, and cross-functional work. Expect questions about pipeline incidents, disagreements with stakeholders, or mentoring others. Uber values engineers who take responsibility for outcomes and communicate clearly during high-pressure situations.
Tip: Frame stories around impact and learning. Showing how you improved systems after issues highlights maturity and long-term thinking.
Hiring Committee and Offer
After the interview loop, interviewers submit independent feedback that is reviewed by a hiring committee. The committee evaluates consistency across rounds, technical strength, communication clarity, and role level alignment. If approved, Uber determines your level and prepares an offer that reflects scope, experience, and location. Team matching may also occur at this stage based on interview signals and business needs.
Tip: Strong, consistent performance across interviews matters more than excelling in a single round. Focus on clarity and sound judgment throughout the process.
Want to master the full data engineering lifecycle? Explore our Data Engineering 50 learning path to practice a curated set of data engineering questions designed to strengthen your modeling, coding, and system design skills.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Uber?
Uber Data Engineer Interview Questions
The Uber data engineer interview includes a mix of SQL, data modeling, pipeline design, and behavioral questions that reflect how data systems support real-time marketplace decisions at Uber. At Uber, interviewers evaluate how you work with event-driven data, reason about scale and latency, and design systems that remain reliable under constant change. The goal is not just to test technical correctness, but to understand how you handle ambiguity, trade-offs, and communication in high-impact environments where data directly influences pricing, dispatch, and safety.
Read more: Data Engineer Case Study Interview Questions + Guide
SQL and Analytics Interview Questions
SQL is a core signal in Uber data engineer interviews. SQL questions often involve large event tables, time-based metrics, window functions, and data quality challenges common in streaming systems. Interviewers want to see whether you can write clean, performant queries while reasoning carefully about time, duplicates, and incomplete data.
How would you calculate rider retention over time using trip data?
This question tests whether you can turn a business concept into a precise, defensible metric. Uber cares about retention because rider behavior directly affects marketplace liquidity and pricing efficiency. To answer, you would cohort riders by their first completed trip, then track whether they take subsequent trips in defined windows such as weekly or monthly intervals. You would aggregate activity by cohort and time bucket, being explicit about what counts as “active,” and ensure riders with sporadic usage are handled consistently.
Tip: At Uber, always state your retention definition out loud before querying. This shows metric ownership and prevents misalignment with product and growth teams.
-
This question evaluates your ability to translate probabilistic logic into SQL, which matters for fair and efficient dispatch systems at Uber. You would typically compute a cumulative distribution using the weight column, generate a random number, and select the driver whose cumulative weight crosses that threshold. This approach ensures drivers with higher weights are more likely to be chosen without being deterministic.
Tip: Call out fairness and repeatability concerns. Uber values engineers who think about how randomness affects driver trust and marketplace balance.
-
This tests your understanding of randomness and bias in SQL selection. Uber asks this to see if you recognize that naïvely ordering by random on the raw table can overweight popular values. The correct approach is to first select distinct manufacturers, then apply a random ordering and limit to one. This ensures each make has equal probability regardless of frequency.
Tip: Explicitly explain why you deduplicate first. That reasoning shows awareness of bias in real marketplace data.
Head to the Interview Query dashboard to practice the exact SQL, data pipeline design, system reasoning, and behavioral questions tested in Uber data engineer interviews. With built-in code execution, performance analytics, and AI-guided feedback, it helps you work through production-style problems, identify gaps in your reasoning, and sharpen how you explain trade-offs at marketplace scale.
-
This question tests joins, aggregation, and ranking, all common in Uber analytics workflows. You would join users to rides, aggregate total distance per user, then rank using a window function such as
RANK()orDENSE_RANK(). Uber interviewers look for clean logic, correct handling of users with no rides, and awareness of performance on large fact tables.Tip: Mention how you would handle missing rides or inactive users. This signals production-ready thinking, not just query correctness.
How do window functions help with time-based marketplace metrics?
This question checks whether you understand why window functions are foundational at Uber, not just how they work. Window functions let you compute rolling averages, week-over-week changes, and rankings without collapsing event-level data. At Uber, this is critical for tracking metrics like rolling trip volume, driver utilization, or incentive effectiveness while preserving granularity.
Tip: Tie each window function to a real Uber metric. Showing business context tells interviewers you design queries for decisions, not dashboards alone.
If you want to master SQL interview questions, join Interview Query to access our 14-Day SQL Study Plan, a structured two-week roadmap that helps you build SQL mastery through daily hands-on exercises, real interview problems, and guided solutions. It’s designed to strengthen your query logic, boost analytical thinking, and get you fully prepared for your next data engineer interview.
Data Modeling and Schema Design Interview Questions
This section evaluates how well you design schemas that can power Uber’s real-time marketplace while remaining reliable for long-term analytics. At Uber, data models sit behind pricing, dispatch, incentives, and experimentation, so interviewers focus on correctness over time, scalability, and how easily downstream teams can reason about metrics.
How would you design a schema for trips and payments?
This question tests whether you can separate core facts while preserving analytical flexibility. Uber asks this because trips and payments evolve at different cadences and serve different consumers. A strong answer explains modeling trips as the primary fact table, payments as a related but distinct fact, and linking them with stable keys. You should discuss how to avoid duplicating metrics like revenue while still supporting common joins for analytics and experimentation.
Tip: Explain how your design prevents double counting across teams. That signals strong metric ownership, a critical skill for Uber data engineers.
-
This question evaluates your ability to model relationships clearly and at scale. Uber cares about clean separation between entities such as riders, drivers, vehicles, and trips, with well-defined foreign keys. To answer, walk through the core tables, how they join, and how the schema supports both real-time queries and historical analysis. Emphasize simplicity and extensibility rather than over-optimization.
Tip: Call out how your schema adapts when new ride types or pricing models are introduced, which shows forward-looking system design.
When would you denormalize tables and why?
This question looks for judgment, not rigid rules. Uber asks this because denormalization can significantly reduce query latency in high-volume analytics, but it also increases maintenance risk. A strong answer explains denormalizing for read-heavy, latency-sensitive workloads while keeping authoritative sources normalized. You should tie the decision directly to query patterns and cost considerations.
Tip: Mention how you monitor denormalized data for drift. That shows you think about long-term correctness, not just performance wins.
-
This question tests end-to-end modeling and system thinking. Although framed broadly, Uber uses similar reasoning for dispatch and pricing systems. A good answer defines core entities, separates real-time availability from historical pricing data, and explains how schemas support fast reads and accurate billing. Interviewers want to see how you balance functional needs with non-functional requirements like latency and reliability.
Tip: Explicitly connect schema choices to real-time pricing updates. This demonstrates awareness of how data models affect live user experience.
Head to the Interview Query dashboard to practice the exact SQL, data pipeline design, system reasoning, and behavioral questions tested in Uber data engineer interviews. With built-in code execution, performance analytics, and AI-guided feedback, it helps you work through production-style problems, identify gaps in your reasoning, and sharpen how you explain trade-offs at marketplace scale.
How do you version schemas safely?
This question evaluates how you manage change without breaking downstream consumers. Uber asks this because many teams depend on shared datasets. A strong answer covers backward-compatible changes, versioned fields or tables, validation checks, and staged rollouts. You should also explain how you communicate changes and deprecations clearly.
Tip: Emphasize consumer communication as part of versioning. That signals collaboration skills and production-level ownership.
Watch next: Top 10+ Data Engineer Interview Questions and Answers
For deeper, Uber-specific preparation, explore a curated set of 100+ data engineer interview questions with detailed answers. In this walkthrough, Jay Feng, founder of Interview Query, breaks down more than 10 core data engineering questions that closely mirror what Uber looks for, including advanced SQL patterns, distributed systems reasoning, pipeline reliability, and data modeling trade-offs. The explanations focus on how to think through real-world scenarios, making it especially useful for preparing for Uber’s data engineer interview loop.
Data Pipeline and Systems Design Interview Questions
This section evaluates how well you design, operate, and evolve data pipelines under real-world constraints. At Uber, pipelines power real-time pricing, dispatch, experimentation, and marketplace monitoring, so interviewers focus on reliability, scalability, and how systems behave when things go wrong, not just ideal architectures.
-
This question tests whether you can reason through a full pipeline lifecycle, from ingestion to analytics-ready data. Uber asks this to see how you handle multiple sources, daily batch ingestion, transformations, and data quality before modeling. A strong answer walks through ingestion, validation, normalization, aggregation, and storage, with clear ownership of failures and reprocessing. The emphasis is on correctness and repeatability, not model tuning.
Tip: Explain how you would reprocess historical data safely. That signals you understand long-term maintenance, not just initial setup.
How do you ensure data quality in streaming systems?
This question evaluates proactive quality ownership in environments where bad data can immediately impact decisions. Uber expects you to discuss validation at ingestion, schema enforcement, completeness checks, and real-time monitoring. You should also explain how you detect silent failures, such as partial event drops or skewed distributions, rather than relying on downstream bug reports.
Tip: Call out checks that run automatically without manual review. This shows reliability thinking suited for always-on marketplace systems.
-
This question tests your ability to balance scale, cost, and performance. Uber asks this because inefficient designs quickly become expensive at marketplace scale. A strong answer explains tiered storage, partitioning strategies, retention policies, and separating hot and cold data. You should show awareness of query patterns and how architecture choices reduce unnecessary compute.
Tip: Tie cost decisions to query frequency and business value. That demonstrates pragmatic engineering judgment.
-
This question evaluates robustness in less predictable data flows. Uber wants to see how you handle missing files, late arrivals, schema drift, and partial uploads. A good answer explains ingestion triggers, validation steps, idempotent processing, and clear failure alerts, ensuring downstream teams can trust the data despite unreliable inputs.
Tip: Emphasize idempotency. This shows you design pipelines that recover cleanly from retries and upstream issues.
Head to the Interview Query dashboard to practice the exact SQL, data pipeline design, system reasoning, and behavioral questions tested in Uber data engineer interviews. With built-in code execution, performance analytics, and AI-guided feedback, it helps you work through production-style problems, identify gaps in your reasoning, and sharpen how you explain trade-offs at marketplace scale.
How do you monitor pipeline reliability?
This question focuses on observability and accountability. Uber expects monitoring beyond job success, including freshness, volume, distribution shifts, and SLA breaches. A strong answer explains how alerts tie directly to business impact, such as incorrect pricing or delayed metrics, rather than generic system health.
Tip: Frame monitoring in terms of who is affected when something breaks. That signals outcome-driven ownership, not just technical vigilance.
Behavioral and Collaboration Interview Questions
This section focuses on how you communicate, take ownership, and collaborate in high-pressure environments. At Uber, data engineers regularly work across product, operations, analytics, and platform teams, often when systems are under load or metrics are moving unexpectedly. Interviewers use these questions to assess judgment, accountability, and your ability to drive alignment when stakes are high.
Why should we hire you for an Uber data engineer position?
This question evaluates how well you understand Uber’s needs and how clearly you can connect your skills to real impact. Uber looks for candidates who go beyond generic strengths and explain how their experience building reliable pipelines, improving data quality, or supporting real-time decisions maps directly to marketplace problems.
Sample answer: In my previous role, I owned a high-volume event pipeline that supported pricing analytics across multiple regions. When data delays began affecting decision timelines, I redesigned the ingestion and monitoring flow, reducing latency by 30 percent and eliminating manual backfills. That experience taught me how critical reliability and clear communication are when data drives live decisions, which is why Uber’s real-time marketplace problems strongly align with how I like to work.
Tip: Tie your answer to concrete outcomes. Uber interviewers value clarity on impact more than broad statements about passion or skills.
Tell me about a time you owned a critical pipeline failure.
This question tests accountability and learning under pressure. Uber expects engineers to take ownership when systems fail, communicate clearly, and improve the system afterward.
Sample answer: A daily aggregation pipeline I owned failed silently due to an upstream schema change, causing incorrect metrics to be published. I identified the issue through anomaly checks, rolled back the data, and coordinated with stakeholders to reset expectations. Afterward, I added schema validation and alerting, which prevented similar issues and reduced incident response time by over 40 percent.
Tip: Focus on what you changed after the incident. Uber values engineers who turn failures into lasting system improvements.
Describe a disagreement with a product or data science partner.
This question evaluates collaboration and influence without authority. Uber engineers often need to align on metrics, trade-offs, or timelines across teams.
Sample answer: I once disagreed with a product partner on how to define an engagement metric for an experiment. Instead of pushing my view, I walked through historical data showing how their definition introduced bias. We aligned on a revised metric that better reflected user behavior and shipped the experiment on time, improving decision confidence across the team.
Tip: Emphasize listening and data-backed alignment. Uber looks for engineers who resolve conflict by building trust, not winning arguments.
How would you convey insights and the methods you use to a non-technical audience?
This question tests communication clarity. Uber data engineers frequently explain data issues to operations or product teams who need actions, not internals.
Sample answer: When presenting a pipeline change to non-technical stakeholders, I focused on what changed, why it mattered, and what actions were needed. I avoided implementation details and used simple visuals to show the before-and-after impact, which helped the team adjust decisions without confusion.
Tip: Frame explanations around impact and decisions. Uber values communication that enables action, not technical depth for its own sake.
Head to the Interview Query dashboard to practice the exact SQL, data pipeline design, system reasoning, and behavioral questions tested in Uber data engineer interviews. With built-in code execution, performance analytics, and AI-guided feedback, it helps you work through production-style problems, identify gaps in your reasoning, and sharpen how you explain trade-offs at marketplace scale.
Tell me about mentoring a junior engineer.
This question assesses leadership and leverage. Uber values engineers who raise the bar for the entire team.
Sample answer: I mentored a junior engineer who struggled with debugging distributed jobs. I paired with them during incidents, explained how to trace failures systematically, and helped them document common patterns. Within two months, they were independently resolving issues and reduced on-call escalations by 25 percent.
Tip: Highlight how mentorship improved team output. Uber looks for engineers who scale impact beyond their own tasks.
Looking for hands-on problem-solving? Test your skills with real-world challenges from top companies. Ideal for sharpening your thinking before interviews and showcasing your problem solving ability.
What Does an Uber Data Engineer Do?
An Uber data engineer designs and maintains the data systems that power one of the world’s largest real-time marketplaces. At Uber, data engineers sit at the intersection of streaming infrastructure, analytics, and machine learning, enabling decisions across pricing, dispatch, incentives, safety, and fraud. The role focuses on building scalable batch and streaming pipelines, enforcing data quality, and modeling datasets that support both near real-time decisioning and long-term analysis. Uber data engineers work closely with product managers, data scientists, and platform engineers to ensure that data is trustworthy, timely, and usable across teams that operate at city and global scale.
| What They Work On | Core Skills Used | Tools And Methods | Why It Matters At Uber |
|---|---|---|---|
| Trip and event ingestion | Streaming systems, schema design, backpressure handling | Event-based pipelines, incremental processing | Ensures trip, rider, and driver events are captured accurately in real time |
| Real-time analytics pipelines | Low-latency data processing, windowing, aggregation | Streaming ETL, watermarking, late-event handling | Powers pricing, dispatch decisions, and marketplace health metrics |
| Data modeling for analytics | Dimensional modeling, normalization trade-offs | Fact tables, slowly changing dimensions | Enables consistent reporting and experimentation across teams |
| Data quality and reliability | Monitoring, validation, failure recovery | Checks, alerts, backfills | Prevents downstream metric breaks and incorrect business decisions |
| Platform and pipeline scalability | Distributed systems, performance tuning | Partitioning strategies, compute optimization | Keeps data systems reliable during peak demand and traffic spikes |
Tip: Uber data engineers are evaluated on how well they design for real-world constraints. In interviews, explain how your pipelines handle late data, failures, and scale growth, showing judgment in reliability and system ownership, not just technical correctness.
How To Prepare For An Uber Data Engineer Interview
Preparing for an Uber data engineer interview requires more than rehearsing SQL patterns or memorizing pipeline components. You are preparing for a role that supports real-time pricing, dispatch, experimentation, and marketplace reliability at global scale. At Uber, data engineers are expected to think in terms of latency, correctness, and downstream impact while communicating clearly with product, analytics, and platform partners. Strong candidates show they can reason about messy, evolving data systems and make sound trade-offs under pressure.
Below is a focused, practical approach to preparing effectively.
Build intuition for event-driven and time-sensitive data: Uber’s data ecosystem is centered around event streams where late arrivals, duplicates, and partial data are normal. Practice reasoning about event time versus processing time, watermarking, and how metric definitions change when data arrives out of order. Focus on how these realities affect business metrics, not just pipeline mechanics.
Tip: Be ready to explain how you would prevent a late event from silently changing a published metric, which signals strong ownership of data correctness.
Practice SQL with scale and performance in mind: Go beyond writing correct queries and focus on efficiency, readability, and edge cases. Practice queries that involve large fact tables, window functions, and time-based comparisons, while explicitly thinking about partitioning and filtering. Uber interviewers care about how your queries behave on billions of rows.
Tip: Always explain how your query scales and where it might break, which demonstrates production-level SQL judgment.
Strengthen schema and modeling judgment: Review how to design schemas that support experimentation, analytics, and machine learning simultaneously. Practice explaining trade-offs between normalization and denormalization, and how modeling decisions affect downstream consumers months later. This is a key differentiator for senior candidates.
Tip: Frame schema decisions around metric consistency and experimentation velocity to show awareness of how data is actually used at Uber.
Prepare end-to-end pipeline narratives: Uber values engineers who think in systems, not isolated components. Practice walking through a pipeline from ingestion to consumption, including monitoring, alerting, backfills, and failure recovery. Emphasize how you would detect issues before stakeholders notice them.
Tip: Call out specific failure modes and how you would respond, since this highlights reliability instincts interviewers look for.
Refine behavioral stories around ownership: Review past incidents where you owned a pipeline, fixed a broken metric, or improved reliability without being asked. Structure stories around impact, learning, and what you changed afterward. Uber interviewers listen closely for accountability and long-term thinking.
Tip: Focus on what you did after the issue, not just how you fixed it, which signals maturity and leadership.
Simulate realistic interview conditions: Practice full interview loops that include SQL, modeling or systems design, and behavioral discussions back to back. Time yourself, explain your thinking out loud, and identify where explanations become unclear. Structured mock practice is often the fastest way to improve signal quality.
Use Interview Query’s mock interviews to rehearse Uber-style scenarios with targeted feedback.
Tip: Treat every mock as a real interview and track repeated hesitation points, since eliminating those moments often leads to the biggest performance gains.
Want to get realistic practice on SQL and data engineering questions? Try Interview Query’s AI Interviewer for tailored feedback that mirrors real interview expectations.
Uber Data Engineer Salary
Uber’s compensation framework is built to reward engineers who design highly reliable, low-latency data systems that support real-time marketplace decisions. Data engineers receive competitive base pay, annual bonuses, and substantial equity through restricted stock units. Your total compensation depends on level, location, technical scope, and the business-critical systems you support. Most candidates interviewing for Uber data engineering roles are evaluated at mid-level or senior bands, particularly if they have experience with streaming systems, large-scale data infrastructure, or marketplace analytics at scale.
Read more: Data Engineer Salary
Tip: Confirm your target level early with your recruiter, since Uber’s leveling strongly influences both compensation range and the expectations tied to system ownership and impact.
| Level | Role Title | Total Compensation (USD) | Base Salary | Bonus | Equity (RSUs) | Signing / Relocation |
|---|---|---|---|---|---|---|
| L4 | Data Engineer (Mid Level) | $160K – $220K | $130K–$160K | Performance based | Standard RSU grants | Offered selectively |
| L5 | Senior Data Engineer | $200K – $280K | $150K–$180K | Above target possible | Larger RSU packages | Common for senior hires |
| L6 | Staff Data Engineer | $250K – $350K+ | $170K–$210K | High performer bonuses | Significant RSUs + refreshers | Frequently offered |
| L7 | Senior Staff / Principal | $300K – $450K+ | $190K–$240K | Top-tier bonuses | Very large RSU grants | Case dependent |
Note: These estimates are aggregated from data on Levels.fyi, Glassdoor, TeamBlind, public job postings, and Interview Query’s internal salary database.
Tip: Compensation increases meaningfully at L5 and above, where Uber expects broader ownership over data platforms and cross-team reliability.
Average Base Salary
Average Total Compensation
Negotiation Tips That Work for Uber
Negotiating compensation at Uber is most effective when you understand both market benchmarks and Uber’s internal leveling expectations. Recruiters respond best to candidates who communicate clearly, use data-backed benchmarks, and articulate impact at scale.
- Confirm your level early: Uber’s L4 to L7 levels define scope, ownership, and compensation bands. Clarifying level alignment before negotiation prevents mismatched expectations and strengthens your position.
- Anchor with verified benchmarks: Use data from Levels.fyi, Glassdoor, and Interview Query salaries to ground discussions. Frame your value through concrete outcomes such as latency reductions, pipeline reliability gains, or cost efficiency improvements.
- Account for geographic differences: Pay varies across San Francisco, Seattle, New York, and remote roles. Ask explicitly for location-specific ranges to evaluate the offer accurately.
Tip: Request a full compensation breakdown including base salary, bonus target, equity vesting schedule, refreshers, and any signing incentives so you can compare offers clearly and negotiate from a position of confidence.
FAQs
How long does the Uber data engineer interview process usually take?
Most candidates complete the process within three to five weeks. Timelines depend on interviewer availability, level calibration, and whether team matching happens in parallel. Recruiters typically share next steps within a few days after each stage.
Does Uber emphasize streaming data experience over batch systems?
Uber values experience with both, but streaming is especially important for real-time pricing, dispatch, and marketplace monitoring. Candidates who can explain how batch and streaming pipelines coexist and complement each other tend to stand out.
What level of SQL depth is expected for Uber data engineers?
Uber expects strong intermediate to advanced SQL skills. This includes complex joins, window functions, time-based aggregations, and reasoning about performance and data correctness on large event tables.
How important is system design for mid-level data engineer roles at Uber?
System design becomes increasingly important at L5 and above, but even mid-level candidates are expected to reason about end-to-end pipelines. Interviewers look for structured thinking around reliability, scalability, and failure handling.
Are Uber data engineer interviews tool-specific?
No. Uber interviewers focus on concepts and reasoning rather than specific technologies. You can discuss tools you have used, but success depends on explaining trade-offs and system behavior, not naming frameworks.
What behavioral traits does Uber prioritize for data engineers?
Ownership, clear communication, and accountability matter most. Uber values engineers who proactively improve systems, handle incidents calmly, and collaborate effectively with product and analytics partners.
Can candidates be down-leveled after interviews?
Yes. Uber’s hiring committee may recommend a different level if interview signals better match another scope. This is common and does not reflect poor performance, but rather alignment with expectations.
How are teams assigned after the interview loop?
Team matching may happen before or after the final decision depending on business needs. Recruiters often consider your interests, past experience, and interviewer feedback when aligning you with a team at Uber.
Become an Uber Data Engineer with Interview Query
Preparing for the Uber data engineer interview means developing deep technical judgment, strong system-level thinking, and the ability to operate confidently in a real-time, marketplace-driven environment. At Uber, data engineers are evaluated on how well they design reliable pipelines, reason through scale and latency trade-offs, and communicate clearly with cross-functional partners. By understanding Uber’s interview structure, practicing real-world SQL, and refining how you explain system decisions and trade-offs, you can approach each stage with clarity and confidence.
For focused preparation, explore the full Interview Query’s question bank, practice with the AI Interviewer, or work directly with an expert through Interview Query’s Coaching Program to sharpen your approach and stand out in Uber’s data engineering hiring process.
Discussion & Interview Experiences