
SQL Scenario Based Interview Questions (With Answers & Real Examples)


Introduction
In today’s competitive hiring environment, companies are shifting from textbook SQL questions to real-world, scenario-based problems that mimic everyday business challenges. Whether you’re applying for a role as a data analyst, data scientist, data engineer, or backend developer, these questions aim to test not just your knowledge of SQL syntax, but your ability to think critically and solve problems using data.
Unlike traditional queries that ask you to define JOIN types or list SQL functions, scenario-based SQL interview questions demand a practical mindset, requiring you to write complex queries for use cases like tracking user churn, generating cohort reports, or aggregating sales by product category and region. These mirror the actual problems teams face when working with production databases.
This guide dives deep into SQL real-time interview questions and answers across experience levels from freshers to senior professionals with examples in MySQL, PostgreSQL, SQL Server, and Oracle. Whether you’re preparing for your first job or targeting top tech firms like Amazon or Meta, this is your one-stop resource for mastering scenario-based SQL interview prep.
Beginner Level SQL Scenario Interview Questions (0–3 Years)
If you’re preparing for entry-level roles like data analyst, data engineer, or QA analyst, then SQL scenario-based interview questions are your gateway to standing out.
This section covers questions suited for freshers and professionals with up to 3 years of experience, helping you build strong SQL fundamentals. You’ll practice key operations like joins, filtering, grouping, and conditional logic through relatable use cases. These questions are especially valuable for mastering SQL interviews at companies like Amazon, Meta, Capgemini, and startups where real-time analytics matter.
For each question, we include a clickable link to its problem page, a short explanation of what it tests, how to approach it, and why it matters in practice.
Find the largest wireless packages sent per SSID.
This question tests time-based filtering, aggregation, and maximum value extraction. It’s asked to see if you can isolate a specific timeframe and identify top-performing devices per group. To solve this, filter by timestamp for the first 10 minutes of Jan 1, 2022, group by device and SSID, then find the max number of packages per SSID. This is common in network analytics, especially during high-traffic periods or system testing.
You can explore the Interview Query dashboard that lets you practice real-world SQL interview questions in a live coding environment. You can write, run, and submit queries while getting instant feedback, perfect for mastering scenario-based SQL problems across domains.
Return users who were ‘Excited’ but never ‘Bored’.
This question tests your ability to perform negative filtering using subqueries or anti-joins. It’s asked to check whether you can detect inclusion in one state while excluding another. You’ll filter users who ever had the ‘Excited’ state and use
NOT EXISTSorLEFT JOINto ensure no ‘Bored’ records. This logic is essential in segmenting engaged users in behavioral analytics.Select the 2nd highest salary in the engineering department.
This question tests your understanding of ranking, sorting, and filtering logic. It’s asked to verify if you can find the second distinct value while handling duplicates. You can use
DENSE_RANK(), a subquery withMAX(), orLIMIT + OFFSETdepending on the platform. This is commonly used in performance benchmarking and reporting second-best metrics.Write a query to answer multiple transaction-related questions.
This question tests multi-step aggregation and filtering logic. It’s asked to evaluate whether you can extract various insights—like counts, statuses, and revenue—in a single query. To solve this, use multiple aggregations such as
COUNT,MAX, and conditional filters withCASE WHEN. This models real-world dashboards where diverse KPIs are presented together.Count users with identical logins on Jan 1, 2022.
This question tests your understanding of nested aggregation. It’s asked to assess whether you can calculate frequency distributions of events. First, count logins per user, then group by that count to see how many users share the same login frequency. This technique is key in clustering and understanding behavioral distributions.
Return all neighborhoods that have zero users.
This question tests anti-joins and gap detection across related tables. It’s asked to determine whether you can identify records that don’t have any associated activity. Use a
LEFT JOINfromneighborhoodstousersand filter forNULLvalues in the joined result. This is widely used in real estate, CRM, or geographic coverage analytics.Calculate the average revenue per customer.
This question tests grouped aggregation across different revenue types. It’s asked to assess whether you can separate and compute averages by customer or revenue source. Group by customer ID and use
AVG()on revenue, possibly segmented by product type (e.g., service vs software). This logic underlies core B2B SaaS analytics and monetization breakdowns.Summarize each game with result and score differential.
This question tests string manipulation and conditional formatting. It’s asked to evaluate whether you can generate human-readable output using SQL. Use
CONCAT()or equivalent to format a result string like “Won by 5” or “Lost by 3” based on game outcomes. Such output formatting is useful for reporting dashboards and summary exports.Determine how many different users gave a like on June 6, 2020
This question tests event filtering and deduplicated counting. It’s asked to verify if you can isolate actions on a specific date. Filter with
WHERE action = 'like' AND date = '2020-06-06'and useCOUNT(DISTINCT user_id). This is used in campaign analysis or feature adoption tracking.Find the largest salary grouped by department.
This question tests grouped maximum value queries. It’s asked to check your ability to extract top values per category. Use
GROUP BY departmentwithMAX(salary)to return the highest-paid employee per group. This pattern is frequent in compensation reports and budget planning.Count how many users opened an email.
This question tests behavioral filtering with event logs. It’s asked to assess how well you track specific user actions. Use a
WHERE action = 'email_opened'filter and countDISTINCT user_id. This is foundational for email campaign analytics and funnel conversion metrics.Find the average quantity of each product per transaction by year.
This question tests your ability to handle grouped aggregations over time. It’s asked to verify if you can break down metrics by year and product. Group by
YEAR(order_date)andproduct_id, and computeAVG(quantity)per transaction. This is often used in demand forecasting and inventory management.Return number of songs played per date per user.
This question tests temporal grouping and event counting. It’s asked to check if you can track activity levels across users and time. Group by user ID and date, and count the number of song play events. This mirrors user retention dashboards and listening analytics in media apps.
Count daily active users by platform in 2020.
This question tests filtering by time and computing unique daily metrics. It’s asked to confirm if you understand the definition of “active users.” Filter for
YEAR(date) = 2020, group by date and platform, and countDISTINCT user_id. This is essential in mobile and SaaS product analytics for tracking growth.Get the average order value segmented by gender.
This question tests joined aggregation and demographic segmentation. It’s asked to assess whether you can combine user and transaction data. Join customer and transaction tables on
user_id, group by gender, and applyAVG(order_value). This supports business decisions in marketing and product targeting.Find the average ride duration per user in minutes.
This question tests date/time arithmetic and user-level aggregation. It’s asked to see if you can compute time deltas and convert them appropriately. Subtract
start_timefromend_time, convert to minutes, and average by user ID. Used in transportation and mobility services for efficiency reporting.Identify users with fewer than 3 orders or total spend under $500.
This question tests conditional logic inside grouped filters. It’s asked to evaluate your ability to apply multiple thresholds in a
HAVINGclause. Group by user ID, count orders, sum spend, and filter withHAVING count < 3 OR sum < 500. This is used in retention models and campaign targeting for low-spend users.Return total distance traveled by each user.
This question tests joins and numerical aggregations. It’s asked to confirm your ability to sum up user activity metrics. Join user and ride tables, group by user, and compute
SUM(distance). This is common in logistics, delivery, and transportation analytics.Calculate the overall acceptance rate of friend requests.
This question tests join logic and ratio calculation. It’s asked to assess your ability to combine request and acceptance datasets. Join both tables, count total requests and accepted ones, then divide to get the rate. This pattern models social app KPIs and engagement funnels.
Compare average downloads for free vs paid accounts.
This question tests grouped averages with conditional filtering. It’s asked to check how well you separate cohorts and calculate behavior stats. Join downloads and accounts tables, filter by date, group by account type, and calculate average downloads. This reflects product analytics in freemium models like mobile apps and SaaS tools.
Intermediate SQL Scenario Interview Questions (3–5 Years)
At the intermediate level, SQL interviews shift from basic syntax checks to testing your problem-solving ability with complex datasets and real-time business logic. These questions often involve multi-table joins, window functions, aggregations, datetime filters, and subqueries, simulating real-world reporting or analytics pipelines.
You’ll face challenges such as:
- Aggregations & Conditional Grouping: e.g., “Summarize monthly revenue by category excluding discounts.”
- Temporal Logic & Ranking: e.g., “Retrieve the last three purchases per customer.”
- Set Operations & CTEs: e.g., “Find users who were active last quarter but not in the current one.”
These types of SQL scenario based interview questions for 3–5 years experience test not just correctness but clarity, efficiency, and your ability to handle scale. Whether you’re prepping for a BI Analyst or Senior Data Engineer interview, mastering these scenarios will help you stand out.
Return the running total of sales for each product since its last restocking.
This question tests your ability to perform time-aware aggregations with filtering logic. It’s specifically about calculating the running sales total that resets after each restocking event. To solve this, identify restocking dates and partition the sales by product, resetting the cumulative total after each restock using window functions and conditional logic. This pattern is critical for real-time inventory tracking in logistics and retail.
Compute percentage of comments in feed vs moments by ad.
This question tests aggregation and source-based breakdowns. It’s about counting and comparing interactions from two distinct app areas. Join necessary tables, group by ad and section, and compute each share using
COUNTand ratios. This reflects product analytics focused on content performance by the UI section.Return users who placed more than 3 orders in both 2019 and 2020.
This question tests conditional aggregation across time periods. It’s specifically about counting transactions per user per year, then filtering those who meet thresholds in multiple years. To solve this,
GROUP BYuser and year, useHAVINGto apply conditional logic for both years. This logic is commonly used in cohort or retention analyses.Calculate the average commute time for each NY commuter and the overall NY average.
This question tests layered aggregation and use of window functions. It’s about computing both individual and collective commute metrics. Filter by NY, calculate per-user averages, then use
AVG()OVER()to get the global average. This logic supports UX improvements and city-level mobility insights.Compute the average number of accepted friend requests per age group.
This question tests aggregation and conditional filtering. It’s about grouping user data by age group and summarizing social behavior. Join users with requests table, filter for accepted requests, group by age group, and calculate averages. This mirrors real-world analyses of demographic behavior in social platforms or marketing segments.
This interactive dashboard from Interview Query lets you practice real-world SQL interview questions in a live coding environment. You can write, run, and submit queries while getting instant feedback, perfect for mastering scenario-based SQL problems across domains.
Write a query to build a pivot table of total sales per branch by year.
This question tests time-series restructuring using conditional aggregation. It’s about displaying grouped values across multiple years as columns. Use
GROUP BYwithSUMandCASEstatements to pivot the data. Pivot tables like this are widely used in BI tools and reporting dashboards for trend comparison.Identify which products have prices greater than their own average transaction total.
This question tests your understanding of subqueries and comparative aggregation. It’s specifically about comparing a product’s price with the average of its own sales performance. To solve this, calculate average transaction total per product and filter where fixed price exceeds the computed average. This use case is relevant for pricing optimization and understanding underperforming SKUs.
Return the histogram of comment counts per user in Jan 2020 with bin = 1.
This question tests grouping and frequency analysis. It’s about determining how many users fall into each bucket of comment activity. First, filter for January 2020, count comments per user, then group by that count. This logic is often used in engagement clustering, especially for visualizations or dashboard summaries.
Write a query to determine if a shipment happened during a user’s membership.
This question tests date range comparisons and boolean labeling. It’s about checking if shipment dates fall within a user’s membership period. Use
CASE WHENwith date conditions to assign flags. This is often used in loyalty program tracking or benefit attribution analysis.Label users as ‘paid’ if they visited Facebook or Google, and ‘organic’ otherwise.
This question tests classification using filters and
CASEstatements. It’s specifically about tagging users based on their activity source. UseWHEREconditions orCASE WHENstatements to define the logic. This logic powers marketing attribution models and user segmentation pipelines.Write a query to decide whether to use Python or SQL to preprocess large mortgage datasets.
This question tests conceptual judgment in tool selection. It’s about evaluating tradeoffs between performance (SQL) and flexibility (Python). SQL is preferred for simple aggregations on large volumes, while Python suits custom or iterative logic. This distinction is crucial in modern data engineering workflows.
Calculate the % of accounts that closed on Jan 1, 2020, after being active on Dec 31, 2019.
This question tests your ability to filter records across consecutive days and calculate conditional percentages. It’s about tracking account closures using date snapshots. Filter for accounts active on Dec 31 and check if they closed by Jan 1, then compute the ratio. This is widely used in churn and transition metric calculations.
Compute the cumulative sales per product ordered by product_id and date.
This question tests the use of window functions to compute running totals. It’s specifically about calculating cumulative sales grouped by product and ordered chronologically. Use
SUM()OVER(PARTITION BY product_id ORDER BY date)for accuracy. This logic supports real-time dashboards and sales monitoring systems.Categorize sales into standard, premium, or promotional based on region, date, and amount.
This question tests nested conditional logic using
CASEstatements. It’s about applying a multi-factor classification rule. UseCASE WHENconditions on the required fields to assign categories appropriately. This type of logic is foundational for business rules in reporting pipelines and sales tagging.Write a query to identify which users had transactions with exactly a 10-second gap.
This question tests sequencing logic using window functions like
LAGandLEAD. It’s specifically about comparing timestamps across rows to find specific time intervals. UseLAGto get the previous timestamp per user and check for a 10-second gap. This is critical in fraud detection and anomaly detection systems.Compute which top 3 users got the most upvotes on comments written in 2020.
This question tests filtering, multi-table joins, and ranking logic. It’s about excluding deleted and self-upvoted comments, counting upvotes, and ranking users. Use filters with joins, then
GROUP BYandORDER BYto apply rank logic. This is useful in social network analytics for understanding top contributors.Find the percentage of users who had a 7-day streak visiting the same URL.
This question tests sequential pattern detection in time-series data. It’s about finding continuous daily visits to a URL per user. Use grouping, date-difference logic or
ROW_NUMBERto check for streaks. Streak tracking is common in user engagement, gamification, and loyalty metric systems.Design schema and query to find fastest car and model crossing Golden Gate Bridge.
This question tests schema design and time-difference analysis. It’s about modeling timestamped entries and calculating durations. Propose a schema with car_id, model, entry_time, exit_time, and compute duration differences, then aggregate by model. It’s important for event tracking and high-volume sensor applications.
Find which two students have the closest SAT scores and the difference.
This question tests your ability to perform self-joins and compute pairwise differences. It’s specifically about comparing every student’s score against others and finding the minimum absolute difference. To solve this, join the table to itself, compute absolute differences excluding identical IDs, and order by the difference to fetch the smallest. This is commonly used in similarity scoring or student ranking systems.
Return the running average number of item categories per order per user, then find the max.
This question tests nested aggregation and depth of grouping. It’s about counting unique categories per order, then averaging per user. Use
COUNT DISTINCTwithGROUP BYat two levels and applyMAX. This logic supports analytics in e-commerce around order diversity and product exploration.
Advanced SQL Scenario Interview Questions (10+ Years)
At the senior level, SQL scenario-based interview questions often mimic real-world data infrastructure challenges. These questions go beyond writing queries, they assess your ability to design scalable logic, debug long-running queries, and optimize for both correctness and performance. You may be asked to analyze billions of rows, handle recursive JOINs, or build decision trees inside SQL using nested CASE WHEN clauses.
Typical advanced challenges include:
- Recursive logic: Build organizational hierarchies or file system paths.
- Windowed computation: Use
PERCENT_RANK(),LAG(), andLEAD()to model trends. - Performance tuning: Speed up a report that processes 200M records.
- Nested logic flows: Apply multi-layered conditionals that mimic business decision trees.
Interviewers may also introduce constraints such as “no extra indexing” or “you must use CTEs only,” pushing you to think creatively. These advanced SQL challenges reflect your readiness to own analytics systems, debug query performance, and drive architectural decisions across teams.
We have a hypothesis that CTR is dependent on device type. How do you test it?
This question tests hypothesis testing and A/B test design. It’s asked to validate your ability to segment and statistically test categorical features. Split data by device, calculate click-through rates, and apply a t-test or chi-squared test. This is crucial in ad tech and marketing analytics when optimizing UI or targeting strategies.
Write a query to display a graph to understand push notification open rates.
This question tests event funnel tracking and time-series chart prep. It’s asked to confirm if you can analyze conversion steps across multiple stages. You’ll group by timestamp and notification event, then calculate open/conversion rates over time. This is widely used in product analytics and CRM engagement tracking.
Find the top five paired products and their names.
This question tests self-joins and pair enumeration. It’s asked to determine how you compute co-occurrence or joint metrics. You’ll join the product list with itself and filter based on cart/session context. This is critical in recommendation engines and market basket analysis.
Find the percentage of users that posted a job within 180 days of signing up.
This question tests time-difference filtering and cohort analysis. It’s asked to see how you tie action events to user lifecycles. To solve this, join users with job postings, calculate the day difference, and filter where
days ≤ 180, then compute percentage. This question relates to onboarding effectiveness and user lifecycle behavior.Write a query to calculate rolling balances for bank accounts
This question tests running totals. It’s specifically about maintaining a cumulative transaction balance over time. To solve this, use
SUM(amount) OVER (PARTITION BY account ORDER BY date). In finance, this underpins fraud monitoring and balance history.Detect overlapping subscription periods
This question tests interval joins. It’s specifically about detecting overlapping subscription periods for customers. To solve this, self-join subscriptions where one
start_dateis within another’s range. Businesses use this for churn and double-billing prevention.Count successful vs failed notification deliveries
This question tests
CASEstatements. It’s specifically about segmenting successful vs failed notifications. To solve this,SUM(CASE WHEN status=‘success’ THEN 1 ELSE 0 END). In real-world apps, this ensures reliability KPIs for messaging.Write a query to sum payments received grouped by type
This question tests aggregation by category. It’s specifically about summing payments by type or source. To solve this, group by
payment_typeandSUM(amount). In finance analytics, this rolls into revenue dashboards.Write a query to assign first-touch attribution in campaigns
This question tests window functions and attribution modeling. It’s asked to see if you can assign a conversion to the earliest campaign touchpoint. To solve this, partition by
user_id, order byevent_time, and filter forROW_NUMBER()=1. In practice, this models marketing attribution and informs budget allocation.
This interactive dashboard from Interview Query lets you practice real-world SQL interview questions in a live coding environment. You can write, run, and submit queries while getting instant feedback, perfect for mastering scenario-based SQL problems across domains.
Compute swipe precision metrics
This question tests ratios from engagement events. It’s asked to check if you can compute true positives ÷ all swipes. To solve this, filter correct swipes, divide by total swipes. In real-world apps, this measures quality of recommendation systems.
Count second-order likes (liker’s likers)
This question tests recursive joins or self-joins. It’s asked to see if you can count second-order likes (friends of friends). To solve this, join the likes table to itself, matching
liker_idtouser_id. In production, this models social graph engagement.Compute a cumulative distribution function (CDF)
This question tests window functions. It’s asked to see if you can compute running cumulative percentages. To solve this, use
SUM() OVER(ORDER BY value)/SUM(total). In practice, this is used for histograms and engagement analysis.Write a query to analyze how user activity influences purchasing behavior
This question tests CTE vs materialization cost and join selectivity when modeling conversion funnels. It’s asked to see if you can compute activity-to-purchase lift without massive shuffles. To solve this, pre-aggregate activity per user/day, materialize to a temp table with indexes on
(user_id, event_date), then join to purchases and compute uplift; compareEXPLAINplans for inline CTE vs temp table strategies. In practice, efficient funnel queries drive marketing and product decisions with timely SLAs.Compute cumulative users added daily with monthly resets
This question tests window framing and partition strategy on large time-series. It’s asked to evaluate if you can compute per-month cumulative counts without rescans. To solve this, use
SUM(1) OVER (PARTITION BY DATE_TRUNC('month', created_at) ORDER BY created_at ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)and ensure(created_at)clustering; validate no sort spills. In real-world BI, this feeds monthly growth dashboards with sub-second slices.Write a query to model notification conversions by type and event
This question tests composite indexing and semi-joins for event funnels. It’s asked to verify you can compute type-level conversion rates without duplicate counting. To solve, dedupe by
(user_id, notification_id)with a covering index, computeview → click → actionusingLEFT JOINchains andNOT EXISTSguards; confirm withEXPLAINthat joins hit the right indexes. In practice, this powers channel attribution and budget allocation.Recommend top users for new friends based on mutuals
This question tests graph-style joins and Top-K with window functions on large social tables. It’s asked to see if you can rank candidates without generating blow-ups from many-to-many joins. To solve, compute per-signal scores with semi-joins, aggregate to a candidate table, index on
(user_id, candidate_id), thenDENSE_RANK()by total score; validate join order viaEXPLAIN. In real products, this is the backbone of people-you-may-know features.Compute average response time to system messages
This question tests self-joins and
LAG()with precise ordering keys and indexes. It’s asked to ensure you can pair system→user events efficiently without whole-table windows. To solve, partition bythread_id, order by timestamp,LAG()to find the previous system msg, compute deltas, and ensure(thread_id, ts)indexing to avoid sorts. In operations analytics, this drives SLA and responsiveness dashboards.Calculate daily minutes in flight per plane
This question tests timestamp arithmetic and grouping. It’s specifically about converting departure/arrival timestamps into minute-level duration per plane and day. To solve this, compute
EXTRACT(EPOCH FROM arrival - departure)/60, group byplane_idandflight_date, and round down fractional minutes; handle overnight flights carefully. In aviation analytics, this supports aircraft utilization dashboards.Return the second-longest flight for each city pair
This question tests ranking within groups. It’s specifically about normalizing city pairs (A-B = B-A), computing durations, and finding the 2nd-longest. To solve this, store sorted city names as city_a, city_b, compute duration_minutes, then apply
ROW_NUMBER() OVER (PARTITION BY city_a, city_b ORDER BY duration_minutes DESC)and filter where rank=2. Airlines use this to plan backup aircraft allocations for long-haul routes.Write a query to track flights and related metrics
This question tests grouping and ordering. It’s specifically about summarizing flights per plane or route. To solve this, group by
plane_idor city pair andCOUNT/AVGdurations. This supports airline operations dashboards.
SQL Scenario Questions by Platform
While SQL’s foundations are consistent across platforms, subtle differences in syntax, optimization strategies, and query execution behavior can dramatically affect performance. Each database engine introduces its own quirks, making it essential to tailor your approach depending on the system you’re working with.
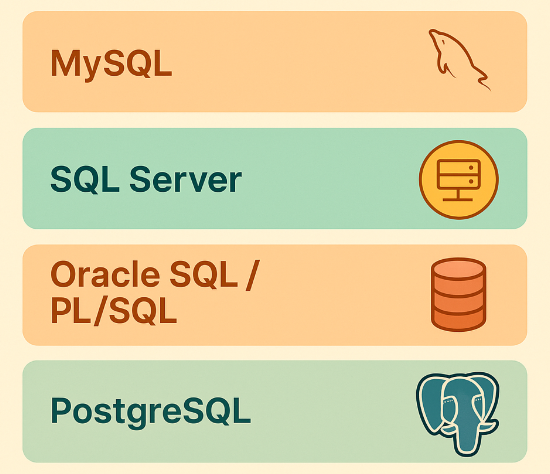
| Database | Common Interview Focus Areas |
|---|---|
| MySQL | - Uses LIMIT OFFSET for pagination, which performs poorly on large datasets. - Expect questions on indexed pagination, query caching, and optimizing slow joins with subqueries. - Advanced questions may test quirks in |
| SQL Server | - Uses TOP() instead of LIMIT. - Performance tuning with indexes, CTEs, and - Common topics include concurrency handling, deadlocks, and large ETL pipeline strategies. |
| Oracle SQL / PL/SQL | - Row limiting with ROWNUM or FETCH FIRST N ROWS. - Must understand ordering and filtering quirks with - PL/SQL introduces procedural elements (loops, cursors, - Common scenarios include stored procedures, nested blocks, and transaction rollback. |
| PostgreSQL | - Strong in analytics and warehousing. - Heavy use of advanced window functions ( - Interviewers may test JSON handling, arrays, CTEs, and recursive queries for semi-structured data. |
Understanding these platform-specific nuances not only improves your interview performance, it mirrors what real-world data engineers, analysts, and architects deal with when scaling SQL across diverse systems.
MySQL Examples
Concept:
How does MySQL handle pagination at scale?
MySQL’s
LIMIT OFFSETapproach can degrade performance on large tables due to full-table scans with increasing offsets.How does MySQL differ from PostgreSQL in handling
GROUP BYsemantics?MySQL is more lenient and allows selecting columns not in
GROUP BYwhenONLY_FULL_GROUP_BYis disabled.
Code Examples:
1 . Write a query to paginate results for product listings using MySQL.
This question tests your grasp of pagination and offset mechanics. It’s specifically about using LIMIT and OFFSET to fetch results page by page. You’d structure your query with LIMIT page_size OFFSET page_number * page_size. This is essential in frontend pagination and optimizing API responses for product catalogs or search results.
-- MySQL: Paginate product listings (inefficient for large offsets)
SELECT * FROM products
ORDER BY product_id
LIMIT 10 OFFSET 1000;
2 . Find products with prices higher than their average category price using MySQL.
This question tests subquery filtering and intra-group comparison. It’s specifically about comparing a row’s value to its group’s average. Use a subquery to calculate average price per category and join it back to filter rows. MySQL’s subquery optimization is key in real-world pricing strategies.
-- MySQL: Products with price > average of their category
SELECT p.product_id, p.price, cat_avg.avg_price
FROM products p
JOIN (
SELECT category_id, AVG(price) AS avg_price
FROM products
GROUP BY category_id
) cat_avg
ON p.category_id = cat_avg.category_id
WHERE p.price > cat_avg.avg_price;
SQL Server Examples
Concept:
What is the role of
WITH (NOLOCK)in SQL Server reads?It allows reading uncommitted data (dirty reads), improving performance but sacrificing accuracy.
Why does SQL Server use
TOP()instead ofLIMIT?TOP()limits rows in SELECT/UPDATE/DELETE and integrates withORDER BY, but requires a different syntax than standard SQL.
Code Examples:
1 . Write a query to prevent reading locked rows in SQL Server.
This question tests concurrency control awareness. It’s specifically about reading data without blocking writes using the WITH (NOLOCK) hint. Apply it in SELECT * FROM tablename WITH (NOLOCK). Useful for analytics dashboards where eventual consistency is acceptable.
-- SQL Server: Read without locking
SELECT * FROM Orders WITH (NOLOCK)
WHERE status = 'shipped';
2 . Update only the top 10 rows using SQL Server.
This tests conditional updates with row limiting. Since UPDATE TOP() doesn’t allow ordering, use a Common Table Expression (CTE) with ROW_NUMBER() to simulate ordered updates.
-- SQL Server: Update top 10 most expensive products in Electronics
WITH RankedProducts AS (
SELECT *, ROW_NUMBER() OVER (ORDER BY price DESC) AS rn
FROM Products
WHERE category = 'Electronics'
)
UPDATE RankedProducts
SET price = price * 1.1
WHERE rn <= 10;
Oracle & PL/SQL Examples
Concept:
What makes
ROWNUMtricky in Oracle for top-N queries?Oracle does not support
LIMIT, andROWNUMis assigned beforeORDER BY, so sorting must be pushed into a subquery.When should PL/SQL be used instead of SQL in Oracle?
Use PL/SQL for procedural logic such as error handling, loops, or complex transactions that SQL alone can’t handle.
Code Examples:
1 . Fetch top 3 salaries using Oracle SQL.
This tests your ability to work around the lack of LIMIT. It’s specifically about using ROW_NUMBER() in subqueries. You’d order salaries descending in a derived table, then filter using ROWNUM. Common in performance reviews and salary analysis.
-- Oracle: Get top 3 salaries with ROWNUM in subquery
SELECT * FROM (
SELECT employee_id, salary
FROM employees
ORDER BY salary DESC
) WHERE ROWNUM <= 3;
2 . Write a query using PL/SQL to handle division-by-zero errors.
This tests control flow and error handling. It’s specifically about using BEGIN ... EXCEPTION WHEN ZERO_DIVIDE THEN ... to prevent crashes. This is crucial in report generation or billing systems.
-- PL/SQL: Safe division with ZERO_DIVIDE error handling
DECLARE
result NUMBER;
amount NUMBER := 100;
divisor NUMBER := 0;
BEGIN
BEGIN
result := amount / divisor;
EXCEPTION
WHEN ZERO_DIVIDE THEN
result := NULL; -- fallback
END;
DBMS_OUTPUT.PUT_LINE('Result: ' || result);
END;
/
PostgreSQL Examples
Concept:
How do PostgreSQL’s
FILTER()andWINDOWfunctions improve readability?They allow scoped aggregation without subqueries, ideal for dashboards and analytical queries.
What’s a real-world use case for recursive CTEs in PostgreSQL?
Traversing hierarchies (e.g., org charts, category trees) or recursive financial rollups.
Code Examples:
1 . Write a query to filter rows using the FILTER clause in PostgreSQL.
This question tests selective aggregation. It’s specifically about applying a condition within an aggregate, e.g., COUNT(*) FILTER (WHERE status = 'active'). Helps in concise and efficient summarization, especially for dashboard metrics.
-- PostgreSQL: Use FILTER to count only active users
SELECT
COUNT(*) FILTER (WHERE status = 'active') AS active_users,
COUNT(*) AS total_users
FROM users;
2 . Traverse a product category hierarchy using a recursive CTE.
This question tests recursive query construction using WITH RECURSIVE. It’s specifically about retrieving nested categories, e.g., all subcategories under a root node which is a common requirement in e-commerce, organizational trees, or financial rollups. Use a base case for top-level categories (parent_id IS NULL), then recursively join to find children.
-- PostgreSQL: Recursive CTE to build category hierarchy
WITH RECURSIVE category_tree AS (
SELECT id, name, parent_id
FROM categories
WHERE parent_id IS NULL
UNION ALL
SELECT c.id, c.name, c.parent_id
FROM categories c
JOIN category_tree ct ON c.parent_id = ct.id
)
SELECT * FROM category_tree;
SQL Scenario Questions from Real-World Business Applications
In real-world analytics roles, SQL isn’t just about writing syntactically correct queries, it’s about solving domain-specific problems. These business case scenario questions simulate operational needs in industries like e-commerce, logistics, finance, and security, where understanding the business goal is as important as the technical implementation.
Expect to be evaluated not just on SQL syntax, but on how you translate stakeholder goals into queries, apply aggregations, and optimize logic for performance and clarity. Here’s a curated breakdown of SQL scenario questions across four practical domains:
E-commerce Order Classification (High/Low Value)
Find customers who made upsell purchases after their initial order.
This question tests conditional joins and purchase segmentation. It’s specifically about identifying customers who made upsell purchases post-initial transaction. You’d typically use
JOINwith a time filter on purchase timestamps. This supports e-commerce strategies like funnel analysis and upsell optimization.Write a query to identify when a user made their third purchase.
This question tests window functions and purchase event ordering. It’s about detecting when a customer made their third purchase. You can solve it using
ROW_NUMBER()over user IDs ordered by purchase date, then filter by row = 3. Common in loyalty program targeting.Write an SQL query to determine the most recent purchase date per user.
This question tests the use of aggregation with time-based logic. It’s about identifying the last purchase date per user, which can help segment users based on recency. You’d typically apply
MAX(purchase_date)grouped byuser_id. This supports churn analysis and re-engagement campaigns.Fill in missing dates in a user purchase timeline.
This question tests time-bucketing and data interpolation. It’s about filling missing dates in a purchase timeline using window functions and joins. Useful in time series visualization and retention curves.
Compute average order value per customer.
This question tests aggregation and basic filtering. It’s specifically about computing average transaction value per customer or session. Solve using
GROUP BYon user/session andAVG(amount). Used for spend segmentation in marketing.
Inventory Stock Management with CASE
Find products priced above their category average.
This question tests intra-group comparisons. It’s about selecting products whose prices exceed their category’s average. Use subqueries or window functions to compute category averages. Common in pricing audits.
Calculate the average quantity purchased per year for each product.
This question tests grouping with conditional aggregation. You’re asked to find average yearly purchases for each product. Use
GROUP BYon product and year derived from the order date. Important in forecasting and restocking.Compute monthly product sales counts.
This tests time-based aggregation. It’s about counting or summing sales per month using
DATE_TRUNC()orMONTH()functions. Common in inventory health monitoring and seasonality detection.Find users who repeatedly purchase from the same category.
This tests pattern recognition. It’s about identifying users who repeatedly purchase from the same category. Solve using
COUNT(DISTINCT month)after filtering by product category. Useful for retention and churn modeling.Write a query to label products as ‘Understocked’, ‘Balanced’, or ‘Overstocked’ based on current inventory vs reorder thresholds.
This question tests conditional classification using
CASE WHEN. You’re asked to classify products into stock health categories depending on whether theircurrent_inventoryis above or below definedreorder_level. UseCASEwith custom logic thresholds to map inventory status. Useful for automating alerts in stock dashboards.
Fraud Detection Queries
Detect users who created multiple accounts to upvote themselves.
This question tests anomaly detection via joins and aggregation. It’s about users creating multiple accounts to upvote themselves. Solve using self-joins on
user_id,ip_address, orpost_idand check abnormal patterns. Crucial in trust & safety systems and moderation.Detect users making multiple transactions within 1 minute.
This question tests time-based anomaly detection. It’s specifically about identifying unusually fast repeat transactions. Use
LAG()orLEAD()over user transactions ordered by timestamp, then filter where the time difference is under 60 seconds. This is useful in spotting bot activity or flash fraud.Flag users accessing accounts from multiple IPs in a short time window.
This question tests your understanding of joins and distinct IP tracking. It’s about detecting if a user accessed their account from different IPs within a short interval. Use
COUNT(DISTINCT ip_address)with a time filter. Useful in identifying credential stuffing or account sharing.Find transactions with mismatched billing and shipping addresses.
This question checks conditional joins or CASE usage. It’s about identifying orders where the billing and shipping addresses differ. You can flag them using a
CASE WHEN billing_address != shipping_address THEN 'suspicious'. Common in fraud scoring systems.Find multiple accounts linked to the same payment method.
This question tests grouping and filtering on shared identifiers. It’s about detecting multiple users using the same card or payment method. Group by
payment_method_idand filter forCOUNT(DISTINCT user_id) > 1. Often used to detect fake account farms or policy violations.
Finance Reporting with Conditional Aggregation
Calculate each year’s percentage contribution to total revenue.
This tests percent-of-total calculation. It’s about calculating yearly revenue and its share of the total. Use
SUM() OVER()in a subquery or CTE. Found in executive dashboards.Compute average revenue per customer.
This question tests aggregation per user. It’s about dividing total revenue by the number of distinct customers. Use
SUM(amount)/COUNT(DISTINCT user_id). Supports lifetime value calculations.Find advertisers with revenue above a defined threshold.
This question evaluates filtering with thresholds. It’s about selecting advertisers with revenue above a set level. Use
HAVING SUM(revenue) > threshold. This mirrors performance-based partner reports.Write a query to compute daily or monthly listing bookings.
This question tests date aggregation. It’s about computing daily or monthly booking totals. Use
GROUP BY listing_id, DATE(created_at). Used in travel, hospitality, and marketplace analytics.Write an SQL query to calculate the average monthly spend per user.
This question tests grouped time-based aggregation. It’s about determining how much a user spends on average each month. Use
DATE_TRUNC()(PostgreSQL) to extract the month, thenGROUP BY user_idand the truncated date to compute monthly totals, followed by averaging per user. This pattern is valuable for monitoring spend behavior or triggering retention campaigns.
Common SQL CASE WHEN Pitfalls and How to Fix Them

When working with CASE WHEN logic in SQL, especially in scenario-based questions, it’s easy to fall into traps that either produce incorrect results or lead to performance issues. Below are some of the most common mistakes, along with tips to avoid them.
1. Overusing Nested CASE Statements
Mistake: Writing overly complex nested CASE blocks when a simpler approach using JOIN, COALESCE(), or IF() might work better.
Example:
SELECT
user_id,
CASE
WHEN status = 'active' THEN 'Engaged'
ELSE
CASE
WHEN status = 'inactive' THEN 'Dormant'
ELSE 'Unknown'
END
END AS user_segment
FROM users;
Why It’s a Problem: Deeply nested CASE statements reduce readability and are harder to debug. This can often be rewritten more clearly using IF() (MySQL), IIF() (SQL Server), or a lookup table with JOIN.
Optimization Tip: Flatten your logic or extract mapping into a CTE or subquery when possible.
Fixed Version: This version eliminates unnecessary nesting and improves readability while producing the same logic. If there are more than a few categories or more complex mappings, consider using a lookup table and JOIN instead.
SELECT
user_id,
CASE
WHEN status = 'active' THEN 'Engaged'
WHEN status = 'inactive' THEN 'Dormant'
ELSE 'Unknown'
END AS user_segment
FROM users;
2. Forgetting the ELSE Clause
Mistake: Omitting the ELSE block in a CASE expression, which causes unmatched cases to return NULL.
Example:
SELECT
order_id,
CASE
WHEN amount > 100 THEN 'High Value'
WHEN amount BETWEEN 50 AND 100 THEN 'Medium Value'
END AS value_category
FROM orders;
Why It’s a Problem: Any order under $50 will return NULL, which might break downstream logic or mislead reporting tools.
Optimization Tip: Always include an ELSE clause as a fallback, even if it’s just ELSE 'Other' or ELSE 'Unknown'.
Fixed Version:
SELECT
order_id,
CASE
WHEN amount > 100 THEN 'High Value'
WHEN amount BETWEEN 50 AND 100 THEN 'Medium Value'
ELSE 'Low Value'
END AS value_category
FROM orders;
3. Misusing CASE in the WHERE Clause
Mistake: Trying to use CASE in WHERE clauses to apply different filtering logic per row which leads to unreadable code and potential logic bugs.
Example:
SELECT *
FROM products
WHERE
CASE
WHEN category = 'Electronics' THEN price < 500
WHEN category = 'Books' THEN price < 50
END;
Why It’s a Problem: This doesn’t work as intended. CASE returns a value, not a boolean expression, so the engine doesn’t evaluate conditions correctly.
Optimization Tip: Use OR/AND with explicit conditions, or use CASE inside a CTE or derived table.
Fixed Version:
SELECT *
FROM products
WHERE
(category = 'Electronics' AND price < 500)
OR
(category = 'Books' AND price < 50);
FAQs on SQL Scenario Based Interview Questions
How do I practice SQL scenario based questions?
Use platforms like Interview Query or LeetCode. Focus on real-world data problems such as users, orders, sessions, and practice on tools like BigQuery, PostgreSQL, or Kaggle notebooks.
What are advanced SQL scenario questions for experienced professionals?
They involve CTEs, window functions, recursive queries, and optimization. Think: rolling metrics, deduplication with ROW_NUMBER(), or handling millions of rows efficiently.
Can I use multiple CASE WHEN in SQL queries?
Yes, multiple CASE WHEN clauses are allowed. Keep them readable and always use an ELSE clause for defaults.
Where can I download SQL scenario interview questions in PDF?
Check Interview Query, GeeksforGeeks, or GitHub. You can also export custom sets from practice platforms or convert Markdown notes to PDF.
What are tricky SQL interview questions?
They test logic and edge cases, like finding second-highest values, users with single actions, or purchases in every month of a year.
Recap & Best Practices for SQL Interviews
Before you walk into your next data interview, let’s summarize the most valuable takeaways from this guide and how to apply them under real-time constraints.
Summary of Patterns and Techniques
| Skill Area | What to Focus On |
|---|---|
| Joins & Aggregations | Practice clean JOIN operations followed by GROUP BY, COUNT(), SUM(), etc. |
| CASE WHEN Logic | Write readable logic blocks, always include an ELSE clause for edge cases. |
| Window Functions | Use ROW_NUMBER(), RANK(), LAG() for ordering, rankings, and change detection. |
| Subqueries & CTEs | Break down problems into modular steps using CTEs (WITH) for clarity and reuse. |
| Performance Awareness | Optimize for large datasets — filter early, avoid CROSS JOIN, and use indexing. |
| Platform Specifics | Learn quirks of MySQL, SQL Server, Oracle, and PostgreSQL syntax and optimizations. |
Advice for Answering Scenario Questions Under Time Pressure
- Simulate Interviews: Time yourself solving 3–5 SQL problems with a 20–30 minute timer.
- Don’t Over-Engineer: Focus on correctness first, then optimize if time permits.
- Write Comments as You Go: Explain your logic inline, it helps you stay structured and reduces backtracking.
- Use Patterns: Recognize common patterns like deduplication, running totals, or date grouping.
Helpful Interview Query Resources
Want to master SQL interview questions? Start with our SQL Question Bank to drill real-world scenario questions used in top interviews.
Master CASE WHEN logic or GROUP BY filters with our step-by-step SQL Learning Path to go from basic joins to advanced optimization.
Then simulate the real pressure using Mock Interviews.