

Deloitte Data Scientist Interview Guide (2025) – Questions, Process & Tips

Introduction
Deloitte data scientist interview questions are designed to assess not just technical skill, but also how candidates apply analytics to solve real-world problems across industries. As Deloitte rapidly expands its AI and data science initiatives, the firm is building NLP systems, ML models, and GenAI tools that power decision-making in healthcare, government, and tech. With 90% of Fortune Global 500 companies as clients, Deloitte’s analytics teams are already shaping how industries operate. Their 2025 vision emphasizes democratizing AI and using it responsibly, addressing energy efficiency, bias, and trust. Recent reports highlight that enterprise GenAI adoption is accelerating, with Deloitte leading key transformations. As their AI work scales, so does their need for sharp, adaptable data scientists ready to deliver real business impact.
Role Overview & Culture
A Deloitte data scientist works at the intersection of technology, analytics, and business transformation. You will use machine learning and natural language processing to drive decision-making across sectors like healthcare, finance, and public services. From deploying NLP tools in Azure to creating predictive models on Spark clusters, the work spans industries and technologies. In 2023 alone, Deloitte’s AI and analytics division supported over 2,500 client engagements globally, with use cases ranging from optimizing healthcare delivery to modernizing fraud detection in banking.
The pace is fast. You might juggle a Spark-based predictive pipeline on Monday and design a Power BI dashboard for executives by Thursday. With tools like TensorFlow, Kafka, and Kubernetes in your stack, you’ll solve real problems alongside engineers and strategists. Deloitte’s culture values mentorship, collaboration, and continuous growth, ensuring you’re not just coding—you’re influencing the future of entire industries.
Why This Role at Deloitte?
Thinking about joining Deloitte as a Data Scientist? It’s more than just a strong career move—it’s a chance to help shape the future of AI. Deloitte recently announced a $1.4 billion investment in generative AI and is actively hiring for data science roles to power that transformation. You won’t just write models. You’ll solve real-world problems for Fortune 500 clients, contribute to cutting-edge research, and experiment with technologies that affect millions. Salaries are highly competitive, reaching up to $250K for senior positions, and generous benefits, including nearly a month of PTO in some regions, make the package hard to beat. You’ll collaborate with some of the brightest minds in analytics, have access to ongoing training and certifications, and grow in a place that values both your curiosity and your career trajectory.
What Is the Interview Process Like for a Data Scientist Role at Deloitte?
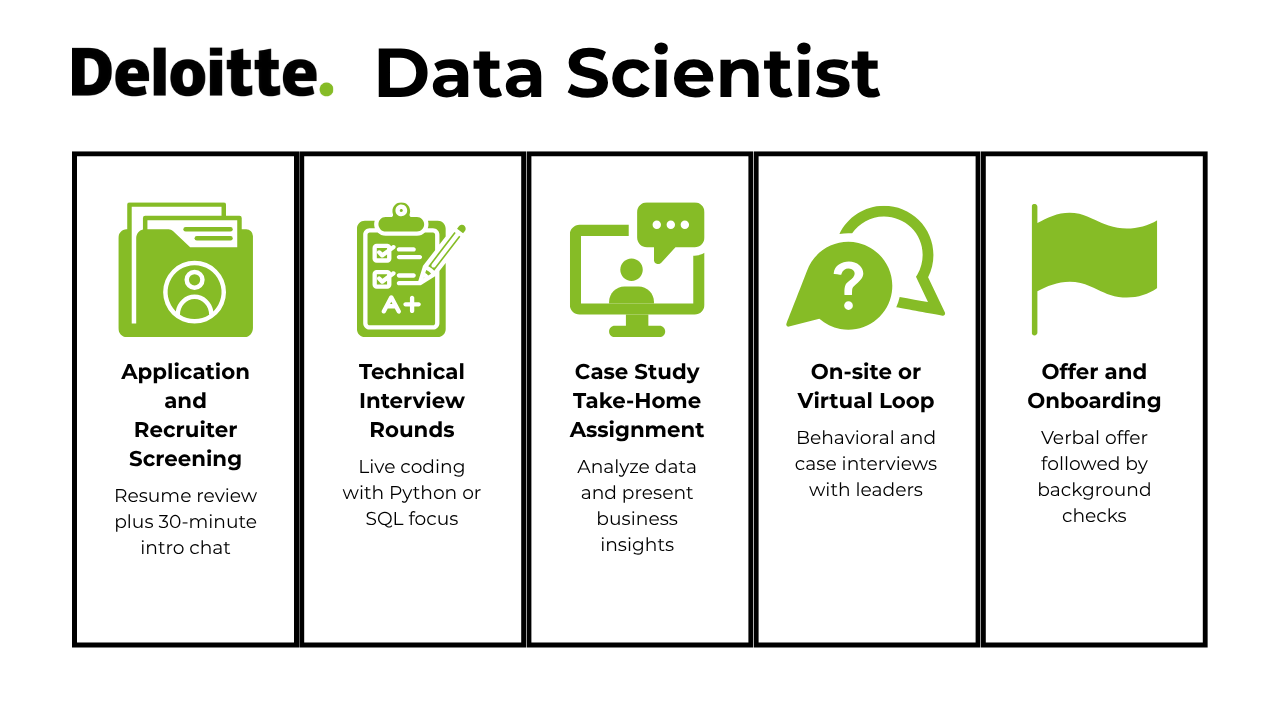
The Deloitte data scientist interview process is structured, fast-paced, and designed to evaluate both technical expertise and consulting potential. From your first recruiter screen to the final decision loop, each stage builds on your ability to code, analyze, and communicate like a true business partner. Below is a breakdown of the full journey:
- Application and Recruiter Screening
- Technical Interview Rounds
- Case Study Take-Home Assignment
- On-site or virtual Loop
- Offer and Onboarding
Application and Recruiter Screening
Your Deloitte data science interview journey typically begins with an online application and resume review. Recruiters are scanning for proficiency in Python, SQL, and machine learning, along with experience in analytics or data visualization. If your background aligns, you’ll proceed to a 20 to 30-minute recruiter screen. This conversation focuses on your past projects, your reasons for applying, and how your goals align with Deloitte’s mission to make an impact that matters. Treat this stage as your first opportunity to demonstrate both technical credibility and enthusiasm for consulting work.
Technical Interview Rounds
Once you pass the initial screen, you’ll enter the technical rounds. These usually consist of one or two interviews conducted by Deloitte’s data scientists or engineering leads. You’ll be expected to write Python or SQL code live, analyze structured and unstructured data, and walk through your logic clearly. Questions often explore machine learning algorithms, model selection and evaluation, feature engineering, and handling real-world challenges like class imbalance or missing data. Tableau, Power BI, and other visualization tools may also come up. Communication is key—interviewers are not only testing accuracy, but also how well you explain your decision-making.
Case Study Take-Home Assignment
For roles with a strong business-facing component, Deloitte often includes a take-home data challenge. You might be asked to segment customers, forecast trends, or evaluate A/B test results, usually based on a real or semi-realistic dataset. This task evaluates your end-to-end thinking: from data exploration and cleaning to modeling and storytelling. Your submission should include clear code, visualizations, and business recommendations. While technical rigor is crucial, this stage is also about showing how your insights translate into action. Expect this round to last about 3 to 5 days, depending on the assignment’s scope.
On-site or virtual Loop
If you advance past the technical and case rounds, you’ll reach the final loop—an intensive series of interviews conducted either virtually or at a Deloitte office. These sessions typically involve partners, senior managers, and project leads. You’ll face behavioral questions that explore your leadership, adaptability, and communication style. You’ll also work through business scenarios where you’ll need to demonstrate both your technical thinking and your consulting intuition. They may ask how you’d scope a client engagement, lead a data team, or deliver insights under uncertainty. This is where your potential to lead projects and engage clients will be closely examined.
Offer and Onboarding
If all goes well, Deloitte will extend a verbal offer, followed by a formal written one. Before your start date, you’ll go through standard pre-employment checks such as background verification and possibly a psychometric evaluation. The onboarding process includes training on Deloitte’s internal tools, methodology, and project workflows.
What Questions Are Asked in a Deloitte Data Scientist Interview?
In this section, we’ll break down the most common types of Deloitte data science interview questions, including technical challenges, business case studies, and behavioral prompts that reflect the firm’s consulting environment.
Technical / Machine-Learning Questions
Deloitte data science interview questions in this category assess your coding ability, machine learning knowledge, and how you explain technical decisions, often in the context of real business problems or scalable systems:
To solve this, use a binary search to efficiently find the closest element to the given integer. Then, handle edge cases where the k-next or k-previous elements go out of bounds, and return the appropriate sublist of elements.
To solve this, calculate the daily increment in revenue by dividing the difference between the total revenue target and Day 1 revenue by the number of days minus one. Then, generate a list of daily revenues starting from Day 1, adding the daily increment to the previous day’s revenue until Day N is reached.
3. Build a random forest model from scratch with specific conditions
To build a random forest model from scratch, you need to create decision trees that evaluate every permutation of the feature columns in the data frame. The model should take a dataframe and a new data point, both consisting of binary values, and return the majority class vote for the new data point. The solution involves using permutations from the itertools package to iterate through feature combinations and pandas to handle data operations, excluding the use of scikit-learn.
To solve this, calculate the median of the ‘Price’ column in the dataframe and use it to fill in the missing values. This can be achieved using the median() method to find the median and fillna() to replace the missing values with the median.
Dynamic pricing allows businesses to maximize profits by adjusting prices based on real-time market demand and supply conditions. To estimate supply and demand, businesses can use demand forecasting through statistical and machine learning models, monitor supply availability, and model price elasticity to understand how price changes affect demand. These techniques help businesses set optimal prices that reflect current market conditions.
6. How would you interpret coefficients of logistic regression for categorical and boolean variables?
In logistic regression, the sign of the coefficient indicates whether the variable has a positive or negative influence on the outcome. The magnitude of the coefficient reflects the strength of this effect, but care must be taken when comparing variables of different types (e.g., boolean vs. continuous). Categorical variables should be one-hot encoded to avoid misleading interpretations due to assumed rankings.
Case Study & Business Insight Questions
These Deloitte data science consulting questions test your business sense and analytical depth by asking you to frame, analyze, and solve case-style problems using data, especially in A/B testing, pricing, and product optimization:
Potential problems include the model’s inability to generalize due to biased or unrepresentative data, leading to inaccurate sentiment predictions. Additionally, the dynamic nature of language and slang used in WallStreetBets can pose challenges in maintaining model accuracy over time.
To set up and analyze an A/B test for conversion rates, first, define the key metrics and success criteria. Randomly assign users to control and variant groups, ensuring equal distribution. Use statistical methods like bootstrap sampling to calculate confidence intervals, ensuring the results are statistically valid.
9. How would you approach designing a test for a price increase in a B2B SAAS company?
When testing a price increase, consider the potential downsides of A/B testing, such as user opt-out and statistical anomalies. Instead, a before-and-after test may be more effective, comparing similar time periods to assess customer behavior and lifetime value. The challenge lies in managing the overhead of testing, requiring coordination across teams. Reducing this overhead can lead to more efficient pricing tests and better revenue outcomes.
10. How would you assess the validity of the result in an A/B test with a .04 p-value?
To assess the validity of an A/B test result with a .04 p-value, first ensure that the user groups were properly separated and that the variants were equal in all other aspects. Check the sample size, duration, and measurement method of the test to ensure they align with industry standards. Continuous monitoring of the p-value can lead to false positives, so it’s crucial to determine the minimum effect size and appropriate experiment duration beforehand.
To measure the success of Facebook stories without using a standard A/B test, consider alternative testing strategies such as cohort analysis or time-series analysis. Key metrics to track include engagement levels (total story views, unique viewers, replies, and reactions), content creation frequency and diversity, and retention rates. These metrics provide insights into user interaction, content generation, and the feature’s long-term appeal, helping to assess its success on the platform.
12. How would you evaluate whether a 50% rider discount promotion is a good or bad idea?
To evaluate the effectiveness of a 50% rider discount, you should first state assumptions, such as the goal being to increase retention and revenue. Implement an A/B test with a control and test group to measure long-term revenue against the average cost of the promotion. Consider user lifetime revenue models to extrapolate beyond the test period and analyze the frequency of promotions for product stickiness. Further considerations include user segmentation, market conditions, and supply-side constraints.
Behavioral / Culture-Fit Questions
Behavioral questions at Deloitte are designed to evaluate your alignment with the firm’s values, including adaptability, collaboration, and client-facing communication skills essential for data science roles in consulting:
13. How would you answer when an Interviewer asks why you applied to their company?
When interviewing at Deloitte, emphasize how your values align with their mission to drive client impact through innovative analytics. Mention specific initiatives such as their investment in AI or sustainability consulting that resonate with your goals. Be sure to tie in how Deloitte’s collaborative and fast-paced environment matches your strengths as a data scientist.
14. Tell me about a project in which you had to clean and organize a large dataset.
Deloitte projects often involve working with complex and messy datasets across industries like healthcare, finance, or public sector. When answering this question, describe your process for handling inconsistencies or missing data, especially under tight client deadlines. Highlight the tools you used, such as SQL or Python, and how your work improved data integrity or enabled key business decisions.
15. Describe a data project you worked on. What were some of the challenges you faced?
Frame your response around a client-oriented or cross-functional project, which is common at Deloitte. Explain how you translated ambiguous business questions into structured analyses and overcame roadblocks like incomplete requirements or technical constraints. Show how you collaborated with stakeholders and delivered insights that influenced strategy or operations.
At Deloitte, you’ll regularly present to both technical teams and executive clients. Describe a time when your message didn’t initially land—perhaps due to jargon or data complexity—and how you refined your approach. Emphasize your adaptability and how you adjusted to the audience’s needs, such as using visual dashboards or storytelling techniques.
17. How do you handle shifting priorities when working on multiple projects?
Deloitte consultants often juggle several engagements across industries. In your answer, explain how you prioritize tasks using frameworks like the Eisenhower Matrix or agile stand-ups. Discuss how you proactively manage expectations and communicate trade-offs with both internal teams and clients.
18. Describe a time you had to learn a new tool or technology quickly.
Innovation is key to Deloitte’s analytics practice. Share a situation where you ramped up quickly on a new tool—such as Databricks, Tableau, or a cloud platform—to meet project demands. Highlight your learning strategy and how you applied the tool to generate immediate business value.
How to Prepare for a Data Scientist Role at Deloitte
Preparing for the Deloitte data scientist interview means focusing on both technical excellence and business fluency right from the start. Within the first few days of preparation, you should map out the entire interview structure so you understand how recruiters evaluate fit and capability.
Begin by refining your core coding skills. Practice SQL queries that use window functions and joins, and brush up on Python for data manipulation and modeling tasks. Dedicate time to studying ML ops topics such as deployment pipelines and model monitoring, since Deloitte values production-ready thinking. When reviewing machine learning concepts, go beyond accuracy metrics. Understand AUC, F1-score, and confusion matrices, especially in imbalanced datasets.
Prepare behavioral answers using the STAR method and our AI Interviewer, focusing on ownership and adaptability. Conduct mock interviews focused on case studies, and simulate how you would explain a model to a non-technical stakeholder—this reflects the real consulting scenarios in data science Deloitte roles.
Also, research Deloitte’s data science work by exploring industry-specific projects they’ve led in healthcare, finance, or sustainability. Finally, analyze feedback from platforms like LinkedIn or Reddit. Candidates often note that aligning your communication style and values with Deloitte’s culture is just as important as getting the code right.
FAQs
What Is the Average Salary for a Data Scientist at Deloitte?
Average Base Salary
Average Total Compensation
Where Can I Read More Deloitte Data Scientist Threads on IQ?
Explore real candidate experiences, interview breakdowns, and strategy tips from the Interview Query community.
Are There Open Deloitte Data Scientist Roles on Interview Query?
Yes, Interview Query regularly features job openings for data scientist roles at Deloitte. Check frequently to apply early and gain access to role-specific interview prep resources.
Conclusion
Acing the Deloitte data scientist interview requires more than technical readiness—it’s about positioning yourself as a strategic thinker and adaptable communicator. Take inspiration from Jayandra Lade’s success story. And, start with the Learning Roadmap for data scientists. This includes SQL sets, mock machine learning challenges, and consulting-style case practice. It’s tailored for analytics roles at firms like Deloitte.
And when you’re ready to go deeper, explore our curated list of Deloitte data scientist interview questions from real candidates. With the right mix of technical prep, consulting mindset, and cultural alignment, you can land not just the job but a long-term data career at Deloitte.