
Deloitte Data Engineer Interview Guide: Process, Questions, Salary, and Prep


Introduction
A Deloitte data engineer operates at the backbone of large-scale analytics, AI, and digital transformation programs, building the pipelines and platforms that allow data to move reliably from raw source systems to decision-ready products. Deloitte serves clients operating at enterprise scale, where data volume, velocity, and governance constraints are non-trivial. As organizations modernize legacy systems, migrate to cloud platforms, and operationalize machine learning, demand has surged for engineers who can design resilient data architectures while translating business needs into production-grade systems.
This context shapes the Deloitte data engineer interview. The role goes beyond writing ETL scripts or optimizing queries in isolation. Interviewers evaluate how candidates reason about system design, data quality, scalability, and stakeholder trade-offs in real client environments. In this guide, we break down how the Deloitte data engineer interview process works, what each stage is designed to assess, and how candidates should prepare for the mix of coding depth, architectural thinking, and consulting-style communication Deloitte expects.
Deloitte Data Engineer Interview Process
The Deloitte data engineer interview process is designed to assess technical depth, system-level thinking, and readiness for client-facing delivery work. Rather than focusing only on syntax or tools, Deloitte evaluates how candidates design data systems under real-world constraints, explain trade-offs, and collaborate across functions. The exact structure varies by geography and service line, but most candidates progress through several stages over a few weeks.
Many candidates prepare by practicing applied problems from Interview Query’s data engineer interview questions and pressure-testing explanations through mock interviews that reflect consulting-style follow-ups.
Interview Process Overview
Candidates typically move from an initial recruiter screen into technical assessments, followed by multiple interview rounds covering coding, platform knowledge, system design, and behavioral judgment. Compared with product-focused tech companies, Deloitte places heavier emphasis on end-to-end data flows, governance, and the ability to explain engineering decisions to non-technical stakeholders.
Some candidates rehearse this progression using real-world challenges that require them to design pipelines, reason about scale, and defend architectural choices under questioning.
| Interview stage | What happens |
|---|---|
| Application and recruiter screen | Background, motivation, and role alignment |
| Online assessment | Aptitude, logic, and foundational technical skills |
| Technical interview (coding) | SQL, Python, and core data engineering concepts |
| Technical interview (systems/platforms) | Cloud, Spark, ETL design, and data modeling |
| Behavioral or managerial round | Collaboration, delivery pressure, and judgment |
| Partner or director round | Communication maturity and long-term fit |
Recruiter Screen
The recruiter screen is typically a short phone or video conversation focused on confirming fit for the Deloitte data engineer role, availability, and interest in consulting-style work. Interviewers assess whether you understand the difference between building internal data products and delivering client-facing solutions across varied industries.
Many candidates refine this narrative through mock interviews to avoid generic explanations.
Tip: Be ready to explain why you enjoy building production data systems, not just writing code or running analyses.
Online Assessment
Some candidates complete an online assessment before technical interviews. These may include logical reasoning, basic SQL or Python questions, and scenario-based prompts. The goal is to evaluate structured thinking, attention to detail, and comfort with foundational concepts under time pressure.
Practicing timed questions from the data engineer interview questions set helps candidates stay disciplined.
Tip: Focus on correctness and clarity before optimization, especially when explaining assumptions.
Technical Interview: Coding and Core Concepts
Early technical rounds focus on SQL, Python, and data engineering fundamentals. Interviewers may ask you to write complex queries using joins, CTEs, and window functions, or to reason through Python-based data transformations. Questions often test how you handle edge cases, data quality issues, and performance considerations.
Working through SQL-heavy problems on the Interview Query platform helps candidates practice explaining logic step by step rather than jumping straight to solutions.
Tip: Talk through your approach before writing code, and explain how you would validate results.
Technical Interview: Platforms and System Design
Later technical rounds dive into system design and platform expertise. Candidates may be asked to design batch or streaming pipelines, explain trade-offs between data lakes and warehouses, or discuss how they would implement data quality and governance checks at scale. Cloud-native tools such as Azure Data Factory, Databricks, Spark, and Snowflake often feature in these discussions.
Practicing system-level scenarios through case-style challenges helps candidates articulate architecture decisions clearly.
Tip: Anchor designs to business requirements first, then layer in scalability, reliability, and governance.
Behavioral or Managerial Round
This round focuses on how you operate in team-based, high-ambiguity environments. Interviewers explore how you have handled delivery pressure, collaborated with analysts or data scientists, and communicated trade-offs to stakeholders. Answers should be structured and outcome-oriented.
Candidates often rehearse these stories through mock interviews to refine clarity and pacing.
Tip: Center each story on a concrete decision you made and the impact it had on the project.
Partner or Director Round
The final round typically involves a discussion with a Partner or Director. This conversation assesses communication maturity, judgment, and long-term fit within Deloitte’s consulting model. Interviewers may revisit earlier technical topics at a higher level or ask how you think about risk, scalability, and client trust.
Tip: Demonstrate that you can connect technical decisions to client outcomes and business value.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Deloitte?
Deloitte Data Engineer Interview Questions
Deloitte data engineer interview questions are designed to test more than whether you can write working SQL or spin up a Spark job. Interviewers want to see how you think about end-to-end data delivery: correctness, reliability, cost, governance, and the ability to explain trade-offs to stakeholders who may not care which tool you used.
If you want reps that feel close to the real thing, practice on Interview Query’s data engineer interview questions and use the Interview Query challenges to rehearse system design scenarios where you have to defend decisions under follow-up pressure.
SQL And Data Modeling Questions
SQL questions in Deloitte data engineer interviews focus on correctness, edge cases, and business logic rather than trick syntax. Interviewers expect clean reasoning, clear validation steps, and an understanding of how queries behave on large datasets.
How would you calculate weekly user retention using event data?
This question tests cohort definition, time-based aggregation, and your ability to reason about user behavior across periods. Deloitte interviewers care less about syntax and more about whether your logic avoids double counting and ambiguous definitions.
Tip: Start by clearly defining the cohort event and explain how you would validate retention numbers against raw activity counts.
How would you compute rolling metrics, such as a 7-day moving average, on large event tables?
This evaluates your understanding of windowing logic and performance implications on high-volume datasets. Interviewers often follow up by asking how your approach scales and how you would validate correctness.
Tip: Talk through partitioning, ordering, and how you would sanity-check results on a small sample before trusting production outputs.
How would you identify duplicate records in a dataset and keep only the most recent entry per key?
This tests data quality reasoning, deduplication strategy, and how you enforce deterministic outcomes in analytical tables.
Tip: Explain how you define “latest,” how ties are handled, and how you prevent duplicates from reappearing in downstream loads.
How would you calculate daily active users (DAU) and weekly active users (WAU) from an events table?
This question assesses aggregation logic, date handling, and clarity in metric definitions. Deloitte interviewers want to see whether you align metrics with business interpretation.
Tip: Clearly explain how you handle timezone consistency and partial days to avoid misleading trends.
-
This blends SQL reasoning with diagnostic thinking, mirroring real Deloitte client scenarios where data engineers must investigate anomalies.
Tip: Describe the checks you would run on data freshness, completeness, and upstream changes before concluding it is a business issue.
System Design
How would you add a column to a billion-row table without affecting user experience?
This tests whether you understand “online schema changes” and the operational reality of making changes in production without breaking downstream consumers. Strong answers talk through database-specific behavior, phased rollouts, and verification plans (not just “ALTER TABLE”).
Tip: Propose a low-risk rollout (add nullable column → dual-write → backfill in batches → validate → enforce constraints later) and call out how you’d monitor regressions.
Describe how you would design a secure, scalable data pipeline using AWS, Azure, or GCP.
This evaluates whether you can map a real pipeline (ingest → transform → store → serve) and bake in security and governance without treating them as afterthoughts.
Tip: Anchor your design on IAM/role-based access, encryption in transit and at rest, and audit logs first—then discuss scaling and observability.
Explain the differences between AWS S3, Azure Blob Storage, and Google Cloud Storage for data lake use cases.
This tests platform fluency and whether you can connect storage choices to downstream processing, lifecycle policies, access controls, and cost.
Tip: Don’t over-index on feature trivia—frame selection around access patterns (batch vs streaming), ecosystem fit (Databricks, Snowflake, native services), and compliance requirements.
Helpful references: AWS S3 docs, Azure Blob docs, and Google Cloud Storage docs. ER/Studio
How do you manage access control and data governance in a multi-cloud environment?
Deloitte-style client work often means multiple tenants, multiple teams, and conflicting security expectations. This question checks whether you can keep governance consistent while still enabling delivery speed.
Tip: Describe a “single identity plane” pattern (federation/SSO), a centralized catalog/lineage approach, and enforceable tagging + policy-as-code rather than manual approvals.
-
This assesses streaming fundamentals (ordering, idempotency, late-arriving data), latency targets, and how you’d keep multiple consumers consistent. Deloitte also cares about how you clarify requirements before drawing architecture boxes.
Tip: Ask for the target latency SLA, expected throughput, and “source of truth” first—then choose the simplest architecture that meets it.
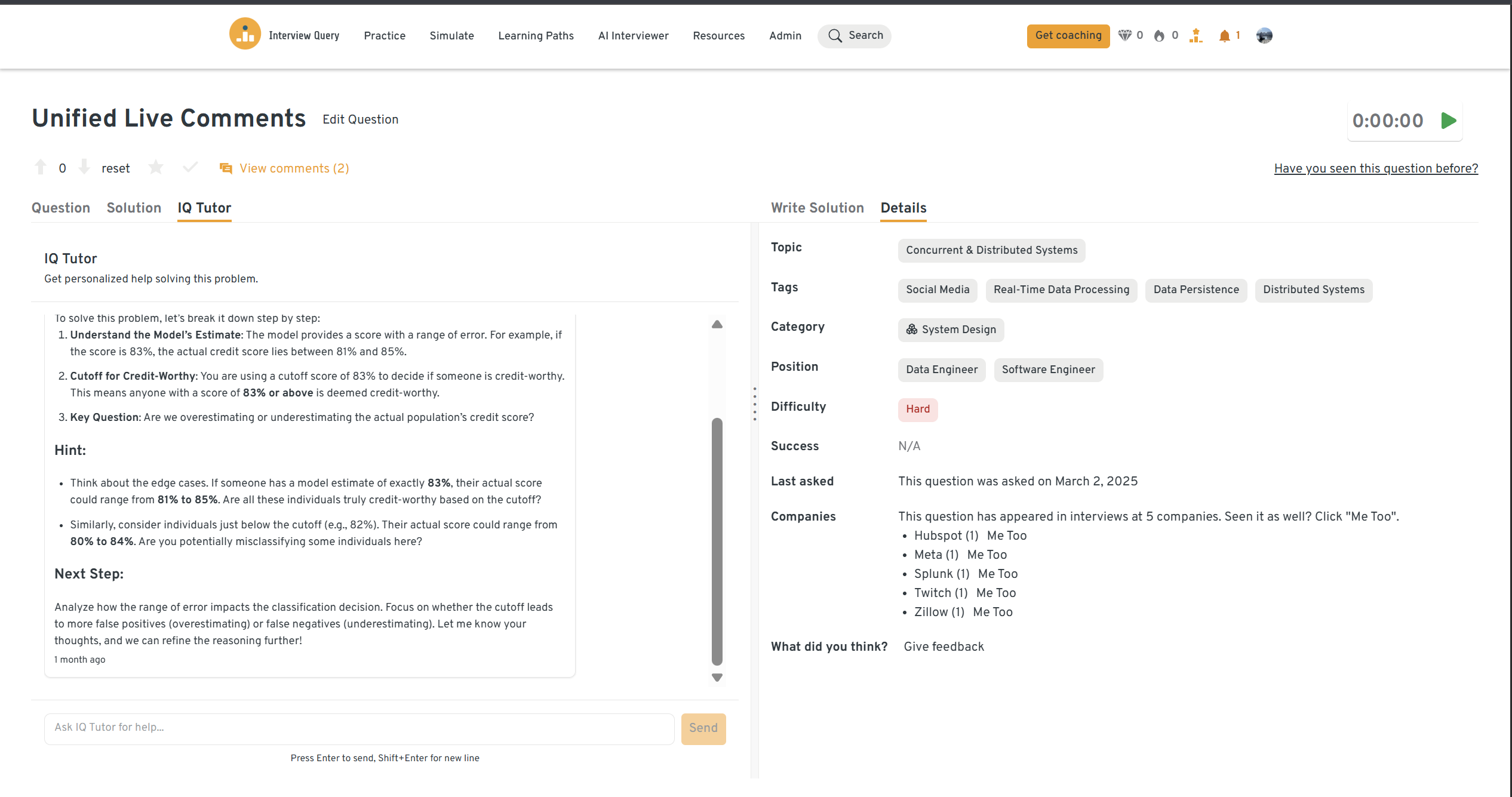
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
Pipelines, Lakehouse, And Spark
Design a data pipeline for hourly user analytics
This evaluates orchestration, incremental processing, data modeling for analytics, and how you prevent silent data drift when jobs run every hour.
Tip: Include an explicit strategy for backfills and late data (watermarks, partition overwrite strategy, or reconciliation jobs).
How would you build an ETL pipeline to get Stripe payment data into the database?
This tests API ingestion patterns, schema design, and correctness under retries (idempotency), which is a common failure point in real pipelines.
Tip: Call out idempotency keys, dedupe logic, and how you’d handle replays when Stripe resends events or your job restarts.
-
This measures your ability to design for unstructured data, quality evaluation (OCR accuracy), and building something “queryable” (search + metadata + indexing).
Tip: Separate it into two systems: (1) ingestion + processing (OCR/extraction) and (2) retrieval (indexing/search API), then define measurable quality checks for each.
Define Bronze, Silver, Gold layers in a modern data lakehouse.
This tests your conceptual clarity and whether you can explain data layering as an operational strategy (reprocessing, quality gates, and trust levels), not just definitions.
Tip: Tie each layer to a “contract”: Bronze preserves raw truth, Silver enforces cleaning/standardization rules, and Gold optimizes for business consumption and SLAs. A quick explainer video on the medallion approach is here. YouTube
Explain how to build scalable ETL pipelines with PySpark.
This evaluates whether you actually understand distributed processing: partitioning, shuffles, skew, caching, joins, and how to debug performance.
Tip: Mention how you diagnose a slow job (Spark UI, shuffle stages, skewed keys) and what you change first (partition strategy, broadcast join, predicate pushdown, file formats).
Behavioral And Client-Facing Collaboration
Deloitte behavioral questions are rarely “soft.” They’re usually about how you drive outcomes in ambiguity, handle stakeholder pressure, and communicate trade-offs without losing trust. If you want to drill these under realistic follow-ups, use mock interviews.
-
This tests initiative with judgment: did you improve outcomes without creating scope chaos or breaking stakeholder alignment?
Tip: Quantify the improvement, and explain how you aligned the “extra” work with the client’s real success metrics.
Sample answer: In a pipeline modernization project, we initially scoped a basic batch ETL rebuild, but I noticed our validation checks were too shallow and would not catch upstream schema drift. I proposed adding a lightweight data quality layer with contract checks and alerting, then I aligned it with the engagement lead by framing it as reducing rework risk. I implemented the checks, added clear dashboards for failures, and documented runbooks so the client could operate it after handoff. The result was fewer broken downstream reports, faster incident resolution, and a smoother transition to the client’s ops team.
-
This evaluates whether you can translate technical constraints into decision language and keep delivery moving when stakeholders disagree or lack context.
Tip: Show how you changed the artifact (diagram, KPI definition, sample output) instead of repeating the same explanation louder.
Sample answer: I worked with a business stakeholder who kept asking for “real-time dashboards” but couldn’t define acceptable latency or what actions the dashboard enabled. I scheduled a short alignment session, brought two options with concrete trade-offs (near-real-time streaming vs frequent micro-batches), and used an example dashboard to clarify expectations. Once we agreed on a latency target and the decisions it supported, I translated it into technical requirements and a delivery plan the team could execute. That reset reduced churn, improved trust, and stopped scope changes mid-sprint.
How do you prioritize multiple deadlines?
This tests whether you triage based on business impact and risk, not just who asked first or who is loudest.
Tip: Describe a repeatable system (impact × urgency × dependency risk), then explain how you communicate trade-offs proactively.
Sample answer: When I have competing deadlines, I start by mapping which deliverables unblock others and which carry the highest business risk if delayed. I confirm requirements and acceptance criteria early, then I sequence work to reduce rework, for example, locking schemas and quality gates before scaling transformations. If priorities conflict, I bring a short trade-off summary to the lead and propose a sequencing decision rather than asking them to “pick.” This approach keeps stakeholders informed and prevents last-minute surprises.
Describe a time you handled unrealistic client demands.
This evaluates consulting maturity: can you protect delivery quality while preserving the relationship and keeping the client feeling heard?
Tip: Use a phased plan: “what we can do now safely” + “what we can do next with more time/data/budget,” backed by concrete constraints.
Sample answer: A client requested a major new data source integration late in the timeline, but it would have required new security approvals, additional modeling, and weeks of testing. I acknowledged the value of the request, then I quantified the trade-offs clearly: timeline impact, risk to existing deliverables, and operational overhead. I proposed a phased alternative—deliver a minimal ingestion to land raw data with basic validation now, then complete the modeled tables and dashboards in a follow-on sprint after approvals. The client accepted the phased approach because it kept momentum while staying realistic about risk.
How To Prepare For A Deloitte Data Engineer Interview
Preparing for a Deloitte data engineer interview requires more than brushing up on tools. The interview process is designed to mirror real client delivery, where engineers are expected to reason through ambiguity, design reliable systems, and communicate trade-offs clearly. Strong candidates prepare in a way that balances technical depth with consulting-style communication.
Below are the most effective preparation strategies, structured to reflect how Deloitte actually evaluates data engineers.
Build end-to-end pipeline thinking, not tool-level answers
Deloitte interviewers rarely want isolated explanations of Spark, SQL, or cloud services. They want to see whether you can design an entire data flow, from ingestion to consumption, and explain why each decision was made.
Practice describing pipelines out loud: source systems, ingestion method, transformation layer, storage choice, serving layer, and monitoring. When possible, frame answers around business constraints such as latency, data quality, and governance rather than naming tools.
Tip: Use system-style prompts from the data engineer interview questions page and practice explaining your design step by step before jumping into implementation details.
Practice SQL and data modeling with an emphasis on correctness
SQL questions at Deloitte tend to focus on joins, window functions, aggregation logic, and edge cases rather than trick syntax. Interviewers want to see whether you can write queries that are correct, readable, and easy to validate.
Equally important is explaining how your query handles duplicates, missing data, and changing schemas. This mirrors real client environments where data is messy and definitions evolve.
Tip: Practice reasoning through SQL problems using the Interview Query SQL interview questions set, and narrate how you would validate outputs before sharing results with stakeholders.
Be fluent in Spark and distributed data concepts
For roles involving Databricks or PySpark, Deloitte evaluates whether you understand distributed processing fundamentals, not just APIs. Expect follow-ups on performance issues, data skew, partitioning, and how you would debug a slow or failing job.
You should be able to explain how Spark executes jobs at a high level and how design choices affect cost and reliability in production.
Tip: When practicing Spark-related questions, focus on explaining why a job might be slow and what you would investigate first, rather than listing optimizations blindly. System-style scenarios in the Interview Query challenges section are especially useful here.
Prepare cloud and governance answers from a client perspective
Deloitte works with clients across AWS, Azure, and GCP, often with strict security and compliance requirements. Interviewers care less about memorizing service names and more about whether you can design secure, auditable systems that scale.
Be ready to explain access control models, encryption strategies, logging, and how governance is enforced across teams and environments.
Tip: Frame cloud answers around risks you are mitigating, such as unauthorized access, silent data corruption, or audit failures, instead of listing features.
Rehearse behavioral stories that show judgment under ambiguity
Behavioral interviews are a critical part of the Deloitte data engineer evaluation. Interviewers want evidence that you can manage competing priorities, communicate with non-technical stakeholders, and make trade-offs under pressure.
Prepare stories that highlight decisions you made, why you made them, and what changed as a result. Generic teamwork stories tend to underperform compared with examples tied to delivery impact.
Tip: Practice these responses through mock interviews so you get comfortable handling follow-up questions that challenge your assumptions or decisions.
Practice explaining technical decisions clearly and calmly
Across all rounds, Deloitte evaluates how you communicate. Candidates who pause to clarify requirements, state assumptions, and walk through reasoning consistently outperform those who rush to answers.
You should be comfortable explaining the same idea at multiple levels of depth, depending on the audience.
Tip: Use Interview Query’s guided explanations and live mock interviews to practice delivering structured answers under realistic interview pressure.
Simulate real interview conditions before interview day
Passive preparation rarely translates into strong interview performance. Timed practice, live feedback, and pressure-testing your explanations reveal gaps that reading alone will not.
Combining technical practice with behavioral rehearsal helps reduce cognitive load and improves clarity on interview day.
Tip: Pair scenario-based practice from the Interview Query challenges with at least one live mock interview to mirror Deloitte’s interview dynamics as closely as possible.
Role Overview: Deloitte Data Engineer
A Deloitte data engineer builds and operates the data foundations that power analytics, automation, and AI initiatives across client organizations. At Deloitte, this role sits at the intersection of engineering rigor and consulting delivery. You are expected to design reliable pipelines, model data for downstream use, and ensure data quality and governance at enterprise scale, often across complex, multi-cloud environments.
Day to day, Deloitte data engineers work on real client systems rather than hypothetical products. That means translating loosely defined business needs into technical designs, collaborating closely with data scientists and analysts, and supporting production workloads where correctness, auditability, and uptime matter. Engineers are evaluated not just on whether systems work, but on whether they are understandable, maintainable, and aligned with client objectives.
Core responsibilities
- Data pipeline development: Design and maintain batch and streaming pipelines that ingest data from operational systems, APIs, and third-party sources, then transform and deliver it to analytics-ready layers.
- System and architecture design: Build scalable data lakes, warehouses, and lakehouse architectures that balance performance, cost, and governance.
- Data modeling and integration: Create dimensional and analytical models that support reporting, experimentation, and machine learning use cases.
- Quality and reliability: Implement validation checks, monitoring, and alerting to detect data issues early and prevent downstream failures.
- Client-facing collaboration: Work directly with stakeholders to clarify requirements, explain trade-offs, and support decision-making with data.
- Delivery and standards: Contribute to code reviews, documentation, and SDLC practices to ensure solutions are production-ready and transferable to client teams.
Candidates preparing for this role benefit from practicing end-to-end scenarios in the data engineer interview questions bank, which emphasize pipeline reasoning, data quality, and stakeholder context rather than isolated tools.
Culture And What Makes Deloitte Different
Deloitte’s data engineering culture reflects its consulting-first model. Engineers are embedded in multidisciplinary teams and are expected to balance technical depth with communication and judgment. Success is defined by outcomes delivered for clients, not just elegant architecture diagrams.
What Deloitte interviewers look for
- Structured thinkers: Engineers who can impose clarity on ambiguous problems and explain system design choices step by step.
- Production mindset: Comfort operating systems that must be reliable, auditable, and compliant, not just technically interesting.
- Client-ready communication: The ability to explain complex data concepts to non-technical stakeholders and align technical work with business decisions.
- Ownership without authority: Willingness to drive progress, surface risks, and resolve misalignment in matrixed project teams.
- Learning orientation: Curiosity about evolving platforms such as cloud-native data services, Spark-based processing, and data governance frameworks.
Because projects vary by industry and geography, Deloitte data engineers often rotate across problem types and technology stacks. This rewards adaptability and judgment over memorizing specific tools. Practicing behavioral scenarios through mock interviews and pressure-testing explanations with case-style challenges helps candidates demonstrate these traits clearly.
Average Deloitte Data Engineer Salary
Deloitte data engineer compensation in the United States follows a structured consulting ladder and is primarily base-salary driven, with modest bonuses and no equity at most levels. The figures below reflect annualized total compensation reported on Levels.fyi and should be used as directional benchmarks when evaluating offers or leveling discussions.
Average Annual Compensation by Level (United States)
| Level | Title | Total (Annual) | Base (Annual) | Stock | Bonus (Annual) |
|---|---|---|---|---|---|
| L1 | Analyst (Entry Level) | ~$80K | ~$78K | $0 | ~$2.5K |
| L2 | Consultant | ~$120K | ~$120K | $0 | ~$4K |
| L3 | Senior Consultant | ~$150K | ~$144K | $0 | ~$12K |
| L4 | Manager | — | — | — | — |
| L5 | Senior Manager | — | — | — | — |
| L6 | Director / Partner track | — | — | — | — |
Note: L4+ compensation varies significantly by service line and is less consistently reported in public datasets.
What To Know About Deloitte Data Engineer Compensation
- Base-heavy structure: Unlike big tech roles, Deloitte data engineers receive little to no equity; compensation is largely driven by base salary.
- Bonuses are modest: Annual bonuses exist but typically represent a small percentage of total compensation and depend on performance ratings and utilization.
- Promotion matters most: The largest compensation jumps occur at promotion points (L1 → L2, L2 → L3), not through incremental raises.
- Service line impact: Offers may vary depending on whether the role sits in Consulting, Technology, or Analytics-focused practices.
Average Base Salary
Average Total Compensation
Because leveling outcomes can materially affect where you land within these bands, it helps to practice data engineer interview questions and simulate evaluation scenarios through mock interviews before final offer discussions.
FAQs
What does a Deloitte data engineer do day to day?
A Deloitte data engineer spends most of their time designing, building, and maintaining production data pipelines for client organizations. This includes ingesting data from source systems, modeling it for analytics or machine learning use cases, and implementing data quality and governance checks. The role is highly collaborative and often involves working closely with analysts, data scientists, and non-technical stakeholders to translate business needs into reliable data systems.
How technical is the Deloitte data engineer interview?
The interview is technically rigorous, but it goes beyond writing code. You are expected to demonstrate strong SQL, data modeling, Spark, and cloud fundamentals, while also explaining architectural decisions and trade-offs clearly. Interviewers frequently probe how your solutions behave at scale, how you validate correctness, and how you would operate systems in production. Practicing system-style questions from the data engineer interview questions set helps reflect this balance.
Does Deloitte test system design for data engineers?
Yes. System design is a core part of the Deloitte data engineer interview, especially at the Senior Consultant level and above. Candidates are often asked to design batch or streaming pipelines, data lake or lakehouse architectures, and data quality frameworks. Interviewers care less about drawing perfect diagrams and more about whether your design choices are grounded in business requirements, governance constraints, and operational realities.
Do I need consulting experience to pass the Deloitte data engineer interview?
No. Deloitte hires data engineers from a wide range of backgrounds, including industry, startups, and pure engineering roles. What matters more is whether you can operate effectively in a client-facing environment, communicate clearly, and make sound trade-offs under ambiguity. Candidates without consulting backgrounds often benefit from rehearsing behavioral scenarios through mock interviews.
What skills differentiate strong Deloitte data engineer candidates?
Strong candidates consistently demonstrate structured thinking, production awareness, and client-ready communication. They clarify requirements before designing solutions, anticipate data quality and governance issues, and explain technical decisions in business terms. They also show adaptability across tools and industries, which reflects the variety of Deloitte client engagements.
How to Approach the Deloitte Data Engineer Interview
The Deloitte data engineer interview is designed to surface how you think under real delivery constraints, not how many tools you can name. Strong candidates show they can design reliable pipelines, anticipate data quality and governance issues, and explain trade-offs clearly to both technical and non-technical stakeholders.
The most effective prep mirrors that reality. Focus on practicing SQL and system questions from the data engineer interview questions bank, then pressure-test your reasoning with case-style challenges and live mock interviews. This combination reflects how Deloitte evaluates data engineers and helps you walk into the interview confident, structured, and delivery-ready.
Deloitte Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Easy | |||||||||||||||||||||||
Write a SQL query to select the 2nd highest salary in the engineering department. Note: If more than one person shares the highest salary, the query should select the next highest salary. Example: Input:
Output:
| ||||||||||||||||||||||||
Data Structures & Algorithms | Easy | |||||||||||||||||||||||
Data Structures & Algorithms | Medium | |||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences