
Data Engineer Interview Questions and Answers (2025)


Introduction
Data engineers aren’t optional anymore; they’re mission-critical. As data volumes keep exploding, teams need engineers who turn raw exhaust into reliable, governed assets on scalable, cost-aware platforms.
Over the next decade, the role will shift from hand-built ETL to owning end-to-end data platforms: automating ingestion with data contracts, unifying batch + streaming in lakehouse architectures, productionizing ML/LLM feature pipelines, enforcing privacy/compliance and FinOps by default, and tracking reliability with SLOs and lineage. The strongest hires will blend software engineering, platform ops, and analytics stewardship to deliver trustworthy, real-time data products.
The average U.S. salary for a data engineer now exceeds $133,000, while senior and staff-level engineers can earn anywhere from $165,000 to over $200,000, depending on experience and company scale. But landing those roles? That’s where it gets tricky.
Today’s data engineering interviews go far beyond writing clean SQL, they test how you design, optimize, and troubleshoot data systems under real-world constraints. Employers want to see how you think: how you structure pipelines, handle data quality issues, and reason through scaling challenges.
In this guide, we’ll cover 150+ practical data engineering interview questions, organized by:
- Experience level: Entry → Mid → Senior → Manager
- Topic: SQL, Python, ETL vs ELT, streaming, cloud, system design
- Tools: Kafka, Spark, Airflow, dbt, AWS, GCP, and more
You’ll get practical answers, system design walkthroughs, behavioral frameworks, and whiteboard-ready diagrams to help you interview like a builder, not a memorizer.
How Data Engineer Interviews Really Work
Data engineer interviews in 2025 are evolving. The data engineer interview process isn’t just about writing SQL or transforming data, it’s about showing how you solve complex, real-world problems across the stack. Whether you’re applying to a cloud-native startup or a Fortune 500 company, the structure is surprisingly consistent.
Typical Rounds and Evaluation Rubric
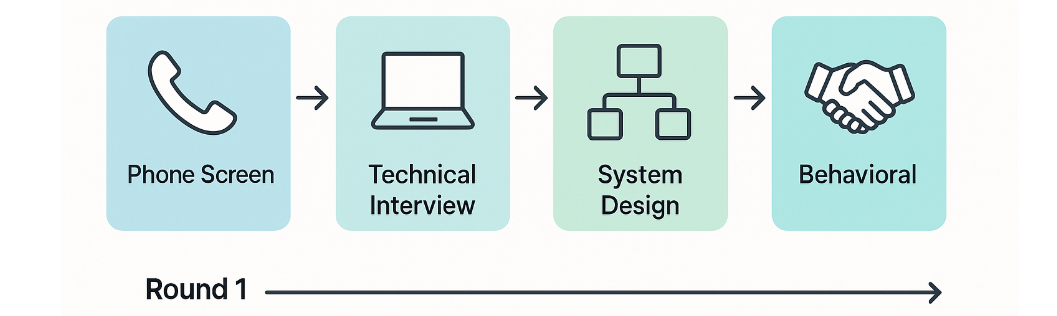
Here’s how a modern data engineering interview process typically unfolds:
- Phone Screen or Online Assessment - A quick 20–30 minute call to confirm role alignment, expected compensation, location, and interview logistics. Be ready to summarize your project experience in 2–3 clear bullets.
- Technical Interview Round - Usually a take-home or live coding session covering SQL queries, Python scripting, and basic ETL logic.
- System Design Round - A deep-dive into how you’d architect real-world pipelines. Interviewers look for trade-off thinking, schema design, and monitoring decisions.
- Behavioral & Cross-Functional Round - Tests your communication, ownership, and crisis-handling under the STAR-IR method.
Focus on structure over perfection. Interviewers care more about your ability to reason through tradeoffs than having the “right” answer.
What Interviewers Actually Measure
Regardless of company size, the scoring rubric usually centers around:
| Skill Area | What Interviewers Look For |
|---|---|
| Core Technical Skills | Strong SQL, Python, and data modeling |
| System Design Judgment | Tradeoffs, reliability, and scalability |
| Collaboration & Ownership | Clear communication, cross-team alignment |
| Business Thinking | Aligning pipelines with product goals |
Quick Start: What To Review First (7–14 Day Plan)
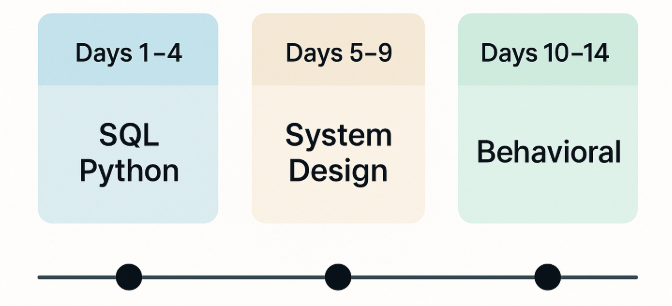
If you’re short on time, this section is your fast-track data engineer interview preparation plan. Instead of trying to memorize 500 concepts, focus on the handful of patterns that show up across almost every interview.
Whether you’re brushing up before a screen or going into final rounds, this checklist will help you prep smart, not just hard.
Days 1–4: Nail the Core - SQL and Python checklist
This is where most interviews start. Master these to clear screens and technical rounds confidently.
| SQL Priorities | Python Priorities |
|---|---|
JOIN patterns: inner, left, self, anti |
Core syntax: list/dict/set comprehensions |
GROUP BY + aggregates |
Utility functions: zip, enumerate, sorted, Counter, defaultdict |
Window functions: ROW_NUMBER, RANK, LAG, LEAD, running totals |
Pandas: groupby, merging, filtering |
Filtering logic: CASE WHEN, HAVING, IS NULL, anti-joins |
Memory-efficient iteration: iterators vs generators |
| CTEs vs subqueries for clean, readable queries | Reusable, clean functions with basic error handling |
Spend time solving 1–2 real-world problems per day using public datasets (e.g. NYC Taxi, COVID, Reddit), or Interview Query’s SQL + Python banks.
Days 5–9: System design must knows
Now shift focus to how data engineers design systems at scale. Key Concepts:
- Batch vs Streaming: When to use which? Latency, throughput, SLOs
- ETL vs ELT: Schema evolution, idempotency, cost tradeoffs
- Lakehouse architecture: Where it fits between warehouses and lakes
- Orchestration tools: Airflow vs Dagster vs Prefect — strengths, DAG structure, retries
- Observability: Logs, data quality alerts, lineage tracking
Days 10–14: Tell Your Story - Behavioral frameworks
Even great coders and architects stumble here. Strong communication can differentiate you, especially for incident response and ownership questions.
Frameworks to Practice
- STAR (Situation, Task, Action, Result) - for project retros, teamwork, persuasion
- STAR-IR (STAR + Incident Response) - for production issues, failed pipelines, root cause analysis
Rehearse 2–3 real incidents from past roles or side projects using STAR/STAR-IR. Don’t shy away from failures; show how you adapted.
Questions by Experience Level
Data engineer interview questions vary depending on your experience level. Entry-level candidates often face SQL and ETL basics, while mid-level engineers are asked about architecture and cost efficiency. Senior engineers get system design and stakeholder-focused prompts, and managers are tested on leadership, compliance, and technology adoption.
Read more: Data Engineer Career Path: Skills, Salary, and Growth Opportunities
Entry-Level & Associate Data Engineer Interview Questions
For entry-level data engineer interview questions, companies look for evidence of SQL fluency, ETL knowledge, and practical problem-solving in handling messy datasets. Expect to explain how you clean, organize, and transform data, plus demonstrate understanding of schema design and distributed systems like Hadoop.
What ETL tools do you have experience using? What tools do you prefer?
There are many variations to this type of question. A different version would be about a specific ETL tool: “Have you had experience with Apache Spark or Amazon Redshift?” If a tool is in the job description, it might come up in a question like this. One tip: include any training, how long you’ve used the tech, and specific tasks you can perform.
What’s the difference between WHERE and HAVING?
Both WHERE and HAVING are used to filter a table to meet the conditions that you set. The difference between the two is apparent when used in conjunction with the GROUP BY clause. The WHERE clause filters rows before grouping (before the GROUP BY clause), and HAVING is used to filter rows after aggregation.
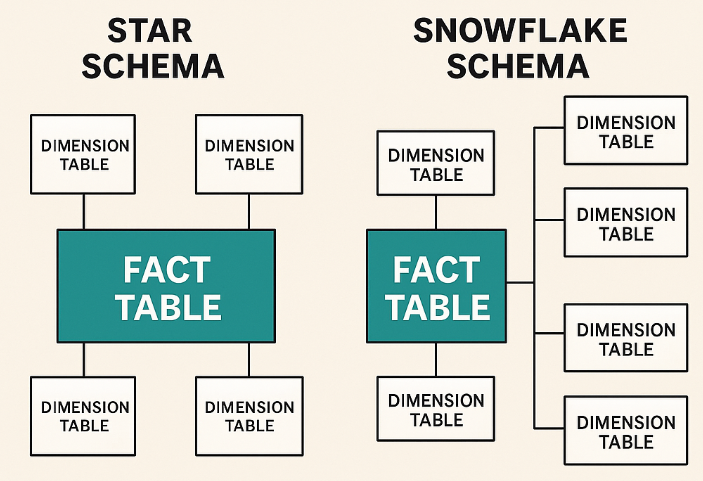
Can you explain the design schemas relevant to data modeling?
In data modeling, two schemas are most common:
- Star Schema: A central fact table (e.g., sales transactions) connected to multiple dimension tables (customers, products, time). It simplifies queries and is widely used in reporting.
- Snowflake Schema: An extension of the star schema where dimensions are normalized into multiple related tables (e.g., product → product category → product department). It reduces redundancy but adds query complexity.
- Galaxy/Fact Constellation Schema: Multiple fact tables share dimension tables, useful in complex systems (e.g., sales + inventory).
When explaining, mention tradeoffs: star schema offers faster query performance, while snowflake saves storage and enforces consistency.
What are the key features of Hadoop?
When discussing Hadoop, focus on its core features: fault tolerance ensures data is not lost, distributed processing allows handling large datasets across clusters, scalability enables growth with data volume, and reliability guarantees consistent performance. Use examples to illustrate each feature’s impact on data projects.
How would you design a data pipeline?
Begin by clarifying the data type, usage, requirements, and frequency of data pulls. This helps tailor your approach. Next, outline your design process: select data sources, choose ingestion methods, and detail processing steps. Finally, discuss implementation strategies to ensure efficiency and scalability.
Mid-Level Data Engineer Interview Questions
Data engineer interview questions for 3 years experience or more often shift toward warehouse design, cost-aware analytics, and building scalable solutions. Mid-level engineers are expected to balance hands-on SQL skills with architectural judgment and optimization strategies.
-
To handle unstructured video data in an ETL pipeline, you can use tools like Apache Kafka for data ingestion, followed by processing with frameworks like Apache Spark or TensorFlow for video analysis. Storage solutions such as AWS S3 or Google Cloud Storage can be used to store the processed data, and metadata can be managed using databases like MongoDB or Elasticsearch.
How would you ensure the data quality across these different ETL platforms?
Ensuring data quality across multiple ETL platforms involves implementing data validation checks, using data profiling tools, and setting up automated alerts for data anomalies. Additionally, maintaining a robust data governance framework and using translation modules for language consistency are crucial for cohesive analysis.
Tell me about a project in which you had to clean and organize a large dataset.
In this scenario, you should describe a real-world project where you encountered a large dataset that required cleaning and organization. Discuss the steps you took to identify and address data quality issues, such as missing values, duplicates, and inconsistencies, and how you organized the data to make it suitable for analysis.
Describe a data project you worked on. What were some of the challenges you faced?
A typical data project might involve building an end-to-end pipeline that ingests raw data, transforms it for analysis, and loads it into a warehouse or lakehouse. Common challenges include integrating data from multiple inconsistent sources, handling schema drift, and ensuring data quality during transformation. Performance tuning is often required to process large volumes efficiently, and cost optimization becomes a factor in cloud-based environments. Overcoming these challenges involves implementing validation checks, partitioning strategies, and automated monitoring to ensure both reliability and scalability.
How would you design a data warehouse given X criteria?
Begin by clarifying requirements: sales metrics, customer data, and product details. Sketch a star schema with a central fact table for sales and dimension tables for products, customers, and time. Ensure data integrity and scalability for future growth.
Senior & Staff Data Engineer Interview Questions
When you reach the senior or staff level, senior data engineer interview questions test your ability to design resilient pipelines, manage large datasets, and collaborate with stakeholders. Expect open-ended design prompts, SQL performance optimization, and deep dives into reliability and observability.
What kind of data analytics solution would you design, keeping costs in mind?
For a cost-effective data analytics solution for clickstream data, consider using cloud-based services like AWS Kinesis or Google Pub/Sub for data ingestion, and Apache Hadoop or Google BigQuery for storage and querying. Implementing data partitioning and compression can further optimize storage costs.
What questions do you ask before designing data pipelines?
When designing data pipelines, start by understanding the project’s requirements. Ask stakeholders about the data’s purpose, its validation status, and the frequency of data extraction. Determine how the data will be utilized and identify who will manage the pipeline. This ensures alignment with business needs and helps in creating an efficient and effective data pipeline. Document these insights for clarity and future reference.
How do you gather stakeholder input before beginning a data engineering project?
To gather stakeholder input effectively, start by conducting surveys and interviews to capture their needs. Utilize direct observations to understand workflows and review existing logs for insights. Document findings to ensure alignment and maintain open communication throughout the project, fostering collaboration and clarity.
How would you optimize a slow-running SQL query on a large dataset?
Optimization starts with analyzing the execution plan to identify bottlenecks. Common strategies include adding appropriate indexes, rewriting queries to leverage partition pruning, and avoiding expensive operations like
SELECT *or nested subqueries. Using materialized views or pre-aggregations can also reduce scan costs. For distributed systems like Spark or BigQuery, tuning partitioning and clustering improves performance.How do you design pipelines to ensure reliability and observability at scale?
Reliable pipelines are built with idempotent operations, retry logic, and checkpointing to recover from failures. Observability is ensured by adding metrics on throughput, latency, and error rates, along with structured logging and distributed tracing. Dashboards and alerting systems are configured to notify the team of anomalies. Together, these practices guarantee that pipelines can scale while maintaining trust in the data.
Data Engineering Manager Interview Questions
At the leadership level, data engineer manager interview questions focus on decision-making, compliance, and strategic use of technology. Expect questions about how you prioritize, guide your team, and ensure governance while balancing technical tradeoffs with business goals.
How do you approach decision-making when leading a data engineering team?
As a manager, decision-making involves balancing technical tradeoffs with business priorities. Strong leaders:
- Use data-driven decisions to ensure objectivity.
- Align with stakeholder needs so projects deliver business value.
- Weigh risks vs. impact when choosing technologies or timelines.
- Apply agile practices for flexibility.
- Invest in mentorship and training to grow team capabilities.
How do you handle compliance with data protection regulations in your data engineering projects?
Managers are expected to build systems with compliance in mind. This includes:
- Staying updated on GDPR, CCPA, HIPAA requirements.
- Implementing a data governance framework with clear policies.
- Enforcing encryption at rest and in transit.
- Applying strict access controls and audits.
- Proactively monitoring usage and performing regular compliance checks.
Can you describe a challenging data engineering project you managed?
Answer by walking through:
- Scope & objectives: Define the business problem.
- Challenges: e.g., resource constraints, conflicting priorities.
- Solutions: Technical fixes (like schema redesign), plus people fixes (like aligning stakeholders).
- Outcome: Improved performance, reliability, or business impact.
How do you evaluate and implement new data technologies?
Good managers balance innovation with pragmatism:
- Track market trends and emerging tools.
- Run proof of concept (PoC) to test fit.
- Perform cost-benefit analysis for ROI.
- Secure stakeholder buy-in with clear value cases.
- Roll out with an implementation plan + team training.
How do you prioritize tasks and projects in a fast-paced environment?
Use structured prioritization frameworks (e.g., Eisenhower Matrix or MoSCoW). Align with business objectives, communicate priorities clearly, and focus team energy on the projects with the highest impact and urgency. Revisit priorities regularly as needs change.
Core Technical Questions (With Answers)
Core technical data engineer interview questions test your ability to build and optimize pipelines, write efficient queries, and debug real-world issues. These questions go beyond theory and measure how well you apply SQL, Python, ETL vs ELT, modeling, streaming, and cloud concepts in practice.
Read more: Meta Data Engineer Interview Guide – Process, Questions, and Prep
SQL for Data Engineers
SQL is at the center of every data engineer interview. SQL interview questions for data engineers often cover window functions, anti-joins, deduplication, slowly changing dimensions, partition pruning, and performance tuning. Candidates are expected to solve practical tasks like overlapping ranges, top-N queries, gap-and-island problems, last row per group, and idempotent upserts.
Strong answers show not just correct syntax, but also an understanding of scalability, efficiency, and tradeoffs. Common SQL questions include:
Find the average yearly purchases for each product
To find the average quantity of each product purchased per transaction each year, group the transactions by year and product_id. Calculate the average quantity for each group and round the result to two decimal places. Ensure the output is sorted by year and product_id in ascending order.
Write a query that returns all neighborhoods that have 0 users
To find neighborhoods with no users, perform a LEFT JOIN between the
neighborhoodstable and theuserstable on theneighborhood_id. Filter the results where theuser_idis NULL, indicating no users are associated with those neighborhoods.-
We have a table called song_plays that tracks each time a user plays a song. For this problem, we use the
INSERT INTOkeywords to add rows to thelifetime_playstable. If we set this query to run daily, it becomes a daily extract, transform, and load (ETL) process. Write a query to get the current salary data for each employee.
You have a table representing the company payroll schema. Due to an ETL error, the employee’s table isn’t properly updating salaries; instead, it inserts them when performing compensation adjustments.
-
To solve this, first filter departments with at least ten employees. Then, calculate the percentage of employees earning over 100K for each department and rank the top three departments based on this percentage.
Write an SQL query to retrieve each user’s last transaction
This question tests window functions. It’s specifically about finding the most recent transaction per user. To solve this, partition by
user_id, order by date desc, and pickROW_NUMBER=1. In practice, this supports recency tracking.Return the running total of sales for each product since its last restocking.
This question tests your ability to perform time-aware aggregations with filtering logic. It’s specifically about calculating the running sales total that resets after each restocking event. To solve this, identify restocking dates and partition the sales by product, resetting the cumulative total after each restock using window functions and conditional logic. This pattern is critical for real-time inventory tracking in logistics and retail.
-
To solve this, you need to compare each user’s subscription date range with others to check for overlaps. This can be done by joining the table with itself and checking if the start date of one subscription is before the end date of another and vice versa, ensuring the subscriptions belong to the same user.
Compute click-through rates (CTR) across queries
This question tests your ability to design performant queries for search analytics using selective filters, proper join order, and targeted indexes. It’s asked to evaluate whether you can compute click-through rates across query segments while minimizing full scans and avoiding skewed groupings. To solve this, pre-aggregate impressions/clicks by normalized query buckets, ensure a composite index on
(query_norm, event_time)with covering columns for counts, then join safely to deduped clicks; validate withEXPLAINto confirm index usage.
You can explore the Interview Query dashboard that lets you practice real-world Data Engineering interview questions in a live environment. You can write, run codes, and submit answers while getting instant feedback, perfect for mastering Data Engineering problems across domains.
Write a query to track flights and related metrics
This question tests grouping and ordering. It’s specifically about summarizing flights per plane or route. To solve this, group by
plane_idor city pair andCOUNT/AVGdurations. This supports airline operations dashboards.What are Common Table Expressions (CTEs) in SQL?
This question tests query readability and modularization skills. It specifically checks whether you can use CTEs to simplify subqueries and complex joins. Define a temporary result set with
WITH, then reference it in the main query. Multiple CTEs can also be chained for layered logic. In real-world analytics, CTEs make ETL transformations and reporting queries more maintainable, especially when debugging multi-step calculations.How do you handle missing data in SQL?
This question tests data cleaning and null handling. It specifically checks whether you know how to replace or manage
NULLvalues in queries. To solve this, use functions likeCOALESCE()to substitute default values, orCASEstatements to conditionally fill missing data. In production pipelines, handling missing data ensures consistent reporting and prevents errors in downstream ML models or dashboards.How do you perform data aggregation in SQL?
This question tests group-based aggregation and summary reporting. It specifically checks whether you can apply aggregate functions like
SUM(),AVG(), andCOUNT()withGROUP BY. To solve this, group rows by a key (e.g., department) and apply aggregation functions to summarize values across groups. In real-world analytics, aggregation supports business metrics like revenue per product, active users by region, or error rates per system.How do you optimize SQL queries for better performance?
This question tests query tuning and execution efficiency. It specifically checks whether you know optimization strategies like indexing, selective filtering, and avoiding unnecessary operations. To solve this, add indexes on frequently queried columns, replace
SELECT *with explicit columns, and analyze execution plans to detect bottlenecks. In large-scale data engineering, performance tuning reduces compute costs and accelerates queries against billions of rows.What is the difference between DELETE and TRUNCATE?
To explain the difference, clarify that DELETE is a DML command used for removing specific records, allowing for conditions via the WHERE clause. In contrast, TRUNCATE is a DDL command that removes all rows from a table without conditions, quickly and without logging individual row deletions. Emphasize that TRUNCATE resets any identity columns, while DELETE retains the table structure.
What is the difference between UNION and UNION ALL?
This question tests set operations and query deduplication. It specifically checks whether you know how combining datasets affects duplicates. UNION combines results and removes duplicates, while UNION ALL preserves all rows including duplicates, making it faster. In real-world data pipelines, UNION is used when deduplicated results are required, while UNION ALL is preferred when performance is critical, and duplicates are acceptable.
What is an index in SQL? When would you use an index?
Indexes are lookup tables that the database uses to perform data retrieval more efficiently. Users can use an index to speed up SELECT or WHERE clauses, but it slows down UPDATE and INSERT statements.
What SQL commands are utilized in ETL?
When discussing SQL commands in ETL, focus on their roles: SELECT retrieves data, JOIN combines tables based on relationships, WHERE filters specific records, ORDER BY sorts results, and GROUP BY aggregates data for analysis. Emphasize understanding how to use these commands effectively to extract, transform, and load data, ensuring clarity in data manipulation and retrieval processes.
Does JOIN order affect SQL query performance?
How you join tables can have a significant effect on query performance. For example, if you JOIN large tables and then JOIN smaller tables, you could increase the processing necessary by the SQL engine. One general rule: Joining two tables will reduce the number of rows processed in subsequent steps and will help improve performance.
Why is it standard practice to explicitly put foreign key constraints on related tables instead of creating a normal BIGINT field? When considering foreign key constraints, when should you consider a cascade delete or a set null?
Using foreign key constraints ensures data integrity by enforcing relationships between tables, preventing orphaned records. Cascade delete is useful when you want related records to be automatically removed, while set null is appropriate when you want to retain the parent record but remove the association. Always assess the impact on data consistency before implementing these options.
Python for Data Engineers
Python is the go-to programming language in modern data engineering, and it frequently appears in interviews. Python questions for data engineer roles typically test how well you can handle data structures, write efficient code, and optimize for memory and speed. Expect topics like iterators vs generators, multiprocessing vs threading, type hints, and pandas vs Spark workflows.
These questions often mirror real tasks such as aggregating data by week, parsing logs, or implementing sampling algorithms. Below are common Python interview questions, from coding challenges to conceptual best practices.
Given a string, write a function to find its first recurring character
This question tests string traversal and hash set usage. It specifically checks if you can efficiently identify repeated elements in a sequence. To solve this, iterate through the string while tracking seen characters in a set, and return the first duplicate encountered. In real-world data pipelines, this mimics finding duplicate IDs, detecting anomalies, or flagging repeated events in logs.
Find the bigrams in a sentence
This question tests string manipulation and iteration. It specifically evaluates your ability to generate consecutive word pairs. To solve this, split the input into words and loop to create tuples pairing each word with its successor. This technique is widely used in NLP tasks like tokenization, query autocomplete, and analyzing clickstream sequences.
Given a list of integers, identify all the duplicate values in the list.
This question tests your understanding of data structures, hash-based lookups, and iteration efficiency in Python. It specifically checks whether you can detect and return duplicate elements from a collection. To solve this, you can use a set to track seen numbers and another set to store duplicates. Iterating once through the list ensures O(n) time complexity. In real-world data engineering, duplicate detection is critical when cleaning raw datasets, ensuring unique identifiers in ETL pipelines, or reconciling records across multiple sources.
-
This question tests algorithm design and complexity analysis. It specifically evaluates whether you understand brute-force versus optimized solutions for subset sum problems. Small inputs can use backtracking or combinations, while larger cases are better solved using prefix sums and hash maps in O(n). This problem has real-world applications in financial reconciliation, anomaly detection, and fraud analysis.
-
This question tests probability, simulation, and Python’s random utilities. It specifically checks whether you can implement random sampling without external libraries. To solve this, use Python’s
random.gauss()or implement Box-Muller transform; discuss time-space complexity and randomness quality. In real-world analytics, this underpins A/B testing, Monte Carlo simulations, and load-testing scenarios. Given an integer N, write a function that returns a list of all of the prime numbers up to N.
This question tests algorithmic thinking, loops, and efficiency in Python. It specifically checks whether you can implement prime detection using control structures and optimization. To solve this, use trial division up to √N for each candidate number, appending only primes to the result list. In real-world data engineering, efficient prime detection maps to designing optimized algorithms for filtering and deduplication in large-scale datasets.
You can explore the Interview Query dashboard that lets you practice real-world Data Engineering interview questions in a live environment. You can write, run codes, and submit answers while getting instant feedback, perfect for mastering Data Engineering problems across domains.
-
This question tests probability and memory-efficient algorithms. It specifically evaluates whether you know reservoir sampling for infinite streams. To solve this, maintain one candidate and replace it with the i-th element at probability 1/i, ensuring uniform distribution in O(1) space. This is crucial for telemetry sampling, log analysis, and real-time analytics where full storage is infeasible.
-
This question tests recursion and backtracking. It specifically checks whether you can generate all subsets that meet a target sum. To solve this, you’d recursively explore adding or excluding elements until the current sum matches N, backtracking when it exceeds N. In practice, this models subset sum problems like budget allocation or balancing workloads across servers.
Which Python libraries are most efficient for data processing? The most widely used libraries include:
- pandas – best for tabular data manipulation and analysis.
- NumPy – optimized for numerical computation and array handling.
- Dask – enables parallel computing and out-of-core processing for large datasets.
- PySpark – scales Python data processing across distributed clusters. The choice depends on dataset size, complexity, and whether you need single-node analysis or distributed computation.
What is the difference between “is” and “==”?
==checks for value equality, meaning two objects contain the same data.ischecks for identity, meaning both variables point to the exact same object in memory. For example, two identical lists will return True for==but False forisunless they reference the same instance. This distinction is key for debugging object references and avoiding subtle Python bugs.What is a decorator?
A decorator in Python is a function that takes another function as input and returns a modified function. It allows you to add behavior such as logging, caching, or authorization checks without changing the original function code. Decorators are commonly used in frameworks like Flask and Django for routes, middleware, and access control.
How would you perform web scraping in Python?
To perform web scraping, use the
requestslibrary to fetch HTML content, then parse it with BeautifulSoup or lxml. Extract structured data into Python lists or dictionaries, clean it with pandas or NumPy, and finally export to CSV or a database. Web scraping is useful for gathering competitive intelligence, monitoring prices, or aggregating open data.How do you handle large datasets in Python that do not fit into memory?
For datasets that exceed memory, use chunked processing with pandas (
read_csvwithchunksize), leverage Dask or PySpark for distributed processing, or use databases to stream queries. Compression and optimized file formats like Parquet also reduce memory footprint. This ensures scalability for production-grade pipelines handling terabytes of data.How do you ensure your Python code is efficient and optimized for performance?
Efficiency comes from using vectorized operations in NumPy/pandas, minimizing loops, and applying efficient data structures (
set,dict). Profiling tools (cProfile,line_profiler) help identify bottlenecks. Caching results, parallelizing tasks, and memory management (iterators, generators) further improve performance in data engineering pipelines.How do you ensure data integrity and quality in your data pipelines?
In Python pipelines, data integrity is ensured through validation checks (e.g., schema validation, null checks), unit tests on transformations, and anomaly detection using libraries like Great Expectations. Adding logging and monitoring ensures issues are caught early. Strong practices prevent downstream errors and keep pipelines reliable.
ETL vs ELT, Orchestration, and Cost Control
Modern data engineer interviews often include ETL interview questions that test how well you understand data transformation strategies, pipeline orchestration, and cost optimization. Companies want engineers who can design pipelines that are scalable, reliable, and cost-efficient, while handling real-world issues like late-arriving data, schema evolution, and backfills. Expect to discuss the differences between ELT vs ETL, tradeoffs of orchestration tools, and best practices for managing partitions in ETL processes.
Explain the key differences between ETL and ELT. When would you choose one over the other?
When asked about ETL vs ELT, start by clearly defining each: ETL transforms data before loading into a warehouse, while ELT loads raw data into the warehouse and applies transformations later. You should highlight that ETL is often chosen when data must be cleaned or standardized before loading, while ELT is better when using modern cloud warehouses that handle transformations efficiently. Emphasize that you evaluate the choice based on data volume, transformation complexity, and cost considerations, showing that you understand tradeoffs in real-world pipelines.
How do you design ETL pipelines to ensure idempotency?
When asked about idempotency, explain that you design pipelines so rerunning jobs won’t create duplicate data or incorrect results. You can describe strategies like using primary keys for deduplication, implementing merge/upsert logic, or partition overwrites. Highlight that you also maintain checkpoints and audit logs to track what has been processed. This shows interviewers that you build pipelines resilient to retries, failures, and backfills.
What strategies do you use to handle late-arriving or out-of-order data in batch pipelines?
When this comes up, start by explaining that late-arriving data is common in real-world systems. You can mention using watermarks, backfills, or time-windowed processing to manage delays. Point out that you typically design pipelines to reprocess affected partitions and use idempotent transformations to avoid duplication. This demonstrates your ability to balance correctness with efficiency when handling unpredictable data.
What is partitioning in ETL, and how does it improve performance and cost-efficiency?
When asked about partitions in ETL, explain that partitioning breaks large datasets into smaller, more manageable subsets, usually by time, region, or customer ID. Highlight how this improves query performance by pruning irrelevant partitions and reduces costs by scanning only necessary data. You can also mention using optimized storage formats like Parquet or ORC. This shows that you know how to design scalable pipelines that control both compute and storage costs.
How do you implement schema evolution in ETL or ELT processes without breaking downstream jobs?
When discussing schema evolution, start by mentioning strategies like backward-compatible changes (adding nullable columns) and versioning schemas. Point out that you use tools like Avro or Protobuf that support evolution, and you validate schema changes before deploying them. Emphasize your ability to communicate changes to downstream teams and build tests that catch breaking changes early. This shows you understand both the technical and collaborative aspects of schema management.
What are the pros and cons of using orchestration tools like Airflow vs managed services like AWS Step Functions?
When asked about orchestration, begin by explaining that tools like Airflow give flexibility and open-source control, while managed services like Step Functions reduce operational overhead and integrate tightly with cloud ecosystems. You should highlight that you choose based on context: Airflow for complex DAGs and hybrid environments, Step Functions when reliability and scaling matter more than customization. This demonstrates that you weigh tradeoffs based on team resources and long-term maintenance.
How would you handle a large-scale backfill of data without disrupting production workloads?
When this comes up, explain that you prioritize minimizing impact on production. Mention strategies like running backfills in batches, throttling jobs, or scheduling them during off-peak hours. You can also bring up isolating backfill jobs to separate clusters or queues. Emphasize monitoring progress and validating data after completion. This shows that you understand operational realities and avoid compromising SLAs.
What strategies can reduce cloud costs in ETL/ELT pipelines (e.g., storage formats, partition pruning, caching)?
When asked about cost control, explain that you reduce expenses by choosing efficient file formats (Parquet, ORC), applying partitioning and clustering, caching intermediate results, and cleaning up unused data. Highlight monitoring and cost dashboards to track spend and optimize storage tiers. You should also mention tuning compute resources and autoscaling policies. This shows interviewers that you not only build pipelines but also keep an eye on business value.
How do you deal with duplicate records in ETL workflows while ensuring data consistency?
When asked about duplicates, you can describe using primary keys, deduplication logic (
ROW_NUMBER,DISTINCT), or merge/upsert strategies. Emphasize building validation steps that detect duplicates early and designing pipelines that enforce constraints at the database or warehouse level. Mention that you also monitor for anomalies in record counts. This shows you take data quality seriously and can prevent downstream issues.Describe a scenario where you optimized an ETL job for performance. What steps did you take and what tradeoffs did you make?
When this comes up, walk through a concrete example, such as reducing a Spark job’s runtime from hours to minutes. Explain that you optimized by adjusting partition sizes, reducing shuffles, and leveraging caching or broadcast joins. Point out the tradeoff between job complexity vs performance gains. Emphasize the impact on the business, such as meeting SLAs, reducing costs, or enabling faster insights. This shows that you focus on measurable improvements.
Data Modeling and Warehousing
Data modeling and warehousing are core skills for data engineers. In interviews, you’ll face data warehouse interview questions for data engineer roles that test your ability to design schemas, choose the right level of normalization, and balance performance with cost. For data modeling interview questions, focus on how well you design star vs snowflake schemas, implement surrogate keys, and support real-world analytics with scalable models.
Design a database to represent a Tinder style dating app
To design a Tinder-style dating app database, you need to create tables for users, swipes, matches, and possibly messages. Optimizations might include indexing frequently queried fields, using efficient data types, and implementing caching strategies to improve performance.
How would you create a schema to represent client click data on the web?
To create a schema for client click data, you should include fields that capture essential information such as the timestamp of the click, user ID, session ID, page URL, and any relevant metadata like device type or browser. This schema will help in tracking user interactions effectively and can be used for further analysis and insights.
Design a data warehouse for a new online retailer
To design a data warehouse for a new online retailer, you should start by identifying the key business processes and the data they generate. Use a star schema to organize the data, with fact tables capturing transactional data and dimension tables providing context. This design will facilitate efficient querying and reporting.
Design a database for a ride-sharing app
To design a database for a ride-sharing app, you need to create tables that capture essential entities such as riders, drivers, and rides. The schema should include tables for users (both riders and drivers), rides, and possibly vehicles, with foreign keys linking rides to both riders and drivers to establish relationships between these entities.
You can explore the Interview Query dashboard that lets you practice real-world Data Engineering interview questions in a live environment. You can write, run codes, and submit answers while getting instant feedback, perfect for mastering Data Engineering problems across domains.
What is the difference between normalization and denormalization in data modeling?
When asked this, explain that normalization reduces redundancy by breaking data into related tables, while denormalization combines data for faster reads. You should highlight that normalization is ideal for OLTP systems, while denormalization is common in data warehouses. Emphasize that the choice depends on whether the priority is storage efficiency or query performance.
Explain the star schema and when you would use it.
When this comes up, describe that a star schema has a central fact table connected to dimension tables like customers, products, or time. You should point out that it simplifies queries and is widely used in reporting and BI systems. Emphasize that you choose it when ease of use and fast query performance matter most.
What is a snowflake schema, and how is it different from a star schema?
When asked this, explain that a snowflake schema is a normalized extension of the star schema where dimensions are split into multiple related tables. You should highlight that it saves storage and enforces data consistency but can make queries more complex. Emphasize that you use it when the warehouse needs high normalization or when dimensions are very large.
What are surrogate keys, and why are they used in data warehouses?
When this comes up, explain that surrogate keys are system-generated identifiers (like integers) that uniquely identify rows in dimension tables. You should highlight that they are preferred over natural keys to avoid business logic changes breaking relationships. Emphasize that surrogate keys improve join performance and support slowly changing dimensions.
What are common challenges in designing schemas for clickstream or event data?
When this comes up, explain that clickstream data has high volume, nested attributes, and evolving schemas. You should highlight strategies like flattening nested fields, partitioning by date, and designing wide fact tables for scalability. Emphasize that schema design must balance storage cost, query performance, and business usability.
How do you decide between a data lake, data warehouse, and lakehouse architecture?
When asked this, explain that data lakes are for raw, unstructured storage, warehouses are for structured, query-optimized analytics, and lakehouses combine both. You should highlight that the choice depends on the workload: BI reporting, ML pipelines, or both. Emphasize that modern teams often lean toward lakehouse for flexibility, but you evaluate based on company needs.
How do you ensure data quality in a data warehouse?
When this comes up, explain that you enforce quality with validation checks, primary key/foreign key constraints, and data profiling. You should highlight tools like Great Expectations or dbt tests for automating validations. Emphasize that you integrate these checks into pipelines so errors are caught before they impact reporting.
What strategies do you use to optimize query performance in a data warehouse?
When asked this, explain that you use partitioning, clustering, indexing, and materialized views. You should highlight file format choices (Parquet/ORC), compression, and pruning as cost-saving strategies. Emphasize that query optimization directly reduces both compute costs and end-user latency.
Can you describe a data modeling decision you made that had a significant business impact?
When this comes up, walk through a real example. Explain the problem (e.g., a slow sales dashboard), the schema decision you made (e.g., moving to a star schema with pre-aggregations), and the outcome (e.g., queries that ran 10x faster). Emphasize the business impact—such as enabling executives to make faster decisions or cutting costs.
What are some things to avoid when building a data model?
When building a data model, avoid poor naming conventions by establishing a consistent system for easier querying. Failing to plan can lead to misalignment with stakeholder needs, so gather input before designing. Additionally, neglecting surrogate keys can create issues; they provide unique identifiers that help maintain consistency when primary keys are unreliable. Always prioritize clarity and purpose in your design.
What are the features of a physical data model?
When asked this, explain that a physical data model defines how data is actually stored in the database. You should highlight features like tables, columns with data types, indexes, constraints, relationships, and partitioning strategies. Emphasize that unlike a logical model, the physical model is tied to a specific database system and includes performance tuning considerations. This shows interviewers you understand how design choices affect scalability, storage efficiency, and query speed in production systems.
Streaming & Real-Time Systems
Streaming has become a core skill for data engineers, especially as companies rely on real-time insights for personalization, fraud detection, and system monitoring. Streaming data engineer interview questions often focus on tools like Kafka, Spark Streaming, or Flink, and how you handle latency, throughput, and fault tolerance. Expect real-time data engineering interview questions that test your ability to design pipelines with watermarking, exactly-once semantics, and stateful processing.
What is Apache Kafka, and why is it used in streaming pipelines?
Kafka is a distributed publish-subscribe messaging system designed for high throughput and fault tolerance. It is widely used for event-driven architectures and real-time analytics. Kafka’s durability and scalability make it a backbone for many streaming systems.
What do exactly-once semantics mean in streaming systems?
Exactly-once semantics ensure each event is processed a single time with no duplicates or data loss. They are achieved through idempotent producers, transactional writes, or checkpointing. This is critical for use cases like financial transactions or billing systems where precision matters.
How do you handle late-arriving or out-of-order events in a streaming pipeline?
Late-arriving data is managed using watermarks and event-time windows, which allow delayed events to be included within a defined tolerance. Buffering and backfill processes can also be used. These strategies are essential in IoT, payments, and user activity tracking.
What is watermarking, and why is it important in stream processing?
Watermarking tracks event-time progress and signals when a window of events is complete. It balances accuracy with latency by deciding when to stop waiting for late data. Without watermarks, systems risk either discarding valid data or delaying results indefinitely.
How do you ensure fault tolerance in real-time systems?
Fault tolerance is achieved through checkpointing, replication, retries, and idempotent writes. Distributed systems like Kafka and Flink provide built-in resilience against node or network failures. This ensures continuous processing even under system disruptions.
What are stateful operations in stream processing, and how are they managed?
Stateful operations maintain context across multiple events, such as session windows or running aggregates. Frameworks manage this state using backends with checkpointing to provide durability. Stateful processing enables advanced use cases like fraud detection and recommendation engines.
How do you design a streaming pipeline to scale with growing data volume?
Scalability is achieved through horizontal scaling, partitioning, parallelism, and backpressure handling. Cloud platforms support autoscaling to adjust resources dynamically. These practices allow systems to handle millions of events per second without downtime.
What is the difference between stream processing and micro-batching?
Stream processing handles each event individually in near real time, while micro-batching groups small sets of events for efficiency. Spark Streaming traditionally uses micro-batching, while Flink and Kafka Streams provide true event-by-event processing. The choice depends on latency and throughput requirements.
Can you give an example of designing a real-time analytics pipeline?
A common example is building a clickstream pipeline. Kafka ingests user activity events, Flink or Spark Streaming processes and aggregates them, and results are stored in a warehouse or NoSQL database. Observability and exactly-once guarantees ensure reliability and correctness.
What are common challenges in real-time data engineering, and how do you address them?
Challenges include late data, low-latency requirements, duplicate events, and cost management. These are addressed with watermarking, idempotent processing, partition pruning, and active monitoring of lag. Effective solutions balance correctness, speed, and cost.
Watch how a data engineer tackles Streaming and Analytics Interview questions in this mock session. This walkthrough highlights practical problem-solving techniques you can apply in your own interview prep.
In this mock interview, Jitesh, a Data Engineer at Amazon, tackles real-world streaming and analytics questions posed by Rob, the founder of Remot. The session highlights how effective communication and logical reasoning can distinguish top candidates.
Cloud Platforms and Infra
Cloud services and modern data stack tools are central to data engineering. AWS data engineer interview questions, Azure data engineer interview questions, and GCP data engineer interview questions test your ability to leverage cloud-native services for storage, compute, and analytics. Meanwhile, Airflow interview questions and dbt interview questions focus on orchestration and transformations, while Kafka interview questions emphasize event-driven design and scalability.

What are the key AWS services used by data engineers?
Core AWS services include S3 for storage, Glue for ETL, EMR for big data processing, Athena for serverless queries, and Redshift for warehousing. Additional services like Kinesis handle streaming and Lambda supports serverless compute. Together, they form a complete data engineering ecosystem.
How do you design a scalable data pipeline on GCP?
On GCP, data pipelines often use Pub/Sub for ingestion, Dataflow for transformation, BigQuery for warehousing, and GCS for storage. These services are serverless and scale automatically with load. This design supports both batch and real-time processing.
What is Azure Synapse Analytics, and how does it differ from Azure Data Lake?
Azure Synapse is a cloud data warehouse designed for analytics and BI workloads. Azure Data Lake, on the other hand, stores raw structured and unstructured data at scale. Synapse is optimized for queries and reporting, while Data Lake serves as a foundation for transformations and ML pipelines.
How do you implement data partitioning in cloud warehouses like BigQuery, Redshift, or Synapse?
Partitioning divides large tables into smaller, manageable segments—commonly by date or region. This reduces the amount of scanned data, lowering both query time and cost. Clustering can further improve performance by ordering within partitions.
What is Apache Airflow, and why is it popular for orchestration?
Airflow is an open-source orchestration tool that defines workflows as Directed Acyclic Graphs (DAGs). It is popular because of its flexibility, strong community, and ability to schedule and monitor complex pipelines. Airflow also integrates easily with cloud services and data platforms.
How does DBT fit into the modern data stack?
dbt focuses on the transformation layer in ELT workflows, using SQL-based models to define transformations directly in warehouses. It brings software engineering practices like version control, testing, and documentation to analytics. DBT simplifies collaboration between data engineers and analysts.
What are the main differences between Kafka and cloud-native messaging services like AWS Kinesis or GCP Pub/Sub?
Kafka provides more control, fine-grained configuration, and strong guarantees like exactly-once semantics. Cloud-native services are managed, scale automatically, and reduce operational overhead. The choice depends on whether you prioritize flexibility and control (Kafka) or ease of use and integration (Kinesis, Pub/Sub).
How do you secure sensitive data in cloud-based data pipelines?
Security involves encrypting data at rest and in transit, applying IAM roles and least privilege access, and using VPC or private endpoints. Services like AWS KMS or GCP Cloud KMS manage encryption keys. Regular auditing and monitoring help maintain compliance.
What are some cost optimization strategies in cloud data warehouses?
Strategies include partitioning and clustering to minimize scanned data, using compressed columnar formats, pruning unused tables, and scheduling workloads during off-peak times. Serverless query engines like Athena or BigQuery can further reduce costs by charging only for data scanned.
Can you describe a project where you used cloud services to build an end-to-end data platform?
An example is building a pipeline on AWS where S3 stored raw data, Glue transformed it, Redshift served as the warehouse, and QuickSight powered dashboards. The system used Lambda for lightweight compute and Kinesis for real-time ingestion. This design delivered both batch and streaming insights with cost efficiency.
System Design Case Studies (Whiteboard-style)
System design is one of the most challenging parts of the data engineering interview. Unlike straightforward coding problems, data engineer system design interview questions test how you architect pipelines, balance tradeoffs, and meet real-world business requirements. These scenario based interview questions for data engineers often require you to sketch architectures on a whiteboard, explain your reasoning, and defend choices around scalability, reliability, cost, and observability.
The following case studies illustrate common scenarios of real-time analytics, event-driven ETL, and cost-aware BI showing how to structure your answer, highlight tradeoffs, and think like an engineer solving real production problems.
Real-Time Clickstream Analytics: From ingestion to serving (batch + streaming lambda vs lakehouse)
Building a real-time clickstream analytics system involves designing an end-to-end data pipeline, from ingesting raw user events to serving actionable insights. The choice of architecture, particularly between the traditional Lambda model and the modern Lakehouse, significantly impacts the system’s complexity, performance, and cost.
The pipeline: From ingestion to serving
| Stage | Description | Technologies / Tools |
|---|---|---|
| 1. Ingestion | Captures user interactions like clicks, page views, scrolls, and events as continuous data streams from websites, mobile apps, and IoT devices. | - Apache Kafka: Scalable, fault-tolerant event streaming - Amazon Kinesis Data Streams: Serverless streaming service - Google Cloud Pub/Sub |
| 2. Processing & Storage | Data is cleaned, enriched (e.g., with user metadata or geolocation), and aggregated for analytics. The refined data is stored for both real-time and historical analysis. | - Apache Spark, Flink, Beam for processing - Snowflake, BigQuery, Redshift, Data Lake (S3/GCS) for storage |
| 3. Serving | Serves processed data for applications like dashboards, machine learning, or batch reports. Can combine real-time and historical data for a unified view. | - Druid, ClickHouse, Presto, Trino - Caching layers like Redis for low-latency responses |
| 4. Visualization & Reporting | Business users interact with dashboards and reports to make data-driven decisions based on the clickstream analysis. | - Tableau, Looker, Power BI, Mode Analytics |
Architectural choice: Lambda vs. Lakehouse
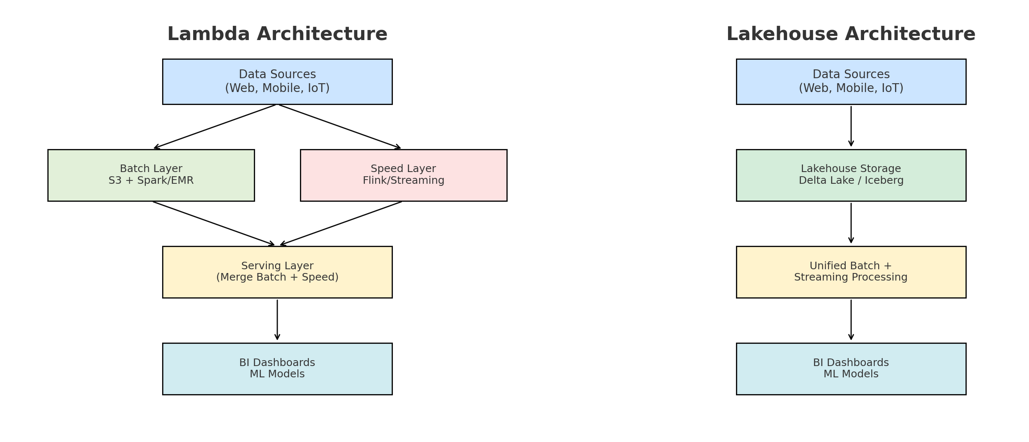
Architectural comparison: Lambda vs. Lakehouse
| Stage | Lambda Architecture | Lakehouse Architecture |
|---|---|---|
| Ingestion | Raw data is sent to both the batch and speed layers simultaneously. | Streaming data is ingested directly into the lakehouse in open table formats (e.g., Delta Lake, Apache Iceberg). |
| Processing | - Batch Layer: Periodic (e.g., nightly) batch jobs read from data lakes (e.g., S3) and run accurate aggregations. - Speed Layer: Processes streams in real-time for quick insights. |
Both batch and streaming jobs run on the same data table. Streaming handles real-time inserts, while batch jobs can run cleanups or heavy aggregations. |
| Serving | Combines results from both layers: - Batch for high accuracy and completeness. - Speed for low-latency, fresh insights. |
BI tools connect directly to the lakehouse, accessing unified tables for both real-time and historical analytics — no need to merge separate results. |
| Pros | - High accuracy from batch layer - Fast insights from speed layer |
- Simplified architecture - Unified source of truth - Fresh data through streaming on same table |
| Cons | - Complex to manage two pipelines - Requires separate codebases and infra for batch & streaming |
- Newer, less mature tooling - Possible vendor lock-in with specific formats (e.g., Delta Lake, Hudi) |
Conclusion
For real-time clickstream analytics, the choice between Lambda and Lakehouse boils down to trade-offs between simplicity and operational control.
- Choose Lambda if your organization has existing batch and streaming expertise and wants distinct, highly-tuned pipelines for maximum control over latency and accuracy.
- Choose a Lakehouse if you prioritize architectural simplicity, unified governance, and want to accelerate the time-to-insight for both real-time and historical analytics without the overhead of maintaining two separate systems. The Lakehouse model is increasingly becoming the modern standard for its streamlined approach.
Event-Driven ETL for a Marketplace: Idempotent upserts, schema evolution, SLOs, observability
An event-driven ETL for a marketplace must handle data from diverse sources reliably and scalably. The following is a blueprint for such a system, covering idempotent upsert logic, schema evolution, Service Level Objectives (SLOs), and end-to-end observability.
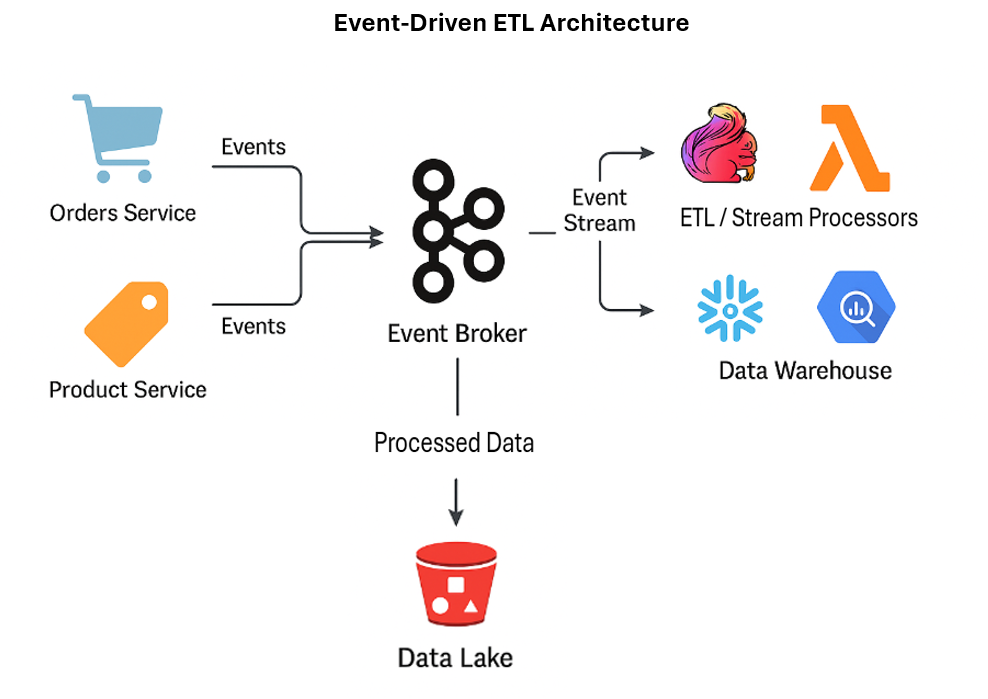
Architecture overview
A typical event-driven ETL for a marketplace involves several core components:
- Producers: The source systems that publish events, such as microservices for orders, users, and products.
- Event Broker: A central message queue that decouples producers and consumers, like Apache Kafka or AWS Kinesis.
- Consumers: Services that ingest events from the broker. This may include a stream processing engine like Apache Flink or a serverless function.
- Data Lake/Warehouse: The final destination for the processed data, such as a data lake (e.g., S3, ADLS) or a data warehouse (e.g., Snowflake, BigQuery).
Idempotent upsert
To prevent duplicate records from retries or multiple event deliveries, consumers must be designed to perform idempotent upserts (update-or-insert).
Implementation strategies
| Strategy | Description |
|---|---|
| Idempotency Keys | - Include a unique key in each event. Check cache or store before processing to avoid duplicate execution. - Store processed keys in a fast key-value store. Return cached result if key is found. |
| Upsert Logic | - Use MERGE/UPSERT with primary keys in warehouses. - Partition files by event ID in lakes for overwrite. |
Example workflow
- An
order_updatedevent is published withidempotency_key = "123-abc". - The ETL consumer receives the event, begins processing, and stores
"123-abc"in a cache as “in progress.” - Due to a network issue, the consumer retries.
- Before reprocessing, the consumer checks the cache, finds the “in progress” key, and discards the duplicate event.
Schema evolution
In a dynamic marketplace, event schemas will change over time. A robust system must handle schema evolution to prevent data pipelines from breaking.
Implementation strategies
| Strategy | Description |
|---|---|
| Schema Registry | Use centralized registry for schema versions and compatibility enforcement (e.g., Avro, Protobuf). |
| Compatibility Modes | - Backward: New consumers read old data - Forward: Old consumers ignore new fields - Full: Both directions |
| Breaking Changes | Use versioned topics (e.g., orders-v2) and migrate consumers incrementally. |
Example workflow
- The
product_createdevent schemav1is registered. - The marketplace team adds a new, optional
seller_infofield to the event schema, creatingv2. - The new schema is registered with a backward-compatible rule.
- The ETL consumer, still using the
v1schema, can successfully processv2events by ignoring the newseller_infofield.
Service Level Objectives (SLOs)
SLOs for an event-driven ETL define what constitutes an acceptable level of service. They are based on Service Level Indicators (SLIs), which are quantitative metrics.
| Service Level Indicator (SLI) | Definition |
|---|---|
| Latency | Time from event creation to availability in warehouse (track p95/p99). |
| Throughput | Number of events processed per time unit. |
| Correctness | % of valid events without schema/data quality issues. |
| Availability | % of time the ETL system is operational. |
| Sample SLOs | |
|---|---|
| Data Freshness | 99% of order_placed events available within 5 minutes. |
| Correctness | 99.9% of events pass validation. |
| Availability | Pipeline is up 99.9% of the time. |
Observability
Robust observability provides a deep understanding of the ETL pipeline’s internal state through metrics, logs, and traces.
| Observability Area | What to Monitor |
|---|---|
| Metrics | - Event broker delivery rates - Queue depth, consumer lag - ETL consumer errors, retries - Upsert query times |
| Logs | - Structured logs (JSON) with event ID, timestamps - Centralized in systems like ELK, Splunk |
| Traces | - Distributed tracing with tools like OpenTelemetry, Datadog - Use correlation IDs to trace across services |
| Dashboards/Alerts | - Set alerts on consumer lag, failure rates - Dashboards for pipeline health (metrics + logs + traces) |
Cost-Aware Warehouse for BI: Partitioning, clustering, pruning, caching layers
To build a cost-aware data warehouse for Business Intelligence (BI), you must combine different techniques to reduce the amount of data processed and optimize resource utilization. A multi-layered strategy using partitioning, clustering, pruning, and caching ensures fast query performance while controlling costs, especially in cloud-based data warehouses where pricing is often based on usage.
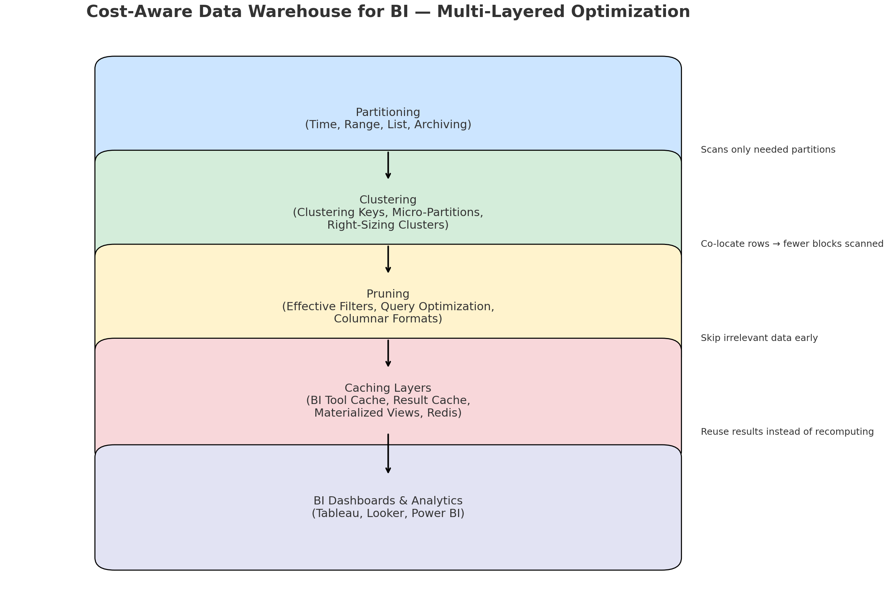
Partitioning
Partitioning divides large tables into smaller, more manageable parts based on specified criteria. This is particularly effective for time-series data or other large tables, as it allows queries to scan only the necessary subsets of data, dramatically reducing the amount of data processed.
| Strategy | Description | Benefit |
|---|---|---|
| Time-unit partitioning | Partition tables by timestamp, date, or datetime (e.g., daily or monthly) | Speeds up queries by reducing scan range |
| Range partitioning | Divide tables based on integer or key ranges | Optimizes queries filtering by value range |
| List partitioning | Partition tables based on specific values (e.g., country, region) | Improves query performance on known values |
| Archiving old data | Move older partitions to cheaper storage tiers automatically | Reduces storage costs |
Clustering
Clustering physically co-locates related data within the same or nearby storage blocks. Unlike partitioning, which creates distinct sections, clustering orders data within or across partitions to speed up access based on query patterns. For cloud warehouses that bill by data scanned, effective clustering is a powerful tool for cost optimization.
| Strategy | Description | Benefit |
|---|---|---|
| Clustering keys | Sort data based on columns frequently used in WHERE or JOIN clauses |
Enables query engine to skip irrelevant data blocks |
| Right-sizing clusters | Start with small compute clusters and scale up for high-volume jobs | Avoids over-provisioning and idle cost |
Pruning
Pruning is the process of eliminating irrelevant data from being read or processed during query execution. It is directly enabled by effective partitioning and clustering. By analyzing a query’s filter conditions, the query optimizer can “prune” or skip entire data blocks or partitions, saving significant compute costs and time.
| Strategy | Description | Benefit |
|---|---|---|
| Effective query filters | Use specific WHERE/JOIN clauses that match partition or cluster structure |
Reduces data scanned and improves speed |
| Avoid transformation filters | Avoid expressions like TRUNC(column) in WHERE clauses |
Helps query engine prune efficiently |
| Columnar data formats | Use formats like Parquet and ORC | Boosts pruning with column-level access |
Caching layers
Caching stores the results of frequently executed queries in a temporary, high-speed storage layer. This allows the system to return a cached result instantly for repeat requests, avoiding the need to re-scan large tables and re-execute complex logic. This is particularly valuable for BI dashboards that run the same reports repeatedly.
| Strategy | Description | Benefit |
|---|---|---|
| BI server caching | Configure caching in tools like Tableau, Looker | Reduces backend query loads |
| Warehouse result caching | Use cloud warehouse caching for repeated queries | Minimizes compute on repeated queries |
| Materialized views | Precompute results of complex queries | Speeds up repeat analytical workloads |
| External caching | Use Redis or similar tools for frequent, high-volume reads | Offers ultra-fast access for hot data |
Reliability, Data Quality, and Observability
Modern data engineering is about making sure that data is reliable, accurate, and observable at scale. In interviews, expect data quality interview questions and data observability interview questions that test whether you can guarantee trusted data pipelines. Topics include testing with tools like Great Expectations or dbt, anomaly detection, SLAs/SLOs, lineage, incident playbooks, and how to manage backfills and reconciliation when data goes wrong.
Great Expectations/dbt Tests, Anomaly Detection, SLAs/SLOs, Lineage, and Incident Playbooks
Data quality starts with automated testing and proactive monitoring. Tools like Great Expectations and dbt tests allow engineers to define expectations (e.g., no nulls, values within ranges, referential integrity) directly in the pipeline.
- Anomaly detection: Set up statistical or ML-based monitoring to flag unusual spikes, drops, or distribution shifts in critical metrics.
- SLAs/SLOs: Define guarantees such as “95% of data available by 9 AM daily” (SLA) or “p95 pipeline latency under 10 minutes” (SLO). These help align engineering work with business expectations.
- Data lineage: Track data from source → transformation → warehouse → dashboard. This makes debugging easier and builds trust with downstream users.
- Incident playbooks: Prepare runbooks for common failures (e.g., upstream API outage, schema drift). Interviewers often ask how you would triage, communicate, and resolve such incidents in production.
When answering these questions, show that you not only test data but also design for recovery. Teams value engineers who can spot issues early and restore pipelines fast.
How would you use dbt or Great Expectations to enforce data quality in a pipeline?
Data quality can be enforced with schema.yml tests in dbt or expectation suites in Great Expectations, checking for non-null primary keys, valid ranges, or referential integrity. These tests are integrated into the pipeline to block bad data before it reaches production.
What’s your approach to anomaly detection in data pipelines?
Anomaly detection combines rule-based checks (row counts, thresholds) with statistical monitoring (e.g., 3σ deviations). For mission-critical datasets, real-time alerts are set up in observability tools like Datadog or Prometheus to flag unexpected changes.
Can you explain the difference between SLAs and SLOs in data engineering?
An SLA is a business-facing promise such as “sales data will be ready by 9 AM,” while an SLO is an engineering metric like “p95 pipeline latency under 10 minutes.” SLAs manage stakeholder expectations, while SLOs drive internal monitoring and performance targets.
How do you ensure data lineage is visible across your systems?
Lineage is tracked through orchestration metadata (Airflow), transformation graphs (dbt), and catalog tools (DataHub, Collibra). This makes it clear where data originates, how it is transformed, and where it is consumed, supporting debugging and trust.
What steps do you include in a data incident playbook?
A playbook includes detection via monitoring, scoping impact, stakeholder communication, pausing downstream jobs if necessary, resolving the root cause, and documenting the incident for postmortems. This ensures quick recovery and knowledge sharing.
Backfills, Reprocessing, and Reconciliation Strategies
Even the best pipelines need reprocessing when data arrives late, upstream systems fail, or business rules change. Handling this gracefully is a core reliability skill.
- Backfills: Use idempotent processing so rerunning jobs won’t duplicate data. Partitioned tables (daily/hourly) make it easier to reprocess specific time ranges.
- Reprocessing: Design workflows that can safely replay events (e.g., with Kafka offsets) or reload from raw data stored in S3/GCS.
- Reconciliation: Compare source-of-truth counts vs warehouse counts to catch gaps or duplicates. Automated reconciliation scripts are common in finance and compliance-heavy industries.
When asked about backfills or reconciliation, walk through both the technical solution (partition overwrite, idempotent upserts, validation queries) and the operational process (alerting, stakeholder communication, preventing cost blowups).
How do you safely run a backfill on partitioned data?
Backfills are run idempotently on partitioned tables, typically by overwriting or merging data for specific time windows. Using SQL
MERGEoperations in warehouses like BigQuery or Snowflake prevents duplication, while staging environments validate changes before production.What’s your strategy for reprocessing when late-arriving data shows up?
Late-arriving data is handled by replaying from raw immutable logs stored in a data lake (S3/GCS). For streaming, replay is achieved with Kafka offsets or dead-letter queues. Incremental models in DBT or Spark pipelines reduce the need for full reloads.
How do you reconcile differences between source and warehouse data?
Reconciliation starts with counts by partition, followed by aggregate comparisons for key metrics. Discrepancies are investigated with join-based comparisons. Automated reconciliation tests in dbt or SQL scripts are used in compliance-heavy pipelines.
What challenges do you consider when backfilling large historical datasets?
Challenges include the cost of scanning terabytes of data, schema drift over time, and downstream load. These are addressed by chunking backfills, validating schemas, and scheduling work during off-peak hours to avoid business disruption.
How would you handle a failed reprocessing job in production?
Failures are triaged by checking logs for schema mismatches, timeouts, or resource limits. Retries are run in smaller batches or with scaled compute resources. If data must continue flowing, impacted partitions are flagged as “dirty” until resolved, while stakeholders are kept informed.
Behavioral & Cross-Functional Questions
Data engineering interviews test how you communicate, collaborate, and lead under pressure. Companies want to know if you can explain tradeoffs to non-technical stakeholders, handle production incidents responsibly, and manage priorities when deadlines are tight. Expect a mix of behavioral interview questions where data engineer candidates often face, framed around real-world scenarios that reveal problem-solving style, ownership, and communication skills.
Read more: Data Analyst Behavioral Interview Questions & Answers (STAR Method Guide)
Production Incident Story Using STAR-IR (Incident Response)
One of the most common behavioral prompts is to describe how you handled a production issue. Interviewers expect a STAR-IR framework:
- Situation: Context of the incident.
- Task: Your role and responsibility.
- Action: Steps taken to diagnose and resolve the issue.
- Result: Outcome and business impact.
- Incident Response: Lessons learned, monitoring added, and prevention strategies.
This framework demonstrates not just technical resolution skills but also accountability and ability to improve systems after failure.
Persuasion and Tradeoff Communication with Non-Technical Stakeholders
Data engineers often need to explain why a certain design is chosen, why a pipeline will take longer than expected, or why costs need to be balanced against speed. Interviewers look for examples of how you translate technical tradeoffs into business terms.
- Explain tradeoffs in terms of business impact (cost, reliability, user experience).
- Use analogies or simplified explanations for stakeholders without technical backgrounds.
- Highlight collaboration based on how you gained alignment rather than pushing a purely technical agenda.
Ownership, Prioritization, and Deadlines
Interviewers want to know how you balance competing priorities. Behavioral interview questions here focus on how you take ownership, how you prioritize tasks when multiple deadlines compete, and how you communicate progress or risks. Strong answers highlight:
- Frameworks for prioritization (e.g., impact vs urgency matrix).
- How you balance quick wins with long-term fixes.
- Clear communication with teammates and stakeholders to set realistic expectations.
How would you answer when an Interviewer asks why you applied to their company?
When responding to why you want to work with a company, focus on aligning your career goals with the company’s mission and values. Highlight specific aspects of the company that appeal to you and demonstrate how your skills and experiences make you a good fit for the role.
You can explore the Interview Query dashboard that lets you practice real-world Data Engineering interview questions in a live environment. You can write, run codes, and submit answers while getting instant feedback, perfect for mastering Data Engineering problems across domains.
How would you convey insights and the methods you use to a non-technical audience?
To effectively convey insights to a non-technical audience, simplify the concepts by breaking them down into key components and using relatable analogies. Visual aids like charts or diagrams can enhance understanding, and encouraging questions ensures clarity and engagement.
What do you tell an interviewer when they ask you what your strengths and weaknesses are?
When asked about strengths and weaknesses in an interview, it’s important to be honest and self-aware. Highlight strengths that are relevant to the job and provide examples. For weaknesses, choose something you are actively working to improve and explain the steps you are taking to address it.
How would you describe your communication style?
To effectively describe your communication style, start by identifying key traits, such as assertiveness or adaptability. Use a specific example to illustrate your approach, like leading a project where you engaged stakeholders to understand their needs. Highlight how you addressed challenges, such as resource constraints, by communicating openly with the project manager, ultimately leading to a successful outcome. This demonstrates your proactive and collaborative communication style.
Hint: The most crucial part of your answer is how you resolved the dispute.
Please provide an example of a goal you did not meet and how you handled it.
This scenario is a variation of the failure question. With this question, a framework like STAR can help you describe the situation, the task, your actions, and the results. Remember: Your answer should provide clear insights into your resilience.
How do you handle meeting a tight deadline?
To handle tight deadlines, start by gathering input from stakeholders to understand priorities. Develop a clear project timeline with milestones to track progress effectively. Delegate tasks based on team strengths to optimize efficiency. Regularly communicate updates to stakeholders to manage expectations and address any issues promptly. This structured approach ensures that you stay organized and focused, ultimately meeting the deadline successfully.
Tell me about when you used data to influence a decision or solve a problem.
To recommend UI changes through user journey analysis, start by examining user event data to identify drop-off points and engagement levels. Analyze user flows to pinpoint friction areas, then segment users based on behavior. Use visualizations to present findings and suggest UI improvements that enhance user experience. Document insights for future reference and continuous improvement.
Talk about a time when you had to persuade someone.
This question addresses communication, but it also assesses cultural fit. The interviewer wants to know if you can collaborate and how you present your ideas to colleagues. Use an example in your response:
“In a previous role, I felt the baseline model we were using - a Naive Bayes recommender - wasn’t providing precise enough search results to users. I felt that we could obtain better results with an elastic search model. I presented my idea and an A/B testing strategy to persuade the team to test the idea. After the A/B test, the elastic search model outperformed the Naive Bayes recommender.”
What data engineering projects have you also worked on? Which was most rewarding?
When discussing data engineering projects, start by clearly outlining the problem you aimed to solve. Summarize your approach, detailing the tools and methodologies used. Highlight the steps taken during the project, including any challenges faced and how you overcame them. Conclude with the results achieved and key learnings, emphasizing what you would do differently in future projects to improve outcomes.
With weaknesses, interviewers want to know that you can recognize your limits and develop effective strategies to manage the flaws that affect your performance and the business.
Describe a data engineering problem you have faced. What were some challenges?
When discussing a data engineering problem, start by clearly outlining the situation, such as data inconsistency or integration issues. Highlight specific tactics, like implementing data validation rules or using automated scripts for data cleaning. Describe the actions taken, such as collaborating with team members or utilizing specific tools. Finally, emphasize the results achieved, like improved data accuracy or streamlined processes, showcasing your problem-solving and communication skills.
Talk about a time you noticed a discrepancy in company data or an inefficiency in the data processing. What did you do?
Your response might demonstrate your experience level, that you take the initiative, and that you have a problem-solving approach. This question is your chance to show the unique skills and creative solutions you bring to the table.
Don’t have this type of experience? You can relate your experiences to coursework or projects. Or you can talk hypothetically about your knowledge of data governance and how you would apply that in the role.
In the interview, you are to develop a new product. Where would you begin? When asked about developing a new product, start by emphasizing the importance of understanding user needs and market trends. Conduct thorough research on the company’s existing products and business model to identify gaps or opportunities. Collaborate with cross-functional teams to gather insights and brainstorm ideas. Prioritize features based on user feedback and feasibility, ensuring alignment with the company’s goals. Document your process to facilitate future iterations and improvements.
How do you prioritize multiple data engineering tasks with conflicting deadlines?
Prioritization is done by weighing business impact and urgency. High-value, business-critical tasks are addressed first, while lower-priority work is scheduled around them. Frameworks like the impact-urgency matrix or input from stakeholders help align priorities. Clear communication ensures expectations are managed across teams.
Can you describe a time you had to take ownership of a failing data pipeline?
Ownership involves first identifying the root cause, such as schema drift or infrastructure limits, and then leading the resolution process. Actions may include coordinating with upstream teams, rerunning backfills, or deploying fixes. Documenting the issue and implementing preventive monitoring demonstrate long-term accountability.
How do you explain technical tradeoffs, like speed vs. cost, to non-technical stakeholders?
Tradeoffs are framed in terms of business outcomes. For example, choosing larger clusters may deliver data faster but increase cloud costs, while smaller clusters save money but slow reporting. Using analogies, cost estimates, and user impact helps stakeholders make informed decisions and builds alignment across teams.
Tool-Specific Question Banks (Skimmable)
Different companies use different ecosystems, so interviewers often ask tool-specific questions to gauge hands-on familiarity. This section highlights the most common platforms like AWS, Azure, GCP, Airflow, dbt, and Kafka with sample questions and answers. These aws/azure/gcp data engineer interview questions 2025 and airflow/dbt/kafka interview questions reflect what’s trending in current interviews.
AWS Data Engineer
AWS is one of the most widely used cloud ecosystems for data engineering. Candidates are expected to understand storage (S3), compute (Glue, EMR), query (Athena, Redshift), and orchestration (Step Functions).
What’s the difference between Redshift and Athena?
Redshift is a data warehouse optimized for structured, large-scale analytical queries. Athena is serverless and query-on-demand over S3 data using Presto. Redshift is better for frequent, heavy workloads; Athena suits ad-hoc analysis.
How do you design a data lake on AWS?
A common design uses S3 for raw storage, Glue for cataloging, EMR/Spark for processing, and Athena/Redshift Spectrum for querying. Partitioning and Parquet formats reduce costs and improve query speed.
How do you optimize AWS Glue jobs?
Optimizations include using pushdown predicates, partition pruning, efficient file formats (Parquet/ORC), and tuning worker node types. Job bookmarking ensures incremental loads instead of full scans.
What’s the role of Kinesis in AWS data pipelines?
Kinesis ingests streaming data for real-time analytics. It supports multiple consumers and integrates with Lambda, S3, and Redshift for processing and storage.
How do you secure data in AWS S3?
Best practices include enabling encryption (SSE-S3 or SSE-KMS), using bucket policies and IAM roles, enabling access logs, and enforcing VPC endpoints for private access.
Azure Data Engineer
Azure pipelines often combine Azure Data Factory (ADF), Synapse Analytics, and Databricks. Interviewers test knowledge of integration and cost control.
What is Azure Data Factory used for?
ADF is a managed orchestration tool for data ingestion and transformation. It connects diverse data sources and schedules pipelines with built-in monitoring.
How is Synapse different from Databricks?
Synapse is a data warehouse service focused on querying structured data. Databricks is a unified analytics platform for big data and machine learning, with strong Spark-based processing.
How do you optimize performance in Azure Synapse?
Optimizations include partitioning fact tables, using materialized views, leveraging result set caching, and scaling DWUs based on workload.
What’s a common use case for Azure Event Hubs?
Event Hubs is used for real-time data ingestion, such as telemetry, IoT events, or clickstream data, which can then be processed in Azure Stream Analytics or Databricks.
How do you manage costs in Azure Data Factory pipelines?
Strategies include minimizing pipeline activity runs, leveraging data flows only where needed, reusing linked services, and scheduling pipelines during off-peak hours.
GCP Data Engineer
Google Cloud’s stack emphasizes BigQuery, Dataflow, and Pub/Sub. Questions focus on scalability and serverless design.
What makes BigQuery different from traditional warehouses?
BigQuery is serverless and charges per query based on scanned bytes. It scales automatically and supports near real-time analytics without provisioning hardware.
How do you partition and cluster in BigQuery?
Partitioning is done by ingestion or timestamp columns; clustering orders data within partitions by keys like user_id or region, reducing scan costs.
What’s the role of Dataflow in pipelines?
Dataflow is a managed service for batch and stream processing, built on Apache Beam. It unifies streaming and batch workloads with autoscaling.
How do you handle schema evolution in BigQuery?
BigQuery supports adding new nullable columns without breaking queries. For breaking changes, versioned tables or views are recommended.
How do you optimize BigQuery query costs?
Strategies include using table partitioning, clustering, selective
SELECTstatements, avoidingSELECT *, and materialized views for common aggregations.
Airflow Orchestration
Airflow remains a standard for workflow orchestration in modern data engineering interviews.
What is an Airflow DAG?
A DAG (Directed Acyclic Graph) defines a workflow of tasks with dependencies, executed by Airflow’s scheduler.
How do you handle retries in Airflow?
Retries can be configured per task with parameters like
retriesandretry_delay. This allows failed tasks to be retried automatically.How do you monitor Airflow pipelines?
Monitoring is done via Airflow’s web UI, email/Slack alerts, and external integrations with Datadog or Prometheus.
What’s the difference between Sensors and Operators in Airflow?
Operators perform tasks (e.g., PythonOperator, BashOperator), while Sensors wait for a condition (e.g., file arrival, partition ready) before allowing downstream tasks to run.
How do you make Airflow DAGs idempotent?
Idempotency is achieved by designing tasks to rerun safely—for example, overwriting partitions instead of appending, or checking for existing outputs before running.
dbt Transformations
dbt has become the default transformation framework for SQL-first data teams.
What is dbt used for in data engineering?
dbt (data build tool) manages transformations in the warehouse using SQL and Jinja templates. It also automates testing and documentation.
How do you implement incremental models in dbt?
Incremental models use the
is_incremental()macro to load only new or updated rows. This reduces compute cost compared to full refresh.What’s the difference between ephemeral and materialized models in dbt?
Ephemeral models are inlined as CTEs, while materialized models create persistent tables/views in the warehouse. Materialization choices balance speed, cost, and reusability.
How do dbt tests work?
Tests are SQL queries that check conditions (e.g.,
not null,unique,accepted values). Failing rows are returned, allowing engineers to catch data issues early.How do you document dbt models?
Documentation is stored in
schema.ymlfiles and compiled into a dbt docs site, showing lineage graphs, descriptions, and test coverage.
Kafka & Streaming
Kafka is a key component in real-time data systems. Questions test knowledge of message delivery, partitions, and consumer groups.
What is a Kafka topic?
A Kafka topic is a log-structured stream where events are stored. Topics are partitioned for parallelism and replicated for fault tolerance.
How do Kafka consumer groups work?
Consumer groups coordinate multiple consumers so that each partition is consumed by exactly one consumer in the group, ensuring scalability.
What’s the difference between at-least-once and exactly-once delivery in Kafka?
At-least-once guarantees no data loss but may cause duplicates. Exactly-once ensures each message is processed once, using idempotent producers and transactional APIs.
How do you handle schema evolution with Kafka messages?
Schema evolution is managed with Schema Registry (Avro, Protobuf). Backward compatibility rules allow adding optional fields while avoiding breaking existing consumers.
What’s the role of Kafka Streams or ksqlDB?
Kafka Streams provides a Java API for real-time transformations directly on Kafka topics. ksqlDB offers a SQL-like interface for stream processing without writing code.
FAQs
Is SQL enough for a data engineer interview?
SQL is essential for data engineering interviews, but not sufficient on its own. Candidates are expected to also understand data modeling, system design, ETL/ELT concepts, cloud platforms, and Python or Scala for transformations. SQL interview questions for data engineers usually test joins, window functions, and performance tuning, but you’ll also face broader questions on pipelines and scalability.
What is asked in a data engineer system design round?
A data engineer system design round focuses on how you architect pipelines and storage systems at scale. Expect questions on:
- Designing batch vs streaming pipelines
- Choosing between a lakehouse vs warehouse
- Handling late data, retries, and idempotency
- Partitioning, clustering, and schema evolution
- Tradeoffs around cost, latency, and reliability
These are scenario-based interview questions where you sketch solutions and explain your tradeoff decisions.
ETL vs ELT: Which One Should You Use and Why?
Mention ETL (Extract-Transform-Load) when describing pipelines where transformations happen before loading into the warehouse, often for legacy systems or compliance-heavy environments. Mention ELT (Extract-Load-Transform) when working with modern cloud warehouses like Snowflake, BigQuery, or Redshift that handle transformations at scale after loading. In interviews, highlight that you understand both and can pick based on context.
Which language is best for data engineering: Python or Scala?
Both languages are valuable. Python is the default for most data engineers, thanks to libraries like Pandas, PySpark, and frameworks like Airflow. Scala is widely used in Spark-heavy environments for performance and type safety. The best answer is that you’re fluent in Python but can adapt to Scala if the organization requires high-performance Spark workloads.
How do I prepare for a data engineer interview in 2 weeks?
A two-week prep should focus on high-leverage topics:
- Drill SQL (joins, window functions, aggregations)
- Practice Python coding questions (generators, multiprocessing, data transformations)
- Review ETL vs ELT, orchestration, and data modeling basics
- Read 2–3 system design case studies (real-time pipelines, cost-aware warehouses)
- Practice 4–5 behavioral answers with the STAR framework
- Run through mock questions on the cloud platform listed in the job description (AWS, Azure, or GCP)
What projects help me stand out as an entry-level data engineer?
Entry-level candidates stand out with hands-on projects that mimic real pipelines. Examples include:
- A data lake + warehouse pipeline on AWS or GCP (S3 + Redshift or GCS + BigQuery).
- A streaming project using Kafka + Spark to process logs or clickstream data
- A DBT project with transformations, tests, and a documentation site
- Building a portfolio dashboard powered by Airflow or Dagster orchestration
Projects should show you can move from raw ingestion to clean, queryable data and document the tradeoffs you made.
What coding concepts are important for Data Engineering interviews at FAANG+ companies?
FAANG+ companies test strong coding fundamentals in Python, Java, or Scala, focusing on writing efficient, production-grade code. You should be comfortable with data structures: arrays, hash maps, heaps, linked lists; algorithms: sorting, searching, recursion, dynamic programming basics; Big O complexity: optimizing transformations and queries for scale; file handling & streaming: working with JSON, Parquet, and Kafka streams; SQL efficiency: optimizing joins and window functions.
What are the fundamental questions in a data engineering interview?
Most interviews begin with core questions that test your understanding of end-to-end pipelines. Common areas include:
- How data moves from ingestion → storage → transformation → consumption
- Difference between batch and streaming pipelines
- Designing data models (star, snowflake schemas)
- Partitioning, indexing, and query optimization
- Data quality checks, orchestration (Airflow, dbt), and error handling
Expect follow-ups that evaluate tradeoffs between scalability, latency, and cost.
What is the average Data Engineer salary in the USA?
According to recent market data, the average salary for a Data Engineer in the United States is around $133,000 per year. Entry-level roles: typically earn $90,000–$110,000; Mid-level engineers: average around $130,000–$150,000; Senior and staff-level engineers: can exceed $175,000–$210,000, especially in tech hubs or FAANG+ companies.
Compensation also varies by industry, with finance, cloud, and AI-driven firms paying at the higher end.
Resources and Next Steps
Becoming confident in data engineering interviews requires consistent practice across SQL, Python, ETL/ELT, cloud platforms, and system design. Here’s how to continue your prep:
- Follow a Data Engineering Learning Path that covers fundamentals of pipelines, batch vs. streaming, and modern architectures like lakehouses.
- Get role specific interview prep tips at the How to Prepare for a Data Engineer Interview Guide
- Drill case study questions with the Data Engineer Case Study Interview Questions + Guide
Practice Next
Ready to nail your next Data Engineering interview? Start with our Data Engineer Question Bank to practice real-world scenario questions used in top interviews, questions. Sign up for Interview Query to test yourself with Mock Interviews today.
If you want to explore company-specific hubs, browse our tailored hubs for top companies like Meta, Google, Microsoft, and Amazon. Pair with our AI Interview Tool to sharpen your storytelling.
Need 1:1 guidance on your interview strategy? Explore Interview Query’s Coaching Program that pairs you with mentors to refine your prep and build confidence.