
Top 47 ETL Interview Questions & Answers (2025)


Introduction
With a projected growth of $5.76 billion in 2025, Extract, Transform, and Load (ETL) processes are the backbone of efficient data management and analytics. ETL transforms raw information into valuable insights when integrating data from multiple sources, ensuring data quality and optimizing performance.
ETL interviews assess your ability to design, implement, and debug data pipelines without turning them into spaghetti code. Expect questions on ETL testing, SQL wizardry, Python scripting (because everything comes back to Python), and system design.
You’ll also need to flex your problem-solving abilities and communicate clearly in these interviews.
Our most common ETL interview questions and answers will help you prepare for it by exploring key concepts, practical scenarios, and coding challenges.
Typically, ETL interview questions can range in difficulty and cover the following sections:
- Basic ETL Interview Questions: The questions at this level revolve around fundamental ETL concepts and definitions. Topics can include:
- ETL Terms And Other Basic ETL Questions
- ETL Data Sources
- ETL Design Approaches
- APIs with Python
- Intermediate ETL Interview Questions: Here, the questions typically pertain to scenarios that test the depth of your ETL knowledge. The topics often covered are:
- ETL Testing and Troubleshooting Interview Questions
- OLAP Cubes and Structures
- SQL for ETL Questions
- Advanced ETL Interview Questions: These questions involve advanced case studies where you are asked to design ETL solutions for specific (and often complex) business uses. Key areas of focus include:
- Unconventional and Unstructured Data
- System Design
- Coding Challenges for ETL Interviews: These questions assess your ability to write efficient, scalable, and maintainable ETL code. Expect to encounter:
- Writing ETL Pipelines in Python
- Data Cleaning and Transformation Challenges
- Performance Optimization in ETL Jobs
- Handling Large-Scale Data Processing
Who Is Most Likely to Be Asked ETL Questions?
ETL interview questions extend beyond ETL developer interviews. The ETL process impacts numerous fields and subfields, making it essential knowledge for various data management and analytics roles. The following positions may encounter ETL-related questions during their interviews:
- Data Scientist
- Business Intelligence Analyst
- Data Analyst
- ETL Developer
- Python Developer
- SQL Database Administrator
- Data Engineer
What Do You Need to Know for ETL Interviews?
ETL interviews may consist of technical deep dives, problem-solving challenges, and system design discussions. To stand out, show that you understand ETL concepts and can apply them effectively in real-world scenarios. With automation, cloud-native tools, and real-time analytics shaping the future of ETL, staying ahead of the curve is key.
Here’s what you should be ready to showcase:
Core Skills & Concepts
Be able to explain the ETL process (including Reverse ETL) and design scalable, fault-tolerant pipelines using tools like Airflow, Spark, or Kafka. Know when to use batch vs. real-time processing and how to manage schema changes or deduplication.
SQL + Data Handling
Expect to write and optimize complex SQL queries (joins, window functions, CTEs). Show how you transform raw data—filtering, cleaning, aggregating—especially across formats like JSON, Parquet, and streaming sources.
Tools & Cloud Platforms
Be familiar with tools like Fivetran, AWS Glue, Informatica, or Azure Data Factory. Understand how they scale in cloud environments and connect to BI tools like Tableau or Power BI.
Emerging Trends
Stay current on AI-driven ETL—from automated data cleansing to anomaly detection and predictive scaling. These topics often come up in forward-looking interviews.
Basic ETL Interview Questions
1. What is ETL?
ETL is an integral part of data science and stands for Extract, Transform, and Load.
Extract refers to the process of gathering and aggregating data from one or more data sources.
After aggregation, you Transform (clean) the data using calculations and eliminations, techniques like null handling, interpolation, and normalization.
Finally, Load refers to storing the data in a data warehouse or dashboard for future use. Typically, ETL questions are a core part of data engineering interview questions.
2. What are some of the benefits of ETL in data science?
ETL (Extract, Transform, Load) offers several benefits. First, it allows for the consolidation of data from different sources into a unified format. Second, it simplifies the data landscape and provides a comprehensive information view, making it easier to analyze and derive insights.
Next, ETL transforms data. By structuring, cleaning, and standardizing raw data, ETL ensures consistency and quality. It also enhances the accuracy and reliability of subsequent analyses, reducing the risk of incorrect or misleading conclusions.
Moreover, ETL enables data scientists to process and manipulate large volumes of data efficiently. By automating the extraction, transformation, and loading processes, ETL tools streamline the workflow, saving time and effort.
Additionally, ETL aids data integration. By combining data from various sources, ETL facilitates the creation of comprehensive data sets that provide a more complete picture of the subject under investigation. It opens opportunities for deeper analysis and enables the discovery of hidden patterns or correlations that may not have been apparent when considering individual data sources in isolation.
Ultimately, ETL empowers data scientists to leverage organized and meaningful data to uncover patterns, make informed decisions, and drive data-driven strategies for organizations.
3. What ETL tools are you most familiar with?
Your specific tech stack adds to your appeal as an engineer. However, experience with different tools also matters. Share your experiences using specific tech tools, such as the challenges you faced learning or using it.
Start by researching the ETL tools the company already uses. If you are unsure of the companies’ tools or if they use proprietary in-house products, consider mastering SQL, a programming language of choice (preferably Python), ETL tools such as Informatica PowerCenter, and a business intelligence suite such as Power BI.
4. How can we differentiate ETL from ELT, and what use cases favor ETL?
When it comes to distinguishing between ETL (Extract-Transform-Load) and ELT (Extract-Load-Transform) processes, it’s important to note that they are not mutually exclusive. Many organizations adopt variations like ETLT, choosing the approach that proves to be more efficient or cost-effective for their specific needs.
The main differentiation lies in how raw data is loaded into data warehouses. ETL traditionally involves loading data onto a separate server for transformation. In contrast, ELT directly moves data onto the target system before performing transformations—essentially placing the load step before the transform step.
One advantage of ETL is its capability to handle certain transformations that cannot be performed within a warehouse. In contrast, ELT performs transformations inside the warehouse, necessitating the use of enhanced privacy safeguards and robust encryption measures.
5. What is a data warehouse?
The data warehouse is a culmination of the SSOT (Single Source of Truth) ideology, where an organization stores all of its data in the same place, primarily for convenience and comparability. Because businesses store their data in a single location, creating insights is more accessible, and one can make strategic business decisions faster. Decision makers are also not left wondering if there are separate/forgotten/hidden locations for the information they may wish to access. No more sudden discoveries of customers in a far-flung market, for example.
6. What is the difference between a data warehouse, a data lake, a data mart, and a database?
A data warehouse, a data lake, a data mart, and a database serve different purposes and use cases. A data warehouse is a structured repository of historical data from various sources designed for query and analysis. It’s the go-to place for deriving insights useful to strategic decision-making.
On the other hand, a data lake is a vast pool of raw data stored in its native format until needed. It’s a more flexible solution that can store all data types, making it perfect for big data and real-time analytics scenarios.
A data mart is a subset of a data warehouse tailored to meet the needs of a specific business unit or team. It’s more focused, making accessing relevant data quicker and easier.
Lastly, a database is a structured set of data. It’s the basic data storage building block, capable of handling transactions and operations in applications, but it’s not optimized for the complex queries and analytics data warehouses.
Here are some keywords you can use to distinguish these four formats easily:
| Storage Type | Keywords |
|---|---|
| Data Warehouse | Analytics, Read, Query |
| Data Lake | Raw, Big Data, Unstructured |
| Data Mart | Specific, Tailored, Subset |
| Database | Schema, CRUD, base |
7. What are the typical data sources used in an ETL process?
The crucial part of the ETL process is aggregating data from various places. Most ETL pipelines extract their data from the following sources:
- The most common data sources are databases, which can be relational (like MySQL, Oracle, or SQL Server) or non-relational (NoSQL databases like MongoDB or Cassandra). These databases often hold operational data such as sales, inventory, and customer information.
- Cloud storage platforms like AWS S3, Azure Blob Storage, or Google Cloud Storage are common solutions for unstructured data.
- Flat files like CSV, Excel, or XML files are also frequent data sources.
- Data from APIs are commonly used, especially when third-party data is needed, such as social media feeds, weather data, or geolocation data.
- A non-conventional method is web scraping, which extracts data from websites. However, web scraping is unreliable and has potential legal implications, making it risky to integrate and replicate.
- Finally, enterprise applications like CRM (Customer Relationship Management) or ERP (Enterprise Resource Planning) systems can typically house valuable business data.
So, the data sources for an ETL process are quite diverse, and the choice depends largely on the business requirements and the nature of the data being handled.
8. How do you approach ETL design?
This question is vague and requires some clarity since ETL design varies by the organization’s data needs. For example, Spotify holds over 80 million songs and has over 400 million users. Spotify’s ETL solutions must be built for efficiency and performance, whereas a startup might focus more on building for accuracy.
When you describe your design process, consider discussing:
- Gathering stakeholder needs.
- Analyzing data sources.
- Researching architecture and processes.
- Proposing a solution.
- Fine-tuning the solution based on feedback.
- Launching the solution and user onboarding.
9. How would you approach designing an ETL solution for a large amount of data, like in big data scenarios?
Designing ETL solutions for big data scenarios requires careful strategizing, as the sheer volume, variety, and velocity of data can easily overwhelm traditional ETL frameworks. For instance, consider the work Google faces while crawling and indexing billions of web pages daily – tasks that require a massively scaled and highly robust ETL infrastructure.
When plotting out your strategy, there are some key stages you should go through, such as:
- Understanding the business requirements: Define what data needs to be extracted and what level of transformation is necessary.
- Scoping out the data landscape: With big data, you could be dealing with a mix of structured and unstructured data across various sources, such as logs, social media feeds, or IoT sensors. Understanding these data sources and their peculiarities will influence the ETL design.
- Choosing the right tools and architecture: Big data ETL often involves specialized tools, such as Hadoop and Spark, or cloud-based platforms like AWS Glue, Google Dataflow, etc. The choice of tool depends on factors like data volume, speed, processing capability, and cost.
- Designing the ETL processes: Big data ETL may need parallel processing, data partitioning, or incremental loading techniques to manage the data volume. Also, complex transformation logic may be required due to the variety of data.
- Iterating and optimizing based on feedback: After the initial design and implementation, you should continuously monitor the system for performance and accuracy, making improvements as needed.
10. How would you use Python to extract data from an API and load it into a Pandas DataFrame?
Let’s assume you’re tasked with pulling data from an open API for weather. You must extract this data, convert it to a Pandas DataFrame, and perform some basic data cleaning operations. How would you go about this task?
Python’s requests library is great for making HTTP requests to APIs. Once you have the data, you can use Pandas to convert it to a DataFrame for further processing. Here’s an example of how you could do it:
import requests
import pandas as pd
# make a GET request to the API
response = requests.get('http://api.open-weather.com/data/path')
# The data is usually in the response's JSON. Convert it to a DataFrame
data = response.json()
df = pd.DataFrame(data)
# perform some data-cleaning operations
# For example, we might remove missing values
df = df.dropna()
print(df)
This basic workflow can be extended or modified depending on the specifics of the data and the API.
11. How would you handle rate limiting while extracting data from APIs using Python requests?
Many APIs enforce rate limits in order to control the number of requests a client can make in a given time period. If your ETL process involves fetching data from such APIs, how would you ensure your script respects these rate limits?
API rate limiting can be managed by controlling the frequency of the requests in your script. A common way to do this is to introduce a delay between requests using Python’s time.sleep() function. Another way is to check the response headers, as some APIs return information about the rate limits
Note: This example presumes a simple form of rate limiting (e.g., a fixed number of requests per minute). Some APIs may use more complex forms, like progressively decreasing limits, and you’ll have to adjust your approach accordingly.
Intermediate ETL Interview Questions
These questions require more advanced knowledge of ETL and are typically in-depth, discussion-based questions. At this level of questioning, you might be presented with a scenario and asked to provide an ETL solution.
12. How do you process large CSV files in Pandas?
More context. Let’s say that you’re trying to run some data processing and cleaning on a .csv file that’s currently 100GB large. You realize it’s too big to store in memory, so you can’t clean the file using pandas.read_csv(). How would you get around this issue and still clean the data?
Two main methods to handle large datasets are streaming and chunking.
Streaming: The term streaming refers to reading the data in ‘stream’, i.e., only one line at a time. It allows Pandas to limit the memory use to the current line. You can do streaming with the following syntax:
with open('large_file.csv') as file: for line in file: # do somethingThe downside of this approach is that you can’t use many of Pandas’ powerful data processing functions, which operate on entire DataFrames. - Chunking: A more effective approach for utilizing Pandas’ capabilities on large datasets is to read the file in chunks. ? Note that a chunk represents a line in your CSV file. Pandas provides the
read_csv()function, which has the keyword argumentchunksizeto allow you to specify the size of the chunk.read_csv()returns an iterable, which you combine with aforloop to iterate through the chunks. Consider the following syntax:CHUNK_SIZE = 10000 # modify the chunk size as needed processed_data = [] chunks = pd.read_csv('very_large_csv.csv', chunksize=CHUNK_SIZE) # processes all the chunks for chunk in chunks: processed = process_data(chunk) processed_data.append(processed) # combine all the data into a singular df big_dataframe = pd.concat(chunks, axis=0)
13. What is ETL testing, and why is it important?
During the transformation stage, ETL testing identifies any potential bugs or data errors. It aims to ensure that these issues are addressed before the data reaches the data warehouse. Conducting ETL testing effectively mitigates risk factors such as double records and compromised data integrity. Most importantly, it helps prevent any loss or mishandling of data.
Without the implementation of ETL testing, incorrect data could potentially make its way into the data warehouse, leading to significant misinterpretations in subsequent analysis. This not only introduces bias into the analytical perspective of data analysts but also has the potential to result in ill-informed business decisions.
It is essential to remember the fundamental business axiom of “Garbage In, Garbage Out,” which succinctly emphasizes how bad data can result in worse outputs. Inversely, good inputs will lead to better outputs.
14. What could be a bottleneck that can severely hamper data processing during the ETL process?
Knowing the limitations and weaknesses of ETL is critical to demonstrate in ETL interviews. It allows you to assess, find workarounds, or entirely avoid specific processes that may slow the production of relevant data.
For example, staging and transformation are extremely time-intensive. Moreover, if the sources are unconventional or structurally different, the transformation process might take a long time. Another bottleneck of ETL is hardware involvement (specifically, disk-based pipelines) during transformation and staging. The hardware limitations of physical disks can create slowdowns that no efficient algorithm can solve.
15. How would you validate data transformations during ETL testing?
Validating data transformations during ETL testing is pivotal to ensuring the integrity and accuracy of the data moving from the source system to the target data warehouse. It involves numerous checks and validations to ensure that the data has not been corrupted or altered in a way that could distort the results of data analysis.
A multi-step approach can help ensure accurate ETL testing:
1. Source-to-Target Count Check: This involves checking the record count in the source and then again in the target system after the ETL process. If the numbers don’t match, then there’s a high probability of data loss during the ETL process.
2. Data Integrity Check: Here, the tester confirms that the transformations didn’t compromise the data’s integrity. They need to understand the business rules governing these transformations, as data discrepancies can result from complex transformation logic.
3. Verification of Data Transformations: To validate the transformation rules, the tester would select a sample of data and trace its journey from the source to the destination system. They would manually calculate and compare the expected transformation results to the actual results.
4. Check for Data Duplication: Duplicate entries can affect the accuracy of analyses, so testers should include a check for duplicate data in their testing strategy.
5. Performance Testing: Finally, evaluating the performance of the ETL process is crucial. It needs to run in a reasonable time and without straining the system’s resources. Therefore, ETL testing should include performance and load testing.
16. You have a table with a company payroll schema. Due to an ETL error, an INSERT was used instead of updating salaries in the ‘employees’ table. Find the current salary of each employee.
SQL is closely related to ETL work and is widely used in ETL design and development. SQL questions are asked regularly in ETL interviews, assessing your ability to write clean SQL queries based on given parameters.
Hint. The first step we need to do is to remove duplicates and retain the current salary for each user. The interviewer lets you know that there are no duplicate first and last name combinations. We can, therefore, remove duplicates from the employees table by running a GROUP BY on two fields, the first and last name. This allows us to then get a unique combinational value between the two fields.
This is great, but we are stuck trying to find the user’s most recent salary. Without a DateTime column, how can we tell which was the most recent salary?
The interviewer tells you that “instead of updating the salaries every year when making compensation adjustments, they did an insert instead.” This means that the current salary could be evaluated by looking at the most recent row inserted into the table.
We can assume that an insert will auto-increment the ID field in the table, which means that the row we want to use would be the maximum ID for the row for each given user.
SELECT first_name, last_name, MAX(id) AS max_id
FROM employees
GROUP BY 1,2
Now that we have the corresponding maximum ID, we can rejoin it to the original table in a subquery in order to identify the correct salary associated with the ID in the subquery.
17. If your ETL fails, how should you address the problem?
ETL failures are common, and data engineers and data scientists must know how to handle them.
The first thing to do when checking for errors is to test whether one can duplicate the said error.
- Non-replicable - Fixing a non-replicable error can be challenging. Typically, these errors need to be observed occurring again, either through brute force or by analyzing the logic implemented in the schemas and the ETL processes, including the transformation modules.
- Replicable - If the error is replicable, run through the data and check if the data is delivered. After that, it is best to check for the source of the error. Debugging and checking for ETL errors is troublesome but worth performing in the long run.
Documenting errors can be integral to creating an efficient environment and repeatedly avoiding the same mistakes that mess up the pipeline. Document the error and your actions to inform people outside the development/engineering team.
18. Can you explain regression testing in ETL? Why is it important, and how would you conduct it?
Regression testing is critical to maintaining a data warehouse’s integrity. After any changes are made, regression testing is performed to ensure that no unintended issues arise due to these modifications. There are typically two types of changes you’ll see in a data warehouse:
- Database component changes: These are adjustments to the database’s elements or processes that modify their definitions.
- Code updates: These are alterations in the database modules, often implemented by ETL developers.
When creating regression tests, it’s important to consider the following:
- Did any table relationships or data source-to-target mappings change?
- Were there updates to the code or modifications to the modules?
- Were any modules redefined or data components adjusted?
- Did we add or remove any files or tables?
- Did we make any changes to ETL processes, and if so, what are those changes?
These questions will help guide your testing and ensure that the data warehouse is functioning as expected after the changes are implemented.
19. What are OLAP cubes?
OLAP, or Online Analytical Processing, is a data structure designed for fast, on-demand processing. For example, if one collates data spread over a decade (i.e., sales numbers of multiple products), it might take a lot of processing power to fully scour all those years.
Because of the heavy load required, real-time solutions and insights are almost impossible in large data sets. However, OLAP allows us to pre-process data, leading to speeding up processing times and narrowing the time gap.
20. When should we use (or not use) OLAP cubes?
The question of whether to embrace OLAP cubes versus exploring alternative approaches is no small matter. The answer hinges on your data’s specific characteristics and your situation’s unique demands. In the realm of large businesses, traditional databases often struggle to generate reports with the necessary speed to address critical business challenges.
OLAP presents a compelling solution by allowing for the pre-aggregation and pre-computation of data, enabling swift query responses. As such, a great use case of OLAP is when your business environment has structured analytics needs, such as in accounting and finance.
However, it’s important to consider potential hurdles when employing OLAP. Flexibility in data analysis can pose challenges, as modifications to OLAP cubes typically require IT involvement, potentially slowing down progress. Moreover, constructing an OLAP structure that effectively satisfies analytics needs can be complex in business environments where data requirements are less clearly defined.
In a business environment that needs real-time data, OLAP is simply not the answer. While it can produce speedy queries, the data is certainly not produced in real time.
21. You are running an SQL query that is taking a long time. How would you know if it is taking an overlong time? What would you do to debug the issue and improve efficiency?
You might start with some clarifying questions about the table size and composition of the dataset. A simple process you could use would be to:
- Use the EXPLAIN statement to understand the query processes.
- See if the table is partitioned.
- Use filters or indexing to query only the necessary data.
- Use CTE instead of sub-queries.
22. Write an ETL SQL query that records the song count by date for each user in a music streaming database every day.
For this problem, we use the INSERT INTO statement to add rows to the lifetime_plays table. If we set this query to run daily, it becomes a daily ETL process. We would also want to make sure that:
- The rows we add are sourced from the subquery that selects the
created_at date,user_id,song_id, and counts the columns from thesong_playstable for the current date. - We use
GROUP BYbecause we want to have a separate count for every unique date,user_idandsong_idcombination.
23. When querying data from an SQL database for an ETL process, you notice that the entire result set is larger than your computer’s memory. How will you solve this problem?
When working with Big Data, it is common to encounter data sets larger than our machine’s memory. You might even be working with datasets that are double or triple your computer’s memory. The key here is to remember that we don’t have to pull all the data in one go, especially when there are robust tools designed to handle such scenarios. Enter the age-old solution: streaming.
When dealing with large datasets, it is better to use streaming to break them down into manageable pieces. Big Data frameworks like Hadoop and Spark can help streamline this process.
- Apache Hadoop: A well-known software framework for distributed storage and processing of large datasets. Hadoop’s HDFS (Hadoop Distributed File System) can store enormous amounts of data, and its MapReduce component can process such data in parallel.
- Apache Spark: A powerful big data processing and analytics tool. Spark excels in handling batch processing and stream processing, with Spark SQL allowing you to execute SQL queries on massive datasets.
- Apache Beam: Beam is a unified model for defining both batch and streaming data-parallel processing pipelines. It provides a portable API layer for building sophisticated data processing pipelines running on any execution engine.
- Apache Flink: Known for its speed and resilience, Flink is excellent for stream processing. It’s designed to run stateful computations over unbounded and bounded data streams.
Aside from these Big Data frameworks, you can still adopt the traditional approach of fetching and processing data in smaller batches. SQL query optimizations using LIMIT and OFFSET clauses can help you retrieve a portion of the records, allowing you to iterate through your data in manageable chunks instead of trying to load everything into memory all at once.
24. How would you design an ETL pipeline for a distributed database?
More context: You’ve been asked to create a report aggregating quarterly and regional sales data for a multinational company using SQL. The original data is stored across multiple databases housed with each country-level operations department. What would be your approach?
- Data Extraction: The extraction phase involves collecting data from various source databases. In this case, each regional database represents a data source. If the databases in use are SQL-based, direct SQL queries can be utilized to aggregate the data. But be aware that the combined result set may exceed your computer’s memory capacity.
Alternatively, consider leveraging data marts or Online Analytical Processing (OLAP) systems if they house the required data per region. This method is more efficient than resource-intensive processes such as streaming and using Big Data frameworks.
- Data Transformation: This stage encompasses cleaning and restructuring the data into a suitable format for reporting and analysis. Some specific transformations that may be required include data normalization, type conversions, null handling, and even aggregation.
- Data Loading: After transformation, the data is loaded into a centralized data warehouse. A typical choice for this is Amazon Redshift, given its capacity to store and query large volumes of data.
Furthermore, distributing the reports across several data marts can provide easy access for each region’s analytics team. The structure of these data marts can vary depending on specific business requirements. However, it’s critical to keep them in sync with the centralized data warehouse. This synchronization can be achieved by setting up data pipelines to update the data marts whenever new data is loaded into the warehouse, ensuring consistency across all platforms.
25. How would you handle rapidly growing SQL tables?
More context: Consider a SQL database where the table logging user activity grows very rapidly. Over time, the table becomes so large that it negatively impacts the performance of the queries. How would you handle this scenario in the context of ETL and data warehousing?
To handle rapidly growing SQL tables in the context of ETL and data warehousing, you can employ several strategies to improve performance. For example, partitioning is a technique that involves dividing the large table into smaller partitions based on a specified criterion. Another helpful strategy is indexing, which allows queries to run faster, reducing execution time.
Archiving, or purging, older data that is no longer actively used for reporting or analysis can also help manage the table size. Moving these older records to an archival database or storage system reduces the data processed during queries, improving performance.
Using summary tables, OLAP cubes, and data warehousing for analytics and reporting can help reduce query times. As a last resort, scaling up or scaling out the database infrastructure can accommodate the growing load. Scaling up involves upgrading hardware resources, while scaling out involves distributing the load across multiple servers or utilizing sharding techniques.
26. What kind of end-to-end architecture would you design for an e-commerce company (both for ETL and reporting)?
Let’s say you work for an e-commerce company. Vendors can send products to the company’s warehouse to be listed on the website. Users can order any in-stock products and submit returns for refunds if they’re unsatisfied.
The website’s front end includes a vendor portal that provides sales data at daily, weekly, monthly, quarterly, and yearly intervals.
The company wants to expand worldwide. They put you in charge of designing its end-to-end architecture, so you must know what significant factors you’ll need to consider. What clarifying questions would you ask?
What kind of end-to-end architecture would you design for this company (both for ETL and reporting)?
27. Write a query to get the number of players who played between 5 and 10 games (5 and 10 excluded) and the number of players who played 10 games or more.
You wish to categorize players into two groups based on the number of games they’ve played and then count the number of players in each category. The two categories are:
Players who have played more than 5 games and less than 10 games. Players who have played 10 or more games.
To help conceptualize a solution, imagine you have a bucket of apples and oranges. You want to know how many apples there are and how many oranges. You review each fruit individually and place a tally mark for each type. At the end, you count the tally marks.
Let’s do the same thing for bucketing the players. We will review each player individually, check the number of games they’ve played, and then place them in one of the two categories. Finally, we count the number of players in each category.
We combine two aggregate functions to solve this problem. They are SUM(), conjoined with CASE statements. Using these two clauses in conjunction with each other allows us to do a conditional check with the CASE statement and decide what value to return for that row. Then, the SUM() function will count up everything that the CASE statement returns.
SELECT SUM(CASE
WHEN games_played > 5
AND games_played < 10 THEN 1
ELSE 0
END) AS players_more_than_5_to_10_games,
SUM(CASE
WHEN games_played >= 10 THEN 1
ELSE 0
END) AS players_10_plus_games
FROM players
More ETL Interview Resources
ETL interview questions are a commonly tested subject in addition to understanding of common definitions and scenario-based questions for ETL. You should also practice various data engineer SQL questions to build your competency in writing SQL queries for ETL processes. For more SQL help, premium members also get access to our data science course, which features a full module on SQL interview prep.
If you want to learn from the pros, watch Interview Query’s mock interview with an Amazon Data Engineer, or check out our blog as well.
Advanced ETL Interview Questions
Hard ETL questions provide more challenging scenarios and relate to more complex data types, such as multimedia information. They are typically reserved for developers and engineers and assess the specialized knowledge needed for those roles.
28. How would you collect and aggregate data for multimedia information, specifically with unstructured data from videos?
Video data is difficult to aggregate, and the techniques used for video data differ greatly from text-based data. Three steps you might propose for working with video and multimedia data are:
- Primary metadata collection and indexing.
- User-generated content tagging.
- Binary-level collection.
The first level, primary metadata collection and indexing, refers to aggregating the video metadata and then indexing it.
The second level is user-generated content tagging. This is typically done manually but can be scaled with machine learning.
The last and most complex step is the binary-level collection. This process concerns analyzing and aggregating binary data (which often needs coding).
29. How do you manage pipelines involving a real-time dynamically changing schema and active data modifications?
Dynamically changing schemas can be troublesome and can create problems for an ETL developer. Changes in the schema, data, or transformation modules are also high-cost and high-risk, especially when dealing with massive databases or when the wrong approach is pursued.
How do you manage pipelines involving a changing schema and active data modifications? Such a question is relatively easy to phrase but is challenging to visualize correctly. It is helpful to visualize the problem with an example:
- You have two databases, one of which will handle raw data and be appropriately named
RAW. - The data in the
RAWdatabase needs to be transformed through some code, most often Python. This process can include cleaning, validating, and pushing the processed data into our second database, which we will nameOUT. OUTis the database designed to collate all processed data from RAW. Data fromOUTwill be prepared and transported to an SQL database.- The RAW database can undergo changes, including schema changes, such as changing values, attributes, and formats, and adding or reducing fields.
- Your problem is that you will need the
RAWandOUTdatabase to be consistent whenever a change occurs.
There are many ways to approach this problem, one of which is through CI/CD. CI/CD stands for continuous implementation and continuous development.
Knowing that changing or modifying anything in the RAW database can make or break a whole data ecosystem, it is imperative to use processes that come with many safety measures and are not too bold during implementation. CI/CD allows you to observe your changes and see how the changes in the RAW database affect the OUT database. Typically, small increments of code are pushed out into a build server, within which exist automated checking areas that scan the parameters and changes of the released code.
After the checks, the ETL developer will look at the feedback and sift through the test cases, evaluating whether the small increment succeeded or failed. This process allows you to check how the changes in the RAW database affect those in the OUT database. Because the changes are incremental, they will rarely be catastrophic if they do evade your checks and negatively impact the database, as they will be easily reversible.
Typically, after raw data goes through the transformation pipeline, metadata is left, which can include a hash of the source in RAW, the dates and times it was processed, and even the version of code you are using.
After that, use an orchestrator script that checks for new data added to the RAW database. The orchestrator script can also check for any modifications made to the RAW database, including additions and reductions. The script then gives a list of updates to the transformation pipeline, which processes the changes iteratively (remember: CI/CD).
30. Can you describe the process of designing an ETL pipeline for audio data?
Suppose you’re a data engineer at Spotify tasked with assisting the analytics team in creating reports. These reports aim to analyze the correlation between a song’s audio characteristics and the playtime of the curated playlists it features in. How would you approach constructing an ETL pipeline for this scenario?
Creating an ETL pipeline for processing audio data in a context such as Spotify requires a strategic approach:
- Extraction: The initial step entails gathering the relevant audio data. This information typically includes audio attributes such as tempo, key, loudness, and duration, along with other metadata like the artist’s name and album details. Spotify’s internal databases would be a primary source for this information, but depending on the requirement, we might also need to use APIs like the Spotify Web API to extract this data.
- Transformation: After extraction comes the transformation process, where we clean and structure the data for further analysis. This might involve removing any non-essential features, dealing with missing or null data, or restructuring the data into a format that’s compatible with our analytics tools. For instance, we might employ the Pandas library in Python for data cleaning and transformation, as it offers robust features for handling missing data and performing complex transformations. We could also use Apache Spark for more extensive datasets, given its ability to handle large-scale data processing tasks efficiently.
- Loading: The final stage involves loading the transformed data into a data warehouse. Here, we’re primarily concerned with making the data usable and accessible for the analytics team. For instance, we might use Google BigQuery or Amazon Redshift as our data warehouse solution. These platforms can handle large volumes of data and provide fast query results, which would benefit the analytics team when generating their reports. This stage should also include checks to ensure that the data has been loaded correctly and completely.
To ensure that this pipeline is reliable and can handle the constant influx of new data, we would design it to be robust, scalable, and automated. We might use tools like Apache Airflow for orchestrating these workflows, as it allows us to schedule and monitor workflows and ensure that the data pipeline is working as expected. To handle potential issues and troubleshoot effectively, efficient error handling and logging processes should be in place. Tools such as ELK (Elasticsearch, Logstash, Kibana) Stack could be useful for managing and monitoring logs.
31. How would you build an ETL pipeline for Stripe payment data?
More context. Let’s say that you’re in charge of getting payment data into your internal data warehouse.
How would you build an ETL pipeline to get Stripe payment data into the database so that analysts can build revenue dashboards and run analytics?
32. System Design ETL: International e-Commerce Warehouse
Context. Let’s say you work for an e-commerce company where vendors can send products to the company’s warehouse to be listed on the website. Users are able to order any in-stock products and submit refundable returns if they’re not satisfied.
The website’s front end includes a vendor portal that provides sales data at daily, weekly, monthly, quarterly, and yearly intervals.
The company wants to expand worldwide. You will be in charge of designing its end-to-end architecture, so you need to know what significant factors to consider before you start building. What clarifying questions would you ask?
What kind of end-to-end architecture would you design for this company (both for ETL and reporting)?
For questions 31-33, refer to the following case:
Digital Classroom System Design
You are a data engineer for Slack and are tasked to design their new product, “Slack for School”. When designing their database, you ponder upon the following questions:
33. What are the critical entities, and how would they interact?
The first step in designing a database is to identify the critical entities, i.e., the core building blocks for the eventual success of the product. Identifying critical entities in a database allows you to build features around them, and it will be these product features that teachers and students interact with.
For a product like “Slack for School”, we can identify the following entities:
- User: A user is the primary entity for handling both students and teachers. At its barest minimum, your user is assigned one relation and will have the following attributes:
Relations as a term can be used interchangeably with “tables”.
| attribute name | data type | constraints |
|---|---|---|
| UserID | BIGINT | PK, Auto Increment |
| FirstName | VARCHAR(256) | |
| LastName | VARCHAR(256) | |
| UserType | TINYINT |
When answering for an interview, always explain the thought process behind your choices. Let’s consider the following explanation of the User entity:
“While this looks like a standard user table, there are a few points of interest here. For example, we use BIGINT instead of INT to account for users above the two million mark (the max value for SQL’s INT).
In a service that’s built to handle several million users, we must design the product to scale up in the future.”
- For more comprehensive control around our users, we incorporate the inheritance technique. User is a super entity, while it has student and teacher as a sub-entity. This allows us to highlight the similarities and differences between the student and teacher entities.
- We can differentiate the two sub-entities through our
UserTypeattribute. We assign 1 for students and 2 for teachers. Because we used TINYINT for this field, it becomes relatively efficient in space, while also allowing for up to 256 user types (0-255).
Typically, we define inheritance in our ERD like this:
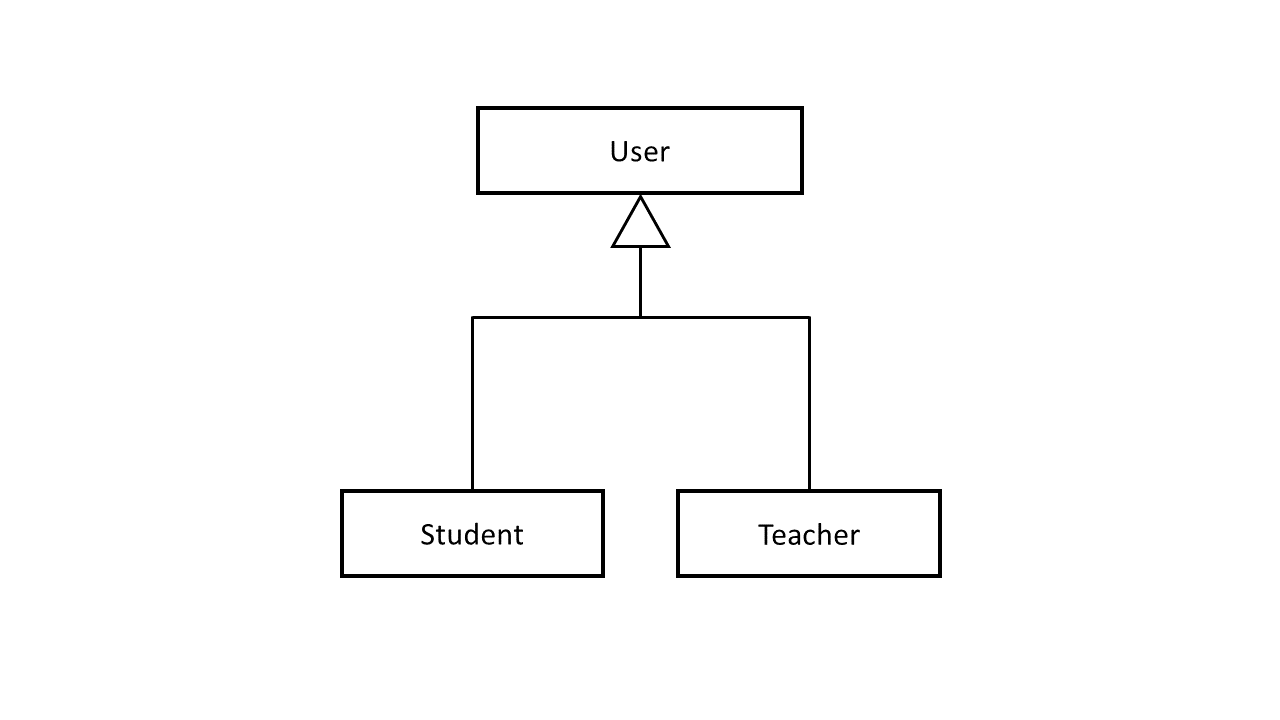
Other critical entities include:
- Course: This would represent the different courses offered in the product. Attributes could include Course ID, Course Name, Course Description, and Teacher User ID (foreign key referencing User).
- Enrollment: This entity would capture which students are enrolled in which courses. Attributes could include Enrollment ID, User ID (foreign key referencing User), Course ID (foreign key referencing Course), and Enrollment Date.
- Assignment: This entity would capture the required assignments within each course. Attributes could include Assignment ID, Course ID (foreign key referencing Course), Assignment Name, Assignment Description, and Due Date.
- Submission: This entity would capture each student’s assignment submissions. Attributes could include Submission ID, Assignment ID (foreign key referencing Assignment), User ID (foreign key referencing User), Submission Date, Submission File, and Grade Earned.
- Interaction: This would capture all the interactions users have with the app. Attributes could include Interaction ID, User ID (foreign key referencing User), Course ID (foreign key referencing Course, optional if the interaction is course-specific), Interaction Type (viewed assignment, submitted assignment, posted a message, etc.), and Interaction Date & Time.
When explaining these entities during an interview, follow a similar approach as with the User entity by providing insights into the design choices and their implications on product use.
34. Imagine we want to provide insights to teachers about students’ class participation. How would we design an ETL process to extract data about when and how often each student interacts with the app?
Extract
First, we would need to extract the data from the Interaction entity in our database. While we could theoretically assign a separate relation for each type of interaction, to maintain a simplified schema and reduce the need for multiple joins, we’ve decided to leverage a general ‘Interactions’ relation.
To define “participation”, we’ll focus on specific types of interactions, such as posting a message, submitting an assignment, or viewing course materials.
During the design process, it is important to acknowledge that as our service attracts an increasing number of users, the Interactions table, which has a one-to-many relationship per course, would benefit from the creation of an index.
Consider, for example, this index:
CREATE INDEX idx_interaction_course_id ON Interaction (Course_ID);
As our process might generate a substantial volume of queries (think in the thousands or even millions) to deliver these insights, ensuring our table is appropriately indexed can significantly enhance performance.
Transform
The extracted data might need some cleaning or reformatting to be useful. For example, we might want to calculate each student’s frequency of interaction by day, week, or month.
Additionally, we may want to categorize different types of interactions. This could mean a category of “communication” for message posts or “coursework” for assignment views and submissions.
Load
Finally, we would load this transformed data into a new analytics database table, which we will call ParticipationMetrics. Let’s consider the following schema:
| attribute name | data type | constraints |
|---|---|---|
| Interaction ID | INTEGER | PK |
| User ID (FK to Users) | INTEGER | FK |
| Course ID (FK to Courses) | INTEGER | FK |
| Date | DATE | |
| Interaction Category | VARCHAR(50) | |
| Interaction Count | INTEGER |
This table would provide a high-level view of participation for each student in each course, and could be queried easily to provide insights for teachers. A real-world example for this table would look like the following:
| User ID | Course ID | Date | Interaction Category | Interaction Count |
|---|---|---|---|---|
| 123 | Math101 | 2023-07-01 | Communication | 5 |
| 123 | Math101 | 2023-07-01 | Coursework | 2 |
| 456 | English101 | 2023-07-01 | Communication | 8 |
| 456 | English101 | 2023-07-01 | Coursework | 3 |
Note: The ParticipationMetrics table’s schema is not optimal. To ensure that your queries are performant and normalized, transfer the “Interaction Category” column to a separate table and have FKs that refer to each category instead.
35. Suppose a teacher wants to see the students’ assignment submission trends over the last six months. Write a SQL query to retrieve this data.
This SQL query assumes that we have a Submission table as described under critical entities above and that we are looking at the submission date to understand trends.
SELECT
User_ID,
Assignment_ID,
-- change to FORMAT or DATE_TRUNC depending on your SQL engine.
DATE_FORMAT(Submission_Date, '%Y-%m') AS Month,
COUNT(*) AS Number_of_Submissions
FROM
Submission
WHERE
Submission_Date >= CURDATE() - INTERVAL 6 MONTH
GROUP BY
User_ID,
Assignment_ID,
Month
ORDER BY
User_ID,
Assignment_ID,
Month;
This query would provide a count of the number of submissions for each student (User_ID), under each assignment (Assignment_ID), by month for the last six months. It should provide a strong overview of assignment submission trends. If you want more granular aggregations to observe trends in much greater detail, you can modify the DATE_FORMAT and the GROUP BY clause.
Note: Please replace the column and table names in the SQL query and the ETL process with your actual database schema.
36. How would you design a scalable streaming platform?
More context. You work for a video streaming company. Content creators can upload videos to the platform, and viewers can watch, like, share, and comment on the videos. Additionally, content creators can monitor their video performance metrics (views, likes, shares, comments, etc.) on a dashboard.
The company has become increasingly popular, and management is expecting a surge in its worldwide user base. To accommodate this growth, they have assigned you to design a scalable, resilient, and performant architecture.
What clarifying questions would you ask? What architectural approach would you propose for the platform, taking into consideration data ingestion, processing, storage, and content delivery?
Clarifying Questions:
- What kind of scale are we talking about? How many users and how much content do we expect to handle?
- Do we need to support live streaming, or are we only dealing with pre-recorded videos?
- What’s the average, median, and maximum size of the videos?
- What are the requirements for video encoding? Do we need to support multiple formats and resolutions?
- What are the requirements for content delivery? Should we have our own CDN or use a third-party provider?
- How quickly do the video performance metrics need to be updated and presented to content creators?
- What kind of analytics do we need to provide to content creators?
- Do we need to support different levels of access control for different types of users (e.g., admins, content creators, viewers)?
- What are the requirements for data durability, availability, and security?
- What are the expectations around system uptime, and what sort of disaster recovery plans should be in place?
Architectural Approach: The architecture would likely be a distributed system, incorporating various technologies for different requirements. It might include:
- A load balancer distributes incoming traffic evenly across multiple servers.
- Microservices architecture for different tasks such as video upload, encoding, delivery, and user interaction management.
- A scalable storage solution (like S3) to store the raw and encoded videos.
- A video encoding service to convert videos to various formats and resolutions.
- A Content Delivery Network (CDN) for efficient and fast video delivery to users worldwide.
- A Database (like Cassandra or DynamoDB) for storing user data and video metadata.
- A data processing system (like Spark or Hadoop) for calculating video performance metrics.
- A caching layer (like Redis or Memcached) for storing frequently accessed data and improving performance.
- A dashboard with real-time or near real-time updating capability for content creators to monitor their video performance.
- Robust security measures, including access controls, data encryption, and compliance with relevant regulations.
- An appropriate backup and recovery strategy to ensure data durability and availability.
- Comprehensive monitoring and alerting to detect and address issues quickly.
The architecture should be designed to handle high loads and scale smoothly as the user base and content volume grow. It should also be resilient to failures, ensuring high availability and a good user experience.
For questions 35 and 36, refer to the following case:
Streaming ETL Bank System Design
You are a data engineer for a large bank. The bank wants to develop a customer relationship management (CRM) system to streamline its operations and provide better services to its customers. You are tasked with drafting the database design and ETL processes for this CRM system.
37. How would you handle real-time updates to account balances in our database, considering thousands of transactions could be happening at any given moment?
To handle real-time updates with thousands of concurrent transactions, we’d need a combination of proper database design and a transactional system. For the database, we’d want to leverage ACID (Atomicity, Consistency, Isolation, Durability) compliant databases to ensure data integrity during these transactions.
For the transactional system, we could utilize something like Apache Kafka or Google Cloud Pub/Sub. These systems can handle high-volume, real-time data feeds and ensure that all transactions are processed in real-time. Also, consider partitioning and sharding strategies to distribute the load, enabling your system to handle a higher volume of concurrent transactions.
38. We’re developing a feature that alerts customers when their spending in a particular category (like dining out or groceries) exceeds a threshold. How would you design an ETL pipeline to support this feature?
In a real-time setup, the ETL process is often referred to as the “Streaming ETL” process. Here’s how it can be applied:
Extract
Data is extracted in real-time from the source, which is typically transactional data coming from an application. As each transaction is made, it is sent to a real-time data processing system such as Apache Kafka, Amazon Kinesis, or Google Cloud Pub/Sub.
Transform
This is where the real-time processing happens. Using stream processing technologies like Apache Flink, Apache Beam, or Spark Streaming, the incoming data stream is processed in real-time. For each incoming transaction, the system would:
- Identify the user and category for the transaction.
- Calculate the new total spending for that user and category by adding the transaction amount to the current total. This might involve retrieving the current total from a fast, distributed cache like Redis or a real-time database like Google Cloud Firestore.
At this stage, the system can also check if the new total exceeds the user’s threshold for that category.
Load
If the new total spending exceeds the threshold, the system would then load this event into a separate real-time alerting system. This might involve publishing a message to another Kafka topic, sending an event to a real-time analytics platform like Google Analytics for Firebase, or calling an API to trigger a push notification or email alert.
Meanwhile, the updated total spending is also loaded back into the cache or database, ready for the next transaction.
This kind of “streaming ETL” pipeline allows for real-time data transformation and alerting. However, it also requires careful engineering and tooling to ensure data consistency and accuracy and to handle large volumes of data efficiently.
Note: In a real-time setup, the “load” phase doesn’t necessarily involve loading data into a traditional, static database. Instead, it often involves sending data to other real-time systems or services or updating real-time stores of data.
For questions 37 and 38, refer to the following case:
Migrating from Regional Warehouses to a Global Data Lake
Your organization is a leading online retailer operating in over 30 countries worldwide. The company’s current relational databases are struggling to keep up with the exponential growth in data from various sources, including clickstream data, customer transaction data, inventory management data, social media feeds, and third-party data. To solve this, the company plans to migrate to a big data solution by creating a data lake and moving its data warehouse operations into a distributed database.
39. What considerations should be made when selecting a technology stack for building the data lake and the distributed data warehouse?
When choosing a technology stack for a data lake and distributed data warehouse, consider some factors, such as scalability to handle the growing data volume, which requires horizontal scaling capabilities. Secondly, the technology should be able to handle the wide variety of data typically found in a data lake, including structured, semi-structured, and unstructured data.
Additionally, consider data processing requirements (batch processing, real-time processing, or both), security compliance protocols to protect sensitive customer data, data cataloging, and quality tools for effective data management, and the total cost of ownership, including setup, maintenance, and scaling costs. Integration with existing systems and tools within the organization is also crucial for seamless operations. Lastly, a technology stack with a strong community and good vendor support can provide valuable resources and expertise for issue resolution and faster development.
40. How would you design the ETL process for the data lake and distributed data warehouse considering the scale and variety of data?
Designing the ETL process for a data lake and a distributed data warehouse at this scale requires careful planning. Here’s how it could be approached:
Extract
Given the variety of data sources, you would need different data extraction tools. Apache NiFi, for instance, can connect to many data sources and stream data in real-time.
Transform
Once the data is in the data lake, it can be transformed based on use cases. Some data might need to be cleaned, some aggregated, some joined, etc. Given the scale, distributed processing frameworks like Apache Spark would be useful for transformation. Tools like Apache Beam can handle both batch and stream data.
Load
Finally, the cleaned and transformed data needs to be loaded into the distributed data warehouse. If you choose a Hadoop-based ecosystem, you might use Apache Hive or Impala. If you go with a cloud solution like BigQuery or Redshift, they provide their own tools for data loading.
The data lake could also serve as a staging area before loading the data to the data warehouse. This way, raw data is always available and can be reprocessed if necessary.
Next, monitor the data since the scale can cause small issues, resulting in big data quality problems. Tools like Apache Airflow help manage and monitor the ETL workflows.
Remember, with such a scale of data, the traditional ETL may evolve into ELT (Extract, Load, Transform), where data is loaded into the system first and then transformed as required. This is because it’s often more scalable to use the distributed power of the data lake or warehouse to do the transformation.
Coding Challenges for ETL Interviews
41. Write a Python script to extract data from a CSV file, transform it, and load it into a database.
Challenge: Given a sales.csv file, write a script to:
- Extract data from the file
- Convert all
pricevalues from strings to floats - Load the cleaned data into an SQL table
Answer:
Use pandas to read and transform the data, then psycopg2 or SQLAlchemy to insert it into the database.
import pandas as pd
import psycopg2
# Extract
df = pd.read_csv("sales.csv")
# Transform
df["price"] = df["price"].astype(float)
# Load
conn = psycopg2.connect("dbname=mydb user=myuser password=mypass")
cursor = conn.cursor()
for _, row in df.iterrows():
cursor.execute("INSERT INTO sales (id, product, price) VALUES (%s, %s, %s)",
(row["id"], row["product"], row["price"]))
conn.commit()
cursor.close()
conn.close()
42. How would you handle large datasets efficiently in an ETL pipeline?
Challenge: You need to process a dataset with 100 million+ rows. What techniques would you use to make it efficient?
Answer:
- Use batch processing instead of inserting row by row.
- Utilize Apache Spark or Dask for parallel processing.
- Compress data formats (
Parquet,ORC) for efficiency. - Optimize SQL queries with indexes, partitions, and proper joins.
- Store and process data incrementally using change data capture (CDC).
43. Implement an ETL pipeline using Apache Airflow.
Challenge: Design an Airflow DAG to:
- Extract data from an API
- Transform it into a structured format
- Load it into a data warehouse
Answer:
Use Airflow’s PythonOperator and PostgresOperator:
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime
import requests
def extract_data():
response = requests.get("https://api.example.com/data")
data = response.json()
return data # Store in XCom
def transform_data(**kwargs):
ti = kwargs['ti']
raw_data = ti.xcom_pull(task_ids="extract")
transformed_data = [{"id": d["id"], "value": float(d["value"])} for d in raw_data]
ti.xcom_push(key="transformed_data", value=transformed_data)
def load_data(**kwargs):
ti = kwargs['ti']
data = ti.xcom_pull(task_ids="transform", key="transformed_data")
# Insert into database (example with psycopg2)
dag = DAG("etl_pipeline", schedule_interval="@daily", start_date=datetime(2024, 1, 1))
extract = PythonOperator(task_id="extract", python_callable=extract_data, dag=dag)
transform = PythonOperator(task_id="transform", python_callable=transform_data, dag=dag)
load = PythonOperator(task_id="load", python_callable=load_data, dag=dag)
extract >> transform >> load
44. How would you handle API rate limits while extracting data?
Challenge: An API allows 1000 requests per hour. How do you extract large datasets without exceeding limits?
Answer:
- Implement pagination (
limit&offsetparameters). - Use exponential backoff to handle retries.
- Store last processed timestamp/ID to resume if interrupted.
- Consider batch processing instead of frequent small requests.
Example using Python:
import time
import requests
url = "https://api.example.com/data"
headers = {"Authorization": "Bearer YOUR_TOKEN"}
params = {"limit": 100, "offset": 0}
while True:
response = requests.get(url, headers=headers, params=params)
if response.status_code == 429: # Rate limit hit
time.sleep(60) # Wait before retrying
elif response.status_code == 200:
data = response.json()
process_data(data)
params["offset"] += 100
if not data: # Stop when no more data
break
45. Write an SQL query to deduplicate a table while keeping the latest record.
Challenge: Given a users table with duplicate entries, keep only the latest updated_at record per user.
Answer:
Use window functions to rank records and filter only the latest ones.
WITH ranked_users AS (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY updated_at DESC) AS rnk
FROM users
)
DELETE FROM users WHERE user_id IN (
SELECT user_id FROM ranked_users WHERE rnk > 1
);
46. How would you detect and handle corrupted data in an ETL pipeline?
Challenge: Some records in your ETL pipeline contain missing values or incorrect formats. How do you manage them?
Answer:
- Validation rules (e.g., check for null values, enforce data types).
- Logging & alerting (flag bad records for review).
- Quarantine tables (store faulty records separately for debugging).
- Retry mechanisms (e.g., re-fetching data if incomplete).
- Fill missing data using default values or statistical imputation.
Example using Python:
import pandas as pd
df = pd.read_csv("data.csv")
# Drop rows with missing values
df_cleaned = df.dropna()
# Convert incorrect data types
df_cleaned["price"] = pd.to_numeric(df_cleaned["price"], errors="coerce")
# Handle outliers
df_cleaned = df_cleaned[df_cleaned["price"] < 10000] # Example threshold
47. How would you optimize ETL performance for high-volume data?
Challenge: Your ETL pipeline is running slowly. How do you improve performance?
Answer:
- Parallel processing (e.g., Spark, Dask, multi-threading in Python).
- Partitioning & indexing in databases.
- Columnar storage (Parquet, ORC) instead of row-based storage.
- Incremental loads instead of full refreshes.
- Optimize queries with proper joins, filters, and indexing.
Example: Using Apache Spark for parallel processing:
Key Takeaways from Interview Experiences
ETL interview questions are a commonly tested subject in addition to an understanding of common definitions and scenario-based questions for ETL. You should also practice various data engineer SQL questions to build your competency in writing SQL queries for ETL processes. For more SQL help, premium members also get access to our data science course, which features a full module on SQL interview prep. Candidates also find our AI Interviewer particularly useful when preparing for interviews.
If you want to learn from the pros, watch Interview Query’s mock interview with an Amazon Data Engineer, or check out our blog as well.