
Deloitte Machine Learning Engineer Interview Guide: Process, Questions & Prep


Introduction
A Deloitte machine learning engineer is rarely judged by model accuracy alone. In client environments, a strong model that cannot be deployed, monitored, or explained is often less valuable than a slightly weaker one that runs reliably in production. Industry benchmarks consistently show that well over half of machine learning initiatives fail to reach production, usually due to infrastructure gaps, unclear ownership, or misalignment between technical design and business needs. This reality shapes how Deloitte evaluates machine learning engineers.
The Deloitte machine learning engineer interview is therefore designed to test more than algorithmic knowledge. Interviewers assess whether you can translate ML ideas into production-ready systems, reason through MLOps and cloud constraints, and explain trade-offs to non-technical stakeholders. In this guide, we break down how the Deloitte machine learning engineer interview process works, what each stage is intended to evaluate, and how to prepare for the blend of coding, ML system design, and consulting-style discussions Deloitte expects.
Deloitte Machine Learning Engineer Interview Process
The Deloitte machine learning engineer interview process evaluates end-to-end ML delivery readiness, not just theoretical understanding. Rather than isolating model-building in a vacuum, Deloitte interviews focus on how candidates design, deploy, and maintain ML systems in real client environments shaped by data constraints, cloud architecture, and business trade-offs. The exact flow varies by service line and geography, but most candidates go through several rounds over a few weeks.
Many candidates prepare by practicing applied problems from machine learning interview questions and pressure-testing explanations through mock interviews that simulate consulting-style follow-ups.
Interview Process Overview
Candidates typically move through a resume screen, recruiter conversation, one or more technical interviews covering coding, ML fundamentals, and system design, and a final discussion with senior leaders. Compared with pure research or product ML roles, Deloitte places heavier emphasis on production readiness, explainability, and business impact.
Candidates often rehearse this progression using real-world challenges that require them to articulate assumptions, infrastructure choices, and trade-offs clearly.
| Interview stage | What happens |
|---|---|
| Resume screening | Evaluation of ML, cloud, and deployment experience |
| Recruiter or HR screen | Communication skills, motivation, and role alignment |
| Coding interview | Python fundamentals, data structures, and problem-solving |
| ML fundamentals interview | Core concepts such as bias–variance, metrics, and data issues |
| System design / MLOps round | Designing deployable ML systems on cloud platforms |
| Partner or director round | Judgment, communication maturity, and long-term fit |
Recruiter Or HR Screen
This initial conversation focuses on confirming fit for the Deloitte machine learning engineer role and assessing communication clarity. Interviewers look for evidence that you understand Deloitte’s consulting model and can articulate why production ML and client delivery appeal to you.
Many candidates refine this narrative through mock interviews to avoid sounding overly academic or tool-focused.
Tip: Be ready to explain why you enjoy turning models into deployed systems, not just experimenting with algorithms.
Coding And ML Fundamentals Interviews
Technical interviews typically include Python coding questions and conceptual ML discussions. Coding focuses on data manipulation, logic, and clarity rather than trick algorithms. ML fundamentals questions assess your understanding of bias–variance trade-offs, evaluation metrics, and common data issues like imbalance or leakage.
Practicing applied problems from machine learning interview questions helps candidates stay structured and decision-oriented.
Tip: When discussing ML concepts, tie them back to deployment or monitoring implications rather than treating them as abstract theory.
System Design And MLOps Interview
This round evaluates how you design production-grade ML systems. Interviewers may ask you to architect an end-to-end pipeline covering data ingestion, model training, deployment, monitoring, and retraining using cloud platforms such as Azure or AWS.
Working through system design interview questions helps candidates practice articulating infrastructure choices, failure modes, and trade-offs.
Tip: Explicitly discuss observability, rollback strategies, and ownership when models degrade.
Partner Or Director Round
The final round typically focuses on judgment, communication maturity, and long-term fit. Interviewers may revisit earlier projects or ask higher-level questions about how you balance innovation, risk, and client expectations when deploying AI systems.
Candidates often prepare for this stage by simulating executive-level conversations in mock interviews.
Tip: Show that you can think beyond models and understand how ML systems create sustainable business value.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Deloitte?
Deloitte Machine Learning Engineer Interview Questions
Deloitte machine learning engineer interview questions are designed to assess whether you can build models that survive production, not just notebooks. Interviewers evaluate how you reason through ML trade-offs, design scalable systems, and explain technical decisions in business terms. Questions typically fall into three categories: ML fundamentals and applied coding, ML system design and MLOps, and behavioral or consulting scenarios.
You can practice many of these patterns using machine learning interview questions and pressure-test your explanations through mock interviews.
ML Fundamentals And Applied Coding
These questions test whether you understand core ML concepts well enough to make deployment-ready decisions. Deloitte interviewers care less about academic proofs and more about how your choices affect generalization, monitoring, and downstream systems.
How would you explain the bias–variance trade-off when choosing a model?
This evaluates whether you can connect underfitting and overfitting to real business outcomes like unstable predictions or poor generalization in production. Interviewers look for explanations grounded in model selection and iteration, not textbook definitions.
Tip: Tie bias and variance to deployment risks such as retraining frequency or performance drift.
How would you combat overfitting when building tree-based models?
This question assesses your understanding of regularization techniques like depth constraints, pruning, and ensembling. Deloitte expects you to explain why you choose a technique based on data size, noise, and interpretability needs.
Tip: Mention how overfitting shows up in validation metrics and post-deployment monitoring.
Describe the difference between bagging and boosting algorithms.
Interviewers test whether you understand ensemble trade-offs, including variance reduction, bias reduction, and sensitivity to noise.
Tip: Explain when boosting may become risky in noisy or highly imbalanced enterprise datasets.
When should you use regularization versus cross-validation?
This evaluates whether you understand the difference between controlling model complexity and evaluating generalization. Deloitte looks for candidates who can integrate both into a disciplined training workflow.
Tip: Frame regularization as a training choice and cross-validation as a decision-validation tool.
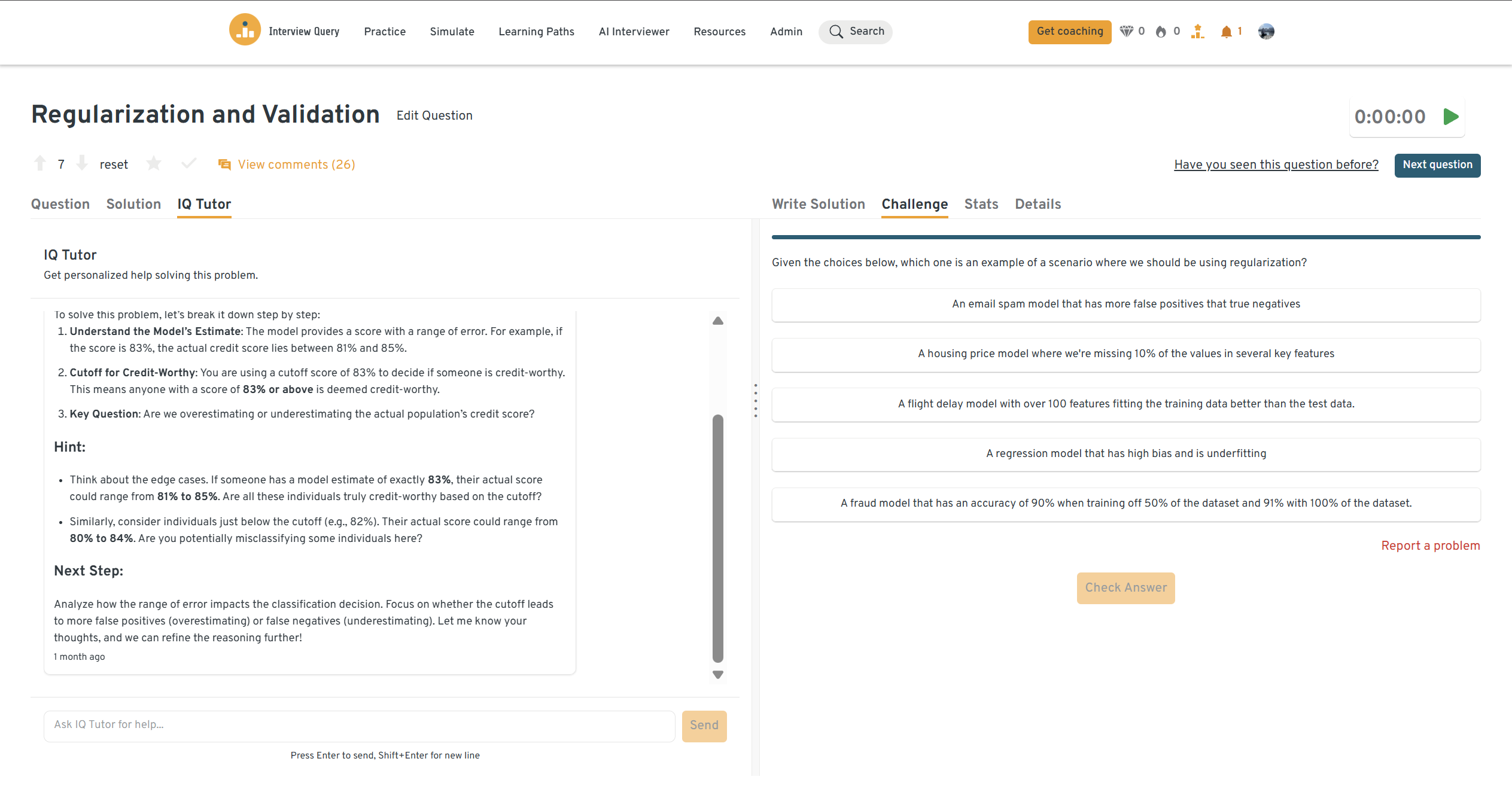
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
ML System Design And MLOps
These questions assess your ability to design end-to-end ML systems that are scalable, observable, and maintainable in cloud environments. Deloitte interviewers focus on practicality, failure modes, and ownership.
Designing a fraud detection system
This tests your ability to combine real-time inference, feature pipelines, and monitoring under strict latency constraints. Interviewers look for clear reasoning around false positives, retraining triggers, and system reliability.
Tip: Discuss how you would monitor model drift and handle delayed labels.
How would you automate model retraining?
This evaluates your understanding of MLOps workflows, including orchestration, validation, and deployment gates. Deloitte expects candidates to think beyond cron jobs and discuss data quality and rollback strategies.
Tip: Explain what metrics or signals would trigger retraining versus rollback.
What are the benefits of using containers in ML workflows?
This assesses whether you understand reproducibility, environment consistency, and deployment scalability. Containers are central to Deloitte’s production ML stack.
Tip: Connect containers to CI/CD pipelines and multi-environment deployments.
Design an ML system to predict outcomes from unstructured text data.
This tests your ability to integrate NLP models, preprocessing pipelines, and inference services into a production system.
Tip: Mention model versioning, inference latency, and monitoring for data drift.
To sharpen these skills, practice system design interview questions that reflect real enterprise ML constraints.
Behavioral And Consulting Scenarios
Behavioral questions assess whether you can deliver ML solutions in client-facing environments. Deloitte interviewers care deeply about communication, prioritization, and decision-making under ambiguity.
Tell me about a time you explained a complex ML concept to a non-technical stakeholder.
This evaluates your ability to translate technical complexity into decision-ready insight. Deloitte expects ML engineers to influence outcomes, not just present metrics.
Tip: Anchor your explanation around business impact rather than algorithms.
Sample answer: I explained a model’s performance using business scenarios instead of technical metrics, focusing on how prediction errors affected costs and risk. This helped stakeholders align on the trade-off and move forward confidently.
Give an example of a project with ambiguous goals or unclear data. How did you proceed?
This tests how you impose structure when requirements are incomplete. Deloitte values engineers who can move forward without perfect information.
Tip: Emphasize clarification, iteration, and validation.
Sample answer: I worked with stakeholders to define success metrics, explored the data to identify constraints, and delivered a phased solution that improved clarity while generating early value.
Describe a situation where you balanced model performance with business constraints.
This assesses judgment around trade-offs such as latency versus accuracy or interpretability versus complexity.
Tip: Clearly state why the business constraint mattered.
Sample answer: I chose a simpler model that met latency requirements, then validated that the accuracy loss was acceptable. This allowed the system to scale reliably while still delivering business value.
How do you prioritize multiple ML initiatives with limited resources?
Interviewers want to see structured prioritization tied to impact and feasibility.
Tip: Frame prioritization around value, risk, and delivery effort.
Sample answer: I ranked initiatives by expected impact and implementation complexity, aligned priorities with stakeholders, and focused resources on projects with the clearest path to production.
How To Prepare For A Deloitte Machine Learning Engineer Interview
Preparing for a Deloitte machine learning engineer interview requires a shift from pure model building to end-to-end ML delivery thinking. Deloitte evaluates whether you can move from problem framing to deployment, monitoring, and stakeholder communication in real client environments.
Practice ML Fundamentals With Production Context
Deloitte expects strong grounding in bias–variance trade-offs, evaluation metrics, and handling real-world data issues such as imbalance and leakage. However, interviewers look for candidates who can explain how these concepts influence deployment decisions and long-term model performance.
Tip: Practice applied questions from machine learning interview questions and explicitly connect theory to monitoring, retraining, or failure modes.
Strengthen Python And Data Handling Fluency
Coding interviews emphasize clean, readable Python for data manipulation and ML workflows rather than obscure algorithms. You should be comfortable reasoning about data transformations, edge cases, and performance trade-offs.
Tip: Solve Python-based problems while narrating your thinking out loud, and validate your approach using Interview Query challenges.
Prepare For ML System Design And MLOps Discussions
System design interviews test how you architect scalable ML systems using cloud platforms like Azure or AWS. Interviewers expect you to reason through data ingestion, training pipelines, deployment strategies, and monitoring.
Tip: Practice explaining full pipelines using system design interview questions and be explicit about rollback strategies and ownership.
Be Ready To Defend Your Resume Projects End To End
Deloitte interviewers frequently deep-dive into past ML projects. They expect you to explain not just what model you built, but why you made certain design choices and how the solution delivered business value.
Tip: Prepare one or two projects you can explain end to end, including trade-offs, limitations, and what you would improve next.
Develop Consulting-Style Communication For ML
Strong machine learning engineers at Deloitte can translate technical detail into business impact. Behavioral interviews test your ability to influence stakeholders, manage ambiguity, and balance competing priorities.
Tip: Practice structured responses to behavioral interview questions and pressure-test clarity through mock interviews.
Simulate Real Interview Conditions Before Interview Day
The fastest way to improve interview performance is realistic simulation. Timed coding, ML design walkthroughs, and behavioral drills reveal gaps that passive preparation does not.
Tip: Combine hands-on practice from Interview Query challenges with live mock interviews to mirror how Deloitte evaluates ML engineers holistically.
Role Overview: Deloitte Machine Learning Engineer
A Deloitte machine learning engineer focuses on turning machine learning ideas into reliable, production-grade systems that deliver measurable business value. The role sits between data science and software engineering, emphasizing deployment, scalability, and long-term operability over experimentation alone. Machine learning engineers at Deloitte work on client-facing engagements where models must integrate with existing systems, comply with security and governance requirements, and perform consistently under real-world constraints.
Rather than owning a single product indefinitely, Deloitte machine learning engineers operate across multiple projects and industries. Success depends on the ability to design end-to-end ML pipelines, collaborate with cross-functional teams, and explain technical decisions clearly to both technical and non-technical stakeholders.
Core Responsibilities
- Model development and deployment: Design, train, and deploy machine learning or GenAI models that can operate reliably in production environments.
- ML system architecture: Build end-to-end pipelines covering data ingestion, feature processing, training, inference, and monitoring.
- MLOps and automation: Implement CI/CD pipelines for ML workflows, manage model versioning, and automate retraining and validation.
- Cloud and infrastructure work: Deploy ML workloads on cloud platforms such as Azure or AWS, including containerized services and managed Kubernetes environments.
- Technical leadership: Contribute to architectural decisions, review code, and guide junior team members on best practices.
- Client collaboration: Translate business requirements into technical designs, support pitches, and communicate trade-offs to client stakeholders.
Candidates preparing for this role benefit from practicing end-to-end ML problems that emphasize deployment and monitoring, such as those found in machine learning interview questions.
Culture And What Makes Deloitte ML Engineering Different
Deloitte’s machine learning engineering culture reflects its consulting model. Engineers are evaluated not just on technical depth, but on judgment, communication, and delivery discipline.
What Deloitte Interviewers Look For
- Production mindset: Comfort designing systems that must run, scale, and be monitored long after launch.
- Clear reasoning: The ability to explain ML and infrastructure trade-offs in plain language.
- Ownership under ambiguity: Willingness to make decisions with incomplete information and adjust as constraints evolve.
- Collaboration-first approach: Success depends on working closely with data scientists, architects, and business leaders.
- Business impact orientation: Models are valuable only when they enable decisions, reduce risk, or improve outcomes.
Because Deloitte ML engineers rotate across projects and industries, adaptability and structured thinking matter more than specialization in a single algorithm. Practicing behavioral interview questions and pressure-testing explanations through mock interviews helps candidates demonstrate these traits clearly.
FAQs
Is a Deloitte Machine Learning Engineer role more engineering or data science focused?
It leans more toward engineering and production ML than exploratory data science. Deloitte machine learning engineers are expected to deploy, monitor, and scale models in real client environments, often owning pipelines, infrastructure, and reliability. If your background is closer to notebooks than production systems, you’ll want to strengthen MLOps and system design skills using resources like Interview Query’s machine learning interview questions.
Do I need prior consulting experience to pass the interview?
No, but you do need consulting-style communication. Interviewers care deeply about how you explain tradeoffs, justify decisions, and translate ML outcomes into business value. Candidates who practice behavioral framing alongside technical prep using behavioral interview questions tend to perform better in manager and partner rounds.
How technical are the ML interviews compared to Big Tech?
Deloitte interviews emphasize practical ML systems over theoretical depth. You’re more likely to be asked about model deployment, retraining strategies, cloud architecture, or monitoring than advanced proofs. Strong preparation includes hands-on system design practice, which you can find in Interview Query’s ML system design question bank.
Are GenAI and LLM questions now common in Deloitte interviews?
Yes, especially for AI-focused teams. Expect questions around RAG pipelines, prompt engineering, data privacy, and production risks when deploying LLMs in enterprise settings. Reviewing machine learning interview prep can help you connect classical ML fundamentals with modern GenAI workflows.
What differentiates strong candidates from average ones?
Strong candidates show they can ship ML, not just build models. They explain end-to-end ownership clearly: data ingestion, training, deployment, monitoring, and iteration. Interviewers consistently favor candidates who combine technical clarity with structured thinking, something you can practice across Interview Query’s coding and ML question banks.
From Models to Market Impact: Succeeding as a Deloitte Machine Learning Engineer
A Deloitte machine learning engineer interview isn’t about proving you know the most algorithms. It’s about showing you can turn models into reliable, business-critical systems under real-world constraints. Interviewers want to see how you reason through ambiguity, communicate tradeoffs, and build solutions that clients can actually operate at scale.
If you’re serious about standing out, focus your prep on production thinking: system design, MLOps, and clear storytelling around impact. Practicing with Interview Query’s machine learning interview questions, system design scenarios, and behavioral prompts will help you walk into the interview with the confidence and structure Deloitte expects from engineers trusted to deploy AI in the real world.
Deloitte Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
Data Structures & Algorithms | Medium | |
Machine Learning | Easy | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences