

Meta Data Engineer Interview Questions: Process, Preparation, and Tips


Introduction: The Meta Data Engineer Role
Meta’s data engineers sit at the heart of how billions of people experience Facebook, Instagram, and WhatsApp. Every tap, like, and story view generates signals that fuel product innovation, from optimizing Reels recommendations to improving data infrastructure for the metaverse. The scale is unmatched since Meta processes trillions of events daily, transforming raw data into insights that drive smarter products and better decisions.
At Meta, data engineers go beyond building tables. They design infrastructure that fuels the company’s decision-making, blending software engineering, data architecture, and analytical thinking.
In this guide, you’ll learn everything you need to prepare for and ace the Meta Data Engineer interview. We’ll cover each stage of the process, from recruiter screens and technical interviews to system design and behavioral rounds, along with sample questions, preparation strategies, and salary insights. Whether you’re just starting your prep or finalizing your mock interviews, this guide will help you think, design, and communicate like a Meta engineer.
Meta Data Engineer Interview Process & Timeline
Meta’s interview process for data engineers is structured, transparent, and designed to evaluate both technical depth and product intuition. You’ll go through a mix of hands-on coding challenges, applied data-modeling scenarios, and behavioral assessments that reveal how you collaborate and take ownership.
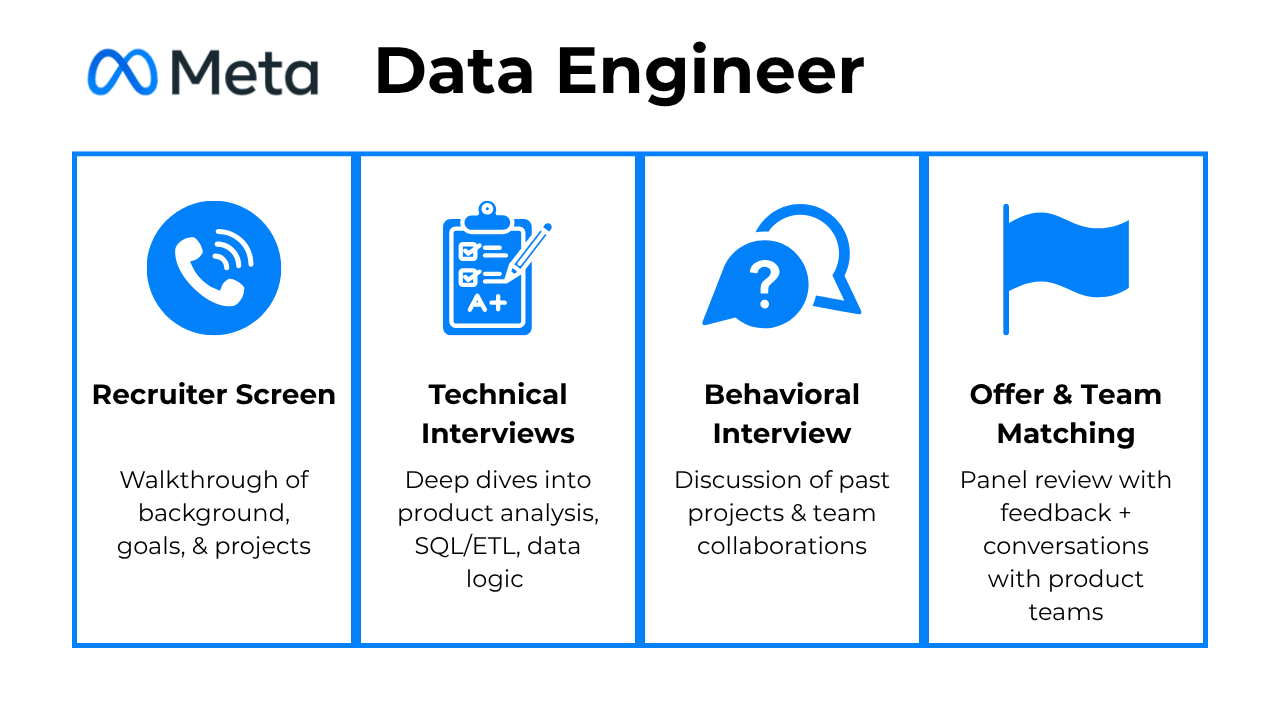
Here’s what the typical process looks like:
Step 1: Recruiter Screen (20–30 minutes)
This is your kickoff call with a Meta recruiter. It’s casual but important where the recruiter is assessing fit, communication style, and alignment with the role level (usually IC4–IC6). Expect them to ask about your background, current role, and project highlights, especially those that show large-scale data work.
They’ll walk you through the upcoming process, clarify timelines, and sometimes even suggest which Meta teams (like Ads, Instagram, or Infrastructure) your experience best aligns with. You’ll also have time to ask about the tech stack, team culture, or how data engineering fits into product teams at Meta.
Tip: Treat this call like a two-way conversation, not a test. Show enthusiasm for Meta’s data challenges (“I’ve always been curious how Meta handles real-time pipelines at global scale”), it signals both interest and initiative.
Step 2: Technical Interviews (3 × 1 hour)
This is the core of the process with three deep, 60-minute interviews designed to cover the full spectrum of your data engineering skills.
Each one has a clear focus:
Product Sense & Analytical Reasoning
You’ll get open-ended product problems that test how you think with data. The interviewer might ask something like, “How would you measure engagement for Reels?” or “Why might click-through rate drop on the Ads dashboard?”
They’re evaluating how you define metrics, connect data to product impact, and reason through trade-offs. Think out loud, Meta loves structured thinkers who can break a messy problem into measurable pieces.
Tip: Start every answer with, “Here’s how I’d approach this…” It shows confidence and keeps your reasoning visible, even if your conclusion evolves mid-discussion.
Data Modeling & SQL/ETL
Next comes schema and pipeline design, which is your chance to prove you can build systems that scale. You’ll likely sketch schemas or write queries on Excalidraw and CoderPad. Expect prompts like “Design a data model for Facebook posts and comments” or “Write a query to find users who didn’t log in this week.”
You’ll be judged on how clean, efficient, and maintainable your design is. Interviewers love to see you justify trade-offs, for instance, when to normalize vs. denormalize, or why you’d partition by
user_idinstead ofregion_id.Tip: Narrate your schema design like a story such as what the data represents, how it flows, and why your approach helps teams query faster. Clarity counts as much as correctness.
Python & Data Processing Logic
Finally, you’ll switch gears to pure problem-solving. You’ll use Python (in CoderPad) to transform data structures, parse logs, or implement small ETL functions. These aren’t trick questions so they’re about clean logic and sound reasoning.
For example, you might be asked to find duplicate user IDs, flatten a nested JSON, or simulate part of a data pipeline. The goal is to see how you reason about complexity, not just syntax. Write clean, readable code with comments explaining your thought process.
Tip: Focus on edge cases since Meta interviewers often ask, “What if the input were empty or malformed?” Showing you anticipate real-world messiness gives you a big credibility boost.
Step 3: Ownership Interview (30 minutes)
This is Meta’s behavioral round, which looks at how you work with people and handle ambiguity. You’ll discuss past projects, challenges, and decisions where you demonstrated leadership, even without a title.
Expect questions like:
- “Tell me about a time you debugged a critical pipeline under pressure.”
- “Describe a situation where you influenced a team’s technical direction without authority.”
Interviewers are looking for evidence of scope (how big or complex your work was), influence (how you drove alignment), and leadership (how you take initiative and follow through).
Tip: Use the Problem → Approach → Impact → Reflection framework to structure your answers. This helps you tell a clear, results-driven story that highlights both technical depth and interpersonal strength.
Step 4: Post-Interview Timeline & Team Matching
Once you finish your loop, your recruiter usually reaches out within a week with feedback. If things go well, you’ll enter team matching, where you meet with hiring managers from specific product teams (e.g., Ads, Instagram, or Reality Labs). This is less formal, think of it as finding your best-fit role and project domain.
Once matched, the recruiter will present the offer package, including level, location, and compensation details.
What to Do After the Interview:
- Follow up: Send a short thank-you email to your recruiter within 24–48 hours. Reaffirm your excitement about the role and mention one topic that stood out.
- Be patient but proactive: If you haven’t heard back after a week, politely check in with your recruiter for an update.
- Reflect: Write down what went well and what you’d improve for next time, it helps you stay sharp for team matching or future rounds.
- Ask for feedback: If you don’t move forward, request constructive feedback. Meta recruiters often share general pointers about areas to strengthen.
Tip: Keep communication professional and concise. Recruiters appreciate enthusiasm paired with respect for the process and it leaves a strong final impression.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Meta?
Meta Data Engineer Interview Evaluation Criteria
Meta’s interviews are built around a simple idea: hire data engineers who think like builders and analysts. The company is looking for people who can design data systems that answer real product questions at global scale.
The Philosophy: Problem-Solving Over Perfection
Meta wants to see how you think, not just whether your query runs. Interviewers focus on your reasoning process, trade-off discussions, and ability to simplify complex problems.
If you’re stuck, it’s perfectly fine to ask clarifying questions or talk through alternatives. In fact, that’s encouraged. Interviewers value curiosity, product awareness, and the ability to connect data design back to the user experience.
Example:
If you’re asked to optimize a data pipeline that’s running slowly, don’t jump straight into code. Walk through how you’d analyze bottlenecks, assess trade-offs between compute and storage, and suggest incremental improvements.
Tip: Talk through your reasoning clearly, even if your first idea isn’t perfect. Meta values a thoughtful, iterative approach over rushing to the “right” answer.
What Meta Evaluates
Across the loop, you’ll be assessed on three key focus areas:
Product sense: Can you understand the “why” behind a dataset?
Meta data engineers are expected to think like product analysts by identifying the right metrics, defining success for a feature, and spotting anomalies in engagement or retention.
Example prompt: “How would you measure the success of a new Instagram Reels feature?”
Tip: Always connect your answer back to business impact. Explain why a metric matters, not just how you’d calculate it.
Data modeling & architecture: Can you design schemas and data marts that scale?
You’ll be asked to brainstorm how data should be logged, stored, and joined to support analytics. Expect to justify decisions around normalization vs. denormalization trade-offs, partitioning strategy, and query optimization.
Example prompt: “Design a data model to track Facebook post interactions and how you’d optimize it for analytics.”
Tip: Focus on clarity and scalability. Meta prefers simple, well-reasoned designs over over-engineered solutions.
ETL (Pipeline Design, SQL & Python): Can you build the systems that move data reliably?
Expect to write transformations, debug queries, and explain how you’d schedule or monitor a pipeline. Efficiency, readability, and resilience matter more than memorizing syntax.
Example prompt: “How would you design and schedule an ETL job that computes daily active users across Meta’s products?”
Tip: Meta cares deeply about trustworthy data pipelines so mention testing, validation, and alerting to highlight reliability.
Culture & Ownership Fit
Meta’s culture prizes initiative and collaboration. In the ownership interview, you’ll discuss times when you led a project, solved an ambiguous problem, or influenced a technical decision beyond your immediate scope. Interviewers assess three traits: scope, influence, and leadership.
Example:
You might describe how you optimized a reporting pipeline that several teams depended on. You identified the issue, proposed a redesign, and led a cross-team rollout that reduced latency by 40%. That story shows initiative, technical leadership, and measurable impact—all qualities Meta values.
It’s less about titles and more about the mindset: of being open to feedback, showing data-driven decision-making, and communicating clearly even when stakes are high.
Tip: Use the Problem → Approach → Impact → Reflection framework. It keeps your story structured and demonstrates both results and self-awareness.
Meta Data Engineer Interview Questions: What to Expect
So what kinds of questions does Meta actually ask?
Expect real-world, product-focused problems instead of textbook theory. Every question tests how you turn ambiguous product goals into scalable, data-driven solutions. The interviews typically revolve around four key areas: SQL, Python, data modeling, and product sense.
Tip: Always frame your answers around impact. Meta loves when you connect your technical solution back to how it improves product performance or user experience.
Product Sense & Analytical Thinking Interview Questions
Meta wants data engineers who understand why data matters. You’ll get open-ended business problems where you must define metrics, design the dataset, and interpret results.
What interviewers look for: structured reasoning, clarity on metric definitions, and your ability to connect technical solutions to user impact.
What metrics would you use to determine the value of each marketing channel?
You’ll want to look at both efficiency and effectiveness when evaluating marketing channels. Start with conversion rate and cost per acquisition (CPA) to measure how efficiently each channel drives results. Then, go deeper with ROI, customer lifetime value (LTV), and incremental lift to understand which channels bring in the most valuable users. Segment results by campaign type, audience, or region to spot differences, and use multi-touch or data-driven attribution to see how channels interact. The goal is to find channels that don’t just convert cheaply, but build long-term, high-value engagement.
Tip: Mention how you would segment performance by audience type and region. This shows you can analyze performance at Meta’s scale rather than relying on one-size-fits-all metrics.
Investigate a drop in photo posts on Facebook’s composer tool
First, confirm the drop is real by checking the statistical significance and whether it’s isolated to certain devices, regions, or demographics. Once confirmed, compare engagement trends before and after the decline and look for recent UI or feature changes that could explain it. Don’t forget technical checks like slow uploads, bugs, or latency in the composer flow. If there’s no technical cause, consider behavioral shifts like maybe users are moving toward Reels or Stories. Finally, run a survey or small experiment to validate whether the drop reflects user preference changes or an experience issue.
Tip: Explain how you would approach the problem from both a data and product perspective. Meta looks for engineers who combine debugging skills with user empathy.
How would you measure success for Facebook Stories?
You’d measure success by looking at both creator and viewer engagement. Key metrics include daily active story creators, completion rates, and average stories viewed per user. Then, track retention—are users coming back daily or weekly to create or view stories? You should also monitor time spent in Stories and whether it increases total engagement across Meta’s ecosystem. The real win is when Stories keeps users active longer without hurting usage on other surfaces like Feed or Reels.
Tip: Talk about short-term and long-term success metrics. This shows you can measure both immediate feature adoption and sustained user engagement.
Determine whether adding a feature identical to Instagram Stories to Facebook is a good idea.
Look at whether the feature adds incremental value or just duplicates effort. Start by comparing the audience overlap between Facebook and Instagram, if users already engage heavily on Instagram Stories, the feature might not add much new behavior. Then, run a controlled experiment to see how Facebook users respond. Track engagement metrics like active story posters, view rates, and session time. If the new feature increases total time in Meta apps and attracts a distinct user segment, it’s a good move; if not, it risks cannibalizing Instagram’s success.
Tip: Discuss how you would evaluate potential cannibalization between products. Meta values candidates who can think strategically about user overlap and ecosystem health.
Conduct a user journey analysis and recommend UI changes
Begin by mapping the full user flow, from the landing page to the final conversion, and identify where users drop off most frequently. Use funnel metrics like CTR, bounce rate, and average session time to find friction points. Segment your analysis by user type or device to spot specific issues. Once you’ve identified the bottlenecks, brainstorm UI changes like simplify navigation, add progress indicators, or streamline forms. Then, validate your hypotheses with A/B tests to confirm which UI tweaks actually improve conversions and retention.
Tip: Always connect UI recommendations to measurable impact. For example, mention how a change could improve retention or conversion rate to show you think in outcomes, not just design tweaks.
Data Modeling & Schema Design Interview Questions
These questions test how you design tables and relationships to support analytics or reporting use cases.
Tip: Explain why you choose a star vs. snowflake schema, what trade-offs you make for query speed vs. storage, and how you’d evolve the model as the product scales.
-
You’d store query terms and their frequencies in a structured table with fields like
query_text,search_count, andlast_updated. Use indexing and caching to deliver real-time suggestions and track user interactions for ranking optimization. To measure effectiveness, monitor CTR on suggested queries, latency, and search completion rate to ensure that users find results faster and abandon searches less often.Tip: Talk about how you’d handle freshness and scalability. For example, explain how incremental updates or a streaming layer could keep autocomplete results up to date as search volume grows.
How would you migrate a social network’s data from a document to a relational database?
Start by identifying main entities—users, posts, comments, and relationships—and normalize them into tables with foreign keys to maintain integrity. Design migration scripts to flatten nested structures, ensure referential consistency, and validate sample outputs post-migration. Finally, benchmark query performance and add indexes to handle frequent joins efficiently.
Tip: Highlight data validation and rollback planning. Meta values engineers who consider edge cases and ensure data integrity throughout migrations.
How would you design a data warehouse for a new online retailer?
You’d first define the business processes—like orders, shipments, and returns—and decide the data granularity (e.g., per order or item). Then, identify dimensions (customers, products, dates, regions) and fact tables for sales or transactions. Organize everything into a star schema for simplicity and performance, ensuring ETL processes refresh facts and dimensions daily.
Tip: Emphasize scalability and flexibility. Mention how you’d design for incremental loads, schema evolution, and efficient partitioning as data volume increases.
Design a data pipeline for hourly user analytics
You’d build an ingestion layer to collect raw event logs from apps, process them in Spark or SQL, and aggregate by hour, user_id, and activity_type. Store results in summary tables optimized for dashboards or trend monitoring. Schedule the pipeline with Airflow and include data validation checks to catch anomalies or delays.
Tip: Mention how you’d monitor pipeline health. Meta expects engineers to think about alerting, logging, and recovery steps for production reliability.
Create a schema to represent client click data
Design a
click_eventstable with columns likeuser_id,session_id,action_name,timestamp,device_type, andutm_source. Add partitions on time for scalability and indexes onuser_idfor quick lookups. This schema lets you analyze engagement by user behavior, campaign performance, or device trends with minimal joins and faster queries.Tip: Explain how you’d balance query performance with cost. Discuss why you might use partition pruning, columnar storage, or even pre-aggregated tables to handle large-scale clickstream data efficiently.
Watch Next: Uber Data Engineer Interview: Design a Ride Sharing Schema
In this mock session, Jitesh, an Interview Query Coach and data engineer from Uber walks through how they would build and monitor a high-volume data pipeline, from ingestion to analytics. You’ll see how real-world decisions around schema design, latency, and monitoring are made in a fast-moving environment to help you connect architecture choices to business impact at your next data engineering interview.
SQL & ETL/Data Processing Interview Questions
Expect a blend of conceptual and practical SQL tasks like joins, aggregations, window functions, plus reasoning about performance and pipeline design. What matters here is efficiency, readability, and handling edge cases. Be prepared to explain how you’d schedule jobs, manage dependencies, and debug pipeline failures.
Write a query that returns all neighborhoods that have 0 users
To find neighborhoods with no users, perform a LEFT JOIN between the
neighborhoodstable and theuserstable on theneighborhood_id. Filter the results where theuser_idis NULL, indicating no users are associated with those neighborhoods.Tip: Always mention indexing and query plan review. Saying you’d check with
EXPLAINto ensure proper join performance shows you think about efficiency, not just correctness.-
To solve this, first filter departments with at least ten employees. Then, calculate the percentage of employees earning over 100K for each department and rank the top three departments based on this percentage.
Tip: Describe how you’d handle ties or performance optimization. Meta appreciates candidates who think through both accuracy and edge conditions.
Write an SQL query to retrieve each user’s last transaction
This question tests window functions. To solve this, use a window function:
ROW_NUMBER()over a partition byuser_idordered bytransaction_date DESC. Then filter forrow_number = 1to get the most recent transaction per user. This pattern is highly reusable for “last event” queries in ETL or analytics workflows.Tip: Explain why you’d prefer window functions over subqueries. It shows you understand performance trade-offs and maintainable SQL patterns.
Compute click-through rates (CTR) across queries
Aggregate impressions and clicks per normalized query using subqueries or CTEs, then compute
clicks / impressionsas CTR. To keep it performant, pre-aggregate by(query_norm, event_time)and ensure proper indexing on those columns. Finally, useEXPLAINto confirm the optimizer avoids full scans. This demonstrates your ability to balance accuracy and performance.Tip: Mention data validation. For example, say you’d filter out queries with fewer than a threshold number of impressions to avoid noisy or misleading CTR values.
Write a query to track flights and related metrics
This question tests grouping and ordering. Group data by
plane_idor route (origin_city,destination_city) and compute aggregate metrics likeCOUNT(flight_id),AVG(duration), andMAX(delay). Order by metrics such as delay or flight count to feed summary dashboards for airline operations.Tip: Add how you’d apply filtering or windowing for time-based trends. This shows you can adapt queries for reporting dashboards and longitudinal analysis.
Design a database to represent a Tinder style dating app
To design a Tinder-style dating app database, you need to create core tables for
users,swipes,matches, andmessages. Each swipe links two user IDs with a direction (likedorpassed), and matches form when two users mutually like each other. Add indexes onuser_idandtimestampfor quick lookups, and consider caching recent swipes or matches for low-latency queries.Tip: Discuss how you’d maintain data consistency between swipes and matches. Meta values engineers who think about both performance and data integrity.
Explain how you’d build an ETL process to track daily active users for Facebook Messenger.
You’d ingest event logs from message sends, opens, and logins, then aggregate unique
user_ids per day. Store this in adaily_active_usersfact table. Automate the pipeline with Airflow, ensuring dependency checks and automated validation scripts flag anomalies or drops in user counts.Tip: Always mention monitoring. Saying you’d add alerting for drops in daily counts or delayed loads highlights reliability thinking, which is something Meta prizes in production systems.
How would you ensure data quality across ETL platforms?
Standardize data formats and enforce validation at every stage. Use checksums or row counts to confirm load completeness, define semantic rules (e.g., valid date ranges or non-null keys), and track lineage for auditability. Collaborate with stakeholders to maintain shared data contracts and recurring quality reviews.
Tip: Include proactive checks. Mention implementing automated data audits or anomaly detection jobs to ensure consistent data quality over time.
Interview Questions on Data Transformation with Python
These rounds test your ability to manipulate data structures in Python like loops, dictionaries, and set operations to implement small-scale ETL logic or transform datasets.
Tip: The focus is on problem-solving, not memorization. Use clean code and talk through trade-offs like time vs. space complexity.
Given a string, write a function to find its first recurring character
This question tests string traversal and hash set usage. It checks if you can efficiently identify repeated elements in a sequence. To solve this, iterate through the string while tracking seen characters in a set, and return the first duplicate encountered. In real-world data pipelines, this mimics finding duplicate IDs, detecting anomalies, or flagging repeated events in logs.
Tip: Explain why a set is optimal here since it allows O(1) lookups. It shows you understand both performance and readability in your code.
Find the bigrams in a sentence
Start by splitting the sentence into words, then iterate through them to create consecutive pairs—
(word[i], word[i+1]). You can store these as tuples or strings depending on your use case. This method is simple but powerful, forming the basis for NLP tasks like autocomplete, text prediction, or even understanding user navigation sequences in logs.Tip: Mention how you’d handle punctuation or capitalization in preprocessing. Meta interviewers appreciate when you consider real-world data imperfections.
Given a list of integers, identify all the duplicate values in the list.
This question checks whether you can detect and return duplicate elements from a collection. To solve this, you can use a set to track seen numbers and another set to store duplicates. Iterating once through the list ensures O(n) time complexity. In real-world data engineering, duplicate detection is critical when cleaning raw datasets, ensuring unique identifiers in ETL pipelines, or reconciling records across multiple sources.
Tip: Point out how this method scales efficiently with large datasets, which is crucial when discussing big data processing at Meta’s scale.
-
This question tests algorithm design and complexity analysis. Use a hash-based approach or prefix sums to detect zero-sum subsets efficiently. For small inputs, a brute-force or recursive combination search works fine, but it grows exponentially (O(2ⁿ)). A prefix-sum technique cuts that to O(n) by tracking cumulative sums in a dictionary. This logic mirrors how engineers detect mismatched debits and credits in financial datasets or anomalies in transaction logs.
Tip: Walk through how you’d reason about scalability. Meta interviewers like candidates who can discuss when and why to move from brute force to optimized algorithms.
Given a nested dictionary of user events, flatten it into a list of JSON objects.
Recursively traverse the dictionary, carrying parent keys forward as you go. Each leaf node becomes a key-value pair in a flattened JSON object. In Python, recursion or iterative stack methods both work but ensure consistency in key naming (like
"parent.child.key"). Flattening helps simplify event logs for downstream analytics or loading into relational tables.Tip: Clarify how you’d handle nested arrays or inconsistent key structures. Showing that you can adapt your code to messy, real-world data demonstrates strong engineering judgment.
How would you stream and process log data in near real-time?
You could design a producer-consumer setup using Kafka or Kinesis for ingestion and a processing layer like Spark Streaming or Flink. Events would be batched in short intervals, processed for aggregations or anomalies, and written to a storage system like Hive or BigQuery. The key is balancing throughput and latency—keeping data fresh without overloading your consumers.
Tip: Emphasize how you’d monitor the system for lag, dropped messages, or processing failures. Meta values engineers who not only build streaming systems but also think about maintaining and scaling them effectively.
Behavioral/Ownership-Style Interview Questions
Even technical rounds may include light behavioral prompts. Meta interviewers often wrap up by asking such questions to gauge communication, collaboration, and impact.
Tip: Always ground your answers in real examples from your past experience. Meta values authenticity, reflection, and measurable impact over rehearsed answers.
What do you tell an interviewer when they ask you what your strengths and weaknesses are?
When asked about strengths and weaknesses in an interview, it’s important to be honest and self-aware. Focus on strengths relevant to data engineering, such as clarity in modeling, optimizing ETL workflows, or mentoring others. For weaknesses, choose something real but manageable, and show how you’re improving it (e.g., balancing perfectionism with speed).
Tip: Keep your tone honest and professional. Meta appreciates self-aware engineers who actively work on self-improvement rather than claiming to have no weaknesses.
How comfortable are you presenting your insights?
Explain how you adapt your message depending on the audience, using dashboards for executives and detailed reports for peers, and highlight a moment when your insights influenced a major decision.
Tip: Mention tools like dashboards, reports, or visualizations that help you convey insights clearly. This shows that you understand not just analysis, but storytelling with data.
What are effective ways to make data accessible to non-technical people?
Describe simplifying complex concepts through intuitive dashboards, clear naming conventions, and concise documentation. Talk about training or support you provided to help stakeholders interpret metrics confidently. The key is translating data into actions, not just numbers.
Tip: Share an example where your efforts improved decision-making speed or accuracy. Meta interviewers value data engineers who empower others to self-serve and think data-first.
What data engineering projects have you also worked on? Which was most rewarding?
Share a project where you solved a meaningful problem, for example, improving data latency or automating manual reporting. Use the Problem → Approach → Impact → Reflection format to show structured thinking and measurable outcomes. Focus on how your contribution improved performance, saved time, or enabled better business insights.
Tip: Include a clear metric of success, like “cut query latency by 40%” or “eliminated manual reporting for 10 teams.” Quantifiable impact makes your story memorable and credible.
Describe a situation where you influenced a technical decision without direct authority.
Share an example where you proposed a change, like migrating from manual SQL scripts to Airflow DAGs that improved scalability or maintainability. Highlight how you built consensus through data, prototypes, or performance metrics, and how your collaborative communication convinced stakeholders. Focus on driving alignment and demonstrating impact through logic and teamwork, not hierarchy.
Tip: End with what you learned about persuasion and teamwork. Meta values leaders who can drive change through influence and clear communication rather than formal authority.
System Design & Data Architecture: Senior-Level Focus
If you’re interviewing for a senior data engineer (IC6+) role at Meta, expect the conversation to zoom out, from writing queries to architecting data ecosystems that handle billions of events daily.
At this level, interviewers want to see whether you can design reliable, scalable, and observable systems that empower product teams, data scientists, and machine-learning pipelines.
Inside the Senior-Level System Design Interview
The senior-level system-design portion often surfaces within the third technical round or as an extended scenario in your loop. You’ll use CoderPad for SQL/Python logic and Excalidraw to sketch data-flow diagrams or architecture blueprints .
Interviewers may frame a challenge like:
“Design a data platform to compute engagement metrics for Reels in near real-time.”
or
“Architect a system that logs, aggregates, and exposes ad-performance data to multiple downstream consumers.”
The goal isn’t a perfect diagram, but your thought process of how you decompose the problem, reason about trade-offs, and communicate clearly under ambiguity.
Tip: Always start by clarifying requirements, such as volume, velocity, and use case before jumping into a solution. Meta values engineers who slow down to understand the why before designing the how.
Core Areas of Evaluation in Meta’s Senior System Design Round
At the senior level, Meta’s interviewers want to see how you think about systems holistically. This section breaks down the four core areas where your design decisions, communication, and leadership approach will be evaluated.
Data Modeling at Scale
Interviewers test whether you can design schemas that evolve with product growth. You’ll discuss how to manage schema drift, late-arriving data, and versioning while maintaining efficiency. Be ready to justify when to denormalize for performance versus maintaining normalization for flexibility.
Example: “How would you design a data model for tracking engagement across multiple Meta surfaces like Reels, Feed, and Stories?”
Tip: Frame your answer around scalability and maintainability. Show that you think beyond the first version of the system. Meta appreciates engineers who anticipate future evolution, not just immediate needs.
Pipeline Orchestration & Reliability
You’ll dive into ETL scheduling, dependency management, retries, and monitoring. Interviewers want to know how you ensure reliability at scale when dozens of jobs depend on each other. Expect to discuss Airflow DAGs, data lineage, alerting mechanisms, and quality checks for detecting stale or inconsistent data.
Example: “How would you design a pipeline to refresh engagement metrics hourly and alert if any job fails?”
Tip: Always mention proactive monitoring. Explain how you’d implement alert thresholds, logging, and recovery mechanisms—Meta’s production mindset prioritizes resilience as much as correctness.
System Performance & Cost Trade-offs
This part explores how you balance performance, scalability, and efficiency. You’ll be asked to optimize compute costs while handling terabytes of logs daily. Discuss partitioning strategies, query optimization, caching, and storage format selection (e.g., Parquet vs. ORC). You might also need to reason about trade-offs between batch vs. streaming or cold vs. hot data storage.
Tip: Demonstrate business awareness. It’s not just about saving compute—show that you can justify trade-offs based on latency needs, product priorities, and user impact.
Cross-Functional Design Collaboration
Meta expects senior engineers to act as connectors between teams. You’ll often justify your architectural decisions to product engineers, data scientists, or ML teams. Strong candidates explain designs clearly, anticipate downstream needs, and align stakeholders before implementation.
Tip: Use examples where you influenced multiple teams. Meta values engineers who can bridge technical and non-technical conversations with empathy and data-backed reasoning.
How to Prepare for Meta’s Senior System Design Round
To perform well in Meta’s system design interviews, focus on clarity, structure, and trade-off reasoning. Practice explaining why you’d choose certain tools or data models for specific use cases.
Here’s how to prepare effectively:
Study Meta’s tech stack: Review Meta’s official post on Data Engineering to learn how tools like Presto, Spark, Airflow, Scuba, and Hive fit together in real-world pipelines. Understanding how these components interact gives you authentic examples to reference in interviews.
Practice end-to-end design flows: Pick familiar use cases, like “tracking video engagement metrics” or “building a recommendation analytics system”, and draw data-flow diagrams from ingestion → processing → storage → analytics. Explain what happens at each step and why.
Simulate design trade-offs: Practice comparing design alternatives aloud: batch vs. streaming, SQL vs. Spark, OLTP vs. OLAP. Meta interviewers care about how you evaluate trade-offs under constraints.
Build narration skills: Use a step-by-step communication pattern:
“I’ll start with ingestion… here are the constraints… now let’s discuss scalability options.”
Clear narration makes your reasoning easy to follow and shows leadership in complex discussions.
Tip: In mock sessions, practice thinking aloud. Meta’s senior interviews are as much about communication and reasoning clarity as they are about technical depth.
How Meta Evaluates Senior Data Engineers
At the senior level, Meta’s interviewers look for ownership and system-level thinking. They assess your ability to connect technical design with organizational and product impact.
You’ll be evaluated on:
- System thinking: Do you understand data lifecycles end to end—from ingestion to consumption?
- Technical depth: Can you design fault-tolerant, scalable, and cost-effective systems under real-world constraints?
- Influence & mentorship: Have you demonstrated the ability to guide peers, set best practices, and shape technical direction across teams?
It’s about showing ownership of complex data systems that deliver measurable business value.
Tip: Treat this round as a conversation between peers. Interviewers want to see that you can think strategically about architecture, collaborate effectively, and drive alignment in complex systems.
Tips to Curate Meta Data Engineer Portfolio
When Meta interviewers say they want to “see your impact,” they mean it literally. Your projects, pipelines, and dashboards are the best proof of your problem-solving ability and your sense of ownership. Interviewers use it to see how you think, execute, and communicate technical work in a business context. They expect you to demonstrate both technical depth (how you built it) and strategic value (why it mattered). A well-presented project can often be the deciding factor in team matching and offer discussions.
Even though there’s no formal portfolio presentation, you’ll walk interviewers through 2–3 projects as mini case studies that highlight your end-to-end ownership such as how you defined the problem, designed the solution, and measured its success.
Tip: Choose projects that show variety, like one focused on ETL, one on data modeling, and another on scalability or automation. Meta looks for engineers who can flex across the data stack.
What Interviewers Want to Hear about Your Portfolio
- Scope: What problem were you solving? Why did it matter to the business?
- Solution design: Walk through the architecture like data sources, transformations, and outputs.
- Trade-offs & Decisions: Explain why you chose one approach over another.
- Impact: Quantify outcomes such as reduced latency by 30%, automated 90% of manual reporting, etc.
- Collaboration: Highlight how you worked with product managers, analysts, or ML engineers to make the project successful.
Meta interviewers often look for projects where you went beyond assigned tasks like built tooling to improve reliability, mentored others, or introduced better data-quality checks. That’s what “ownership” means at Meta.
Tip: For every project, quantify your results. Even simple metrics like “cut pipeline runtime from 3 hours to 45 minutes” make your story more compelling and data-driven.
How to Structure Your Project Walkthrough
When a question starts with “Tell me about a project you’re proud of”, use this simple structure:
Problem → Approach → Impact → Reflection
Example:
“Our marketing dashboards were taking hours to refresh.
I designed a new ETL pipeline in Airflow that pre-aggregated metrics hourly instead of daily.
The result was a 40% drop in load time, and teams could track campaigns in near real time.
If I did it again, I’d add better anomaly detection earlier in the workflow.”
This framework keeps your story focused, measurable, and memorable.
When you describe your impact, go beyond results and explain what you specifically did that others didn’t. For example, if you introduced a new process, solved a critical bottleneck, or influenced a team-wide change, spell that out. This turns your story into a “show, don’t tell” moment and makes your contribution stand out as tangible and unique.
Tip: Practice your walkthrough aloud. Keep it under two minutes per project and lead with measurable impact before diving into technical details.
Tips for a Strong Portfolio Discussion
- Bring 2–3 projects that show breadth and depth (ETL, modeling, automation, etc.).
- Include visuals like simple architecture sketches or metric dashboards, they make complex systems easy to follow.
- Translate technical achievements into business impact: for example, “reduced query cost by $5K per month by migrating data to Parquet format.”
- Stay concise, Meta prefers clarity and impact over excessive detail.
Tip: End each project story with a short reflection on what you’d improve next time. This shows humility, growth mindset, and the kind of ownership Meta values most.
Average Meta Data Engineer Salary
Average Base Salary
Average Total Compensation
Meta’s compensation philosophy is simple, pay top-of-market for top performance.
For data engineers, that means strong base pay, competitive bonuses, and equity packages that can grow significantly over time.
Your total compensation will depend on your IC level (individual contributor level), location, and team. Most candidates interview at IC4–IC6, with IC7 reserved for principal-level engineers who lead large cross-functional systems.
Tip: Always clarify your IC level early in the process. It directly determines your compensation band, responsibilities, and growth path.
Estimated Meta Data Engineer Salary Bands (2025)
| Level | Typical Role Title | Total Compensation Range (USD) | Breakdown |
|---|---|---|---|
| IC4 | Data Engineer | $180K – $240K | Base $145K–$175K + Bonus + Equity |
| IC5 | Senior Data Engineer | $230K – $320K | Base $170K–$200K + Bonus + RSUs |
| IC6 | Staff Data Engineer | $320K – $450K | Base $190K–$225K + High RSUs |
| IC7 | Principal / Lead | $450K – $650K+ | Base $220K+ + Substantial Equity |
Note: These estimates are based on aggregated data from Levels.fyi, Blind, and Glassdoor as of 2025. Actual offers vary by location (e.g., Menlo Park vs. Austin vs. Remote).
Tip: Compensation bands can shift yearly. Cross-check data from at least two sources (like Levels.fyi and Glassdoor) before negotiating or accepting an offer.
How Meta Structures Compensation
Meta’s total compensation package has four main parts:
- Base salary: The fixed component—competitive across FAANG peers.
- Annual bonus: Typically 10–15% of base, performance-based.
- Equity (RSUs): The biggest differentiator. Meta issues RSUs that vest quarterly over four years. Strong performers often receive top-up grants during annual reviews.
- Signing bonus: Common for new hires, usually split over the first year to offset vesting delays.
Tip: Don’t underestimate the value of RSUs. Since Meta stock prices fluctuate, always ask for the number of shares and not just the dollar value, this helps you better estimate long-term earnings.
Negotiation Tips That Work
Negotiating at Meta is about showing that you understand your market value, can back it up with data, and can navigate recruiter conversations with confidence and tact.
Here’s how to make the most of your offer discussions and handle any curveballs along the way.
- Confirm your leveling early: Your level determines everything from compensation to scope. If you’re on the border between IC4 and IC5, ask the recruiter directly. Explain how your experience and responsibilities align with the higher level since even a one-level bump can add $50K–$100K to your total package.
- Use verified comp data as leverage: Reference updated benchmarks from Levels.fyi or Teamblind. Be specific: “The average IC5 data engineer package at Meta is around $280K–$300K”, so your ask sounds factual, not inflated.
- Leverage competing offers strategically: Meta recruiters expect top candidates to have options. Present comparable offers professionally, like “I’ve received another offer at $X total, but I’d love to make Meta work if we can align on comp.”, and they’ll often counter with equity top-ups or signing bonuses.
- Lead with impact, not experience: Instead of saying “I’ve worked in data engineering for six years,” say “I built a distributed data pipeline that cut compute costs by 30%.” Meta values outcomes and scope, so tie your results directly to measurable business or system impact.
- Address remote or hybrid pay differences early: Meta adjusts compensation by location, so if you’re interviewing for a remote or hybrid role, clarify your pay range upfront. This helps avoid surprises later and shows professionalism in handling logistics.
Once you’ve clarified level, range, and structure, get the offer in writing. Review all components such as base, bonus, equity, and signing, before committing. If you’re unsure, ask your recruiter for a breakdown by vesting year. Then, express gratitude and enthusiasm, even if you’re still deciding; recruiters remember respectful candidates when new roles open up.
Tip: Treat negotiations as a partnership, not a contest. Your goal is to align value on both sides—your impact for their investment.
Meta Data Engineer Interview Preparation Checklist
Meta interviews test both the depth and breadth of your technical skills, product thinking, and communication, all matter. The best prep strategy is to keep practicing your thought process.
Here’s a clear, week-by-week plan to help you get ready with confidence.
| Week | Focus Area | What to Practice / Key Actions |
|---|---|---|
| Week 1–2 | Fundamentals First | SQL & Data Modeling: - Review joins, window functions, CTEs, and aggregations. - Practice schema design for Instagram or Messenger (users, posts, interactions). - Try pgexercises, LeetCode SQL, and Meta-style case studies on Interview Query. Python for Data Processing: - Brush up on lists, dictionaries, loops, and set operations. - Practice transforming and cleaning data efficiently. |
| Week 3–4 | Systems Thinking & Product Sense | Product Sense: - Pick a Meta product (e.g., Reels or Ads Manager) and identify 3–5 core metrics. - Ask “If this metric dropped, how would I diagnose it?” - Review questions like “How would you measure feature success?” System Design (for Senior Candidates): - Sketch data-flow diagrams for ingestion → transformation → storage → analytics. - Explain trade-offs (batch vs. streaming, denormalization vs. normalization). |
| Week 5 | Ownership & Behavioral Prep | - Prepare 2–3 projects where you led or improved something beyond your assigned task. - Use STAR (Situation, Task, Action, Result) or Problem → Approach → Impact → Reflection. - Reflect on challenges, lessons learned, and influence on others. |
| Final Week | Mock & Refine | Simulate the Full Loop: - 1 hour technical practice (SQL + Python + design prompts). - 30-min behavioral mock summarizing your top projects and impact. - Review recruiter tips and check camera, environment, and screen-share setup before your live session. |
Meta Interview Preparation: Last-minute Checklist
Before your final loop, review this quick checklist to ensure you’re ready across all core areas. It’s designed to help you track your readiness and spot any last-minute gaps before interview day.
| Prep Area | Goal | Resources / Actions |
|---|---|---|
| SQL & ETL | Clean, optimized queries | Interview Query SQL questions, pgexercises |
| Data Modeling | Clear schema design | Kimball modeling, practice on Instagram-like dataset |
| Python | Solid data manipulation | LeetCode Easy–Medium Python sets/dicts |
| Product Sense | Metric definition & reasoning | Meta product metrics analysis |
| System Design | End-to-end data pipeline thinking | Practice whiteboarding Spark/Airflow flows |
| Ownership | Clear impact stories | STAR or Problem–Approach–Impact–Reflection |
| Logistics | No tech issues, confident setup | Check Zoom screen-share & quiet workspace |
Common Technical Mistakes and How to Avoid Them
Even top candidates stumble on Meta’s interviews, not because they lack skill, but because they forget the interview’s purpose, which is to show how you think.
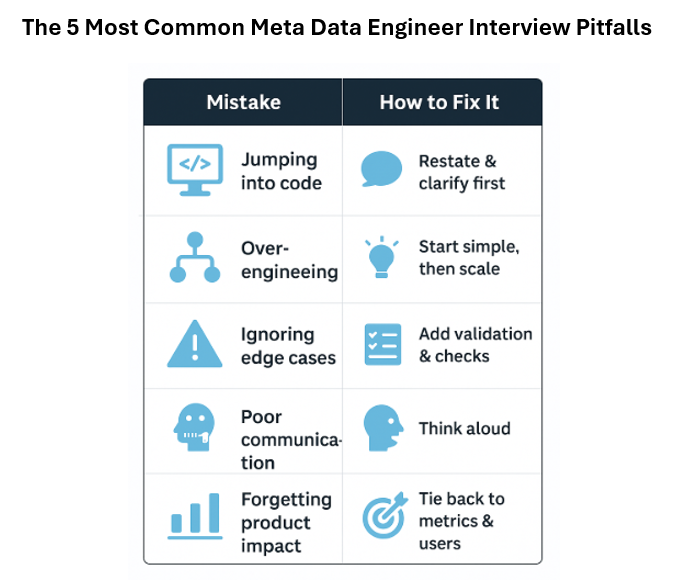
Here are the mistakes Meta interviewers see most often (and how to avoid them).
1. Jumping Straight Into Code
The mistake: Writing SQL or Python immediately without clarifying the problem.
Why it hurts: Meta’s questions are product-oriented and they test reasoning, not just syntax.
Fix:
- Restate the problem in your own words before coding.
- Ask clarifying questions: “Should this metric be unique per user or per session?”
- Outline your plan aloud → then code.
Tip: Meta explicitly encourages this collaborative reasoning during interviews.
2. Over-engineering the Solution
The mistake: Designing massive data architectures for simple problems.
Fix:
Start with the simplest possible solution. Then explain how you’d scale it.
Example: “For now, I’d schedule this ETL daily in Airflow, but if latency becomes an issue, I’d move to a streaming pipeline.”
Showing trade-off awareness beats flashy complexity every time.
3. Ignoring Data Quality & Edge Cases
The mistake: Writing perfect logic that breaks on nulls, duplicates, or missing joins.
Fix:
Meta loves engineers who anticipate data messiness.
- Add guards for nulls or mismatched joins.
- Mention validation and monitoring.
- Reference how you’d test or alert on anomalies.
This demonstrates reliability thinking which is a core Meta value.
4. Poor Communication Under Pressure
The mistake: Going silent while debugging or optimizing.
Fix:
Narrate your thought process. If you hit a snag, explain what you’re checking next.
Interviewers are gauging collaboration style of how you’d work with teammates when things go wrong.
5. Forgetting Product Context
The mistake: Treating every question as pure engineering.
Fix:
Always tie your solution back to impact.
“This schema helps product managers see retention trends daily.”
It’s a subtle way to show product sense — one of Meta’s core pillars of evaluation.
Tip: If you’re unsure midway through a solution, ask for feedback cues like, “Is this the right level of detail, or should I expand on optimization?”
That’s how Meta’s best interviewees keep alignment and stay confident.
FAQs
How many rounds are there in the Meta data engineer interview process?
You’ll typically complete four interviews in total:
- Three × 1-hour technical interviews (Product Sense, Data Modeling, SQL/Python ETL)
- One × 30-minute ownership interview focused on collaboration, leadership, and impact.
How long does the entire process take?
From recruiter screen to decision, expect 2 – 4 weeks, depending on interviewer availability and feedback review. Recruiters usually follow up within a week after your final round.
What is the salary range for a Meta data engineer?
Compensation varies by level and location, but typical total packages range from $180K (IC4) to $450K (IC6) +, including base, bonus, and equity.
What technical skills does Meta look for?
Meta evaluates:
- SQL & ETL: joins, aggregations, window functions
- Python: data structures and transformations
- Data modeling: schema design for analytics
- Product sense: connecting data to business impact.
How should I prepare for the system design interview at Meta?
Practice explaining data architecture trade-offs—batch vs. streaming, partitioning, caching, and schema evolution. Sketch simple ingestion → processing → storage flows and talk through why you chose each design choice.
What kinds of projects should I showcase in my portfolio?
Bring 2 – 3 projects that highlight end-to-end impact such as ETL pipelines you designed or optimized, data models that improved reporting efficiency or cross-functional projects showing leadership or mentorship.
What are common mistakes candidates make?
Jumping into code without clarifying the problem, over-engineering solutions, and forgetting to explain product context.
What is Meta’s culture like for data engineers?
Meta emphasizes collaboration, transparency, and ownership. Engineers are encouraged to move fast, measure everything, and build with impact. Casual dress, open codebases, and cross-team mentorship are part of daily life.
How can I negotiate my offer at Meta?
Come prepared with market data (e.g., Levels.fyi), clarify your IC level, and highlight your impact. Meta recruiters expect professional negotiation and can adjust equity or signing bonuses accordingly.
Conclusion
Interviewing at Meta as a Data Engineer is challenging, but entirely achievable with the right prep. Meta’s process rewards candidates who explain their reasoning clearly, connect data systems to business outcomes and show ownership through impactful past work. If you prepare methodically, starting with fundamentals, layering in system design, and finishing with storytelling, you’ll walk into your interviews ready to build with confidence.
Tip: After each mock session or real interview, take five minutes to jot down what went well, where you hesitated and how you’d explain that concept more clearly next time
This small habit compounds into big improvement by the time your Meta loop arrives.
Leverage Interview Query for Your Meta Interview Prep
Need Structured Prep? Follow our structured data engineer learning path tailored to Meta’s format. See how Chris Keating reached the offer stage, and explore our full list of Data Engineer interview questions to practice what Meta actually asks.
Need 1:1 guidance on your interview strategy? Explore Interview Query’s Coaching Program that pairs you with mentors to refine your prep and build confidence.
With focus, feedback, and the right resources, you’ll be ready to succeed.
Meta Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Brainteasers | Medium | |
When an interviewer asks a question along the lines of:
How would you respond? | ||
Machine Learning | Medium | |
SQL | Easy | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences