
AI Engineer Interview Questions and Answers: Complete 2026 Preparation Guide


Introduction: The Evolving Role of AI Engineers
AI engineers are shaping the future of tech. From ChatGPT to self-driving cars, every company wants in, and they need the people who can build what’s next.
The job has changed fast. It’s not just about training models anymore; it’s about building systems that learn, scale, and act responsibly. Today’s AI engineers code, deploy, and debug real-world intelligence. Interviewers know that. They’re testing more than your math—they want to see how you think, collaborate, and turn ideas into impact.
This guide is your step-by-step roadmap to prepare for that challenge. Whether you’re applying for your first AI engineer role or aiming for a senior-level position, you’ll find practical insights, example questions, and preparation tips to help you ace your interview and stand out from the crowd.
How AI Engineer Interviews Work: Process, Stages, and What to Expect
If you’re preparing for an AI engineer interview, knowing the structure of the process can make all the difference. These interviews are designed to test not only your AI skills but also how you approach real-world problems, collaborate with teams, and think on your feet.
Whether it’s a tech giant like Google or a fast-growing AI startup, most AI engineer interview processes follow a similar flow, starting with screenings and ending with deep technical and behavioral evaluations. Let’s break it down step by step.
Initial Screening (Recruiter or Technical Screener)
The journey usually begins with a short screening interview. Here, a recruiter or technical screener will review your AI background, programming experience, and recent projects. Expect questions about your exposure to frameworks like TensorFlow, PyTorch, or cloud platforms such as AWS and Azure AI.
Some companies may include a basic coding quiz or multiple-choice test to check your grasp of Python fundamentals, data preprocessing, and core ML concepts like regularization, loss functions, and gradient descent.
Tip: Treat this as your “first impression” round. Prepare a concise 2–3 minute summary of your AI engineer experience, highlighting one technical achievement and one impact-driven result. Keep your examples simple but quantifiable, e.g., “Optimized inference latency by 40% using model quantization.”
Technical Rounds: Coding + Machine Learning + Deep Learning
Once you’re through the screening, the focus shifts to technical interviews which are often the toughest part of the process. These rounds dive deep into:
- Coding Interviews – Expect Python-based problems focused on algorithms, data manipulation, and ML-specific challenges. Think data preprocessing, feature engineering, or implementing small model components from scratch.
- Machine Learning Theory – Be ready to explain core topics like loss functions, optimization algorithms, overfitting vs. underfitting, or how gradient descent works under the hood.
- Deep Learning & Architectures – You might be asked to describe architectures like CNNs, RNNs, or Transformers, and more importantly, when and why you’d use each.
Expect questions like:
- “Write Python code to normalize input features before training.”
- “Explain how backpropagation works and what happens if you don’t initialize weights properly.”
- “Compare transformers vs. RNNs and when would you choose one over the other?”
In addition to theory, you may be asked to implement a small ML component from scratch, like logistic regression or a feedforward network using NumPy.
Tip: Practice writing clean, readable code in an online IDE (like LeetCode or HackerRank) and narrate your thought process while solving problems. Interviewers value reasoning and structure over brute-force solutions.
System Design and Applied AI Rounds
The AI system design interview tests how you build scalable, production-grade systems. This is where AI engineering meets software architecture. You’ll likely face open-ended prompts such as:
- “Design a large-scale AI-powered recommendation engine.”
- “How would you deploy a multimodal model that combines text and image data?”
In these rounds, interviewers assess how you approach data ingestion, model training, inference optimization, and monitoring. They also look for your awareness of latency constraints, cost trade-offs, and model governance.
Tip: Use a structured approach like IDEAL (Inputs, Data flow, Execution, Architecture, Limitations). Start from the problem, walk through data pipelines, and conclude with how you’d measure success (e.g., accuracy, latency, reliability).
Behavioral and Cross-Functional Interviews
These rounds may not involve code, but they often decide who gets the offer. Behavioral and cross-functional interviews assess how you work in teams, communicate complex AI ideas, and handle ethical or ambiguous situations.
Common questions include:
- “Tell me about a time when you had to explain a complex AI model to a non-technical audience.”
- “How do you ensure your model’s predictions are fair and explainable?”
- “Describe a situation where you disagreed with a product decision, how did you handle it?”
Tip: Use the STAR method (Situation, Task, Action, Result) to structure your answers. Focus on impact since interviewers want to see that your decisions improved something measurable, like model accuracy, latency, or user trust.
What to Expect Overall
Most AI engineer interview processes last between 2–4 weeks and include 3–6 rounds, depending on the company’s scale. You might have a take-home assignment, a technical presentation, or even a research discussion if you’re interviewing for an applied AI or generative AI role.
Tip: Keep a journal or spreadsheet of your interview progress such as a list for each company, the interview rounds, key questions, and feedback notes. Reviewing this weekly helps you identify patterns and improve faster.
Quick Start: AI Engineer Interview Preparation Plan (7–14 Days)
If your AI engineer interview is coming up soon, you don’t need to study everything; you just need a smart plan. This quick-start roadmap is designed to help you cover the most critical AI concepts, practice efficiently, and build confidence in under two weeks.
We’ve divided the plan into four focused phases. Each phase can take 1–3 days depending on your schedule, totaling roughly 7–14 days of prep. Think of this as a sprint that balances depth and efficiency—you’ll review the fundamentals, sharpen your technical edge, and simulate the real interview experience before the big day.
Read more: BCG X AI/ML Engineer Interview Guide
| Phase | Focus Area | Core Topics to Review | Practice & Resources | Outcome |
|---|---|---|---|---|
| Day 1–3: Core Python & ML Foundations | Refresh coding and machine learning basics | - Python (NumPy, Pandas, OOP) - Probability & Statistics - Supervised vs Unsupervised Learning - Evaluation metrics (precision, recall, F1) - Overfitting, bias-variance tradeoff |
- Solve ML-focused coding challenges on LeetCode/Interview Query - Read “Hands-On ML” (Ch. 1–3) - Watch fast.ai Intro ML lectures |
Build speed and confidence in core coding + ML problem-solving |
| Day 4–6: Deep Learning & Modern Architectures | Strengthen deep learning theory and model intuition | - Neural Networks & Backpropagation - CNNs, RNNs, LSTMs - Transformers, Attention, and LLMs - Fine-tuning & Transfer Learning - Regularization & Optimization techniques |
- Implement models in PyTorch or TensorFlow - Review Hugging Face tutorials on Transformers - Watch Andrew Ng’s Deep Learning Specialization videos |
Understand core architectures and explain them confidently in interviews |
| Day 7–9: System Design & Applied AI | Learn to design scalable AI pipelines and deployment systems | - AI system design principles - Data pipelines & ETL - Model deployment (APIs, Docker, CI/CD) - Inference optimization, monitoring - Edge AI, latency, and cost trade-offs |
- Study system design examples on Interview Query/GitHub AI system repos - Sketch architecture diagrams on paper or Miro - Practice describing trade-offs aloud |
Ability to explain end-to-end AI solutions clearly and logically |
| Day 10–14: Behavioral, Ethics & Mock Interviews | Refine communication, ethics, and real-world reasoning | - Explainable AI & Responsible AI - Model bias, fairness, and data reliability - STAR method for behavioral answers - Team collaboration & stakeholder communication - Mock interviews/take-home challenges |
- Use ChatGPT or Interview Query’s AI Interview Simulator - Review past AI project case studies - Conduct 1–2 mock interviews with peers |
Build confidence in soft skills and learn to connect technical depth with clarity |
Tip: Don’t try to memorize everything, focus on frameworks and reasoning. Interviewers are less interested in perfect recall and more in how you think through trade-offs and explain your decisions. End each day by writing a one-paragraph summary of what you learned, it helps reinforce key ideas for long-term retention.
Questions by Experience Level: Entry, Intermediate, Senior
Not all AI engineer interviews are created equal. What you’ll be asked depends a lot on where you are in your career and what kind of problems you’ve already solved.
An entry-level AI engineer interview might test your understanding of basic ML and Python, while a senior candidate could be asked to design large-scale AI infrastructure or discuss research-level optimizations.
This section breaks down what to expect at each stage of your career, so you can target your preparation smartly instead of studying everything under the sun.
Read more: OpenAI Interview Questions & Process Guide
Entry-Level AI Engineer Interview Questions
If you’re just starting out, interviewers want to see that you have a strong grasp of the fundamentals, both in theory and coding. Expect a mix of Python programming, linear algebra, statistics, and introductory machine learning questions.
They may ask you to implement small ML algorithms from scratch, interpret model metrics, or explain concepts like gradient descent, activation functions, and regularization. You might also get simple case studies, like predicting customer churn or image classification, to test how you apply basic ML workflows to real data.
The goal isn’t to catch you off guard but to check your problem-solving mindset and whether you can connect concepts to code.
Tip: Focus on clarity over complexity. When answering questions, walk through your logic step by step. Even if your final answer isn’t perfect, demonstrating a clear thought process often earns full marks in entry-level interviews.
-
This problem checks your ability to design a complete ML workflow from data exploration to evaluation. Begin with data cleaning and feature engineering to handle imbalance (using SMOTE or weighted classes). Split data into training and test sets, use models like Random Forest or XGBoost, and evaluate with precision, recall, and ROC-AUC. Emphasize explainability and real-time performance. It shows you understand both technical modeling and business risk in fraud detection.
Tip: Highlight how handling imbalanced data is critical in fraud detection to avoid false positives.
-
The question evaluates how you balance technical depth with communication. Justify using neural networks by discussing their ability to capture nonlinear relationships and large-scale data patterns. Explain interpretability with SHAP or LIME to make predictions transparent to stakeholders. It’s vital for AI engineers to bridge technical modeling with practical business reasoning.
Tip: Show that you can simplify complex models into actionable insights for non-technical teams.
What strategies would you use to prevent overfitting in tree-based classification models?
Here, interviewers want to see how you prevent overfitting in ML models. Mention techniques like pruning, setting max depth, or using regularization parameters such as
min_samples_split. Cross-validation and early stopping are also effective. Understanding overfitting shows your awareness of model generalization and reliability.Tip: Connect regularization techniques to their effect on improving model stability across unseen data.
-
This question checks your understanding of model selection and performance tracking. Start by explaining why a decision tree fits the problem (interpretable, handles categorical data). Evaluate using metrics like accuracy, precision, and recall, and track post-deployment performance with drift monitoring. It highlights your ability to choose practical, explainable solutions.
Tip: Emphasize model interpretability as a key reason for selecting decision trees in financial use cases.
-
This coding challenge measures your object-oriented programming and data structure design. Implement
__len__,__getitem__, and insertion methods while enforcing capacity constraints. Raise appropriate exceptions when full or out of range. Strong coding structure and defensive programming show precision and reliability—traits vital for AI system implementation.Tip: Demonstrate how thoughtful data structure design supports efficient model data handling.
-
This question assesses your grasp of window-based computation. Use iteration or cumulative sums to compute averages for each moving window. It demonstrates your ability to translate mathematical operations into efficient code, important for handling time-series and streaming data.
Tip: Point out how moving window averages are widely used in signal processing and anomaly detection tasks.
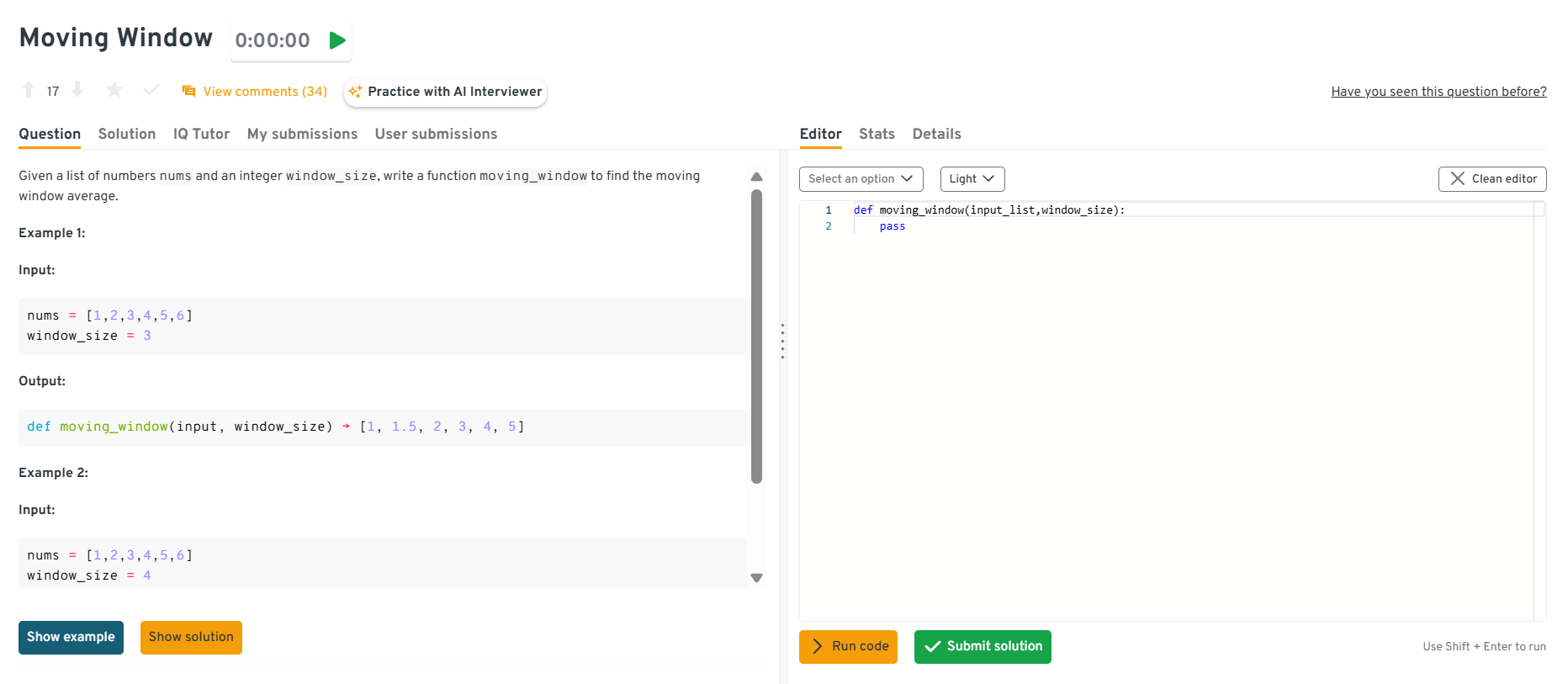
You can explore the Interview Query dashboard that lets you practice real-world AI Engineering interview questions in a live environment. You can write, run codes, and submit answers while getting instant feedback, perfect for mastering practical questions across domains.
-
Interviewers use this to test your knowledge of optimization fundamentals. Derive gradients for slope and intercept, then iteratively update parameters using a chosen learning rate. Explain how convergence works and how gradient descent minimizes errors. Understanding this foundation is crucial for tuning and training neural networks effectively.
Tip: Link your answer to how gradient descent powers learning in modern AI models.
-
This question checks your conceptual clarity and communication skills. Explain bias as underfitting (too simple) and variance as overfitting (too complex). Use examples like predicting exam scores with linear vs polynomial models. Simplifying technical ideas shows strong teaching ability, which is a valuable trait for cross-functional AI teams.
Tip: Use analogies when explaining, like balancing accuracy and consistency to make complex ideas relatable.
-
The goal here is to see if you can identify real-world challenges in NLP. Discuss data bias, slang, sarcasm, and evolving sentiment trends on WallStreetBets. Also, mention issues like overfitting to niche language patterns. It proves you can think critically about AI ethics, generalization, and robustness.
Tip: Mention that text data from social media needs constant retraining due to changing context.
-
This question focuses on your understanding of regularization in regression models. Explain that Lasso (L1) can shrink some coefficients to zero, performing feature selection, while Ridge (L2) shrinks coefficients evenly without eliminating them. Understanding this distinction helps tune models efficiently and avoid overfitting.
Tip: Emphasize that Lasso is great for simplifying models, while Ridge is ideal for multicollinearity control.
Intermediate (Mid-Level) AI Engineer Interview Questions
At this stage, interviewers want to see that you can build production-grade AI systems, not just models in notebooks. You’ll be tested on model deployment, scalability, monitoring, and debugging performance drift. Expect hands-on discussions around MLOps tools, cloud infrastructure, and data reliability.
The focus here is on how you connect data, models, and systems to deliver measurable impact at scale.
Tip: Always tie your answers back to reliability, reproducibility, and performance in production. That’s what separates mid-level engineers from entry-level ones.
-
This question checks algorithmic thinking and understanding of pointer manipulation. Use two pointers,
slowandfast, that traverse the list at different speeds. If they ever meet, a cycle exists. This method runs in O(n) time and O(1) space. It shows that you can write efficient, memory-conscious code, a valuable skill for systems handling large data streams.Tip: Mention Floyd’s cycle detection algorithm by name, it’s a common and elegant solution.
How would you design a scalable, fault-tolerant Azure Kubernetes infrastructure with Terraform?
This evaluates your system design and cloud deployment skills. Architect multiple availability zones with AKS (Azure Kubernetes Service), using Terraform for infrastructure automation. Include load balancers, autoscaling node pools, and monitoring with Azure Monitor. It demonstrates you can design resilient cloud-native architectures that meet enterprise standards.
Tip: Emphasize modular Terraform design and automated rollbacks to ensure continuous uptime.
How would you deploy a trained model on AWS SageMaker to serve 100 low-latency requests per second?
Here, interviewers test your AWS architecture understanding. Deploy the model to SageMaker endpoints behind an API Gateway with autoscaling enabled. Use CloudWatch for monitoring latency, request volume, and errors. Cache frequent predictions and use asynchronous inference if necessary. This reflects production awareness and cloud proficiency.
Tip: Highlight balancing between cost efficiency and real-time performance through autoscaling policies.
How would you handle a sudden performance drop in a deployed recommendation model?
This question focuses on model monitoring and debugging. Start by checking for data drift, feature quality degradation, or changing user behavior. Compare recent input distributions with training data and review retraining schedules. Proposing A/B tests and retraining workflows shows ownership and end-to-end awareness.
Tip: Stress the importance of proactive model observability to catch drift early.
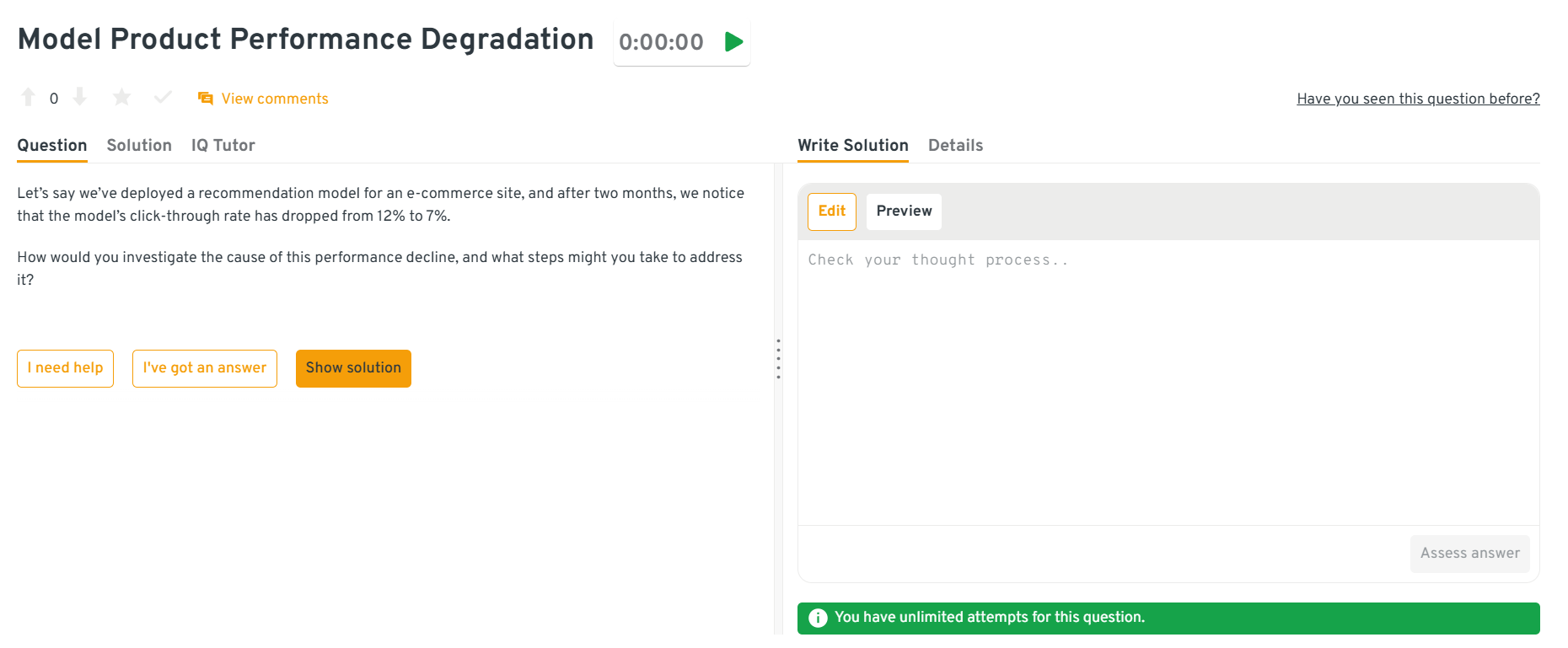
You can explore the Interview Query dashboard that lets you practice real-world AI Engineering interview questions in a live environment. You can write, run codes, and submit answers while getting instant feedback, perfect for mastering practical questions across domains.
How would you architect and integrate a feature store into an ML pipeline on AWS SageMaker?
You’re being tested on pipeline automation and data consistency. Use Amazon SageMaker Feature Store or Feast to centralize feature computation and storage. Integrate with S3 and Glue for batch and streaming ingestion, and serve real-time features to models during inference. This highlights your skill in productionizing reusable ML components.
Tip: Mention that feature stores reduce training-serving skew and speed up retraining cycles.
How would you design a scalable API deployment for a real-time ML prediction model on AWS?
Interviewers want to assess your deployment design skills. Use SageMaker endpoints or containerized models on ECS/Fargate behind an API Gateway. Enable autoscaling, caching, and load balancing, with metrics in CloudWatch. This demonstrates practical experience deploying production ML systems with reliability in mind.
Tip: Discuss using CI/CD pipelines to automate version control and rollback of models.
How would you investigate a one-hour drop in ride-hailing prices caused by an ML pricing model?
This tests your analytical reasoning and incident response approach. Form hypotheses such as data ingestion errors, feature latency, or API misconfigurations. Check logs, retraining history, and recent code deployments. This question shows your ability to debug live systems where ML meets operations.
Tip: Emphasize a structured debugging approach—data, model, infrastructure, in that order.
-
You’re being evaluated on real-time ML system design. Start with data preprocessing and training a binary classifier using historical transactions. Deploy a real-time inference API integrated with an SMS service like Twilio. When fraud is flagged, trigger alerts and capture user feedback for retraining. It highlights your understanding of end-to-end AI pipelines with feedback loops.
Tip: Stress using event-driven architecture (e.g., AWS Lambda + SNS) for low-latency alerts.
How would you determine whether a new delivery time model outperforms the existing one?
This question tests experimental design. Explain setting up an A/B test where one group sees predictions from the new model, the other from the old. Compare metrics like MAE and RMSE, plus customer satisfaction. It shows your understanding of model evaluation in real business terms.
Tip: Mention statistical significance testing to support objective model comparisons.
-
This examines your understanding of probability calibration. Use Bayes’ theorem to rescale predicted probabilities based on the true prevalence of each class. This ensures realistic outputs on the original data distribution. It demonstrates mastery of handling imbalance and statistical rigor.
Tip: Mention Platt scaling or isotonic regression for post-hoc probability calibration in production models.
Senior AI Engineer Interview Questions
At the senior level, interviews focus on architectural decisions, trade-offs, and leadership in building scalable AI systems. You’ll need to show mastery over transformers, multi-modal systems, and enterprise-grade deployment while communicating complex ideas with clarity and confidence.
Tip: Frame each answer with impact and show not just what you did, but why it mattered to the business or product.
-
This question gauges your understanding of transformer internals. Explain that self-attention computes attention weights via the dot product of Q and K, scaled by √dₖ, and applied to V. Masking ensures tokens only attend to past words during sequence generation. Mastering this shows deep knowledge of LLM architecture fundamentals.
Tip: Mention that masking enforces causal dependency, a key element for autoregressive generation.
How would you design a secure, context-aware customer support chatbot for a banking platform?
This tests your ability to blend NLP with data security. Describe integrating an LLM with strict data access controls, contextual retrieval from FAQs and transaction logs, and anonymized session-level memory. Include compliance (PCI-DSS) and real-time human fallback systems. It demonstrates leadership in designing safe, regulated AI systems.
Tip: Stress the importance of governance layers, since every financial AI system must prioritize user data privacy.
What is Parameter-Efficient Fine-Tuning (PEFT), and why use it instead of full model fine-tuning?
Interviewers want to see that you can optimize large models effectively. Explain that PEFT adapts only small parameter subsets (e.g., LoRA, adapters) instead of retraining the full model, saving compute and memory. It’s key for enterprise-scale AI where cost and deployment efficiency matter.
Tip: Mention that PEFT allows faster experimentation and easy rollback between tasks.
-
This checks your strategic modeling judgment. Clarify that RAG works best for dynamic, explainable retrieval; prompt engineering for quick prototypes; and fine-tuning for stable, domain-specific knowledge. As data grows, fine-tuning or hybrid (RAG + fine-tune) becomes optimal. This shows your ability to tailor methods to data maturity.
Tip: Highlight interpretability in regulated industries, transparent AI choices matter more than raw accuracy.
How would you design and de-bias a multi-modal AI system that generates marketing visuals and text?
This evaluates your awareness of bias and architecture. Explain using joint embeddings for text-image pairs and auditing outputs across demographics. Collect balanced datasets, apply fairness metrics, and include human review for brand safety. This demonstrates ethical and practical multi-modal AI design leadership.
Tip: Mention pre-launch bias audits, which is a must-have step for generative content systems.
How would you build a text-to-image retrieval system for an e-commerce platform?
This question focuses on embedding-based retrieval design. Propose dual-encoder models (e.g., CLIP) mapping text and images into shared embedding space, indexed with FAISS or ElasticSearch. Include feature normalization and relevance feedback. It shows your ability to connect AI models with production-scale retrieval systems.
Tip: Explain how embedding normalization and efficient indexing reduce latency under heavy traffic.
-
This assesses your understanding of retrieval-augmented pipelines. Describe chunking documents, embedding storage in vector databases, semantic retrieval, and summarization using hierarchical or map-reduce prompting. This ensures scalability and efficiency for long-context processing.
Tip: Stress on retrieval accuracy, chunk overlap and embedding quality are key to preserving context.
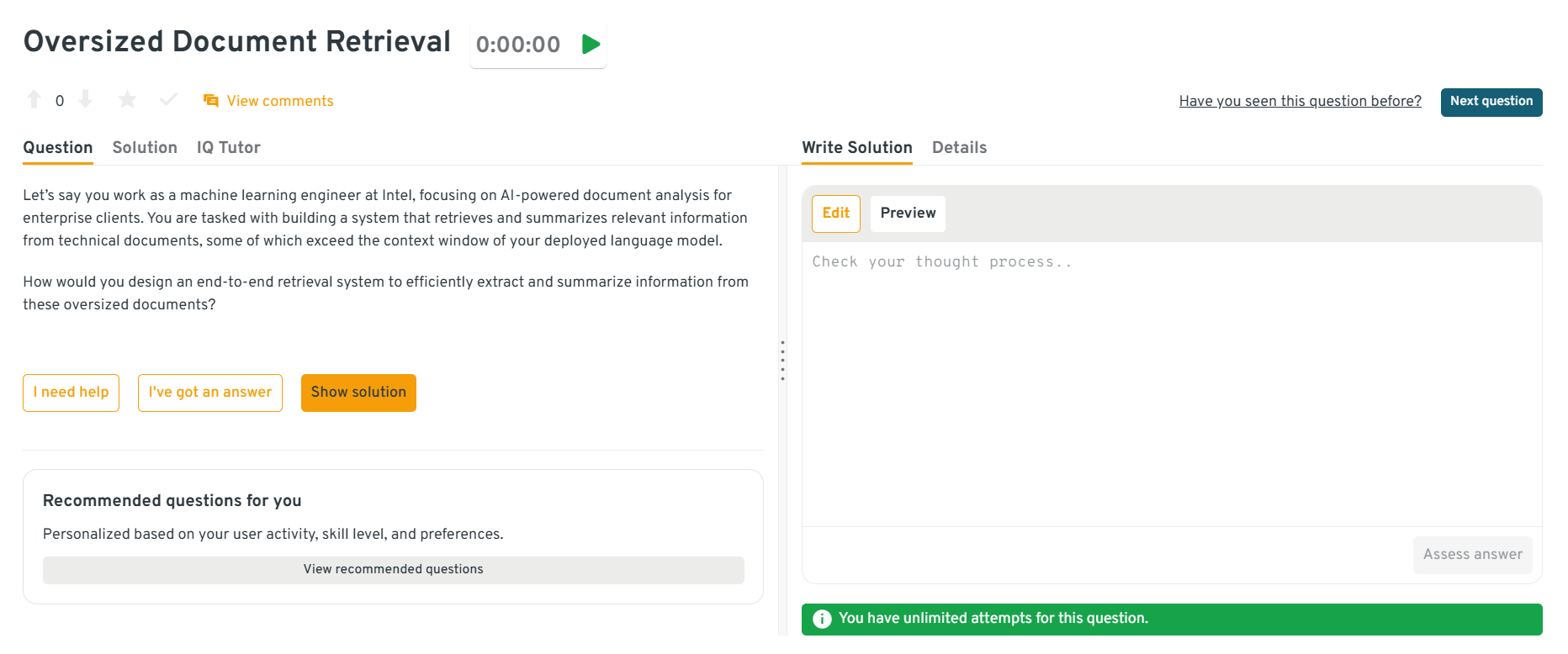
You can explore the Interview Query dashboard that lets you practice real-world AI Engineering interview questions in a live environment. You can write, run codes, and submit answers while getting instant feedback, perfect for mastering practical questions across domains.
-
This measures your infrastructure and scalability skills. Use model sharding, token streaming, and autoscaling clusters behind a load balancer. Include caching, request batching, and observability via metrics and tracing. This showcases your ability to engineer performant AI services.
Tip: Point out how batching and asynchronous inference drastically reduce GPU idle time.
-
This tests governance and architecture precision. Design a strict RAG pipeline where LLM access is restricted to retrieved documents only, using embeddings and context filters. Implement guardrails that reject responses not grounded in source data. This ensures compliance and factual reliability.
Tip: Mention grounding verification, and compare final answers against retrieved snippets for validation.
How would you architect an enterprise LLM-powered search tool for large-scale internal data?
This examines end-to-end enterprise search architecture. Describe using document chunking, embeddings via OpenAI or Cohere APIs, vector database indexing, and RAG for contextual retrieval. Add role-based access, observability, and model feedback loops. It highlights leadership in building secure, scalable AI systems.
Tip: Include access control and ranking feedback loops to maintain search accuracy and compliance.
Core Technical Interview Questions (With Model Answers)
This is the heart of every AI engineer interview. It’s where theory meets code, and where your ability to translate concepts into working solutions truly shines.
Expect a mix of coding challenges, conceptual questions, and applied problem-solving scenarios covering everything from neural networks and transformers to optimization, feature engineering, and prompt design.
Your answers don’t need to be long, they need to be logical, structured, and aware of real-world trade-offs. Here are some examples of how you can frame your responses.
Read more: Deloitte AI Engineer Interview Questions & GenAI Guide
How does backpropagation work in neural networks?
Backpropagation computes the gradient of the loss function with respect to each weight by applying the chain rule through the network layers. These gradients are then used to update the weights via gradient descent. The process continues iteratively until the loss converges or reaches a minimum threshold. Clear understanding of how partial derivatives flow backward helps in tuning models and debugging training issues.
Tip: Emphasize that you monitor vanishing or exploding gradients during training, interviewers love when you connect math to practical debugging.
What are the main differences between CNNs and RNNs?
Convolutional Neural Networks (CNNs) are best suited for spatial data like images since they capture local patterns through filters and pooling layers. Recurrent Neural Networks (RNNs), on the other hand, process sequential data, retaining temporal dependencies across time steps. CNNs excel in vision tasks, while RNNs are strong for time-series or text-based inputs.
Tip: Add that transformers now outperform RNNs in sequence tasks by removing recurrence, showing you stay updated with current architectures.
How would you handle missing data during feature engineering?
First, determine whether the missingness is random or systematic. For numerical features, you can impute with mean, median, or model-based estimates. For categorical variables, mode or a “missing” token can be used. Dropping columns is only advisable if the feature has little predictive value. Always validate post-imputation distributions to avoid bias.
Tip: Mention that you’d log imputation steps in an ML pipeline for reproducibility, which is a signal of mature engineering practice.
Explain how transformers work and why they replaced RNNs.
Transformers use self-attention to capture dependencies between tokens without sequential processing. This parallelization drastically speeds up training and allows for modeling long-range relationships in text. Each token attends to all others, weighted by attention scores. Layers of multi-head attention and feedforward blocks build contextual embeddings, which made models like BERT and GPT possible.
Tip: Tie your answer to deployment, e.g., mention using quantization or distillation to make transformer inference more efficient in production.
How would you explain GANs to a non-technical stakeholder?
GANs (Generative Adversarial Networks) consist of two models, a generator that creates fake samples and a discriminator that tries to distinguish them from real ones. Both models train in opposition, improving each other iteratively until the generator’s outputs become realistic. The concept can be explained as a “forger versus detective” game where both improve over time.
Tip: Mention you’d visualize training stability using loss curves, it shows you understand the practical challenges of GAN convergence.
How do you choose the right optimization algorithm for model training?
Choice depends on problem size and data behavior. SGD is efficient for large datasets but may oscillate near minima; Adam adapts learning rates per parameter and is great for most deep learning tasks. RMSProp and Adagrad handle sparse gradients well. Understanding each optimizer’s bias toward speed or stability helps in selecting the right one for convergence efficiency.
Tip: Explain how you tune learning rates or use schedulers since practical insight often matters more than naming algorithms.
How do you evaluate an imbalanced classification model?
Accuracy alone is misleading. Use precision, recall, F1-score, or AUC to reflect the model’s performance on minority classes. Techniques like SMOTE, class weighting, or threshold tuning can also balance outcomes. Frame your reasoning around the business impact — for instance, preferring higher recall in fraud detection to avoid missing risky cases.
Tip: Add that you’d visualize results with a confusion matrix and validate metrics using
classification_report()to confirm robustness.What is prompt engineering and why is it important in AI applications?
Prompt engineering is the process of designing and refining textual inputs to guide large language models toward accurate and consistent responses. Effective prompts provide clear instructions, role context, and sometimes examples. Techniques like few-shot prompting, chain-of-thought reasoning, and RAG (retrieval-augmented generation) are increasingly vital for production-grade LLM systems.
Tip: Mention that you iterate on prompt phrasing using evaluation metrics like factual accuracy or BLEU score, showing an experimental approach to prompt design.
System Design and Real-World Case Studies
One of the most telling parts of an AI engineer interview is the system design round, where you’re asked to design an AI-powered system from scratch. This stage tests your ability to think beyond algorithms and understand how AI fits into real-world engineering.
Here, interviewers evaluate how well you can break down complex problems, reason about scalability, handle trade-offs, and design end-to-end pipelines that are both efficient and reliable. You’re not just expected to know what model works, but how that model fits into a larger architecture.
Read more: Top 17 Machine Learning Case Studies to Look Into Right Now
Let’s walk through a few examples of what these case studies look like in practice.
Design an AI-Powered Recommendation System
A classic interview question might be:
“Design a movie recommendation system for a streaming platform like Netflix.”
Start with problem definition, recommending personalized movies based on user behavior. Outline your data pipeline: user history, watch time, ratings, and metadata (genre, actors, etc.).
Next, discuss your modeling approach:
- Begin with collaborative filtering for initial user-item mapping.
- Then, integrate content-based embeddings using NLP to capture similarity between movies.
- For scale, mention using a hybrid model combining embeddings with user-event logs.
Finally, talk about serving and monitoring: caching top results, updating recommendations asynchronously, and tracking performance via CTR or engagement metrics.
Tip: Interviewers love it when you mention iteration, e.g., “I’d A/B test between embeddings and hybrid models to measure improvements in recommendation diversity.”
Build a Real-Time Fraud Detection Pipeline
Another common case study:
“Design a real-time fraud detection system for credit card transactions.”
Here, start by explaining the data ingestion layer, which includes streaming transactions from sources like Kafka or AWS Kinesis. Discuss feature extraction (transaction amount, geolocation, device ID, past behavior) and handling data drift through real-time monitoring.
For the model, describe a hybrid approach: a supervised classifier (like XGBoost) for known fraud patterns and an unsupervised anomaly detector (like autoencoders or isolation forests) for new patterns.
Then, highlight the deployment layer, which includes scoring models through REST APIs or a lightweight inference server, ensuring latency < 100ms. Conclude with monitoring and feedback loops to retrain models periodically.
Tip: Always mention trade-offs, for example, “I’d prioritize low false negatives to catch fraud early, even if it slightly increases false positives.” It shows you understand business risk.
Conceptual Breakdown: Designing for Scalability and Inference Optimization
Sometimes interviewers skip a concrete problem and ask something broader, like:
“How would you scale a deep learning model for real-time inference?”
Here, outline key stages:
- Model compression: Use pruning, quantization, or knowledge distillation to reduce latency.
- Batching and caching: Serve predictions in micro-batches for efficiency.
- Hardware optimization: Deploy on GPUs, TPUs, or edge devices depending on latency and cost needs.
- Monitoring: Track throughput, latency, and prediction drift; retrain when performance dips.
You can also mention multi-model serving (for fallback or AB testing), and frameworks like TensorRT, ONNX, or FastAPI for optimized inference pipelines.
Tip: Don’t stop at the design, always describe how you’d measure success. Saying “I’d monitor latency under 50ms while maintaining AUC above 0.95” shows data-driven engineering maturity.
By mastering how to design scalable, explainable, and resilient systems, you’ll stand out as more than just a model builder, you’ll demonstrate that you can own the full AI lifecycle from concept to deployment.
Reliability, Ethics, and Explainability in AI Engineering
As AI systems become more complex and influential, interviews increasingly include questions that go beyond technical performance. Companies now want AI engineers who can build systems that are not just powerful but reliable, fair, and transparent.
This section covers three essential areas: reliability, ethics, and explainability, all of which demonstrate that you understand what it takes to deploy AI responsibly in the real world.
Reliability: Building Trustworthy AI Systems
Expect interviewers to ask questions like:
“How do you ensure the reliability of an AI model in production?”
“What steps would you take if your model performance suddenly drops?”
A strong answer focuses on monitoring, testing, and retraining. Explain that reliability in AI engineering means ensuring consistent, predictable behavior across environments. This involves tracking key metrics like accuracy, drift, latency, and uptime. Implement continuous evaluation pipelines that detect when input data changes or model accuracy degrades.
You can also mention redundancy and fallback systems, for instance, reverting to a simpler baseline model if the main model fails in production.
Tip: Mention that you’d integrate automated retraining triggers based on data drift thresholds, it shows you understand real-world reliability and maintenance cycles.
Ethics: Ensuring Fairness and Responsible AI Use
Ethical awareness has become a cornerstone of AI engineer interviews, especially for roles in industries like finance, healthcare, or social platforms. Interviewers may ask:
“How do you detect and mitigate bias in a machine learning model?”
“What ethical concerns would you consider when designing an AI system for hiring or lending?”
Explain that AI ethics begins with data by identifying and addressing bias in datasets, ensuring diverse representation, and performing fairness audits using metrics like demographic parity or equalized odds. Then move to model-level interventions such as reweighting or adversarial debiasing.
You can also highlight the importance of transparency and consent, particularly when using user-generated or sensitive data.
Tip: A great way to stand out is by referencing frameworks like IBM AI Fairness 360 or Google’s Responsible AI Principles, it signals that you’re aware of best practices and industry standards.
Explainability: Making AI Decisions Understandable
Expect prompts such as:
“How would you explain a model’s predictions to a non-technical audience?”
“What tools or techniques do you use for explainable AI?”
Start by explaining that explainable AI (XAI) aims to make model decisions interpretable and justifiable. Mention methods like SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations), or attention visualization in neural networks.
In practice, you might use these tools to identify feature importance or detect bias in predictions. For communication, stress the importance of contextual clarity by translating technical metrics into simple business insights.
Tip: When discussing explainability, emphasize the audience. For example, “I use SHAP plots for the data science team but summarize results as decision narratives for business stakeholders.” This shows empathy and adaptability.
By mastering these three pillars of reliability, ethics, and explainability, you’ll demonstrate the maturity and judgment companies seek in senior-level AI engineers. These are the qualities that distinguish a model developer from an AI system architect who can build technology people actually trust.
Behavioral & Cross-Functional Interview Questions
By this stage of the AI engineer interview, you’ve already proven your technical ability. Now, interviewers want to understand how you think, collaborate, and communicate, especially in fast-paced, cross-functional teams.
These questions reveal your ability to translate AI concepts into real-world impact, handle setbacks, and align with stakeholders who might not speak the same technical language. Great answers balance clarity, humility, and measurable results.
Read more: Top 32 Data Science Behavioral Interview Questions
Here are some common examples of what to expect and how to approach them.
Tell me about a time when your model underperformed. What did you do next?
Start by describing the situation briefly: what the project was, what the performance issue was, and how you diagnosed it. Then, walk through the steps you took, such as data audits, feature reengineering, model tuning, or cross-validation. End by mentioning the final outcome, like improving accuracy by a measurable percentage or identifying a root cause that prevented future issues.
Tip: Use the STAR method (Situation, Task, Action, Result) to keep your answer structured. Interviewers value process-oriented thinking over quick fixes.
How do you communicate complex AI results to non-technical stakeholders?
Explain that you simplify results without oversimplifying meaning. You might use visual aids (feature importance plots, confusion matrices, dashboards) and focus on outcomes that matter to the audience, like revenue impact or efficiency gains. Clarity and relevance are your priorities, not jargon.
Tip: Mention how you tailor your message, like “For executives, I summarize business impact; for engineers, I explain the model’s reasoning and limitations.” It shows strong communication range.
Describe a time you had a disagreement with a teammate over an AI approach. How did you handle it?
Start by acknowledging that technical disagreements are normal. Share an example where you listened to your teammate’s perspective, proposed an experiment or A/B test to validate both ideas, and used results to make the final call. Emphasize that collaboration and data-driven reasoning guided your decision.
Tip: Avoid framing anyone as “wrong.” Instead, highlight your objectivity and emotional intelligence in resolving conflict with evidence, not ego.
How do you balance model performance with ethical or business constraints?
Explain that you weigh accuracy against fairness, interpretability, and compliance. For instance, you might cap model complexity to maintain explainability in regulated domains, or adjust class weights to reduce bias. Mention involving stakeholders early when ethical trade-offs arise.
Tip: Reference real-world implications, e.g., “In healthcare, a false positive might be acceptable, but a false negative could be dangerous.” It shows awareness of context and consequences.
What’s an example of cross-functional collaboration you’re proud of?
Describe a project where you worked with teams outside data science, perhaps integrating with a product or DevOps team. Explain how you aligned timelines, managed dependencies, and ensured your AI component fit smoothly into production. End with a clear, quantifiable success metric.
Tip: Highlight your adaptability, for example, “I adjusted my workflow to sync with the product sprint cadence.” This signals strong collaboration and execution skills.
Tool-Specific Question Banks (Skimmable)
Every company’s AI stack looks a little different, but interviewers still expect you to be fluent in the tools that drive modern AI development.
From model-training frameworks to cloud-native infrastructure and deployment platforms, these questions test how hands-on and adaptable you are with production-grade ecosystems.
Below, we’ve grouped the most common AI engineer interview questions by category so you can focus your review where it matters most.
Frameworks and Libraries (PyTorch, TensorFlow, Hugging Face, scikit-learn, OpenCV)
These questions check whether you can move seamlessly between research and production code. Companies expect familiarity with at least one deep-learning framework (usually PyTorch or TensorFlow) and awareness of ecosystem tools for model building and experimentation.
How do PyTorch and TensorFlow differ in workflow and deployment?
PyTorch uses a dynamic computation graph, making it more intuitive for experimentation and debugging, while TensorFlow’s static graph allows optimized deployment on devices and servers. In practice, PyTorch dominates in research; TensorFlow still leads in large-scale enterprise serving.
Tip: Add that you’d convert trained PyTorch models to ONNX for cross-framework deployment — this shows production-readiness.
How would you fine-tune a pretrained Hugging Face model for text classification?
Load a transformer like
bert-base-uncased, replace the classification head, and train on your labeled dataset using the Trainer API. Use a low learning rate (2e-5 – 5e-5) and monitor validation F1-score to prevent overfitting.Tip: Mention saving model checkpoints to the Hub — it signals awareness of MLOps best practices.
What is the role of scikit-learn pipelines in ML workflows?
Pipelines bundle preprocessing and modeling steps into one object, ensuring reproducibility and avoiding data leakage during cross-validation.
Tip: Note that wrapping transformers in
ColumnTransformermakes mixed numeric + categorical workflows maintainable.How would you perform image augmentation efficiently in OpenCV or PyTorch?
Apply transformations like rotation, flipping, cropping, and color jittering either offline (dataset expansion) or on-the-fly with PyTorch’s
torchvision.transforms.Tip: Add that you’d balance augmentation strength with label preservation — shows domain awareness.
When would you choose gradient accumulation or mixed-precision training?
Use gradient accumulation to simulate larger batch sizes under GPU memory limits; mixed-precision halves memory usage and speeds up training on supported hardware.
Tip: Mention verifying numerical stability via loss-scaling — it shows depth beyond memorization.
Cloud Platforms (AWS, Azure, GCP)
AI engineers are increasingly judged by their ability to ship and scale. These questions assess how you integrate models with managed cloud services for storage, training, and inference.
How do you train and deploy models on AWS SageMaker?
SageMaker manages the full ML lifecycle — you define training jobs with built-in or custom containers, store artifacts in S3, and deploy endpoints that auto-scale.
Tip: Bring up cost control — e.g., “I enable spot instances and auto-termination to manage training spend.”
What’s the difference between Azure Machine Learning and Azure Synapse for AI tasks?
Azure ML focuses on model training, MLOps, and deployment, while Synapse handles analytics and large-scale data warehousing. Together, they form the analytics-to-AI pipeline.
Tip: Mention using Azure ML pipelines with Synapse datasets for end-to-end automation — shows architectural fluency.
How does Google Cloud Vertex AI simplify model management?
Vertex AI unifies AutoML, custom training, and model registry under one API. It streamlines experimentation and monitoring with minimal infrastructure management.
Tip: Add that you’d use Vertex AI Model Monitoring for drift detection — it shows awareness of post-deployment reliability.
What strategies improve cost efficiency when running large training jobs in the cloud?
Use spot/preemptible instances, distributed training, data locality (storing data near compute), and efficient checkpointing to reduce re-runs.
Tip: Always connect cost savings to impact — “cut training time 30% and cost 25% via distributed data-parallel setup.”
How do you secure sensitive model data in cloud environments?
Encrypt data at rest and in transit, apply least-privilege IAM policies, rotate keys (AWS KMS/GCP KMS), and restrict access via private endpoints.
Tip: Mention compliance (GDPR, HIPAA) if relevant — shows you think like an engineer in regulated settings.
Deployment, MLOps, and Infrastructure Tools (Docker, Kubernetes, MLflow, Airflow, FastAPI)
These tools bridge the gap between prototype and production. Interviewers look for engineers who can containerize, orchestrate, and monitor AI systems reliably.
How would you deploy a trained model using FastAPI?
Expose the model as a REST endpoint by loading it in memory and defining
/predictroutes. Useuvicornfor serving and pydantic for request validation.Tip: Mention setting up batch vs real-time endpoints — it shows you understand different inference modes.
Why is Docker essential for AI engineering workflows?
Docker packages code, dependencies, and runtime into portable containers, ensuring reproducibility across environments. It also simplifies CI/CD integration.
Tip: Reference lightweight images (e.g.,
python:3.11-slim) to highlight efficiency awareness.How does Kubernetes help scale AI workloads?
Kubernetes orchestrates containers, enabling horizontal scaling, GPU scheduling, and automatic recovery. Ideal for distributed training or multi-model serving.
Tip: Add that you’d use custom resource definitions (CRDs) like Kubeflow Jobs for ML-specific workloads — a great bonus detail.
What role does MLflow play in the MLOps lifecycle?
MLflow tracks experiments, versions models, and manages deployment through its registry. It creates reproducible runs and simplifies model promotion between stages.
Tip: Tie it to collaboration — “It ensures reproducibility when multiple data scientists experiment in parallel.”
How would you orchestrate retraining pipelines with Airflow?
Define a DAG that schedules data extraction, retraining, validation, and model upload to the registry. Airflow’s task dependencies ensure reliable sequencing and alerting.
Tip: Mention integrating Airflow with Slack or email notifications — it signals operational maturity.
Salary Negotiation, Career Growth, and Remote Work
AI engineering isn’t just one of the most in-demand jobs, it’s one of the highest-paid across the entire tech industry. But while companies are eager to hire, salary ranges vary widely depending on experience, specialization, and location.
So before you walk into your next AI engineer interview, it’s essential to know what the market looks like, and how to negotiate from a position of confidence.
AI Engineer Salary Trends (2025-2026)
| Experience Level | U.S. Salary Range (Annual) | Top Employers Hiring | Notes |
|---|---|---|---|
| Entry-Level/Junior AI Engineer | $100K – $140K | Google, NVIDIA, Meta, startups (Series A–C) | Typically includes base salary + sign-on bonus; some roles overlap with ML Engineer I. |
| Mid-Level AI Engineer | $140K – $190K | Amazon, Microsoft, OpenAI, Tesla | Often includes stock grants and quarterly performance bonuses; remote/hybrid flexibility is common. |
| Senior AI Engineer/Research Engineer | $190K – $260K+ | DeepMind, Anthropic, Meta FAIR, Apple AI | High demand for LLMs, multimodal systems, and production AI experience; strong equity packages offered. |
| AI Engineering Manager/Lead | $230K – $350K+ | OpenAI, Netflix, Meta, Google DeepMind | Compensation blends high base pay, stock units, and leadership bonuses tied to product milestones. |
Data Source: Levels.fyi, Glassdoor, and Indeed AI salary aggregates (Q3 2025).
Remote-first companies like Anthropic, Hugging Face, and Stability AI report remote salary parity with on-site roles in major U.S. metros.
Tip: Always benchmark by total compensation, not just base pay. Equity, bonuses, and cloud credits for AI experimentation can add 20–40% to your real annual package.
Career Growth Paths in AI Engineering
AI engineers often evolve into one of three tracks as they gain experience:
Applied AI/ML Engineering → Focused on building deployable products and optimizing inference pipelines.
Example roles: ML Engineer II, Applied Scientist, Model Deployment Specialist.
AI Research & Architecture → Emphasizing foundational model design, LLM tuning, and multi-modal systems.
Example roles: Research Engineer, Generative AI Specialist, AI Architect.
MLOps & Infrastructure Leadership → Managing scalable training, serving, and monitoring across teams.
Example roles: AI Platform Engineer, MLOps Lead, Director of AI Infrastructure.
Growth here is rarely linear, the strongest engineers combine all three: research intuition + system design + operational reliability.
Tip: Keep a portfolio of measurable outcomes, like “Reduced model inference time by 30%,” “Deployed multimodal pipeline on GCP with 99.9% uptime.” Concrete results fuel promotions and salary increases.
Negotiation Scripts for AI Engineers
Most candidates under-negotiate simply because they don’t have a plan.
Here are a few ready-to-use negotiation frameworks tailored for AI roles, whether you’re at the offer stage or negotiating a raise.
Scenario 1: After Receiving an Offer
“I’m really excited about the opportunity to contribute here, especially on the LLM optimization work.
Based on my research and market data from Levels.fyi, I’d expect a total compensation around $180K–$190K, which aligns with similar AI engineer roles in this market.
Is there flexibility in adjusting the base or stock component to bring the offer closer to that range?”
Why it works: It’s polite, data-driven, and expresses enthusiasm while anchoring your counteroffer to credible benchmarks.
Scenario 2: Negotiating with Competing Offers
“I wanted to share that I’m currently in the final stages with another team offering around $200K total compensation, but I’m genuinely more interested in your AI platform’s vision.
If you could match or come closer to that range, I’d be happy to commit right away.”
Why it works: You’re transparent but respectful. It frames the conversation as an opportunity for them to secure a motivated candidate.
Scenario 3: Requesting a Raise or Adjustment Post-Hire
“Over the past year, I’ve scaled our inference system to handle a 3x increase in traffic and deployed two new AI models into production with measurable revenue impact.
Given this contribution and recent market adjustments, I believe my compensation could be realigned to the $200K+ range typical for Senior AI Engineers at similar orgs.
Could we revisit my compensation at the next review cycle?”
Why it works: Anchors the ask to impact, not tenure, showing business alignment rather than entitlement.
Remote & Hybrid Work in AI Engineering
Remote AI work isn’t just possible, it’s thriving. Over 60% of surveyed AI engineers in 2025 report fully remote or hybrid setups, especially for roles in model development, evaluation, and prompt engineering.
However, on-site roles remain common for positions requiring secure data access, hardware integration, or collaborative model experimentation.
Remote advantage:
- Access to global companies without relocation.
- Asynchronous workflows powered by MLOps tools (Weights & Biases, Neptune.ai, Airflow).
- Pay parity in many U.S. regions (especially after 2024’s shift toward remote compensation normalization).
Tip: When interviewing remotely, emphasize ownership and communication like “I document experiments, version models, and proactively sync with teams.” Recruiters see that as proof you can excel without constant supervision.
AI Engineer Projects and Portfolio Building
If there’s one thing that can instantly differentiate you in an AI engineer interview, it’s a portfolio that proves what you can build.
Hiring teams no longer just want to hear about your experience, they want to see it. Whether it’s a neural network for healthcare diagnostics, an LLM-powered chatbot, or an optimization pipeline running on the cloud, your portfolio is your real calling card.
This section will show you how to design a professional, recruiter-friendly AI engineer portfolio, what types of projects to include, and how to present them effectively.
Choosing the Right AI Engineer Portfolio Format
Your portfolio should be visual, modular, and verifiable, something that can be explored quickly and shared easily during interviews. Here are the most effective formats:
GitHub Repository (Core Requirement)
Every AI engineer should maintain a clean, well-documented GitHub repo.
- Organize by project folder → notebooks → README.md → demo links.
- Include environment files (
requirements.txt,Dockerfile, orenvironment.yml). - Pin your top 3–4 repositories at the top of your profile.
- Add concise READMEs with results, visualizations, and model explanations.
Example:
- Brain Tumor Classifier: CNN + TensorFlow + Streamlit demo.
- MediBot: Medical chatbot using LangChain + FastAPI.
- MLOps Pipeline: Automated training and deployment with Airflow + MLflow.
Tip: Add concise “How it works” GIFs or Colab badges in READMEs, since they grab attention instantly.
Personal Website or Portfolio Page
Your website is your professional identity hub. Tools like GitHub Pages, Notion, or Webflow make it easy to set up.
Include:
- A 2–3 sentence headline summary (“AI Engineer specializing in multimodal and healthcare models”).
- Sections for Projects, Resume, Publications, and Contact.
- Embedded demos or YouTube walkthroughs for live model interactions.
Tip: Recruiters spend under 90 seconds on a portfolio. Make your homepage scannable with visual project cards, not walls of text.
Interactive Demos and Notebooks
Interactive content (like Colab, Hugging Face Spaces, or Streamlit apps) gives life to your work.
- Use Hugging Face Spaces for hosting public model demos.
- Streamlit/Gradio are perfect for lightweight frontends.
- Jupyter notebooks work for step-by-step narratives (training → inference → evaluation).
Tip: Always include versioned datasets or links to open-source data sources. Reproducibility earns major bonus points.
Portfolio Project Types That Impress Interviewers
Your portfolio should highlight breadth and depth. The best strategy is to showcase 3–5 polished projects across different AI engineering domains, each with a clear problem statement, methodology, and measurable outcome.
| Category | Focus Area | Example Projects |
|---|---|---|
| Foundation Models & NLP | LLMs, text generation, summarization, or prompt engineering | - RAG-powered chatbot using LangChain + OpenAI API - Fine-tuning BERT for sentiment classification on IMDB dataset - Multi-document summarizer with Hugging Face transformers |
| Computer Vision & Multimodal AI | CNNs, diffusion models, and visual-text understanding | - Brain tumor detection with CNN + Grad-CAM visualization - Diffusion model for AI art generation - Multimodal captioning system using CLIP embeddings |
| MLOps and Production AI Systems | Deployment, automation, and monitoring workflows | - Model retraining workflow with Airflow DAGs + MLflow - Dockerized FastAPI inference service on AWS Lambda or GCP Cloud Run - Data drift detection pipeline using EvidentlyAI or Great Expectations |
| Applied AI for Social or Business Impact | Human-centered or business-driven AI solutions | - Predictive model for hospital readmissions (healthcare) - Retail demand forecasting using LSTMs (business analytics) - Toxic comment detector for online safety (ethics in AI) |
How to Present Projects During Interviews
Even the best project falls flat if you can’t explain it clearly. Interviewers want to see how you think.
When walking through a project:
- Start with the problem: What was the goal? Why did it matter?
- Explain your role: What decisions did you make?
- Summarize technical depth: Key models, frameworks, and design choices.
- Discuss results: Metrics, trade-offs, or lessons learned.
- End with reflection: How you’d improve it next time or scale it further.
Tip: Use a storytelling pattern of Problem → Approach → Impact. It keeps your answer concise and memorable.
Common Mistakes to Avoid
- Listing every small assignment - focus on quality over quantity
- Neglecting README clarity or project documentation.
- Sharing private datasets without anonymization.
- Forgetting reproducibility - missing dependencies frustrate reviewers
- Overcomplicating explanations - clarity always beats complexity
Tip: Have one “flagship” project that ties to your career goal (e.g., healthcare AI, multimodal systems). It’s better to go deep on one great case study than spread too thin.
FAQs: AI Engineer Interview Preparation
What technical skills are essential for an AI engineer interview?
AI engineers need strong foundations in machine learning, deep learning, and software engineering. Core skills include Python (NumPy, pandas, PyTorch, TensorFlow), data preprocessing, neural networks, optimization, and cloud or MLOps tools like Docker, Kubernetes, and AWS SageMaker. Interviewers expect fluency in both theory and implementation.
How do AI engineer interviews differ from ML engineer interviews?
While ML engineers focus on building and evaluating models, AI engineers emphasize deploying, scaling, and integrating models into production systems. Expect more system design and MLOps questions, covering topics like pipeline reliability, model monitoring, and inference optimization.
What are common behavioral questions in AI interviews?
Behavioral questions test collaboration, ownership, and communication. You might be asked about handling model failures, resolving technical disagreements, or explaining AI results to non-technical stakeholders. Use the STAR method (Situation, Task, Action, Result) to give structured, impactful answers.
How can I showcase my AI projects during the interview?
Explain each project clearly: define the problem, describe your approach, highlight measurable outcomes, and share what you learned. Live demos or short videos help make your work memorable. Focus on results that show real-world impact—accuracy gains, reduced latency, or automation improvements.
Is remote work common for AI engineers?
Yes. Most AI teams are now hybrid or fully remote, especially in research and deployment roles. Companies expect strong self-management, communication, and documentation habits. Demonstrating autonomy and consistency is key to succeeding in remote AI roles.
How do I negotiate salary for an AI engineer position?
Base your discussion on verified data from sources like Levels.fyi or Teamblind. Express your expectations confidently, tying them to your expertise and business impact. Discuss total compensation, not just base pay, and negotiate after receiving a formal offer.
What are best practices for preparing for an AI engineer interview in 2025?
Focus on deep learning fundamentals, AI system design, and deployment pipelines. Practice explaining trade-offs between performance, cost, and reliability. Build one strong, end-to-end project that shows practical application, and rehearse concise, confident storytelling for both technical and behavioral rounds.
Conclusion and Further Resources
Preparing for an AI engineer interview doesn’t end with theory, it’s about staying sharp, connected, and consistent. Whether you’re aiming for your first AI role or stepping into a senior position, focus on continuous learning, hands-on projects, and community engagement. Below are some trusted resources to keep your momentum strong.
Ready to ace your next AI Engineer interview? Start with our AI Engineer Question Bank to practice real AI and ML interview questions with detailed explanations and guided solutions. Sign up for Interview Query to test yourself with Mock Interviews today.
If you need 1:1 guidance on your interview strategy, explore Interview Query’s Coaching Program that pairs you with mentors to refine your prep and build confidence.
Keep Practicing and Building
- LeetCode/HackerRank - Sharpen your coding and algorithmic reasoning skills
- Kaggle - Explore real datasets, publish notebooks, and learn from top data scientists
- Hugging Face Courses - Learn transformers, fine-tuning, and model deployment with hands-on labs
- Google Cloud ML Labs/AWS ML Labs - Build, train, and deploy models on industry-grade platforms
Join AI Communities
- MLOps Community - Stay ahead with live discussions, meetups, and best practices.
- Weights & Biases Slack - Network with engineers optimizing real production ML pipelines.
- LinkedIn AI Groups - Follow top AI researchers, hiring managers, and innovators.
- Reddit: r/MachineLearning/r/Artificial - Engage in deep technical debates and share your projects for feedback.
Read and Reflect
- Deep Learning with Python by François Chollet
- Designing Machine Learning Systems by Chip Huyen
- Building Machine Learning Pipelines by Hannes Hapke & Catherine Nelson
Your Next Step
Don’t stop here, take what you’ve learned and build something that matters. Create a new AI project this week, share it on GitHub or LinkedIn, and join a community, discuss your challenges, and refine your craft.
Every model you train, every question you practice, and every project you ship moves you closer to mastering AI engineering. You can access several recently asked AI engineering interview questions in actual interviews on Interview Query!
Keep learning. Keep experimenting. And keep building the future of AI.