

The 2021 Data Science Interview Report

Overview
We analyzed over 10,000 data science-related interview experiences. Specifically, we were looking at:
- How did Covid-19 change data science interviews in 2020?
- What question topics were asked most frequently?
- How do FAANG (Facebook, Amazon, etc..) data science interviews differ from other companies?
- What are the fastest growing data science positions?
Our Summary Findings
Growth in data science interviews plateaued in 2020. Data science interviews only grew by 10% after previously growing by 80% year over year.
FAANG companies, however interviewed 25% more data science candidates in 2020 versus 2019.
Data engineering-specific interviews increased by 40% in the past year. The second fastest position growth within data science roles went to business and data analysts, which increased by 20%.
The top interview question topics in 2020 for data science roles were: machine learning, coding and algorithms, and statistics.
FAANG companies all have different requirements for their data science roles. Together their interviews focused more on coding and algorithms, SQL, and machine learning.
Take-home challenges were given in 25% of all data science-related interviews. In FAANG interviews, take-home challenges were only given 8% of the time.
Data science might be cooling down
In 2020 we saw a global hiring freeze that definitely cooled down the job market. However, the data shows that while the number of data science interviews is still growing, it’s not at the same pace as before.
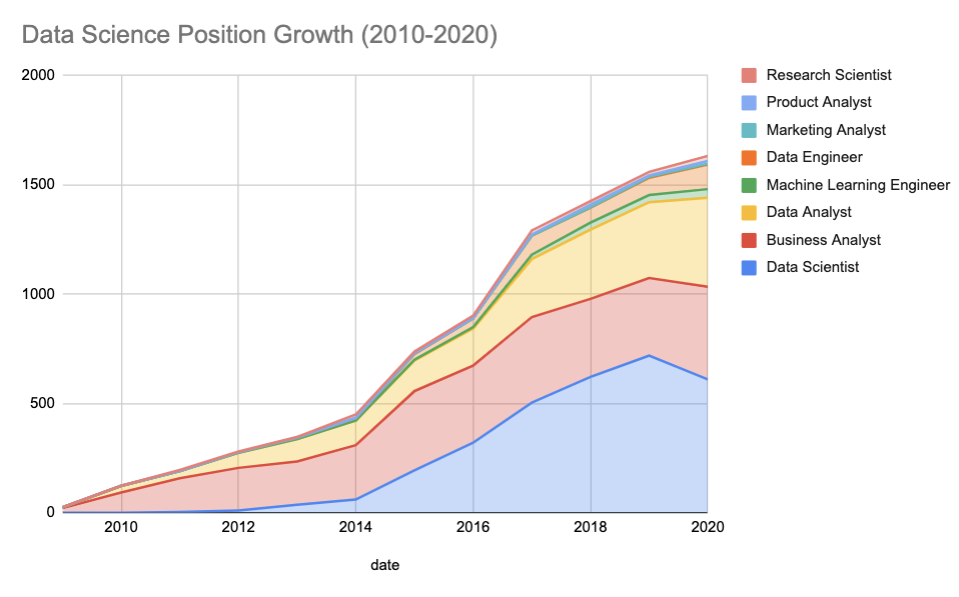
Each interview experience has some pre-conceived bias, given that the candidates had to opt-in to write about their interview on the internet. Luckily for us, we can analyze year over year data-points was, given this bias is consistent across time!
Looking at over 450+ tech companies, we segmented the data science roles into eight different types. Specifically, within the data scientist role, there was actually a 15% dip in interviews in 2020 versus 2019. This was offset by the growth in business analyst, data analyst, and data engineering interviews.
Data engineering is the new data science
Data engineering has grown on its own in the last few years or so. Fueled by a growing need for managers of data infrastructure, the actual interviews posted are likely much lower than the real amount, given how common data engineering is labeled into software engineering titles without distinction.
However, data engineering interviews in the past year have grown by 40%!

Currently, most data engineering roles require only three main types of skillsets: SQL, Python, and algorithms.
We see a rise, though, in data engineers needing to understand system design and architecture problems as well.
FAANG companies are still interviewing like crazy
Through 2020, the FAANG companies all increased their total market cap in the stock market by significant margins. This was also demonstrated by a complete lack of stoppage in hiring through the Covid-19 pandemic. We saw an increase in interviews of 25% for data science roles in the five FAANG companies.
This hiring was led by Amazon, who increased their interviews for data science roles by 40% over the last year!

Coding as a New Requirement for Data Science
As data science has gotten more well-defined, we’re seeing more and more commonalities in the topics covered in the data science interview. We broke down the data science interview into eight different topics:
- Algorithms
- Probability
- Machine Learning
- Statistics & A/B Testing
- Product & Business Case Study
- SQL
- Python Scripting
- System Design
Tracking these topics in each interview experience over time, we’ve seen a huge increase in coding skill tests that include algorithms, Python questions, and SQL queries.

There’s been a huge growth in the number of data science roles that require algorithms as a skillset. This is likely caused by the increase in demand for machine learning and data engineering skillsets.
If we look specifically at the data scientist role, we see a big emphasis in the number of questions around algorithms, machine learning, and statistics.

Data Science Roles at FAANG Companies
FAANG companies don’t have consistent data science roles
Across the most common FAANG companies of Facebook, Amazon, and Google, there are extreme differences across the interview for what each company calls a data scientist.

While each company may label the role data scientist, the actual position reflected by the interview questions asked is very different across each company.
- Google focuses on statistics and A/B testing interview questions.
- Amazon cares more about machine learning fundamentals and case studies.
- Facebook keeps a strong emphasis on product intuition, analytics, and SQL ability.
We can also see the breakdown by question topic for the five FAANG companies by year.

Take-home challenges for Data Science Interviews
2020 saw a 10% drop in take-home challenges and presentations given in interviews compared to 2019. But this may be a function of bias given the slowdown in hiring from startups versus big tech companies.
FAANG companies tend to not ask take-home challenges in their interviews, with only 8% of their interviews requiring it for data science related roles compared to 25% from non-FAANG companies.
Data Science Interview Experience Methodology
Let’s say that you have an interview coming up - how do you figure out what’s going to be asked on it?
The most obvious approach is just asking the recruiter. This is usually hit or miss, depending on how well informed the recruiter is and how interested they are in helping you. Another similar approach is to ask around for someone who recently interviewed at the same company.
At Interview Query, we decided to tackle this problem and formulate our own methods for understanding what would be asked on data science interviews without relying on anecdotes. We did this by applying data science to over 10,000 interview experiences that we found online and in our internal submissions from data scientists. We then classified and mapped the interview experiences at each company into 9 different question topics and skills buckets.
Here’s a list of links to other popular companies and roles:
Building the Interview Topics Graph
Our job at Interview Query is to make the interview process more transparent for aspiring data scientists and machine learning engineers. Our first task towards that goal was classifying data science interview questions into 8-10 different problem types, such as SQL and data analysis, probability and statistics, machine learning, and so on.
User feedback was great– we were adding structure to an obscure field that is always rapidly changing.
But it came to the point that most of our customers wanted even more insightful information about the specific roles that they were applying for. It didn’t make sense for candidates to study probability concepts if the interviewers were only going to ask questions on SQL.
Additionally, we realized that interview questions should reflect a job’s work on a day-to-day basis. Classifying different companies and positions then adds more transparency to the different kinds of data science positions and allows anyone to assess if the job is the right fit for them!
For example, if we compare Amazon’s and Google’s data science roles, we can see that they test vastly different subjects. Amazon places a higher emphasis on machine learning and coding, while Google mostly cares about statistical analysis.


We built these charts by utilizing two techniques:
- Crowdsourcing information from our members.
- Applying unsupervised learning techniques on interview experience text data online.
The first technique was pretty simple. Given our audience of data science candidates, we periodically sent out surveys asking about interview experiences. We also put interview question submission forms on different parts of our website to encourage users to add questions they’ve seen before.
Crowdsourcing from our members had a tremendous effect. Just a simple aggregation of each question type was all that was necessary to understand the frequency of different questions. Additionally, we could segment question types by how far candidates got throughout each stage of the interview, adding some granularity into the question topics.
Unsupervised Learning on Interview Text Data
The second method we used was applying unsupervised learning on interview text data to classify the text into different topics. Many times, online and within our own Slack community, members will post their interview experiences from different companies to share.

Given the string of text, as humans, we can clearly see that the member who interviewed at Convoy for a data scientist position was asked a behavioral question, a SQL question, a product intuition question, and a couple of business case questions. But it’s rather difficult for a computer to process this kind of output from reading plain text.
Given we didn’t have any training dataset and labeling data was impractical in our case, the only way we could process these at scale would be to apply unsupervised machine learning algorithms.
Topic Keyword Extraction and Weighting System
We decided the most practical approach would be a combination of keyword extraction with a manual rule engine. First, we had to extract as many relevant keywords as possible from the corpus to then manually map to our desired topic. Once we aggregated the topics for each interview experience, then we could understand the topic ratio for each company/position combo.
This method, however, wasn’t foolproof. Take the keyword and root word of “code”. If the user mentions code in their interview, they could be talking about coding in SQL, Python, data structures and algorithms, or even a problem with decoding a hashed string. Therefore, we had to either throw out these keywords or apply a weighting system that would be able to understand the relative context of the ambiguous word.
We attempted a couple of different approaches for keyword extraction. We tried both Latent Dirichlet Allocation and K-Means in order to generate topic models, and clusters and retrieve relevant keywords relating to each topic without having to manually assign them. But these proved difficult and less effective than simply counting keywords, given the wide and disparate range of our classifications. At the end of the day, we extracted 200+ relevant keywords.
Lastly, once we had our keywords mapped to the larger topics, we performed a standard bag of words count and aggregated the sum of the topics for each combination of company and interview.
We decided to set up a weighting system to make it a little more accurate. Each topic would be weighted differently based on three traits:
- The recency of the interview. Recent interviews should have a higher weighting towards accuracy than older interviews.
- We added different weighting on the keyword itself, dependent on if it was a strong predictor of the actual topic. For example, if someone mentions the word Leetcode, it’s likely they encountered an algorithms question.
- Finally, while we summed the actual values, we realized that data science interviews are zero-sum, in which the actual values don’t matter as much as the relative relationship of each question type frequency against each other.
Last Notes
If you would like to see more company interview experiences - check out our company guides page.
Additionally If you’d like to add more to our community of interview experiences and interview questions, please submit your recent interview here!