

2024 Ultimate Guide: Top 100+ Data Engineer Interview Questions Unveiled

Overview
Whether you’re just getting into the data engineer job market or your interview is tomorrow, practice is an essential part of the interview preparation process for a data engineer.
Data engineering interview questions assess your data engineering skills and domain expertise. They are based on a company’s tech stack and technology goals, and they test your ability to perform job functions.
We have detailed the most common skills tested after analyzing 1000+ data engineering interview questions.
To help, we’ve counted down the top 100 data engineering interview questions. These questions are from real-life interview experiences, and they cover essential skills for data engineers, including:
Behavioral Interview Questions for Data Engineers
Behavioral questions assess soft skills (e.g., communication, leadership, adaptability), your skill level, and how you fit into the company’s data engineering team.
Behavioral questions are expected early in the data engineering process (e.g., recruiter call) and include questions about your experience.
Examples of behavioral interview questions for a data engineer role would be:
1. Describe a data engineering problem you have faced. What were some challenges?
Questions like this assess many soft skills, including your ability to communicate and how you respond to adversity. Your answer should convey:
- The situation
- Specific tactics you proposed
- What actions you took
- The results you achieved
2. Talk about a time you noticed a discrepancy in company data or an inefficiency in the data processing. What did you do?
Your response might demonstrate your experience level, that you take the initiative and your problem-solving approach. This question is your chance to show the unique skills and creative solutions you bring to the table.
Don’t have this type of experience? You can relate your experiences to coursework or projects. Or you can talk hypothetically about your knowledge of data governance and how you would apply that in the role.
3. In the interview, you are to develop a new product. Where would you begin?
Candidates should have an understanding of how data engineering plays into product development. Interviewers want to know how well you’ll fit in with the team, your organizational ability in product development, or how you might simplify an existing workflow.
One Tip: Get to know the company’s products and business model before the interview. Knowing this will help you relate your most relevant skills and experiences. Plus, it shows you did your homework and care about the position.
MORE BEHAVIORAL PRACTICE QUESTIONS
4. Tell me about a time you exceeded expectations on a project. What did you do, and how did you accomplish it?
The STAR framework is the perfect model for answering a question like this. That will cover the how and why. However, one difference with this type of question is showing the value add to your work. For data engineering positions, you might have gone above and beyond, and as a result, you were able to reduce costs, save time, or improve your team’s analytics capacity.
5. Describe a time you had to explain a complex subject to a non-technical person.
Questions like this assess your communication skills. In particular, interviewers want to know if you can provide clear layperson descriptions of the technology and techniques in data engineering.
For example, you could say: “In a previous job, I was working on a data engineering project. For our developing credit-risk analysis tool, I needed to explain the differences between predictive models (using random forest, KNN, and decision trees). My approach was to distill the definition into easily understandable 1-2 sentence descriptions for each algorithm. Then, I created a short presentation with slides to walk the team through the pros and cons of all three algorithms.”

6. Why are you interested in working at our company?
These questions are common and easy to fail if you haven’t thought through an answer. One option is to focus on the company culture and describe how that excites you about the position.
For example, “I’m interested in working at Google because of the company’s experimentation and engineering innovation history. I look forward to being presented with engineering problems requiring creative, outside-the-box solutions, and I also enjoy developing new tools to solve complex problems. I believe this role would challenge me and provide opportunities to develop novel approaches, which excites me about the role.”
7. How would you describe your communication style?
One helpful tip for a question like this: Use an example to illustrate your communication style.
For example, you could say:“I would describe my communication style as assertive. I believe it’s essential to be direct in my project needs and not be afraid to ask questions and gather information.
In my previous position, I was the lead on an engineering project. Before we started, I met with all stakeholders and learned about their needs and wants. One issue that arose was timing, and I felt I would need more resources to keep the project on schedule, so I communicated this to the PM, and we were able to expand the engineering team to meet the tight deadline.”
8. Tell me a time when your colleagues disagreed with your approach. What did you do to address their concerns?
When interviewers ask this question, they want to see that you can negotiate effectively with your coworkers. Like most behavioral questions, use the STAR method. State the business situation and the task you need to complete. State the objections your coworker had to your action. Do not try to downplay the complaints or write them off as “stupid”; you will appear arrogant and inflexible.
Hint: The most crucial part of your answer is how you resolved the dispute.
9. Please provide an example of a goal you did not meet and how you handled it.
This scenario is a variation of the failure question. With this question, a framework like STAR can help you describe the situation, the task, your actions, and the results. Remember: Your answer should provide clear insights into your resilience.
10. How do you handle meeting a tight deadline?
This question assesses your time management skills. Provide specific details on how you operate. You might say I approach projects by:
- Gathering stakeholder input
- Developing a project timeline with clear milestones
- Delegating the workload for the project
- Tracking progress
- Communicating with stakeholders
11. Tell me about a time you used data to influence a decision or solve a problem.
STAR is a great way to structure your answers to questions like these. You could say:
“My previous job was at a swiping-based dating app. We aimed to increase the number of applications submitted (through swiping). I built an elastic search model to help users see relevant jobs. The model would weigh previous employment information and then use a weighted flexible query on all the jobs within a 50-mile radius of the applicant. After A/B testing, we saw a 10-percent lift in applications, compared to the baseline model.”
12. Talk about a time when you had to persuade someone.
This question addresses communication, but it also assesses cultural fit. The interviewer wants to know if you can collaborate and how you present your ideas to colleagues. Use an example in your response:
“In a previous role, I felt the baseline model we were using - a Naive Bayes recommender - wasn’t providing precise enough search results to users. I felt that we could obtain better results with an elastic search model. I presented my idea and an A/B testing strategy to persuade the team to test the idea. After the A/B test, the elastic search model outperformed the Naive Bayes recommender.”
13. What data engineering projects have you also worked on? Which was most rewarding?
If you have professional experience, choose a project you worked on in a previous job. However, if this is your first job or an internship, you can cite a class or personal project. As you present a data science or data engineering project, be sure to include:
- Include an overview of the problem
- Summarize your approach to the problem
- Discuss your process and the actions you took
- Define the results of the project
- Include information about what you learned, challenges, and what you would do differently
14. What are your strengths and weaknesses?
When discussing strengths, ask yourself, “what sets me apart from others?”. Focus on those strengths you can back up with examples using the STAR method, showing how your strength solved a business issue. If you have no prior full-time work experience, feel free to mention takeaways or projects from classes you have taken or initiatives from past part-time jobs.
With weaknesses, interviewers want to know that you can recognize your limits and develop effective strategies to manage the flaws that affect your performance and the business.
Basic Data Engineering Technical Questions
Interviewers use easy technical questions designed to weed out candidates without the right experience. This question assesses your experience level, comfort with specific tools, and the depth of your domain expertise. Basic technical questions include:
15. Describe a time you had difficulty merging data. How did you solve this issue?
Data cleaning and data processing are key job responsibilities in engineering roles. Inevitably unexpected issues will come up. Interviewers ask questions like these to determine:
- How well do you adapt?
- The depth of your experience.
- Your technical problem-solving ability.
Clearly explain the issue, what you proposed, the steps you took to solve the problem, and the outcome.
16. What ETL tools do you have experience using? What tools do you prefer?
There are many variations to this type of question. A different version would be about a specific ETL tool, “Have you had experienced with Apache Spark or Amazon Redshift?” If a tool is in the job description, it might come up in a question like this. One tip: Include any training, how long you’ve used the tech, and specific tasks you can perform.
17. Tell me about a situation where you dealt with alien technology.
This question asks: What do you do when there are gaps in your technical expertise? In your response, you might include:
- Education and data engineering boot camps
- Self-guided learning
- Working with specialists and collaborators
MORE BASIC TECH PRACTICE QUESTIONS
18. How would you design a data warehouse given X criteria?
This example is a fundamental case study question in data engineering, and it requires you to provide a high-level design for a database based on criteria. To answer questions like this:
- Start with clarifying questions and state your assumptions
- Provide a hypothesis or high-level overview of your design
- Then describe how your design would work
19. How would you design a data pipeline?
A broad, beginner case study question like this wants to know how you approach a problem. With all case study questions, you should ask clarifying questions like:
- What type of data is processed?
- How will the information be used?
- What are the requirements for the project?
- How much will data be pulled? How frequently?
These questions will provide insights into the type of response the interviewer seeks. Then, you can describe your design process, starting with choosing data sources and data ingestion strategies, before moving into your developing data processing and implementation plans.
20. What questions do you ask before designing data pipelines?
This question assesses how you gather stakeholder information before starting a project. Some of the most common questions to ask would include:
- What is the use of the data?
- Has the data been validated?
- How often will the information be pulled, and how is it used
- Who will manage the pipeline?
21. How do you gather stakeholder input before beginning a data engineering project?
Understanding what stakeholders need from you is essential in any data engineering job, and a question like this assesses your ability to align your work to stakeholder needs. Describe the processes that you typically utilize in your response; you might include tools like:
- Surveys
- Interviews
- Direct observations
- Social science / statistical observation
- Reviewing existing logs of issues or requests
Ultimately, your answer must convey your ability to understand the user and business needs and how you bring stakeholders in throughout the process.
22. What is your experience with X skill on Python?
General experience questions like this are jump-off points for more technical case studies. And typically, The interviewer will tailor questions as they pertain to the role. However, you should be comfortable with standard Python and supplemental libraries like Matplotlib, Pandas, and NumPy, know what’s available, and understand when it’s appropriate to use each library.
One note: Don’t fake it. If you don’t have much experience, be honest. You can also describe a related skill or talk about your comfort level in quickly picking up new Python skills (with an example).
23. What experience do you have with cloud technologies?
If cloud technology is in the job description, chances are it will show up in the interview. Some of the most common cloud technologies for data engineer interviews include Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform, and IBM Cloud. Additionally, be prepared to discuss specific tools for each platform, like AWS Glue, EMR, and AWS Athena.
24. What are some challenges unique to cloud computing?
A broad question like this can quickly assess your experience with cloud technologies in data engineering. Some of the challenges you should be prepared to talk about include:
- Security and Compliance
- Cost
- Governance and control
- Performance
25. What’s the difference between structured and unstructured data?
With a fundamental question like this, be prepared to answer with a quick definition and then provide an example.
You could say: “Structured data consists of clearly defined data types and easily searchable information. An example would be customer purchase information stored in a relational database. Unstructured data, on the other hand, does not have a clearly defined format, and therefore, a relational database can’t store it in a relational database. An example would be video or image files.”
26. What are the key features of Hadoop?
Some of the Hadoop features you might talk about in a data engineering interview include:
- Fault tolerance
- Distributed processing
- Scalability
- Reliability
SQL Interview Questions for Data Engineers
SQL questions for data engineers cover fundamental concepts like joins, subqueries, case statements, and filters. In addition, if required to write SQL code, it could test if you know how to pull metrics or questions that determine how you handle errors and NULL values. Common SQL questions include:
27. What is the difference between DELETE and TRUNCATE?
Both of these commands will delete data. However, a key difference is that DELETE is a Database Manipulation Language (DML) command, while TRUNCATE is a Data Definition Language (DDL) command.
Therefore, DELETE is used to remove specific data from a table, while TRUNCATE removes all table rows without maintaining the table’s structure. Another difference: DELETE can is available with the WHERE clause, but TRUNCATE cannot. In this case, DELETE TABLE would remove all the data from within the table while maintaining the structure, and TRUNCATE TABLE would completely delete the table.
28. What’s the difference between WHERE and HAVING?
Both WHERE and HAVING are used to filter a table to meet the conditions that you set. The difference between the two is apparent when used in conjunction with the GROUP BY clause. The WHERE clause filters rows before grouping (before the GROUP BY clause), and HAVING is used to filter rows after collection.
29. What is an index in SQL? When would you use an index?
Indexes are lookup tables used by the database to perform data retrieval more efficient. Users can use an index to speed up SELECT or WHERE clauses, but they slow down UPDATE and INSERT statements.
30. What are aggregate functions in SQL?
An aggregate function performs a calculation on a set of values and returns a single value summarizing the background. SQL’s three most common aggregate functions are COUNT, SUM, and AVG.
COUNT - Returns the number of items of a group. SUM - Returns the sum of ALL or DISTINCT values in an expression. AVG - Returns the average of values in a group (and ignores NULL values)
31. What SQL commands are utilized in ETL?
Some of the most common SQL functions used in the data extraction process include SELECT, JOIN, WHERE, ORDER BY, and GROUP BY.
- SELECT - This function allows us to pull the desired data.
- JOIN - This is used to select columns from multiple tables using a foreign key.
- WHERE - We use where to specify what data we want.
- ORDER BY - This allows us to organize a column in ascending or descending order.
- GROUP BY - This function groups the results from our query.
32. Does JOIN order affect SQL query performance?
How you join tables can have a significant effect on query performance. For example, if you JOIN large tables and then JOIN smaller tables, you could increase the processing necessary by the SQL engine. One general rule: joining two tables that will reduce the number of rows processed in subsequent steps will help to improve performance.
33. How do you change a column name by writing a query in SQL?
You would do this with the RENAME and ALTER TABLE functions. Here’s an example syntax for changing a column name in SQL:
ALTER TABLE TableName
RENAME COLUMN OldColumnName TO NewColumnName;
34. How do you handle duplicate data in SQL?
You might want to clarify a question and ask some follow-up questions of your own. Specifically, you might be interested in A. what kind of data is processed, B., and what types of values can users duplicate?
With some clarity, you’ll be able to suggest more relevant strategies. For example, you might propose using a distinct or unique key to reduce duplicate data. Or you could walk the interviewer through how the GROUP BY key.
35. Write a query that returns true or false whether or not each user has a subscription date range that overlaps with any other user.
Hint: Given two date ranges, what determines if the subscriptions overlap? If one field is after the other, nor entirely before the other, then the two ranges must overlap.
To answer this SQL question, you can think of De Morgan’s law, which says that:
Not (A Or B) <=> _Not A And Not B_.
What is the equivalent? And how could we model that out for a SQL query?
36. Given a table of employees and departments, write a query to select the top 3 departments with at least ten employees.
Follow-up question. Rank them by the percentage of employees making USD100,000+.
This question is an example of a multi-part logic-based SQL question that data engineers face. With this SQL question, you need:
- Calculate the total number of employees making USD100,000+ by department**. This logic means we will have to run a
GROUP BYon the department name since we want a new row for each department. - Formula to differentiate employees making USD100,000+ vs. those that make less. What does that formula entail?
37. You are given a users table and a neighborhoods table. Write a query that returns all neighborhoods with 0 users.
Whenever the question asks about finding “0 values,” e.g., users or neighborhoods, start thinking LEFT JOIN! An inner join finds any values in both tables; a LEFT JOIN keeps only the values in the left table.
With this question, our predicament is to find all the neighborhoods without users. To do this, we must do a left join from the neighborhoods table to the user’s table. Here’s an example solution:
SELECT n.name
FROM neighborhoods AS n
LEFT JOIN users AS u
ON n.id = u.neighborhood_id
WHERE u.id IS NULL
This question is used in Facebook data engineer interviews.
38. Write a query to account for the duplicate error and select the top five most expensive projects by budget to employee count ratio.
More context. You have two tables: projects (with columns id, title, start_date, end_date, budget) and employees_projects (with columns project_id, employee_id). You must select the five most expensive projects by budget to employee count. However, due to a bug, duplicate rows exist in the employees_projects table.
One way to remove duplicates from the employees_projects table would be to GROUP BY the columns project_id and employee_id simply. By grouping by both columns, we’ve created a table that sets distinct values on project_id and employee_id, thereby eliminating duplicates.
39. Write a SQL query to find the last bank transaction for each day.
More context. Use when given a table of bank transactions with id, transaction_value, and created_at, a DateTime for each transaction.
Start by trying to apply a window function to make partitions. Because the created_at column is a DateTime, multiple entries can be for different times on the same date. For example, transaction 1 could happen at ‘2020-01-01 02:21:47’, and transaction 2 could happen on ‘2020-01-01 14:24:37’. To make partitions, we should remove information about when the transaction was created. But, we still need that information to sort the transactions.
To do this, you could try:
ROW_NUMBER() OVER (PARTITION BY DATE(created_at) ORDER BY created_at DESC
Now, how would you get the last transaction per day?
40. Given the transactions table, write a query to get the average quantity of each product purchased for each transaction every year.
To answer this question, we need to apply an average function to the quantity for every different year and product_id combination. We can extract the year from the created_at column using the YEAR() function. We can use the ROUND() and AVG() functions to round the average quantity to 2 decimal places.
Finally, we make sure to GROUP BY the year and product_id to get every distinct year and product_id combination.
Bonus Question: Why should we use surrogate keys over normal keys?
Surrogate keys are system-generated, unique keys for a record in a database. They offer several advantages over normal or natural keys:
- Consistency: Surrogate keys are typically consistent in format, often being auto-incremented integers.
- Unchanging: Because they are system-generated, they aren’t subject to the same change potential as natural keys, which might be based on mutable data.
- Anonymity: They can’t typically be used to identify characteristics of the real-world, which is useful for ensuring data privacy.
- Compatibility: They can bridge the gap during scenarios in which natural keys from different systems or contexts are inconsistent or incompatible.
- Performance: Integer-based surrogate keys can be more efficient for querying compared to longer, string-based natural keys.
It’s important to note that while surrogate keys have their benefits, they should be used judiciously, and the decision should be based on the specific requirements of the database design.
Data Engineer Python Interview Questions
Be prepared for a wide range of data engineer Python questions. Expect questions about 1) data structures and data manipulation (e.g., Python lists, data types, data munging with pandas), 2) explanations (e.g., tell us about search/merge), and 3) Python coding tests. Sample Python questions include:
41. What is the difference between “is” and “==”?
This is a simple Python definition that’s important to know. In general, “==” is used to determine if two objects have the same value. And “is” determines if two references refer to the same object.
42. What is a decorator?
In Python, a decorator is a function that takes another function as an argument and returns a closure. The closure accepts positional or keyword-only arguments or a combination of both, and it calls the original function using the arguments passed to the closure.
Decorators help add logging, test performance, perform caching, verify permissions, or when you need to run the same code on multiple functions.
43. How would you perform web scraping in Python?
With this question, outline the process you use for scraping with Python. You might say:
“First, I’d use the request library to access the URL and extract data using BeautifulSoup. With the raw data, I would convert it into a structure suitable for pandas and then clean the data using pandas and NumPy. Finally, I would save the data in a spreadsheet.”
44. Are lookups faster with dictionaries or lists in Python?
Dictionaries are faster. One way to think about this question is to consider it through the lens of Big O notation. Dictionaries are faster because they have constant time complexity O(1), but for lists, it’s linear time complexity or O(n). With lists, you have to go through the entire list to find a value, while with a dictionary, you don’t have to go through all keys.
45. How familiar are you with TensorFlow? Keras? OpenCV? SciPy?
How familiar type questions show up early in the interview process? You might hear these in the technical interview or on the recruiter screen. If a Python tool, skill, or library is mentioned in the job description, you should expect a question like this in the interview.
You could say: “I have extensive experience with TensorFlow. In my last job, I developed sentiment analysis models, which would read user reviews and determine the polarity of the text. I developed a model with Keras and TensorFlow and used TensorFlow to encode sentences into embedding vectors. I built most of my knowledge through professional development courses and hands-on experimentation.”
46. What is the difference between a list and a tuple?
Both lists and tuples are common data structures that can store one or more objects or values and are also used to store multiple items in one variable. However, the main difference is that lists are mutable, while tuples are immutable.
47. What is data smoothing and how do you do it?
Data smoothing is a technique that eliminates noise from a dataset, effectively removing or “smoothing” the rough edges caused by outliers. There are many different ways to do this in Python. One option would be to use a library like NumPy to perform a Rolling Average, which is particularly useful for noisy time-series data.
48. For what is NumPy used? What are its benefits?
NumPy is one of the most popular Python packages, along with pandas and Matplotlib. NumPy adds data structures, including a multidimensional array, to Python, which is used for scientific computing. One of the benefits of using NumPy arrays is that they’re more compact than Python lists, and therefore, it consumes less memory.
49. What is a cache database? And why would you use one?
A cache database is a fast storage solution for short-lived structured or unstructured data. Generally, this database is much smaller than a production database and can store in memory.
Caching is helpful for faster data retrieval because Users can access the data from a temporary location. There are many ways to implement caching in Python, and you can create local data structures to build the cache or host a cache as a server, for example.
50. What are some primitive data structures in Python? What are some user-defined data structures?
The built-in data types in Python include lists, tuples, dictionaries, and sets. These data types are already defined and supported by Python and act as containers for grouping data by type. User-defined data types share commonalities with primitive types, and they are based on these concepts. But ultimately, they allow users to create their data structures, including queues, trees, and linked lists.
51. Given a list of timestamps in sequential order, return a list of lists grouped by week using the first timestamp as the starting point.
This question asks you to aggregate lists in Python, and your goal is an output like this:
def weekly_aggregation(ts) -> [
['2019-01-01', '2019-01-02'],
['2019-01-08'],
['2019-02-01', '2019-02-02'],
['2019-02-05'],
]
Hint: This question sounds like it should be a SQL question. Weekly aggregation implies a form of GROUP BY in a regular SQL or pandas question. But since it’s a scripting question, it’s trying to pry out if the candidate deals with unstructured data. Data scientists deal with a lot of unstructured data.
52. Given a string, write a function recurring_char to find its first recurring character.
Given that we have to return the first index of the second repeating character, we should be able to go through the string in one loop, save each unique character, and then check if the character exists in that saved set. If it does, return the character. Here’s a sample output for this question:
input = "interviewquery"
output = "i"
input = "interv"
output = "None"
53. Given a list of integers, find all combinations that equal the value N.
This type of question is the classic subset sum problem presented in a way that requires us to construct a list of all the answers. Subset sum is a type of problem in computer science that broadly asks to find all subsets of a set of integers that sum to a target amount.
We can solve this question through recursion. Even if you didn’t recognize the problem, Users could guess at its recursive nature if you recognize that the problem decomposes into identical subproblems when solving it. For example, if given integers = [2,3,5] and target = 8 as in the prompt, we might recognize that if we first solve for the input: integers = [2, 3, 5] and target = 8 - 2 = 6, we can just append 2 to each combination in the output to obtain our final answer. This subproblem recursion is the hallmark of dynamic programming and many other related recursive problem types.
Let’s first think of a base case for our recursive function.
54. Write a function find_bigrams to take a string and return a list of all bigrams.
Bigrams are two words grouped next to each other, and they’re relevant in feature engineering for NLP models. With this question, we’re looking for output like this:
def find_bigrams(sentence) ->
[('have', 'free'),
('free', 'hours'),
('hours', 'and'),
('other', 'activities.')]
Solution overview: To parse them out of a string, you must split the input string. You can do this with the python function .split() to create a list with each word as an input. Then, create another empty list that a user will eventually fill with tuples.
This question has appeared in Google data engineer interviews.
Database Design and Data Modeling Questions for Data Engineers
Data modeling and database design questions assess your knowledge of entity-relationship modeling, normalization and denormalization tradeoffs, dimensional modeling, and related concepts. Common questions include:
55. What are the features of a physical data model?
The physical database model is the last step before implementation and includes a plan for how you will build the database. Based on the requirements of the build, the physical model typically differs from the logical data model.
Some of the key features of the physical data model include:
- Specs for all tables and columns
- Relationships between tables
- Customized for a specific DBMS or data storage option
- Data types, default values, and lengths for columns
- Foreign and primary keys, views, indexes, authorizations, etc.
56. What database relationships do you know?
With this question, explain the types of relationships you know, and provide examples of the work you’ve done with them. The four main types of database relationships include:
- 1-to-1 - When one entity is associated with another. An example would be each employee associating with a particular department.
- 1-to-Many - When one entity is associated with many others. An example would be all the employees associated with a particular work location.
- Many-to-1 - When many entities are associated with one entity. An example would be all of the students associated with a single project.
- Many-to-Many - When many entities are associated with many others. An example would be customers and products, as customers can be associated with many products, and many products can be associated with various customers.
57. How would you handle data loss during a migration?
Complex migrations can result in data loss, and data engineering candidates should have ideas for minimizing loss. A few steps you can take to reduce data loss during migration would include:
- Define the specific data required for migration
- Avoid migrating data that is no longer needed
- Profile the data (possibly with a tool) to determine the current quality
- Perform data cleaning where required
- Define data quality rules via business analysis, system analysis, or gap analysis
- Gain approval for the quality rules
- Perform real-time data verification during the migration
- Define a clear flow for data, error reporting, and rerun procedures
58. What are the three types of data models?
The three most commonly used data models are relational, dimensional, and entity-relationship. However, many others aren’t widely used, including object-oriented, multi-value, and hierarchical. The type of model used defines the logical structure and how it is organized, stored, and retrieved.
59. What is normalization? Denormalization?
Data normalization is organizing and formatting data to appear similar across all records and fields. Data normalization helps provide analysts with more efficient and precise navigation, removing duplicate data and maintaining referential integrity.
On the other hand, Denormalization is a database technique in which redundant data is added to one or more tables. This technique can optimize performance by reducing the need for costly joins.
60. What are some things to avoid when building a data model?
Some of the most common mistakes when modeling data include:
- Poor naming conventions - Establish a consistent naming convention, which will allow for easier querying.
- Failing to plan accordingly - Gather stakeholder input and design a model for a specific analytics purpose.
- Not using surrogate keys - Surrogate keys are always helpful or best practice. However, because they are unique and system-generated, surrogate keys are useful when primary keys are inconsistent or incompatible.
61. Why are NoSQL databases more useful than relational databases?
Compared to relational databases, NoSQL databases have many advantages, including scalability and superior performance. Some of the benefits of NoSQL databases include:
- Store all types of data (unstructured, semi-structured, and structured data)
- Simplified updating of schemas and fields
- Cloud-based, resulting in less downtime
- Can handle large volumes of data
62. Design a database to represent a Tinder-style dating app. What does the schema look like?
Let’s first approach this problem by understanding the scope of the dating app and what functionality we must design around it.
Start by listing out 1) essential app functions for users (e.g., onboarding, matching, messaging) and 2) specific feature goals to account for (e.g., hard or soft user preferences or how the matching algorithm works).
With this information, we can create an initial design for the database.
63. Create a table schema for the Golden Gate Bridge to track how long each car took to enter and exit the bridge.
64. Write a query on the given tables to get the car model with the fastest average times for the current day.
In this two-part table schema question, we’re tracking not just enter/exit times but also car make, model, and license plate info.
The car model for licensing plate information will be one-to-many, given that each license plate represents a single car, and each car model can replicate many times. Here’s an example for crossings (left) and model/license plate (right):
| Column | Type |
|---|---|
id |
INTEGER |
license_plate |
VARCHAR |
enter_time |
DATETIME |
exit_time |
DATETIME |
car_model_id |
INTEGER |
| Column | Type |
|---|---|
id |
INTEGER |
model_name |
VARCHAR |
65. How would you create a schema representing client click data on the web?
This question is more architecture-based and assesses experience within developing databases, setting up architectures, and in this case, representing client-side tracking in the form of clicks.
A simple but effective design schema would be to represent each action with a specific label. In this case, it assigns each click event a name or title describing its particular action.
66. You have a table with a billion rows. How would you add a column inserting data without affecting user experience?
Many database design questions for data engineers are vague and require follow-up. With a question like this, you might want to ask: What’s the potential impact of downtime?
Don’t rush into answers to questions. A helpful tip for all Python and technical questions is to ask for more information, and this shows you’re thoughtful and look at problems from every angle.
67. How would you design a data mart or data warehouse for a new online retailer?
In addition, you’re tasked with using the star schema for your design. The star schema is a database structure that uses one primary fact table to store transactional data and a smaller table or tables that store attributes about the data.
Some key transactional details you would want to include in the model:
– orders - orderid, itemid, customerid, price, date, payment, promotion
– customer - customer_id, cname, address, city, country, phone
– items - itemid, subcategory, category, brand, mrp
– payment - payment, mode, amount
– promotions - promotionid, category, discount, start_date, end_date
– date - datesk, date, month, year, day
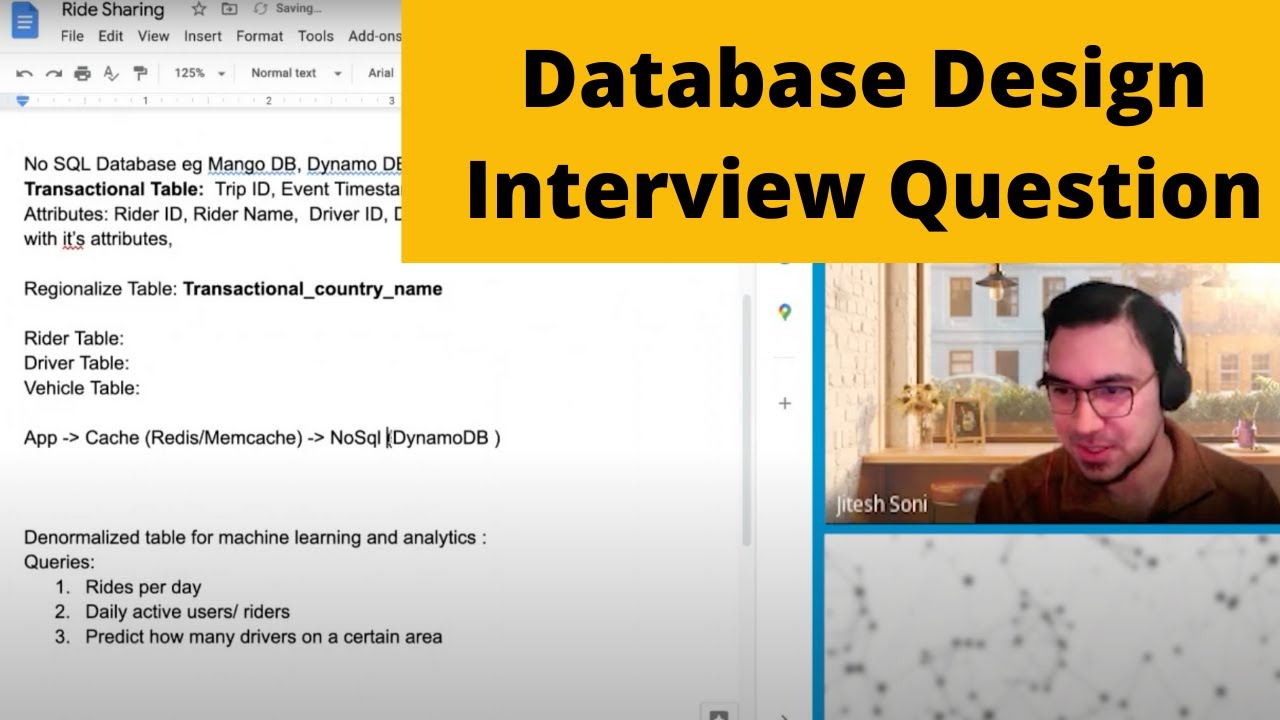
68. How would you design a database that could record rides between riders and drivers for a ride-sharing app?
Follow-up question: How would the table schema look?
See a complete mock interview solution for this database design question on YouTube:
Bonus Question: When should we consider using a graph database? A columnar store?
Graph databases are particularly effective when relationships between data points are complex and need to be queried frequently. They shine in scenarios involving social networks, recommendation engines, and fraud detection, where the connection and path between entities are of primary importance.
A columnar store, or column-oriented database, is instead advantageous when the workload involves reading large amounts of data with minimal update operations. They are apt for analytical queries that involve large datasets, such as in data warehousing scenarios, because they allow for better compression and efficient I/O.
Data Engineering Case Study
Data engineering case studies, or “data modeling case studies,” are scenario-based data engineering problems. Many questions focus on designing architecture, and then you walk the interviewer through developing a solution.
69. How would you design a relational database of customer data?
A simple four-step process for designing relational databases might include these steps:
- Step 1 - Gather stakeholder input and determine the purpose of the database. What types of analysis will the database support?
- Step 2 - Next, you could gather data, begin the cleaning and organization, and specify primary keys.
- Step 3 - Next, create relationships between tables. There are four main relationship types: 1-to-many, many-to-many, many-to-1, and 1-to-1.
- Step 4 - Lastly, you should refine the data. Perform normalization, add columns, and reduce the size of larger tables if necessary.
70. How would this design process change for customer data? What factors would you need to consider in Step 1?
How do you go about debugging an ETL error?
Start your response by gathering information about the system. What tools are used, and how does the existing process look?
Next, you could talk about two approaches:
- Error prevention: Fixing error conditions to prevent the process from failing.
- Error response: How you respond to an ETL error.
At a minimum, ETL process failure should log details of the loss via a logging subsystem. Log data is one of the first places you should look to triage an error.
71. With what database design patterns do you have the most experience
With architecture problems, you should have a firm grasp of design patterns, technologies, and products users can use to solve the problem. You might talk about some of the most common database patterns you’ve used like:
- Data mapper
- Identity map
- Object identify
- Domain object assembler
- Lazy load
72. Your task is working on building a notification system for a Reddit-style app. How would the backend and data model look?
Many case study questions for data engineers are similar to database design questions. With a question like this, start with clarifying questions. You might want to know the goals for the notification system, user information, and the types of notifications utilized.
Then, you’ll want to make assumptions. A primary solution might start with notifications:
- Trigger-based notifications: This might be an email notification for comment replies on a submitted post.
- Scheduled notifications: This might be a targeted push notification for new content. These are notifications designed to drive engagement.
73. You are analyzing auto insurance data and find that the marriage attribute column is marked TRUE for all customers.
Follow-up question. How would you debug what happened? What data would you look into, and how would you determine who is married and who is not?
With this debugging data question, you should start with some clarification, e.g., how far back does the bug extend? What’s the table schema appearance? One potential solution would be to look at other dimensions and columns that might be able to answer if someone is married (like marriage data or spouse’s name).
Amazon data engineer interviews have utilized this question
74. Design a relational database for storing metadata about songs, e.g., song title, song length, artist, album, release year, genre, etc.
When answering this question, you might want to start with questions about the goals and uses of the database. You want to design a database for how the company will use the data.
75. What database optimizations might you consider for a Tinder-style app?
The biggest beneficiary of optimizations would likely be increasing the speed and performance of the locations and swipes table. While we can easily add an index to the locations table on something like zip code (U.S.-only assumptions), we can’t add one to the swipes table, given the size of that table. One thing to consider when adding indices is that they trade off space for access speed.
One option is to implement a sharded design for our database. While indexing does a table copy and rearranges records to allow you to read off of a table sequentially, sharding will enable you to add multiple nodes where the specific record you want is only on one of those nodes. This process allows for a more bounded result in terms of retrieval time.
What other optimizations might you consider?
76. How would you design a system for DoorDash to minimize missing or wrong orders placed on the app?
This question requires clarity: What exactly is a wrong or missing order? For example, if the wrong order means “orders that users placed but ultimately canceled,” you’d have a binary classification problem.
If, instead, it meant “orders in which customers provided a wrong address or other information,” you might try to create a classification model to identify and prevent wrong information from being added.
77. How would you design the YouTube video recommendation system? What are important factors to keep in mind when building recommendation algorithms?
The purpose of a recommendation algorithm is to recommend videos that a user might like. One way to approach this would be to suggest metrics that indicate how well a user likes a video. Let’s say we set a metric to gauge user interest in a video: whether users watch a whole video or stop before the video completes.
Once we have a functioning metric for whether users like or dislike videos, we can associate users with similar interests and attributes to generate a basic framework for a recommendation. Our approach relies on the assumption that if person A likes a lot of the things that person B likes or is similar in other respects (such as age, sex, etc.), there’s an above-average chance that person B will enjoy a video that person A likes.
What other factors might we want to take into account for our algorithm?
Data Engineering ETL Interview Questions

Data engineers and data scientists work hand in hand. Data engineers are responsible for developing ETL processes, analytical tools, and storage tools and software. Thus, expertise with existing ETL and BI solutions is a much-needed requirement.
ETL refers to collecting extraction data from a data source, converting (transformation) into a format that users can easily analyze, and storing (loading) into a data warehouse. The ETL process then loads the transformed data into a database or BI platform to be used and viewed by anyone in the organization. The most common ETL interview questions are:
78. You have two ETL jobs that feed into a single production table each day. What problems might this cause?
Many problems can arise from concurrent transactions. One is lost updates. Lost updates occur when a committed value written by one transaction overrides a subsequently committed write from a simultaneous transaction. Another is write skew, which happens when updates within a transaction based upon stale data is made.
79. What’s the difference between ETL and ELT?
The critical point to remember for this question is that ETL transforms the data outside the warehouse. In other words, no raw data will transfer to the warehouse. In ELT, the transformation takes place in the warehouse; the raw data goes directly there.
80. What is an initial load in ETL? What about full load?
There are two primary ways to load data into a data warehouse: initial and full load. The differences between initial and full load are:
- Full load - All the data dumps when the source loads into the warehouse.
- Initial load - Data is dumped between the source and target at regular intervals. Lastly, extract dates are stored; only records are added for the extract date load. This load can be either streaming (better for small volume) or batch (better for large volume).
Full loads take more time and include all rows but are less complicated. Initial loads take less time (because they contain only new or updated records ) but are more challenging to implement and debug.
81. With what ETL tools are you most familiar?
You should be comfortable talking about the tools with which you are most skilled. However, if you do not have experience with a specific tool, you can do some pre-interview preparation.
Start by researching the ETL tools the company already uses. Your goal should be a solid overview of the tools’ most common processes and uses. The most common ETL platforms, frameworks, and related technologies are:
- IBM InfoSphere DataStage
- SQL
- Python
- Informatica PowerCenter
- Microsoft SQL Server Integration Services (SSIS)
- Microsoft Power BI
- Oracle Data Integrator
Note: If you only have basic tool knowledge, do not be afraid to admit it. However, describe how you learn new tools and how you can leverage your existing expertise in evaluating the unknown tool.
82. What are partitions? Why might you increase the number of partitions?
Partitioning is the process of subdividing data to improve performance. The data is partitioned into smaller units, allowing for more straightforward analysis. You can think of it like this: partitioning will enable you to add organization to a large data warehouse, similar to signs and aisle numbers in a large department store.
This practice can help improve performance, aid in management, or ensure the data stays available (if one partition is unavailable, other partitions can remain open).
83. What are database snapshots? What’s their importance?
In short, a snapshot is like a photo of the database. It captures the data from a specific point in time. Database snapshots are read-only, static views of the source database. Snapshots have many uses, including safeguarding against admin errors (by reverting to the snapshot if an error occurs), reporting (e.g., a quarterly database snapshot), or test database management.
84. What are views in ETL? What is used to build them?
Creating views may be a step in the transformation process. A view is a stored SQL query that an interface can store for use in the database environment. Users build views with a database management tool.
85. What could be potential bottlenecks in the ETL process?
Knowing the limitations and weaknesses of ETL is critical to demonstrate in ETL interviews. It allows you to assess, find workarounds or entirely avoid specific processes that may slow the production of relevant data.
For example, staging and transformation are incredibly time-intensive. Moreover, if the sources are unconventional or inherently different, the transformation process might take a long time. Another bottleneck of ETL is the involvement of hardware, specifically disk-based pipelines, during transformation and staging. The hardware limitations of physical disks can create slowdowns that no efficient algorithm can solve.
86. How would you triage an ETL failure?
The first thing to do when checking for errors is to test whether one can duplicate the error.
- Non-replicable - A non-replicable error can be challenging to fix. Typically, these errors need to be observed more, either through brute force or through analyzing the logic implemented in the schemas and the ETL processes, including the transformation modules.
- Replicable - If the error is replicable, run through the data and check if the data is delivered. After which, it is best to check for the source of the error. Debugging and checking for ETL errors is troublesome, but it is worth performing in the long run.
87. Describe how to use an operational data store.
An operational data store, or ODS, is a database that provides interim storage for data before it’s sent to a warehouse. AN ODS typically integrates data from multiple sources and provides an area for efficient data processing activities like operational reporting. Because an ODS typically includes real-time data from various sources, they provide up-to-date snapshots of performance and usage for order tracking, monitoring customer activity, or managing logistics.
88. Create an ETL query for an aggregate table called lifetime_plays that records each user’s song count by date.
For this problem, we use the INSERT INTO keywords to add rows to the lifetime_plays table. If we set this query to run daily, it becomes a daily extract, transform, and load (ETL) process.
The rows we add from the subquery that selects the created_at date, user_id, song_id, and count columns, are chosen from the song_plays table for the current date.
89. Due to an ETL error, instead of updating yearly salary data for employees, an insert was done instead. How would you get the current salary of each employee?
With a question like this, a business would provide you with a table representing the company payroll schema.
Hint. The first step we need to do would be to remove duplicates and retain the current salary for each user. Given that there aren’t any duplicate first and last name combinations, we can remove duplicates from the employee’s table by running a GROUP BY on two fields, the first and last name. This process allows us then to get a unique combinational value between the two fields.
Data Structures and Algorithms Questions for Data Engineers
Data engineers focus primarily on data modeling and data architecture, but a basic knowledge of algorithms and data structure is also needed. The data engineer’s ability to develop inexpensive methods for transferring large amounts of data is of particular importance. If you’re responsible for a database with potentially millions (let alone billions) of records, finding the most efficient solution is essential. Common algorithm interview questions include:
90. What algorithms support missing values?
There are many algorithms and approaches to handling missing values. You might cite these missing value algorithms:
- KNN - This algorithm uses K-nearest values to predict the missing value.
- Random Forest - Random forests work on non-linear and categorical data and are valid for large datasets.
You might also want to incorporate some of the pros and cons of using algorithms for missing values. For example, a downfall is that it tends to be time-consuming.
91. What is the difference between linear and non-linear data structures?
Linear data structures are elements that attach to the previous and adjacent elements and only involve a single level. In non-linear structures, data elements attach hierarchically, and multiple levels are involved. With linear data structures, elements can only be traversed in a single run, whereas in non-linear structures, they cannot.
Examples of linear data structures include queue, stack, array, and linked list. Non-linear data structures include graphs and trees.
92. Give some examples of uses for linked lists.
Some potential uses for linked lists include maintaining text directories, implementing stacks and queues, representing sparse matrices, or performing math operations on long integers.
Use list comprehension to print odd numbers between 0 and 100.
List comprehension defines and creates a list based on an existing list.
list1 = [0, 1, 2, 3, 4, 5.. 99,100]
only_odd = [num for num in list1 if num % 2 == 1]
print(only_odd)
93. How would you implement a queue using a stack?
This question asks you to create a queue that supports enqueue and dequeue operations, using the stack’s push and pop operations. A queue is a first-in, first-out structure in which elements are removed in the order in which the process adds them.
One way to do this would be with two stacks.
To enqueue an item, for example, you would move all the elements from the first stack to the second, push the item into the first, and then move all elements back to the first stack.
94. What is a dequeue?
Dequeue is a queue operation to remove items from the front of a queue.
95. What are the assumptions of linear regression?
There are several linear regression assumptions, which are baked into the dataset and how the model is built. Otherwise, if these assumptions are violated, we become privy to the phrase “garbage in, garbage out”.
The first assumption is that there is a linear relationship between the features and the response variable, otherwise known as the value you’re trying to predict. This assumption is baked into the definition of linear regression.
What other assumptions exist?
96. Write a function that returns the missing number in the array. Complexity of O(N) required.
Example:
nums = [0, 1, 2, 4, 5]
missingNumber(nums) -> 3
We can solve this problem in a logical iteration or mathematical formulation.
97. Given a grid and a start and end, find the maximum water height you can traverse to before there is no path. You can only go in horizontal and vertical directions.
Example:
S 3 4 5 6
2 4 6 1 1
9 9 9 9 E
Here’s a solution: Recursive backtrack to the end while saving the max path water level on each function call. Track a visited cell set to trim the search space. O(n^2)
98. Given a string, determine whether any permutation of it is a palindrome.
The brute force solution to this question will be to try every permutation and verify if it’s a palindrome. If we find one, then return true; otherwise, return false. You can see the complete solution on Interview Query.
99. Given a stream of numbers, select a random number from the stream, with O(1) space in the selection.
A function that is O(1) means it does not grow with the input data size. For this problem, the function must loop through the stream, inputting two entries at a time and choosing between the two with a random method.
100. Write a function to locate the left insertion point for a specified value in sorted order.
Here’s a solution for this Python data structures question:
import bisect def index(a, x): i = bisect.bisect_left(a, x) return i a = [1,2,4,5] print(index(a, 6)) print(index(a, 3))
Video: Top 10+ Data Engineer Interview Questions and Answers
Watch a video overview of the types of questions that get asked in data engineer interviews:

More Data Engineer Interview Resources
The best way to prepare for a data engineer interview is practice. Practice as many example interview questions as possible, focusing primarily on the most important skills for the job, as well as where you have gaps in knowledge.
If you’d like to land a job in Data Engineering, Interview Query offers the following resources:
- The Data Engineering Learning Path to sharpen your skills and learn to tackle data engineering interview questions.
- The job board showing recent openings and company interview guides to help you prepare.
- The list of database design interview questions, as well as the list of SQL Interview Questions, to help you practice for your next interview.
- Discover more with 9 Best Data Engineering Books.
- Interviewing for a higher position? Check out Data Engineering Manager Interview Questions. For more in-depth learning, we offer individual coaching sessions with our experts.