
44 Best Data Science Projects With Source Code (2025 Edition)


Introduction
Data science projects are an incredible learning tool for practicing new skills and deepening your expertise. Whether you want to master data analytics or brush up on machine learning fundamentals, a data science project is one of the best ways to gain hands-on experience and learn by trial and error.
So, where to begin? What data projects should you focus on?
Data science is such a broad field, and you can pursue an endless array of data projects, from building chatbots to testing fraud detection models. Ultimately, it depends on your goals and the tools you want to master. Want to improve on data analytics? Perform exploratory data analysis on a dataset that you scraped. Want to master Python? Try building a recommendation engine.
To provide inspiration, we’ve highlighted 41 data science projects with source code, which we’ve also broken down into several relevant categories.
How to Start Building Data Science Projects From Scratch
Watch a video overview of building data science projects:

These projects will help you practice some of the most useful analytics, data science, and machine learning skills. We’ve also included tips, free datasets to use (and be sure to see our list here too), as well as source code. Browse projects by type:
Python Data Science Projects With Source Code
These projects are built entirely in Python and come with datasets, tutorials, or source code to help you get hands-on experience with real-world data science workflows:
1. Detecting Fake News with NLP
This is a great beginner data science project for practicing NLP techniques like text classification.
You can start with this Fake and Real News Dataset on Kaggle, which features two four-column charts (true and fake news) with the title, text, subject, and date of the article. You can follow along with this tutorial for using Python to determine if an article is real or fake.
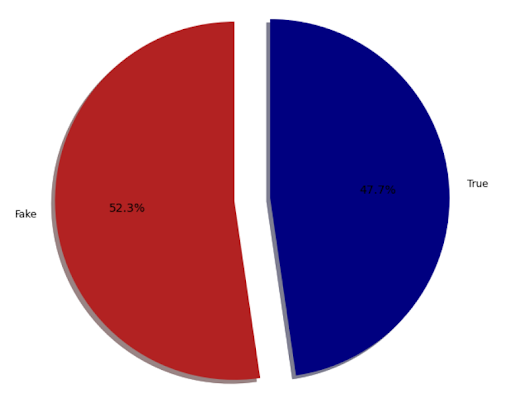
How to do the project: The tutorial above gives step-by-step directions on using Python, as well as libraries like TensorFlow and PyCare
2. Build a Simple Movie Recommendation System
The TMDB 5000 Movie Database is a sprawling movie dataset, that includes 24 columns for each entry.
You can use this dataset to build a basic movie recommendation system, which is a perfect beginner project. To get started, check out this Kaggle notebook, which provides a walk-through for all three types of recommendation systems.
How to do the project: Follow the tutorial above and start with demographic filtering first, which is the most straightforward method for a recommendation system. Then, work through the content-based and collaborative filtering examples.
3. Predict Income with Census Data
All of the datasets in the University of California, Irvine Machine Learning Repository are perfect for beginner data science projects. Because they’ve been pre-processed, they’re usually ready for analysis. Plus, there are many tutorials online that will walk you through how to use them and how to analyze performance.
One that is particularly great for beginners is the US Census Income Dataset. This is a great introductory data science classification project that asks you to determine if someone’s income is greater than $50,000 based on attributes in the dataset.
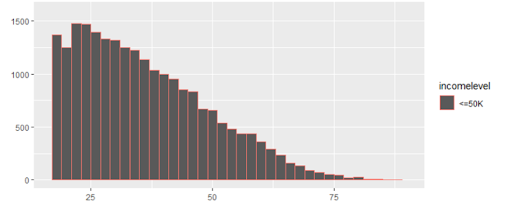
How to do the project: Check out this helpful tutorial to get started. It shows you how to build a model to predict income based on a variety of census data.
4. Build a Music Recommendation Engine
There are numerous datasets you can use for building recommendation engines, but if you want to build an engine for music, take a look at the Million Song Dataset.
Featuring metadata for a million songs, this is a great source for building a recommendation engine with Python.
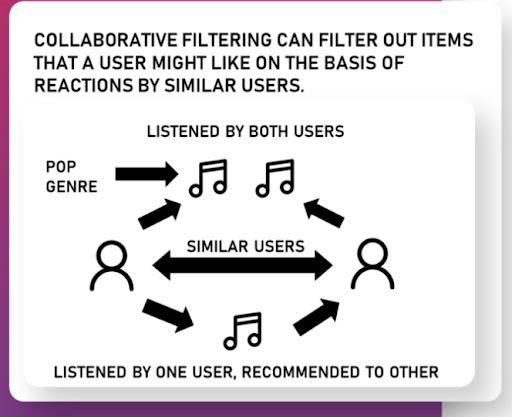
How to do the project: Follow along with this helpful tutorial from Ajinkya Khobragade on Medium.
In particular, you’ll learn how to build a collaborative-filtering recommendation engine. Also, see this video on creating TreeMaps in Tableau.
5. Cassava Leaf Disease Classification
This Kaggle competition introduces a dataset of 20,000+ images of cassava leaves, providing a great classification machine learning project. Your task is to then classify the images into four disease categories or determine if the leaf is healthy.

How to do the project: Take a look at this Kaggle notebook for an overview of working with this dataset. You’ll also want to flip through the Getting Started tutorial from the competition’s authors.
6. Barcode & QR Code Scanner App
If you want to get started with computer vision, this is a straightforward project that will allow you to work with concepts, like edge detection. Behic Guven’s tutorial on Towards Data Science, which will walk you through building this type of app, is a good starting point.
How to do the project: You’ll need to use libraries like OpenCV, Pyzbar, and Pillow if you follow along with the tutorial. Or, if you prefer a video walk-through, see this helpful video.
7. Titanic Survival Prediction
Although many of the projects mentioned in this article are beneficial for different reasons, sometimes we want to build a project just for fun and hone our skills.
One such project is predicting who would have survived the Titanic.
You can create a machine learning algorithm using the Kaggle Titanic dataset, which contains information about the names, ages, and sexes of around 891 passengers in the training set and 418 passengers in the testing set with a linear regression model.
8. Transform Images into Cartoons with OpenCV
This is another fun machine learning project using OpenCV that provides practice in concepts like image transformation, facial recognition, and object detection.
Get started with this tutorial on DataFlair, which includes source code and step-by-step instructions.

How to do the project: You’ll find the source code in the DataFlair tutorial.
Another option: Check out this helpful mini-project tutorial on Medium.
9. Build Your Own Trading Bot
Let’s preface this one by saying that creating sustainable income with a trading bot is very difficult and high-risk. Instead, this might be more of a project you do for learning, rather than a passive income generator.
But if you want to give it a shot: check out this guide to building an algorithmic trading app with machine learning on GitConnected. It focuses particularly on day trading U.S. stocks.
How to do the project: Other avenues to look at: sports betting or cryptocurrency trading. Again, these are high-risk endeavors that require ongoing maintenance… so maybe not be the best passive income data science projects to try.
10. Alternative Asset Arbitrage
Data science simplifies the process of arbitrage, making it easier to find price differences between markets. In fact, that’s exactly the strategy Sam Bankman-Fried used to make millions on crypto-asset arbitrage.
Crypto and NFTs seem to be the big ones these days, but the strategy also works in sports betting, concert tickets, sneakers, and trading cards.

How to do the project: There are a number of tutorials and articles to read. Take a look at this one that looks at quantifying sneaker resale prices, based on features. Here’s another on crypto-asset arbitrage.
11. Building a Python Package
Although building a Python package doesn’t generate income, it can help you build your personal brand, and looks great on the resume. Check out this guide to building your first Python package on Towards Data Science to get started.

How to do the project: The guide above provides step-by-step directions for developing a Python package, including creating a Read.Me file, as well as licensing and deployment.
Beginner-Friendly Data Science Projects
These beginner-level projects focus on simple concepts and clear outcomes, making them perfect for first-time data science learners to build confidence and foundational skills:
12. Color Detection Beginner Computer Vision Project
Computer vision is extremely complex, but there are many projects beginners can try to start experimenting with computer vision. This project, for example, will allow you to practice color detection using Python. Start with this helpful DataFlair tutorial, which covers how to build a simple app for color detection.

How to do the project:The tutorial above features a color dataset, as well as source code to help you get started.
13. Iris Flower Classification
The UCI Repository is a go-to source for free data, and this is a classic classification project. Essentially, the project asks you to build a classification engine based on images of Iris flowers, and there are numerous tutorials and how-tos online.
How to do the project: One of the most famous datasets in the UCI Repository is the Iris dataset.
This is the perfect source for a beginner machine learning classification project (because there are so many tutorials with source code available online).
14. Fruit & Vegetable Image Classifier
This is a comprehensive dataset featuring over 75,000 images of various fruits and vegetables. If you’re interested in a machine learning project, this is an excellent data source.
Project ideas include: building a fruit and vegetable classifier, developing an application for automated grocery checkout, or experimenting with transfer learning models for fine-tuned image recognition tasks.
How to use the data: Creating a fruit and vegetable classifier with this dataset is a great way to gain practical experience in machine learning.
15. Text Mining & Text Normalization
Text mining is one of the most in-demand data science skills, and there are many ways you can practice this technique. First, read through this beginner’s guide to text mining for some helpful hints. Another strategy would be to look at text pre-processing tasks, like text normalization. The Google Text Normalization Challenge on Kaggle is a great dataset to work with.

How to do the project: After you complete the Text Normalization Challenge, look at doing other projects with text data, like text analytics, text classification, or text clustering.
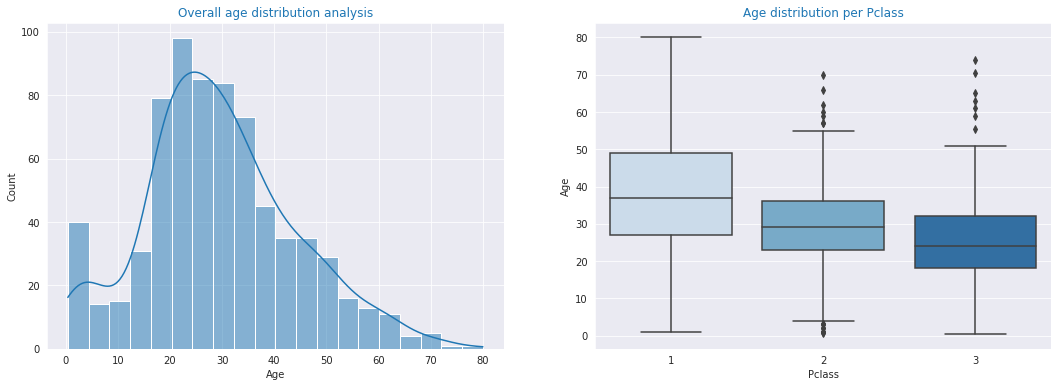
16. Titanic Dataset – Basic Modeling
One of the most well-known Kaggle datasets is the Titanic dataset. This is one of the best sources for a predictive modeling project, especially for beginners, as there are numerous notebooks you can view and get help from.
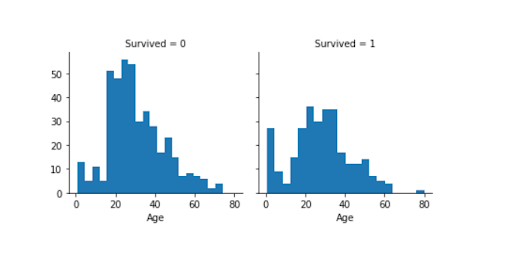
How to use the data: Build a model to predict if a passenger survived the sinking of the Titanic. This is a great introduction to using Python for predictive modeling.
17. Data Cleaning Project (Beginner level)
Data cleaning may be the janitorial work of data analytics, but it’s absolutely essential. Bad data equals bad results, and if you can’t do things like handle missing values, parse dates, or manage inconsistent data entries, you’ll likely run into problems in future data analytics projects.
Fortunately, this Kaggle challenge offers three mini data cleaning projects you can try.
How to do the project: This is a five-day challenge that provides hands-on practice with a variety of data cleaning tasks. Both source code and data are provided.
18. Music Recommendation Engine
There are numerous datasets you can use for building recommendation engines, but if you want to build an engine for music, take a look at the Million Song Dataset.
Featuring metadata for a million songs, this is a great source for building a recommendation engine with Python.
How to do the project: Follow along with this helpful tutorial from Ajinkya Khobragade on Medium.
In particular, you’ll learn how to build a collaborative-filtering recommendation engine. Also, see this video on creating TreeMaps in Tableau.
19. EDA on Sports Supplement Data
In sports, athletes and enthusiasts alike use supplements to improve their overall performance. This dataset bridges the gap between claims of effectiveness and scientific validation.
An Exploratory Data Analysis (EDA) will reveal which legal supplements truly enhance performance, endurance, and strength according to rigorous scientific scrutiny.
20. Concert Ticket Reselling
Concert tickets are one of the highest-value resale items. One project idea: build an app that monitors ticket prices on Craigslist and ticket reseller sites, like StubHub or SeatGeek, and then buys those tickets below a certain threshold.
Take a look at this article on analyzing concert ticket pricesfor ideas.
How to do the project: Take a look at this tutorial for scraping data on Craigslist. Although it looks at scraping used items, you can adapt it to concert tickets or other high-value items.
Final Year & Student Projects
These end-to-end projects are ideal for academic portfolios or resumes, showing your ability to handle real datasets, build predictive models, and communicate business impact:
21. Telco Customer Churn Prediction
This project leverages the Telco Customer Churn dataset on Kaggle, which is an IBM dataset. You can read more about it here.
Using the dataset, you can perform a number of analytics projects, focused on predicting and analyzing churn.
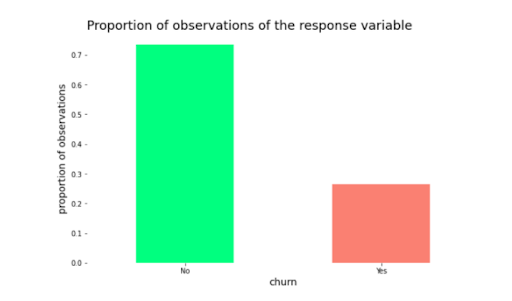
How to do the project: Follow along with this end-to-end tutorial from Amanda Iglesias Moreno on Medium. In particular, you’ll get detailed info on how to use histograms and normalized stacked bars to visualize the data.
22. Build a Smart Health Recommendation System
If you’re interested in applying data science to healthcare, AetherWell offers a compelling project. Developed as a final year endeavor, AetherWell is a health recommendation system that leverages PySpark and deep learning to provide personalized health insights. This project integrates various technologies to process and analyze health data efficiently.GitHub+1GitHub+1
How to do the project: To embark on a similar project, you’ll need to familiarize yourself with PySpark for handling large datasets and deep learning frameworks for building predictive models. Understanding how to integrate these components into a cohesive system is crucial. Additionally, deploying the application using Docker and creating a user-friendly interface with Flutter can enhance the project’s practicality. This project not only deepens your technical skills but also provides valuable experience in developing end-to-end data-driven applications in the healthcare domain.
23. Stroke Prediction Model
If you’re interested in health informatics, this is a go-to source for a beginner-to-intermediate health analytics project.
The Stroke Prediction Dataset features 5,000+ data points that you can use to build a stroke prediction model or practice creating health data visualizations.
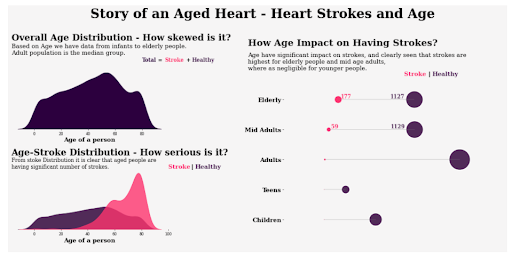
How to use the data: This is a great source for a data visualization project– specifically, data storytelling. Plus, it gives you practice in Python or R.
24. Cryptocurrency Price Prediction
Cryptocurrency exchanges are hiring data scientists at a fast pace. Although most don’t work on pricing predictions (they focus more on business analysis), this is a great project if you want to build your portfolio for a crypto data science job.
Follow along with this helpful walk-through from Abhinav Sagar on Medium.
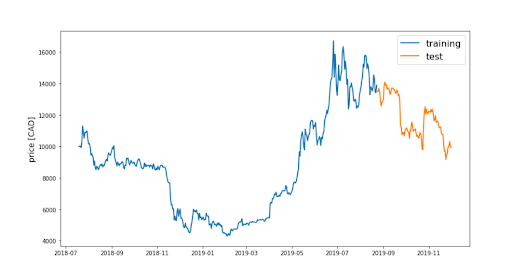
How to do the project: In the tutorial, you’ll learn how to build a machine learning app that uses LSTM neural networks to predict crypto prices.
25. Real Estate Investment Analysis
Real estate investing is an age-old passive income generator. But data science can help you maximize profit margins. Essentially, what you’re looking for are homes in areas where average rents cover the mortgage, or even better, turn payments that are more than the monthly mortgage.
You can do this by scaling your analysis across the U.S. First, scrape sold home data from sites like Zillow or Redfin, as well as rental data from sites like Zumper and Craigslist.
Then, merge the datasets together to determine which areas have the best price-to-rental ratios across segments, like square footage and the number of bedrooms.
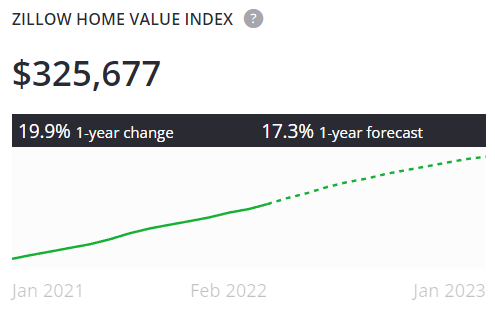
How to do the project: Analysis is the most intense part of this project. After you’ve scraped the data, look for investments in areas you’d like to own properties.
26. Credit Card Approval Prediction
Risk analysis and assessment is a classic use of machine learning, and it’s one of the best project topics for anyone interested in fintech data science jobs.
To start, you can use this dataset on Kaggle, which is perfect for predicting if a client is a “good” or “bad” client for approval.
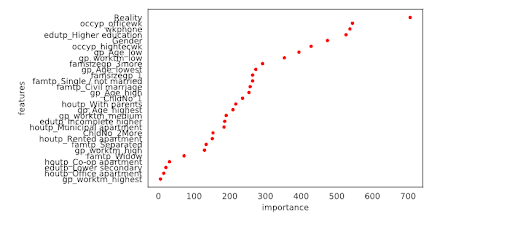
How to do the project: Take a look at this Kaggle credit card approval notebook, which should provide some direction.
If you’re interested in data science jobs in the finance industry, this is definitely a project to give a try.
27. Car Rental Demand Analysis
Which car models get rented most frequently? When’s the best day to rent a car? You can answer this question using the Cornell Car Rental Dataset on Kaggle. Featuring information on 6,000+ rental cars, the dataset is great for EDA-type data analytics projects.
How to do the project: Think up some problem statements before you get started. You might want to analyze fares, car rentals by model, or seasonal trends.
28. Life Expectancy Data Analysis
The WHO’s life expectancy dataset is perfect for diving into practicing exploratory analysis. With life expectancy data for 193 countries, with several attributes, you can use this to build prediction models, determine which factors correlate with longer life expectancy, and much more.
How to use the data: This is one of the best datasets for EDA, data visualization, or data storytelling projects. Here’s a helpful overview of doing EDA with the life expectancy dataset.
29. Retail Data Analysis with SQL
SQL is one of the go-to languages for data scientists, and SQL projects are one of the best ways to learn intermediate-to-advanced SQL functions.
With this project, you can perform sales reporting using SQL on an open retail dataset. Check out this tutorial to get started.
How to do the project: Check out this e-commerce dataset on Kaggle, or this churn dataset for a large Telco. You can use the above tutorial to walk you through writing SQL functions for e-commerce reporting or building a customer churn model.
30. Toughest Sports in Terms of Skills
Are you wondering which sport is truly the hardest?
This dataset offers a unique perspective by evaluating sports based on various skills. Through detailed analysis, it seeks to quantify the complexity and challenge of different sports, providing data-driven insights into this decades-long discussion.
31. Airbnb Analytics Project
Ever wondered how Airbnb listings look in your cities? Things like listings by neighborhood, the number of listings per host, or average prices? Check out Inside Airbnb– the site is your source for cleaned and aggregated Airbnb data for numerous cities worldwide, making this an excellent source for a data analytics project.
How to do the project: Check out Inside Airbnb’s About page for question prompts to get you started.
32. Handling Missing Values: NFL Play-by-play
Analyze NFL play-by-play data from 2009 to 2016 to uncover insights into game strategies, player performance, and team dynamics. This three-day take-home project requires 72 hours and tests skills in data cleaning, data visualization, exploratory data analysis (EDA), and statistical analysis. The deliverable is a single document that includes the code, visualizations, and a write-up of your findings.
Clean and process the data, handling missing values and ensuring consistency. Conduct exploratory analysis to identify trends and patterns, then create visualizations to highlight key findings. Analyze play types, team and player performance, and factors contributing to wins. Summarize insights, discuss implications, and suggest areas for further investigation.
33. Automated Wildlife Monitoring with Human-in-the-Loop AI
Iterative Human and Automated Identification of Wildlife Images is a PyTorch-based framework designed to streamline wildlife image classification by integrating human expertise into the machine learning loop. This approach significantly reduces the need for manual annotations while maintaining high accuracy.
How to do the project: The system employs an iterative process where a model trained on camera trap images identifies wildlife species. Low-confidence predictions are flagged for human review, and the confirmed labels are then used to retrain the model. This cycle continues, enhancing the model’s performance over time. The project utilizes techniques like energy-based loss functions and Open Long-Tailed Recognition (OLTR) to handle class imbalances and novel species detection. Data and annotations are available through the LILA BC repository, and the codebase provides configuration files for training and deployment.
Take-Home Projects for Data Science Interviews
These projects simulate real-world interview take-homes, testing your ability to clean data, build models, and communicate insights clearly—under time constraints:
34. Flowcast Credit Card Fraud Detection Take-Home

- Overview: Create a model to detect if a transaction on a credit card is fraudulent or not
- Time Required: 1-2 hours
- Deliverable: You will use credit card transaction data to detect fraud. Fraud can take many forms, whether it is someone stealing a single credit card, large batches of stolen credit card numbers being used on the web, or even a mass compromise of credit card numbers stolen from a merchant via tools like credit card skimming devices.
Note: This dataset loosely resembles real transactional data, but the entities and relations within are purely fictional.
35. Airbnb Algorithms Take-Home

- Overview: Train a recommender model that can predict which listings a specific user is likely to book.
- Time Required: 72 hours
- Skills Tested: Machine learning, recommendation engines, algorithms
- Deliverable: Please submit one document and provide code and a write-up.
This is an in-depth, three-day model-building take-home, and you’re provided with minimal direction. For this recommendation engine problem, Airbnb suggests formulating it as a ranking problem or a top-K recommendation problem. The key to this challenge is your model-building process. Where do you start (e.g., a baseline model)? And what are the steps you use to tune the model?
36. Thinking Machines: Traffic Congestion Analysis Takehome

- Overview: Create a presentation with suggestions on how to reduce traffic congestion
- Time Required: 72 Hours
- Skills Tested: Marketing analytics, business case, growth marketing
- Deliverable: 1) Describe the data. 2)Share your insights and conclusions based on your analysis.
The Data Strategist plays a central role in designing and implementing Thinking Machines’ proposals for potential clients. On a typical engagement, your initial activities typically involve:
- A pitch to the client on Thinking Machines’ capabilities
- An exploratory data analysis (EDA), which allows us to become more familiar with the client’s data assets and thus propose a scope of work.
37. GrubHub- Best State for Growth Takehome

- Overview: Analyze the data and recommend which states Grubhub should expand.
- Time Required: 3 hours
- Skills Tested: Marketing analytics, business case, growth marketing
- Deliverable: Present your recommendations and discuss any limitations or assumptions you made.
This take-home challenge provides you with a bare-bones dataset, including orders, visits to Grubhub’s site, and revenue. Because the dataset is so limited, you’ll be required to “make assumptions and list them in your response.” Ultimately, you’ll recommend which states to target for expansion.
38. DoorDash Take-Home Analytics Project
- Overview: This DoorDash take-home features user and transaction data and asks you to build a model to predict the delivery time.
- Time Required: 5.5 hours
- Deliverable: A short write-up explaining your model, code for the model, and code that outputs a .tsv file for the application.
This assessment is a two-part machine learning challenge. The first is a classic modeling case study where you build a model to predict total delivery duration in seconds.
DoorDash’s take-home is meant to test your model tuning and evaluation skills, define why you used the model, how you evaluated performance and any information of note about your approach.
It would also help if you made recommendations based on your model to reduce delivery time. Finally, you must create an app that uses the model to predict each delivery in the JSON file and writes predictions to a new tab-separated file.
39. UpTop: Messy JSON Processing Take-Home

- Overview: Given a data file containing scored records in your favorite programming language, write a program to output the N highest record IDs & scores by the score in descending order, highest score first.
- Skills Tested: Programming Languages
- Deliverable: The output should be correctly formatted JSON. The program should take the file path of the data file as its first parameter and a number of scores to return as its second parameter, like so.
40. Build a Valuable Dataset
Businesses, investors, and governmental agencies pay high prices for quality data. Building a dataset that’s valuable–or at the very least useful– means that you can then generate passive income with a data science project.
Here’s a helpful blog post about building valuable datasets that might offer some direction, and you might think of some from this list:
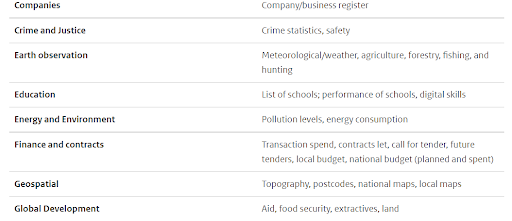
How to do the project: Typically, industries like real estate, cryptocurrency and NFTs, and finance have potential customers that would be willing to pay for a monthly data subscription.
One tip: think about how you can add value (or more data) to an existing dataset, e.g., making it more accessible through an API or aggregating multiple datasets.
Open-Source & Real-World Projects
These projects use real-world datasets—often from open-source platforms like Kaggle or GitHub—and are perfect for showcasing your ability to derive insights from complex, messy, and high-impact data:
41. Formula 1 Race Data Analysis
Formula 1 is a sport that’s as much about strategy and data as it is about speed. With races determined by split-second decisions, the information provided in this dataset can offer invaluable insights into the performance of each F1 racers over the season.
To begin, ensure that all datasets are consistent, free from discrepancies, and interlinked correctly. Perform an EDA to visualize metrics such as wins, podium finishes, and other pivotal performance metrics of the racers.
For a more challenging take, you could also analyze a racer’s performance over tracks and identify which tracks they perform the best in.
42. NBA Stats Scraping & Visualization
Data scraping is a go-to skill for analysts and data scientists, and Python is one of the best tools for scraping your data.
This tutorial shows you have to scrape data from Basketball-Reference. Follow along and build your free dataset for an NBA analytics project or data visualization project.
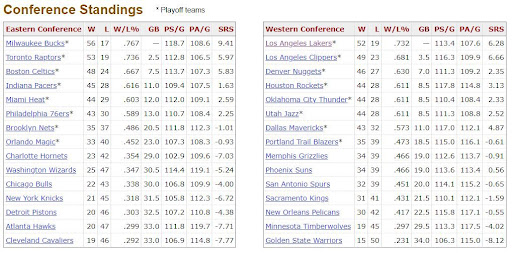
How to do this project: Customize datasets with scraping and answer a basketball analytics question like “What’s the correlation between free-throw percentage and win percentage?” Or, “What’s the optimal strategy for the 2-for-1 play?”
43. Earth Surface Temperature Visualization (Climate Change)
Here’s a great data visualization project to practice Python and building visualizations.
First, check out the Earth Surface Temperature Data on Kaggle. Then, take a look at this Kaggle notebook to see how to conduct some analysis and build visualizations.
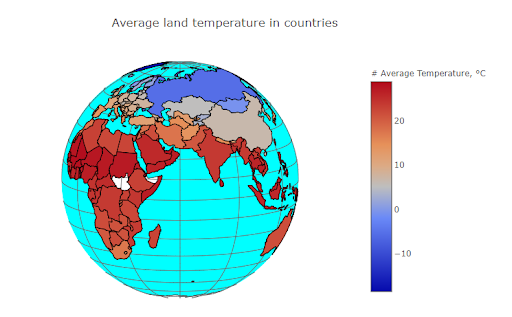
How to do the project: Here’s a helpful tutorial for doing time-series analysis using the Earth Temperature dataset.
44. Build a Computer Vision Face-Swapping App in Python
This is a massive dataset featuring more than 200,000 images of celebrity faces. If you’re interested in an OpenCV project, this is your go-to data source.
Project ideas include: building a Python face-swapping app, facial recognition, or celebrity face generation with deep convolution GANs.

How to use the data: Building a face-swapping app with OpenCV is one of the best ways to gain hands-on experience in computer vision. Check out this tutorial for hints and source code.
More Project Ideas from Interview Query
If you don’t want to commit to a project, you might consider answering real data science interview questions.
Practice questions will help you build your data science skills, including Python, SQL, and machine learning, as well as skills essential to a data science career, like business sense and product sense.
Also, you can check out these other data science project lists and datasets from Interview Query: