
Top 23 Regression Projects and Datasets (2025 Update) | Linear & Logistic Regression Ideas


Introduction
A well-curated regression dataset is crucial to building effective predictive models that analyze variable relationships. Whether you’re an experienced data scientist or just beginning your journey, there are two primary ways to initiate a new data science project. You can either develop a project by implementing an idea from scratch or by discovering an engaging dataset that sparks a project concept.
Both methods have their merits, and you’ll likely alternate between them throughout your data science journey. As a beginner in data science, I preferred searching for intriguing datasets to inspire my projects. I often found captivating datasets that enabled me to apply and implement various data science algorithms.
A simple yet powerful domain in data science involves regression projects and datasets. Numerous types of regression algorithms exist in data science, such as linear, logistic, lasso), polynomial, and more. Machine learning applications employ these algorithms to build predictive models that analyze relationships between dependent and independent variables in datasets.
This article explores regression projects in machine learning using the best datasets for linear, logistic, and multiple regression analysis. These projects are suitable for those who are studying machine learning or preparing for job interviews, as well as for experts looking to challenge themselves.
Whether you’re learning or interviewing, hands-on regression project ideas can solidify your grasp of modeling techniques.
Beginner Regression Projects and Datasets
1. Flowcast - Credit Card Fraud Detection Take-Home:

Fraud can take numerous forms, whether a single stolen credit card or credit card details getting compromised by a merchant using tools like credit card skimming devices. This logistic regression dataset allows for training classification models that mimic real-world decision-making.
This regression project takes 1-2 hours to complete and is ideal if you’re looking for hands-on practice with a dataset for regression analysis.
You must also document your solution by providing a clear and concise explanation of the methods you used, the assumptions you made about the data, and any other methods you considered.
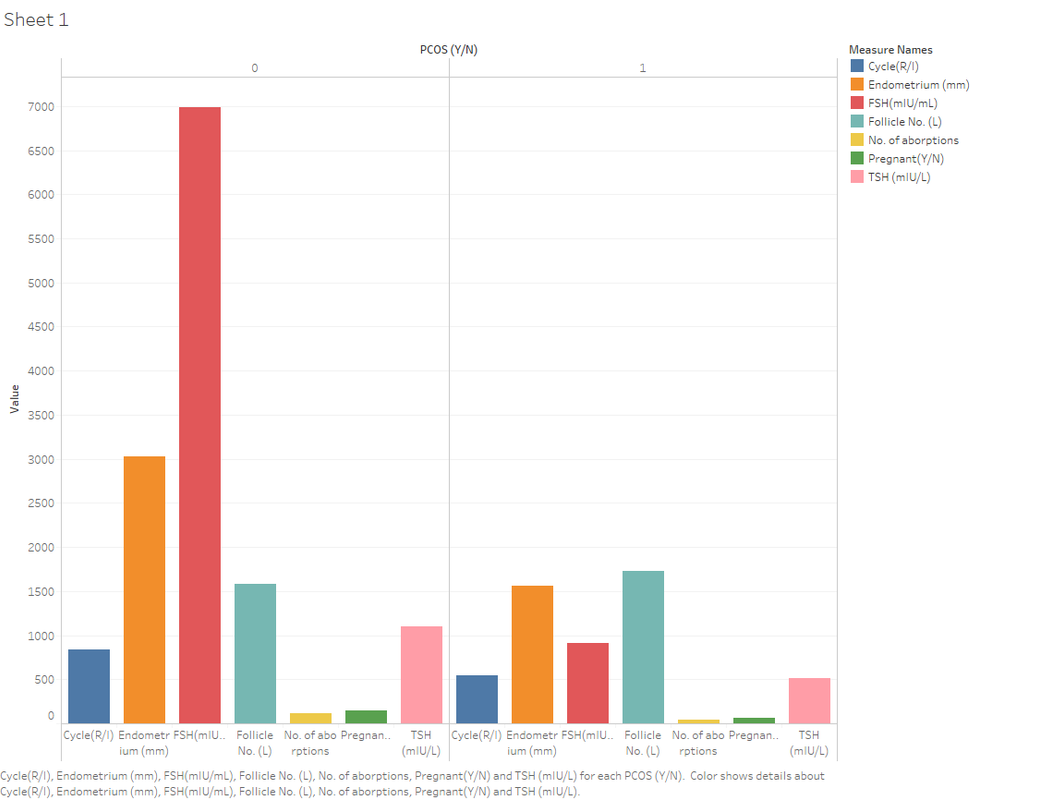
2. PCOS Diagnostic
Disease diagnostics is crucial to how data science is involved in many aspects of our lives. PCOS is one condition for which machine learning models have proven efficient in decreasing the chances of misdiagnosis due to human error. Diagnostic models for PCOS are often built using logistic regression.
Using the Polycystic Ovary Syndrome (PCOS) dataset, you can create your own.
3. Movie Revenue and Rating Prediction
One fun data science project for movie lovers is to create a machine learning model to predict a particular movie’s revenue and rating based on historical data of the genre. This information can help movie production companies decide what movies to invest in based on how well they draw in an audience. This is a great dataset for linear regression that helps you understand how independent variables influence a target outcome.
You can design and implement this project using the prebuilt TMDB 5000 Movie Dataset or build your custom dataset with The Movie Database API. Any multivariate regression model would be great for this project.
4. Fraud Detection
Today, everything is online, including some of our most critical and private information. Machine learning algorithms, especially logistic regression projects mixed with decision trees, can be used to track and analyze credit card transactions and predict fraud when it occurs.
Using a Card Transactions dataset, you can build a predictive model to classify credit card transactions and detect fraud.

5. Stock Price Prediction
In the finance world, stock prices are important to companies and individuals, making the ability to predict prices accurately very valuable.
Using multiple linear regression datasets, you can develop a stock price predictor and test different model variations. This can be taken even further by using Lasso and Ridge regression models and tested on the Tesla stock from the 2010 to 2020 dataset from Kaggle.
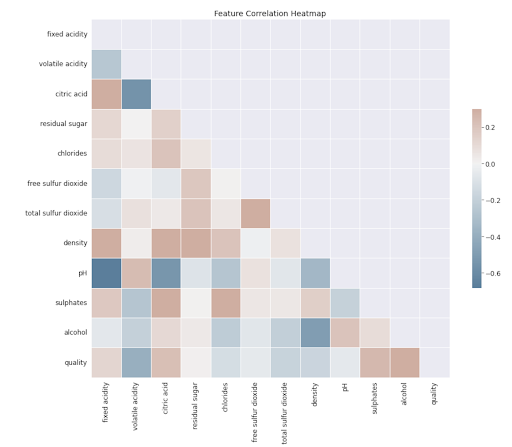
6. Wine Quality Classifier
Last but not least, for all the wine-loving data scientists out there, Kaggle has a red wine dataset that can be used to build a classification algorithm to predict whether a particular wine is good or bad based on 11 different variables. You can use linear or logistic regression to score wines and rank their overall quality.
7. Iris Flower Classification
Iris flower classification is a classic machine-learning problem that is perfect for beginners. The objective is to classify iris flowers into three species (setosa, versicolor, and virginica) based on four features: sepal length, sepal width, petal length, and petal width. This is a simple supervised learning problem, and you can experiment with various classification algorithms such as k-nearest Neighbors, Decision Trees, and Support Vector Machines.
You can start by using the famous Iris Flower Dataset from the UCI Machine Learning Repository.
8. Experience and Salary Analysis
Understanding the dynamics between experience and income is pivotal in the workforce, and this dataset provides a foundational base for exploring this relationship through simple linear regression.

Intermediate Regression Projects and Datasets
9. Capgemini: Movie Revenue Prediction Take-Home

Your client is a movie studio, and they need to be able to predict movie revenue to greenlight the project and assign a budget. Most of the data is comprised of categorical variables. While the budget for the movie is known in the dataset, it is often an unknown variable during the greenlighting process.
How to do the Project: Prepare a 20 to 30-minute presentation on a specific topic. This exercise aims to demonstrate your ability to draw insights from data, put insights in a business-friendly format, and confirm coding knowledge.
10. Demand Forecasting For Stock
One of the most essential things for any business is knowing how much stock they need to meet consumer demand in their area. Accurate demand forecasting can save companies a lot of money and help reduce losses due to waste, perishable products, or the inability to meet demand.
Again, data science– particularly machine learning-based demand forecasting models– comes to the rescue. Although there are various algorithms you can use in this project, linear regression is one of the simplest and most powerful ones.
To implement a demand forecasting project, you can use the Forecasts for Product Demand dataset, which contains historical product demand for a manufacturing company with four central warehouses.
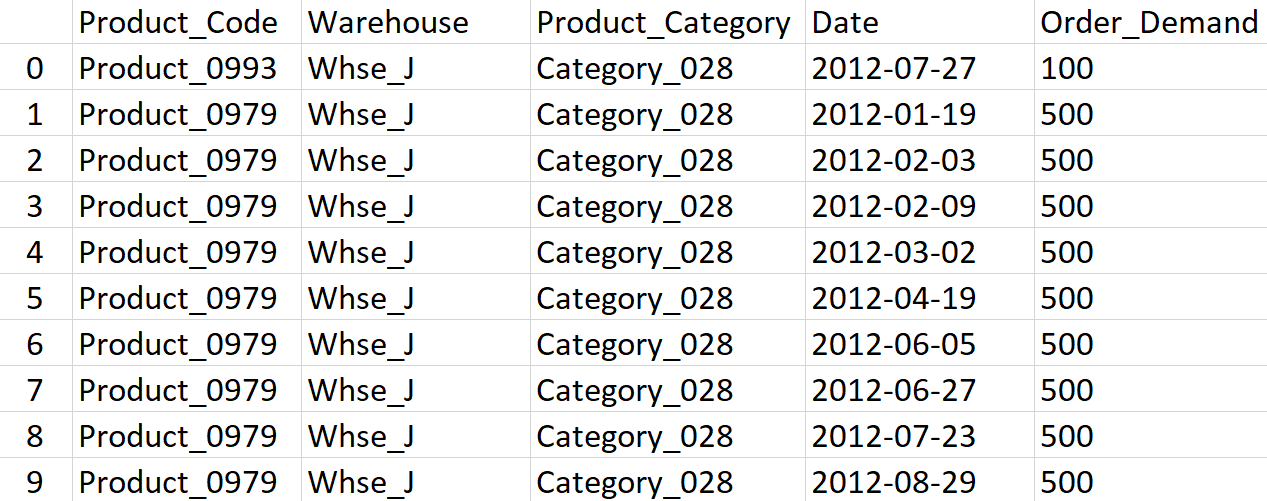
11. Customer Ad Clicks
We all have to deal with ads online – you’ve probably seen a few just in getting to this article. When it comes to ads, customer engagement is the top priority. The more clicks an ad gets, the higher the possibility that a customer will purchase.
Because of that, many companies focus on creating predictive models, often using logistic regression to analyze patterns and optimize ad locations and timing.
You can try this logistic regression project out by using the Predicting Customer Ad Clicks dataset or design and build a Bayesian Logistic Regression mode more suited to incorporate the real-time probability of ad clicks data.
12. Global Temperature and Pollution
Pollution and its environmental impact are among the most significant global concerns. Data science and machine learning can help us better understand how to tackle and solve that problem.
You can use multiple datasets to analyze the change in temperature, air pollution, and overall climate throughout the years with linear and other forms of regression. You can find multiple datasets to work within this GitHub repository.
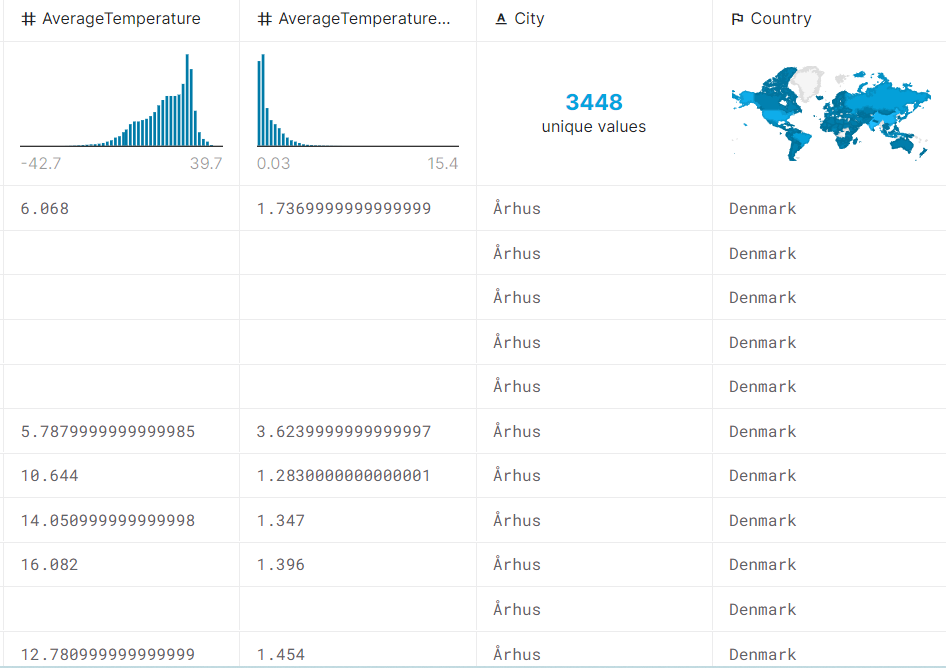
13. Who Will Survive the Titanic?
Although many of the projects mentioned in this article are beneficial for different reasons, sometimes we want to build a project just for fun and hone our skills.
One such project is predicting who would have survived the Titanic.
You can create a machine learning algorithm using the Kaggle Titanic dataset, which contains information about the names, ages, and sexes of around 891 passengers in the training set and 418 passengers in the testing set with a linear regression model.
14. Air Quality Index Prediction
Air pollution has become a growing concern for people worldwide. Machine learning models can predict the Air Quality Index (AQI) based on various factors, such as weather conditions, traffic data, and industrial activities. A time series model such as ARIMA or LSTM can be utilized for this purpose.
To create your own AQI prediction model, you can use the Air Quality in Madrid (2001-2018) dataset, which contains hourly data on air quality in Madrid, Spain.
15. Online Shopper’s Intention
Understanding customer behavior and preferences has become increasingly important in the age of e-commerce. Machine learning models can be employed to predict whether a customer will make a purchase based on their online activity. Common models used for this task include decision trees and logistic regression.
You can create your own predictive model using the Online Shoppers Purchasing Intention Dataset, which contains information about user behavior on an e-commerce platform. This dataset includes features like pages visited, time spent on the website, and the month and type of device used for browsing.
16.Medical Cost Personal Datasets
Insurance safeguards our health, possessions, and future. Predicting the insurance charges based on various parameters is crucial for insurance providers and policyholders.
What are the actual factors that influence insurance premiums? With this dataset, we can predict the insurance charges and discern the key drivers behind the cost
17. Mental Illnesses Prevalence Analysis
This project involves analyzing a dataset on the prevalence of mental illnesses to uncover key trends and insights. You will conduct an exploratory data analysis (EDA) to identify patterns across demographic groups and geographical regions, focusing on age, gender, and other relevant factors. The goal is to understand how mental health issues are distributed and correlated with different variables.
Please document your approach by briefly explaining the methods used, any assumptions made about the data, and why you chose your specific analysis techniques. The project should take approximately 1-2 hours to complete.
18. Predicting Environmental Pollution: Analyzing Ammonium Concentration Levels
The dataset provided contains information on ammonium (NH4) concentration levels recorded at various stations over time, along with the corresponding distances from a specific point of reference. This project analyzes the NH4 concentration data to identify patterns or anomalies that might indicate environmental changes or pollution events.
To complete this task, you must develop a model that can predict NH4 levels based on the provided data. Your solution should include a brief but clear documentation of your approach, covering the methodologies used, any assumptions made during analysis, and any alternative approaches considered.
Advanced Regression Projects and Datasets
19. ClearMotion: Vertical Acceleration Predictor Take-Home

With the recorded vertical acceleration of different cars on a given road, we can accurately cancel it using feedforward control.
For that purpose, we can map the road data regarding road velocity and store the data on the server. However, instead of actually driving different cars on the same road and recording their vertical accelerations, it is more efficient to train a neural network model for each car to predict the acceleration whenever some new road data is available through crowd-sourcing.
This assignment asks you to train such a model with given data. This Machine learning takehome asks you to train a neural network that takes road velocity (m/s2)(m/s2) as output.
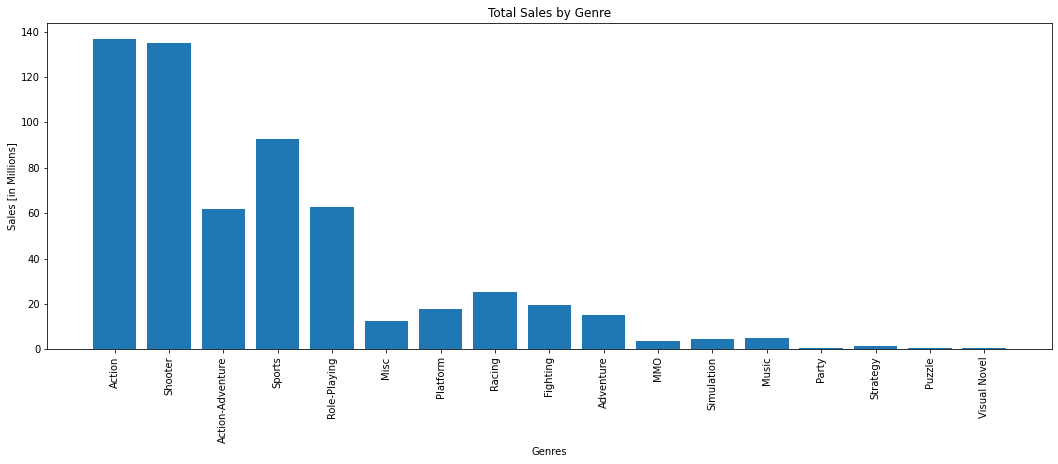
20. Video Game Sales Prediction
Video games are one of the biggest markets, and a lot of time, money, and effort goes into designing, developing, and distributing new video games. Access to sales data can make a tremendous difference for video game companies, gamers, or anyone working in that particular industry.
21. Song Popularity Predictor
Music is an essential part of everyone’s life. We use it to destress, express ourselves, or spend time with others. Getting a song on the top 10 or 20 lists is a challenging yet desirable goal for artists.
This raises an important question—what makes a song reach top status? If you’re a music fan, you can use the Spotify dataset with a regression model, like a decision tree, to predict which song will reach the top 10 list and the commonalities between the songs.
Using the Video Game Sales dataset with a neural network regression model can help you create a games sales predictor that will give you helpful information about what games to invest in, or if you’re a gamer, to buy and play.
22. Human Activity Recognition
Human Activity Recognition (HAR) is an advanced machine-learning problem that predicts human activities (walking, standing, sitting, etc.) based on data from wearable sensors like accelerometers and gyroscopes. This problem is challenging because it involves working with time-series data and requires advanced feature engineering or deep learning techniques such as Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs).
To build your own HAR model, try using one of the best datasets for regression analysis involving time-series features, which contains accelerometer and gyroscope data collected from smartphones worn by 30 subjects performing various activities.
23. WHO Life Expectancy Dataset
Life expectancy doesn’t just indicate the average duration of life. It tells stories of healthcare, socio-economic dynamics, public policies, and regional challenges. Through this, countries and regions can evaluate their success and areas needing attention.
What drives one nation to boast a higher life expectancy than another? This dataset lets you dig deep into the variables that play a pivotal role in shaping life expectancy.
Conclusion
As your career in data science progresses, building an extensive portfolio of projects not only deepens your expertise in the field but also significantly enriches your professional profile, making it more appealing to potential employers or collaborators.
When I first started, I couldn’t decide on a project simply because I didn’t have enough knowledge to choose a project and a dataset. One of the things that helped me was browsing dataset websites (e.g., Kaggle) and reading about different datasets and how they can be used.
That gave me the inspiration I needed to kick-start new projects. It also gave me the ability to work backward, starting with an algorithm in mind and then deciding on a particular project and dataset.
As your knowledge base and experiences grow with implementing more projects, you’ll soon develop an eye for suitable datasets and how to see their potential.
You can also explore public datasets for regression analysis on platforms like UCI or Kaggle to expand your project repertoire.
Learn more about Regression Models
This course is designed to help you learn everything you need to know about working with data, from basic concepts to more advanced techniques.