Top 20 Classification Machine Learning Datasets & Projects (Updated in 2025)


Classification Projects Overview
Classification techniques have numerous applications in data science and machine learning, particularly in relation to churn prediction, recommendation engines, sentiment analysis, loan approval, and anomaly detection.
Therefore, if you want to land a data science job, you need to understand how classification works, the math behind it, and the situations we can treat classification problems.
Besides reading up on the subject and practicing interview questions, you can build your expertise by exploring hands-on projects. Projects provide training in classification algorithms and real-world use cases, and, ultimately, they can help build domain expertise.
We’ve highlighted some of the best datasets for classification along with machine learning projects (although you might prefer to scrape your own and create an original dataset).
You’ll also find links to tutorials and pre-set projects for these data sources.
Beginner Datasets for Classification
Practice using classification algorithms, like random forests and decision trees, with these datasets and project ideas. Most of these projects focus on binary classification, but there are a few multiclass problems. You’ll also find links to tutorials and source code for additional guidance.
Also, check out our list of great beginner data science projects for more ideas.
1. Create a model to predict if a permit is about electrical permissions

Build a classifier that predicts whether a building permit’s ‘type’ is ELECTRICAL or not. Note that there are many different types of permits, but we are only interested in ELECTRICAL.
You are free to use any algorithm(s). You are also free to use all or a subset of the information included. Use your classifier to predict whether each building permit contained in xtest_data.csv is ELECTRICAL or not.
How to do the Project: Please write in python and comment appropriately to justify your feature selection, model(s) choices, validation, etc.
Ideally, your code and comments should tell a complete story, but you are also welcome to write a short note highlighting your work on this project.
For example, feel free to identify something you found particularly challenging and how you tackled it or what avenues you might pursue, given substantially more time.
2. Classifying Mushrooms
One of the best sources for classification datasets is the UCI Machine Learning Repository. The Mushroom dataset is a classic, the perfect data source for logistic regression, decision tree, or random forest classification practice. Many of the UCI datasets have extensive tutorials, making this a great source for beginner classification projects. A few specific UCI datasets to consider include the Wine Quality dataset and Iris classification data.
How to Do the Project: Check out this tutorial for an overview of using several algorithms to classify mushrooms, including KNN, decision tree, random forest, and support vector machine classifiers.
3. Image Classification with Handwriting Recognition
Want to learn image classification? Take a look at the MNIST dataset, which features thousands of images on handwritten digits. MNIST includes a training set of 60,000 images and a test set of 10,000 examples. This is one of the best datasets to practice image classification, and it’s perfect for a beginner.

How to Do the Project: Practice computer vision concepts and build a simple digit recognizer. Here’s a helpful tutorial to get started.
4. Predicting Titanic Survivors
The Titanic Machine Learning Competition is one of the most popular data science competitions on Kaggle. It’s the perfect building expertise with classification algorithms, like K-nearest neighbor and random forest. The competition’s aim is simple: predict who survived the sinking of the Titanic using machine learning.
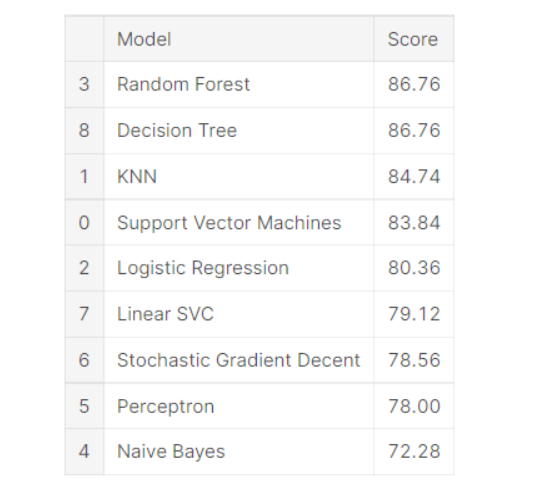
How to Do the Project: See this tutorial on Medium, which will help you apply seven classification algorithms to the Titanic dataset. Which algorithm do you think has the best accuracy?
5. Loan Prediction with Classification Models
Classification is widely used for loan prediction. If you’re interested in fintech jobs, you should absolutely have experience building loan prediction models. A great dataset to start with is the Loan prediction dataset on Kaggle, which you can use to build a yes/no loan approval model. Another finance dataset to check out is this bank marketing dataset. Use the data to determine whether a client will make a deposit.
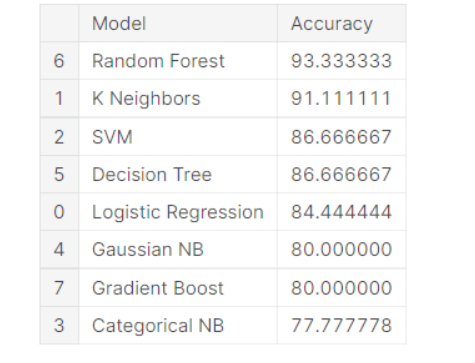
How to Do the Project: This Kaggle notebook offers a solid explanation of using logistic regression, support vector machine, or decision tree classifiers for loan approval.

Intermediate Datasets for Classification
These projects test more intermediate classification skills, like using convolutional neural networks (CNN). Any of these datasets and project ideas are great for those who have experience working with machine learning.
6. Dia & Co.: Business Loan Repayment Take-Home
As a company, we have to buy our books ahead of time. We took out a loan last month to buy our original batch of books. The value of the loan was the total cost of all the books that we bought.
We made some money back through customers buying our books last month. Next month, we know which books we will be sending to which customers, but we do not know who will buy what books.
The question for you to answer is: Will we be able to both pay back our loan and afford our next book purchase order?
You should create some sort of machine learning model for answering this take-home as opposed to simply looking at the average conversion rate or something like that).
However, we do not expect you to build models from scratch. NumPy, SciPy, sci-kit-learn, and everything else are all fair game.
7. Predicting Breast Cancer with Deep Learning
Health informatics is a fast-growing field in data science, and there’s a wide range of applications of machine learning in healthcare. This Python project uses the IDC (Invasive Ductal Carcinoma) dataset and asks you to build a model to predict IDC breast cancer. You could also work on a similar project using the UCI Breast Cancer dataset. )

How to Do the Project: This tutorial walks you through using Python - along with the Keras library - to build a convolutional neural network.
You might also want to check out the ImageNet dataset, a great source for CNN projects, or this tutorial for building a CNN with Python.
8. Conversion Rate Modeling
One use case for classification is building prediction models, specifically related to marketing and conversions. The challenge for projects like these is finding reliable data sources.
One option is this Clicks and Conversion Tracking dataset on Kaggle, which features the social media marketing performance of an anonymous brand. If you’re looking for another source, check out this conversion rate dataset on Github.
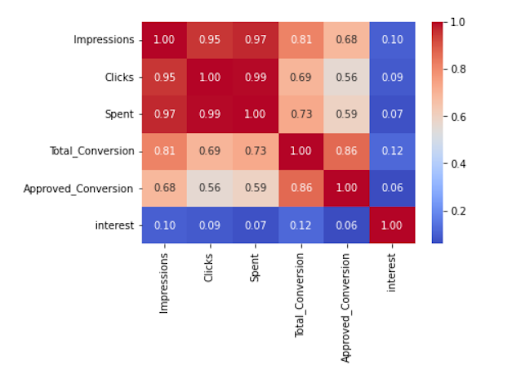
How to Do the Project: There are numerous models you can create to predict conversions, but here’s a helpful tutorial that examines using decision trees to predict conversion rate.
9. Music Genre Classification Project
Building genre classification models will allow you to practice intermediate Python techniques, including K-nearest neighbor and random forest algorithms, as well as the Librosa library.
There are numerous datasets you can use. While the Million Song Dataset is one of the best, there are also music datasets in the data world.

How to Do the Project: Here’s a helpful tutorial that looks at using content-based filters for music genre classification.
10. Speech Emotion Recognition
The RAVDESS dataset features 7,000+ files, in which actors express various emotions while speaking. In terms of building speech recognition models, this dataset is one of the most comprehensive out there.
You might also want to check out data sources like the LSSED: A Large-Scale Dataset and Benchmark for Speech Emotion Recognition or see this list of emotion recognition datasets.
How to Do the Project: This tutorial walks you through using a convolutional neural network to examine RAVDESS data.
11. News Article Categorization
With the increasing volume of news articles available on the internet, classifying them into different categories can be helpful in organizing and filtering content for users. In this project, you’ll build a machine-learning model to classify news articles into various categories, such as politics, technology, sports, and entertainment.
You can start by using the BBC News Classification Dataset, which contains over 2,000 news articles categorized into five classes: business, entertainment, politics, sports, and tech. You can experiment with various classification algorithms, such as Naive Bayes, k-Nearest Neighbors, and Support Vector Machines.
How to do the Project: Follow this tutorial on Analytics Vidhya that demonstrates how to perform text classification using various machine learning algorithms, such as Naive Bayes, Logistic Regression, and Support Vector Machines.
12. German Credit Data Analysis
The German Credit dataset provides insights into the factors that financial institutions consider when determining the creditworthiness of an applicant. Featuring a mix of numerical and categorical attributes, this dataset presents opportunities for various forms of data analysis, machine learning, and prediction modeling. By understanding the correlations and patterns within this data, one can develop predictive models to determine the likelihood of an approval based on an applicant’s credit, or even spot potential biases in the credit decision-making process.
The dataset has been sourced from Professor Dr. Hans Hofmann of the Universität Hamburg. It comprises 1000 instances with attributes capturing an applicant’s financial behavior, history, and personal details. For instance, it includes attributes such as the status of the applicant’s checking account, credit history, purpose for the loan, and personal information like age and job type. Two versions of the dataset are provided: the original dataset (german.data), which contains a mix of numerical and categorical attributes, and a modified dataset (german.data-numeric), formatted for algorithms that prefer numerical input, wherein categorical variables have been transformed into numerical indicators.
How to do the Project: Download this dataset from GitHub and identify the features in the dataset using this .names file. Dive into the German Credit dataset, assess the patterns and build a predictive model for credit approval. Begin with german.data to grasp the categorical essence of the data and consider using german.data-numeric for algorithmic requirements.
13. Loan Default Model
![]()
Assume you have been selected to help BusinessOptics build a machine learning model to estimate the value of current loans using historical credit data. This project aims to enhance their credit risk assessment process by developing a probabilistic model to predict the probability of default on loans.
The goal of this task is to fit a statistical model to historical credit data and then use the model to estimate the value of current loans.
How to do the project: Load the data_science_task.csv file using pandas and explore the dataset with plots to understand variable distributions and relationships. Separate the data into historical (“PAID_UP” or “DEFAULT”) and current (“LIVE”) datasets using the status field. Fit a probability of default model to the historical data with a scikit-learn classification algorithm, creating a hold-out set for evaluation and encoding categorical variables appropriately. Assess model performance using a suitable metric from scikit-learn by predicting default probabilities for the test set. Predict default probabilities for current loans, calculate expected repayment amounts by multiplying one minus the default probability by the outstanding amount, and sum these to find the total expected book value, ensuring it reflects the historical default rate.
Advanced Datasets for Classification
Practice advanced machine learning skills with these datasets and project ideas. Most advanced classification problems include multiclass classifiers, deep learning, and image classification.
14. Sonder: Real-time Crime Categorizer Take-Home

Assume you have been selected to help the Chicago Police Department build the machine learning services that will power their next generation of mobile crime analytics software. This software aims in particular at predicting, in real-time, the crime category as soon as it is reported by an emergency call (for instance robbery, assault, theft).
This prediction can only be made with information available at the time of the call (such as time and location) without on-the-ground assessment or knowledge of ex-post action (such as arrest, conviction, demographics of the victim(s) or offender(s).
Build a model that can predict whether or not the crime is a THEFT (identified in the Primary Type column), given a relevant set of features at your disposal. Please explain your choice of features in light of the use case highlighted above. Use the training data to train the model and discuss its performance on the test data.
The questions for you to answer in this take-home are:
- What is the accuracy of a naïve model that would always guess
THEFT, and what is the accuracy of your model? - Are there any other metrics you have computed to assess your model’s performance? If yes, discuss their values.
- What approach did you use and why?
- How would you improve your model if you had another hour/another week at your disposal?
15. Multiclass Text Classification
You’ll find a variety of text datasets available online, many of which are great launching points for a text classification project. Text classification, however, can be tricky, so here are a few specific datasets we thought would be particularly helpful.
The Hate Speech and Offensive Language dataset on Kaggle is a great source for a Python natural language processing problem looking at multiclass classification – determining whether the text is offensive, hate speech, or neither.
You might also consider Fake News detection. A team from UC Berkeley built a multiclass classifier to determine if news articles were fake news, clickbait, or neither. You can read about that project here.
How to Do the Project: You can scrape your own text data source. Twitter is great for projects like this, like this example that determined the most hated player in the NFL.
16. Detecting Emotion in Text with Python
Here’s a great Python project for text classification: What emotion is being conveyed? These problems are difficult, often because there aren’t many reliable labeled datasets, on top of filtering for multiclass.
This Kaggle text emotion dataset is perfect for the problem. But you’ll also find others, like this Rotten Tomatoes sentiment analysis from Stanford, which features a rating between 1-25 for movies, or the Sentiment140 dataset, with data on brand sentiment from Twitter.
How to Do the Project: This end-to-end tutorial from The Clever Programmer walks you through data preparation, tokenization, and creating a list of emotional words to classify the text.
17. Python Sign Language Detection
One of the best advanced machine learning projects, gesture recognition is one of the most challenging problems in computer vision. There are two types: static and real-time dynamic gesture recognition. Check out this problem Sign Language and Static Gesture recognition with scikitlearn on GitHub, which features a great dataset of ASL images. Be sure to check out this guide to sign language recognition with CNNs.

How to Do the Project: The hardest part will be finding good data – you also have the option to create your own dataset. This YouTube tutorial shows how to capture images with OpenCV and label them with Labellmg. Ultimately, it walks you through real-time gesture recognition with Tensorflow.
18. Object Detection with COCO Dataset
Object detection and image segmentation are two complex data science problems. One of the best datasets for exploring object detection is the Common Objects in Context dataset, a large-scale dataset featuring numerous images in context.

How to Do the Project: If you want to give it a shot, check out this guide on image segmentation with COCO. The tutorial will show you how to manipulate images with the Python Pycoco library and use Keras to process and classify images.
19. Banknote Authentication Dataset
The Banknote Authentication dataset offers a unique perspective into the realm of banknote verification. Stemming from high-resolution grayscale images of genuine and counterfeit banknote specimens, this dataset enables machine learning enthusiasts and researchers to construct predictive models that differentiate genuine banknotes from forgeries. The essence of this dataset revolves around attributes derived from the Wavelet Transform of these banknote images, making it an intersection of image processing and predictive modeling.
This dataset has been generously made available by Volker Lohweg from the University of Applied Sciences, Ostwestfalen-Lippe. The data encapsulates properties extracted from 400x400 pixel images, which were captured using an industrial camera typically employed in print inspection. These grayscale images boast a resolution of approximately 660 dpi. A Wavelet Transform tool was employed on these images to distill the dataset attributes, extracting key features pertinent to the authentication process. With attributes like the variance, skewness, kurtosis, and entropy of the Wavelet Transformed image, this dataset forms a basis for robust banknote authentication systems.
How to do the Project: Access this dataset from the UCI Machine Learning Repository and acquaint yourself with its intricacies. While exploring the Banknote Authentication dataset, discern the intricacies of the Wavelet Transformed attributes and understand their implications for banknote verification. Use this data to build a predictive model adept at differentiating genuine banknotes from counterfeit ones, leveraging the unique attributes it offers. As you progress, consider diving deeper into the Wavelet Transform technique to understand its potency in image feature extraction.
20. Spam Article Classifier
![]()
Assume you have been selected to help our team develop a machine-learning model to classify articles as either spam or valid for our researchers. We have been inundated with spam articles in our news feeds, and we aim to identify and eliminate these to ensure only informative content is delivered.
How to do the project: To classify articles as SPAM or not, start by loading and examining the data from scraped_articles.json and blacklist.json. Perform exploratory data analysis to identify key features and clean the data by preprocessing text and removing blacklisted sources. Select features like word frequencies and TF-IDF scores, then choose and implement a machine learning algorithm such as Logistic Regression or Random Forest. Train and validate your model, evaluating performance using metrics like accuracy and F1 score. Interpret the model’s results to understand key drivers of classification, and document your process and findings.
More Data Science Project Ideas & Datasets
Interview Query offers a variety of ways to learn and practice classification. Check out these project idea lists from Interview Query:
- 10 Python Data Science Projects
- 10 Regression Projects & Datasets
- 29 Machine Learning Project Ideas for All Levels
- 31 Free Datasets for Your Next Project
- 10 Sentiment Analysis Project Ideas and Datasets
- 13 Marketing Analytics Projects and Datasets
If you’re currently learning data science or preparing for a data science interview, you’ll also find these resources helpful:
- 500+ Real Interview Questions
- 1,600+ Company Interview Guides
- 30+ Hours of Data Science Interview Course Content
- 30+ Practice Take-Homes
- Top 13 Customer Churn Datasets and Projects