
Top 17 Customer Churn Datasets for Analysis & ML (2025)


Introduction
Whether you’re a beginner or a more advanced data scientist, finding the right data science project is crucial to improving your skills and mastering algorithms. There are a couple of ways to achieve this: 1) by solving a problem statement that you found intriguing, and 2) by delving into some of the free, popular datasets available online.
The main obstacle is selecting the right dataset for a specific problem statement. There is a wide range of available datasets of varying difficulty levels with different functions. This can make settling on the right project difficult, leaving you with no bandwidth to immerse yourself in the fun part – solving the problem!
This article discusses customer churn data, an essential success metric for businesses in every industry and a favorite problem for data scientists. We’ve scoured the internet for different customer churn datasets to highlight our favorites in order of difficulty.
Understanding Customer Churn
Customer churn is the percentage of customers who stopped using a company’s product or service during a specified time period. For example, if a company starts its quarter with 400 customers and ends with 380, its quarterly churn rate is 5%.
This is a vital metric because retaining existing customers is more cost-effective than acquiring new ones. Churn can occur for various reasons, including unsatisfactory service, competing products, changing customer needs, and lacking engagement.
Companies need data scientists and business analysts to analyze customer data to identify patterns and factors contributing to churn. Through data collection, exploratory data analysis (EDA), and predictive modeling, data scientists and analysts help implement targeted strategies to retain customers, enhance consumer satisfaction, and maintain sustainable growth.
Here are the steps to conduct an impactful churn analysis study:
- Define churn: Clearly define what constitutes churn for the company. This could include when a customer doesn’t make a purchase for a specific period or cancels a subscription.
- Benchmark churn threshold: The acceptable level of churn can differ significantly between industries. While a retail company could have a high turnover, industries that require specialized skills might aim for much lower churn rates because of the time and resources invested. For instance, even a 1% churn rate in healthcare could lead to damages of a few million dollars. You’ll analyze historical data and industry benchmarks to determine an acceptable churn level for a specific company.
- Collect the right data: Gather comprehensive customer data. This should include demographics, transaction history, customer support interactions, feedback, and other relevant information.
- Pre-process your data: Remove inconsistencies, missing values, or outliers.
- Perform exploratory data analysis (EDA): Use EDA techniques to explore the data visually and statistically. Understand customer demographics, behavior patterns, and interactions with your products or services.
- Select the right features: Identify relevant features or variables that might influence churn. This could include purchase frequency, customer tenure, customer support interactions, and usage patterns.
- Segment customers: Segment your customer base based on demographics, geography, usage behavior, etc.
- Use predictive modeling: Utilize machine learning algorithms like logistic regression, decision trees, or neural networks to predict churn. Train the model using historical data and test its accuracy using validation datasets. During model selection, one important thing to note is the skewness of the distribution of churned customers - typically less than 5-10%. This will invariably lead to an imbalanced distribution of the two classes, which should be considered during the EDA and the subsequent choice of data science models.
- Identify churn indicators: Determine which factors strongly correlate with churn. These insights are valuable for making strategic business decisions.
- Analyze feedback separately: Using customer survey data, identify common issues mentioned by customers to address the root causes behind churn.
- Suggest retention strategies: Based on the overall analysis, suggest targeted retention strategies to your client. This might include personalized marketing campaigns, improved customer service, loyalty programs, or product enhancements.
- Monitor and iterate: This is a key but underrated step. Continuously monitor the impact of retention strategies. If churn rates decrease, analyze the reasons behind the improvement. If they don’t, refine your strategy based on current customer feedback and new data insights.
Beginner Customer Churn Datasets & Projects
1. Telco Customer Churn
The Telco customer churn data contains information about a company that provides phone and Internet services to over 7000 customers in California. It indicates which customers have left, stayed, or signed up for service. Multiple important demographics are included for each customer and a Satisfaction Score, Churn Score, and Customer Lifetime Value (CLTV) index.

One of the most popular churn datasets to work on, this dataset from IBM is designed to help you practice analyzing customer behavior and developing targeted retention programs, with a focus on understanding which factors influence customer churn.
2. Bank Customer Churn Dataset
This bank’s customer data contains information about a hypothetical European-based bank that has provided a dataset of almost 3,000 customers. This includes customer demographics and bank details, like credit score and the number of bank services they use.
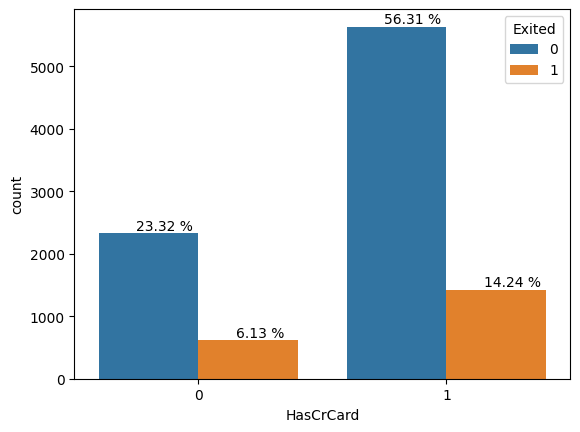
3. Tours and Travels Customer Churn Prediction
A travel company wants to predict whether its customers will churn based on indicators like age, frequent flyer information, annual income, and services used. You can utilize this free Kaggle dataset to build a predictive model using ANN, random forest, or whatever algorithm you consider most suited to the problem statement.
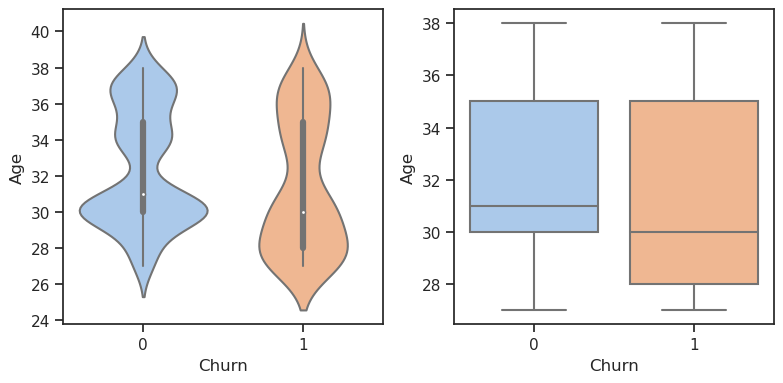
4. E-commerce Customer Churn Analysis and Prediction
The data set belongs to an e-commerce company that wants to know which customers are going to churn so they can better tailor promotional campaigns. This is a common type of data science problem.
The data file has 20 columns and over 5000 rows with detailed information about customer demographics and online behavior.
Tip: Perform a thorough exploratory analysis of the provided data to gain insights into customer behavior. This includes analyzing patterns and trends in variables.
5. Employee Churn
This is another dataset created by IBM data scientists. You’re given employee data, including demographics, performance metrics, and attrition.
Although this is an employee dataset instead of a customer one, it can be very useful to solve a typical HR analytics problem statement. The dataset is rich with information, with various factors ranging from home-work travel distance to the number of jobs the employee has had.
This will allow you to dissect the project in multiple ways, create a multivariate analysis, and have a deeper understanding of the recommendations you may be expected to provide in a similar project.
6. Gym Customer Churn Dataset
This new dataset from Kaggle includes information about a hypothetical gym based in the United States. The dataset contains various attributes such as customer demographics, membership details, and usage patterns. The main goal of this dataset is to predict the probability of customer churn for the next month, identify key customer profiles, and develop specific recommendations to improve customer retention and satisfaction.
Intermediate Customer Churn Datasets & Projects
7. Telecom Churn
With the rapid development of telecommunications, service providers are facing competitive consumer markets. Questions about these scenarios can be applied to the real-world business problems asked in interviews, so practicing multiple projects with advanced analytics in the telecom domain will help prepare you.
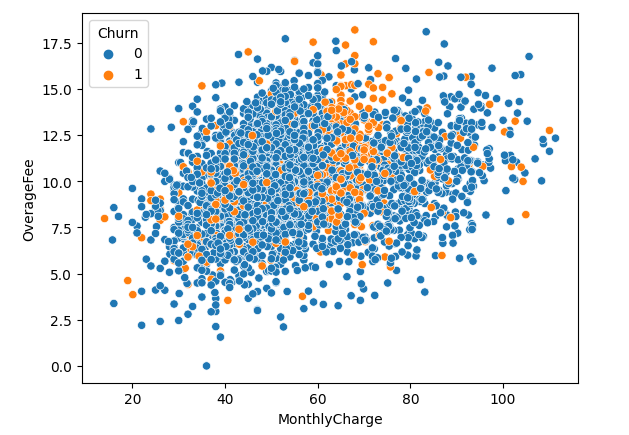
The given dataset contains customer-level information for a telecom company. Service information is recorded for each customer, primarily related to their usage stats. You’ll need to segment customers, analyze each segment separately, and understand their pain points and reasons for attrition.
Tip: Use a heatmap to visualize the correlation between customer demographics and usage numbers.
8. Subscription Service Case Study
In a world where SaaS and streaming services heavily prioritize analytics, experience with analyzing customer churn on subscription-based services is key to acing many job interviews. You need to understand the business and its revenue model, the customer journey, and the buyer persona well to tackle this complex problem.
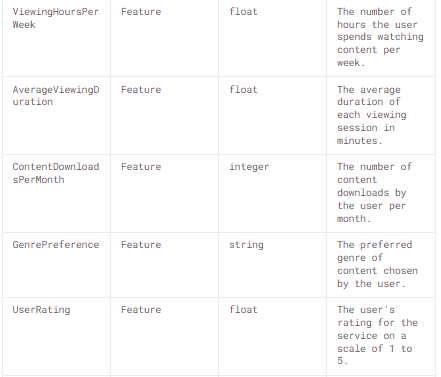
This dataset contains anonymized information about customer subscriptions and their interaction with the service. This includes various features, such as subscription type, payment method, viewing preferences, customer support interactions, and other relevant attributes.
9. Orange Telecom Customer Churn Dataset
This is another telecom churn dataset, with columns detailing customer behavior, usage, and statistics. You can use techniques like ANOVA to conduct a multivariate analysis and implement modeling algorithms, such as the decision tree or random forest, to predict whether a customer will likely churn.
10. Internet Service Provider Customer Churn
This problem statement is similar to the example of a telecom provider. Internet service providers face fierce competition, so optimizing customer attrition is key to increasing their margins.
The provided dataset belongs to an unknown internet service provider. It contains information from over 70,000 unique customers, including their internet usage, subscription age, number of service failures, and additional services used.
You can use a logistic regression model to solve the problem, but remember to keep the business context in mind. For instance, retention surveys have shown that while price and product are important, most customers churn because of service failures and dissatisfaction with the customer care team.
11. Predict Credit Card Churn
Managing credit card churn is essential for banks. Customers who frequently open and close credit card accounts may present a higher risk, indicating financial instability and an increased likelihood of default.
Banks prefer to manage a lower-risk customer base to maintain the overall health of their credit card portfolios. This helps them project revenue with better accuracy and meet regulatory compliance guidelines.
The dataset contains credit card information from 10,000 anonymous customers that provides a detailed overview of their demographics, background, and financial health. With over 18 features provided, this is a fascinating case study to practice with.
12. Insurance Churn Prediction
This dataset contains information about a hypothetical European-based insurance provider that has provided a dataset of over 2,000 participants. The dataset includes various features such as customer demographics, insurance details, and usage patterns. Key attributes include multiple numerical and categorical features, capturing a wide range of customer information.
Advanced Customer Churn Datasets & Projects
13. Cell2Cell Customer Relationship Case Study
This is an open-source dataset created by the Teradata Center at Duke University. The Cell2Cell dataset is pre-processed and contains over 70,000 instances and 58 attributes. It can be used to understand subscriber churn. Some interesting questions to explore while solving this problem are:
- Is the company losing high-value subscribers?
- What different customer segmentations are possible? Which ones can help us analyze the churn problem?
- How well are the retention policies implemented? What role does customer support play in minimizing churn?
14. Assigning a Churn Risk Score
This is an interesting dataset that was part of the HackerEarth ML Challenge. It poses a more advanced churn problem, where instead of assigning a binary churn prediction score, you’re expected to assign a churn risk score between 1 and 5. This will help the company create targeted retention plans and prioritize customer cohorts by their churn risk.
Tip: An important part of your data preparation should be outlier analysis while segmenting the customer groups by churn risk.
15. E-commerce Retail User Churn Dataset
E-commerce businesses rely on repeat customers for sustained revenue. These companies can increase customer lifetime value and overall revenue by reducing churn. This often involves optimizing customer service, personalizing marketing and promotions, and improving website navigation.
The dataset provides a detailed overview of customer interactions with the site.
Try to address the following questions:
- What customers are likely to churn?
- What are their common features?
- Which classification model performs the best?
- Can we redefine the churn event to a multi-class problem?
16. Waze Synthetic User Churn Dataset
This fascinating dataset is provided as part of the Google Advanced Data Analytics Professional Certificate program. It focuses on a user churn problem within the Waze app, where instead of simply predicting whether a user will churn, the aim is to analyze and predict user behavior to understand engagement and retention patterns. This will enable the development of machine learning models that help identify at-risk users and formulate strategies to improve user retention.
17. User Behavior on Instagram Dataset
This is a compelling dataset centered around Instagram user behavior analysis. It delves into various aspects of user engagement, such as likes, comments, and shares, offering a comprehensive view of how users interact with content on the platform. The analysis also extends to understanding content types, hashtag effectiveness, and user demographics, which can provide valuable insights into optimizing content strategy. The dataset helps identify factors that influence user retention by tracking follower growth and churn. Additionally, it explores the impact of influencers and brand advocacy, making it a valuable resource for studying the dynamics of social media engagement.
More Churn Problems
Aside from full-fledged machine learning problems, there are a few categories of churn analysis questions that are commonly asked in data science interviews. Here are some examples that you can practice with on the Interview Query platform:
Conclusion
Ultimately, analyzing customer churn comes down to practice and selecting the right problems and datasets to try. Having a solid understanding of the specific industry while conducting churn analysis is crucial to implementing effective real-world solutions. After all, reducing churn is not just about retaining customers– it’s about building enduring relationships based on trust, value, and exceptional service. To provide value, it is imperative to know both the business and its customers well.
Other sources of open-source data science datasets include the UCI Machine Learning Repository, GitHub, Data.gov, and Google Dataset Search. You can also refer to our ultimate guide to data science projects for more case studies to get your hands on.