
Top 31 Machine Learning Projects with Datasets (2025)


Overview
Machine learning can be a complex field, combining concepts from probability, statistics, linear algebra, calculus, and computer science. Its applications span from fundamental tasks like linear regression to advanced techniques such as image generation, making it both challenging and exciting.
To break into the world of machine learning, having a great resume isn’t enough. You need to demonstrate practical experience with machine learning projects, backed by a strong portfolio.
In this article, we’ve compiled a list of machine learning project ideas with datasets for 2025 to help you build a standout portfolio. Whether you’re looking for beginner machine learning projects or more advanced tasks, these projects will help boost your credentials and give you the hands-on experience needed to land your dream job in machine learning.
How Machine Learning Projects Build Your Portfolio
The importance of portfolios in the machine learning job space cannot be understated, particularly for new grads and candidates without experience. A well-structured portfolio demonstrates a candidate’s expertise, ability to solve real-world problems, and capacity for communicating complex ideas. After all, machine learning jobs require more than just the knowledge of theory; and a proficient machine learning engineer certainly knows more than the documentation of various ML APIs and libraries.
Being a competitive machine learning engineer requires both a grasp of theory and application. The best way to showcase this is through a well-rounded and expansive portfolio. A good project for your portfolio should:
- Expand on your interests: Personally, the best portfolio projects I have made throughout my career are those that align with my personal interests. A project can have objective-based goals and passion-based goals. A recruiter can certainly tell whether a project has passion poured into it— a certain amount of oomph.
- Diversify your interests: This stands in contrast to point number 1. While expanding on your interests can help you create interesting projects, it can also be restrictive. Having experience in different fields of machine learning can help you develop a well-rounded portfolio. A good project should not only expand on your interests but should also introduce you to other aspects of the field.
- Generate insights and learnings: A good project for your portfolio always generates insights and skills that propel you forward in your career. If you have something interesting but provides absolutely no new skills, then you should consider another project.
- Realistic: We understand that a tough project can definitely add a “wow” factor to your portfolio. However, ensuring that your projects are realistic makes sure that you stay grounded and finish in a reasonable time. Projects, even the most passionate ones, when drawn out too long, will be stuck on the back burner.
Here is Interview Query’s handpicked list of interesting, insightful, and realistic machine-learning projects.
Beginner Machine Learning Projects
Beginner machine learning projects will help you practice and build competency in core machine learning skills. If you are a beginner, these projects allow you to understand and slowly strengthen your skills in model engineering (including soft skills). If you are an experienced veteran, these projects can still be insightful and can be fast projects that require little to no commitment.
Examples of beginner projects include basic recommendation engines, prediction models, and entry-level computer vision projects. These are some of the top machine-learning projects for beginners:
1. Analyze Google Search Inquiries
For those interested in: Data analysis, Trend analysis
Difficulty Level: 3⁄10
What do you do when you are missing critical information or need to know more about a specific topic? Today’s most straightforward approach to that question is, “Google it!”. Millions of people use Google every day in billions of searches to find information about a wide variety of topics.
One exciting project idea is to use Google’s Pytrends API to analyze what people around the world are searching for. Pytrends can help you obtain different information about what people use Google for. For example, you can find search statistics about a specific topic, and trending searches, and categorize those pieces of information by time, region, and keywords.
2. Image Recognition
For those interested in: Computer Vision, Neural Networks
Difficulty Level: 4⁄10

Machine learning is an umbrella term covering multiple subfields, including computer vision. Computer vision has quite a bit of active research as the potential for the automatic interpretation of visual inputs is massive. Because of that potential and research, it attracts a lot of attention from the users.
Suppose you’re new to machine learning in general or to computer vision; an excellent place to start is using the MNIST dataset to build a digit recognizer. Building this project will help you get familiar with the basics of computer vision and neural networks.
3. A Simple Article Sharing Recommendation Engine
For those interested in: Recommendation Systems, Collaborative filtering, User-User Similarity Matrix
Difficulty Level: 3⁄10
Categorizing machine learning projects into simple or complex ones is a challenging task. The project’s complexity often depends on how you choose to implement it rather than the project itself. One great example of that is recommendation systems. At first, you would assume that building a recommendation system is an intermediate or advanced project.
But with experience, you can create simple and straightforward code to implement your recommendation engine. For example, you can use the rich, rare dataset to implement a simple recommendation system using a user-user similarity matrix that recommends items that similar users like.
4. Human Activity Recognition
For those interested in: Multiclass classification, Data visualization and analysis, Sensor data analysis, Health and Fitness analytics
Difficulty Level: 4⁄10
If you are into being physically active and sporty, one project that might interest you is the recognition of different human activities using the smartphone dataset. This dataset contains the fitness activity recordings of 30 people captured through smartphone-enabled inertial sensors. This project aims to use machine learning algorithms to accurately classify the different fitness activities. Mainly, you will need to implement a multiclass classification algorithm and work on your data visualization and analysis skills.
5. Predicting Wine Quality
For those interested in: Regression models, Data visualization, Prediction modeling, Wine analytics
Difficulty Level: 3⁄10
How can you tell whether a brand or bottle of wine is worth your money? You probably need to know a bit about the type of grape, the age of the wine, and its price. Or, you could build a prediction model to determine if a bottle is of quality or not. The Wine Quality Data Set is a classic in the UCI Machine Learning Repository (a go-to source for machine learning datasets).
Using the wine dataset, you can build a prediction model, as well as gain hands-on experience with data visualization, regression models, and more. Follow this tutorial for predicting wine quality in Scikit-learn.
Another option: Check out the Red Wine Quality dataset on Kaggle for project inspiration.
6. Cancer Prediction Model
For those interested in: Health analytics, Classification models, Diagnostic analytics
Difficulty Level: 4⁄10
If you’re interested in machine learning’s application in health and wellness, you should try this project and build a breast cancer prediction model.
Using data from the Breast Cancer Wisconsin Diagnostic Dataset, you can follow this tutorial for building a simple classification-based model for predicting cancer, which walks you through every step, including importing data, data exploration, feature selection, and model selection.
7. Machine Learning Flower Classification
For those interested in: Image classification, Supervised learning, Logistic regression, Support Vector Machines
Difficulty Level: 3⁄10
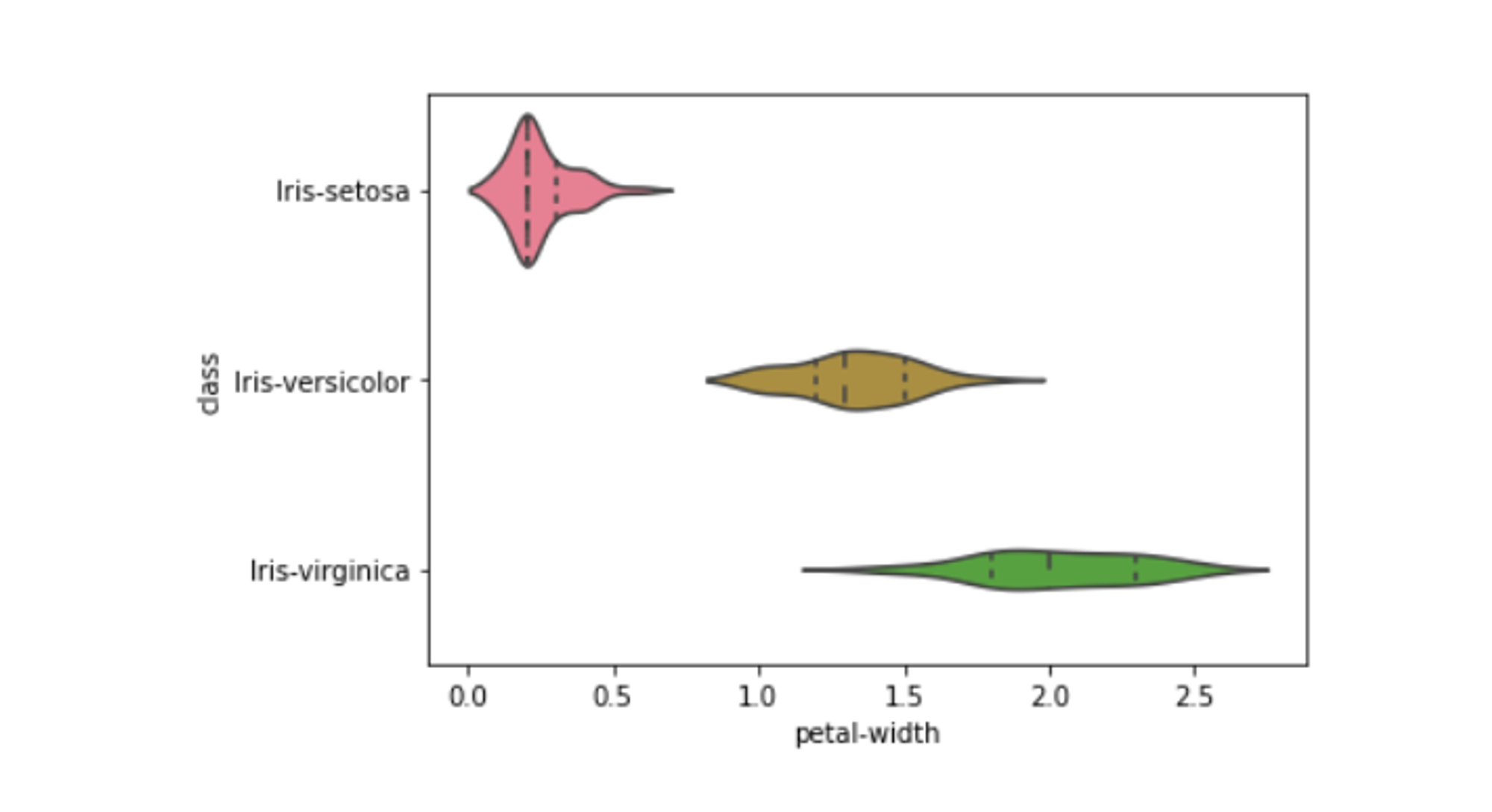
The Iris Flower dataset from UCI is one of the most well-known pattern recognition databases, and it’s used by many beginners to build image classification models to determine the species of an Iris based on the image.
One reason this is a great beginner machine learning project is because there are so many tutorials to get you started. For example, this step-by-step tutorial walks you through the entire project, from setting up the environment and loading the data to comparing different models like logistic regression and support vector machines.
8. Build a Logistic Regression Model from Scratch
For those interested in: Logistic regression, Model building, Mathematics behind machine learning
Difficulty Level: 5⁄10
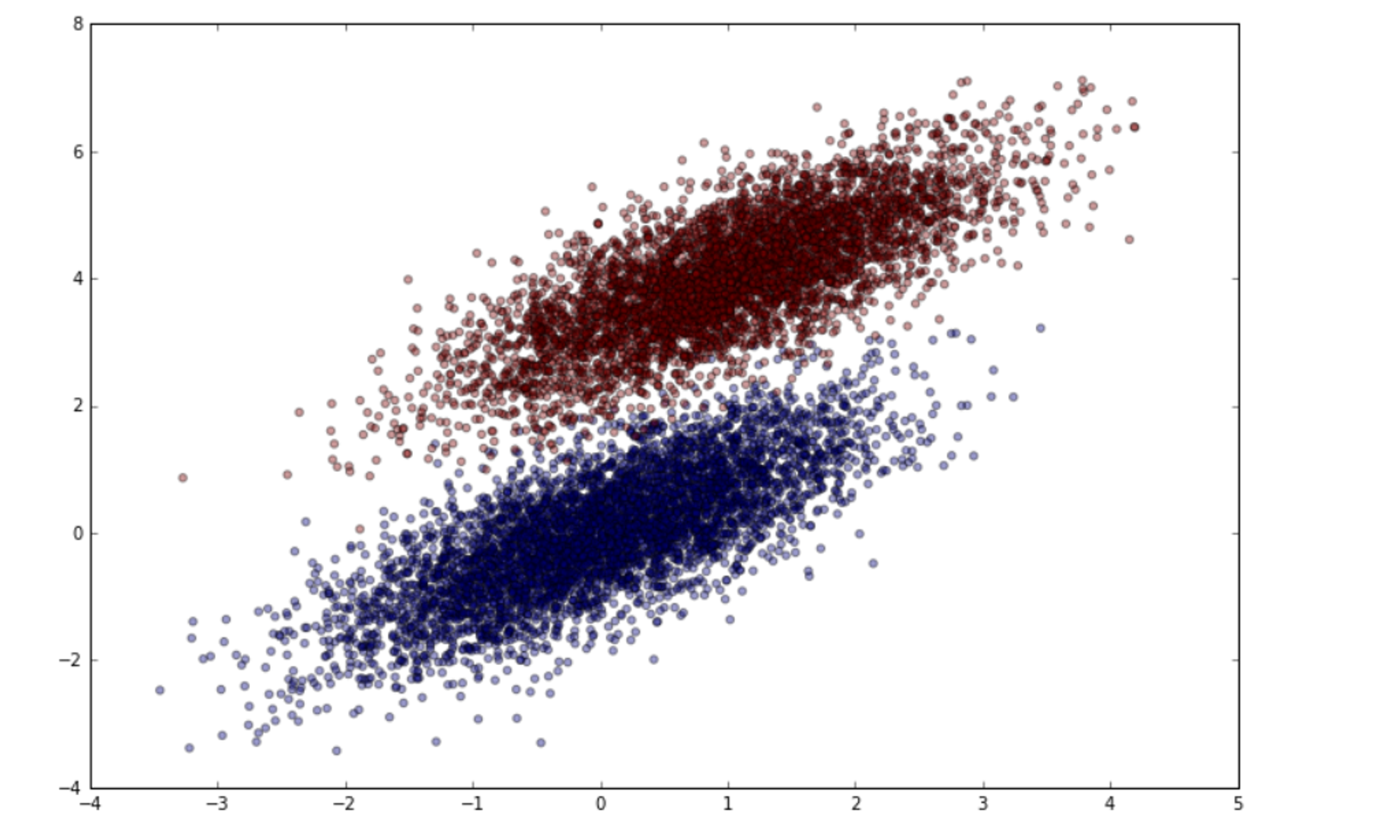
Not only does this project provide a great introduction to model building, but it’s also been asked in interviews for data science positions at Twitter and Walmart. (Try the logistic regression from scratch interview question.) Although you’d likely use Scikit-learn’s logistic regression function in production models, this project does give beginners an in-depth look at the math and provide ideas about developing custom extensions. To jump in, see this helpful tutorial for building a logistic regression model on simulated data.
9. Build a Simple Movie Recommendation Engine
For those interested in: Recommendation systems, Collaborative filtering, Content filtering
Difficulty Level: 4⁄10
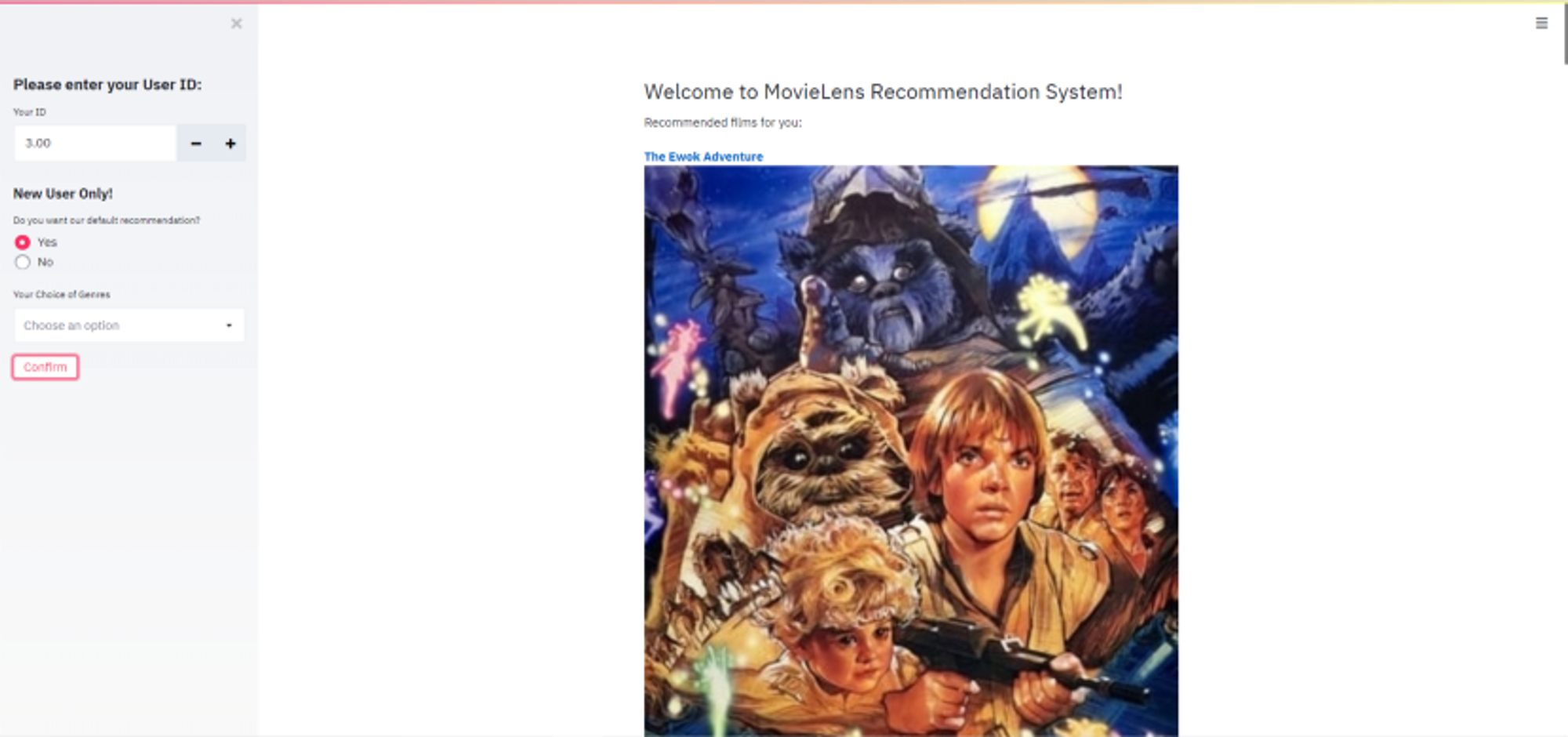
Recommendation engines provide hands-on experience with machine learning tools and techniques. To do this beginner project, use data from the Movielens Dataset, which features more than 25 million movie ratings from 15,000 users.
Follow this movie recommendation system tutorial to see how to build both content filtering and collaborative filtering for the engine. You can keep it simple and just use a few columns from the dataset to build the system, e.g., genre and release date.
10. Pitch Forecast
For those interested in: Sports analytics, Model Evaluation, Data visualization
Difficulty Level: 4⁄10
![]()
If you’re passionate about sports analytics and data modeling, a project that might intrigue you is predicting pitch types using the provided pitches dataset. This dataset includes detailed records from the 2011 baseball season, along with metadata that describes various attributes related to each pitch. The goal of this project is to build and evaluate a predictive model that can accurately determine the probability of different pitch types, such as fastballs and sliders, in real-time. You’ll need to focus on implementing various machine learning techniques, including feature engineering and data analysis, to visualize trends and patterns in the data. Additionally, developing an understanding of model evaluation and refinement will be essential to ensure that your solution is viable for production environments.
11. Driver Churn Case Study
For those interested in: Customer Behavior, Churn, Business Metrics
Difficulty Level: 3⁄10
![]()
If you’re interested in understanding customer behavior and improving retention, a project that might captivate you is analyzing driver churn in a rideshare service using the provided driver_ids.csv, ride_ids.csv, and ride_timestamps.csv. In this project, you will define churn as a driver who has not completed any rides within a specified period, assigning a value of 1 for churn and 0 for active drivers. The next step involves calculating the churn rate by dividing the number of churned drivers by the total number of drivers. To gain deeper insights, you’ll cluster drivers into segments based on their activity and churn status, which can help tailor retention strategies. Additionally, you’ll explore strategies to reduce churn, analyzing the potential positive impact on business metrics. Finally, by forming hypotheses around the opportunity for reducing churn, you can assess the broader effects on revenue and customer satisfaction.
Intermediate Machine Learning Projects
At the immediate level, machine learning projects dive into more advanced techniques like text mining, text summarization, image recognition, and natural language processing (NLP). Some intermediate machine-learning project ideas include:
12. Build a Text Summarizer
For those interested in: Text processing, Abstractive summarization, Natural Language Processing (NLP)
Difficulty Level: 6⁄10
Summarizing a text involves condensing its content while retaining its message and meaning. You can build an abstractive text summarizer that employs advanced natural language processing techniques to generate a new, shorter version that conveys the same information. You can build this project using Pandas, Numpy, and NTLK in addition to an unsupervised learning algorithm for word representation.
13. Practice Text Mining
For those interested in: Text mining, Unstructured data analysis, Natural Language Processing (NLP), Multi-level classification
Difficulty Level: 7⁄10
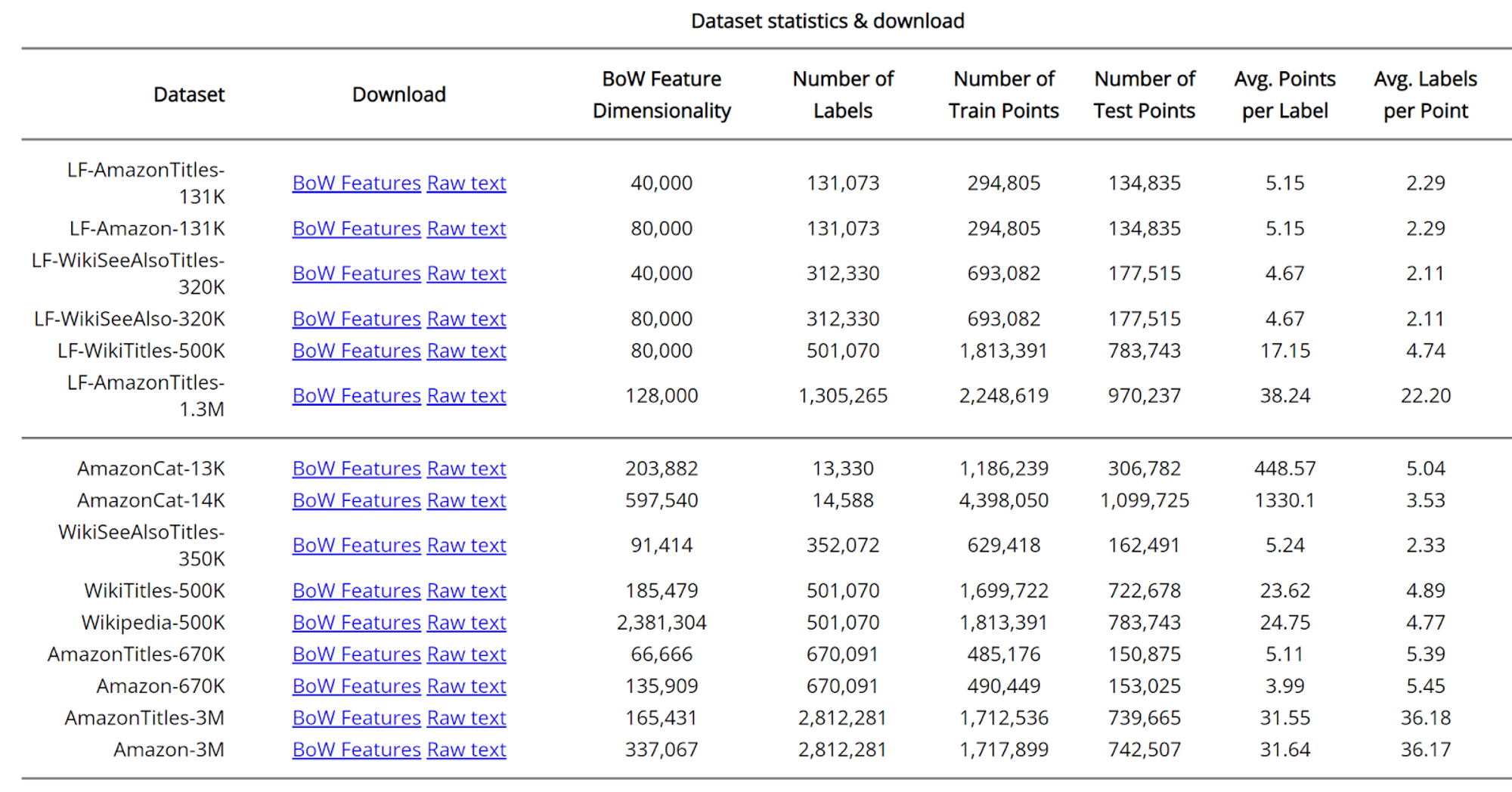
Text mining is the process of structuring and extracting valuable information from unstructured data, which is 80% of all raw text data. When we mine text, we effectively transform it into a structured format, facilitating the identification of key patterns and relationships within datasets.
If you want to dip your toes into some natural language processing, you can use these datasets to implement multi-level classification or to evaluate the performance of multi-label algorithms.
14. Build a Music Genre Classification Engine
For those interested in: Audio processing, Multiclass classification, Music analysis
Difficulty Level: 6⁄10
Music is a big part of everyone’s daily life. Often, people have different tastes in the music they listen to while they work, exercise, or just relax. One exciting project that you can build is a music genre classifier.
This project’s idea is to automatically use one or more machine learning algorithms, such as multiclass support vector machine, K-means clustering, or convolutional neural networks, to automatically classify different musical genres based on audio features. Often this classification is done through the filtering of audio files using their low-level frequency and time-domain features.
15. Intermediate Image Recognition
For those interested in: Handwritten character recognition, Neural Networks, Deep learning
Difficulty Level: 7⁄10

Back to another natural language processing project; an idea that has long intrigued researchers and companies is the automatic recognition of handwritten characters. This project revolves around modeling a neural network to detect and recognize handwritten characters. You can use the A-Z handwritten alphabet dataset along with Keras, TensorFlow, and Pandas to implement this project.
16. Fraud Detection via Enron Emails
For those interested in: Fraud analytics, Text mining, Security analytics
Difficulty Level: 6⁄10
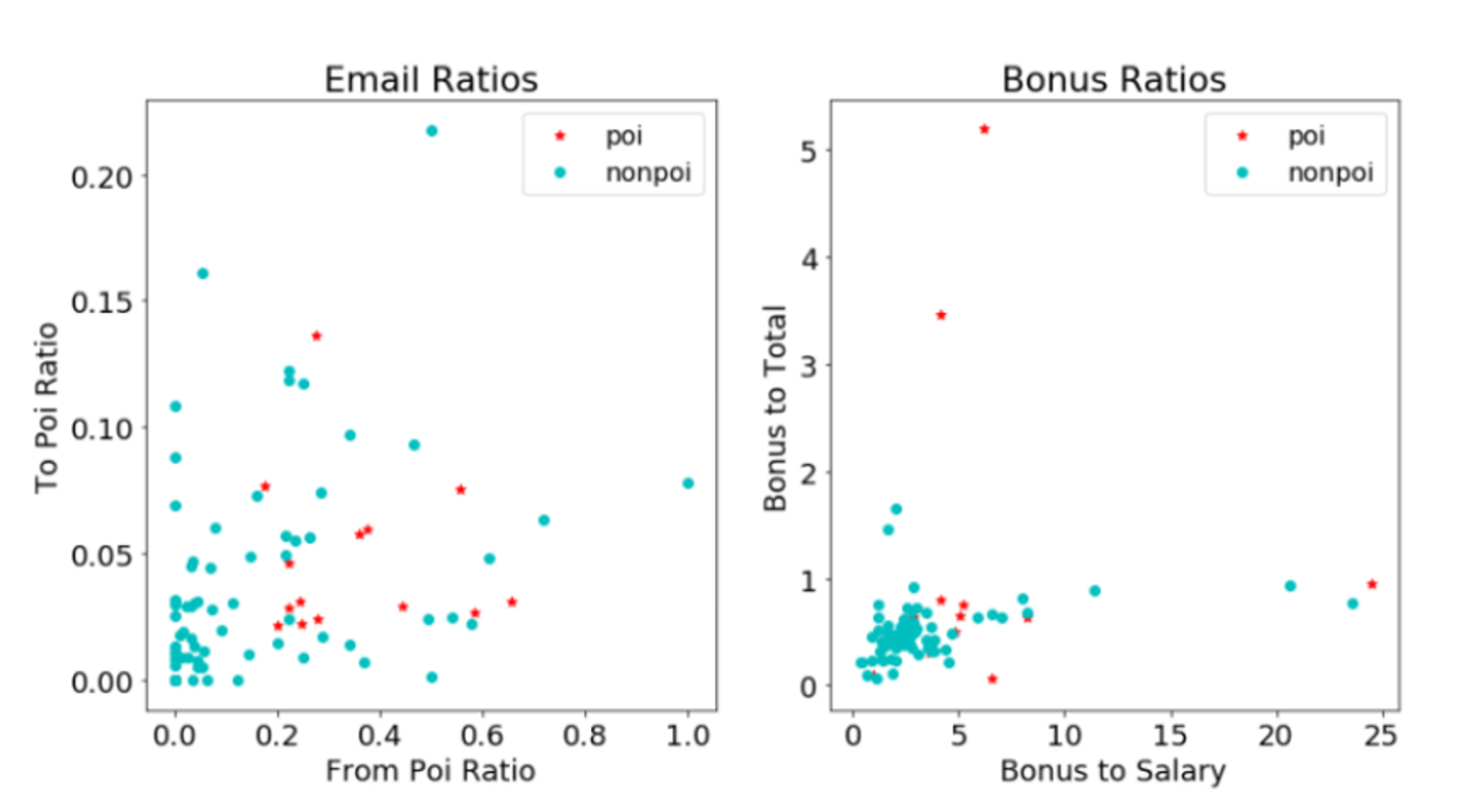
Fraud detection is an intermediate machine learning skill, and this project will help you prepare for fraud analytics and security roles. Follow this tutorial for using Scikit-learn to investigate fraud on the Enron emails dataset. The dataset features 500,000 messages sent by 150 former Enron employees, many of whom were high-level executives. By following this tutorial, you will build a model to predict persons of interest based on the available data.
17. Predicting Stock Prices
For those interested in: Time series analysis, Neural Networks, Financial analytics
Difficulty Level: 7⁄10
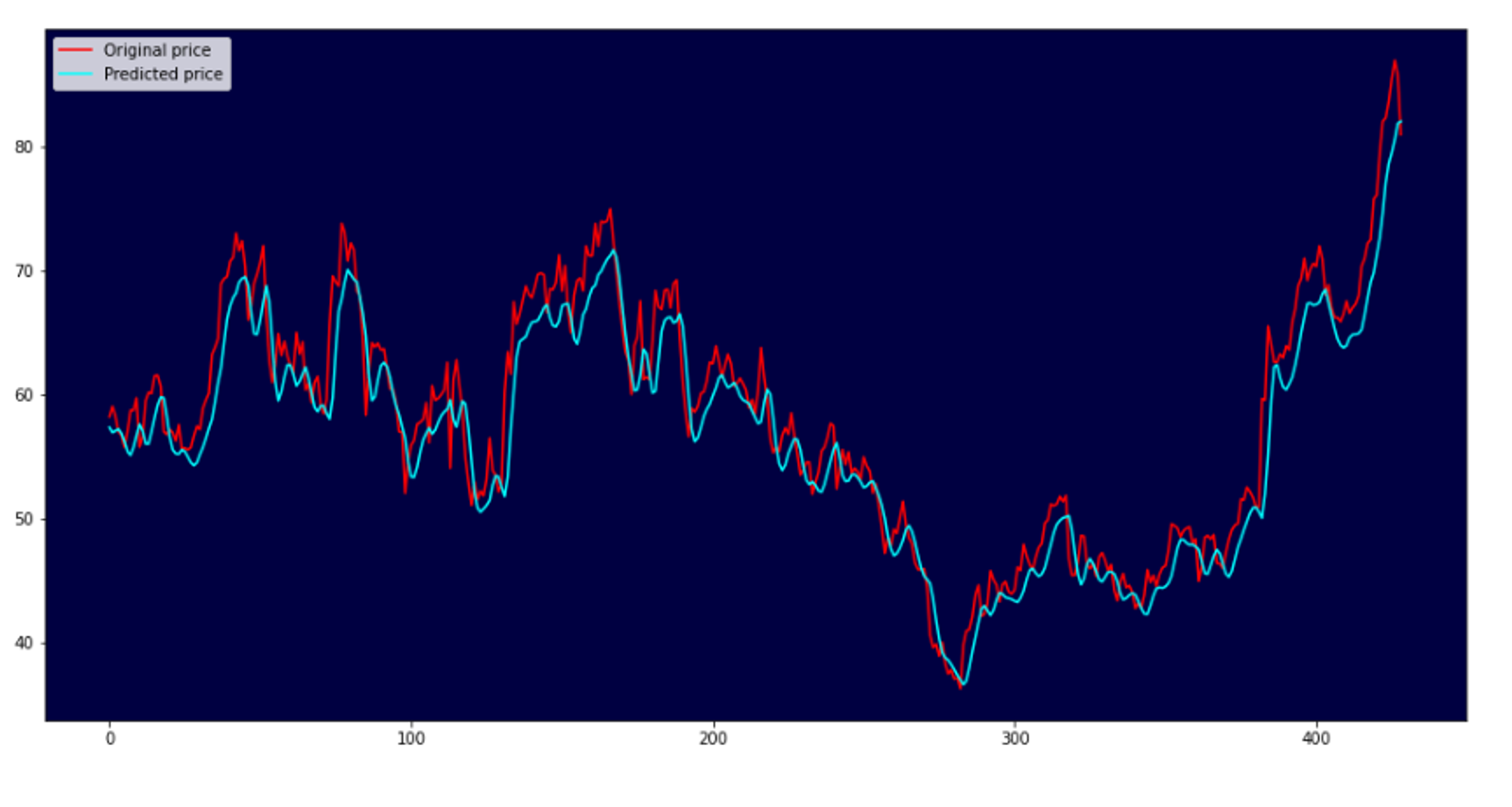
This project will allow you to build a neural network model to predict stock prices. This is an intermediate machine learning project because it requires knowledge of neural networks and solid Python skills. You can source and pull data from Yahoo! Finance, or you can use the historical NASDAQ dataset on Kaggle. This is good practice for a variety of Python packages, including Numpy, pandas, Matplotlib, and Keras.
18. Predicting Customer Churn
For those interested in: Churn prediction, Customer analytics, Regression analysis
Difficulty Level: 6⁄10*
Predicting churn is a valuable skill in a variety of industries, including e-commerce, media, and finance. Fortunately, there are a variety of churn prediction datasets you can use to hone this skill.
In this tutorial, you’ll learn how to use Python, pandas, Scikit-learn, Recency, Frequency and Monetary value (RFM) analysis, and SMOTE to predict churn using this retail dataset on Kaggle. The data features more than 60,000 transactions. After processing the data, you’ll use RFM analysis to qualify customers and predict their annual spending.
19. Market Basket Analysis
For those interested in: Retail analytics, Association rule mining, Apriori algorithm
Difficulty Level: 6⁄10

Market Basket Analysis (MBA) is a widely used machine learning technique in retail. The idea is that if a customer buys from one product group, they’re likely to buy related products. For example, if a customer bought baby wipes, there’s a high likelihood the customer would also buy baby formula.
One way to do MBA analysis is to use an Apriori algorithm to identify patterns for association rule mining. You can perform this task using this Kaggle grocery shopper dataset. And this tutorial will walk you through using Apriori algorithms.
20. Black Friday Sales Prediction
For those interested in: Regression analysis, Sales prediction, Retail analytics
Difficulty Level: 6⁄10
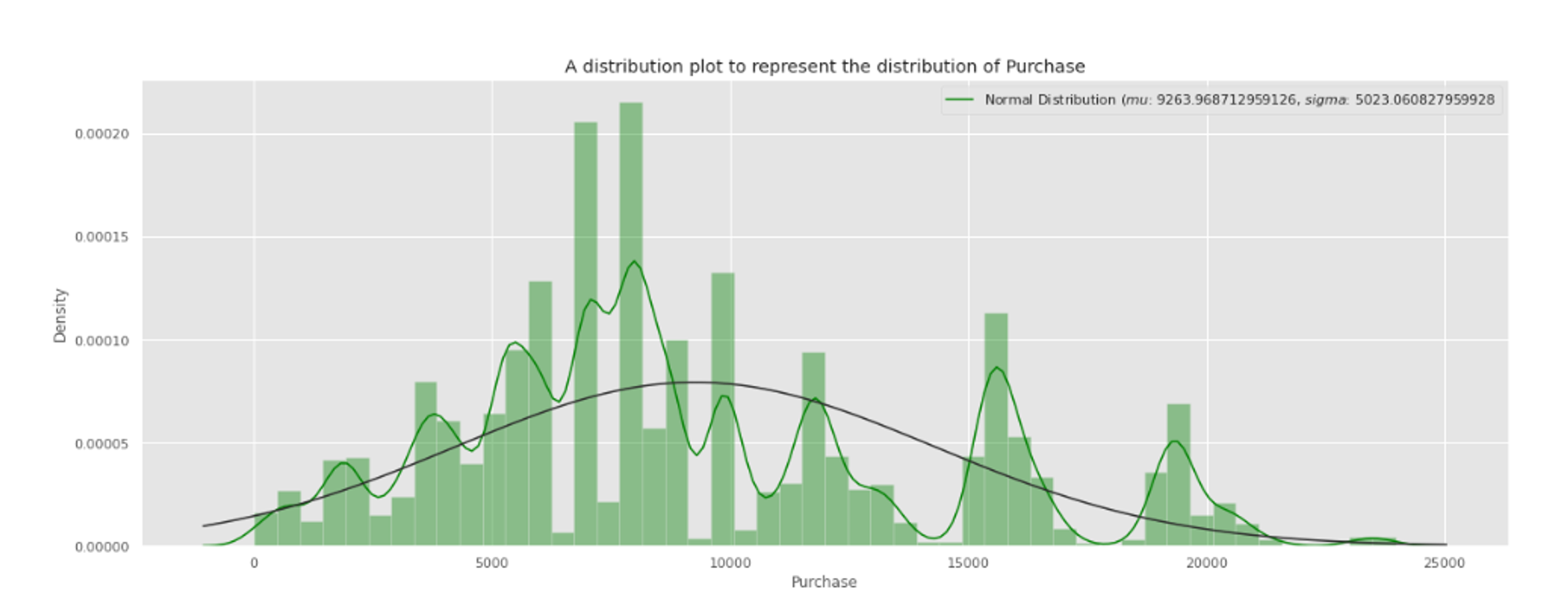
This project allows you to predict sale purchases using regression. You can follow along this Kaggle notebook for an in-depth guide on how to perform data cleaning, feature engineering, and ultimately making predictions.
Although this tutorial uses a proprietary dataset, there are numerous open datasets available including Black Friday on Kaggle.
21. Build a Music Recommendation Engine
For those interested in: Recommendation systems, Music analytics, Popularity based recommendation
Difficulty Level: 6⁄10
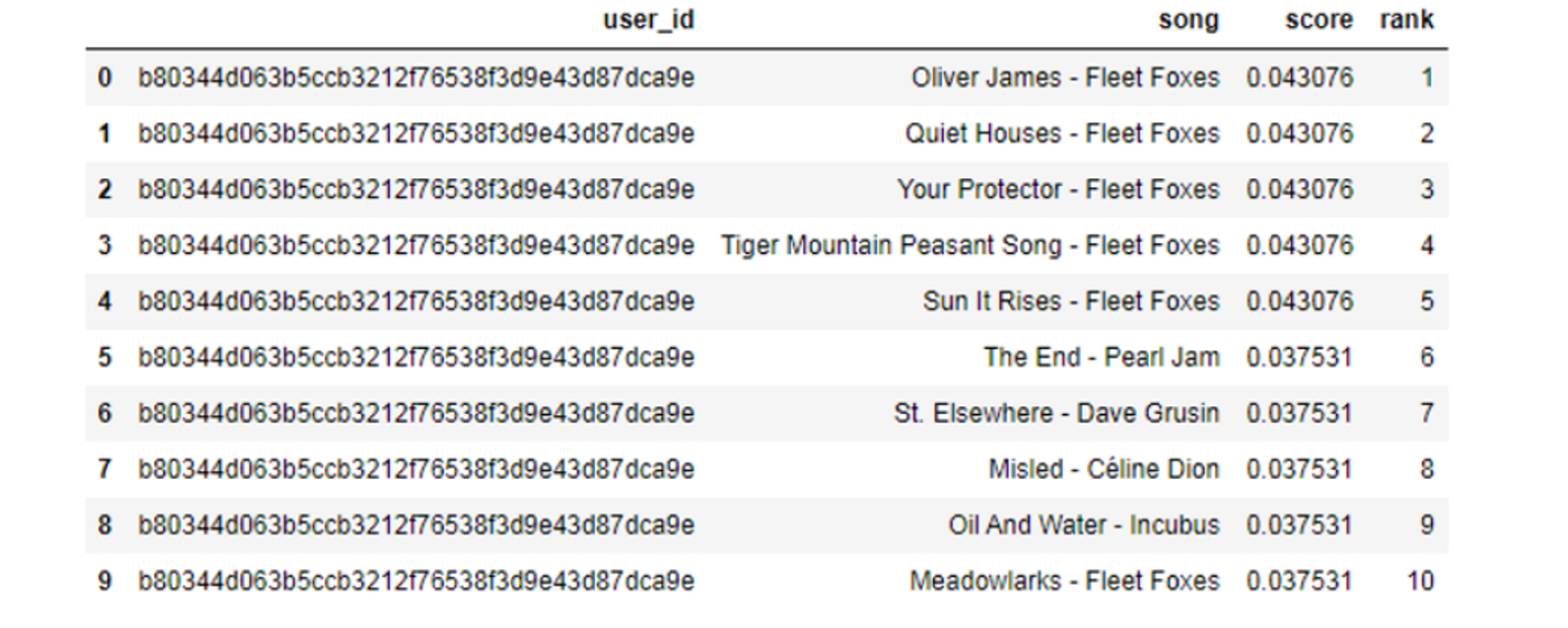
There are numerous music datasets available, but one of the most popular is the Million Songs Dataset. In this project, you’ll build a recommendation engine that provides users recommendations of popular songs, based on their listening history.
Follow this tutorial to see how to perform data loading, data processing, and building a popularity recommendation engine. Ultimately, the engine will take the songs the user has listened to, and a co-occurrence matrix is constructed based on the score and rank of the songs.
22. Heart Attack Analysis and Prediction
For those interested in: Health analytics, Predictive modeling, Cardiovascular disease prediction
Difficulty Level: 5⁄10

This dataset focuses on predicting the likelihood of heart disease based on patient attributes such as age, cholesterol levels, and exercise-induced angina. It’s an excellent dataset to practice binary classification techniques while learning about the medical implications of cardiovascular data.
You can start by building logistic regression or decision tree models, and gradually experiment with more advanced methods like random forests or gradient boosting. For a step-by-step guide, explore this tutorial. By the end, you’ll have a model that predicts whether a patient has heart disease with reasonable accuracy, based on their clinical attributes.
23. Water Quality Explanatory Data
For those interested in: Environmental analytics, Predictive modeling, Water quality assessment
Difficulty Level: 6⁄10

This dataset focuses on predicting the potability of water based on chemical and physical parameters such as pH level, hardness, and chloramine concentration. It’s an excellent resource for practicing binary classification techniques while exploring the environmental factors that influence water quality.
Begin by cleaning the data to handle missing values in features like ph and Sulfate, then experiment with models such as logistic regression or decision trees. Progress to more advanced techniques like random forests or gradient boosting for improved performance.
This project provides valuable experience in data cleaning, feature engineering, and classification modeling, offering insights into water safety and public health. By the end, you’ll have a model that predicts whether water is potable with reasonable accuracy.
Advanced Machine Learning Projects
Advanced machine learning projects dive into the most advanced machine learning skills, including sentiment analysis, deep learning, and computer vision. These are some advanced projects to try:
24. Myers-Briggs Personality Test Validation
For those interested in: Personality analytics, Test validation, Predictive modeling
Difficulty Level: 8⁄10
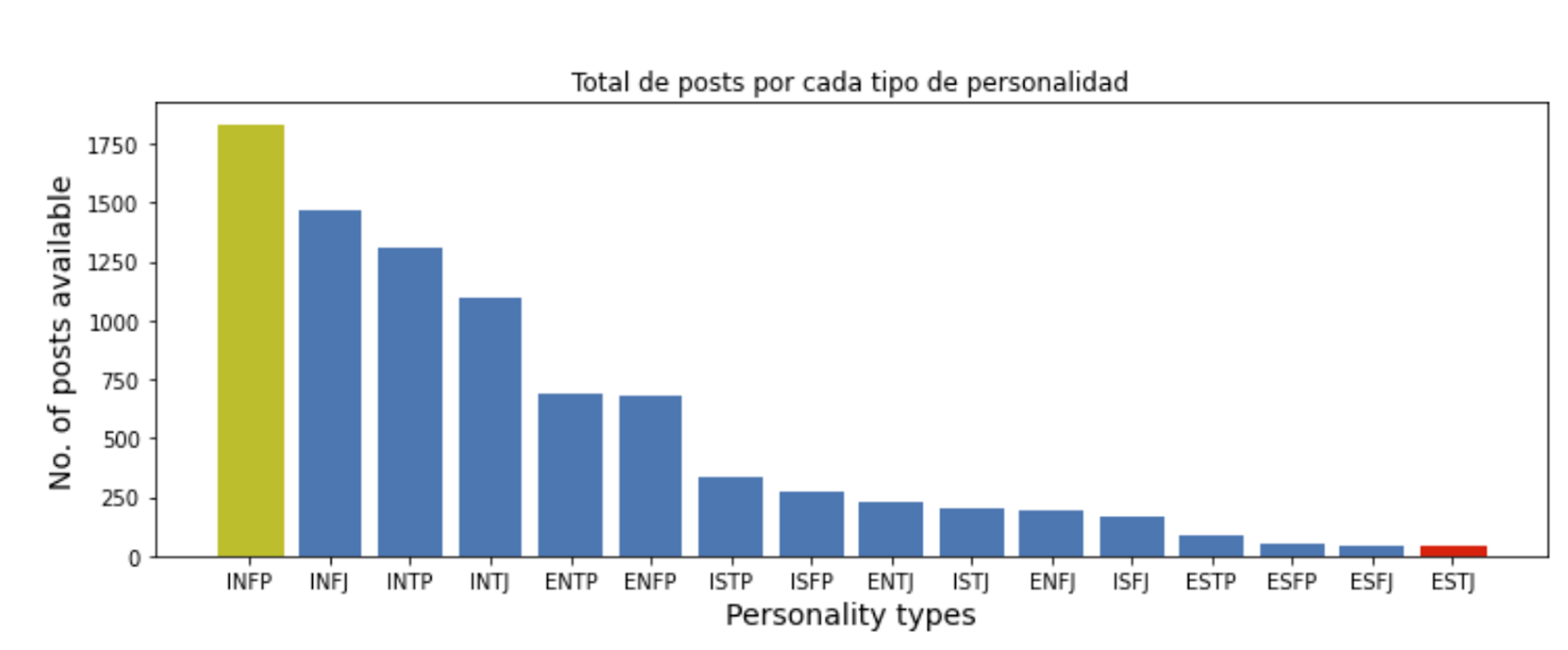
The Myers-Briggs Type Indicator is a famous personality test that divides people into 16 different personality types. You will need to answer various questions, which the system then evaluates to determine your personality type.
This dataset contains different information about the test that you can then use to evaluate the validity of the test design, analyze its results, and make predictions about the different personality types or categorizations of human behavior.
25. YouTube Comment Analysis
For those interested in: Sentiment analysis, Text mining, Social media analysis
Difficulty Level: 7⁄10
In most projects, the first step is often obtaining some data to analyze and apply algorithms. For example, you can use the YouTube-Comment-Scraper-Python library to fetch YouTube video comments and then use those to implement various sentiment analyses, hate-speech flaggers, and bot-detection projects.
Using this library, you will learn how to implement an automated scraper which will help you focus on exploratory data analysis and feature engineering. Follow this Kaggle notebook to learn how to perform YouTube sentiment analysis.
26. Mental Health Analysis with Twitter Data
For those interested in: Mental health analytics, Sentiment analysis, Social media analysis
Difficulty Level: 8⁄10
Mental health is an incredibly important topic of discussion. The ability to detect and recognize people’s mental health state can help save lives or vastly improve quality of life. If you want to build a project that feels important or if you have struggled with mental health issues before, you can use the Twitter dataset (or scrape recent Twitter data) to build a sentiment analysis that recognizes depression cues.
27. Music Generation with Deep Learning
For those interested in: Time Series Analysis, Cryptocurrency, Financial Analysis
Difficulty Level: 8⁄10
Last on today’s projects list is another one for the music lovers. This time we are not categorizing the music; we are going to generate it. Many songs today contain elements generated by computers. One approach to generating music is through the usage of deep learning or neural networks.
If you want to try generating your own music, you can try MuseNet, or WaveNet, or use a dataset like the Maestro to classify and generate your own music.
28. Bitcoin Price Predictions
For those interested in: Cryptocurrency, Time Series Analysis, Machine Learning
Difficulty Level: 8⁄10
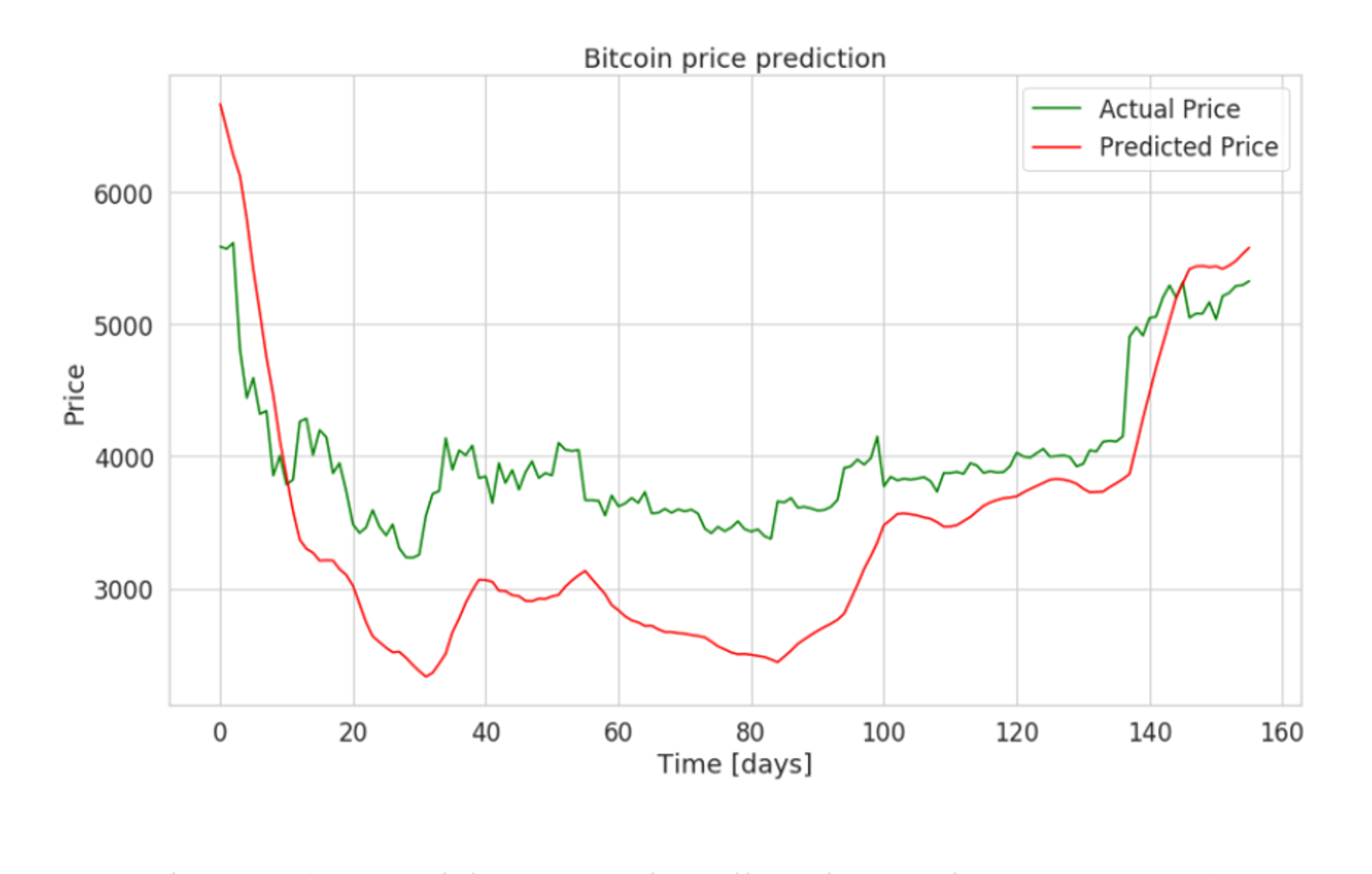
This price prediction machine learning project requires advanced skills and knowledge of bidirectional LSTM neural networks. Using the LSTM deep neural network, you’ll perform time series predictions in TensorFlow 2, with the goal of predicting Bitcoin prices. You can pull Bitcoin prices from Yahoo! Finance, or the Bitcoin Historical Prices dataset on Kaggle, which features minute-to-minute prices for 2017 to 2020.
29. Hotel Review Sentiment Analysis
For those interested in: Natural Language Processing (NLP), Web Scraping, Sentiment Analysis
Difficulty Level: 8⁄10
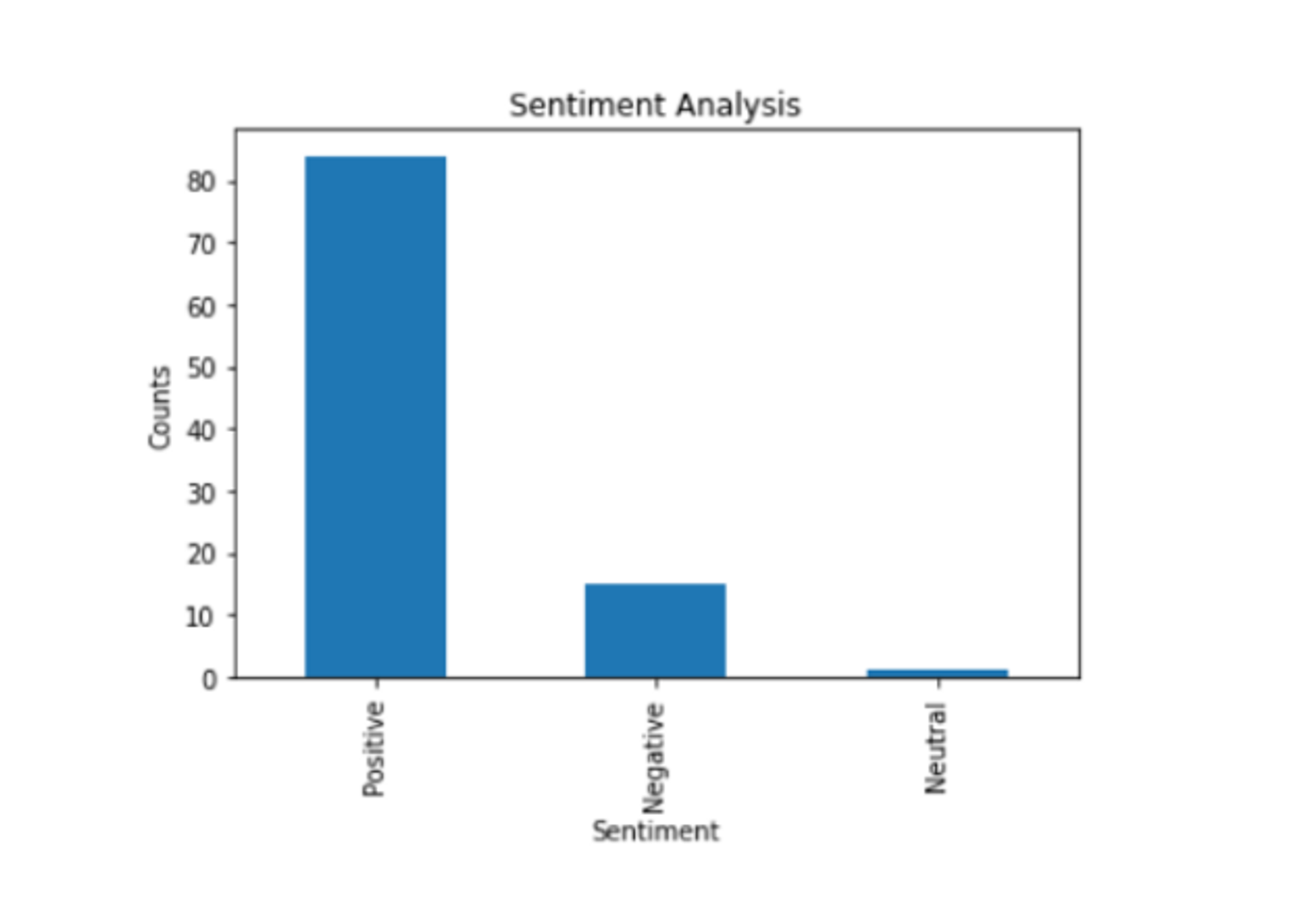
Check out this dataset on Kaggle, featuring reviews for 1,000 hotels. The data comes from Datafiniti’s Business Database. To build a sentiment analysis tool, you’ll first need to perform some advanced web scraping on TripAdvisor. Then, you can follow this tutorial for using the Natural Language Toolkit (NLTK) submodule VADER. This project allows you to practice a variety of skills, including web scraping, natural language processing, and sentiment analysis.
30. Forecasting Energy Consumption
For those interested in: Time Series Analysis, LSTM Modeling, Energy Consumption Analysis
Difficulty Level: 8⁄10
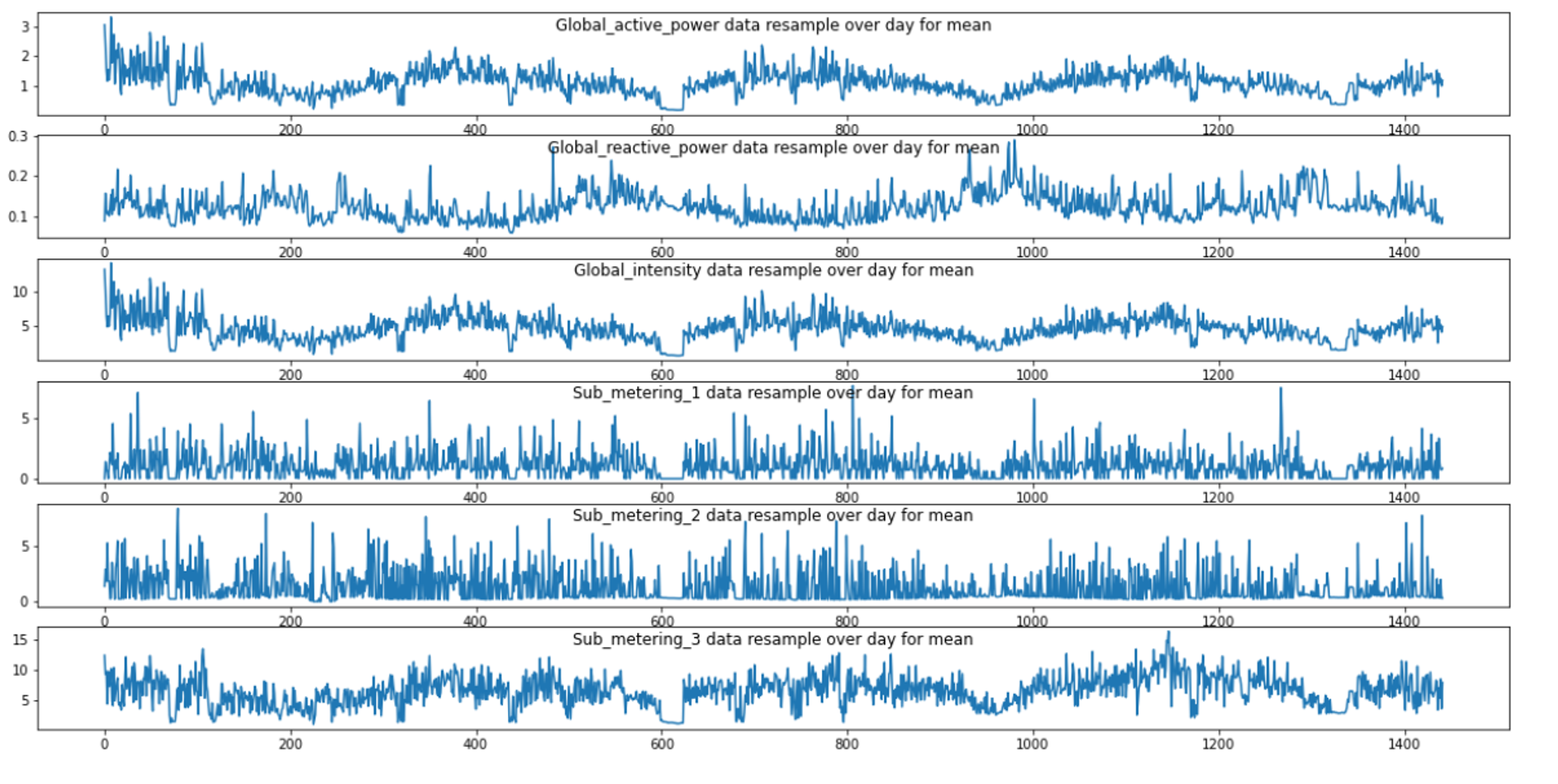
This is an operational analytics project, and it provides practice in several advanced machine learning skills like LSTM modeling for large time-series models. Follow this tutorial to predict the energy consumption for a single household. You can use this Household Energy Consumption dataset from UCI to perform your analysis. However, there are many energy consumption datasets available online, including this historical dataset on Kaggle or you could scrape data from the U.S. Energy Information Administration.
31. Facial Recognition with OpenCV
For those interested in: Computer Vision, OpenCV, Facial Recognition
*Difficulty Level: 7⁄10
There are numerous datasets you can use for this project, including the Yale Face Database or the AT&T Database of Faces.
In this project, you’ll use OpenCV, one of the most popular computer vision libraries, to build a facial recognition tool. You can practice using three main algorithms to do it, including Eigenfaces, Fisherfaces, and Local Binary Patterns Histograms. This OpenCV tutorial offers explanations of all the algorithms, as well as step-by-step instructions for using them.
Get Started on Machine Learning Projects
Building a solid machine learning projects portfolio can make or break your chances of getting the role you’re applying for. Luckily, there are numerous data science projects and free online datasets available to get started. Ultimately, you should be prepared to talk about your projects in interviews and answer the most common data science project interview questions. If you can present a project well, your portfolio will make you much more competitive for machine learning roles.
If you’re interested in reading more on similar topics, be sure to check out our blog!