
Top 18 Data Science Projects in Python with Source Code (Updated in 2025)


Getting Started with Data Science Projects in Python
Python is one of the most popular coding languages used in data science, with an infinite number of ways in which it can be used to perform analysis, scrape data, and build applications.
Data science projects in Python are one of the best ways to build your expertise and learn new Python skills. An end-to-end project allows for the opportunity to quickly gain hands-on experience, learn by trial and error, and improve at data science…
Another added bonus: Python projects will help you build your portfolio, and a strong portfolio is one of the best marketing tools for landing a data science job.
So, where should you begin? There’s an endless array of ways in which Python can be used in data science, from building chatbots to detecting fraud.
To inspire, we’ve highlighted 18 great data science projects with Python read online and source code, ranging from beginning data science projects to more advanced projects and datasets for your use.
End to End Python Data Science Projects: Datasets and Inspiration
Before we get started, look at our list of 30+ free online datasets for inspiration. A wide range of datasets in this list can be used in Python projects like those listed below.
Here, we’ve included everything you need to get started on your next data science project, including links to datasets, tutorials, and ideas on how to ultimately make them your own.
1. VaynerMedia: EDA on Unusual Data Take-Home

The media consulting firm VaynerMedia uses data to generate marketing insights for its clients. This take-home assignment, which has been given to data/marketing analysts at the company, asks you to do some data preparation in Python (in particular with Pandas) and then generate a report with basic insights.
Once you’ve generated the report, you’ll be asked to answer four straightforward questions:
- Unique campaigns for a particular month
- The total number of conversions for a product category
- The audience/asset combination that had the lowest cost conversion
- Total cost per video impression
This is a classic Python/Pandas take-home test. It asks you to merge two datasets and then generate simple insights from the updated dataset you create. If you’re looking at marketing analyst roles, an exploratory data analysis (EDA) take-home like this is good practice.
2. Build a Music Recommendation Engine
The Million Song Dataset is a massive database of contemporary music with audio features and metadata for a million songs. With Python, you can leverage this dataset to build a recommendation engine. Get started with this helpful tutorial from Ajinkya Khobragade, which shows you how to build a collaborative-filtering recommendation engine.
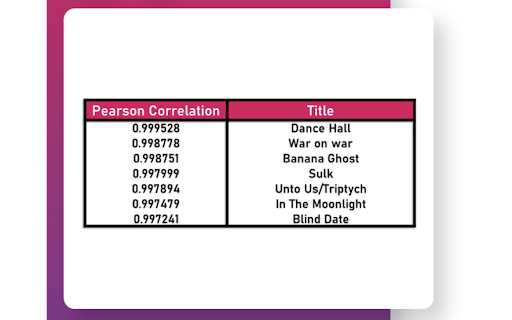
How you can do it: Using the Million Song Database, there are a lot of different recommendation system projects you can pursue. One possible option involves using the LightFM Python implementation to quickly build a recommendation engine.
3. Enigma: Data Take-Home Exercises

This take-home challenge - which requires 1-2.5 hours to complete - is a Python script writing task. You’re asked to write a script to transform input CSV data to desired output CSV data. A take-home like this is good practice for the type of Python takehomes that are asked of data analysts, data scientists, and data engineers.
As you work through this practice challenge, focus specifically on the grading criteria, which include:
- How well do you solve the problems
- The logic and approach you take to solving them
- Your ability to produce, document, and comment on code
Ultimately, the ability to write clear and clean scripts for data preparation.
4. Detecting Spam with Python
This is a great beginner Python data science project, with tons of email datasets out there for beginner spam filtering projects. One of the best is the Enron-Spam Corpus, which features 35,000+ spam and ham messages. To get started, this tutorial goes in-depth on how to build a spam filter using Python and Scikit-learn.
This Python project offers a good introduction to using classifiers (in this case, multinomial Naive-Bayes and support vector machines).
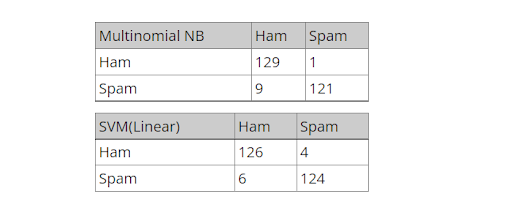
How you can do it: Check out the Enron-Spam dataset or this Kaggle dataset, featuring three email datasets in one. Another option is to build a classifier to categorize clickbait headlines.
5. Hopper: Python Function Writing Take-Home

Hopper’s data science take-home consists of four short Python coding questions. The company estimates the takehome requires about 1 hour to complete.
The first question is specifically related to writing Python functions. You’re given a table of airports and locations and asked to write a function that takes an airport code as input and returns the airports listed from nearest to furthest from the input airport.
Additionally, Python-related questions are asked, but you aren’t required to write code. For example, the second question is related to an experiment, while the third question tests your ability to document code and describe your thought process.
6. Using Python for Home Price Predictions
There’s a wealth of housing data online, and you can do many cool things with Python using this data. Here’s a helpful tutorial from Aman Kharwal, the Clever Programmer, that utilizes a California Census dataset to predict home prices.
Here’s a cool visualization from Aman of home prices in California by location:
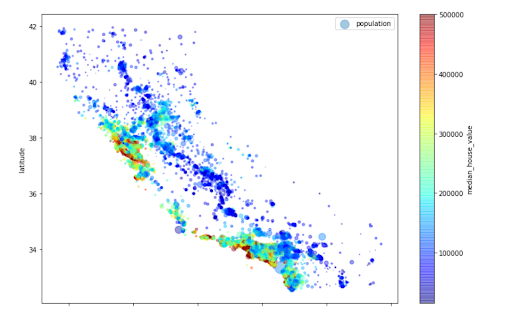
How you can do it: This is a great beginner Python data science project. You can use the California dataset, or switch it up to predict prices for things like used cars and airfare. One option would be to use that dataset and predict prices for Airbnb listings (by city or country).
7. Segment: Transparent Redis Proxy Service Take-Home

Segment, the customer data platform, has given this coding assignment as a take-home for data engineers and data scientists.
The task asks you to build a transparent Redis proxy service, which is implemented as an HTTP web service that allows adding additional features on top of Redis.
This challenge specifically tests systems programming, with grading criteria on concurrency, networking, integration, and some algorithmic optimizations.
8. NBA Analytics with Python
We featured this project in our list of data analytics projects, coming personally from Interview Query’s co-founder, Jay. This project analyzes data scraped from Basketball-Reference to determine if 2-for-1 play in basketball actually provides an advantage. If you’re interested in sports or NBA data science projects, definitely be sure to take a second look at this project.
There are a lot of different ways to visualize sports data. Here’s an example from this project:
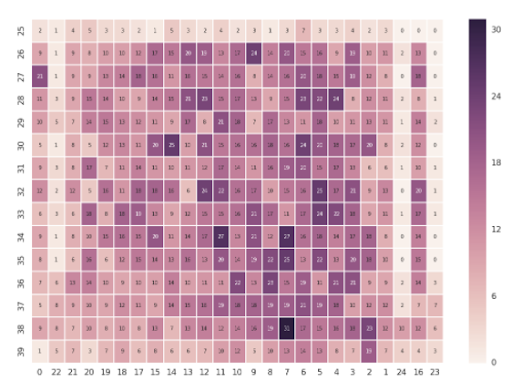
How you can do it: Take a look at the source code on GitHub. There’s really an endless variety of sports stats you can scrape and analyze.
9. Movie Review Sentiment Analysis
If you’re interested in NLP, there are numerous sentiment analysis and text analytics projects to try. A solid beginner-to-intermediate sentiment analysis project could involve classifying or predicting sentiment based on existing movie reviews.
One helpful example to follow uses this dataset of 50,000+ IMDB movie reviews (you might also find some helpful hints in this Kaggle notebook). Here’s a cool word cloud visualization from the dataset from Lakshmipathi:
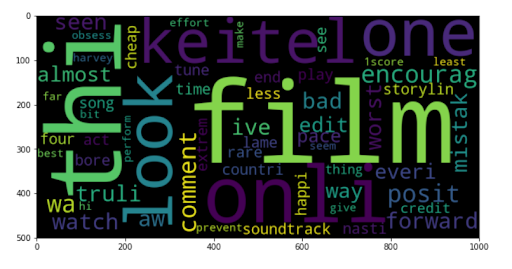
How you can do it: One option to customize this project would be to scrape your own data, using Python, from a variety of platforms. Here’s a tutorial for scraping reviews on Amazon, which you could also apply to a site like Pitchfork for music reviews.
10. Face Swapping with Python and OpenCV
If you’ve ever wondered how Instagram makes face-swapping so easy, check out this computer vision project. Over on Pysource, Sergio Canu created a really helpful tutorial on how to build a face-swapping app with Python and OpenCV.
This is a solid intermediate-to-advanced CV project and a great practice for using the OpenCV library. The tutorial walks you through all the steps (and includes source code), like location mapping:

How you can do it: The CelebFaces dataset is great for a project like this. If you’re interested in pursuing similar projects, check out our list of free data sources for the best computer vision datasets.
11. Detecting Fake News with Python
The rise of fake news has skyrocketed online over the past decade – but machine learning offers a solution for combatting it. In fact, Twitter and Facebook are leveraging machine learning today to fight fake news on the crisis in Ukraine.
Interested in how you can use Python to detect fake news? Check out this tutorial on Medium from Manthan Bhikadiya, which will walk you through the entire process:
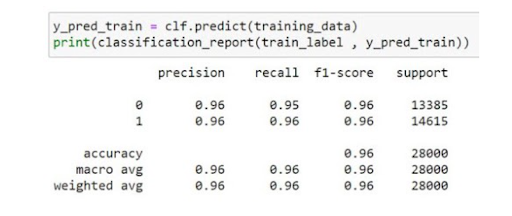
How you can do it: Check out this source, which features a fake news and a true news dataset on Kaggle. Because news changes so quickly, you might also consider web scraping more recent news articles with Python.
12. Building a Chatbot from Scratch
Python is a useful tool for creating chatbots. If you want to try it yourself, check out this DataFlair chatbot tutorial, which walks through how to use Natural Language Toolkit, Keras, and Python. This is a great tutorial to help you work on all three of those tools, and it includes all the source code.
Specifically, you’ll build a retrieval-based chatbot that can answer simple queries:
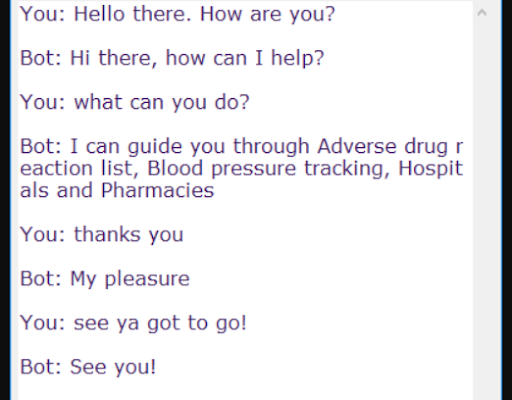
How you can do it: If you want to create your own version, here are two beginner chatbot datasets, one focusing on mental health FAQs and the other featuring a simple chat log.
13. Predicting Forest Fire Damage
Interested in what conditions impact the severity of a forest fire? Take a look at this dataset on Kaggle, which you can use to predict the burned area of a fire. You might start with some exploratory analysis like this from Kaggle user Alex Beg:
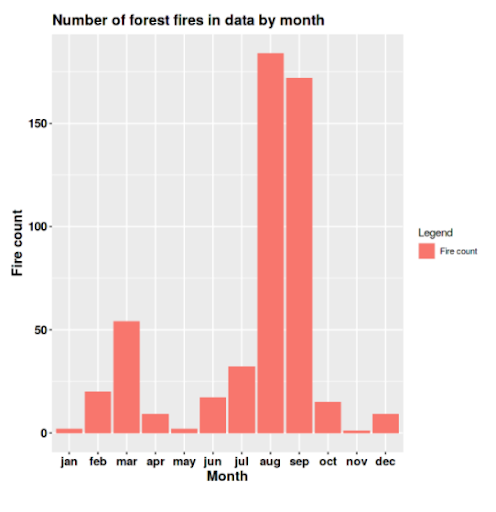
Then, you move into regression or classification analysis to make predictions. See some examples of regression data science projects.
How you can do it: Another option would be to look at data for natural disasters like floods or tornados to make predictions.
14. Finding Cheap Housing on Craigslist
Craigslist is one of the best places for finding data - from used car prices to apartments for rent. This project also comes from Jay, and models San Francisco housing data scraped from Craigslist.
This project is especially helpful for working with Scrapy, the Python framework. Take a look at the source code here for an in-depth look at how to customize the Scrapy implementation for your project.
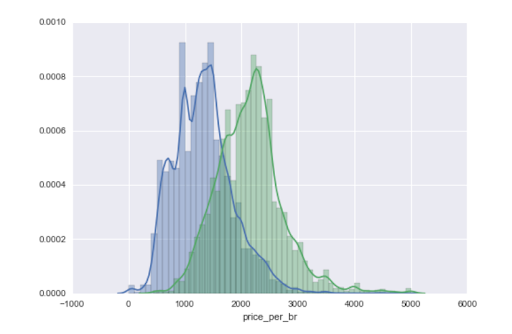
How you can do it: Take a look at the source code. You can scrape your own data from Craigslist to model housing costs from your own city.
15. Time Series Analysis and Forecasting
Time series analysis is crucial in understanding how data points, collected sequentially over time, evolve and can be forecasted. This project explores a dataset containing sales figures from various stores over a specific period, analyzing its trends, seasonality, and stationarity to build reliable forecasting models.
The analysis begins by loading and exploring the dataset, which includes variables like date, country, store, product, and num_sold. Key statistical tests such as the ADF and KPSS are used to determine if the data is stationary, which is essential for accurate forecasting.
How you can do it: To get started, you can use Python libraries like pandas for data manipulation, stats models for statistical tests, and prophet or ARIMA models for forecasting. Scrape or gather time series data relevant to your area of interest, such as sales data, weather data, or financial data, and follow a similar approach to analyze and predict future trends.

How you can do it: Check out the source code here for a detailed implementation of the time series analysis and forecasting process.
16. Predicting Survival on the Titanic
The Titanic dataset is one of the most famous datasets in the world, providing a wealth of information about the passengers aboard the ill-fated ship. This project uses data from the Titanic disaster to predict survival rates among passengers based on various features like gender, age, and class.
This project is an excellent opportunity for those looking to practice their skills in data cleaning, feature engineering, and predictive modeling. The dataset is relatively small, making it perfect for beginners who want to get a grasp on classification problems.

How you can do it: Start by downloading the Titanic dataset from Kaggle. You can begin by exploring the data, cleaning it, and then applying machine learning algorithms like logistic regression or decision trees to predict which passengers are likely to survive.
17. Gender and Age Detection
The Gender and Age dataset is a well-known resource for practicing classification tasks, designed to predict a person’s gender and age group based on a range of features. It includes information like facial attributes, metadata, or behavioral characteristics, depending on the specific dataset version you’re working with.
This dataset offers a fantastic opportunity to develop skills in feature selection, data preprocessing, and building models for multiclass classification. Its real-world relevance makes it an engaging choice for those exploring practical applications of machine learning.

How you can do it: Download the required files (e.g., opencv_face_detector.pbtxt, age_net.caffemodel, etc.) and organize them in a directory named gad. Use Python’s argparse to create an argument parser for the image path, then initialize the models and define classification categories for age and gender. Load the networks with OpenCV’s readNet() method to capture a video stream or load an image. Detect faces using a confidence threshold, preprocess detected face regions into 4D blobs, and feed them into the models to predict gender and age. Finally, the image with the predictions is annotated and displayed using OpenCV’s imshow().
18. Movie Recommendation System
The IMDB Movie Ratings dataset is a popular resource for machine learning enthusiasts exploring collaborative filtering, recommendation systems, and data analysis. It includes two files: a ratings.csv file with user-movie ratings and timestamps and a movies.csv file that maps movie IDs to titles and genres. This pairing enables detailed exploration of user preferences and content-based recommendations.
This dataset is ideal for tasks like building movie recommender systems, performing genre-based clustering, or analyzing user behavior trends. Its real-world structure provides a great foundation for experimenting with techniques in data preprocessing, model evaluation, and hybrid recommendation strategies.
How you can do it: Start by downloading the dataset and organizing the files for easy access. Use Python’s Pandas library to preprocess the data—handle missing values, parse genres into one-hot encodings, and create user-item matrices. Train collaborative filtering models using libraries like Surprise or implement content-based filtering by vectorizing movie genres with techniques such as TF-IDF. Evaluate the models with metrics like RMSE or precision at k. Finally, deploy a visualization dashboard with Streamlit to display personalized recommendations.
Check out Interview Query's Python Course
This course is designed to help you learn everything you need to know about working with data, from basic concepts to more advanced techniques.
More Data Science Learning Resources
These projects are all helpful for practicing skills like Python, data analytics, and Python libraries like OpenCV and Scikit-learn. You can also continue your learning with these resources from Interview Query: