
PayPal Data Engineer Interview Guide: Process, Tips & Sample Questions (2026)


Introduction
Data engineering has become one of the fastest growing tech roles, with the U.S. Bureau of Labor Statistics projecting over 35 percent growth in data roles through 2032, far outpacing most engineering fields. In fintech, this demand is even sharper as companies like PayPal scale real time data systems that process billions of global transactions. With this growth, competition has intensified. Industry estimates show that only 10–20% of data engineering applicants make it past PayPal’s initial screening, given the company’s emphasis on large scale pipelines, distributed systems, and secure financial data processing.
Candidates typically struggle not because they lack technical ability, but because PayPal’s interview blends ETL design, big data execution, cloud architecture, and reliability engineering under strict operational constraints. This guide is built to eliminate that uncertainty. You’ll find a clear breakdown of the PayPal data engineer interview, the most common PayPal specific questions, and focused preparation strategies so you can walk into each stage structured, confident, and ready to stand out.
PayPal Data Engineer Interview Process
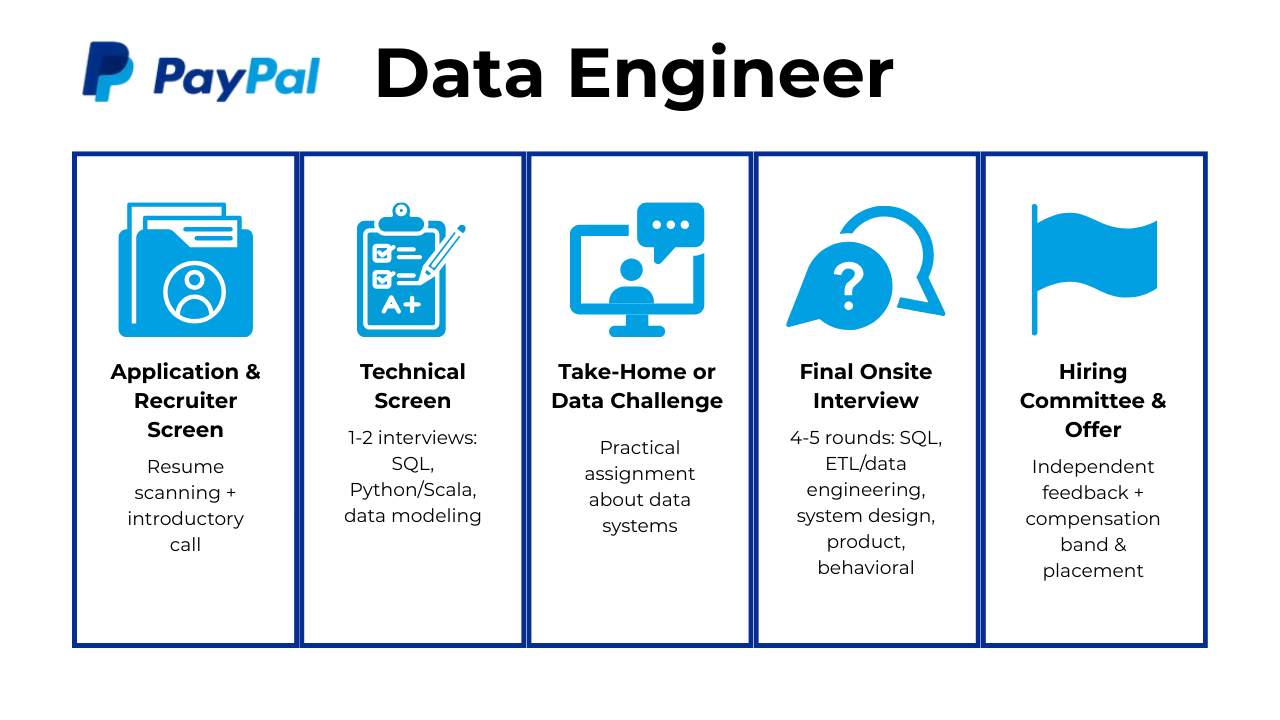
The PayPal data engineer interview process evaluates your ability to design scalable data systems, build reliable pipelines, optimize distributed workloads, and collaborate with cross functional teams across time zones. The stages focus on SQL, big data technologies, cloud architecture, ETL design, data modeling, and behavioral alignment with PayPal’s values of inclusion, innovation, collaboration and wellness. Most candidates complete the full loop within three to six weeks depending on team availability, role level and technical scope. Below is a breakdown of each stage and what PayPal interviewers typically assess throughout the process.
Application and Resume Screen
During the initial review, PayPal recruiters look for experience working with large datasets, production grade ETL systems and cloud technologies such as AWS or GCP. Strong candidates highlight tools like Spark, Hadoop, Hive, DataFlow, BigQuery, Airflow and Kubernetes along with examples of improving pipeline performance, reducing system latency or enhancing data quality. Resumes that demonstrate collaboration with engineers, analysts and architects also stand out since PayPal’s workflows often span multiple time zones and product areas.
Tip: Quantify your engineering impact using metrics such as reduced processing time, improved throughput, cost savings or data reliability gains. Clear measurements improve your chances of passing the screening stage.
Initial Recruiter Conversation
The recruiter call provides an introduction to your background, motivations and familiarity with foundational data engineering concepts. Recruiters verify your experience with SQL, pipeline development, distributed processing and cloud technologies while evaluating how well your skills align with open roles. They may also ask about team preferences, work location, timeline and compensation expectations. This conversation is non technical but helps determine whether you should move forward to technical evaluation.
Tip: Prepare a concise overview describing how you have built or improved data systems and why you want to work on high volume payments data at PayPal.
Technical Screen
The technical screen includes one or two interviews that focus on SQL, Python or Scala, data modeling and distributed compute fundamentals. You may be asked to write joins, window queries or aggregations, explain how you would design a reliable batch or streaming pipeline or walk through a debugging scenario from a past project. Some interviewers present small scale case problems involving inconsistent payment data, schema evolution or optimizing a Spark job. This round emphasizes both your technical reasoning and your clarity of communication.
Tip: Practice writing SQL and code in a plain text environment since PayPal screens often use shared documents without autocomplete.
Take Home Assignment or Data Challenge
Some PayPal teams include a practical assignment to evaluate how you build and reason about data systems independently. You may receive raw logs and be asked to design an ETL workflow, create validated tables, check data quality or outline a lakehouse architecture. Your solution is assessed on correctness, structure, assumptions, documentation and ability to handle edge cases. A clear approach matters as much as the final result.
Tip: Treat the assignment like a real production deliverable by documenting your logic, decisions and possible next steps for future iteration.
Final Onsite Interview
The final onsite loop includes four to five interviews, each focused on a different dimension of the data engineering role. Expect one or two SQL or coding sessions, a system design round, a data architecture discussion, and a behavioral interview centered on teamwork, communication and ownership. Interviewers may explore how you would design a payments data pipeline, handle millions of daily events reliably or optimize data storage strategies for lakehouse systems. They evaluate your ability to structure problems, justify trade offs and communicate decisions clearly.
SQL and data transformation round: You will work with large, sometimes messy datasets and write queries involving joins, window functions and aggregations. Tasks may include validating payment records, identifying anomalies or transforming raw logs into analytics ready tables. Interviewers assess correctness, query clarity and your approach to handling edge cases.
Tip: Restate the problem before writing any query and explain your planned steps to show strong analytical habits.
ETL and big data engineering round: This session focuses on designing reliable pipelines using technologies such as Spark, DataFlow, Hadoop and Airflow. You may discuss handling late arriving events, managing schema changes or optimizing distributed jobs. PayPal values engineers who understand both the conceptual and practical sides of building scalable data systems.
Tip: Reference real experiences where you improved pipeline efficiency, reliability or maintainability.
System design and data architecture round: Interviewers may ask you to design a platform that ingests, stores and serves high volume payment data. Expect to cover partitioning strategies, storage formats, metadata management, data lineage, access patterns and scaling considerations. The goal is to evaluate your ability to build stable, secure and extensible architectures.
Tip: Start by clarifying data sources, volume expectations and business requirements since these shape every architectural choice.
Product and cross functional collaboration round: This round examines how you work with partner teams such as analytics, engineering, product and architecture. You might discuss how you prioritize requests, debug multi team issues or communicate technical decisions. PayPal values engineers who collaborate well and keep downstream users in mind.
Tip: Tie your examples to measurable impact, such as improved reliability, lower operational effort or better data accessibility.
Behavioral and team fit round: Interviewers explore how you handle challenges, give and receive feedback, manage ambiguity and take ownership of long running projects. They look for traits aligned with PayPal’s values, including empathy, clarity and collaborative problem solving.
Tip: Use the STAR method to keep your stories structured, emphasizing what you accomplished and what you learned.
Hiring Committee and Offer
After the onsite interviews, each interviewer submits feedback independently. A hiring committee reviews your performance across all rounds, including technical ability, communication, collaboration, and long term potential. If approved, PayPal determines your level, compensation band, and potential team placement. Recruiters then walk you through the offer and next steps.
Tip: Share your team preferences early since PayPal often evaluates potential matches during the final stages.
Want to build up your PayPal interview skills? Practice real hands-on problems on the Interview Query Dashboard and start getting interview-ready today.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Paypal?
PayPal Data Engineer Interview Questions & Answers
The PayPal data engineer interview includes a wide range of SQL, pipeline design, big data engineering, cloud architecture, and system design questions. These problems evaluate how well you understand real-world data challenges, such as processing high-volume payment events, building reliable batch and streaming pipelines, designing scalable lakehouse structures and maintaining data quality in a financial environment where accuracy and latency matter. Interviewers want to see how you break down complex situations, reason through trade offs and communicate your approach clearly.
SQL And Data Modeling Interview Questions
In this stage of the interview, PayPal focuses on your ability to work with large transactional datasets and transform them into usable structures. SQL questions often involve window functions, schema interpretation, deduplication logic, anomaly detection or aggregations across millions of events. You may also be asked to reason through data inconsistencies that naturally occur in payment workflows such as late arriving events or mismatched timestamps.
Write a query to identify payment attempts that were retried by a user within five minutes of a failure.
PayPal asks this because retry patterns help detect checkout friction, integration issues and potential system instability. The solution partitions by user, orders by timestamp, uses
LEAD()to compare a failed attempt with the next attempt and filters where the time difference is under five minutes. This mirrors how PayPal surfaces rapid retry spikes for incident detection.Tip: Mention how you prevent false positives when users trigger multiple rapid retries during outages.
Find the total volume of successful payments for each merchant after removing duplicate events generated by system retries.
PayPal evaluates deduplication skills because events may be replayed or retried across its distributed systems. You solve this by identifying unique transactions using an ID or by selecting the latest status per transaction with
ROW_NUMBER(), then summing successful events by merchant. This ensures accurate merchant reporting, which PayPal relies on for settlement and financial reconciliation.Tip: Explain why selecting the most recent authoritative status prevents double-counting.
Given a payments table, calculate the percentage of chargebacks for each merchant over the last 30 days.
PayPal uses this question because chargeback monitoring is central to fraud detection, merchant risk scoring and compliance. You filter the last 30 days, group by merchant and calculate
chargebacks / total transactionsusing conditional aggregation. This mirrors how PayPal tracks emerging risk patterns across merchant cohorts.Tip: Mention aligning timestamps to a unified timezone since PayPal processes global transactions.
Write an SQL query to retrieve each user’s last transaction
PayPal asks this to assess understanding of recency driven metrics used in fraud models, credit assessments, and user lifecycle reporting. You partition by user, order by event time in descending order, and select rows with
ROW_NUMBER() = 1. This ensures you retrieve the latest signal for downstream models.Tip: Clarify how you handle tied timestamps, which occur in high-throughput systems.
-
PayPal uses this problem because subscription overlaps can indicate billing issues, duplicate products or potential customer confusion. You join the table to itself on user ID and check if one subscription’s start date occurs before another’s end date and vice versa. If true, the user has overlapping periods.
Tip: Note how you manage open ended subscriptions since they appear often in recurring billing.
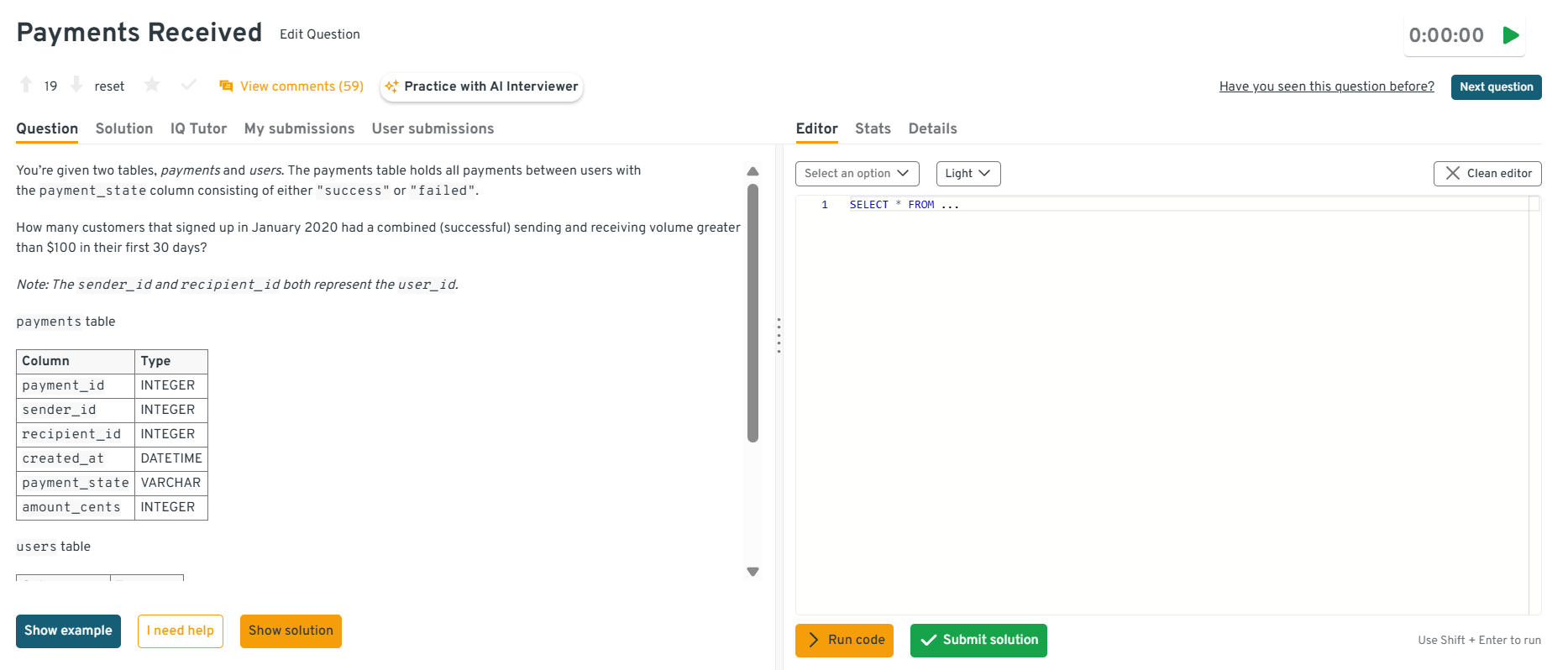
-
PayPal asks this to test your ability to build onboarding and early user engagement metrics. You filter users by signup date, join to transactions, restrict events to the first 30 days and aggregate successful send and receive amounts, then filter where totals exceed 100 dollars. This mirrors PayPal’s early-lifecycle performance tracking.
Tip: Address how you handle users with incomplete or delayed event data.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
Find the month_over_month change in revenue for the year 2019.
PayPal tests this because revenue trend analysis is essential for financial planning and monitoring payment performance across regions. You group by month with
DATE_TRUNC, compute monthly revenue, calculate the previous month’s value usingLAG()and compute the percent change. This replicates PayPal’s internal reporting logic.Tip: State how you handle missing or partial months, common in fiscal reporting.
-
PayPal asks this to evaluate whether you can derive multiple KPIs from a single fact table, which is critical for dashboards used by risk, merchant and product teams. You compute counts, distinct users, conditional sums for high value payments and aggregate revenue by product to find the top performer.
Tip: Mention excluding reversals or refunds since PayPal transaction tables include both.
Want to get realistic practice on SQL and data engineering questions? Try Interview Query’s AI Interviewer for tailored feedback that mirrors real interview expectations.
ETL Pipelines And Big Data Engineering Interview Questions
This section evaluates your understanding of end to end data pipelines and large scale data processing. PayPal uses technologies such as Spark, DataFlow, Hadoop, Hive, Airflow and Kubernetes. You may be asked to design pipelines, troubleshoot failures or reason about latency and throughput constraints when processing billions of records daily.
How would you design a batch pipeline that processes daily payment logs into a merchant level summary table?
This problem checks how you think about ingestion, transformation and reliability for PayPal scale data. A strong answer starts with ingesting logs from storage into Spark or DataFlow, validating schemas and filtering corrupt records. Next, aggregate by merchant and date, apply idempotent deduplication and write results to a partitioned warehouse or lakehouse table. You also describe checkpoints, retries and backfills to handle partial runs and ensure consistent merchant metrics.
Tip: Explain how you track data completeness at each stage before exposing tables to downstream users.
-
This question evaluates your understanding of streaming system internals and why timing semantics matter in fraud detection. Event time represents when the transaction actually occurred, while processing time represents when it reached the system. Relying on processing time skews aggregates because late or out-of-order events inflate or deflate per-minute spending totals. A strong answer explains how to use event-time windows, watermarks, and triggers to correctly group transactions by their true timestamps while still emitting near–real-time results.
Tip: Emphasize how watermark thresholds balance accuracy and latency, and mention strategies like updating windows when late data arrives without reprocessing the entire stream.
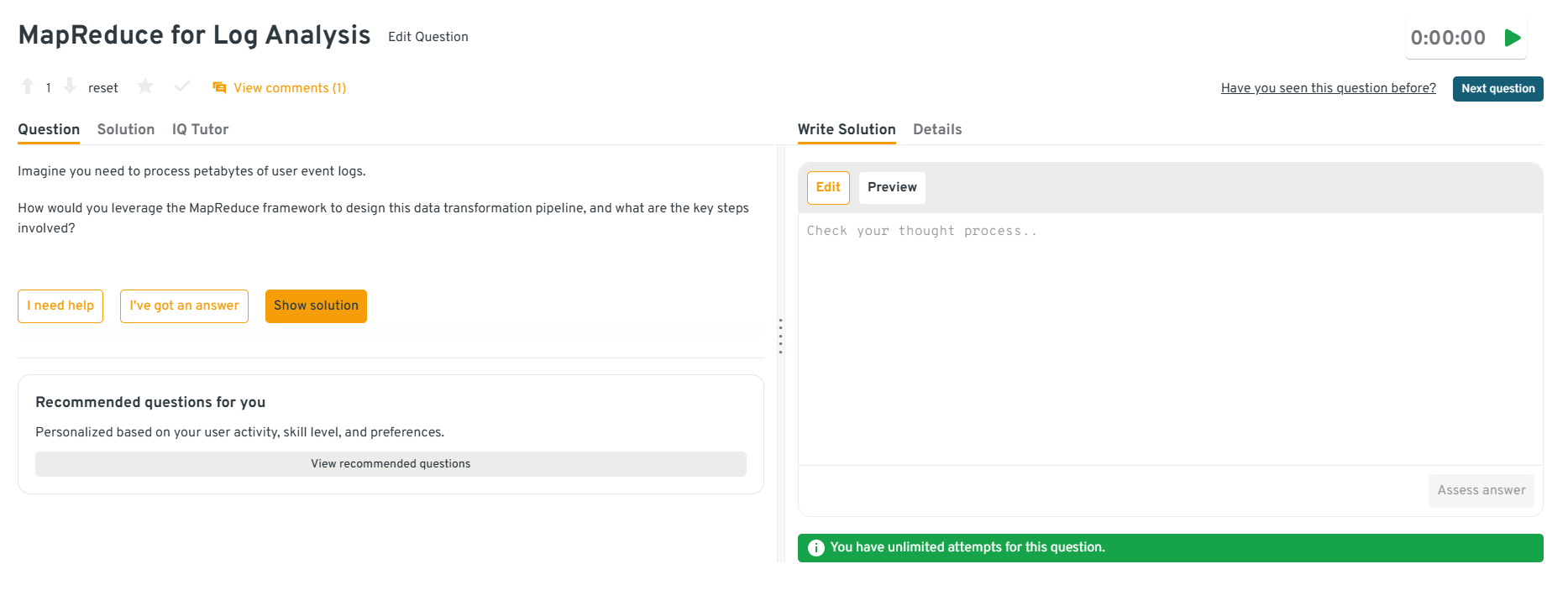
-
Here PayPal is testing your ability to reason about large scale processing even on older frameworks. Start with a map phase that parses raw logs, normalizes fields and emits key value pairs, for example by user, merchant or session. The shuffle groups related records, and the reduce phase aggregates metrics, builds session views or writes cleaned records. You then describe staging outputs, compression, partitioning and job chaining for multi step transformations.
Tip: Highlight how you manage schema changes and backward compatibility across long running MapReduce workflows.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
Describe how you would structure a pipeline that supports both real time fraud signals and daily aggregates.
This scenario tests your ability to design a hybrid architecture for PayPal’s fraud and analytics needs. A good answer separates streaming and batch paths. The streaming layer consumes events from a message bus, applies lightweight enrichment, and writes features to a low latency store for fraud models. In parallel, raw events flow into storage for batch processing, where daily aggregates are computed and reconciled. You explain how schemas and identifiers stay consistent across both paths.
Tip: Call out how you handle late events so streaming and batch views do not drift over time.
How would you design logging and alerting for a pipeline that processes high risk financial events?
This question checks your operational discipline in a regulated environment. You would log key stages such as ingestion counts, validation failures, transformation errors, and publish successes, ideally with structured logs. Metrics include throughput, error rates, lag and data completeness. Alerts trigger on deviations, such as spikes in failures or drops in volume for specific regions or merchants. You also describe routing alerts to on call channels with clear runbooks.
Tip: Mention storing traceable identifiers in logs to support audits and post incident investigations, which is critical for financial systems.
Looking for hands-on problem-solving? Test your skills with real-world challenges from top companies. Ideal for sharpening your thinking before interviews and showcasing your problem solving ability.
Data Architecture And System Design Interview Questions
This part of the interview focuses on designing scalable data platforms that support millions of daily transactions. You may be asked to architect lakehouse structures, define data contracts, design ingestion layers or describe how you would store and serve financial datasets at scale. Interviewers want to understand how you break down complex systems and justify design choices.
How would you design a data platform that ingests payment events from multiple regions and ensures consistent reporting globally?
This question assesses your ability to design multi-region ingestion and harmonized metrics, which PayPal depends on for unified financial reporting. A strong answer includes regional ingestion pipelines writing raw events to local storage, followed by cross region replication into a central lakehouse. You explain using standardized schemas, unified time normalization, idempotent ingestion, and partitioning by region and event date to keep reporting consistent across markets. Global reconciliation jobs ensure accuracy.
Tip: Mention how you align late arriving data to maintain consistent merchant and country level metrics.
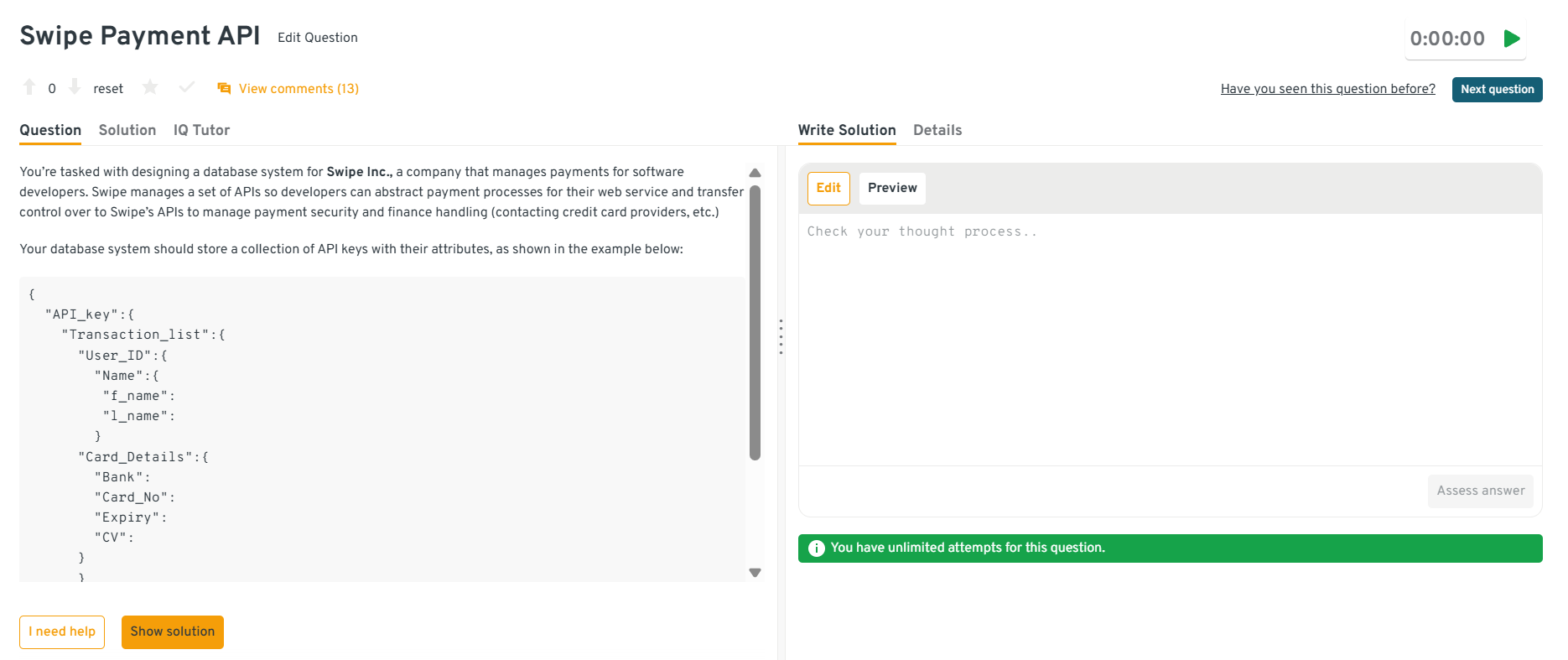
-
This question checks how you document system expectations before designing secure financial storage. Functional needs include storing transactions, linking users and preserving API key metadata. Non functional needs include encryption, strict access control, low latency reads and high availability. You also discuss compliance requirements, backup policies and audit logging, which mirror PayPal level governance expectations.
Tip: Emphasize separation of sensitive data domains so compromises in one area do not affect others.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
-
PayPal asks this question to test how you structure third party ingestion. You describe pulling data from the API or webhook stream, validating schemas, deduplicating events, and storing raw logs before transforming them into clean fact tables. Partitioning by date and merchant supports efficient analytics. The final step writes curated tables for BI tools and financial reporting.
Tip: Mention handling idempotency to prevent duplicate ingestion during retries.
Design a pipeline that supports real time fraud alerts while also providing historical analytics.
This question evaluates hybrid architecture design, which PayPal uses heavily. You outline a streaming layer consuming payment events, enriching features and pushing signals to a low latency store for fraud models. In parallel, raw events land in long term storage for batch jobs that generate daily aggregates and model training data. Shared schemas and identifiers keep both systems consistent.
Tip: Explain how you reconcile late events so alerting logic and historical reporting do not diverge.
Describe how you would ensure secure access to sensitive financial data across engineering and analytics teams.
This question tests your approach to governance, a major priority in PayPal scale environments. You propose using fine grained access controls, column level restrictions for sensitive fields, tokenization of user identifiers and encryption at rest and in transit. Access is granted through role based groups with periodic reviews. Audit logs track every query and modification for compliance.
Tip: Note that anonymized or aggregated datasets help analytics teams work productively without exposing raw sensitive data.
Watch Next: Uber Data Engineer Interview: Design a Ride Sharing Schema
In this mock session, Jitesh, an Interview Query Coach and data engineer from Uber, walks through how they would build and monitor a high-volume data pipeline, from ingestion to analytics. You’ll see how real-world decisions around schema design, latency, and monitoring are made in a fast-moving environment to help you connect architecture choices to business impact at your next PayPal data engineering interview.
Behavioral And Cross Functional Collaboration Interview Questions
PayPal values engineers who communicate clearly, work well across teams and handle complex situations with ownership. These questions explore how you collaborate with analysts, architects, product managers, and distributed engineering teams. Interviewers look for examples that show initiative, empathy, and sound judgment.
Tell me about a time you improved the reliability of a data pipeline that supported critical reporting.
PayPal asks this to assess your ability to stabilize systems that influence payouts, fraud detection, and regulatory reporting. A strong answer outlines diagnosing failures, improving validatio,n and ensuring idempotent processing.
Example: “Our settlement pipeline frequently dropped late events. I added schema checks, idempotent writes, and optimized Spark partitioning. Failures dropped from 4 percent to under 1 percent, and daily reports arrived 25 minutes earlier. This mirrors PayPal’s need for resilient merchant reporting pipelines.”
Tip: Quantify reliability gains clearly.
Describe a situation where you had to resolve a data quality conflict with another team.
This evaluates how you align definitions and resolve inconsistencies across shared datasets, something essential in PayPal’s multi-team ecosystem. Your approach should include tracing discrepancies, validating assumptions and negotiating data contracts.
Example: “Chargeback counts differed between engineering and analytics. I traced lineage, identified inconsistent status mappings and led a working session to unify definitions. Updating the shared table fixed the mismatch and restored dashboard trust, similar to PayPal’s cross-team workflows.”
Tip: Emphasize how documentation prevents future conflicts.
Explain how you handle urgent pipeline issues during high traffic periods.
PayPal tests how you operate under peak load when delays can affect merchant payouts or fraud decisions. The approach includes impact assessment, root cause isolation and rapid communication.
Example: “During a holiday surge, our fraud-signal job lagged 20 minutes. I reviewed cluster metrics, found a skewed join and switched to a broadcast join. Latency dropped under two minutes while I kept risk teams updated. This mirrors PayPal’s traffic patterns.”
Tip: Mention using dashboards and alerts to triage quickly.
What makes you a good fit for our company?
This question checks alignment with PayPal’s mission and the technical scale of its data systems. Your approach should link your engineering strengths to global data pipelines and trust-centered products.
Example: “I’ve built multi-region, event-driven pipelines and recently designed a reconciliation workflow that improved financial accuracy by 15 percent. PayPal’s focus on secure global payments matches the systems I enjoy building.”
Tip: Show awareness of PayPal’s fraud, risk and checkout domains.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
Describe a time you had to work with a difficult stakeholder.
PayPal uses this to see how you collaborate with risk, compliance or product partners who may have competing priorities. Your approach should show patience, transparency and data-backed influence.
Example: “A compliance stakeholder pushed for a redesign that would increase latency. I walked them through pipeline diagrams, demonstrated constraints and proposed a phased solution that met audit needs without performance loss. They aligned quickly and we delivered on schedule.”
Tip: Focus on how your communication improved trust.
Want to master the full data engineering lifecycle? Explore our Data Engineering 50 learning path to practice a curated set of data engineering questions designed to strengthen your modeling, coding, and system design skills.
What Data Engineers Do at PayPal
PayPal data engineers build and maintain the large-scale data systems that power payments, fraud detection, merchant insights, and financial reporting. They work across cloud platforms and distributed systems to ensure data is accurate, timely, and usable for teams across the business.
Core responsibilities include:
- Building scalable batch and streaming pipelines using Spark, DataFlow, Hive and BigQuery
- Designing lakehouse structures and data models for transactional and risk data
- Ensuring data quality, lineage, validation, and governance across shared datasets
- Optimizing ETL performance, cost efficiency, and reliability
- Collaborating with architects, product managers, and analytics teams to support decision making
The work combines deep technical problem solving with clear cross functional communication since PayPal relies heavily on clean, trustworthy data.
How To Prepare For A PayPal Data Engineer Interview
Preparing for the PayPal data engineer interview requires strong technical fundamentals, operational awareness, and the ability to reason through constraints that affect fraud detection, financial reporting, global data movement, and platform reliability. Because PayPal’s systems run on massive distributed pipelines with strict correctness requirements, you must show technical depth, sound engineering judgment, and clear communication.
Read more: How to Prepare for a Data Engineer Interview
Below is a set of targeted strategies to help you stand out.
Build intuition for financial data behavior: Understand the end to end payment lifecycle, including retries, partial authorizations, asynchronous settlement, and late arriving events. These patterns show up directly in pipeline, modeling, and debugging questions.
Tip: Explore fintech datasets or synthetic streams to observe timestamp drift, duplicate events, and idempotency issues.
Strengthen your operational mindset: PayPal evaluates how you prevent data loss, detect anomalies, and recover from failures. Review backfills, checkpointing, retries, alerting, validation rules, and incident triage workflows.
Tip: Practice describing how you’d debug a pipeline during peak traffic and how you communicate status to cross functional teams.
Develop strong architectural reasoning: Be ready to justify storage, partitioning, compute, and orchestration choices under constraints like latency, volume, cost, and compliance. Understand Spark, BigQuery, Hive, DataFlow, Airflow, and common streaming patterns.
Tip: Whiteboard systems and narrate assumptions before locking into a design.
Sharpen cross team collaboration: PayPal engineers partner with risk, product, compliance, and analytics teams. Prepare examples of resolving data inconsistencies, improving dataset usability, or aligning assumptions across stakeholders.
Tip: Rehearse one or two stories highlighting how your communication elevated data quality.
Improve your reasoning for ambiguous scenarios: PayPal frequently tests how you handle missing context, inconsistent records, duplicate events, and sudden data spikes. Show how you validate assumptions, gather context, and narrow root causes systematically.
Tip: Practice thinking aloud so your structure is clear even when the problem is messy.
Run realistic mock system design sessions: System design carries heavy weight in PayPal interviews. Practice building ingestion flows, lakehouse architectures, and fraud data pipelines under time pressure using simulated mock interviews. Use Interview Query’s Question Bank for PayPal style pipelines, or join the Coaching Program for deeper architectural feedback.
Tip: Track recurring gaps like overengineering, missing edge cases, or unclear trade offs and refine them before your onsite.
Need 1:1 guidance on your interview strategy? Explore Interview Query’s Coaching Program that pairs you with mentors to refine your prep and build confidence.
Salary And Compensation For PayPal Data Engineers
PayPal’s compensation framework is designed to reward engineers who can build scalable data systems, maintain high reliability, and support secure global payments. Data engineers typically receive competitive base pay, annual performance bonuses and meaningful equity grants. Your total compensation depends on your level, location, technical scope and the team you join. Most candidates interviewing for data engineering roles fall into mid level or senior bands, especially if they have experience with distributed systems, cloud platforms or large scale ETL architecture.
Read more: Data Engineer Salary
Tip: Confirm your target level with your recruiter early in the process because leveling determines both your compensation range and the expectations for your role.
PayPal Data Engineer Compensation Overview (2025)
| Level | Role Title | Total Compensation (USD) | Base Salary | Bonus | Equity (RSUs) | Signing / Relocation |
|---|---|---|---|---|---|---|
| DE1 | Data Engineer I (Entry Level) | $115K – $155K | $100K–$125K | Performance based | Standard RSUs | Occasional for hard-to-fill roles |
| DE2 | Data Engineer II / Mid Level | $145K – $200K | $120K–$150K | Performance based | RSUs included | Offered case-by-case |
| Senior DE | Senior Data Engineer | $170K – $245K | $135K–$170K | Above target possible | Larger RSU grants | More common at senior levels |
| MTS 1 / Staff DE | Staff or Lead Data Engineer | $210K – $300K+ | $150K–$200K | High performer bonuses | High RSUs + refreshers | Frequently offered |
Note: These estimates are aggregated from 2025 data on Levels.fyi, Glassdoor, TeamBlind, public job postings, and Interview Query’s internal salary database.
Tip: Compare ranges across at least two sources and request location-specific bands early, as PayPal compensation differs across San Jose, NYC, Austin and remote roles.
Average Base Salary
Average Total Compensation
Negotiation Tips That Work For PayPal
Negotiating compensation at PayPal is most effective when you understand market benchmarks and communicate your expectations clearly. Recruiters appreciate candidates who frame negotiations with data and a professional mindset.
- Confirm your level early: PayPal’s leveling (DE2 → Senior DE → MTS) heavily influences base salary, bonus targets and equity, often shifting offers by tens of thousands. Always clarify level before discussing numbers.
- Use real market benchmarks and communicate professionally: Anchor expectations with verified sources such as Levels.fyi, Glassdoor and Interview Query salaries. Share competing offers transparently, as PayPal expects applicants to compare opportunities, and frame your value through measurable impact like latency reductions, pipeline reliability improvements or cost optimizations.
- Account for geographic differences: Pay varies significantly across San Jose, New York, Austin and remote roles. Ask for location specific ranges to ensure you evaluate the offer accurately.
Tip: Ask your recruiter for a complete breakdown, including base salary, bonus target, equity vesting schedule and any signing incentives so you can compare offers accurately and negotiate from an informed position.
FAQs
How long does the PayPal data engineer interview process take?
Most candidates complete the interview process within three to six weeks depending on team availability, the number of technical rounds and the specific engineering group evaluating your profile. Timelines may extend when multiple teams are involved or when additional calibration is required. Recruiters share updates regularly and provide expected timelines after each major stage.
Does PayPal use online assessments for data engineers?
Some PayPal teams use an initial online assessment to evaluate coding fundamentals or basic data transformation skills, especially for early career or high volume hiring pipelines. Mid level and senior candidates often move directly to technical phone screens. When assessments are used, they typically involve practical SQL or data manipulation tasks rather than theoretical questions.
Do I need prior payments or fintech experience?
Fintech experience is helpful but not required. PayPal evaluates candidates based on their ability to design robust pipelines, understand distributed systems and respond to ambiguous data scenarios. Experience with event driven systems, high volume data or compliance driven work is a plus. Candidates without payments experience can still succeed by demonstrating strong engineering fundamentals and curiosity about financial data ecosystems.
What difficulty level should I expect for PayPal’s technical questions?
Technical questions are moderately challenging and often reflect real engineering scenarios. You can expect questions on designing pipelines, debugging distributed jobs, reasoning about late arriving events or evaluating storage decisions. PayPal emphasizes thought process and clarity over memorization. Interviewers want to understand how you break down unfamiliar problems and justify your decisions.
How important is cloud experience for data engineering roles at PayPal?
Cloud experience is valuable because PayPal operates across AWS and GCP. Candidates with exposure to tools such as BigQuery, DataFlow, EMR, S3 or Kubernetes have an advantage. However, PayPal is open to strong engineers who demonstrate transferable system design skills and a willingness to learn its cloud stack.
Does PayPal expect experience with Spark or distributed compute?
Experience with Spark or similar distributed frameworks is highly beneficial since many PayPal workloads process large volumes of transactional data. Interviewers often ask about job optimization, partitioning strategies and diagnosing performance issues. You do not need expert level knowledge but should be comfortable reasoning about how distributed systems handle data.
Will I be asked system design questions as a data engineer?
Yes. System design is a core part of PayPal’s process, especially for mid level and senior roles. Expect to design ingestion layers, data lake structures, streaming pipelines or end to end architectures for payments data. Interviewers evaluate how well you articulate trade offs, handle scaling requirements and maintain data consistency.
How does PayPal evaluate behavioral skills for data engineers?
PayPal values collaboration and expects engineers to communicate clearly with teams across engineering, analytics, product and architecture. Behavioral rounds often explore how you handle ambiguity, manage ownership, resolve conflicts or lead cross team projects. Clear and structured communication is essential.
What tools and languages should I know?
Proficiency in SQL and at least one programming language such as Python or Scala is expected. Familiarity with Spark, Hadoop, Hive, BigQuery, Airflow, Kubernetes or DataFlow is beneficial. You do not need expertise in every tool, but you should understand how modern data ecosystems operate.
Does PayPal support remote or hybrid work for data engineers?
PayPal uses a hybrid model for most engineering roles. Many teams work three days in the office and two days remotely. Policies vary by team and location, so your recruiter will share specifics during the interview process.
How many rounds of interviews should I expect?
Most candidates encounter one recruiter call, one to two technical screens, an optional take home challenge and a four or five round onsite loop. Senior candidates may have an additional architecture or leadership round. The exact structure varies by team.
How can I best prepare for PayPal’s data engineering interviews?
Focus on building strong reasoning skills, practicing architecture discussions and reviewing how distributed pipelines operate at scale. Explore Interview Query’s Question Bank for PayPal specific problems and consider running mock interviews to refine your communication and thought process.
Why does data engineering matter at PayPal?
Data engineering is core to PayPal’s ability to run secure, low latency, globally distributed payment systems. Engineers manage massive transactional pipelines, ensure data integrity for real time risk decisions, and support financial reporting across regions. The scale and complexity make the role highly impactful and technically challenging.
Become a PayPal Data Engineer with Interview Query
Preparing for the PayPal data engineer interview means developing strong technical depth, clear system design thinking, and the ability to work across a fast-moving global payments environment. By understanding PayPal’s interview structure, practicing real-world SQL, ETL, and architecture scenarios, and refining your communication, you can approach each stage with confidence. For targeted practice, explore the full Interview Query’s question bank, try the AI Interviewer, or work with a mentor through Interview Query’s Coaching Program to refine your approach and you’ll be well equipped to stand out in PayPal’s data engineering hiring process.
Paypal Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
Data Structures & Algorithms | Easy | |
SQL | Hard | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences