
EPAM Data Engineer Interview Guide (2025) – Process, Questions, and Prep Tips


Introduction
EPAM Systems stands out as a global leader in digital platform engineering, with over 61,000 employees working across 55 countries. It supports more than 340 Forbes Global 2000 clients, helping them transition to cloud-native ecosystems and AI-powered analytics. In 2025, the EPAM data engineer interview questions you’ll encounter are increasingly shaped by shifts in enterprise architecture. Demand is growing for real-time data processing, Microsoft Fabric implementations, and cloud-native ELT patterns. EPAM’s own hiring reflects these priorities, especially for engineers skilled in Python, Snowflake, Databricks, and Azure. The goal of this guide is to help you confidently approach the EPAM interview process with insights into what the role demands and how you can stand out during technical and behavioral evaluations.
Role Overview & Culture
As a data engineer at EPAM, you will build complex ELT pipelines using tools like Azure Data Factory, Databricks, Spark, and Snowflake. These systems power mission-critical insights for Fortune 500 firms undergoing large-scale digital transformation. Many projects involve re-architecting legacy platforms into Microsoft Fabric-based lakehouses or migrating entire data ecosystems into scalable cloud-native architectures. EPAM’s culture of engineering excellence is more than a tagline. You will work inside a structure known as EngX 360, which ensures code quality through value-stream metrics, automated CI/CD, and peer reviews. With over 373,000 annual learning hours logged and access to more than 1,200 mentors, you are encouraged to grow continuously. These values show up in every sprint and are essential to success. Toward the end of your preparation, make sure to study common EPAM data engineering interview questions to align with this rigorous, system-focused culture.
Why This Role at EPAM?
This role gives you direct access to global clients and opportunities to work on high-scale data estates in sectors like banking, retail, and media. You will use tools that matter in 2025—such as Snowflake, Databricks, and Azure—often inside multi-region, hybrid-cloud environments. EPAM is a Premier Snowflake partner with over 300 certified engineers and has already deployed more than 20 complex Snowflake platforms. The company is also an early mover in Microsoft Fabric. Many Microsoft Fabric interview questions in the interview process will reflect EPAM’s emphasis on lakehouse design, data activation, and Fabric’s integration with Azure Synapse. Finally, with flat promotion structures, 150+ internal tech events each year, and 12 active engineering communities, the EPAM data engineer track is designed for long-term career growth. If you want to build cutting-edge systems while accelerating your learning, this is the role to aim for.
What Is the Interview Process Like for a Data Engineer Role at EPAM?
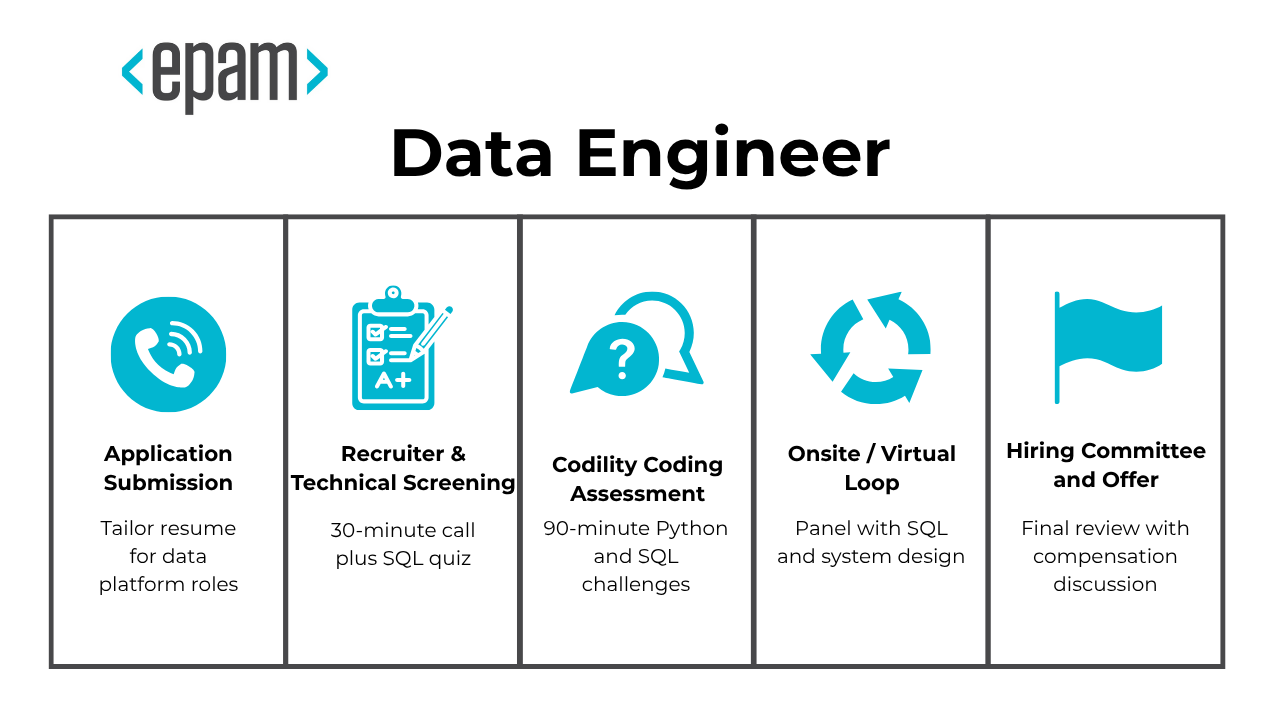
Preparing for an EPAM data engineer role means understanding a structured and technical selection process that prioritizes engineering rigor and hands-on capability. The EPAM interview process is designed to test not just your knowledge, but your problem-solving mindset and ability to build scalable, cloud-native data solutions. The EPAM interview rounds follow a consistent four-step pattern designed to evaluate both technical ability and team fit. Here is how it typically flows:
- Application Submission
- Recruiter & Technical Screening
- Codility Coding Assessment
- Onsite / Virtual Loop
- Hiring Committee and Offer
Application Submission
Your journey at EPAM begins with submitting an application through their careers portal or a referral channel like LinkedIn. Within a week, a recruiter will usually contact you if your profile matches a current opening. To maximize your chances, tailor your resume with data-centric experience. Focus on cloud platforms like Azure or GCP, and highlight work involving Spark, SQL, and Python-based ETL. EPAM places a premium on clarity and technical depth, so make your impact measurable and precise. This stage sets the foundation for everything that follows. A strong first impression here means you’ll move forward faster and face more role-relevant interview questions in later stages.
Recruiter & Technical Screening
This phase starts with a 30-minute call where the recruiter evaluates your background, English fluency, and alignment with EPAM’s distributed team culture. Right after that, you will often face a short technical quiz that includes a structured SQL section. You’ll want to be ready for common EPAM SQL interview questions like optimizing queries using window functions, handling large joins, and analyzing query plans. The screening process also covers basics in cloud platforms and ETL workflows. For senior candidates, expect lightweight questions on statistics and system design. This stage ensures that you are aligned with EPAM’s expectations before proceeding to deeper technical evaluations.
Codility Coding Assessment
The EPAM Codility test for data engineer is where many candidates are truly tested. You’ll face 2 or 3 real-world problems over a 90-minute window, often focusing on practical data manipulation, string parsing, and PySpark DataFrame tasks. The EPAM Codility test is proctored and monitored via webcam, so environment setup and focus are critical. Problems often simulate data engineering pipelines, like cleaning nested JSON data or joining travel datasets using Python and SQL. This round validates your ability to think through transformations, optimize logic, and write bug-free code under time constraints. Your performance here has a major influence on your interview trajectory, especially at the mid to senior level.
Onsite / Virtual Loop
In the virtual panel rounds, you will face 2 technical interviews followed by a behavioral session. Interviewers use EPAM Systems data engineer interview questions that reflect distributed architecture challenges. Expect deep dives into Spark internals, data skew resolution, and multi-step pipeline design. One common discussion revolves around designing scalable ELT workflows using tools like Azure Data Factory or AWS Glue. You may be asked to optimize a slow SQL query live or propose ways to integrate real-time streaming with Kafka. The final session assesses collaboration style, communication, and career aspirations. This loop tests both depth and breadth, ensuring you are ready for EPAM’s high-scale, cross-border engineering challenges.
Hiring Committee and Offer
The hiring committee reviews all interview inputs in the final step, with particular attention to epam senior data engineer interview questions if you are applying at the senior level. These questions often relate to architectural tradeoffs, cloud cost control, and real-time data processing at scale. The decision process typically spans 1 to 2 weeks. If selected, you’ll join an offer discussion where compensation, project type, and potential start date are finalized. EPAM often customizes packages based on role complexity and location. After the offer is accepted, onboarding begins with system setup and possible role-specific training. You can expect to join an active project team soon after.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Epam Systems?
What Questions Are Asked in an EPAM Data Engineer Interview?
The questions asked in an EPAM data engineer interview cover a wide spectrum—from hands-on SQL challenges and distributed system design to consulting-style problem-solving and communication skills. Your ability to reason through trade-offs, optimize for scale, and explain your choices clearly matters as much as writing correct code.
Coding & SQL Questions (45 % of score)
This section evaluates your fluency in SQL and Python through realistic data tasks that simulate production issues or analytics scenarios. You’ll encounter epam sql interview questions involving complex joins, window functions, and CTE-based solutions that test your ability to query and transform data effectively:
To solve this, join the transactions table with the products table to calculate the total order amount. Use COUNT with DISTINCT for the number of customers and COUNT for the number of transactions. Group by the month extracted from the created_at field and filter for the year 2020.
2. Find the total salary of slacking employees
To solve this, use an INNER JOIN to combine the employees and projects tables, filtering for employees assigned to projects. Then, group by employee ID and use the HAVING clause to identify employees with no completed projects (End_dt IS NULL). Finally, sum the salaries of these employees.
3. Write a query to get the current salary for each employee after an ETL error
To solve this, group the employees table by first_name and last_name and find the maximum id for each employee, as the id represents the most recent row due to autoincrement. Then, join this result back to the original table to retrieve the corresponding salary for the maximum id.
To solve this, convert each string into a set of characters. If the length of the set is greater than one, the string does not have all the same characters, and the function returns False. Otherwise, it returns True.
To solve this, iterate through the list while keeping track of the most recent non-None value. Replace each None value with this tracked value. If the first entry is None, initialize the previous value as 0.
System / Pipeline Design Questions (35 %)
Expect scenario-based questions that assess your architectural thinking across ingestion, transformation, storage, and monitoring layers. These data platform engineer interview questions often include designing resilient pipelines using tools like Kafka, Spark, Airflow, and Azure Data Factory under business and performance constraints:
6. How would you design a data warehouse for a new online retailer?
To design a data warehouse for a new online retailer, start by identifying the business process, which in this case is sales data. Define the granularity of the data (e.g., each product sale as a single event), identify dimensions like customer details, product attributes, and time, and determine the facts such as quantity sold, total amount paid, and net revenue. Finally, organize the data into a star schema for efficient querying and analytics.
7. Create a schema to keep track of customer address changes
To track customer address changes, design a schema with three tables: Customers, Addresses, and CustomerAddressHistory. The CustomerAddressHistory table includes move_in_date and move_out_date fields to record occupancy periods, enabling queries for current and historical addresses. This schema ensures normalization and preserves address change history.
8. Design a data pipeline for hourly user analytics
To build this pipeline, you can use SQL queries to aggregate data for hourly, daily, and weekly active users. A naive approach involves querying the data lake directly for each dashboard refresh, while a more efficient solution aggregates and stores the data in a reporting table or view, updated hourly using an orchestrator like Airflow. This ensures better scalability and latency.
9. Redesign batch ingestion to real-time streaming for financial transactions
To transition from batch processing to real-time streaming, use a distributed messaging system like Apache Kafka for event ingestion, ensuring high throughput and durability. Implement a stream processing framework such as Apache Flink for real-time analytics and fraud detection, while maintaining exactly-once semantics. Store raw and processed data in scalable storage systems like Amazon S3 for compliance and historical analysis, and integrate real-time OLAP stores for low-latency querying. Ensure reliability through multi-region clusters, monitoring, and checkpointing mechanisms.
10. Design a reporting pipeline using open-source tools under budget constraints
To architect a cost-efficient reporting pipeline, use Apache Airflow for orchestration, Apache Spark for data processing, PostgreSQL for storage, and Metabase for visualization. Ingest raw data from internal databases and log files, process it with Spark, and store the results in a reporting schema in PostgreSQL. Use Airflow to schedule and monitor the pipeline, and Metabase to create dashboards and deliver reports. Ensure data quality with validation checks and optimize for scalability and security.
Behavioral & Consulting‑Style Questions (20 %)
These questions focus on how you collaborate, lead through ambiguity, and align with EPAM’s engineering culture. Prepare to share STAR-format stories that highlight how you communicate with clients, manage delivery pressures, and engineer solutions that drive tangible business outcomes:
In EPAM’s data engineer interviews, this question often comes up in scenarios where you are expected to support data scientists or productionize ML pipelines. You should demonstrate a solid grasp of techniques like SMOTE, class weighting, and metric selection, especially when the target labels are skewed. Use this opportunity to show how your engineering decisions improve downstream model accuracy and reliability in real-world analytics systems.
12. Tell me about a project in which you had to clean and organize a large dataset.
EPAM interviewers are looking for your ability to work with messy, real-world data from multiple sources—often within the context of complex migrations or lakehouse builds. Explain how you managed schema inconsistencies, handled nulls or outliers, and automated parts of the cleaning process using tools like PySpark or SQL. If possible, link your efforts to performance gains, improved data trust, or accelerated time to insight.
13. What do you tell an interviewer when they ask you what your strengths and weaknesses are?
At EPAM, self-awareness and growth mindset are core to engineering culture. Choose strengths that reflect traits like structured thinking, performance tuning, or scalable pipeline design—then back them up with examples from recent roles. For weaknesses, select something manageable such as over-engineering early-stage solutions, and show how peer feedback or mentorship at EPAM would support your evolution.
14. Why Do You Want to Work With Us?
This question is your chance to show that you’ve done your research and understand EPAM’s value proposition in cloud data and analytics. Talk about how their commitment to engineering excellence, elite Snowflake and Microsoft Fabric partnerships, and open-ended promotion model align with your career goals. Emphasize that you want to contribute to their global-scale projects while continuing to grow in a technically rigorous and supportive environment.
How to Prepare for a Data Engineer Role at EPAM
Preparing for a data engineering role at EPAM involves honing both technical skills and interview strategy. As a mid-senior professional, leverage your experience while also practicing in areas EPAM emphasizes. The process can be rigorous, but focusing on the following key preparation points will boost your confidence and readiness.
Master Codility formats (90 min, 3 tasks)
EPAM typically begins with an online coding assessment on Codility, roughly 90 minutes long with about three tasks. These challenges span different areas – for example, writing a Python script to solve a problem, composing an SQL query for a data scenario, and possibly tackling a PySpark data processing task.
To excel, practice solving algorithmic questions and data problems in a timed environment. Get comfortable with Codility’s interface and ensure you can write correct, efficient code quickly. Even experienced engineers should brush up on core data structures, algorithms, and query writing under pressure. Mastering the Codility format means being able to parse problems swiftly, implement solutions with minimal debugging, and handle edge cases – all within the tight time limit. Time management is key: with about 30 minutes per task on average, you must balance speed and accuracy.
Drill advanced SQL with window functions and CTEs
Strong SQL skills are crucial for EPAM’s data engineering interviews. Expect complex SQL query challenges that go beyond simple selects. Focus your practice on advanced SQL techniques like window functions and Common Table Expressions (CTEs). For instance, you might need to find top-performing entries per category, calculate running totals or percentages, or transform normalized data into analytics-friendly form – tasks well-suited to window functions (like RANK, ROW_NUMBER, SUM() OVER partitions).
Be comfortable writing a multi-step query using CTEs to break down complicated logic into readable parts. By drilling these techniques, you’ll be prepared to write efficient, correct SQL on the fly. EPAM interviewers often want to see how you think in SQL, so narrate your approach: explain how you partition data or why you choose a particular window function. Demonstrating fluency in advanced SQL not only helps solve the problem but also shows you can handle real-world data scenarios.
Practice system‑design whiteboarding (Kafka, Azure Data Factory)
Beyond coding, EPAM may evaluate your architecture and design thinking. Be ready to whiteboard a data pipeline or system design that incorporates modern data engineering tools – for example, Apache Kafka for streaming and Azure Data Factory (ADF) for orchestrating data flows. Practice explaining how you would design a scalable, reliable solution for a typical scenario (say, processing event data from ingestion to analytics). Outline the role of each component: how Kafka would buffer and stream real-time data, how ADF would schedule and manage batch transformations or data movement to storage and databases, and how the pieces fit together.
Focus on clarity and rationale: discuss data partitioning, fault tolerance, and why specific technologies are suited to the task. As a mid-senior professional, draw on any past architecture work you’ve done – it’s impressive to discuss real examples. The goal is to show that you can think at a high level about system components and trade-offs, not just write code. A polished whiteboard explanation of a data pipeline involving tools like Kafka and ADF will demonstrate your ability to design solutions in line with EPAM’s project needs.
Craft STAR stories around client‑facing wins
EPAM places value on communication and client-facing experience, so expect behavioral questions. Prepare several success stories from your past work using the STAR format (Situation, Task, Action, Result), especially those involving client interactions or business impact. For example, recall a project where a client had a tough data problem (Situation), describe your role and goal (Task), explain the steps you took to solve it (Action), and highlight the positive outcome (Result) – ideally with quantifiable results like performance improvements or client satisfaction.
Focus on “wins” that showcase teamwork, adaptability, and leadership in a client context, since EPAM is a consultancy environment. Having these narratives ready will allow you to answer questions about challenges or accomplishments clearly and confidently. It also shows interviewers that you can deliver results and communicate effectively with stakeholders – key qualities for a mid-senior data engineer.
Simulate full loops via mock interviews
Finally, practice the entire interview process to build confidence and identify any weak spots. Simulate a full mock interview loop by combining a timed coding test, technical Q&A, system design discussion, and behavioral interview back-to-back – much like the real sequence at EPAM. You might start with a 90-minute mock Codility test, then have a colleague drill you on advanced SQL and Python questions, followed by a whiteboard exercise designing a data solution, and conclude with behavioral questions about your past projects.
Treat these mock interviews seriously: adhere to the time limits and put yourself under interview-like pressure. Afterwards, seek feedback from our coaches on both your technical answers and communication. This comprehensive rehearsal will help you improve your problem-solving speed, refine how you articulate design choices, and polish your stories. By experiencing a full practice loop, you’ll enter the actual EPAM interviews more relaxed and prepared for each stage.
FAQs
What Is the Average Salary for a Data Engineer at EPAM?
Average Base Salary
Average Total Compensation
Does EPAM Use Azure or AWS More?
While EPAM supports multi-cloud solutions, Azure is the most commonly used platform across their data engineering engagements. The company partners closely with Microsoft and has been early to adopt tools like Fabric, Azure Synapse, and Data Factory. Therefore, you should expect EPAM Azure data engineer interview questions to feature heavily in pipeline, orchestration, and storage scenarios.
Where Can I Find More EPAM Data Engineer Interview Threads?
For more insights and shared candidate experiences, explore the Interview Query blogs and search the EPAM tag. You’ll find detailed posts, coding walkthroughs, and firsthand takes on technical rounds from other data engineers.
Conclusion
The EPAM data engineer interview questions you’ll face reflect a high bar for engineering depth, system design thinking, and real-world problem solving. If you’re aiming to succeed, approach your prep with structure: simulate full interview loops, refine your SQL and cloud pipeline skills, and craft stories that show your impact. Whether you’re just beginning to upskill or pushing toward a senior promotion, our curated Data Engineer Learning Path can guide your technical mastery. Explore the full EPAM Data Engineer Interview Questions Collection to benchmark your readiness. And for inspiration, check out Hanna Lee’s Success Story to see how preparation translated into a dream offer. You’re closer than you think—just one loop away.
EPAM Data Engineer Jobs
Epam Systems Interview Questions
| Question | Topic | Difficulty | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Medium | |||||||||||||
Let’s say you work at Allstate. Allstate is running Create a subquery or common table expression named
Note: Please make the Note: Please return only one query with each number in a different row Example: Input:
Output:
| ||||||||||||||
Data Structures & Algorithms | Medium | |||||||||||||
Machine Learning | Easy | |||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences