
EPAM Data Scientist Interview Guide | Questions, Process & Prep Tips


Introduction
If you are preparing for EPAM data scientist interview questions in 2025, you are entering a space that values depth, impact, and readiness for real-world complexity. EPAM Systems stands as a global leader in technology consulting, and its data science roles reflect this stature. The interview process here has shifted toward dynamic, scenario-based evaluations.
Rather than focusing solely on algorithms or theory, you will be asked to demonstrate how your models perform under operational conditions and how your solutions integrate across cross-functional teams. These interviews aim to measure not just technical skills, but also your ability to think strategically and build systems that scale across industries.
You are not only being evaluated on code but on how effectively you can bring that code to life within enterprise ecosystems. This guide will help you navigate those expectations, build confidence, and align your preparation with EPAM’s high standards.
Role Overview & Culture
As you explore EPAM data scientist interview questions, it is crucial to understand what being an EPAM data scientist actually means. Your role will extend far beyond developing models. You will build end-to-end machine learning pipelines, deploy them to the cloud using platforms like GCP or AWS, and collaborate with global stakeholders to deliver outcomes that matter.
EPAM data scientists operate within Product Oriented Delivery squads, where developers, product owners, AI specialists, and designers work as a cohesive unit. These cross-functional squads promote agility and mutual growth, encouraging experimentation and joint accountability. The heart of EPAM’s culture lies in Engineering Excellence, or EngX.
This framework nurtures software craftsmanship and continuous improvement, making sure you are always growing both technically and strategically. It is not just about writing code; it is about understanding the systems and markets your code will affect. Moreover, EPAM’s ProductX initiative fosters a strong product mindset, ensuring you approach challenges with business impact in mind. This culture transforms technical contributors into strategic thinkers who are empowered to lead transformation, not just participate in it.
Why This Role at EPAM?
You should consider a role in EPAM data science because it gives you access to datasets from some of the most influential companies in the world. You will work on high-stakes, production-grade AI models for clients that include over two-thirds of the Fortune 100. This exposure pushes you to solve problems at scale, delivering insights and automation that impact millions.
Beyond data access, EPAM equips you with one of the most advanced MLOps stacks in the industry. You will gain hands-on experience with Kubernetes, MLflow, TFX, and CI/CD workflows across AWS, Azure, and GCP. This is where infrastructure meets innovation, and you get to drive both. Finally, EPAM’s generous investment in your learning ensures that you never stop progressing. Their custom-built education platforms, 373,000+ learning hours per year, and access to certification programs will give you the tools you need to grow into a leader in this space. This is where your potential meets real opportunity.
What Is the Interview Process Like for a Data Scientist Role at EPAM?
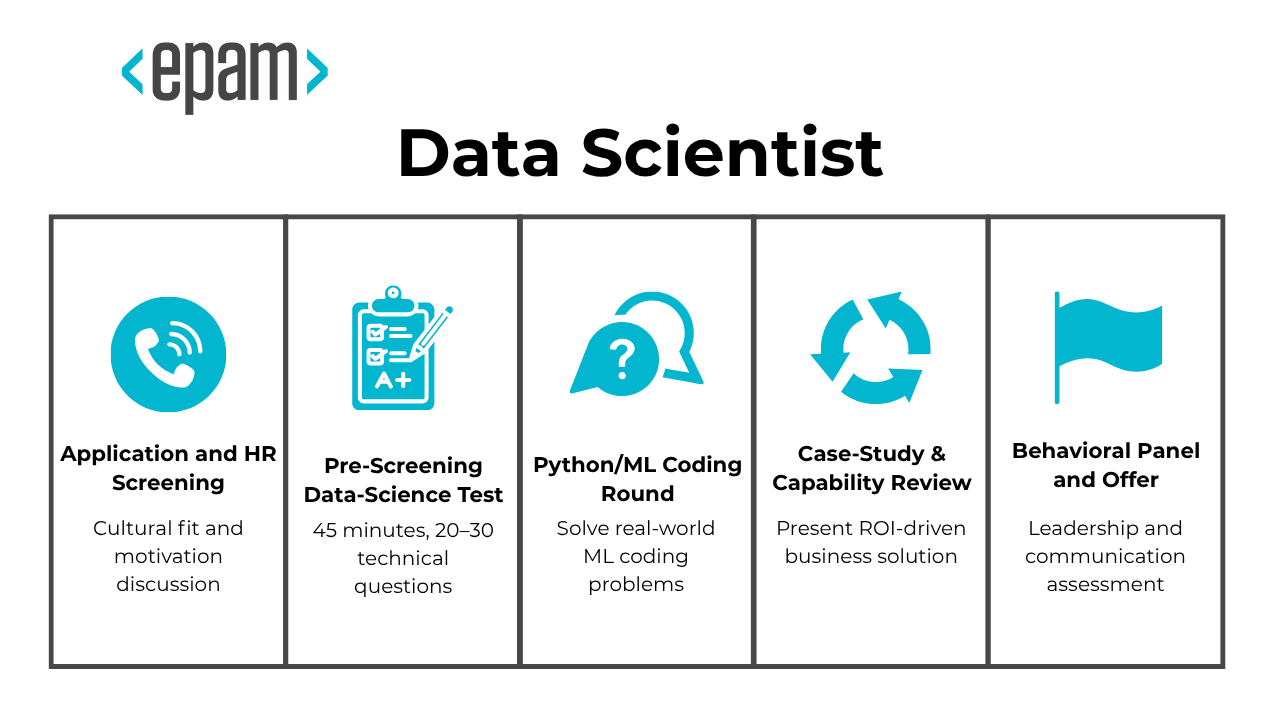
The EPAM data scientist interview questions in 2025 reflect a rigorous, real-world approach that emphasizes business outcomes and technical excellence. The data science EPAM interview journey spans approximately two to four weeks and follows a structured series of assessments that goes through:
- Application and HR Screening
- Pre‑Screening Data‑Science Test
- Python/ML Coding Round
- Case‑Study & Capability Review
- Behavioral Panel and Offer
Application and HR Screening
This stage is your first opportunity to align your profile with EPAM’s global consulting mindset. After you apply through the career portal or a recruiting partner, you will speak with an HR specialist for around 30 minutes. This conversation assesses your academic background, work history, English fluency, and cultural fit. EPAM values flexibility, so expect questions about your preference for remote or hybrid setups. You will also learn what to expect next in the process. At this point, your ability to articulate motivation, demonstrate clarity about the role, and show alignment with EPAM’s engineering excellence values is essential. Think of this as the foundation for everything that follows.
Pre‑Screening Data‑Science Test
The EPAM data science pre-screening test lasts 45 minutes and is designed to simulate the breadth of your technical fluency. You will answer 20 to 30 timed questions that assess your knowledge in statistics, machine learning theory, and basic SQL.
While some questions focus on interpreting Python outputs, most evaluate whether you understand critical data concepts such as feature engineering, A/B testing frameworks, and common model pitfalls. Your score threshold depends on your level, so junior applicants need 60 to 70 percent accuracy, while senior candidates must exceed 80 percent. This stage doesn’t just measure memory—it tests your readiness to think like a real-world data consultant.
Python/ML Coding Round
The live technical session evaluates your ability to translate concepts into code. You will work in Jupyter or EPAM’s internal environment for about 90 minutes. During this round, you will encounter challenges grounded in production scenarios, such as building a churn model or demand forecaster. You’ll be expected to handle everything from missing data and feature selection to model tuning.
The evaluators look for fluency in libraries like Pandas and Scikit-learn. Since this round involves EPAM Python interview questions and EPAM interview questions Python style logic, prepare to explain your code and model choices clearly. Your focus should be solving real business problems, not just writing elegant syntax.
Case‑Study & Capability Review
In this phase, you take on the role of a consultant, presenting your solution to a client-style business problem. EPAM often uses a churn prediction case involving e-commerce data, and you must develop a modeling pipeline with explainable outputs and strategic recommendations. This EPAM data science capabilities review and EPAM Systems data science services review round also examines your understanding of ROI impact, timelines, and stakeholder goals.
You are expected to communicate not only how your model works, but also why it matters and how it integrates with real client systems. If you can connect insights to action, you will stand out in this pivotal stage.
Behavioral Panel and Offer
The final conversation explores your leadership potential, team dynamics, and how well you fit EPAM’s collaborative ecosystem. You will respond to storytelling prompts, client negotiation scenarios, and questions on team conflict. Junior candidates are evaluated on coachability and adaptability, while seniors must show strategic ownership and mentorship ability.
This round assesses more than soft skills—it’s about your ability to inspire confidence and navigate ambiguity. Interviewers seek people who can advocate for data science outcomes in executive settings. Once completed, you typically receive an offer within three to five business days, including compensation details, project alignment, and opportunities for rapid growth within EPAM.
Challenge
Check your skills...
How prepared are you for working as a Data Scientist at Epam Systems?
What Questions Are Asked in an EPAM Data Scientist Interview?
EPAM data science interview questions focus on real-world readiness, combining technical depth with consulting acumen across five key categories: coding, machine learning, business case studies, and behavioral insight.
Python / Coding Questions (40 %)
This section tests your fluency in Python and SQL through hands-on problem solving—expect to encounter vectorization, data manipulation with Pandas, and logic design seen in many EPAM Python interview questions:
To solve this, iterate through each word in the list and calculate the sum of the ordinal positions of its letters using ord(letter) - ord('a') + 1. Use list comprehension to efficiently compute the alphabet sum for all words and return the result as a list..
To solve this, group the truck locations by their model and count the frequency of each location for each model. Use the mode function to find the most frequent location for each truck model. This ensures the output contains the top location for each model.
To solve this, iterate through each row of the matrix, calculate the total number of employees for the company (row sum), and divide each department’s employee count by the total. This will yield the percentage of employees in each department for every company.
4. Descending Alphanumeric Sorting
To solve this, extract the letter and number components from each string using a helper function. Then, use Python’s sorted() function with a custom key that sorts primarily by the letter in alphabetical order and secondarily by the number in descending order.
To solve this, iterate through the dictionary and compare the first element of each list to the input character using the ord() function to calculate the distance. Use the min() function with a lambda key to find the key with the smallest distance.
6. Write a query to get the total three-day rolling average for deposits by day
To solve this, first filter for deposits (transaction_value > 0) and aggregate them by day using DATE_FORMAT. Then, perform a self-join on the aggregated table to include rows within a three-day range for each date. Finally, calculate the rolling average using AVG() grouped by the date.
7. Calculate the first touch attribution for each user_id that converted
To determine the first touch attribution, first identify users who converted using a subquery or CTE. Then, find the earliest session (created_at) for each user and join this information back to the attribution table to retrieve the channel associated with their first visit.
Machine‑Learning & Statistics Questions (35 %)
You’ll be assessed on foundational and applied knowledge of algorithms, model evaluation, and epam machine learning techniques—emphasizing both accuracy and deployment awareness in real scenarios:
8. You are testing hundreds of hypotheses with many t-tests. What considerations should be made?
When testing multiple hypotheses, the risk of false positives increases significantly. To address this, you can use correction methods like the Bonferroni correction to adjust significance levels or opt for an F-test, which evaluates all comparisons simultaneously. However, each method has trade-offs, such as increased false negatives for corrections or limited specificity with F-tests.
To reduce the margin of error from 3 to 0.3, the sample size must be increased. Using the formula for margin of error, the additional samples required can be calculated as (k = 11 \cdot Z^2 \cdot \sigma^2), where (Z) is the Z-score and (\sigma^2) is the population variance. This ensures the margin of error decreases to the desired level.
10. What is an unbiased estimator and can you provide an example for a layman to understand?
An unbiased estimator is a statistic used to approximate a population parameter without systematic error. For example, the sample mean is an unbiased estimator of the population mean if the average difference between the sample mean and population mean is zero. To explain this concept, consider estimating voting preferences using a sample survey. Ensuring unbiased sampling methods, such as avoiding phone-only surveys, helps reduce bias and improve the estimator’s accuracy.
11. How would you build the recommendation algorithm for type-ahead search for Netflix?
To build a type-ahead search recommendation algorithm for Netflix, start with a prefix matching system using a TRIE structure for efficient lookups. Address dataset bias by focusing on user-typed corpus and incorporating Bayesian updates based on user interactions. Enhance recommendations by leveraging user profiles and clustering features like preferences (e.g., Coen Brothers fan). Scale the system using Kubernetes for mapping profiles and caching condensed feature sets to ensure uptime and scalability.
12. How would you build a job recommendation feed?
To build a job recommendation feed, start by analyzing the dataset, which includes user profiles, job application history, and answers to job search questions. Use supervised or unsupervised models, such as collaborative filtering or classification algorithms, to predict job recommendations. Feature engineering is crucial, incorporating user activity data, job browsing behavior, and vectorized job titles and skills. Address challenges like the cold start problem, business impact, and balancing user qualifications with job desirability.
13. How would we build a Bank Fraud Model?
To build a fraud detection model, start by creating a binary classifier on an imbalanced dataset. Consider the accuracy of the data, the interpretability of the model, and the costs of misclassification. Optimize for recall to minimize false negatives, as undetected fraud can lead to significant financial losses. Use techniques like reweighting, custom loss functions, and synthetic data generation (e.g., SMOTE) to address class imbalance.
Case‑Study & Business Impact Questions (15 %)
These questions mirror EPAM’s data science capabilities review format and assess how well you can tie data solutions to KPIs, business impact, and strategy execution for global clients:
14. How would you measure the success of the Instagram TV product?
To measure the success of Instagram TV, start by clarifying its goals, such as increasing user engagement and retention. Define metrics like retention rates (30-day, 60-day, 90-day), active user counts, and average time spent per user. Analyze secondary metrics by comparing cohorts of users based on their Instagram TV usage and retention rates. Additionally, evaluate feature drop-off rates and creators’ usage to understand the impact on content creation and user behavior.
15. How do we measure the launch of Robinhood’s fractional shares program?
To measure the success of Robinhood’s fractional shares program, focus on metrics like new user acquisition, engagement, and trading volume. Use methods such as tracking new user behavior, analyzing retention rates, and conducting hold-out tests to isolate causal effects. Segment users by balance and trading frequency to understand the impact across different groups.
To measure acquisition success, focus on metrics such as conversion rate percentage, cost per free trial acquisition, and daily conversion rate. Additionally, cohort analysis can be used to track retention and engagement over time, comparing metrics like the percentage of free users who convert to paid subscriptions and their long-term retention rates. Engagement metrics, such as average weekly session duration and content consumption patterns, can further help evaluate user behavior and quality of acquisition.
To address this hypothesis, analyze metrics such as subscriber-to-views ratio, channel growth rates, and YouTube recommendation percentages. Compare these metrics across amateur and superstar channels over different time periods to identify trends and divergences in growth and performance.
18. How would you assess the validity of the result in an AB test?
To assess the validity of the result, examine the setup of the AB test, ensuring user groups were properly randomized and variants were equal in all aspects except the tested feature. Additionally, evaluate the measurement process, including sample size, duration, and whether the p-value was monitored continuously, as this can lead to biased conclusions.
Behavioral & Consulting Questions (10 %)
In this final category, EPAM probes your communication skills, leadership readiness, and stakeholder management mindset—all essential for succeeding in cross-functional delivery squads:
In the EPAM data scientist role, your ability to communicate complex findings to non-technical stakeholders is just as important as your modeling accuracy. Interviewers want to hear how you’ve navigated moments when your message didn’t land—perhaps when presenting a model’s output or explaining a metric like ROC-AUC. You should share how you adjusted your approach in real time, like simplifying terminology or inviting feedback, and how that experience shaped your communication style going forward.
20. How comfortable are you presenting your insights?
At EPAM, data scientists frequently present to Fortune 500 clients and executive stakeholders, so interviewers look for confidence and clarity in delivery. Your answer should reflect how you tailor insights using storytelling, visualization tools like Tableau or Plotly, and cloud dashboards for different audiences. Mention recent presentations and highlight your comfort speaking both in live client meetings and virtual collaboration sessions across time zones.
21. What do you tell an interviewer when they ask you what your strengths and weaknesses are?
EPAM values both technical excellence and a growth mindset, so your response should reflect these principles. Share a strength that connects to EPAM’s culture—such as translating business needs into machine learning pipelines—and illustrate it with a specific project example. When discussing a weakness, choose something realistic like overengineering models, and show how you’ve learned to prioritize simpler, scalable solutions that better align with business impact.
22. Why Do You Want to Work With Us?
EPAM wants to see alignment between your professional aspirations and their mission of global digital transformation. In your response, emphasize how EPAM’s data-driven culture, multi-cloud MLOps infrastructure, and commitment to continuous learning align with your personal growth goals. Referencing their client portfolio or programs like Engineering Excellence shows that you’ve done your homework and are motivated to contribute meaningfully.
How to Prepare for a Data Scientist Role at EPAM
EPAM’s data scientist hiring process is multi-stage, starting with an online assessment and moving through technical and case-style interviews. A clear strategy is key: begin by understanding EPAM’s test format, then drill core skills such as Python, SQL, and ML theory, and finally practice communicating your work. Break your prep into phases or milestones so you cover everything thoroughly and develop not only your technical foundation but your consulting mindset as well.
Replicate EPAM’s pre-screen test format
EPAM typically begins with a timed online coding test. This initial assessment covers algorithms, data structures, and SQL challenges in a time-boxed format. Some versions include scripting in Python or PySpark. Practice by solving 45 to 60-minute timed quizzes that simulate real EPAM test conditions. These sessions should focus on query writing, data operations, and Python logic. Aim to balance speed with clarity by reviewing your incorrect answers after each session. When practiced consistently, these time-limited exercises train you to think and respond under pressure, which mirrors the fast-paced, high-stakes environment of EPAM’s consulting work.
Drill Python for data manipulation
Strong Python skills are essential in the EPAM data scientist role. You are expected to be fluent in manipulating large datasets using Pandas and NumPy. EPAM Python interview questions often emphasize function design, OOP principles, and real-time data preprocessing workflows. Focus on building and cleaning dataframes, merging data sources, and using built-in methods efficiently. Practicing in Jupyter Notebooks or similar tools will get you comfortable writing and explaining your code during live technical sessions. When reviewing projects, remember that clarity, reproducibility, and simplicity are often valued more than over-engineered logic. Being fast and accurate with Python is not optional—it is foundational.
Refresh ML theory & deployment
Expect a deep dive into your machine learning foundations. EPAM machine learning interviews test your ability to distinguish between different algorithms, diagnose performance issues, and rationalize deployment decisions. Review supervised and unsupervised methods, model evaluation metrics, regularization techniques, and how these tools are used in a business context. Also focus on operational questions: what happens when your model underperforms in production, or how you would monitor drift. EPAM looks for candidates who can not only implement models but also speak confidently about their design decisions, optimization strategies, and production-readiness. Being able to explain the “why” behind your ML pipeline is a strong signal to your interviewers.
Craft business-impact narratives
The case study and presentation rounds test more than technical depth—they evaluate your ability to generate and communicate business value. Start by choosing one or two past projects and framing them with a clear business problem, your proposed solution, and the measurable impact. Include metrics such as ROI, conversion lift, cost savings, or operational efficiency. Think about how your model helped solve a real-world issue and who it helped. Practice explaining the logic behind your choices without relying on jargon. This approach will help you connect with technical and non-technical interviewers and demonstrate that you can think like a consultant, not just a coder.
Mock stakeholder Q&A
In the final stage, you will likely be interviewed by future teammates and managers who want to assess how you handle stakeholder communication. Rehearsing for this will improve how you explain technical decisions, handle objections, and frame results. Think of common stakeholder scenarios: justifying a black-box model to a skeptical manager, managing changing project requirements, or presenting to a non-technical audience. Practice explaining your solution’s impact in one or two minutes through mock interviews and AI Interviewer. Record yourself and evaluate how clearly and confidently you speak. At EPAM, communication is just as critical as model performance, so treat these scenarios as core to your preparation, not as an afterthought.
Set Milestones and Timeline
Break your study plan into manageable time-boxed goals so you can cover both depth and breadth. In the first two weeks, focus on coding practice—working through timed quizzes to replicate EPAM’s screening format. Then spend the next week refining your Python and ML pipeline work, including Pandas manipulation and model building. In the final stretch, shift to storytelling and mock presentations to prepare for the stakeholder and panel interviews. By balancing these preparation streams—technical fluency, ML judgment, and business communication—you will be ready for every stage of the EPAM data scientist interview process.
Conclusion
If you are aiming to succeed in the EPAM data scientist interview, strategic preparation will make all the difference. Take time to master the technical foundations and sharpen your storytelling, but just as importantly, develop a mindset focused on real-world business outcomes. This guide was built to help you approach each step with clarity. To continue learning, follow our structured data science learning path. For inspiration, check out Chris Keating’s success story. If you are in the final prep stages, explore our curated EPAM data science interview questions collection to practice with precision and confidence. Good luck!
Epam Systems Interview Questions
| Question | Topic | Difficulty | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Medium | |||||||||||||
Let’s say you work at Allstate. Allstate is running Create a subquery or common table expression named
Note: Please make the Note: Please return only one query with each number in a different row Example: Input:
Output:
| ||||||||||||||
Data Structures & Algorithms | Medium | |||||||||||||
Machine Learning | Easy | |||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences