Shopify Machine Learning Engineer Interview Guide (2025)


Introduction
If you’re thinking about becoming a Machine Learning Engineer at Shopify, you’re looking at one of the most influential roles in tech right now. Standing at the heart of the platform, it powers over 2.56 million active stores and facilitates more than $1 trillion in online sales.
As Shopify rapidly evolves into an AI-first commerce platform, this role has become essential. In just the Summer ‘25 Edition alone, the company introduced over 150 feature upgrades, many of which centered on AI tooling and automation.
That impact comes with serious responsibility. The Shopify ML Engineer interview process is rigorous, with some estimates suggesting acceptance rates as low as 0.3%. Candidates are tested on everything from algorithm design to ML system scalability.
This guide gathers the most-searched Shopify machine learning interview questions and maps out each interview step so you can focus your prep on what matters.
What Is the Interview Process Like for a Machine Learning Role at Shopify?
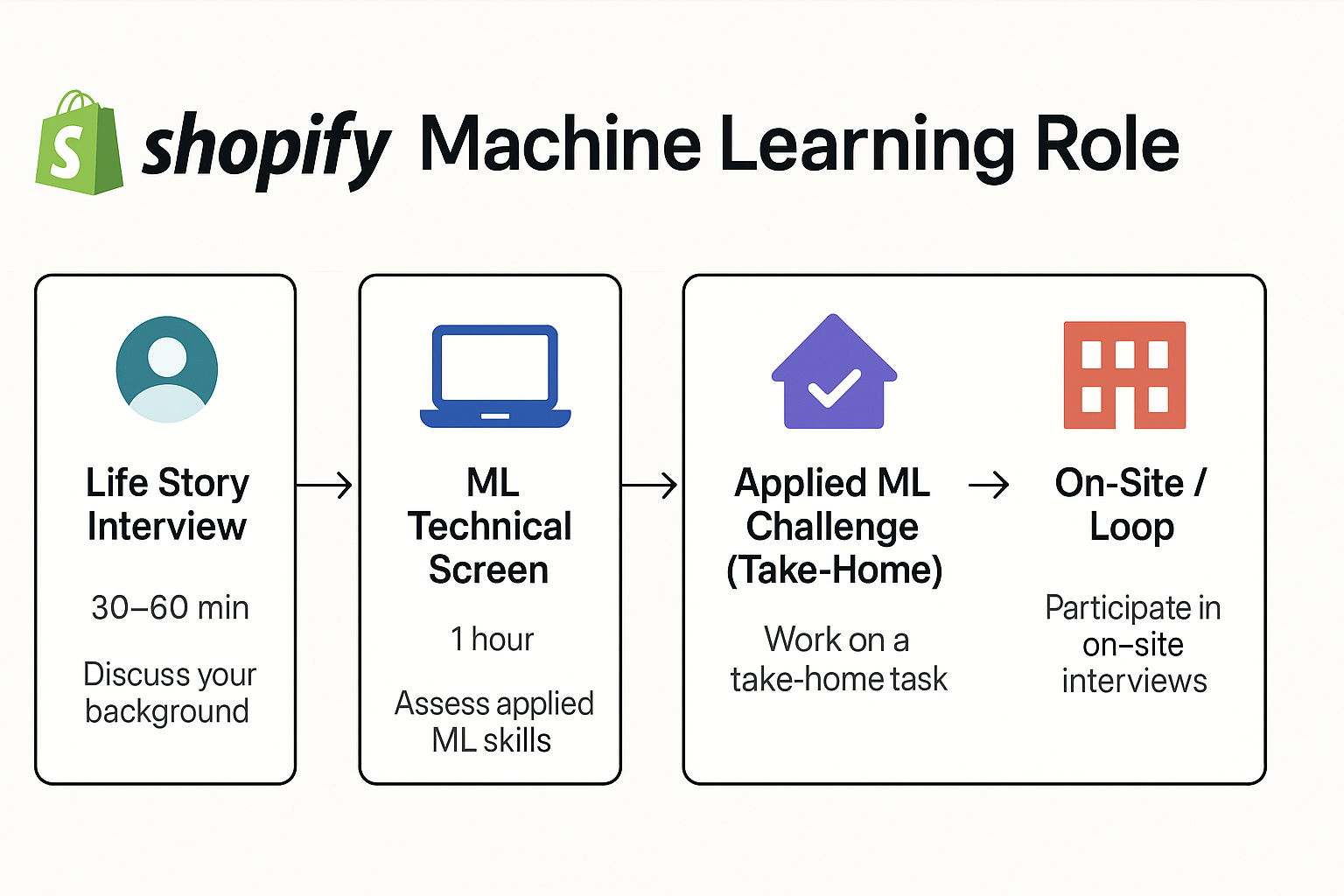
The Machine Learning Engineer Interview process at Shopify revolves around 4 key steps that evaluate your technical skills and cultural fitness as an AI/ML engineer. The steps include:
- Life Story Interview
- ML Technical Screen
- Applied ML Challenge (Take-Home)
- On-Site / Loop
Life Story Interview
The “surprisingly vulnerable” yet “refreshingly human” Life Story Interview functions as an early filter in Shopify’s Machine Learning Engineer hiring pipeline. This 30 to 60-minute session occurs after the recruiter screen but before technical evaluations. It serves as a qualitative checkpoint to determine alignment with Shopify’s core values and long-term mission.
You are expected to articulate personal and professional transitions, focusing on growth, decision-making rationale, and moments of failure or adaptation.
Interviewers look for evidence of resilience, impact-driven motivation, and capacity to adapt in high-velocity environments. As a candidate, you would regret over-indexing on technical achievements without personal framing.
ML Technical Screen
Shopify’s Machine Learning Technical Screen evaluates candidates on applied ML capabilities, production system design, and problem-solving grounded in real-world commerce use cases. The interview uses Shopify’s internal IDE or CoderPad with anonymized datasets reflecting merchant transactions and product metadata.
You’re expected to build models like collaborative filtering for recommendations or GBDTs for product categorization. You may also be asked to optimize real-time inference pipelines.
System design scenarios often involve distributed training setups using Ray, designing batch inference that supports millions of active stores, or integrating feature pipelines with Shopify’s Pano infrastructure.
Evaluation prioritizes technical execution and merchant impact, with additional weight given to collaboration and innovation. A passing average score requires at least 7.5 across categories.
Applied ML Challenge (Take-Home)
The Applied ML Challenge at Shopify tests your ability to design production-ready ML systems that solve commerce-specific problems. You are given 4 to 6 hours to work with anonymized datasets that resemble Shopify merchant data, such as product metadata or transaction logs.
Your task includes cleaning the data, creating domain-relevant features like “average order value” or “days since last purchase,” and training scalable models. You are expected to handle imbalanced classes and temporal data correctly.
You might train models like XGBoost for fraud detection with thresholds such as achieving over 85 percent recall, or fine-tune transformers for product classification. Your deliverable could be a containerized FastAPI service with a /predict endpoint or a well-documented notebook. Efficiency, explainability, and metric-driven tradeoffs are key. Shopify values SHAP-based interpretability and expects validation strategies like time-series splits.
On-Site / Loop
The Shopify on-site interview for Machine Learning Engineers evaluates your ability to design real-time ML systems that scale to Shopify’s demands while aligning with its product philosophy.
You will be asked to architect feature pipelines using Pano, Shopify’s feature store built on Feast, where temporal joins and real-time ingestion from Kafka are crucial.
You must show that you can keep inference under 100 milliseconds by integrating batch and streaming data without duplication.
You must design systems that stay reliable during peak events like Black Friday. This means multi-region Kubernetes deployments with active-active online stores, plus fallback models for low-latency resilience. You will be asked to analyze model errors using SHAP and slice-based metrics and to design A/B tests that measure business metrics like GMV or conversion rate.
Shopify looks for candidates who move fast, communicate clearly, and own decisions. If you can explain tradeoffs, collaborate across teams, and tie ML outcomes to merchant success, you will stand out.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Shopify?
What Questions Are Asked in a Shopify Machine Learning Interview?
Shopify’s Machine Learning interview evaluates core areas such as coding proficiency, model design, and behavioral competencies. Below are example questions from each category that you may encounter during the interview process:
Coding & Data-Manipulation Questions
These types of questions assess your ability to translate real-world commerce scenarios into precise data manipulations, which is critical at Shopify, where ML engineers work closely with transactional datasets to drive model features, uncover insights, and support decision-making across merchant-facing products:
To solve this, you need to query the ad_impressions table to find users who have an “Excited” impression and exclude those who have a “Bored” impression. This can be achieved by using a combination of SELECT, WHERE, and NOT EXISTS clauses to filter the results accordingly.
2. Write a query to get the number of customers that were upsold
To determine the number of customers that were upsold, identify users who made more than one purchase on different days. This involves grouping transactions by user and filtering for those with multiple purchase dates, then counting these users.
3. Calculate daily sales of each product since last restocking
To solve this, use a Common Table Expression (CTE) to find the latest restocking date for each product. Then, join this CTE with the sales and products tables to calculate the cumulative sales since the last restocking date using a window function.
4. Write a query to identify the top 5 products frequently bought together in the same transaction.
To solve this, join the transactions and products tables to associate each transaction with a product name. Use a self-join on the combined table to find pairs of products purchased together by the same user at the same time. Ensure that the first product in the pair is alphabetically less than the second to avoid duplicate pairs. Finally, group the results, count the occurrences of each pair, and order them to find the top five most frequently bought together products.
5. Write a SQL query to count transactions filtered by several criteria
To solve this, you need to write SQL queries to answer four questions: the total number of transactions, the number of different users who made transactions, the number of “paid” transactions with an amount greater than or equal to 100, and the product that generated the highest revenue from “paid” transactions. Each query should be structured to filter and aggregate data from the annual_payments table accordingly.
6. Write a Python function to divide high and low spending customers
To solve this, filter out extreme values in the customer spending data and calculate the return on investment for different spending thresholds. The function should return the minimum spending threshold where the return on investment is at least as high as the total bonus spent on high spenders.
To solve this, split the address into street, city, and zip code, then merge the dataframes on the city column to add the state information. Finally, concatenate the street, city, state, and zip code to form the complete address.
Model Design & Evaluation
These questions evaluate your understanding of fundamental model evaluation metrics and core algorithmic logic, both of which are essential at Shopify where engineers must reason about tradeoffs, debug custom ML pipelines, and build models that are both interpretable and aligned with product goals:
8. Write a function to calculate precision and recall metrics
To calculate precision and recall, use the formulae: precision = true positives / (true positives + false positives) and recall = true positives / (true positives + false negatives). In the given matrix, true positives, false positives, and false negatives can be extracted to compute these metrics.
9. Implement logistic regression from scratch in code
To implement logistic regression from scratch, use basic gradient descent with Newton’s method for optimization and the log-likelihood as the loss function. The model should return the regression parameters without an intercept term and should not include a penalty term. Libraries like numpy and pandas can be used, but not scikit-learn.
10. Build a random forest model from scratch with specific conditions
To build a random forest model from scratch, create decision trees that evaluate every permutation of the data’s value columns, splitting the data based on the values in new_point. Use pandas and NumPy for data manipulation, but avoid scikit-learn. The model should return the majority vote on the class of new_point.
11. Build a k-nearest neighbors classification model from scratch
To implement a k-nearest neighbors (kNN) classification model from scratch, use Euclidean distance to measure closeness. The function should handle data frames with any number of rows and columns, and in case of a tie among the k nearest neighbors, rerun the search with k-1 neighbors. Libraries like pandas and numpy are allowed, but not scikit-learn.
To quantify the uncertainty of a time-series forecasting model, you can analyze the distribution of prediction errors by comparing predicted stock prices with actual prices. Techniques such as calculating prediction intervals, using confidence intervals, or employing probabilistic forecasting methods can help in assessing the uncertainty and reliability of the model’s predictions.
ML System Design
These questions assess your ability to apply statistical reasoning and implement lightweight analytics pipelines, which are critical for Shopify’s ML engineers who often need to validate hypotheses, work with biased or time-sensitive data, and build scalable solutions that reflect real-world temporal dynamics:
To design a classifier for predicting the optimal moment for a commercial break, define the response variable based on the effectiveness of the ad, such as viewthrough rate or clickthrough rate. Use covariates like the time the ad was shown, ad length, video category, and geographic location. Employ classification models like logistic regression or tree-based algorithms to capture non-linear relationships. Test the model with different ad timings to determine the optimal moment.
14. Describe how you might go about building a fraud detection model for credit card transactions.
To build a fraud detection model, consider using a binary classification model like logistic regression, which handles categorical inputs well. Address the bias-variance tradeoff by balancing model complexity to avoid overfitting or underfitting. Due to class imbalance, where fraudulent transactions are rare, use metrics like the F1 score instead of accuracy to evaluate model performance. Consider techniques like resampling or using ensemble models to handle the imbalance effectively.
In designing a chatbot for Thomson Reuters’ news division, the choice between fine-tuning a large language model (LLM) and using Retrieval-Augmented Generation (RAG) depends on the need for high recency, breadth of sources, and traceability. Fine-tuning allows for adaptation to internal terminology but requires frequent retraining due to the fast-paced nature of news, which is costly and operationally disruptive. RAG, on the other hand, separates the knowledge base from the language model, allowing for dynamic updates and verifiable responses, making it more suitable for environments where accuracy and freshness are critical. A hybrid approach, combining RAG with lightweight fine-tuning, can further enhance the chatbot’s effectiveness by aligning it with editorial standards and improving consistency.
16. Design a secure and user-friendly facial recognition system for employee management
To design a secure and user-friendly facial recognition system, start by defining functional and non-functional requirements, such as registration, time recording, and scalability. Use a pre-trained facial recognition model, a secure database, and integration middleware. Consider using Triple Loss Networks for dynamic user enrollment and CNNs for feature vector generation. Implement a user-facing component for interaction, and ensure the system can scale and handle inactive users efficiently.
17. How to model merchant acquisition in a new market?
To model merchant acquisition in a new market, you would need to analyze market data to identify potential merchants that align with the company’s strategic goals. This involves using predictive analytics to assess merchant potential, considering factors such as market demand, merchant size, and competitive landscape.
18. How would you build a system to detect fraudulent merchant behavior in near-real time?
To build a system for detecting fraudulent merchant behavior in near-real time, implement a monitoring system that tracks transaction patterns, merchant activity, and customer feedback. Use machine learning models to identify anomalies and flag suspicious behavior, ensuring the system can process data quickly to provide timely alerts.
Experimentation & Causal Inference
These questions evaluate your ability to simulate probabilistic events, which are foundational for designing robust experiments and making causal inferences in Shopify’s fast-paced, data-rich environment:
To verify the frequency of incorrect pickup locations, first clarify the definition of “wrong locations” and identify potential causes, such as GPS errors or app software issues. Develop a metric based on the total distance traveled by riders from the driver’s reported arrival to the car, using this as a proxy for incorrect locations. Analyze the data for patterns, such as random GPS errors or driver behavior, to distinguish between true and false positives.
20. Write a function to get a sample from a Bernoulli trial
To generate a sample from a Bernoulli trial, use a random number generator to produce a number between 0 and 1. If the number is less than the probability ( p ), return 1; otherwise, return 0.
21. Design an A/B test to evaluate the impact of a new product recommendation algorithm on conversion rates.
To design this A/B test, randomly assign users to either the control group with the existing algorithm or the experiment group with the new algorithm. Track conversion rates for both groups over a significant period, ensuring the sample size is large enough for statistical significance. Analyze the results to determine if the new algorithm significantly improves conversion rates compared to the existing one.
Behavioral & Leadership Themes
These questions assess how well you embody Shopify’s leadership principles, such as adaptability, humility, and collaborative problem-solving. They help interviewers understand how you navigate feedback, resolve conflict, and contribute to a culture that values ownership and continuous learning:
22. What do you tell an interviewer when they ask you what your strengths and weaknesses are?
Describe a situation where you received constructive criticism, focusing on your openness to feedback and growth mindset. Highlight the steps you took to address the feedback and the positive changes that resulted. Emphasize how this experience has prepared you for Shopify’s culture of continuous improvement.
Outline the context and the differing viewpoints, emphasizing your ability to actively listen and foster collaboration. Describe the strategies you used to build consensus or find a compromise, referencing Shopify’s value of “strong opinions, loosely held.” Reflect on the outcome and what you learned about effective teamwork.
To answer this question, select a project where you went beyond the standard requirements and delivered exceptional results. Describe the specific actions you took to identify opportunities for improvement, the steps you implemented to exceed expectations, and how you measured the impact of your efforts. Quantify your results and relate them to the company’s goals, such as Shopify’s focus on merchant success and innovation.
25. How do you prioritize multiple deadlines?
To prioritize multiple deadlines, assess the urgency and importance of each task, possibly using frameworks like the Eisenhower Box. Communicate clearly with your team about priorities and use tools like project management software to stay organized. Balancing urgent requests with long-term goals requires adaptability and a focus on outcomes, aligning with Shopify’s emphasis on merchant success.
How to Prepare for a Machine Learning Role at Shopify
To prepare effectively for a machine learning role at Shopify, begin by refining your Python and pandas skills. Prioritize vectorized operations instead of loops to write clean and efficient code.
Apply memory optimization by converting data types and using chunked reading for large datasets. Practice by calculating customer lifetime value or detecting GMV anomalies using Shopify’s public storefront data.
Next, focus on deploying end-to-end ML projects. Build APIs using FastAPI and containerize with Docker, since Shopify deploys ML services through Kubernetes. Use Locust to measure latency.
Understand Shopify’s ML stack deeply. Learn how Merlin handles over 2,500 predictions per second using Ray Serve and Pano, their feature store built on Feast. Incorporate recent advancements such as the AI Store Builder that interprets merchant intent with generative models.
In system design, demonstrate how to ingest batch and streaming data into a scalable pipeline. Quantize models for efficiency and implement fallbacks for latency-sensitive inference. Monitor performance using drift tests and AUC decay metrics.
However, to ace the Life Story interview, ensure that you understand Shopify’s Culture, their merchant-first values, and insistence on the AI-first approach. Furthermore, focus on preparing stories in the STAR method to deliver more confident responses during the interviews.
Before appearing for the interview, practice mock interviews and AI interviews to stay ahead of the competition.
FAQs
Is Shopify hiring Applied ML Engineers in 2025?
Yes. Roles such as “Applied ML Engineering, GenAI / AI Agent (Americas)” and “Machine Learning Infrastructure Engineers” are currently open on Shopify’s careers site. However, to find Shopify roles more suitable for you, explore the Interview Query Job Board.
How long is the applied ML take-home?
The expected time commitment is 4 to 6 hours. Candidates should aim to submit a clean, reproducible notebook with a clear README to guide reviewers through their workflow.
Which frameworks should I know?
You should be proficient in Python. Familiarity with PyTorch or TensorFlow is essential for modeling. Knowledge of Kubernetes, particularly for model deployment and inference, is a strong plus.
Do ML Scientists face coding rounds?
Yes. While these coding rounds are less intense than engineering interviews, they still include exploratory data analysis in Python and require familiarity with tools like pandas and NumPy.
How does the interview differ from the Data Scientist track?
ML interviews emphasize model architecture, optimization, and deployment strategies. In contrast, Data Scientist interviews focus more on experimentation, business impact, and metric design, including A/B testing and uplift analysis.
Conclusion
Shopify’s ML interviews reward engineers and scientists who can ship robust models fast and tie them to merchant value. Use this guide and Interview Query’s ML question bank to structure your prep, then iterate like an applied scientist. To garner further confidence, follow Chris Keating’s journey and find revision-worthy topics in our ML Learning Path. All the best!
Shopify Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
Data Structures & Algorithms | Medium | |
Data Structures & Algorithms | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences