
OpenAI Interview Questions & Process Guide (2025)


Introduction
Preparing for OpenAI interview questions means navigating a fast-moving company that sits at the center of AI innovation. The OpenAI interview process is shaped by a deep focus on technical excellence, alignment with safety goals, and the ability to build for a future shaped by AI agents and intelligent tools. You’ll be stepping into a company that in 2025 launched GPT-4o and o4-mini, began testing AI agents in production, and hit $10 billion in revenue—all while expanding to over 3,500 employees. Whether you’re building infrastructure for nearly a billion ChatGPT users or designing tools for autonomous agents, your work can shape how people interact with AI. This guide will help you approach interviews with confidence, clarity, and the context to stand out.
Why Work at OpenAI?
If you’re exploring OpenAI interview questions because you’re thinking seriously about joining, it’s worth knowing just how much OpenAI invests in you, not just your work. You’ll earn top-tier compensation that often surpasses big tech, with annual bonuses and equity through Profit Participation Units. The benefits are equally strong, with full family health coverage, 24 weeks of paid parental leave, daily catered meals, and generous PTO. You also get tools for growth, like a $1,500 annual learning stipend, conference budgets, and professional coaching. With nearly 1 billion ChatGPT users and cutting-edge projects like GPT-5 and AI agents, you’ll work on tech that pushes the boundaries, alongside people who do the same for your career. It’s not just meaningful work. It’s rewarding on every level.
Challenge
Check your skills...
How prepared are you for working at OpenAI?
What’s OpenAI’s Interview Process Like?
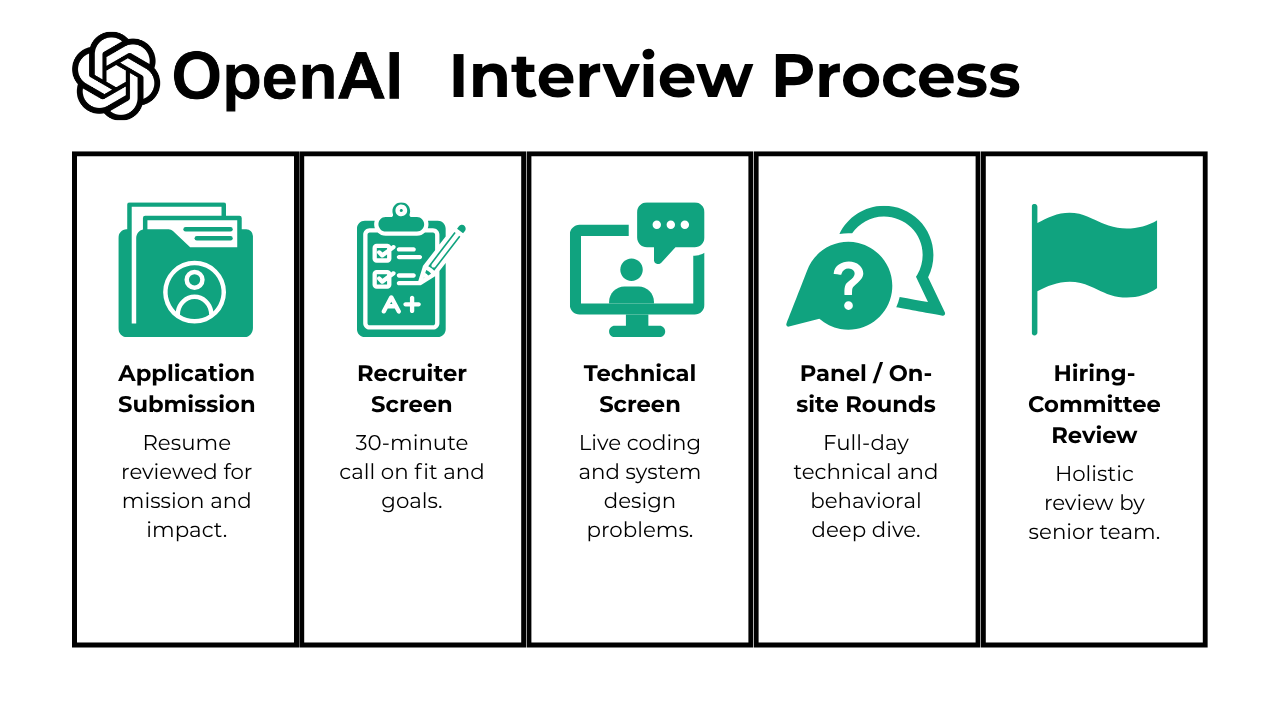
The OpenAI interview process is structured, fast-moving, and deeply focused on both technical excellence and mission alignment. As part of the OpenAI hiring process, candidates move through a series of steps that reflect OpenAI’s collaborative and high-performance culture. The OpenAI interview schedule typically spans two to four weeks and includes multiple rounds designed to evaluate your skills, reasoning, and fit. Here’s what each stage looks like:
- Application Submission
- Recruiter Screen
- Technical Screen (Coding / ML / PM case)
- Panel / On-site Rounds
- Bar-Raiser / Hiring-Committee Review
Application Submission
The OpenAI interview process begins with your application, the first formal step in the OpenAI hiring process and the entry point to your OpenAI interview schedule. This stage is about more than submitting a resume—it’s your first signal of mission alignment and readiness. You’ll apply through OpenAI’s careers page or via referral, and your resume should clearly reflect technical excellence, impact-driven work, and curiosity about AI. Tailor your submission to emphasize relevant projects, cross-functional collaboration, and problem-solving in complex environments. If you’re applying for research or ML roles, include a publication list or project summaries. Applications are screened by recruiters and technical reviewers, often within a few days to a week, and strong candidates move quickly to the recruiter screen.
Recruiter Screen
If you’re searching for insights into the OpenAI interview experience, the recruiter screen is your first official step. This 30 to 45-minute video or phone call is conversational but important. While it’s not technical, you’ll walk through your resume, explain your career journey, and discuss why you’re excited about OpenAI’s mission. With major developments like GPT-4o, AI agents, and industry-specific tools, showing that you’ve done your homework can set you apart. You’ll also talk about team and project preferences and get an overview of the interview process ahead. This is your chance to show motivation, clarity, and enthusiasm. By connecting your background to OpenAI’s real-world impact, you make it easier for the recruiter to picture where you fit next.
Technical Screen
When preparing for OpenAI technical interview questions, you’re getting ready for a screen that mirrors real-world challenges, not just textbook problems. The OpenAI technical interview questions you’ll face are designed to evaluate your coding skills, communication clarity, and engineering judgment in a 45 to 60-minute live coding session. You might implement an LRU cache, solve time-based data structure problems, or design lightweight systems—all while explaining your reasoning. For ML and research roles, expect questions on model architectures, training methods, or recent papers. Your interviewer will care about code quality, scalability, and how well you handle feedback. By focusing on practical, production-level problems and speaking your thoughts clearly, you can show not just that you can code, but that you can build at OpenAI.
Panel / On-site Rounds
As you move into the final stage of the OpenAI interview process, expect a deep dive that combines intense technical sessions with OpenAI behavioral interview questions focused on communication, mission alignment, and teamwork. The panel or onsite round spans 4 to 6 hours over 1 to 2 days, with 4 to 6 different interviewers. You’ll solve coding problems grounded in real engineering work, such as building time-based data structures or architecting scalable systems. You may also present a past project, defend your technical decisions, and discuss ethical questions around AI. This stage is designed to stretch your skills and assess how well you work across functions. If you enjoy solving hard problems and collaborating with brilliant peers, this is where you’ll thrive.
Hiring-Committee Review
After completing all OpenAI interview process steps—the recruiter screen, technical screen, and onsite panel—your application enters the hiring committee review. This final phase is where your entire interview performance is holistically evaluated by a group of senior team members and hiring managers, many of whom weren’t your direct interviewers. Each piece of feedback is weighed against OpenAI’s hiring rubric and benchmarks from past successful candidates. If there are mixed signals, you may be invited for an additional interview. What matters here is not just technical excellence, but also coachability, collaboration, and alignment with OpenAI’s mission. One weaker round can be offset by a standout performance elsewhere. You’ll typically hear back within a week, and if approved, your recruiter will guide you through the offer.
Most Common OpenAI Interview Questions
Most Common OpenAI Interview Questions
This section breaks down the most frequently asked OpenAI interview questions across roles, values, and technical depth, so you can prepare with precision and confidence. For role-specific guides, check out the list below:
Role-Specific Interview Guides
- OpenAI Software Engineer Interview Guide
- OpenAI Data Engineer Interview Guide
- OpenAI Data Scientist Interview Guide
- OpenAI Machine-Learning Engineer Interview Guide
- OpenAI Product Manager Interview Guide
- OpenAI Research Scientist Interview Guide
- OpenAI Data Analyst Interview Guide
Mission & Values Questions
OpenAI behavioral interview questions often center on your alignment with the company’s mission, values, and approach to AI safety, so it’s critical to prepare stories that show your mindset and decision-making:
1. What are your strengths and weaknesses?
At OpenAI, self-awareness and a commitment to growth are essential for building safe and beneficial AI. When discussing your strengths, focus on those that demonstrate your ability to collaborate across disciplines, approach problems with curiosity, and execute with precision. For weaknesses, emphasize areas where you’ve built systems to self-correct or sought feedback to improve, aligning with OpenAI’s values of humility and continuous learning.
2. How comfortable are you presenting your insights?
OpenAI values clarity and transparency, especially when communicating complex research and data. In your response, highlight how you tailor presentations to different audiences, including technical and non-technical stakeholders. Describe how you make your insights accessible and actionable, which reflects OpenAI’s emphasis on shared understanding and knowledge dissemination.
3. Describe an analytics experiment that you designed. How were you able to measure success?
Designing robust experiments speaks to OpenAI’s value of rigorous execution. Explain how you defined a meaningful objective, selected metrics tied to user impact or model performance, and ensured data integrity throughout the process. Framing your success in terms of real-world impact shows alignment with OpenAI’s mission to make AI systems aligned, transparent, and useful to people.
OpenAI thrives on interdisciplinary collaboration, which often means bridging communication gaps. Use this question to show how you adapted your language and approach to build trust and clarity. Reflect on how this experience shaped your ability to foster inclusive collaboration and align diverse perspectives, which supports OpenAI’s goal of building systems that work for everyone.
Technical Depth Questions
Expect OpenAI technical interview questions and OpenAI coding interview questions that reflect real-world engineering and research challenges, emphasizing system design, data fluency, and coding under constraints:
5. Find how much overlapping jobs are costing the company
To estimate the annual cost of overlapping jobs, simulate the scenario by generating random start times for two jobs within a 300-minute window (7 pm to midnight). Check for overlaps between the two jobs and calculate the probability of overlap by averaging the results over multiple simulations. Multiply this probability by 365 days and $1000 to get the annual cost. Alternatively, use probability theory to calculate the overlap probability directly.
6. Find the second longest flight between each pair of cities
To solve this, create a Common Table Expression (CTE) to normalize the source and destination locations, treating (X, Y) and (Y, X) as the same pair. Use ROW_NUMBER() to rank flights by duration for each city pair, and filter for the second longest flight. Finally, order the results by flight ID in ascending order.
7. How would you interpret coefficients of logistic regression for categorical and boolean variables?
For boolean variables, the sign of the coefficient indicates whether the variable has a positive or negative influence on the outcome, while the magnitude reflects the strength of this effect. For categorical variables, one-hot encoding is recommended to avoid implying a ranking structure, and the interpretation of coefficients follows the same guidelines as boolean variables.
The model would not be valid because the removal of decimal points causes some independent variable values to be multiplied by 100, distorting the relationship between the variable and the target label. To fix this, you can visually identify and correct the errors using histograms or apply clustering techniques like expectation maximization to detect and address the anomalies in cases with a large data range.
ChatGPT & Product Impact Questions
These OpenAI ChatGPT interview questions explore how you think about model deployment, user trust, RLHF, and safety, especially as ChatGPT evolves into a workplace and enterprise tool:
9. How would you measure user trust in ChatGPT?
Trust is central to OpenAI’s success. Describe how you would define trust using measurable signals such as user retention, feedback sentiment, and flagging rates. Include how you would design experiments or surveys to capture qualitative insights and validate improvements over time.
10. How do you prioritize product improvements for a model like ChatGPT?
This question probes your ability to balance innovation with user safety. Walk through a framework that considers user feedback, safety risks, technical feasibility, and alignment with OpenAI’s mission. Highlight how you’ve prioritized competing needs in the past while protecting user value.
11. What metrics would you use to evaluate the impact of Reinforcement Learning from Human Feedback (RLHF) on ChatGPT responses?
OpenAI uses RLHF to align models with human intent. Explain how you would track shifts in response helpfulness, safety, and user satisfaction. Include A/B testing, human evaluation pipelines, or any trade-offs you’d consider when analyzing performance across use cases.
12. How would you approach releasing a new ChatGPT capability that introduces novel risks?
This tests your product judgment and awareness of OpenAI’s careful deployment philosophy. Describe how you would assess risk, collaborate with policy and safety teams, and implement rollout mechanisms like staged launches or usage caps to mitigate unintended consequences.
Tips When Preparing for an OpenAI Interview
The OpenAI interview guide and OpenAI interview preparation guide are your starting points for navigating a challenging but rewarding process. OpenAI’s interviews are rigorous, mission-driven, and highly technical, so smart preparation can make a real difference. Here are five key strategies to help you stand out:
Study the Syllabus Thoroughly. Review OpenAI’s blog, research publications, and product releases. Build a solid grasp of fundamentals in coding, system design, machine learning, or ethics, depending on your background.
Pair-Programming Practice. Use mock interviews or collaborative coding platforms to simulate OpenAI’s live technical rounds. Practice thinking aloud and incorporating feedback as you work—these skills reflect strong collaboration and reasoning under pressure.
Write a Research One-Pager. Summarize a recent project or technical achievement in a single page. Prepare to present and defend your decisions, trade-offs, and results. This helps sharpen clarity and depth for both behavioral and technical discussions.
Practice with AI Interviewer. Focus on answering questions about AI alignment, safety trade-offs, and ethical considerations. These show mission awareness and critical thinking, even in roles not directly tied to alignment.
Plan Mission-Fit Stories. Prepare specific stories using the STAR method to explain how your work aligns with OpenAI’s values. Highlight moments of collaboration, problem-solving, or learning from failure—these themes appear often in OpenAI’s behavioral interviews.
With a clear structure, thoughtful preparation, and a strong sense of purpose, you’ll enter the process confident and ready to contribute.
Salaries at OpenAI
Average Base Salary
Average Total Compensation
Conclusion
Mastering the OpenAI interview process and practicing real OpenAI interview questions gives you a clear edge in one of the most competitive hiring environments in tech. Whether you’re just starting to prepare or nearing the final rounds, every step offers an opportunity to showcase your impact, your curiosity, and your alignment with OpenAI’s mission. If you want to see how others have succeeded, read Keerthan Reddy’s success story. For step-by-step learning and practice, follow our full Data Structure and Algorithm Learning Path. And when you’re ready to dive into real prompts, explore our complete OpenAI behavioral interview questions collection. With the right preparation, you’re not just applying—you’re building the future alongside the people shaping it.
FAQs
What’s the typical OpenAI interview schedule?
The OpenAI interview schedule usually spans three to four weeks. After your application is reviewed, you’ll enter the recruiter screen stage, which often takes about two weeks. This is followed by one week of technical interviews, and then a final panel or onsite round. Offers or next steps typically follow within a week of completing the loop.
How long does OpenAI take to respond after final interview?
OpenAI’s interview process response time is typically within 5 to 7 business days after your final panel. In some cases, decisions may take slightly longer depending on the volume of candidates or if additional rounds are being considered. Your recruiter will keep you updated throughout.
What steps are in the OpenAI hiring process?
The OpenAI interview process steps include five main phases: application submission, recruiter screen, technical screen (or take-home), panel or onsite interviews, and a final hiring committee review. Some roles may include additional steps like project presentations or follow-up interviews for clarification.
What is the overall OpenAI interview experience like?
The OpenAI interview experience is known for being intellectually rigorous but respectful and well-structured. Candidates often describe the culture as mission-driven, thoughtful, and fast-paced, with interviewers who are deeply technical and genuinely collaborative.
Does OpenAI ask surprise or abstract questions?
OpenAI questions tend to focus on deep reasoning, real-world problem-solving, and mission alignment—not trick questions or puzzles. You may face open-ended or philosophical prompts, especially in alignment or research roles, but they are designed to explore how you think, not to trip you up.
Discussion & Interview Experiences