
OpenAI Research Scientist Interview Guide: Process, Questions, and Tips


Introduction
If you’re preparing for an OpenAI research scientist interview, you’re stepping into one of the most influential roles shaping AI in 2025. OpenAI is scaling rapidly, with projected revenues of $12.7 billion and ambitions to reach a billion users. Research scientists here drive this momentum by building next-gen models like o3 and o4-mini, advancing agentic systems like Deep Research and Operator, and designing frameworks for automated scientific discovery. You’ll contribute to high-impact domains from rare disease diagnostics to AI-led hypothesis generation, all while reinforcing safety protocols for AGI. Whether you’re optimizing model efficiency or exploring emotional intelligence in ChatGPT-4o, your work directly advances OpenAI’s mission and helps transition AI from passive tools to active collaborators.
Role Overview & Culture
When preparing for OpenAI research scientist interview questions, it’s important to understand the dynamic and high-impact role you’re stepping into. As a research scientist, you’ll drive cutting-edge work across large-scale language models, reinforcement learning, and AI safety, while using tools like PyTorch, CUDA, and Python daily. You’ll collaborate with top-tier engineers and scientists, mentor residents, and translate research breakthroughs into APIs and real-world tools. The culture rewards deep curiosity, bold experimentation, and constant learning, all anchored in OpenAI’s mission to ensure AGI benefits humanity. While the pace is intense, leadership is supportive, and you’ll be part of a diverse, mission-driven team that values your voice as much as your scientific rigor.
Why This Role at OpenAI?
If you’re exploring OpenAI research scientist interview questions, it’s worth knowing just how much this role can accelerate your personal and professional goals. You’ll earn top-tier compensation—often $200K to $300K+—with equity and profit-sharing tied to OpenAI’s rapid growth, including its projected $12.7B revenue in 2025. You’ll have the freedom to own your research direction, access cutting-edge computing, and collaborate with elite scientists, all while building a CV that commands attention across tech and academia. The environment is flexible and deeply supportive, designed to maximize both impact and well-being. Whether you’re chasing technical breakthroughs or long-term career leverage, this role positions you to thrive at the center of AGI innovation.
What Is the Interview Process Like for a Research Scientist Role at OpenAI?
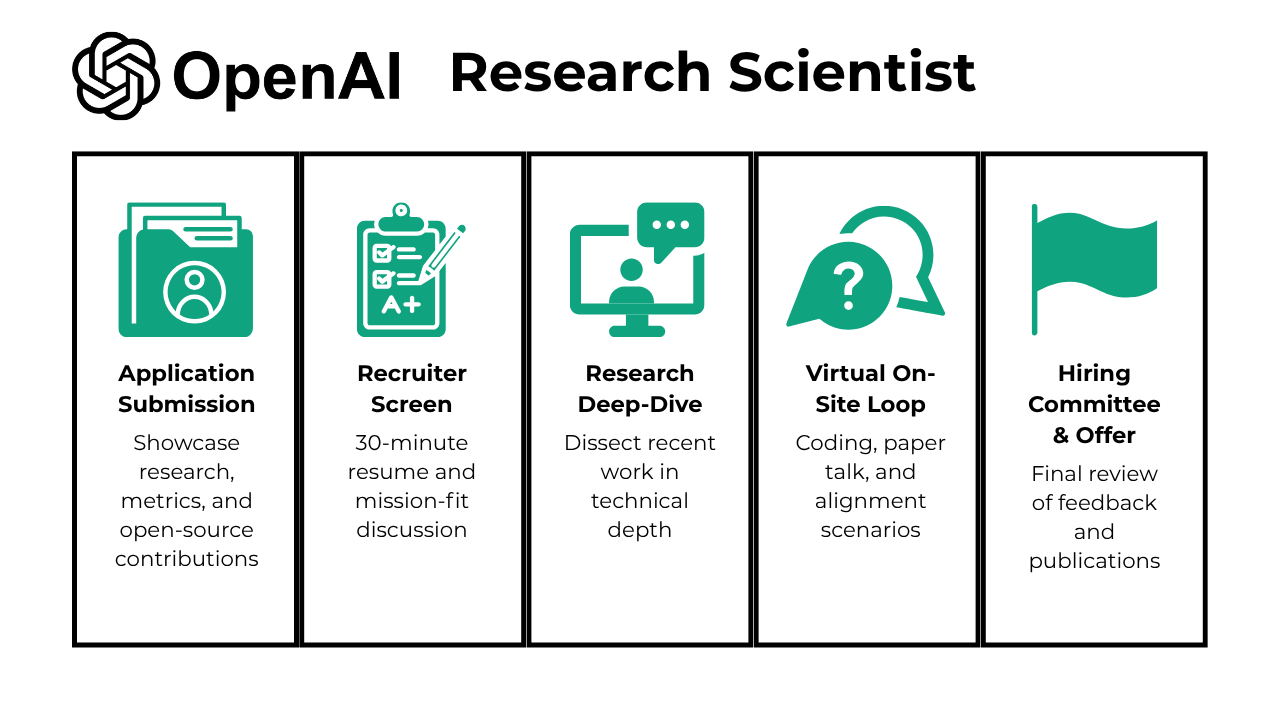
The interview process for a research scientist role at OpenAI is structured to assess your research depth, technical fluency, and alignment with the company’s mission. Here’s a breakdown of what you can expect at each stage:
- Application Submission
- Recruiter Screen
- Research Deep-Dive
- Virtual On-Site Loop
- Hiring Committee & Offer
Application Submission
You start by tailoring your resume and cover letter to highlight your deep learning projects, peer-reviewed publications, and alignment research. OpenAI’s hiring team reviews applications weekly and aims to respond within seven days, so ensure your research contributions and collaborations are front and center. By showcasing reproducible experiments and open-source code—especially on high-impact topics like reinforcement learning efficiency or alignment metrics—you dramatically improve your odds of securing that recruiter call. Emphasize quantitative results, such as improvements in sample efficiency or reduction in model biases, to help your application stand out against the 2,000+ monthly submissions OpenAI receives for research roles.
Recruiter Screen
In your 30-minute recruiter conversation, you’ll explore your resume details and discuss how your expertise aligns with OpenAI’s mission to build safe AGI for humanity. You should be prepared to explain your most significant projects and why you chose specific architectures or training regimes, citing metrics—like achieving 15% higher downstream accuracy on a novel dataset—to illustrate impact. The recruiter will also cover basic behavioral questions and logistics, so this friendly chat offers an opportunity to express your passion for interdisciplinary collaboration and mission-driven research. Clear communication here often translates into a 60% chance of advancing to the next technical stage.
Research Deep-Dive
The OpenAI research scientist interview process begins with a Research Deep-Dive that puts you at the center of rigorous technical discussion in the first 40 words. You’ll engage in a 45-minute virtual session dissecting your recent work: be ready to derive key equations on the spot, critique method limitations, and propose follow-on experiments that could boost performance by 10–20%. Interviewers probe your understanding of probabilistic modeling, optimization algorithms, and large-scale training heuristics. Your success hinges on demonstrating both breadth—linking your work to industry trends like multimodal reasoning—and depth, such as detailing how you tuned gradient clipping to stabilize training at scale.
Virtual On-Site Loop
When you arrive for your virtual on-site loop, expect four to six hours of back-to-back sessions over one or two days. You’ll kick off with a 20-minute paper presentation where you succinctly walk through hypothesis, methodology, and results, fielding questions from five to eight researchers. Next, you’ll tackle coding challenges in NumPy and PyTorch—debugging a faulty transformer layer and implementing batching optimizations under time constraints. Alignment Q&A assesses your approach to controlling unintended model behaviors, while behavioral interviews probe examples of cross-team collaboration. By the end, you’ll have demonstrated both your technical mastery and your ability to communicate complex ideas.
Hiring Committee & Offer
After your on-site, a cross-functional hiring committee convenes to review detailed written feedback, safety review notes, and publication records. This rigorous behind-the-scenes process ensures your alignment with OpenAI’s values—responsibility, transparency, and scientific excellence. The committee typically meets within one week of your on-site interviews and decides within two weeks. When they conclude you’re the right fit, you’ll receive an offer package featuring a competitive base salary, equity, and benefits designed to reward your long-term contributions. Now let’s dive into the exact OpenAI research scientist interview questions you’re likely to face.
Challenge
Check your skills...
How prepared are you for working as a AI Research Scientist at OpenAI?
What Questions Are Asked in an OpenAI Research Scientist Interview?
OpenAI research scientist interview questions are designed to evaluate how well you blend theoretical rigor, hands-on coding skills, and alignment reasoning to solve real-world, frontier-level AI challenges.
Coding / Technical Questions
You’ll face coding prompts that test your debugging intuition, mathematical reasoning, and fluency in frameworks like PyTorch—often under time pressure and with high-performance expectations:
To solve this problem in (O(n)) time, use a dictionary to store the indices of numbers as you iterate through the array. For each number, calculate its complement (target minus the current number) and check if the complement exists in the dictionary. If it does, return the indices; otherwise, add the current number and its index to the dictionary.
To solve this, iterate through the grid following the unlocked doors. Mark visited rooms to avoid revisiting them and check for out-of-bound or revisited conditions. If the southeast corner is reached, return the step count; otherwise, return -1 if no valid path exists.
3. Write a function to get a sample from a Bernoulli trial.
To solve this, use the random.choices method in Python to generate a random sample. Assign weights [p, 1-p] to the outcomes 1 and 0 respectively, ensuring that 1 is returned with probability p and 0 with probability 1-p.
To solve this, create a dictionary to map user IDs to their cumulative tips using collections.Counter. Iterate through the lists to populate the dictionary, then use the most_common() method to identify the user with the highest tips.
To solve this, iterate through all possible values of x and y in the range [0, N) using nested loops. For each pair (x, y), calculate f(x, y) and check if it lies within [L, R]. If it does, add the pair (x, y) to the results list and return the final list.
6. Given a list of numbers, write a function to find the moving window average
To solve this, use two pointers to track the beginning and end of the window. Maintain a running sum of the window’s elements, and as the window moves, subtract the element that is exiting the window and add the new element entering the window. Divide the sum by the window size to compute the average and append it to the output list.
Research & Theory Questions
Expect open-ended technical questions that assess your depth in areas like RLHF, transformer efficiency, and information theory, often with derivations or design trade-off analysis:
7. Show how the objective used in Reinforcement Learning from Human Feedback (RLHF) can be derived both (a) as KL-regularised reinforcement learning and (b) as variational (Bayesian) inference, then explain the practical trade-offs introduced by the KL term.
In RLHF, we start from the standard reinforcement learning objective, which maximises the expected reward predicted by a learned model. To ensure the fine-tuned policy stays close to the supervised model, we introduce a KL divergence penalty, resulting in a KL-regularised objective. This same expression can be reinterpreted as the evidence lower bound (ELBO) in variational inference, where the KL acts as a regulariser on the posterior over policies. The KL coefficient β controls trade-offs: smaller values preserve alignment and training stability but may underutilise feedback, while larger values improve reward exploitation at the cost of potential overfitting or instability.
8. Compare sparse-expert (e.g., Switch Transformer / Mixture-of-Experts) blocks with standard dense transformer blocks in terms of computational complexity, parameter efficiency, optimization difficulty and downstream performance.
Dense transformers activate all parameters per token, which scales quadratically with sequence length and linearly with layer size. In contrast, sparse-expert models route each token to only a few experts, keeping compute per token nearly constant even as total parameters grow. This enables highly parameter-efficient scaling, though it introduces optimisation issues such as expert imbalance, routing instability and gradient sparsity. While sparse models often outperform dense ones under matched FLOPs, they can lag in tasks that require all parameters to interact densely, and they require careful tuning and auxiliary losses to train effectively.
9. Derive the computational complexity of self-attention in transformers and explain why it becomes prohibitive for long sequences. Then, propose and analyze two different approaches to address this limitation, discussing their trade-offs in terms of computational efficiency, memory usage, and model expressiveness.
Self-attention computes pairwise interactions across a sequence, resulting in O(n²d) complexity due to the dot-product, softmax, and value-weighting steps. This becomes costly for long sequences because memory and computation scale quadratically. Linear attention methods reduce this to O(nd²) by low-rank projection but lose some expressiveness, while sparse attention patterns like in Longformer cut it to O(nwd), preserving local structure at the cost of full global context.
10. Explain the Information Bottleneck principle and its application to understanding deep neural networks. Derive the variational bound used in practice, then discuss the controversy around Tishby’s claims about compression during training and what recent empirical evidence suggests about information flow in DNNs.
The Information Bottleneck objective encourages representations that retain information about the target while discarding irrelevant input details, using I(Y;T) − βI(X;T). Variational bounds approximate these mutual information terms using learned distributions, enabling tractable training. While Tishby claimed neural networks compress input information over time, recent studies show this may only occur with specific activations and that sharpening, not compression, may better explain training dynamics.
Behavioral & Alignment Questions
Interviewers want to understand how you navigate complex communication, collaborate across disciplines, and reason through ethical choices in alignment-sensitive AI development:
As an OpenAI research scientist, you may need to communicate nuanced technical work to policy leads, product teams, or external partners. You should describe a situation where the depth or complexity of your research created a communication gap. Explain how you adjusted—for example, by simplifying technical language, using analogies, or incorporating visual tools—and reflect on how this experience helped you refine your communication strategy in cross-functional or high-impact environments.
12. What are some effective ways to make data more accessible to non-technical people?
In an OpenAI setting, bridging the gap between ML research and real-world understanding is critical, especially in areas like AI safety or societal impacts. Mention approaches such as designing clear visualizations for model behavior, creating internal writeups or explainer docs, or using simple examples to clarify complex methods. Emphasize how accessibility fosters better alignment across teams, more informed decision-making, and public trust in advanced systems.
13. Why Do You Want to Work With Us
This is your opportunity to show alignment with OpenAI’s mission to ensure AGI benefits all of humanity. Speak to how your research interests connect with OpenAI’s core challenges—such as alignment, interpretability, or scalable oversight. You can also reference OpenAI’s collaborative research culture, open publications, or a particular paper or model that inspired you to contribute your skills to this community.
14. How would you convey insights and the methods you use to a non-technical audience?
Given OpenAI’s interdisciplinary context, you may often present your work to people without a deep ML background. Start by identifying the audience’s goals—such as safety assurance or user experience—and tailor your explanation to meet their perspective. Use intuitive analogies (like “learning from feedback” rather than “policy gradients”), and highlight trade-offs or risks in a transparent, responsible manner that supports OpenAI’s values around safety and alignment.
How to Prepare for a Research Scientist Role at OpenAI
Preparing for a research scientist role at OpenAI means demonstrating both deep technical insight and practical research fluency. One of the best ways to start is by revisiting your own published work. Expect deep questions—not just about what you did, but why it mattered, how you’d improve it today, and where it falls short under OpenAI-scale deployment. You’ll likely be challenged to critique your assumptions and explain design choices across both theory and implementation.
Hands-on rigor matters just as much. You should be able to reproduce results from recent transformer papers or alignment studies, ideally in PyTorch. Show that you can debug large-scale training pipelines, evaluate trade-offs, and propose improvements.
To mirror the real interview cadence, run mock presentations with peers, allotting yourself fifteen minutes for a slide deck and fifteen for probing questions, simulating the four to six hours of intense on-site loops that open doors at OpenAI.
Staying current with alignment literature is critical, especially frameworks like Eliciting Latent Knowledge (ELK), constitutional AI, or reward modeling with KL penalties. Your interviewers will want to know how you reason about AI behavior, safety, and control under uncertainty. Finally, expect technical exercises that blend theory and implementation. You may be asked to live-code a basic RL algorithm or derive a bound from information theory or variational inference.
The goal isn’t perfection—it’s demonstrating curiosity, rigor, and the ability to think clearly under pressure. At OpenAI, that mindset matters as much as your publication record.
Conclusion
Landing the role starts with mastering each stage of the OpenAI research scientist interview—from your recruiter screen to the on-site technical deep dives. The key is to prepare with intent: sharpen your math and coding fluency, rehearse research presentations, and stay current on alignment literature. Explore our full collection of OpenAI research scientist interview questions to get a sense of what’s asked. If you’re earlier in your journey, follow our Python learning path for aspiring AI researchers. For motivation, read Dania’s success story, who turned prep into a job offer. You’ve got this.
OpenAI Research Scientist Jobs
OpenAI Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Behavioral | Medium | |
Tell me about a data project that didn’t go the way you expected. What did you set out to do, what surprised you, and how did you handle it? | ||
AI & Agentic Systems | Medium | |
A/B Testing | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences