
JP Morgan Interview Questions & Process (2025 Guide)


Introduction
Despite uncertain market dynamics and threats of industry-wide job cuts, JP Morgan had 14,000 open positions as of early 2025, driven by its strong 9% year-over-year (YoY) growth in net income and 8% YoY growth in total revenue this year. This growth and demand for talent have naturally heightened competition, setting the tone for the JP Morgan interview questions in 2025.
With its significant investments in technology and being the largest bank in the US, JPMorgan Chase offers substantial perks to its employees working in engineering, marketing, data, and AI or machine learning roles. For the curious in you, here is why you should consider working at JPM:
Why Work at JP Morgan?
Not only is JPMorgan Chase the largest bank in the US, but it is also the largest in the world by market capitalization. It serves over 82 million customers across 100 countries and continues to lead in rapid technological innovation through advanced AI maturity. It is also recognized on the “Fortune 100 Best Companies to Work For” list, so as an employee, you are exposed to prestige, global reach, and career mobility that stands out in the financial sector. They also offer structured analyst and associate programs to help employees explore diverse roles and accelerate their careers.
Furthermore, diversity, equity, and inclusion shape the core of JPMorgan Chase’s identity, supported by vibrant employee networks for underrepresented groups, women, veterans, and others. As an employee, your commitment to philanthropy is empowered through initiatives such as “Force for Good” and “Tech for Social Good.” To take advantage of these opportunities, it is important to understand the interview process and prepare accordingly.
Challenge
Check your skills...
How prepared are you for working at Jpmorgan Chase & Co.?
What Is JP Morgan’s Interview Process Like?
The JP Morgan interview process typically follows a structured timeline with some variation depending on the role and location. Here is a quick cheat sheet to help you prepare:
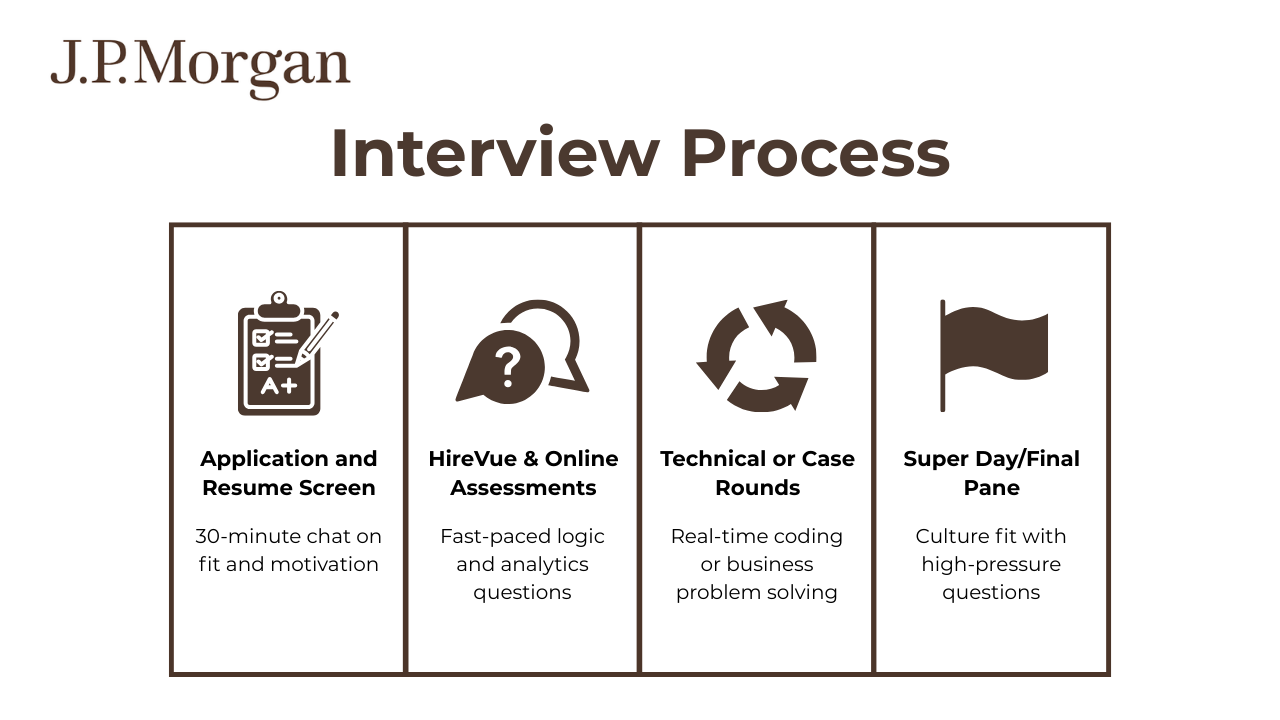
Online Application & Resume Screen
The JP Morgan interview processes typically begin with you submitting your resume via the JPM career portal, though campus drives and referrals are also common. If you are a student trying to get into the program, you can apply to up to three roles, so choose carefully.
For others, your application status may read “under consideration,” “in progress,” or similar, depending on the stage it is in. It is also common to be rejected for not including proper keywords on the resume, often after weeks of seeing “in progress.”
If your resume is accepted, a recruiter screen through HireVue will follow. In some cases, an online assessment round may also be part of your process.
HireVue & Online Assessments
The HireVue video interview round, and sometimes an additional Pymetrics round, usually involves 2–5 questions with 30–120 seconds prep time and 1–2 minutes to record your answer. These rounds typically focus on your behavioral skills and psychometric evaluations, but for investment banking and technical tracks, technical questions may also appear. Be prepared to answer questions probing into your motivation, background, and ethics.
During the online assessment round, you will be asked 2–3 coding questions if applying for a technical role, spanning 60–90 minutes total. It could involve medium to hard SQL, Python, and data structure questions, but may also delve deeper into test-driven development and complex system design problems.
Technical / Case-Study Rounds
If you successfully navigate the online assessment, you will typically encounter one to two rounds of technical interviews, each lasting about 40 to 45 minutes. Expect a mix of live coding, questions about your role fundamentals, and resume-based deep dives.
Difficulty varies by interviewer and role. Roughly, medium to hard coding questions are asked, with more emphasis on real-world scenarios and your resume-specific abilities. For experienced candidates and roles, expect design questions on building scalable systems, load balancing, caching, and database optimization.
Super Day / Final Panel
This is the high-stakes final interview round for JP Morgan. While the Super Day is especially common for investment, corporate, and commercial banking operation roles, it has also become more prevalent in tech roles in 2025 due to AI-driven competitiveness.
It typically consists of 2–5 back-to-back interviews with different interviewers, each lasting about 30–35 minutes, revolving around case studies, networking sessions, behavioral rounds, and financial questions. Expect to dedicate a whole day if you are invited to the JPM campus. In virtual settings, the loop usually takes a single day as well.
The interview rounds are intense by design. Expect fast-paced discussion on your resume, technical skills, and cultural fit. You may meet your hiring manager, senior team members, potential peers, VPs, and directors throughout the day. Once you understand the structure, the next step is to review the types of questions you are most likely to encounter.
Most Common JP Morgan Interview Questions
JP Morgan interview questions vary by role, but they often share core themes around behavioral competencies, technical expertise, and problem-solving ability.
Role-specific interview guides
- Software Engineer → JP Morgan Software Engineer Interview Guide (2025)
- Data Engineer → JPMorgan Chase & Co. Data Engineer Interview Questions + Guide in 2025
- Data Analyst → J.P. Morgan Chase & Co. Data Analyst Interview Questions + Guide in 2025
- Business Analyst → J.P. Morgan Chase & Co. Business Analyst Interview Questions + Guide in 2025
- Data Scientist → JPMorgan Chase & Co. Data Scientist Interview Questions + Guide in 2025
- Machine Learning Engineer → JPMorgan Chase Machine Learning Engineer Interview Questions + Guide in 2025
- Product Manager → JP Morgan Product Manager Interview Guide in 2025
Tips When Preparing for a JP Morgan Interview
Navigating the JP Morgan interview process can be a demanding experience, requiring a specific and multi-faceted preparation strategy.
Research the business lines
Start by researching the firm’s core lines of business, such as the Corporate & Investment Bank (CIB), Asset & Wealth Management (AWM), or Consumer & Community Banking. Clearly articulate how your personal story and ambitions align with a specific division.
Sharpen domain-specific fundamentals
Depending on the role, this could mean mastering data structures and algorithms for a software engineering position, understanding financial regulations like Basel III for a compliance role, or practicing advanced SQL for a data analytics interview.
Practice behavioral responses with STAR
For the ubiquitous behavioral questions, which often start with an automated HireVue assessment, practice concise and structured answers using the STAR method. Aim for responses under 90 seconds. Simulating these with AI interviews will help you refine your delivery and manage pressure effectively.
Mock interview for better preparation
Prepare to close with a compelling and well-researched answer to “Why JP Morgan?” through mock interviews. These sessions will help you demonstrate a genuine understanding of the firm’s market position, technological innovations, and global impact, setting you apart from other candidates.
Salaries at JP Morgan
Most data science positions fall under different position titles depending on the actual role.
From the graph we can see that on average the ML Engineer role pays the most with a $142,188 base salary while the Product Analyst role on average pays the least with a $84,875 base salary.
Conclusion
Understanding the JP Morgan interview process and preparing for common JP Morgan interview questions is the most effective way to secure an offer. Explore the role-specific guides and Interview Query’s practice sets to prepare with precision.
Still overwhelmed about the preparation? Begin with the basic data science case study questions, and explore the beginner Python learning path. If you need more confidence, check Jayandra Lade’s success story. All the best!
FAQs
What does JP Morgan look for in interviews?
JP Morgan interviews focus heavily on behavioral traits like integrity, teamwork, and adaptability. Candidates should use real examples that show leadership, ownership, and alignment with the company’s values.
Is the JP Morgan interview process hard?
Yes, the process is competitive but fair. Many candidates find the interview process challenging due to its multi-stage format. Focused preparation makes a significant difference.
How many rounds are there for analysts?
Analyst roles often involve 3 to 5 rounds, ending with a Super Day. Review our guide on JP Morgan analyst interview questions for more details.
Do all roles use HireVue?
Most early-career and internship roles include a HireVue round, but it is not universal. Mid- and senior-level roles may skip this step and begin with recruiter or technical screens.
Discussion & Interview Experiences