
Garner Health Data Engineer Interview Questions + Guide in 2025


Overview
Garner Health is a fast-growing health technology company focused on helping patients make better care decisions through data-driven insights. By combining clinical expertise with modern analytics, Garner partners with employers and health plans to guide members toward high-quality providers and lower-cost care. As healthcare organizations increasingly rely on large, complex datasets to improve outcomes, Garner’s data platform plays a central role in turning raw claims, provider, and member data into actionable intelligence.
The data engineer role at Garner Health sits at the core of this effort. Data engineers design, build, and maintain the pipelines that power analytics, reporting, and downstream decision-making across the company. You can expect to work closely with data analysts, data scientists, product managers, and clinical teams to ensure data is reliable, well-modeled, and accessible at scale. This role blends strong engineering fundamentals with an understanding of how data supports real-world healthcare decisions.
The Garner Health data engineer interview is designed to evaluate more than technical ability alone. Candidates are assessed on their experience with data pipelines and tooling, their ability to communicate clearly with cross-functional partners, and their alignment with Garner’s mission-driven culture and values.
Garner Health Data Engineer Interview Process
The Garner Health data engineer interview process is structured to evaluate technical depth, problem-solving approach, and alignment with the company’s mission-driven culture. While timelines can vary by level and team, candidates typically move through a multi-stage process that combines practical data engineering work with collaborative and behavioral evaluation. Based on verified candidate experiences, the process emphasizes real-world data challenges rather than abstract puzzles.
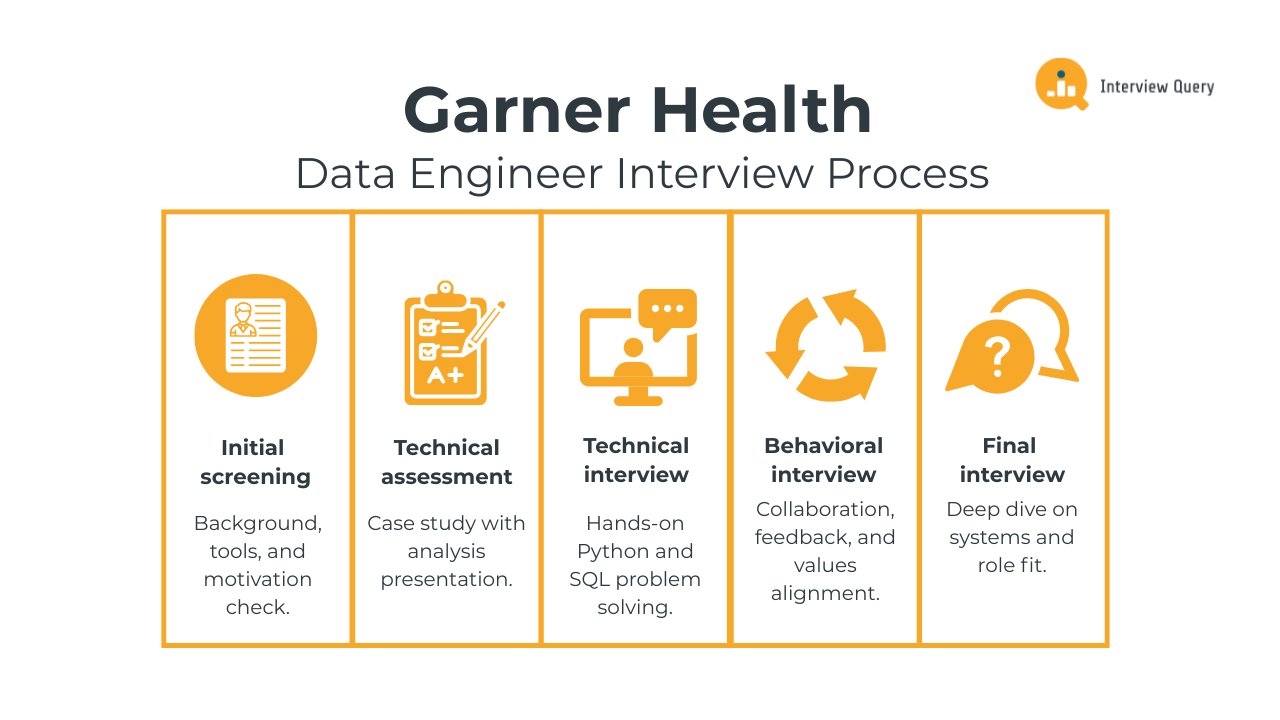
Initial screening
The process usually begins with a recruiter phone or video screen. This conversation focuses on your background, recent data engineering work, and motivation for joining Garner Health. Recruiters also assess baseline fit for the role, including experience with Python, SQL, and modern data tooling. You should be prepared to clearly explain your past projects and how they connect to healthcare or analytics-driven products.
Technical assessment
Candidates who pass the initial screen are often given a technical case study. This stage typically involves analyzing a data problem and presenting findings through a short slide deck. The goal is to evaluate how you structure ambiguous problems, apply statistics or analytical reasoning, and communicate insights clearly to both technical and non-technical stakeholders. Several candidates report that this round mirrors the kind of analysis expected on the job.
Technical interview
Next, you can expect one or more technical interviews focused on hands-on data engineering skills. These interviews commonly include Python and SQL exercises, such as data parsing, file handling, query optimization, or building simple pipeline logic. Interviewers look for clean, readable code, strong fundamentals, and the ability to explain your reasoning step by step.
Behavioral interview
Garner Health places significant weight on culture and collaboration. Behavioral interviews focus on how you work with cross-functional partners, handle feedback, and navigate trade-offs or conflict. Questions are often grounded in real workplace scenarios and are used to assess alignment with Garner Health’s values and team norms.
Final interview
The final stage typically involves a hiring manager or senior team member. This conversation dives deeper into your experience, architectural decision-making, and long-term fit. You may be asked to walk through an end-to-end system you have designed or discuss how you would approach data challenges at Garner Health specifically.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Garner health?
Garner Health Data Engineer Interview Questions
Garner Health data engineer interviews use structured, role-relevant questions to evaluate how you design data systems, collaborate across teams, and align with a mission-driven healthcare organization. Below are common question types you should expect, along with guidance on how to approach each one effectively.
SQL and Python Interview Questions
SQL and Python questions in the Garner Health data engineer interview focus on your ability to manipulate, validate, and transform large healthcare datasets with precision. These problems test whether you can write efficient queries and production-ready Python logic that support reliable analytics and downstream decision-making.
Identify and Return Duplicate Rows in a Table
At its core, this tests your ability to detect duplicate records using SQL aggregation and filtering, a foundational data quality skill. For a data engineer at Garner Health, this matters because duplicate clinical, claims, or eligibility records can cascade into inaccurate analytics and flawed healthcare decisions if not handled correctly in pipelines.
Input:
userstableColumn Type idINTEGER nameVARCHAR created_atDATETIME Determine the Result Size of Different SQL Join Types
This evaluates how well you understand the impact of different SQL joins on row counts and data integrity. Garner Health asks this to ensure data engineers can safely combine complex healthcare datasets, where a misunderstanding of join behavior can quietly distort metrics used for care optimization and cost analysis.
Calculate Each Year’s Percentage Contribution to Total Revenue
The focus here is on aggregating time-based data and computing relative metrics using SQL. For Garner Health’s data engineering role, this reflects the expectation that you can build dependable transformations that support financial and operational reporting consumed by internal teams.
Generate Monthly Product Sales as Columns
This checks your ability to reshape raw transactional data into structured, analytics-ready outputs. At Garner Health, data engineers are expected to design transformations that make downstream analysis and dashboarding straightforward, especially when summarizing performance across time and product dimensions.
Select a Random Sample Row from a Large SQL Table
Here, the emphasis is on selecting representative samples efficiently from large tables without harming performance. Garner Health uses this to assess whether you can validate and debug large-scale healthcare data pipelines in a practical way, where efficiency and correctness both matter.
Input:
big_tabletableColumns Type idINTEGER nameVARCHAR
Data Pipelines & ETL Interview Questions
Garner Health data pipeline and ETL interview questions evaluate how you design resilient, scalable systems for ingesting and transforming healthcare data. Interviewers look for structured thinking around reliability, data quality, and failure recovery in production-grade pipelines.
Design a Resumable Fact Table Load Process
This prompt examines your ability to design a robust ETL pipeline that can resume loading after partial failures without creating duplicates or losing data. At Garner Health, data engineers must build reliable, resumable workflows for large clinical and claims fact tables where interruptions are common and data integrity is critical.
flowchart TD A[Start Load Job] --> B{Fetch Next Batch} B -->|Batch Exists| C[Begin DB Transaction] C --> D[Insert Records with Upsert] D --> E[Commit Transaction] E --> F[Update Checkpoint] F --> B B -->|No More Batches| G[Reconciliation & Validation] G --> H[End] C -->|Failure| I[Rollback Transaction] I --> FHow Would You Address and Improve Data Quality Issues
This question tests your approach to identifying, prioritizing, and systematically improving data quality problems like missing fields and duplicates. Interviewers at Garner Health ask this to understand how you would ensure clean and trustworthy healthcare data that downstream analytics and care decisions depend on.
How Would You Ensure Data Pipelines Scale as Volume Grows
This prompt evaluates your ability to design or adapt data pipelines that remain scalable and reliable as data throughput increases significantly. For a data engineer at Garner Health, demonstrating that you can anticipate growth and build scalable pipelines is essential to support expanding patient, claims, and operational datasets.
Architect an End-to-End CSV Ingestion Pipeline
This question assesses your ability to design a full ingestion system that handles large CSV uploads, including parsing, validation, storage, and query readiness. Garner Health asks this to see if you can build infrastructure that reliably ingests diverse data feeds (e.g., partner exports, survey data) into analytical platforms.
Diagnose and Resolve Pipeline Transformation Failures
This prompt tests your systematic problem-solving skills for identifying root causes of recurring data pipeline transformation failures. At Garner Health, data engineers need to ensure uninterrupted data flows for dashboards and reporting, so interviewers look for structured diagnostic thinking and operational troubleshooting ability.
Data Structures and Algorithms Interview Questions
Data structures and algorithms questions assess your ability to reason about performance, memory constraints, and streaming data at scale. For data engineers at Garner Health, these problems reflect real-world challenges involved in processing large clinical and operational datasets efficiently.
Find the Top N Most Frequent Words in a Text
This question fundamentally tests your ability to process unstructured data and compute frequency-based aggregates efficiently. Garner Health asks this for data engineers to assess whether you can build scalable preprocessing logic for clinical notes, claims descriptions, or other healthcare text inputs that feed downstream analytics.
Input:
posting = """ Herbal sauna uses the healing properties of herbs in combination with distilled water. The water evaporates and distributes the effect of the herbs throughout the room. A visit to the herbal sauna can cause real miracles, especially for colds. """ n = 3Output:
n_frequent_words(posting,N) = [ ('the', 6), ('herbal', 2), ('sauna', 2), ]How Would You Sort a Dataset Larger Than Available Memory
This question evaluates your understanding of external sorting and designing algorithms that operate under strict memory constraints. For a data engineer at Garner Health, this reflects the real need to handle very large healthcare datasets where thoughtful system-level design matters more than in-memory tricks.
Merge N Sorted Lists into One Sorted Output
This question tests your grasp of merging ordered data efficiently while preserving global sort order. Interviewers at Garner Health use this to see if you can reason about combining partitioned or pre-sorted data streams in ETL pipelines without introducing performance bottlenecks.
Maintain the Median of a Continuously Updating Data Stream
This question is fundamentally about maintaining real-time aggregates over streaming data using appropriate data structures. Garner Health asks this to evaluate whether you can support streaming metrics and monitoring use cases where healthcare signals must be summarized accurately as data arrives.
Detect Whether a Data Structure Contains a Cycle
This question assesses your understanding of traversal logic and identifying cycles in pointer-based or graph-like structures. For Garner Health’s data engineering role, it signals whether you can reason about data flow, prevent infinite processing loops, and maintain integrity in pipeline or stream-processing systems.
Behavioral Interview Questions
Behavioral questions in the Garner Health data engineer interview focus on communication, collaboration, and mission alignment. These prompts help interviewers understand how you work with cross-functional healthcare teams and translate technical data work into trusted, real-world impact.
Describe a Time You Had Trouble Communicating With Stakeholders
This behavioral prompt examines how effectively you navigate communication challenges with cross-functional partners, focusing on clarity, conflict resolution, and alignment. Garner Health asks this of data engineers to ensure you can bridge technical data work with healthcare stakeholders (analysts, clinical teams, product) so data pipelines and insights are trusted and actionable.
Explain How You Convey Insights and Methods to a Non-Technical Audience
This question tests your ability to translate complex technical findings into simple, understandable language for audiences without a technical background. At Garner Health, data engineers must collaborate with clinicians, care managers, and business leaders, so interviewers use this prompt to gauge your clarity in communicating data logic and results broadly.
Outline How You Would Prepare a Model for Production Deployment and Monitor It
This prompt evaluates your understanding of the end-to-end lifecycle of a predictive model: from production readiness to monitoring and performance validation. For a data engineer at Garner Health, this shows whether you can operationalize analytical models reliably and ensure they continue to perform as intended in a live healthcare data environment.
How Comfortable Are You Presenting Your Insights to Others
This question assesses your confidence and effectiveness in presenting analytical insights, which goes beyond generating results to storytelling and influence. Garner Health asks this because data engineers often share findings with internal teams and leadership, and the ability to present clearly affects adoption and impact of data solutions.
Why Do You Want to Work With Us
This prompt focuses on your motivation, fit, and understanding of the company’s mission, values, or products. For Garner Health, interviewers want to know that your reasons align with the company’s healthcare orientation and that you see the data engineer role as integral to improving health outcomes and operational efficiency.
Interview preparation tips
Preparing for a Garner Health data engineer interview requires more than rehearsing syntax or memorizing frameworks. The strongest candidates combine technical readiness with a clear understanding of the company’s mission, strong communication skills, and thoughtful questions that signal long-term fit. Below are the most effective ways to structure your preparation.
Understand the mission and values
Garner Health is mission-driven, with a clear focus on helping people receive higher-quality, more affordable healthcare through better data. Before your interview, spend time understanding how Garner uses analytics to guide care decisions and improve outcomes. Reflect on moments in your own career where your work directly supported end users, improved decision-making, or reduced inefficiency. Interviewers often look for candidates who can connect their personal motivations to Garner’s purpose and explain why healthcare data problems matter to them.
Garner Health–specific tip: Be prepared to explain why working with healthcare data feels meaningful to you, not just interesting from a technical perspective.
Technical preparation
Technical interviews at Garner Health emphasize practical data engineering skills. Refresh your Python fundamentals, especially file reading, data parsing, and working with structured datasets. Review advanced SQL concepts such as complex joins, window functions, aggregations, and performance considerations. You should also be comfortable discussing ETL pipeline design, data modeling choices, and how you ensure data quality and reliability. Familiarity with cloud-based data stacks and modern analytics tooling will help you speak confidently about real-world systems.
Garner Health–specific tip: Practice explaining your code and design decisions out loud, as interviewers value clarity as much as correctness.
Case study preparation
Many candidates report a technical case study with a presentation component. Practice structuring ambiguous problems into clear steps: defining the question, outlining assumptions, performing analysis, and communicating conclusions. Focus on telling a clear story rather than over-optimizing for complexity. Your ability to translate data insights into plain language is especially important when presenting to non-technical stakeholders.
Garner Health–specific tip: Use simple visuals and emphasize implications, not just calculations.
Behavioral preparation
Behavioral interviews assess collaboration, ownership, and values alignment. Prepare STAR-based examples that highlight how you handle trade-offs, feedback, and cross-functional work. Choose stories that demonstrate integrity, adaptability, and thoughtful decision-making, especially in situations with imperfect data or unclear requirements.
Garner Health–specific tip: Anchor your answers in real outcomes and lessons learned, not just actions taken.
Ask insightful questions
Asking thoughtful questions is an important part of the Garner Health data engineer interview. This stage helps interviewers gauge your curiosity, communication style, and long-term interest in the role, while giving you clarity on whether the team and problems align with your goals. Strong questions focus on impact, collaboration, and real challenges rather than surface-level details.
Good questions to ask include how success is defined in the first six to twelve months, how data engineers collaborate with product managers, analysts, and clinical partners, and what technical or data-quality challenges the team is currently prioritizing. You can also ask how engineering decisions are evaluated or how feedback is shared across teams.
Well-chosen questions signal that you are thinking beyond the interview and seriously evaluating how you would contribute at Garner Health.
Average Garner Health data engineer salary
Garner Health data engineers earn competitive compensation for health technology companies, though it is important to note that Levels.fyi does not currently publish a robust, role-specific dataset for Garner Health data engineers. As a result, compensation expectations for this role are best interpreted using a proxy baseline from verified Garner Health software engineer data on Levels.fyi, combined with reported job postings and market norms for comparable data engineering roles.
According to Levels.fyi, Garner Health software engineers report a median total compensation of approximately $160,000, which provides a reliable anchor for understanding pay at the company. Data engineer compensation at Garner Health generally tracks closely with this baseline, with variation driven by seniority, ownership of core data infrastructure, and scope of cross-functional impact. Equity is a meaningful component of total compensation, particularly as engineers move into senior or staff-level roles.
Compensation by level (proxy-based estimates)
| Level | Total / Year | Base / Year | Stock / Year | Bonus / Year |
|---|---|---|---|---|
| Data engineer | ~$150K–$165K | ~$135K–$145K | ~$10K–$15K | ~$0–$5K |
| Senior data engineer | ~$170K–$190K | ~$145K–$160K | ~$15K–$25K | ~$5K–$10K |
| Staff data engineer | ~$195K–$215K | ~$165K–$180K | ~$25K–$35K | ~$5K–$10K |
These figures are inferred using Levels.fyi’s verified Garner Health software engineer compensation as a proxy, adjusted for typical market differences between software engineering and data engineering roles in health technology startups. Compensation tends to rise meaningfully after equity vesting begins in year two, especially for senior-level hires with platform ownership.
Regional salary comparison
| Region | Salary range | Notes | Source |
|---|---|---|---|
| United States (remote) | $150K–$210K | Most Garner Health data roles are remote-friendly; pay varies by level and scope | Levels.fyi (proxy baseline) |
| New York City | $160K–$220K | Higher base salaries driven by cost of living and talent competition | Levels.fyi (proxy baseline) |
| San Francisco Bay Area | $165K–$230K | Premium for senior infrastructure and data platform expertise | Levels.fyi (proxy baseline) |
Overall, the data suggests that Garner Health compensates data engineers at or slightly below large public tech companies, but competitively within the healthcare and growth-stage startup space. For candidates motivated by ownership, mission impact, and long-term equity upside, the compensation structure remains attractive relative to peers.
Final insights and next steps
Succeeding in a Garner Health data engineer interview requires balanced preparation across three areas: technical execution, clear communication, and cultural alignment. Strong Python, SQL, and data pipeline fundamentals are essential, but so is your ability to explain decisions, collaborate with cross-functional partners, and connect your work to Garner’s healthcare mission. Interviewers consistently look for candidates who can translate complex data problems into practical, real-world impact.
As you prepare, practice realistic scenarios rather than isolated drills. Walk through end-to-end projects you have built, rehearse explaining trade-offs out loud, and refine how you present insights to non-technical audiences. This type of preparation closely mirrors what you will be asked to do throughout the interview process.
To broaden your preparation, explore related Interview Query guides, including the Garner Health data analyst interview guide. Reviewing adjacent roles can help you better understand how data engineers partner across the organization and sharpen your overall interview strategy.
Garner health Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Analytics | Medium | |
You have access to a set of tables summarizing user event data for a community forum app. You’re asked to conduct a user journey analysis using this data with the eventual goal of improving the user interface. What kind of analysis would you conduct to recommend changes to the UI? | ||
SQL | Easy | |
SQL | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences