
CVS Health Data Engineer Interview Questions + Guide in 2025


Introduction
Landing a data engineering position at CVS means being at the forefront of healthcare analytics, where robust pipelines ensure timely, accurate insights for millions of patients. In this guide, we’ll walk you through the interview stages, common question types, and best practices to help you excel in your preparation.
Role Overview & Culture
As a CVS data engineer at CVS Health, you’ll build and maintain HIPAA-compliant data pipelines that power critical analytics for pharmacy, clinics, and insurance operations. In the role of CVS data engineer, you’ll also optimize SQL transformations, tune Spark jobs, and troubleshoot streaming ingestion pipelines across petabyte-scale datasets.
Collaboration is central: you’ll partner with data scientists, analysts, and platform engineers to translate business requirements into scalable data solutions—embodying the ethos of a data engineer CVS responsible for end-to-end pipeline health. CVS Health’s own-it culture empowers you to own pipeline reliability, implement robust monitoring, and advocate for best practices in data governance and security. Over time, you may lead modernization efforts for legacy systems, becoming a CVS health data engineer who shapes the future of healthcare data infrastructure.
Why This Role at CVS?
Joining as a CVS data engineer offers you the chance to work on data platforms that process billions of records daily, directly influencing the experience of over 90 million CVS Health members. You’ll spearhead cloud modernization efforts, transitioning legacy ETL workloads to scalable, serverless pipelines using Azure Data Factory, Databricks, and Delta Lake. These initiatives illustrate the broad remit of a CVS health data engineer, covering functions from pharmacy inventory management to insurance claims analytics and compliance reporting.
CVS provides well-defined career tracks, enabling you to grow into senior data engineering roles or pivot into data science and analytics engineering. With competitive compensation, stock incentives, and a culture that rewards ownership, you’ll rapidly expand your skills while delivering measurable impact.
What Is the Interview Process Like for a Data Engineer Role at CVS?
The CVS data engineer interview at CVS kicks off with a recruiter screen, progresses through technical assessments, and wraps up with a behavioral deep-dive before an offer. You’ll move from live SQL and ETL exercises to architecture discussions and cultural fit evaluations, all designed to assess your ability to build and maintain critical healthcare data pipelines.
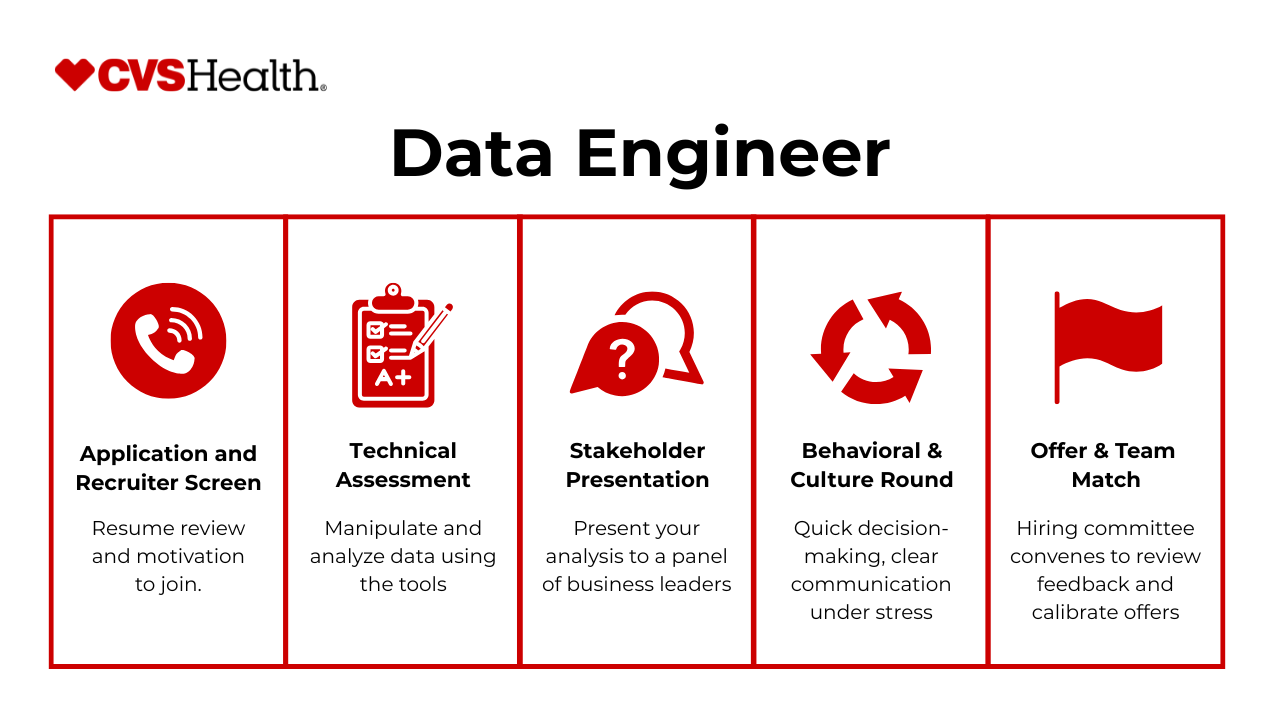
Recruiter Screen
In the initial call, a recruiter confirms your background in data engineering, reviews your résumé for relevant skills (e.g., SQL, Python, Azure), and discusses the role’s responsibilities. This stage ensures alignment on the position’s scope and your interest in supporting CVS’s mission of delivering healthcare insights at scale.
SQL/ETL Live Test
Next, you’ll complete a timed, hands-on assessment—often live-coded or take-home—that evaluates your ability to write efficient SQL queries, design ETL workflows, and troubleshoot data transformations. Expect tasks that mirror production scenarios, such as joining pharmacy and claims tables or handling late-arriving records.
System Design or Architecture Case
As a CVS health data engineer, you’ll then discuss a real-world pipeline challenge: designing end-to-end data flows for patient analytics or insurance claims reporting. Interviewers look for clear diagrams, thoughtful trade-offs (e.g., batch vs. streaming), and strategies for ensuring data quality, scalability, and compliance.
Behavioral / Bar-Raiser
This round probes your cultural fit and ownership mindset. Using STAR stories, you’ll describe times you owned critical incidents, mentored junior engineers, or advocated for process improvements. The “bar-raiser” may challenge you to defend decisions under pressure and demonstrate alignment with CVS’s patient-first values.
Offer
Successful candidates receive a call to discuss compensation, team placement, and start date. CVS typically moves quickly once technical and behavioral feedback are positive, aiming to extend offers within a week of the final round.
Timeline & Internal Feedback
CVS prides itself on rapid feedback cycles: interviewers submit evaluations within 24 hours, and the hiring committee meets weekly to decide next steps. This transparency helps candidates understand where they stand and expedites the path from interview to offer.
Differences by Level
Junior data engineers focus heavily on writing and optimizing SQL/Python for existing pipelines, whereas senior candidates are expected to propose new platform architectures, lead cross-team initiatives, and mentor peers. Compensation discussions at this stage often reference the CVS data engineer salary bands, ensuring alignment with experience and level.
Now that you know what to expect, let’s dive into sample questions to sharpen your preparation.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Cvs Health?
What Questions Are Asked in a CVS Data Engineer Interview?
In the CVS data engineer interview, you’ll face a mix of coding challenges, system design scenarios, and behavioral discussions that reflect the demands of building robust, HIPAA-compliant pipelines at scale. Expect exercises that mirror day-to-day tasks—transforming pharmacy and claims data, ensuring data quality, and driving insights for downstream analytics.
Coding / Technical Questions
Candidates should be ready for in-depth coding problems that test their SQL and Python prowess, such as crafting complex window-function queries over large transaction tables, performing efficient data munging in Python, or optimizing Spark jobs for throughput. These questions evaluate your ability to write clear, performant code and handle edge cases common in healthcare datasets.
-
Data engineers are routinely asked to rebuild marketing funnels so business partners can trust channel ROI. This problem checks that you can join fact and dimension tables, filter to converting sessions only, then apply a window function to grab each user’s earliest converting channel. Key nuances are picking the correct timestamp, handling ties, and keeping the query scalable with sort-friendly indexes. Your approach reveals how well you balance correctness with performance on large click-stream data—exactly the kind of ETL logic you would automate at CVS Health.
-
CVS collects real-time telemetry from pharmacies and apps, so memory-efficient stream algorithms matter. The interviewer wants to see that you know reservoir sampling: keep one candidate value and, for the k-th element, replace it with probability 1/k. Explaining the inductive proof of uniformity shows rigor, while highlighting O(1) space demonstrates you appreciate production constraints on embedded or edge devices feeding CVS’s data lake.
-
Health-care memberships and prescription plans can’t overlap incorrectly, so integrity checks are vital. A self-join on
user_idpaired with date-range overlap logic (startA < endBANDstartB < endA) surfaces conflicts; wrapping it in anEXISTS(or boolean aggregate) returns a simple true/false per user. Discussing exclusion of open-ended rows (NULLend_date) and adding indexes on(user_id, start_date, end_date)shows you design queries that won’t time-out in nightly validation jobs. -
Retail pharmacy baskets are huge, and merchandising teams crave cross-sell insights. Good answers outline a two-pass strategy: pre-aggregate item pairs per basket (possibly with a hashed explode in Spark) then rank by count. You should mention pruning rare items to cut the quadratic explosion and using distributed storage (Parquet, partitioning) to keep the query tractable. This proves you can engineer large-scale association-analysis pipelines.
-
Although CVS doesn’t run airlines, normalizing dimension tables is universal. You’d select distinct
(LEAST(origin,dest), GREATEST(origin,dest))into a new table, ensuring LAX-JFK and JFK-LAX collapse. Adding surrogate keys, primary constraints, and incremental refresh logic shows you can materialize lookup tables that power BI dashboards or downstream joins efficiently. -
Data-engineering coding screens often test recursion and pruning. Here you’d implement backtracking (or DP for optimization) while skipping duplicates via sorting. Complexity analysis (worst-case O(2^n)) and memory trade-offs show you understand when to push such logic into SQL vs. Python batch jobs, a judgment call you’ll make writing CVS’s enrichment services.
-
A canonical window-function exercise that confirms you know
DENSE_RANK()and edge-case handling (ties, NULLs). Because compensation data is sensitive, mentioning role-based access and anonymization demonstrates security awareness. You might also explain why an index on(department_id, salary DESC)keeps HR queries fast—mirroring performance tuning you’d perform on CVS’s workforce analytics warehouse. -
Time-series rollups are bread-and-butter for health-plan claims and POS logs. Using
ROW_NUMBER()overDATE(created_at)ordered DESC—orDISTINCT ONin Postgres—returns the day’s final event. Clarifying timezone handling and recommending a composite index on(CAST(created_at AS DATE), created_at)show production-grade thinking. -
Spatial reasoning appears even in pharmacy-store site-selection work. The interviewer checks whether you normalize unordered corners, compute min/max bounds, and apply the negated “separated” conditions. Edge-case coverage (shared edges count as overlap) and O(1) runtime indicate clean, reliable code you could drop into a geospatial UDF.
-
This extends #7 to grouped ranking; you’d use
DENSE_RANK() OVER (PARTITION BY dept ORDER BY salary DESC)and filter<= 3. Explaining how to handle departments with employees and why window functions beat correlated subqueries demonstrates SQL maturity. Such reporting patterns mirror dividend payout or cost-center rollups CVS Health runs every month.
System / Data-Pipeline Design Questions
You’ll be asked to architect end-to-end data flows—like designing a change-data-capture pipeline for real-time pharmacy transactions—balancing batch versus streaming ingestion, data validation, and downstream consumer needs. Interviewers look for clear diagrams, justification of technology choices, and strategies to ensure latency, reliability, and compliance.
-
CVS Health’s data engineers curate claims, provider, and patient dimension tables that must stay perfectly aligned. The interviewer wants to confirm you understand that foreign-key constraints enforce referential integrity in the database engine itself, preventing orphaned rows that could corrupt analytics or regulatory reporting. You should contrast a plain
BIGINTcolumn (cheap but unsafe) with a constrained FK (slower inserts but safer queries) and discuss indexing side-effects. Finally, walk through real-world deletion semantics—e.g., cascades make sense for child facts that become meaningless without their parent, whereasSET NULLpreserves history while severing a link—and note why soft-deletes are sometimes preferable in healthcare. -
This scenario probes your ability to scope global data-ops: you’d ask about GDPR/PHI locality, currency conversion strategy, SLA for vendor dashboards, expected order volume, and real-time versus batch latencies. A strong answer sketches a layered design—streaming ingestion into a regional raw zone, centralized parquet lake on S3/GCS, Spark + Airflow transformations into a Snowflake or Redshift warehouse, and Looker or Tableau extracts for daily/weekly cuts. Mention slowly-changing dimensions for vendors and a CDC pipeline for orders/returns. Emphasizing monitoring, cost controls, and disaster-recovery shows you think like a principal engineer.
-
Although CVS doesn’t measure car speeds, the question tests your schema-design instincts and SQL chops. You’d propose a
car_crossingsfact withcross_id,plate,model_id,entry_ts,exit_ts, and derivedduration. Indexing onentry_tsor a partition oncross_datekeeps daily queries snappy. Then show a window query (orORDER BY duration LIMIT 1) for the single fastest run today and another grouping bymodel_idwithAVG(duration)followed byORDER BY avg ASC LIMIT 1. This demonstrates you understand event-time analytics over high-velocity IoT feeds. -
The interviewer evaluates your ability to normalize POS data into
orders,order_items,menu_items, andpayments. Explain surrogate keys, price history, and denormalized aggregates for speed. For analytics, you’d sumprice*qtyper item filtered toyesterdayand rank; for drink attach-rate, divide count of orders containing at least one drink by total orders. Mention window functions orCOUNT(DISTINCT order_id)patterns and why indexingorder_dateis critical for lunch-rush reports. Hourly, daily, weekly active-user pipeline from a data lake
CVS Health dashboards rely on roll-ups of web traffic and prescription-refill events. You’d propose a Spark Structured-Streaming job that writes raw events into an open table format (Iceberg/Delta) partitioned by event_date + hour. Then a scheduled Airflow DAG materializes HAU, DAU, and WAU aggregations into a serving warehouse—leveraging incremental upserts and idempotent logic. Discuss watermarking late data, bloom-filter indexes for
user_id, and caching aggregates in Redis for sub-second API latency to BI tools.Schema evolution for customer address history and occupancy tracking
Address data drives mail-order pharmacy deliveries and compliance letters. Suggest an
addressesdimension with immutableaddress_idplus anaddress_historybridge capturinguser_id,address_id,move_in,move_out, and acurrent_flag. Triggers or CDC keep histories consistent; a surrogatehousehold_idhandles new occupants. Mention partitioning bymove_inmonth, and how BI queries join on a point-in-time predicate to reconstruct exposure or shipping audits.High-scale YouTube-style recommendation engine design
Even though CVS isn’t a media firm, the question uncovers your grasp of large-scale ML data plumbing. Outline candidate-generation (collaborative filter, content similarity) followed by ranking with gradient-boosted trees fed by watch-time, dwell, device, and health-privacy features. Detail feature store, real-time feedback loop, and AB-testing harness. Stress recall/precision trade-offs, cold-start remedies, and PII segmentation—skills transferable to personalizing CVS’s digital storefront.
Migrating from a document DB to a relational model for social-network data
Here the assessor wants to hear your data-modeling rigor: explain first questions—scale, consistency requirements, read/write mix. Propose tables for
users,friendships(symmetric edges), andinteractions, enforce PK/FK, and possibly sharded MySQL or Postgres with logical-shard IDs. Discuss ETL backfill, dual-writes during cut-over, and validation checks to avoid orphaned likes. This reflects the kind of migration CVS might do moving legacy NoSQL into a governed warehouse.Booking fact table with 90-day, 365-day, and lifetime counts
The task gauges window-function fluency. You’d use conditional
SUM(CASE WHEN created_at >= DATE '2021-10-03' THEN 1 END)for 90-day, similar for 365-day, alongsideCOUNT(*)for lifetime grouped bylisting_id. Comment on using partition pruning by date and why materializing into a summary table speeds dashboards—practices vital for CVS’s appointment-scheduling analytics.Design a star schema for a new online retailer data warehouse
They’re testing dimensional-model thinking: propose
sales_fctgrain “one line-item per order”, with dimensionsdate,product,customer,store,promotion. Show surrogate keys, slowly-changing type-2 on customer demographic, and degenerateorder_number. Emphasize extensibility for future channels (pharmacy vs. OTC) and why this star supports KPI queries (GMV, basket size) with minimal joins—exactly how CVS structures enterprise BI.Cost-effective clickstream storage and query for 600 M daily events with 2-year retention
The interviewer wants cloud-ops pragmatism: propose Kafka ingestion into compressed Parquet on S3 with partitioning by date and optional user-hash bucketing; catalog via AWS Glue or Hive Metastore. Cold data stays cheap in Glacier; recent partitions load into Athena/Redshift Spectrum or BigQuery for interactive SQL. Summaries feed Snowflake for business users. Calling out columnar compression, object-lifecycle policies, and the balance of cost vs. latency mirrors decisions CVS Health makes to tame exploding telemetry volumes.
Behavioral or “Culture Fit” Questions
These discussions explore how you take ownership of critical data incidents, advocate for data security and privacy, and communicate effectively with cross-functional partners such as data scientists, product managers, and compliance teams. Interviewers seek examples that demonstrate your alignment with CVS’s patient-centric values and collaborative approach.
-
CVS Health wants proof that you can shepherd a pipeline or platform initiative from concept to production while navigating messy realities such as legacy systems, shifting requirements, and cross-team dependencies. Your answer reveals depth of hands-on technical skill (e.g., Spark tuning, CDC ingestion, Terraform IaC) and your ability to de-risk delivery with experiments, documentation, and stakeholder check-ins. By emphasizing measurable impact—reduced refresh latency, lower compute costs, fewer data-quality incidents—you show you can translate engineering effort into business value.
-
Large healthcare organizations live or die by how quickly clinicians, actuaries, and pharmacy ops teams can turn raw data into decisions. CVS wants to hear how you expose curated layers (e.g., Delta Lake bronze/silver/gold), publish data contracts, add meaningful metadata in a catalog, and embed lineage and data-quality scores so users trust the output.
-
Self-awareness is critical in a tightly regulated environment where mistakes carry compliance risk. CVS is probing for honesty about blind spots—perhaps incident post-mortems revealed a need for better runbooks or for delegating more effectively—and concrete steps you’ve taken: taking secure-coding courses, automating data-quality tests, or seeking mentorship.
-
CVS projects often involve explaining latency, PHI compliance, or infrastructure cost trade-offs to product owners and clinicians. The interviewers want to see that you can translate jargon like “Kinesis shard limits” into meaningful business language (“batching events every five minutes keeps error budgets intact and saves $X per month”).
-
CVS is looking for commitment to mission—improving patient outcomes through data—and for evidence you’ve researched their tech stack (Azure, Snowflake, FHIR APIs) and recent initiatives (CarePass, HealthHub). Explaining how the scale and regulatory complexity excite you, and how you can advance initiatives like real-time eligibility checks or predictive adherence models, shows genuine motivation.
When several ingestion jobs, backfills, and ad-hoc requests all land at once, how do you triage and schedule the work so that the most critical SLAs are met without sacrificing data quality?
Data-engineer workloads at CVS span EMR feeds, claims data, and marketing marts—deadlines collide regularly. This prompt tests your prioritization framework: impact × urgency scoring, SLA breach cost, or patient-safety relevance. Mentioning tooling—Airflow pools, service-level objectives, automated data-quality gates—and proactive stakeholder updates shows operational maturity. The interviewer also assesses whether you escalate early and negotiate scope rather than silently missing deadlines, an essential trait in a high-compliance environment.
Give an example of a time your monitoring or data-quality checks surfaced an issue that downstream teams hadn’t noticed yet. How did you diagnose, communicate, and remediate the problem before it affected decision-making?
CVS values engineers who build guardrails that catch PHI leakage or metric drift early. This story highlights your observability toolkit (Great Expectations, Monte Carlo, custom Grafana dashboards), your root-cause methodology, and your sense of ownership across the entire data lifecycle. It also reveals your stakeholder-management style when sounding the alarm and coordinating a fix under time pressure.
Describe a situation where you had to balance HIPAA/PHI compliance requirements with the need for rapid data access. What specific design or process choices did you make, and what did you learn?
Handling protected health information is central to CVS’s mission, so they gauge your familiarity with de-identification, role-based access controls, and encryption-at-rest/in-transit. Sharing concrete design choices—tokenization services, differential-privacy aggregates, pseudonymized development sandboxes—demonstrates practical understanding. The reflection on trade-offs (e.g., slight latency increase vs. audit-readiness) shows you can engineer solutions that satisfy both speed and compliance.
How to Prepare for a Data Engineer Role at CVS
Before stepping into interviews, it’s crucial to understand how your experiences map to CVS’s mission of delivering reliable healthcare insights. Focus your preparation on realistic problem scenarios, clear communication, and demonstrating a proactive ownership mindset.
Study the Role & Culture
Review CVS’s data infrastructure and patient-first mission, then align your past ETL and pipeline successes with their scale and compliance requirements. Showing that you understand how data powers critical healthcare decisions will set you apart.
Practice Common Question Types
Allocate your study time to a balanced mix: roughly 40% on SQL/Python coding challenges, 40% on system and data-pipeline design, and 20% on behavioral scenarios. Work through representative problems to build both speed and depth.
Think Out Loud & Ask Clarifying Questions
In all practice sessions, verbalize your reasoning and surface trade-offs—such as choosing between lower latency with streaming or lower cost with batch processing. Interviewers value candidates who articulate their thought process and adjust based on feedback.
Mock Interviews & Feedback
Simulate full interview loops by pairing with ex-CVS engineers or fellow Interview Query members. Seek critiques on your technical solutions, system designs, and storytelling to ensure you’re ready to perform under real-world pressure.
FAQs
What is the average salary for a CVS Data Engineer?
Average Base Salary
Average Total Compensation
How big is the CVS data engineering org?
Within the CVS health data engineer organization, you’ll find cross-functional squads embedded in Retail, Caremark Pharmacy Services, and Aetna’s analytics teams. In total, hundreds of engineers partner with data scientists and product managers to deliver insights across the enterprise.
Does CVS expect Spark or Snowflake expertise?
As a CVS data engineer, familiarity with Spark is highly valued for streaming and batch pipelines, while Snowflake proficiency is encouraged for scalable data warehousing. CVS also provides internal training programs to onboard you onto these and other cloud-native tools.
What projects do new hires tackle first?
New data engineers often start by building or enhancing data-quality DAGs, migrating legacy batch workflows to streaming architectures, and supporting key ETL processes that feed analytics dashboards for pharmacy and insurance operations.
Can I apply again after rejection?
CVS maintains a six-month cooldown for reapplications. During that period, focus on strengthening your SQL, pipeline design, or domain knowledge before reapplying to demonstrate growth and readiness.
Conclusion
With focused practice on core SQL/Python challenges, hands-on system design scenarios, and clear communication of trade-offs, you’ll be well-prepared to ace the CVS data engineer interview questions and showcase your ability to support CVS’s mission-driven data platform. For additional preparation, explore our Data Engineering Learning Path and book a mock interview to simulate the real loop.
Looking for more role-specific guidance? Check out our sister guides for CVS Data Scientist, Software Engineer, and Data Analyst. Good luck!
Cvs Health Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Easy | |||||||||||||||||||||||
We’re given two tables, a Write a query that returns all neighborhoods that have 0 users. Example: Input:
Output:
| ||||||||||||||||||||||||
SQL | Hard | |||||||||||||||||||||||
Machine Learning | Easy | |||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences