
CVS Health Machine Learning Engineer Interview Questions + Guide in 2025


Introduction
CVS is harnessing the power of machine intelligence to transform patient care, optimize pharmacy operations, and personalize insurance offerings. As healthcare continues to evolve, the ability to build reliable, compliant models on massive, sensitive datasets becomes mission-critical for sustaining both innovation and trust.
Role Overview & Culture
In the CVS machine learning team, you’ll develop predictive models that forecast medication adherence, detect fraud in claims, and tailor retail promotions with strict HIPAA-compliance. You’ll work within agile squads alongside data engineers and clinical experts, iterating rapidly to bring data-driven insights into production while upholding the highest standards of privacy and security. CVS machine learning practitioners are empowered to own end-to-end pipelines—from data ingestion through model deployment—ensuring that every algorithm directly benefits the 90 million members we serve.
Why This Role at CVS?
In CVS machine learning, your work impacts a vast healthcare ecosystem, leveraging petabytes of data to drive decisions that affect patient outcomes and cost efficiencies. This role offers clear career pathways, from ML Engineer to Data Scientist and beyond, as you contribute to projects that balance cutting-edge AI research with real-world clinical and retail applications. If you’re excited about applying your skills in a regulated environment, consider this your opportunity to excel as a CVS ML engineer interview awaits.
What Is the Interview Process Like for a Machine Learning Engineer Role at CVS?
CVS leverages CVS machine learning expertise to drive its next-generation healthcare analytics and AI-powered services. If you’re aiming to join this team, here’s a concise overview of what to expect at each stage of the hiring journey.
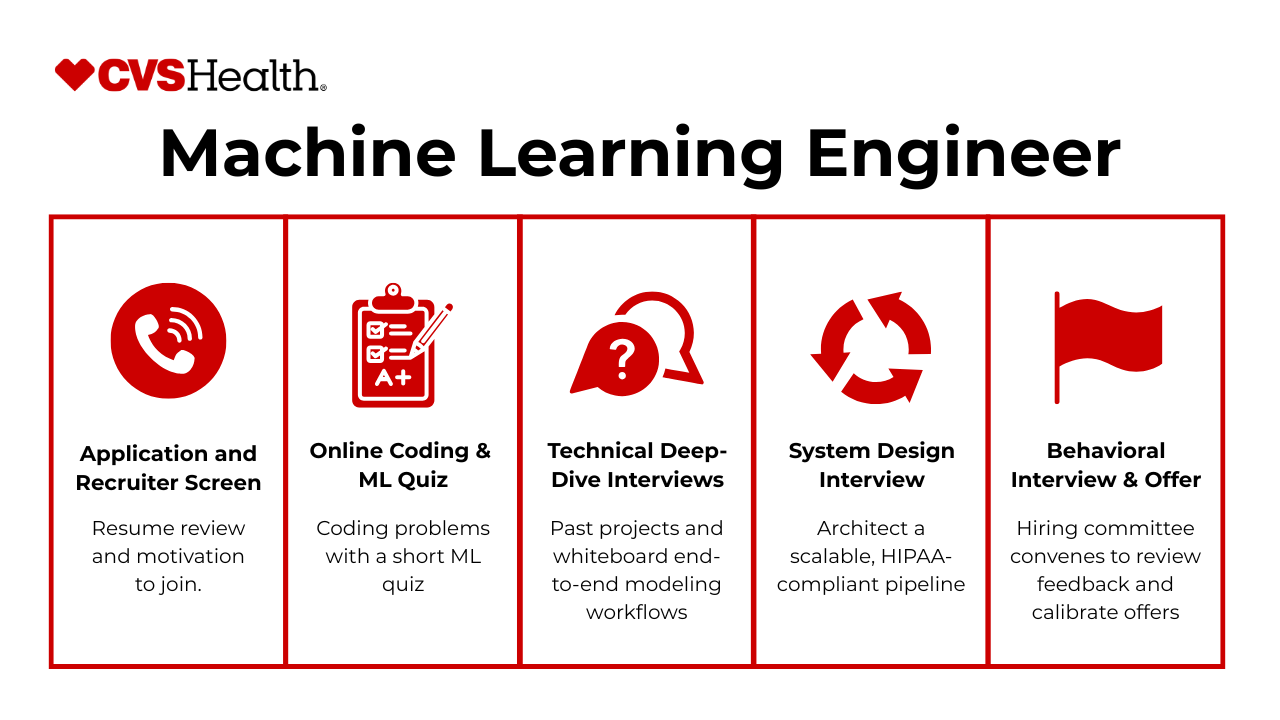
Recruiter Screen
Your first touchpoint is a conversation with a recruiter who assesses your résumé for relevant machine learning experience in regulated environments, cultural fit, and motivation for healthcare analytics. They’ll verify basic qualifications—such as familiarity with Python, model deployment, and data privacy considerations—and outline the overall process and timeline.
Online Coding & ML Quiz
Next, you’ll complete a timed online assessment combining coding problems (e.g., data manipulation in pandas or SQL) with a short ML quiz covering topics like model evaluation metrics, bias-variance trade-offs, and feature engineering. This stage evaluates both your programming fluency and your conceptual grasp of core machine learning principles under time pressure.
Technical Deep-Dive Interviews
Successful candidates then move on to a series of technical deep dives, where you discuss past projects and whiteboard end-to-end modeling workflows—from data preprocessing through production deployment. Expect questions on handling missing data, hyperparameter tuning strategies, and validation approaches in a healthcare setting.
System Design Interview
In this round, you’ll architect a scalable, HIPAA-compliant pipeline for training and serving a predictive model—covering data ingestion, feature stores, monitoring, and retraining. Interviewers look for your ability to balance latency, throughput, and privacy requirements when designing real-world systems.
Behavioral Interview
Finally, a behavioral session explores scenarios around team collaboration, handling ambiguity in clinical data, and decision-making under regulatory constraints. Using the STAR method, you’ll share stories that demonstrate ownership, effective communication with cross-functional partners, and adherence to CVS’s patient-first values.
Behind the Scenes & Timeline
Candidates typically receive feedback within 24 hours after each stage, thanks to CVS’s streamlined hiring-committee process. A cross-functional panel reviews scores, and a designated “bar-raiser” ensures consistency and high standards before extending an offer.
Differences by Level
For junior roles, the emphasis is on hands-on coding and foundational modeling tasks. Senior candidates, in contrast, face additional rounds on solution architecture, team mentorship, and strategic roadmap discussions—reflecting broader scope and leadership expectations.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Cvs Health?
What Questions Are Asked in a CVS Machine Learning Engineer Interview?
CVS machine learning engineers at CVS encounter a balanced mix of technical, theoretical, and design discussions that reflect the company’s healthcare focus and data-driven culture. Below is an overview of the core question categories and what interviewers aim to uncover in each.
Coding / Technical Questions
In this segment, you’ll be tested on your ability to write clean, efficient code for real-world data challenges. Expect problems involving fundamental data structures (e.g., trees, heaps), data wrangling tasks using Spark or pandas, and optimization of streaming or batch pipelines. Interviewers look for both correctness and clarity of thought, as well as your ability to articulate complexity and performance trade-offs.
-
Interviewers use this classic array-manipulation task to check that you’re fluent with index arithmetic, boundary cases (odd vs. even dimensions), and space-time trade-offs. Optimal answers discuss layer-by-layer swaps (O(n²) time, O(1) extra space) and note pitfalls such as integer overflow in lower-level languages or aliasing in Python slice assignments. It also reveals how cleanly you communicate step-by-step logic.
-
This problem probes comfort with bitwise XOR tricks or constant-space math (Σ0…n – Σnums). Recruiters gauge whether you instinctively avoid extra memory and explain overflow safeguards when summing large ranges. It’s a quick litmus test that you can derive elegant O(1) solutions under pressure.
-
Weighted random sampling is everywhere in production (A/B bucketing, recommender exploration). Interviewers want to see cumulative-weight tables, rejection sampling alternatives, and clarity on “with vs. without replacement.” Mentioning performance with large counts or floating-point precision shows real-world savvy.
-
The canonical answer—reservoir sampling—demonstrates that you understand probability proofs as well as constant-space streaming constraints (critical for analytics pipelines or real-time trading). Good candidates justify why each element seen so far has 1/N probability and discuss RNG quality.
-
Date-arithmetic edge cases (leap years, month boundaries, locale-specific holidays) frequently trip up production code. This question checks your mastery of date libraries or, if none are allowed, your ability to craft reliable arithmetic. It also surfaces whether you pre-plan performance for large ranges and pluggable holiday calendars.
-
Merging is at the heart of external sort, stream joins, and merge-phase MapReduce jobs. The interviewer expects a linear two-pointer approach (O(n+m) time) and a concise complexity explanation. Bonus points for handling duplicates and discussing memory if you must merge in-place.
Suppose you’re handed an m × n matrix of integers—how would you return the sum of all its elements?
Though seemingly trivial, this screens for baseline fluency in nested iteration, vectorized NumPy solutions, or functional constructs (reduce). Candidates often reveal coding hygiene—variable naming, off-by-one safety, and unit tests—on easy problems.
-
Monthly roll-ups mirror real reporting dashboards. Interviewers want to see date truncation, conditional aggregation, and correct handling of months with zero activity. Discussing indexes on
created_ator materialized summary tables shows awareness of performance at scale. -
Triplet-sum problems evaluate your ability to extend two-sum hashing or two-pointer patterns. The optimal O(n²) approach (after sorting) demonstrates complexity reasoning and duplicate-avoidance techniques—skills essential when deriving features for fraud-detection or pricing models.
ML Theory & Modeling Questions
Here, the focus shifts to your understanding of core machine learning concepts in the context of healthcare data. You may discuss regularization techniques to prevent overfitting, strategies for detecting and adapting to feature drift, and how to evaluate models on imbalanced datasets—common in clinical or claims data. Strong candidates demonstrate both theoretical knowledge and practical considerations for deploying reliable models in production.
-
Employers ask this to see whether you understand post-hoc model-explanation techniques—e.g., SHAP, LIME, counterfactual explanations, or rule-based surrogate models—and can apply them in a regulated setting. A strong answer weighs fidelity vs. simplicity, addresses fairness (avoiding sensitive-attribute leakage), and proposes operational workflows such as storing top-N contributing features or mapping them to pre-approved policy phrases. Discussing how to monitor drift and keep explanations consistent over model updates shows long-term product thinking.
-
This question checks your grounding in generalized-linear-model theory and your ability to translate log-odds into probabilities that stakeholders can digest. Interviewers want to see you normalize against a reference category, explain the meaning of an odds ratio > 1 or < 1, and highlight caveats such as multicollinearity or sparse levels. Relating coefficient size to lift in conversion or risk demonstrates an aptitude for turning math into actionable advice.
-
These interviews probe whether you can scope messy, language-driven problems: data sources (historical profiles, public name lists), text-normalization (Levenshtein distance, phonetic hashing), and model choice (seq-to-seq, nearest-neighbor, probabilistic graphs). Good answers describe evaluation sets (precision@K, recall), handling many-to-many mappings, and latency constraints if the model powers an autocomplete service.
-
Being able to tailor depth and jargon on the fly is crucial for data scientists who liaise with execs, PMs, and engineers. Interviewers evaluate communication range: analogies for the child (drawing the “best-fit” line), gradient-descent intuition for the student, and matrix normal-equation form for the mathematician. Demonstrating empathy for each listener shows you can make sophisticated models usable company-wide.
-
This probes data-sufficiency reasoning: covering the feature space (time-of-day, geohash, weather), variance vs. bias trade-offs, and learning-curve diagnostics. Strong answers propose slicing by route density, plotting error vs. sample size, and estimating the marginal value of additional data collection versus feature engineering. Mentioning simulation or active-learning to target under-represented corridors shows pragmatic modeling instincts.
-
Companies want to avoid systematically over- or under-estimating prep times for certain cuisines, peak periods, or small vendors. The prompt tests your awareness of label noise (inaccurate POS timestamps), covariate shift (new restaurants), and social-equity angles (penalizing slower kitchens). You should discuss bias metrics (mean error per restaurant, subgroup fairness), feedback loops affecting driver dispatch, and retraining cadence.
-
This gauges debugging discipline: random initialization, nondeterministic hardware (GPU, multithreading), data-splitting leakage, or non-seeded cross-validation folds all introduce variability. Articulating controls—fixed seeds, stratified splits, deterministic libraries—and distinguishing variance from genuine overfitting shows rigorous experimentation habits.
-
Social platforms care about healthy-content mix, so interviewers look for policy-aware feature engineering (relationship strength, content type, recency), multi-objective optimization (engagement, diversity), and guardrails such as publisher quotas. Discussing offline metrics (NDCG, entropy), online holdouts, and causal inference (did increasing public content actually boost session depth?) signals product-led ML thinking.
-
This assesses data-quality vigilance: you’re expected to reason about outlier influence on coefficients, prediction drift, and retraining safety. Proposing detection (range checks, KL-divergence alerts), imputation or robust scaling, and model monitoring (PSI, residual plots) conveys mature ML-ops habits.
-
Large-scale recommenders are central at CVS Health. A strong answer covers candidate generation (embedding nearest neighbors, hierarchical titles), ranking (gradient-boosted decision trees, deep two-tower models), cold-start tactics, feedback loops (click vs. apply), and evaluation (CTR, application completion, long-term job-match success). Addressing fairness (diversity of roles surfaced) and latency constraints rounds out a production-ready design.
System / Product Design Questions
This round explores your architecture skills and your grasp of end-to-end ML systems. A typical prompt might ask you to design a real-time adherence-risk scoring service, detailing data ingestion, feature storage, model serving, and monitoring. Emphasis is placed on balancing latency with accuracy, ensuring data privacy, and maintaining system reliability under high load.
-
Streaming viewers expect instant, high-quality suggestions; Netflix therefore cares about candidate-generation latency, cold-start handling for new shows, and personalization that respects maturity settings and regional catalogs. Your answer should cover lightweight prefix indices or trie-based retrieval for millisecond recall, a re-ranker that blends popularity priors with session context, and safeguards against offensive auto-completions. Interviewers listen for awareness of distributed key-value stores (e.g., Redis, Faiss ANN), online feature freshness, and A/B-testing hooks to measure click-through and downstream watch-starts.
-
The discussion reveals how you translate “viewer fatigue” into model features—scene boundaries, sentiment arcs, historical dropout curves—and balance publisher revenue with user experience. Good solutions propose multi-objective modeling (completion rate vs. ad revenue), use self-supervised shot-boundary detection to generate candidate slots, and reference reinforcement learning or constrained optimization to respect ad-load caps. Demonstrating an offline evaluation plan (simulated counterfactual revenue) plus online guardrails shows product-savvy ML thinking.
-
Spotify values candidates who marry collaborative filtering with content-based embeddings and scalable batch generation. A strong answer outlines multi-stage retrieval (annoy/k-NN on user–track vectors), novelty boosts, and rule-based diversity constraints to avoid artist repeats. Detailing Airflow or Dagster orchestration, offline model retraining cadence, and real-time feedback loops on skips/likes demonstrates end-to-end system ownership.
-
The prompt probes knowledge of speech-to-text ingestion, inverted indices with sub-second query latency, and semantic re-ranking (e.g., BM25 + BERT cross-encoder). Mentioning speaker diarization for quote snippets, entity extraction for facet filters, and a relevance-feedback loop (play-through depth) shows depth in information-retrieval engineering.
How would you build an ML system at DoorDash that minimizes missing or wrong food orders?
You need to reason through noisy labels (support tickets, refund flags), hierarchical features (restaurant, courier, menu complexity), and real-time interventions (double-check prompts). Discuss streaming anomaly detection on order flow, gradient-boosted models for risk scoring, and A/B-tested UX nudges. DoorDash wants engineers who can fuse ops telemetry with ML to cut costly errors.
-
Interviewers expect knowledge of distributed matrix-factorization (Spark ALS, TensorFlow parameter servers), negative-sampling tricks, and feature hashing. Calling out stratified data-sharding, asynchronous SGD, and check-pointing on Spot instances signals you’ve wrestled with memory and cost constraints in production.
How would you detect firearm sales on a marketplace platform where such listings are prohibited?
The challenge blends NLP, image vision, and adversarial behavior. Good answers cover a multimodal pipeline—OCR on images, wordpiece embeddings for euphemisms, and continual-learning loops as sellers obfuscate listings. Emphasizing low-latency moderation queues and human review escalation demonstrates policy-aware system design.
-
This question gauges your grasp of hierarchical model stacks (image, audio, text), streaming inference at scale, and privacy-preserving storage. Highlighting metric trade-offs (recall for safety vs. false-positive creator friction) and auditability (model cards, bias checks) aligns with regulatory scrutiny around user safety.
-
Speak to resampling (SMOTE vs. down-sampling), cost-sensitive losses, ensemble stacking, and monotonic constraints for regulatory explainability. Outlining population-drift monitoring and partial-fit online learning shows you can keep precision high as fraud patterns evolve.
-
The interviewer is testing product empathy plus causal-inference chops: explain feature sets (search views, competitor prices, local events), demand-elasticity estimation, and multi-armed bandit experimentation. Detailing host override tooling and fairness checks (no discriminatory pricing) proves you see beyond pure revenue lift.
-
Discuss signals (check-ins, friend likes, location, photo sentiment) and a two-pass model (approximate nearest neighbor retrieval plus neural re-ranker). Mention cold-start issues, spam reviews, and privacy concerns around location inference; such nuance shows you weigh business value against user trust.
-
The prompt tests data-engineering fundamentals: incremental CDC pulls from the Stripe API, schema evolution handling, idempotent loads into Snowflake/BigQuery, and Airflow with SLA-monitoring. Highlighting PII tokenization and PCI compliance demonstrates industry-relevant diligence.
-
Explain the lambda/kappa architecture: Kafka ingest, feature store with holiday calendars, LightGBM or Prophet retrained nightly, and micro-batch online inference. Non-functional requirements—< 5 % MAPE, 99.9 % uptime—show productization thinking.
What pitfalls could emerge after deploying a sentiment-analysis model on WallStreetBets text?
Reddit slang, sarcasm, and domain shift create label noise; model outputs can move markets and invite manipulation. Discuss continuous monitoring, adversarial content defenses, and clear “confidence” communication to traders. Highlighting ethical concerns (market manipulation, retail-investor harm) signals mature risk awareness.
Behavioral or “Culture Fit” Questions
Finally, interviewers assess how you’ll collaborate within CVS’s cross-functional teams and uphold patient-privacy standards. You might discuss past experiences working with stakeholders in engineering, data science, and healthcare operations, your approach to navigating ambiguous requirements, and how you ensure compliance with regulatory frameworks such as HIPAA. This section gauges your communication skills, adaptability, and alignment with CVS’s ownership-driven values.
-
CVS Health looks for MLEs who can carry an initiative from exploratory analysis through production deployment in a highly-regulated environment. The interviewer wants to hear how you framed an ill-defined business problem, navigated messy pharmacy or claims data, and handled late-stage obstacles—HIPAA constraints, model-performance regressions, or pipeline failures. Showing structured root-cause analysis, crisp communication with cross-functional partners, and measurable impact (e.g., reduced refill prediction error by 15 %) convinces them you can deliver at enterprise scale.
-
At CVS, health-plan executives, clinicians, and care-management teams all consume ML insights. Your answer should highlight tools (Shapley dashboards, narrative data stories), practices (user-centered KPI selection, iterative feedback loops), and empathy for time-pressed clinicians. Emphasizing that better explanations drive adoption—and ultimately patient outcomes—shows you understand the “last-mile” problem of ML in healthcare.
-
This probes self-awareness and coachability, two traits CVS cultivates in its leadership-development culture. Tie a core strength directly to the MLE role (e.g., “I can productionize models with airtight data-lineage tracking”) and illustrate with a brief win. For a weakness, choose something non-fatal—perhaps delegating too slowly—then describe concrete steps you’ve taken (mentoring juniors, async design docs) to improve. The company values humility paired with proactive growth plans.
Tell me about a time you struggled to communicate with stakeholders—how did you bridge the gap?
CVS Health’s analytics work spans retail, PBM, and Aetna divisions, so alignment is hard. Interviewers assess whether you can translate model-centric language into business or clinical terms, resolve conflicting incentives, and keep decision-makers engaged. A crisp story that ends with a shared metric dashboard or a change in clinical workflow proves you can foster trust across silos.
Why do you want to work at CVS Health, and what are you looking for in your next role?
They expect an answer that blends mission—“help close care gaps for millions of members”—with technical appetite—“build streaming models on real-time claims and wearable data.” Referencing recent initiatives (e.g., home-dialysis monitoring, MinuteClinic virtual visits) shows homework, while mapping your skill set (causal inference, ML ops) to those programs demonstrates immediate value add.
When multiple model releases, urgent ad-hoc analyses, and data-quality firefights collide, how do you set priorities and stay organized?
CVS operates under strict regulatory deadlines (CMS reporting, formulary updates) alongside agile product sprints. Interviewers want to hear about frameworks—RICE scores, Eisenhower matrix, sprint planning—and tooling (Jira, Airtable, automated DQ alerts). Highlighting transparent communication of trade-offs and the discipline to protect “focus blocks” for deep work reassures them you can deliver reliably.
Describe a time you balanced model accuracy with inference latency for a real-time health-care application.
CVS Health’s retail checkout and telehealth triage systems need predictions in sub-second windows. The interviewer uses this to gauge your grasp of feature-store caching, model compression, or streaming architectures—and your judgment in deciding when “good enough” accuracy is the right call to meet service-level objectives.
Tell me how you ensured ethical and regulatory compliance when deploying an ML model that influences patient care.
From HIPAA to algorithmic bias, CVS must safeguard member trust. Explaining how you performed bias audits, documented intended use in a model card, or designed a human-in-the-loop override reveals maturity in responsible-AI practice—an area CVS scrutinizes heavily for any system that could affect clinical decisions.
How to Prepare for a Machine Learning Engineer Role at CVS
Diving into the CVS ML engineer interview process requires targeted practice across coding, modeling, and system design, as well as a clear articulation of how your work advances patient outcomes.
Study the Role & Culture
CVS machine learning candidates should map their previous end-to-end ML pipelines to CVS’s mission of improving patient care through data. Research the company’s analytics initiatives—such as medication adherence or insurance fraud detection—and be ready to discuss how your expertise can contribute to similar projects.
Practice Common Question Types
Allocate your prep time roughly as follows: 40 % on coding (data structures, Spark, Python), 30 % on ML theory (model evaluation, feature engineering), and 30 % on system design (architecture, data flow). Use timed exercises to simulate interview conditions and refine your problem-solving pace.
Think Out Loud & Ask Clarifying Questions
During mock sessions, practice verbalizing your assumptions, trade-offs (e.g., accuracy vs. latency), and edge-case considerations. Demonstrating a structured thought process and proactive clarification shows interviewers how you collaborate on complex healthcare analytics problems.
Mock Interviews & Feedback
Pair with former CVS ML engineers or leverage Interview Query’s mock-interview platform to rehearse each interview stage. Solicit feedback on your technical explanations, system designs, and behavioral narratives to iteratively strengthen your performance across all rounds.
Conclusion
With targeted preparation—mastering key frameworks, refining ML-driven system designs, and practicing clear, patient-centric storytelling—you’ll be well positioned to ace the CVS machine learning interview and make a meaningful impact on millions of patients.
For additional insights, explore our CVS Data Scientist Interview Guide, CVS Data Engineer Interview Guide, and the comprehensive CVS Interview Process overview. Good luck, and happy studying!
Cvs Health Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Machine Learning | Easy | |
Let’s say we’re comparing two machine learning algorithms. In which case would you use a bagging algorithm versus a boosting algorithm? Give an example of the tradeoffs between the two. | ||
Probability | Hard | |
Machine Learning | Easy | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences