
Atlassian Data Scientist Interview Guide: Process, Questions, Salary & How to Stand Out


Introduction
Atlassian powers collaboration for more than 300,000 teams worldwide, producing an enormous stream of behavioral and product data that fuels analytics, experimentation, and machine learning across Jira, Confluence, and Trello. As Atlassian accelerates its AI investments, data scientists have become central to how new features are evaluated, optimized, and shipped.
If you are preparing for an Atlassian data scientist interview, this guide gives you a clean, structured overview of the role, the interview process, and the question types you will face across SQL, experimentation, machine learning, and product reasoning. Use it to anchor your preparation and align your approach with how Atlassian’s data teams actually work.
What does an Atlassian data scientist do
Atlassian data scientists blend analytical rigor with product intuition. They help teams understand how users behave, where workflows break down, and which features create meaningful value. Much of the work involves partnering across product, engineering, and design to answer open-ended questions through structured reasoning and well designed experiments.
Key responsibilities include:
- Designing and analyzing A/B tests for new product features across Jira and Confluence
- Building predictive models for search ranking, recommendations, automation, or customer intent
- Creating event based metrics that help teams measure adoption, engagement, and retention
- Investigating behavioral trends to diagnose friction points in user workflows
- Writing clear SQL to extract, transform, and validate large scale product data
- Collaborating asynchronously with PMs and engineers to translate ambiguous questions into measurable steps
- Presenting insights through dashboards, deep dives, or narrative documents that guide product direction
- Applying statistical methods to evaluate changes, identify anomalies, and validate assumptions
This combination of experimentation, modeling, and cross functional alignment makes the role deeply integrated with how Atlassian builds and improves products.
Why this role at Atlassian
This role is ideal if you want to practice data science in a product focused environment where insights influence real customer-facing features used by millions. Atlassian offers modern tooling, strong experimentation infrastructure, and a culture built on openness and thoughtful collaboration. You will have opportunities to work on high visibility projects across AI assisted workflows, product analytics, and experimentation strategy while benefiting from a remote first setup, clear leveling, and meaningful long term growth.
Atlassian Data Scientist Interview Process
Atlassian’s data scientist interview process evaluates three core dimensions: analytical depth, product reasoning, and values driven collaboration. The stages move quickly and follow a structured format so interviewers can assess both your technical skills and how you operate in a remote first environment.
| Stage | Primary Focus |
|---|---|
| Application Submission | Resume strength, clarity of impact, alignment with analytics or ML work |
| Recruiter Screen | Background fit, communication, motivation |
| ML and Statistics Challenge | SQL, experiment design, statistical reasoning, light ML |
| Virtual Loop | Technical depth, product sense, modeling, cross functional collaboration |
| Hiring Committee | Calibration, leveling, consistency, final decision |
Application submission
At this stage, reviewers look for evidence that you can handle real product analytics or modeling work. A strong resume highlights measurable impact, such as improving activation metrics, reducing friction in workflows, or shipping ML models that influenced product decisions. Emphasize ownership, end to end problem solving, and the scale of datasets you worked with. Since Atlassian’s data science roles span product, experimentation, and ML, tailor your resume to the track you are applying for.
Tip: Replace task based bullets with impact based bullets that show how your work changed outcomes for users or teams.
Recruiter screen
This thirty minute call introduces your background and helps the recruiter understand whether your experience aligns with Atlassian’s product oriented data science culture. Expect questions about your past projects, how you collaborate asynchronously, and what motivates you about working on tools like Jira, Confluence, or Trello. This is also where you clarify timelines, role expectations, and level. It sets the tone for the rest of the process, so communicate clearly and connect your experience to Atlassian’s values.
Tip: Bring one strong project example that demonstrates your ability to convert ambiguity into clear analytical structure.
ML and statistics challenge
This assessment evaluates your ability to manipulate data, design experiments, and communicate assumptions with clarity. You will complete SQL transformations, statistical tests, experiment analysis, and a light modeling task. The goal is not sophistication but clarity, correctness, and thoughtful reasoning. Reviewers focus heavily on how you justify choices and how well you narrate your workflow in an async environment.
If you want structured practice for this stage, Interview Query’s Take-Home Test Prep offers realistic case studies and feedback. Practice take-home tests →
| Focus Area | What It Evaluates |
|---|---|
| SQL and data wrangling | Ability to reason through event data and validate assumptions |
| Experiment design | Skill in setting hypotheses, choosing metrics, and interpreting results |
| Statistical testing | Understanding of distributions, p-values, and test conditions |
| ML modeling | Practical judgment in selecting, training, and evaluating models |
Tip: Explain your thought process as if the reviewer cannot ask follow-up questions. That is exactly how async collaboration works at Atlassian.
Virtual loop
The virtual loop consists of three to five interviews that test how you analyze data, reason about product decisions, work with ambiguity, and communicate with cross functional partners. Each session runs for forty five to sixty minutes and mirrors the questions data scientists tackle in real Atlassian teams.
Below is a typical breakdown of the loop:
| Interview Type | What It Tests | Tip |
|---|---|---|
| SQL or Python Deep Dive | Logic, correctness, query structure, data intuition | Validate intermediate steps aloud before committing to an answer. |
| Experiment Design & Statistics | Metric design, test setup, bias detection, interpretation | State the hypothesis first. Then walk through metrics and risks. |
| Machine Learning or Modeling Round | Feature selection, evaluation, tradeoffs, practical modeling | Focus on clarity and business alignment rather than complex algorithms. |
| Product Sense Case | How you translate vague product questions into analytical plans | Clarify the goal, define success, propose metrics, then prioritize steps. |
| Behavioral and Values Interview | Collaboration, communication, async alignment, ownership | Use concise STAR stories tied to teamwork and customer impact. |
Tip for the loop: Interviewers care about how you think. Narrate your decisions, simplify your reasoning, and link every recommendation to a user or business outcome.
Hiring committee
After the loop, each interviewer submits written feedback tied to consistent dimensions such as technical depth, structured reasoning, product understanding, and values alignment. The hiring committee reviews all feedback to ensure fairness and calibration across teams.
The committee evaluates:
- Whether your technical signals meet the bar for the level
- Whether your communication style fits a remote first, async culture
- Whether your approach to experimentation and modeling aligns with Atlassian’s standards
- Whether there are any gaps that require clarification or an additional short interview
- Whether leveling, scope, and expected impact match the offer being considered
Final decisions are made quickly, and strong candidates often receive updates within a few days.
Tip: If you receive a follow-up clarification round, treat it as targeted reinforcement of your strengths and address any gaps directly.
Challenge
Check your skills...
How prepared are you for working as a Data Scientist at Atlassian?
Atlassian Data Scientist Interview Questions
Atlassian data scientist interviews assess how well you combine analytical depth, statistical reasoning, and product intuition to solve real user and business problems. You will be asked to design experiments, interpret data from Jira and Confluence workflows, evaluate model tradeoffs, and communicate insights clearly in an async-first environment. The questions below mirror the structure and complexity of Atlassian’s actual interviews across SQL, experimentation, modeling, and behavioral storytelling. Use these examples to understand the thinking style Atlassian looks for and the level of clarity expected in each round.
Statistics, experiment design and SQL interview questions
These questions evaluate your ability to query event data, design reliable experiments, choose appropriate statistical tests, and translate ambiguous product questions into measurable frameworks. Atlassian values structured reasoning, clear definitions, and practical assumptions grounded in how users interact with their products.
-
Solve this by grouping employees by department, filtering out departments with fewer than ten people, and computing the percentage of employees above the salary threshold. Use a CASE expression inside an AVG or SUM function, then apply a ranking window function to order the results.
Tip: State your grain and filtering logic upfront to avoid subtle mistakes in percentage calculations.
-
Focus on measurable indicators like lead time, inventory turnover, on-time delivery rate, and forecast accuracy. Explain how each metric connects directly to operational efficiency and customer experience.
Tip: Highlight how you would balance short-term efficiency gains with long-term stability.
Write a query to get the number of customers that were upsold.
Upsells occur when users progress from an initial purchase to a higher-value purchase or additional product. Use grouping and HAVING clauses to identify customers with multiple purchase events or increased transaction amounts.
Tip: Ask clarifying questions about what the business considers an “upsell” before writing SQL.
What are the logistic and softmax functions? What is the difference between them?
The logistic function outputs probabilities between 0 and 1 for binary outcomes, while the softmax function produces a probability distribution across multiple classes. Both functions normalize linear combinations of inputs, but softmax generalizes logistic to multi-class settings.
Tip: When comparing functions, connect the math back to the modeling context.
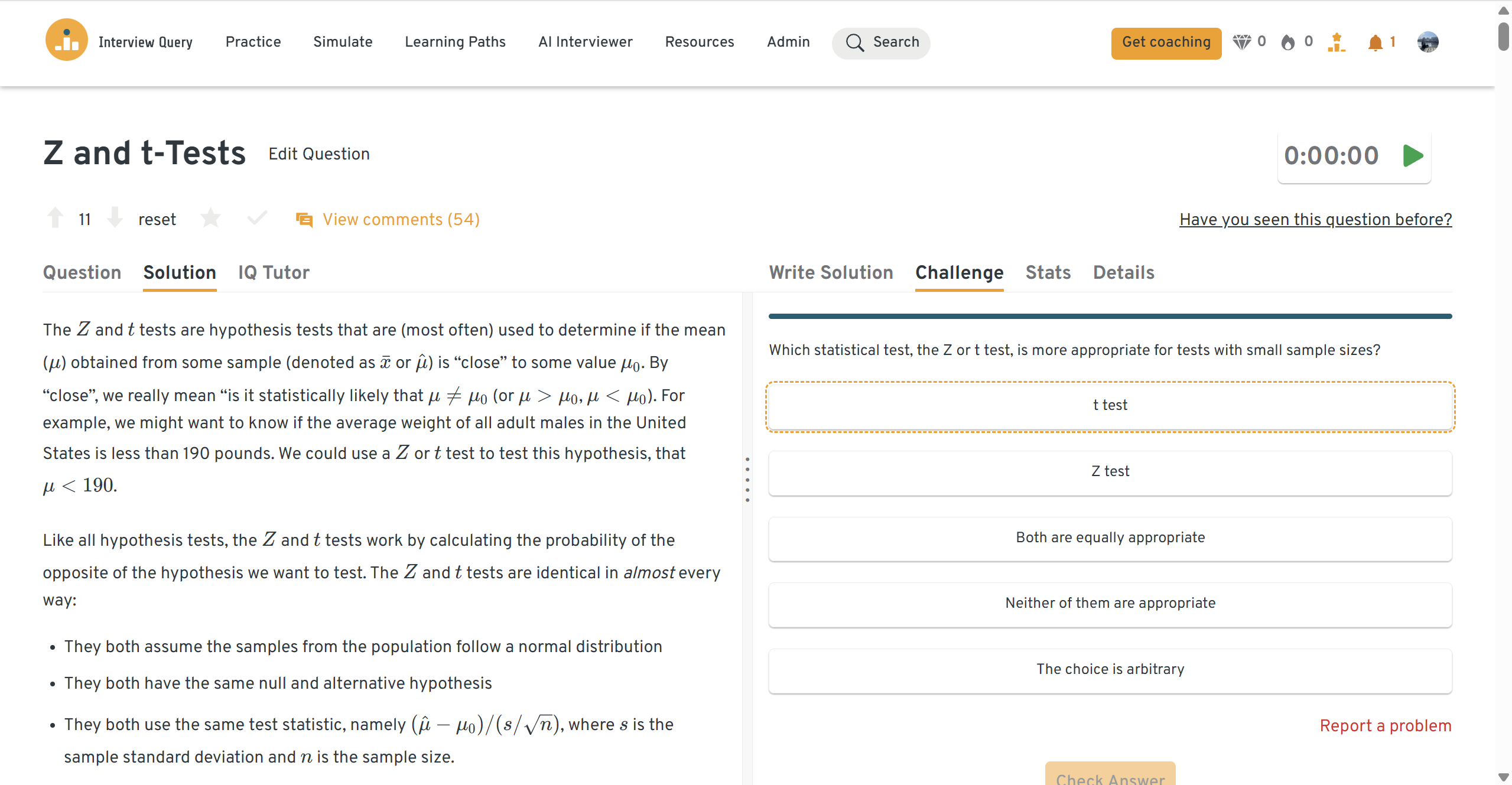
What are the Z and t-tests? What is the difference between them, and when should each be used?
Z-tests rely on the normal distribution and are appropriate for large samples with known variance. T-tests use the t-distribution and are better suited for small samples where variance must be estimated.
Tip: Mention sample size and variance availability first, since they determine which test applies.
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
If you want more practice with realistic SQL and experiment-style problems, explore Interview Query’s SQL Scenario-Based Interview Questions.
Machine learning and modeling interview questions
These questions test whether you can frame modeling problems, weigh tradeoffs, apply practical algorithms, and evaluate model performance in a real product environment. Atlassian prefers grounded, product-aware reasoning rather than overly complex algorithms.
Implement logistic regression from scratch in code.
Use gradient descent or Newton’s method to optimize the log-likelihood and iteratively update coefficients. Treat this as an exercise in matrix operations, convergence logic, and structured modeling.
Tip: Emphasize numerical stability and stopping criteria instead of detailed math.
How would you model merchant acquisition in a new market?
Start by identifying high-signal features like location density, cuisine type, prior demand patterns, and competitor presence. Train a classification model using historic markets as analogues and validate with precision, recall, and ROI metrics.
Tip: Tie the modeling strategy to business objectives such as market expansion or supply balancing.
How would you build a job recommendation feed?
Combine user profiles with job metadata and application histories to construct features for ranking relevance. Use supervised or hybrid recommendation models and evaluate using engagement and conversion metrics.
Tip: Explain how you would address the cold start problem for new users or new jobs.
-
Random forests handle non-linear relationships and diverse features more effectively, making them suitable for heterogeneous markets. Linear regression remains useful when relationships are simple and interpretability is a priority.
Tip: Compare model performance in terms of both accuracy and explainability.
How would we build a bank fraud detection model with a text messaging service?
Use a binary classifier trained on imbalanced transaction data, optimizing for high recall to minimize missed fraud cases. Incorporate techniques such as class weighting, synthetic sample generation, and segmented thresholding by transaction amount.
Tip: Practice describing how you would monitor real-time drift and adjust thresholds over time.
Behavioral and values-driven interview questions
Atlassian’s behavioral interviews assess how you collaborate, communicate, and operate in a remote first, values driven culture. Interviewers look for clarity, structured thinking, and examples that demonstrate ownership, empathy, and measurable impact.
How comfortable are you presenting your insights?
This question evaluates how you communicate findings across engineering, product, and design teams. Strong answers show that you can simplify complexity and adapt to async communication.
Sample Answer: I am very comfortable presenting insights and usually anchor my presentations around one core question before layering supporting evidence. In my last role, I rebuilt our activation deep dive into a narrative dashboard, reducing meeting time by 30 percent and enabling PMs to ship two onboarding improvements that raised week one activation by 5 percent. My goal is always to present data in a way that accelerates decisions.
Tip: Mention how you communicate both synchronously and asynchronously.
What are your strengths and weaknesses?
Interviewers want to understand how you reflect on your working style and improve over time. Focus on strengths tied to collaboration and weaknesses you have created systems to address.
Sample Answer: A key strength of mine is structured communication, which helps teams align quickly during ambiguous work. In my previous role, this reduced clarification cycles with engineering by 40 percent and helped finalize experiment design within one async thread. A weakness I am improving is over-polishing analyses, so I now share 70 percent drafts earlier, which has shortened feedback loops by two days.
Tip: Choose a weakness that demonstrates growth, not a fundamental skill gap.
What are some effective ways to make data accessible to non-technical people?
This assesses how you enable decision making for teams without technical backgrounds. Emphasize clarity, visual storytelling, and removing unnecessary complexity.
Sample Answer: I make data accessible by using annotated dashboards, simple visual metaphors, and recorded walkthroughs to guide teams through insights. I redesigned a KPI dashboard for marketing by grouping metrics into three decision categories, which increased weekly usage from 12 to 46 stakeholders. This change cut their reporting time by 50 percent and contributed to a 9 percent lift in campaign efficiency that quarter.
Tip: Tie your example to a real behavior change or measurable business outcome.
Talk about a time you had trouble communicating with stakeholders. How did you overcome it?
Atlassian wants to see how you reset expectations and clarify ambiguity in a distributed environment. Focus on the adjustments you made and the measurable improvement that followed.
Sample Answer: I once worked with a designer who found my experiment summary too technical, which slowed our alignment. I created a one-page narrative using plain language and visuals, then set up a consistent async update rhythm. This reduced review time from 45 minutes to 15 minutes and allowed us to ship the redesign two weeks ahead of schedule.
Tip: Keep the story focused on process, clarity, and improved collaboration.
Tell me about a time you exceeded expectations during a project.
This reveals initiative and your ability to look beyond the immediate task. Choose a moment with a clearly measurable impact.
Sample Answer: While analyzing churn, I noticed a spike among new teams and conducted an extra segmentation analysis beyond scope. This revealed friction in the issue creation flow, which I flagged along with a proposed fix. After the team implemented the update, new team retention rose by 11 percent over the next release.
Tip: Highlight the unexpected insight and the precise impact it created.
In this video, Jay Feng, co-founder of Interview Query and former data scientist at companies like Nextdoor and Monster, walks through how real data science interviews progress from beginner-level analytics questions to advanced machine learning, product reasoning, and experimentation challenges. He breaks down what interviewers are actually testing, how to structure your thought process, and what separates strong answers from average ones.
Watch it to get a grounded sense of real question patterns and how top candidates communicate their reasoning under pressure.
How to Prepare for an Atlassian Data Scientist Interview
Preparing for an Atlassian data scientist interview means building strength across statistics, SQL, experiment design, machine learning, and product reasoning while aligning your communication style with Atlassian’s remote first culture. The most successful candidates combine technical mastery with clear thinking, structured narratives, and strong values alignment.
Sharpen your SQL foundations with realistic datasets
Atlassian uses event based data from Jira and Confluence, so expect queries involving time series patterns, window functions, segmentation, and funnel logic. Practice querying messy, realistic schemas rather than single-table problems.
Tip: Use Interview Query’s SQL Scenario-Based Questions to prepare with problems that mimic real Atlassian datasets.
Practice designing and analyzing A/B tests
Experimentation is core to the role. Be ready to explain hypotheses, choose metrics, detect bias, and interpret mixed or inconclusive results. Show that you can communicate results clearly and connect them back to user behavior.
Tip: Prioritize clarity. Interviewers want to see strong hypothesis framing and thoughtful metric selection.
Strengthen your Python and ML intuition for product contexts
Atlassian data scientists ship practical models that support ranking, recommendations, automation, and intent detection. Brush up on scikit-learn, feature engineering, model evaluation, and how you would reason about tradeoffs in real product workflows.
Tip: Focus less on complex algorithms and more on how you select, validate, and communicate model choices.
Develop strong product sense for Jira, Confluence, and Trello
You will be asked to evaluate product scenarios, define success metrics, and propose analytical plans for ambiguous prompts. Understanding how teams actually use Atlassian tools gives your answers depth and realism.
Tip: Explore Atlassian’s public documentation and think through how you would measure adoption, engagement, and friction.
Prepare concise STAR stories grounded in impact
Behavioral rounds evaluate how you collaborate asynchronously, communicate clearly, and uphold Atlassian’s values. Use examples that demonstrate ownership, user centered thinking, and measurable results.
Tip: End every STAR story with a number, such as increased activation, reduced review time, or improved model accuracy.
Simulate interview conditions with timed practice
Practicing under realistic constraints helps you build confidence and fluency across SQL, stats, and product reasoning. Mock interviews also help you refine your communication and pacing.
Tip: Use Interview Query’s mock interviews for live feedback from experienced data scientists.
Review Atlassian’s core values and async communication style
Atlassian evaluates cultural alignment closely. Demonstrate transparency, structured thinking, and decision making rooted in user impact. Your communication should be clear, direct, and considerate of remote workflows.
Tip: Show that you can deliver high signal updates through narrative documents and structured written communication.
Study past projects deeply and prepare one polished walkthrough
Expect to discuss one project end to end, including problem framing, data cleaning, modeling choices, experimentation steps, and business impact. Interviewers look for clarity and ownership, not buzzwords.
Tip: Practice a 90 second version and a 3 minute version of your walkthrough so you can adapt to any format.
Average Atlassian Data Scientist Salary
Atlassian data scientists earn competitive compensation across levels, driven by scope, location, and team. According to Levels.fyi, total annual compensation in the United States typically ranges from $168K per year at P30 to $360K per year at P60, with a nationwide median around $276K per year. Stock is a meaningful component of pay, especially at senior and principal levels.
| Level | Total / Year | Base / Year | Stock / Year | Bonus / Year |
|---|---|---|---|---|
| P30 – Junior Data Scientist | ~$168K | ~$132K | ~$33.6K | ~$11.6K |
| P40 – Data Scientist | ~$264K | ~$168K | ~$82.8K | ~$13.2K |
| P50 – Senior Data Scientist | ~$264K | ~$192K | ~$60K | ~$20.4K |
| P60 – Principal Data Scientist | ~$360K | ~$204K | ~$120K | ~$27.6K |
Stock awards vest across Atlassian’s standard schedule, so compensation increases significantly once full vesting begins in year two.
Regional salary comparison
Below is a consolidated view of typical data scientist compensation across major Atlassian hubs.
| Region | Salary Range (Annual Total Comp) | Notes | Source |
|---|---|---|---|
| United States (overall) | $168K – $360K | National data for P30 to P60 levels; median ~$276K. | Levels.fyi |
| San Francisco Bay Area | $180K – $384K | Highest-paying region; significant stock weighting at senior levels. | Levels.fyi |
| Greater Austin Area | $252K – $336K | Strong compensation for P50 and P60 roles; limited junior-level data. | Levels.fyi |
| New York City Area | $132K – $288K | Wider bands due to mixed team structures; fewer principal-level reports. | Levels.fyi |
Average Base Salary
Average Total Compensation
The key takeaway: Atlassian salaries scale sharply with seniority. Moving from P30 to P60 more than doubles total compensation, driven largely by increases in stock. For candidates evaluating long-term upside, leveling accurately and targeting the right scope of role has a substantial impact on total earnings.
FAQs
How long does the Atlassian interview process take?
Most candidates move through the process in three to five weeks, depending on scheduling and the complexity of the ML or stats challenge. Feedback is typically fast, with many candidates receiving updates within 24 to 48 hours after each stage.
What technical topics should I focus on most?
Atlassian focuses heavily on SQL, experiment design, product metrics, and end to end problem solving. Expect questions on time series analysis, A/B testing, statistical reasoning, and lightweight machine learning using Python.
Do I need experience with Jira or Confluence to interview?
You do not need prior experience using Atlassian products, but understanding how teams use Jira, Confluence, and Trello helps strengthen your product intuition. Reviewing public product docs and thinking through key workflows will help you provide more grounded answers.
Are take home challenges common?
Yes, many candidates complete a small ML or statistics challenge that takes 4 to 6 hours. These assessments evaluate your clarity of thought, coding style, experiment logic, and ability to communicate assumptions in an async environment.
Are there intern or early career opportunities?
Atlassian offers data science internships through its Grad++ and early career programs. You can browse open roles on the early careers page.
What is the average salary for a data scientist at Atlassian?
In the United States, total compensation for Atlassian data scientists typically ranges from $168K to $360K per year, depending on level and location. According to Levels.fyi, the nationwide median sits around $276K per year, with stock forming a meaningful share of senior-level packages.
Do data scientists at Atlassian work closely with engineers and PMs?
Yes. Atlassian data scientists partner closely with product managers, designers, and engineers to define metrics, shape experiments, and ship ML powered features. Collaboration is heavily async, so clarity in documentation and communication is key.
How important is experimentation experience for this role?
Very important. A/B testing and experiment analysis appear frequently across teams, especially for Jira, Confluence, and AI features where user behavior changes quickly. Demonstrating comfort with power analysis, guardrails, and interpreting ambiguous outcomes will help you stand out.
What kind of ML work do Atlassian data scientists usually own?
Most ML work focuses on ranking, recommendations, forecasting, and NLP driven workflows that support Jira issues, Confluence pages, and customer support agents. While Atlassian has specialized ML teams, generalist data scientists often build prototypes, evaluate models, or define
Turn Your Preparation Into a Competitive Advantage
Atlassian’s data science interview rewards candidates who think like product strategists, not just analysts. The people who stand out are those who can connect statistical rigor with real user impact and who can articulate their reasoning with the clarity that async teams rely on. If you can show that blend of analytical discipline and product intuition, you immediately rise above the noise in a competitive hiring cycle.
To build that edge, work through the data science learning path and reinforce your judgment with real-world prompts from our data science case study question bank. When you are ready to test your thinking under pressure, schedule mock interviews to simulate the depth and pacing of an actual Atlassian loop. Treat your preparation like a skill you are sharpening, and you will walk into the interview with confidence that feels earned—not improvised.
Atlassian Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Easy | |||||||||||||||||||||||
Write a SQL query to select the 2nd highest salary in the engineering department. Note: If more than one person shares the highest salary, the query should select the next highest salary. Example: Input:
Output:
| ||||||||||||||||||||||||
Data Structures & Algorithms | Medium | |||||||||||||||||||||||
Data Structures & Algorithms | Medium | |||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences