

Google Data Engineer Interview Guide, Process, Questions, and Real Experiences


Introduction
For the first time in over a decade, Google’s search market share has slipped below 90%, a small dip that signals a major shift in how people search. Rather than slowing down, Google is evolving fast. With more than 58% of searches now ending in zero clicks, the company is pouring over $75 billion into AI and data infrastructure to stay ahead.
This transformation has opened up exciting opportunities for data engineers. If you’re preparing for a Google Data Engineer interview, you’ll need to demonstrate not just technical skill but also analytical thinking and real-world problem-solving. In this guide, we’ll walk through the interview process, the most commonly asked questions, and real insights from candidates who’ve been through it, so you can prepare with clarity and confidence.
Google Data Engineer Interview Process
The interview is structured to assess both your technical depth and how you think through complex, real-world data challenges. The process usually spans four to five stages, each testing a different aspect of what it takes to be a successful data engineer at Google. Expect the entire process to take anywhere between four to eight weeks, depending on scheduling and team-matching timelines.
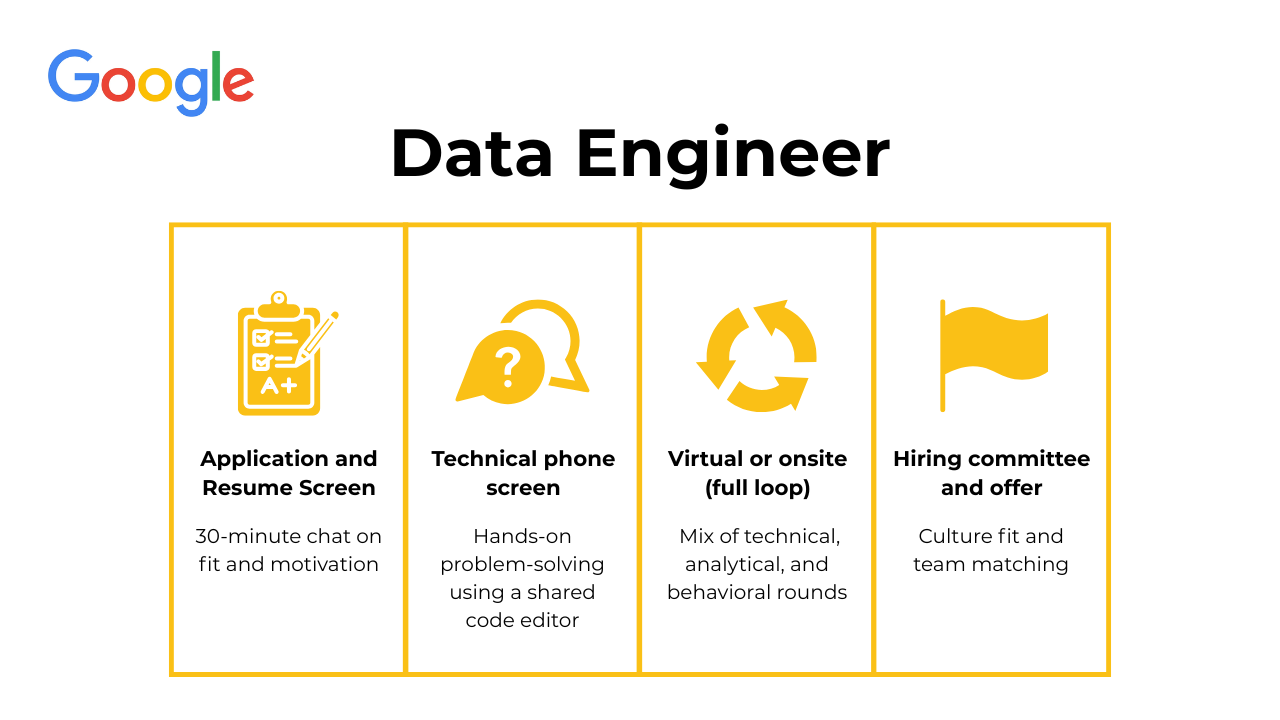
Application submission
The journey starts when you apply through Google Careers or an employee referral. While online applications are reviewed by recruiters and Google’s Applicant Tracking System (ATS), referrals significantly increase visibility and chances of being shortlisted. Make sure your resume emphasizes measurable impact, strong SQL or Python experience, and large-scale data projects.
Tip: Tailor your resume to the specific role by including keywords like “ETL pipelines,” “BigQuery,” and “data modeling.” Recruiters scan for these during the initial screen.
Recruiter/resume screen
If your application passes the first filter, a recruiter will reach out for a 30 to 45-minute call. This stage focuses on your background, technical familiarity, and behavioral alignment with Google’s values. They might ask about your previous projects, why you want to work at Google, and your understanding of data engineering fundamentals. At this stage, recruiters do not dive deep into coding questions but want to confirm that you meet the baseline requirements.
Tip: Be concise but confident. Use the STAR method to structure responses when discussing past projects. Recruiters appreciate clarity over jargon.
Technical phone screen
The technical phone interview is the first deep dive into your problem-solving skills. It usually involves one or two 45 to 60-minute sessions conducted by Google engineers. You will share a collaborative Google Doc or use an in-browser code editor to write SQL queries or Python code. Expect questions on data structures, algorithms, SQL joins, ETL pipeline design, and data wrangling. Some candidates also report system design-style questions that test optimization logic.
For example, you might be asked to optimize a query for a trillion-row dataset or explain how you would handle data skew in distributed systems. The interviewer will focus on both correctness and clarity of thought.
Tip: Practice writing code without syntax highlighting to mimic the real interview setup. Focus on explaining your logic step by step as you write.
Virtual or onsite (full loop)
Once you pass the phone screen, you will be invited to the virtual or onsite loop, which typically includes four to five interviews. Each lasts about 45 to 60 minutes and tests different competencies across technical and behavioral domains.
Here is what the loop usually looks like:
Coding round: You will solve SQL or Python problems that simulate real data challenges at Google. Expect medium to hard difficulty problems related to joins, aggregations, and performance optimization.
Tip: Practice Google data engineer interview questions on window functions and time-series data. Explain your trade-offs and check for efficiency.
System design round: This round evaluates how you build scalable data systems. You may be asked to design a pipeline that processes streaming data or explain how you would create a data lake for global users. Tools like BigQuery, Dataflow, Pub/Sub, and Cloud Composer often come up.
Tip: Focus on scalability, fault tolerance, and cost efficiency. Interviewers appreciate when you reason through trade-offs rather than jumping to specific tools.
Data modeling or architecture round: Expect questions about schema design, normalization, and partitioning strategies. You might be asked to model event logs for YouTube or define metrics for Ads reporting.
Tip: Keep simplicity in mind. Overengineering is a common pitfall. Show that you can design systems that are efficient and easy to maintain.
Behavioral and collaboration round: This is where Google evaluates teamwork, adaptability, and communication. You will answer scenario-based questions like how you handled pipeline failures or influenced stakeholders.
Tip: Use the STAR method and always link your results back to business impact. Highlight collaboration with engineers, data scientists, and PMs.
What to expect overall: The loop tests both technical mastery and communication under pressure. Candidates who perform best are those who can clearly explain their reasoning while writing efficient, scalable solutions.
Hiring Committee & Offer
After completing the interviews, all feedback is compiled and reviewed by a hiring committee. This ensures fair and consistent evaluation across candidates. The committee looks at technical performance, communication, leadership potential, and overall fit for the data engineer Google interview role.
If approved, you move to team matching, where you are introduced to potential managers whose teams are hiring. This step can take anywhere from two to six weeks. Once a match is made, Google will extend a formal offer that includes your base salary, bonus, and equity.
When negotiating, remember that Google expects data-driven reasoning. Research average total compensation for your level using resources like Levels.fyi or Glassdoor. Be respectful but firm about your expectations. It’s also common to discuss location-based adjustments if you are interviewing for hybrid or remote roles.
Tip: During negotiation, focus on long-term value. Equity refreshers and annual bonuses can make a substantial difference, so ask about how performance affects future compensation.
Need 1:1 guidance on your interview strategy? Interview Query’s Coaching Program pairs you with mentors to refine your prep and build confidence. Explore coaching options →
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Google?
What Questions Are Asked in a Google Data Engineer Interview?
The interview is built to test how well you can design, optimize, and maintain large-scale data systems that keep Google’s products running seamlessly. Beyond technical coding challenges, you will be evaluated on how you think about data architecture, efficiency, and collaboration across teams.
You can expect a combination of SQL and coding questions, system and data architecture design problems, and behavioral or collaboration scenarios. These question types aim to reveal not just your technical depth but also your ability to make trade-offs, reason through ambiguity, and communicate complex ideas clearly.
Each section below breaks down the main types of Google data engineer interview questions, complete with detailed explanations, sample answers, and preparation tips drawn from real Google data engineer interview experiences.
Coding/SQL Questions
This section of the Google data engineer interview evaluates how you think with data. Expect a mix of SQL queries, logic puzzles, and data manipulation tasks that test both accuracy and efficiency. The interviewer wants to see if you can write clean, optimized code, explain your reasoning clearly, and apply database principles to large-scale, real-world problems. You may also encounter BigQuery interview questions that simulate working with Google-sized datasets.
-
Join the
employeesanddepartmentstables to combine department names with salary data. Group by department, apply aHAVINGclause to filter those with ten or more employees, and use aCASE WHENstatement inside anAVG()function to find the percentage earning over 100K. Sort the output by this percentage and limit it to the top three results.Tip: Explain why you use certain clauses and indexes. Interviewers look for candidates who can reason through design choices rather than just writing the query.
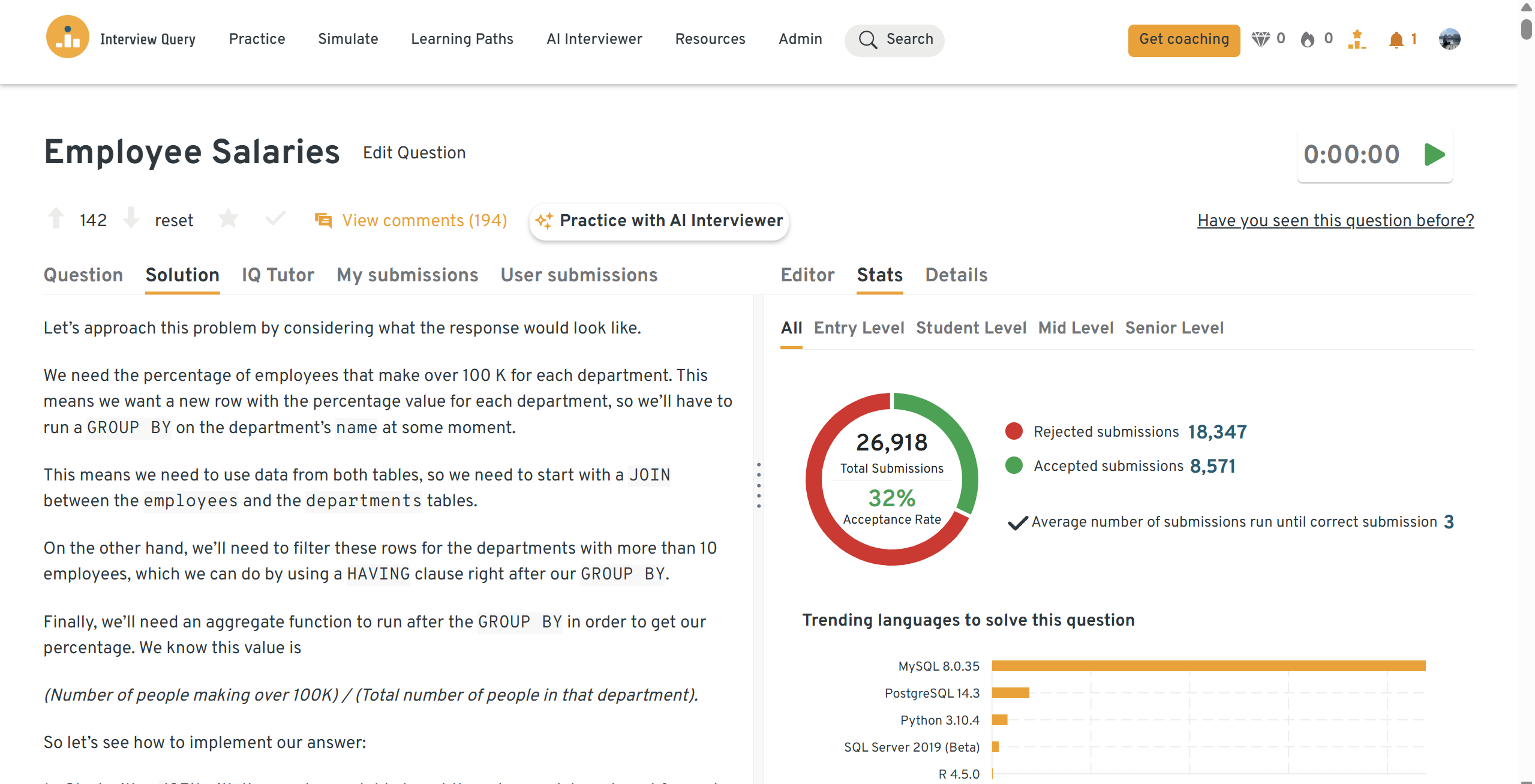
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
-
Use a LEFT JOIN between the
usersandcommentstables so that users with zero comments are still counted. Filter by the January 2020 date range, group by user ID to get the number of comments per user, then group again by that count to get the frequency distribution.Tip: Mention how this query can reveal engagement trends or anomalies. Connecting your technical solution to a real business use case makes your answer stronger.
Given a users table, write a query to return only its duplicate rows.
Use a window function such as
ROW_NUMBER()orCOUNT()with aPARTITION BYclause on the key columns that define uniqueness. Then filter for rows where the count or row number is greater than one to isolate duplicates.Tip: Clarify what defines a duplicate before starting. This shows structured thinking and helps you avoid making assumptions during the interview.
Write a SQL query to select the 2nd highest salary in the engineering department.
Join the
employeesanddepartmentstables, filter for the engineering department, and useDENSE_RANK()to rank salaries in descending order. Select the record where the rank equals two.Tip: If asked to optimize, explain why window functions are more efficient than subqueries for ranking operations in systems like BigQuery.
Write a function to sample from a truncated normal distribution.
Compute the truncation limits using the inverse cumulative distribution function (CDF) or percent-point function (PPF). Generate samples from a normal distribution, then filter out values outside the defined range to achieve truncation.
Tip: If you use Python or SQL for this, highlight the importance of reproducibility and performance. Interviewers value precision over fancy libraries.
-
Group by both date and user ID to count daily conversations, then group again by that count to calculate the distribution. This gives you the frequency of users who created a certain number of conversations each day.
Tip: Discuss how this type of query can be integrated into reporting pipelines. Linking your answer to monitoring or analytics adds depth to your reasoning.
Want more challenges? Test your skills with real-world analytics challenges from top companies on Interview Query. Great for sharpening your problem-solving before interviews. Start solving challenges →
System/data architecture design questions
This part of the interview tests how you approach building systems that handle data at Google scale. You’ll be asked to design solutions that are reliable, cost-efficient, and easy to maintain. The goal is to see whether you can think like a systems architect, balancing trade-offs, explaining your reasoning clearly, and ensuring data remains accurate and accessible.
Expect open-ended questions that let you explore how you would structure pipelines, model data, or integrate Google Cloud tools like BigQuery, Pub/Sub, and Dataflow. Always walk the interviewer through your design step by step instead of jumping straight to tools.
Design a solution to store and query raw data from Kafka on a daily basis.
Start by ingesting data from Kafka into a scalable storage solution like Cloud Storage or BigQuery using Dataflow or Apache Beam. Partition data by day to optimize query performance and cost. Schedule jobs with Cloud Composer to handle daily ingestion and data cleanup. Include monitoring to track pipeline health and late-arriving data.
Tip: Highlight how your design can scale with growing data volume. Interviewers like when you consider both performance and long-term maintenance.
How would you build an ETL pipeline to get Stripe payment data into the database?
Start by pulling raw data from Stripe’s API using scheduled extract jobs. Transform and clean the data with Dataflow or PySpark before loading it into BigQuery for analysis. Include logging, validation, and schema checks to ensure accuracy. Finally, schedule these jobs with Cloud Composer and monitor them with Cloud Monitoring.
Tip: Discuss error handling and retries. Showing how you deal with API limits or data drift demonstrates maturity in production-level data engineering.
How would you design the YouTube video recommendation system?
Frame this as a data flow problem. Collect user engagement events like views, likes, and watch duration through Pub/Sub. Store raw data in BigQuery and use Dataflow to preprocess it into features for the recommendation model. Feed these features into a training pipeline managed by Vertex AI or TensorFlow. For serving recommendations, design a real-time layer that updates as users interact.
Tip: Keep your answer focused on data engineering, not model design. Explain how your pipelines enable fast and accurate recommendations at scale.
How would you design a multi-region data replication strategy on GCP? What architectural patterns would you use to ensure high availability and disaster recovery? How would BigQuery’s multi-region datasets and Cloud Storage replication support this, and how would you handle consistency and failover?
Use BigQuery multi-region datasets to automatically replicate data across regions and Cloud Storage dual-region buckets for redundancy. Choose between active-active for real-time sync or active-passive for backup recovery depending on business needs. Implement monitoring with Cloud Monitoring and automate failover detection using Pub/Sub notifications or Cloud Functions.
Tip: When explaining your design, discuss trade-offs. Active-active systems reduce downtime but raise costs, while active-passive systems are cheaper but slower to recover.
How can you orchestrate a reliable ETL workflow using Cloud Composer, Dataflow, and BigQuery? How would you manage task dependencies, implement retries, and ensure data validation? What monitoring and alerting tools would you use to maintain workflow health?
Set up Cloud Composer (Airflow) as the workflow manager. Use Dataflow for transformation tasks and BigQuery as the final data warehouse. Define dependencies with Airflow DAGs, add retries for transient failures, and validate data through schema checks or row counts before loading. Monitor each task using Cloud Monitoring and trigger alerts when metrics fall outside thresholds.
Tip: Explain how you would isolate and recover from job failures. For instance, partial reruns or task-level retries show that you think about resilience in production systems.
Behavioral & collaboration questions
The behavioral portion of the Google data engineer interview explores how you think, communicate, and collaborate in complex, high-pressure situations. Google looks for engineers who not only excel technically but also demonstrate humility, adaptability, and strong problem-solving skills in team settings.
Expect open-ended questions about communication challenges, decision-making, and leadership moments. Each answer should tell a story: what happened, what you did, and what changed because of your actions. Use the STAR method (Situation, Task, Action, Result) and always include measurable outcomes.
What do you tell an interviewer when they ask you what your strengths and weaknesses are?
This question assesses your self-awareness and growth mindset. Google looks for engineers who can reflect honestly on their capabilities and show how they’ve improved over time. Choose a strength that aligns with the company’s values, such as efficiency, collaboration, or analytical thinking, and a weakness that you have already worked on addressing. Avoid superficial answers like “I’m a perfectionist” unless you can show what you have done to manage it effectively.
Sample Answer: In my previous role, I became known for my ability to optimize large SQL queries and reduce load times for analytics dashboards. One of my solutions shortened query time from 45 minutes to just 12 minutes, improving reporting access for more than 200 users weekly. However, I realized that I often deprioritized documentation while focusing on optimization. To improve, I started implementing shared templates and peer reviews, which increased project handover efficiency by 30 percent and reduced dependency bottlenecks across teams.
Tip: Balance confidence with honesty. Acknowledge your weakness without undermining yourself, and always describe specific actions you took to improve.
-
This question helps recruiters understand your motivation and whether you’ve done your homework about Google’s mission and culture. Focus on the alignment between your career goals and Google’s approach to solving large-scale data problems. Avoid generic answers like “I want to work with smart people.” Instead, speak to specific technologies, challenges, or values that resonate with you.
Sample Answer: I’ve long admired Google’s commitment to building scalable data systems that empower billions of users. During my time managing analytics infrastructure at a fintech startup, I worked with BigQuery and Dataflow to streamline daily data refreshes, reducing dashboard latency by 35 percent. I was drawn to Google because of its scale and its focus on improving access to information globally. I want to contribute to systems that not only manage massive data but also make it meaningful to millions of users every day.
Tip: Connect your past experience to Google’s work. Showing familiarity with the company’s tools and impact areas immediately makes your answer more credible.
Describe an analytics experiment that you designed. How were you able to measure success?
This question examines your analytical thinking, ability to define measurable goals, and follow-through in evaluating results. The interviewer wants to see that you understand both the technical side of running experiments and the strategic reasoning behind measuring their success. Always highlight the metrics that define improvement and explain how your findings influenced decisions.
Sample Answer: In my last role, I led an A/B test comparing two ETL pipeline designs to reduce data processing latency. The main goal was to improve dashboard refresh rates and overall reliability. I tracked success using two KPIs — pipeline runtime and data freshness. After a two-week run, the optimized approach reduced lag from 18 minutes to 5 minutes and improved data completeness by 22 percent. The results were later adopted as the new pipeline standard, which decreased downstream reporting errors by 15 percent across the organization.
Tip: Focus on how your experiment influenced broader business or technical outcomes, not just how you wrote the code.
-
This question gauges your emotional intelligence and ability to adapt communication for different audiences. Google values engineers who can explain technical issues clearly to non-technical partners. Discuss a real scenario where miscommunication occurred and how you took initiative to improve collaboration through visualization, documentation, or proactive updates.
Sample Answer: While working on a data quality monitoring project, I noticed frequent misalignment with the product team regarding data delivery timelines. They found my technical updates too complex to interpret, leading to confusion about when data would be available. To fix this, I created a simplified Data Studio dashboard showing real-time pipeline status and alert triggers. This reduced status meeting time by 40 percent, increased on-time deliverables by 15 percent, and was later adopted as a reporting model for other teams.
Tip: Show ownership. Instead of blaming miscommunication on others, focus on the proactive steps you took to resolve it and how it improved overall collaboration.
After reviewing the main Google data engineer interview questions, it helps to see how they play out in practice. In this video, Jay Feng, co-founder of Interview Query, walks through more than ten essential data engineer interview questions and answers to help you prepare with confidence. Whether you are just starting out or gearing up for your next interview, these examples show how to approach both technical and behavioral questions asked at leading tech companies.
Average Google Data Engineer Salary
Google data engineers in the United States earn some of the most competitive pay packages in the industry, reflecting their critical role in designing and maintaining Google’s large-scale data infrastructure. According to Levels.fyi, total annual compensation ranges from approximately $164K per year for L3 engineers to $358K per year for L6 staff engineers, with the median total compensation averaging around $275K annually. Compensation includes a mix of base salary, stock grants, and annual bonuses that increase with seniority and performance.
- L3 (Entry-Level Data Engineer / SWE II): $164K per year ($120K base + $35K stock + $10K bonus)
- L4 (Data Engineer / SWE III): $252K per year ($180K base + $66K stock + $12K bonus)
- L5 (Senior Data Engineer / Senior SWE): $290K per year ($190K base + $68K stock + $16K bonus)
- L6 (Staff Data Engineer / Staff SWE): $358K per year ($228K base + $97K stock + $22K bonus)
Regional salary comparisons
Compensation for Google data engineers varies significantly by region, primarily due to living costs and local market competitiveness.
- San Francisco Bay Area: Median total compensation is $283K annually, with strong stock components making up a large share of total pay. Base salaries range from $150K to $200K, depending on level. (Levels.fyi)
- New York City: Data engineers earn around $245K per year on average, with slightly higher base pay but lower stock compared to Bay Area packages. (Levels.fyi)
- Greater Austin Area: Median compensation averages $240K per year, with base salaries around $120K and a balanced mix of stock and cash bonuses. (Levels.fyi)
Average Base Salary
Average Total Compensation
Google’s compensation strategy rewards technical excellence, leadership, and long-term contribution. Engineers receive recurring stock grants and annual performance bonuses, with equity typically representing 25 to 30 percent of total pay. Stock vests quarterly, and refreshers are awarded annually to maintain long-term alignment with company growth.
FAQs
Is the Google data engineer interview hard?
Yes, the Google data engineer interview is known for its technical depth and fast-paced problem-solving. The challenge lies in balancing coding accuracy with clear communication. Questions often involve optimizing SQL queries, designing data systems, and reasoning about scalability on tools like BigQuery or Dataflow.
How long does the Google data engineer interview process take?
The process usually takes four to eight weeks from recruiter screen to final offer. After the initial phone interviews, successful candidates move on to a virtual onsite loop that covers SQL, system design, and behavioral collaboration. A hiring committee then reviews feedback before team matching begins.
What data engineering skills should I focus on for the Google interview?
Prioritize SQL, Python, data modeling, and GCP tools like BigQuery, Dataflow, and Pub/Sub. You should also understand ETL design, data validation, and schema optimization. Strong communication and clear reasoning are equally important, especially when explaining design trade-offs to interviewers.
What kind of questions are asked in a Google data engineer interview?
Expect a mix of SQL and coding questions, data architecture design prompts, and behavioral scenarios. Topics include writing efficient queries, designing ETL pipelines, modeling real-time data, and troubleshooting system bottlenecks. Reviewing BigQuery interview questions or real data engineer assessment examples helps you anticipate these patterns.
How can I practice Google data engineer interview questions effectively?
Work through real questions on Interview Query and simulate coding sessions using a shared Google Doc or plain text editor. Recreate pipelines using BigQuery public datasets and time yourself for each exercise. Finish by scheduling mock interviews to refine your structure and communication.
Are there remote or hybrid options for Google data engineers?
Yes. Many data engineer Google roles support hybrid work depending on the team and project sensitivity. Most engineers are based in hubs like the Bay Area, Seattle, Austin, and New York City, but some teams offer fully remote options for experienced hires.
What is the growth path for data engineers at Google?
Data engineers typically advance from L3 to L6, progressing from building pipelines to leading large-scale data strategy. Many later transition into machine learning, data science, or platform engineering roles. Career growth is tied to technical excellence, impact on scalability, and collaboration across Google’s global data teams.
What are the compensation levels for Data Engineers at Google?
According to Levels.fyi, the average total compensation for a data engineer at Google is about $275K per year, ranging from $164K for entry-level (L3) to $358K for staff-level (L6) engineers. Pay packages include base salary, stock grants, and performance bonuses. Compensation also varies by region, with the Bay Area averaging $283K and New York City around $245K.
Your Next Step Toward Becoming A Google Data Engineer
Breaking into Google as a data engineer takes more than strong technical skills—it requires clarity, structure, and the ability to solve real-world problems with precision. Each round of the Google data engineer interview challenges you to think like a systems architect, balance trade-offs, and communicate clearly under pressure. With the right preparation, these interviews can turn from intimidating to achievable.
Build your momentum by practicing Google data engineer interview questions on Interview Query, scheduling mock interviews for live coaching, or following the data engineering learning path. The more realistic your prep, the more confident you’ll feel when it counts. Your next interview could be the one that launches your career at one of the most data-driven companies in the world.
Google Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Brainteasers | Medium | |
When an interviewer asks a question along the lines of:
How would you respond? | ||
Brainteasers | Easy | |
Analytics | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |