
How to Transition from a Data Analyst to Data Engineer in 2025


Overview
As the data science field matures, the distinction between data roles has grown sharper, allowing more standard classification. While the roles of data analyst, data scientist, and data engineer are still somewhat similar, each require specialized knowledge that significantly alter the skillsets required. A migration has been underway for some time, as people realign their skills and goals with these more distinct fields.
One of the most common transitions we are seeing is the shift from data analyst to data engineer. This requires a shift not only in technical skills, but also in foundational knowledge and mindset, as each role interacts with different parts of the data pipelines. In this blog, we look at the differences between the data analytics and data engineering roles, as well as the implications of a transition from one role to another.
What does a data analyst do?
A data analyst focuses on processing structured data, typically queried from a database or cleaned from a data pipeline. A data analyst’s job is to provide insights from the data, often through visualizations. Data analysts have an additional important function, they must translate their findings to non-technical stakeholders inside and outside the organization. Data is only useful if it can be understood.
Data analysts work with a range of tools, including Excel, SQL, as well as data visualization platforms like MatPlotLib or PowerBI. They require proficiency in both statistical and data manipulation skills. Let’s take a look at a data pipeline and break down where a data analyst will be most active:
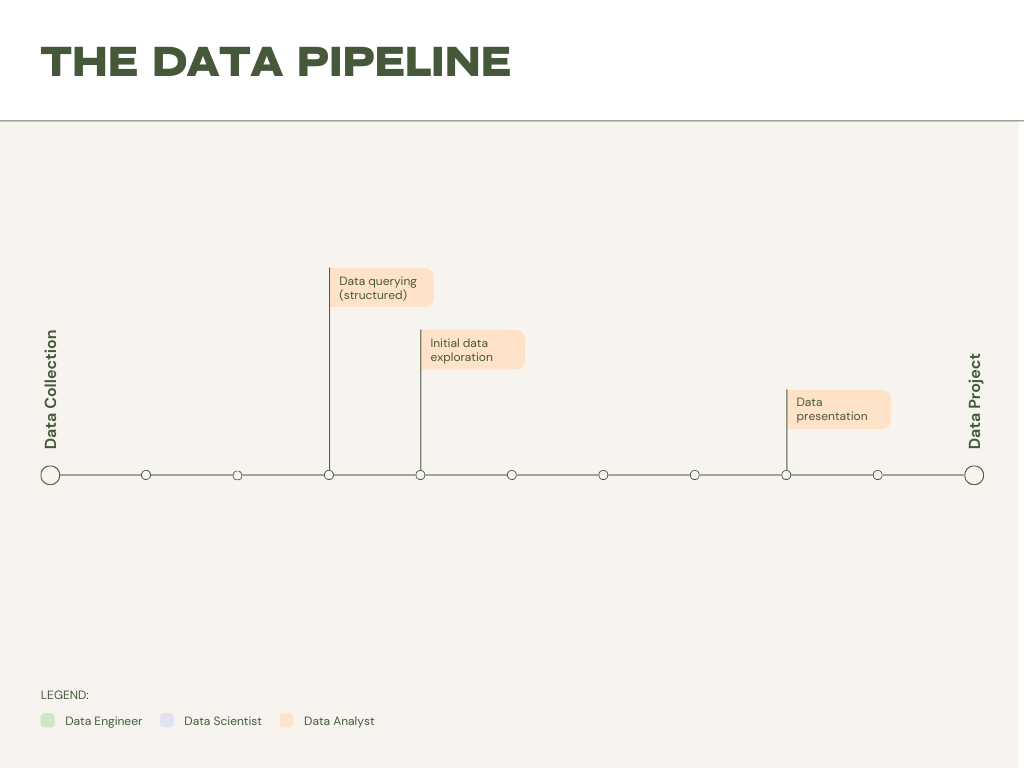
As you can see, the data analyst plays crucial roles in the following tasks:
- Data Querying: A data analyst processes cleaned and loaded data from data marts or data warehouses and loads them to their local environment. This is to prepare the data for exploration.
- Initial Data Exploration: Data can now be examined and observed. Possible patterns, anomalies, and areas of interest are identified in this stage of the data pipeline. For example, a dataset of supermarket sales might benefit from an analyst’s application of association analytics, in order to reveal which items are often purchased together. At this stage you are not exploring the data in order to answer a specific question, but rather in order to formulate an idea of the general connections between data. Exploration often involves looking for areas of interests, where the data team might investigate further and potentially build out data products.
- Data Presentation: Data analysts are often responsible for the data presentations. This is why most people in the field describe data analytics as much a “data” and “statistics” job as it is a “people” job. Being able to present data findings, and effectively explain how these impact the business, is crucial to the role. Being knowledgeable in both the numbers and the communication can be difficult, and explaining complex concepts in simple words is even more challenging. For just a bit more pressure, the presentation is one of the last steps in completing a project, and so proves critical to getting across the finish line.
More about data analyst:
What does a data engineer do?
Data engineers are responsible for creating and maintaining the architecture (databases and large-scale processing systems), pipelines, and data sets that data analysts and data scientists use in their work. These professionals are skilled in data warehousing solutions, and they ensure data is clean, reliable, and easily accessible. Let’s delve into the specifics of a data engineer’s role:
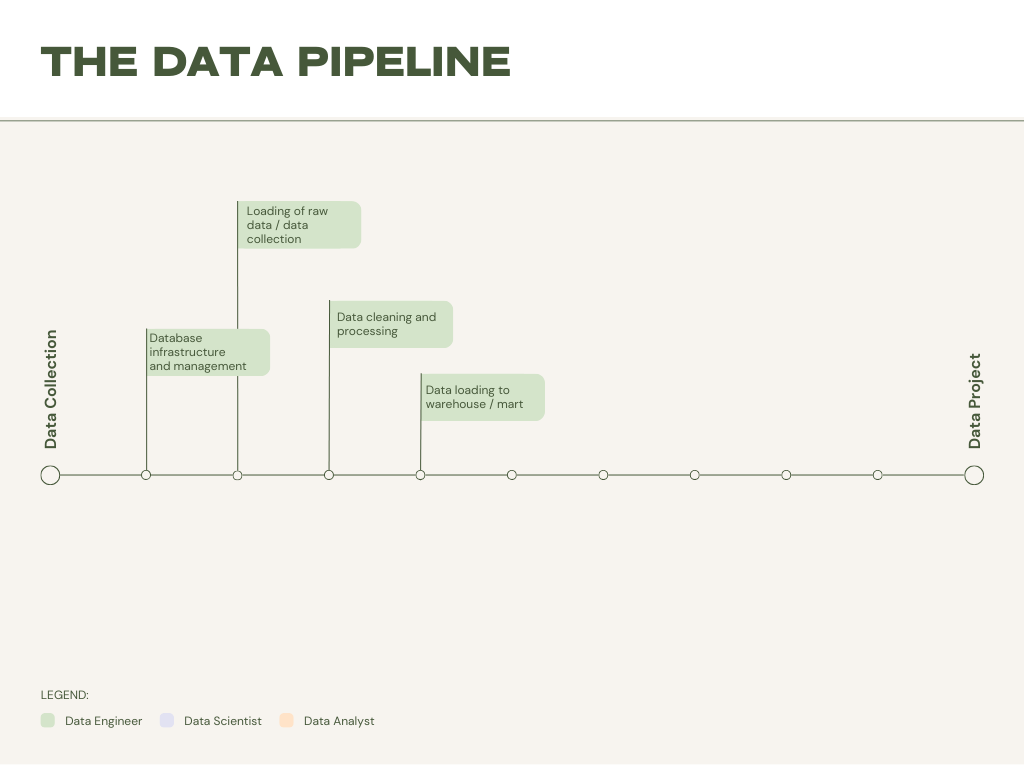
- Database Infrastructure and Management: In this first step, data engineers design, implement, and manage the databases that will store data. These could be relational databases like MySQL or PostgreSQL, or non-relational databases such as MongoDB or Cassandra. Databases are built to be scalable, optimized for performance, and maintain security standards.
- Loading of Data / Data Collection: At the second stage, data engineers are responsible for creating mechanisms to gather and load raw data from various sources into the databases. These mechanisms involve setting up web trackers, integrating with third-party APIs, or collecting data from internal systems. The data might then be loaded in batches or streamed in real-time, depending on the source or requirements.
- Data Cleaning and Processing: Raw data is rarely perfect. It often contains inaccuracies, duplications, or gaps. Data engineers craft processes to clean, transform, and enrich this data. This can encompass activities like normalizing data formats, filling in missing values, and generating new data features based on existing information.
- Data Loading to Warehouse/Mart: After the preliminary cleaning and processing, the data is ready to be moved into a data warehouse or data mart. These are specialized storage structures optimized for analysis. Data engineers create and manage the ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) pipelines to transport data seamlessly to these systems.
Check out our data engineering learning path!
More about data engineering:
What’s the difference between Data Analytics and Data Engineering?
Data analytics and data engineering are two distinct facets of the broader data landscape.
An analyst, armed with tools like SQL, Excel, and Tableau, dives deep into structured data to produce actionable insights. Their primary objective is to make sense of the data and to present it in a way that drives informed business decisions. An emphasis on communication skills is paramount, as translating complex data into understandable narratives is crucial.
Conversely, a data engineer’s realm is the back-end infrastructure. Their challenge lies in ensuring the data’s journey—from raw, unstructured form to a clean, usable state—is effective at scale. Using technologies like Hadoop, Spark, and various database systems, they lay the groundwork for analysts and data scientists. Their focus extends beyond just data storage, it also encompasses data integrity, reliability, and accessibility.
In essence, while analysts shine a light on the “what” and “why” through their insights, engineers craft the “how” by building robust data foundations. Transitioning between these roles means navigating between the nuanced challenges of data interpretation and infrastructure development.
We will now examine the education and experiences that best complement that transition.
What education do I need to become a Data Engineer when coming from a Data Analytics background?

Transitioning from a data analytics background to a data engineering role, via formal education, necessitates a multi-faceted approach.
Firstly, while many data analysts have varied educational backgrounds, data engineering careers will benefit heavily from bachelor’s degrees in Computer Science, Information Systems, or a related field. If you are coming from an unrelated degree field, some universities now cater to this transition by offering “bridge” programs or post-baccalaureate courses. These programs aim to fill foundational gaps and equip students with essential computer science knowledge.
Secondly, for a more specialized and in-depth understanding, considering a master’s degree in Data Engineering or Big Data Analytics can be a strategic move. Offered by several renowned institutions, these programs delve deeper into data architecture, storage, and processing—core areas of data engineering. An advanced degree in this area not only bolsters one’s theoretical knowledge but can also provide a competitive edge in the job market. These courses are not required to be a successful data engineer however.
Lastly, irrespective of one’s familiarity with SQL or database systems from an analytics background, undertaking formal courses in Database Management can be beneficial. A stronger grasp of advanced database concepts is a cornerstone of a data engineer’s skillset, and formal training in this domain ensures proficiency.
Case Study
Two people are looking to transition to data engineering:
Alex comes from a Computer Science background and has experience in data analytics within a tech firm. His strengths lie in programming, system design, and database management.
Jordan, on the other hand, studied Business Administration with a minor in Data Analytics. He worked as a data analyst for a retail chain and brings strong business domain knowledge and insights generation from data.
In transitioning to a Data Engineering role:
- Alex has an advantage with his computer science foundation. The data structures, algorithms, and database courses he took would be directly relevant to building, maintaining, and optimizing large-scale data pipelines and infrastructures. If Alex further refines his skills in distributed systems, cloud platforms, and big data technologies, he could make a smoother transition to data engineering.
- Jordan, on the other hand, would need to invest more time in understanding the technological nuances of data engineering. While his business acumen is valuable (especially in roles that bridge business and tech, like a data analyst or data product manager), data engineering leans more heavily on technical prowess. However, if Jordan undertakes courses in Database Management, distributed systems, and cloud computing (coupled with his domain expertise), he might find niche roles where his combination of skills is highly sought after—such as a data engineer focusing on designing data solutions for specific industries or domains.
What educational options would best help in the transition, and also create a useful project portfolio?
If you’re transitioning from a data analytics background to a data engineering role, you already possess a foundational understanding of data, its importance, and how to interpret it. However, data engineering requires a deeper dive into the technical aspects of data handling, storage, and processing. Here’s an educational path you might consider:
Foundational Courses in Computer Science and Programming:
Concepts such as algorithms, data structures, and object-oriented programming are fundamental. If you don’t have a computer science background, consider taking introductory courses in these areas.
Database Management and SQL:
While you may already be familiar with SQL from your analytics background, a richer understanding will be beneficial. Look into courses or workshops that delve into advanced SQL topics, database architecture, and both relational and NoSQL databases.
Big Data Technologies:
Learn about distributed data storage and processing frameworks like Hadoop, Spark, and Kafka. Platforms like Cloudera and Databricks offer certifications and training in these technologies.
Cloud Platforms:
Familiarize yourself with major cloud platforms such as AWS, Google Cloud, or Azure, particularly their data-related services. Cloud providers often offer training and certifications, which can be immensely beneficial.
ETL Tools and Processes:
Tools like Apache NiFi, Talend, or Informatica are commonly used for data integration tasks. Having hands-on experience with ETL (Extract, Transform, Load) processes and tools will be crucial.
Certifications:
We’ve mentioned a few of the certifications out there, as many companies now offer them for their platforms. Look for ones from cloud providers (e.g., AWS Certified Big Data) or technology-specific certifications (e.g., Apache Spark), which can bolster your resume and provide practical skills.
Hands-on Projects:
Theory and coursework are essential, but there’s no substitute for hands-on experience. Consider building your projects, contributing to open-source initiatives, or seeking internships or temporary roles that allow you to practice data engineering. Consider the following takehomes from Interview Query to boost your portfolio.
Remember, while formal education and certifications can significantly aid your transition, continuous learning and hands-on experience are equally important in the rapidly evolving field of data engineering.
What are the tools, programming languages, and frameworks do I need to learn coming from a data analytics background?

Transitioning from a data analytics to a data engineering role involves a broadening of your toolset. Data Engineering is largely about the design and construction of the systems and infrastructure used in collecting, storing, and analyzing data. As such, you’ll need to be familiar with a wider array of tools, languages, and frameworks. Here’s a breakdown of what you might need to focus on:
Programming Languages:
- Python: It is both versatile and widely used in both data analytics and engineering, especially for scripting and data manipulation. Libraries such as Pandas and NumPy might be familiar to you, but you’ll also want to explore PySpark for big data processing. Try out Interview Query’s Python learning path and explore the comprehensive guide for your Python programming language journey.
- Java: Java is also phenomenal programming language to learn when dealing with big-data technologies. Core software for big data environments like Hadoop and Kafka operate within the Java ecosystem, specifically the Java Virtual Machine. While not necessarily required, having basic Java knowledge can enable you to better understand the APIs and kits that are running under the hood.
Database Systems:
- Relational Databases (RDBMS): While you might already be familiar with SQL, diving deeper into systems like PostgreSQL, MySQL, and Microsoft SQL Server will be beneficial. Being able to handle the many flavors of SQL can be helpful, especially when interacting with data sources that are outside of your control. For more information about SQL, try Interview Query’s SQL learning path or practice with SQL Interview questions.
- NoSQL Databases: Get acquainted with databases like MongoDB (document store), Cassandra (columnar store), Redis (key-value store), and Neo4j (graph-based database). While most analysts handle structured data, most data engineers have to scrape and collect data from different sources. These data sources can, and will often include NoSQL databases.
Cloud Platforms:
- AWS: Services like S3 (object storage), EC2 (compute), Redshift (data warehousing), EMR (managed Hadoop and Spark), and Glue (ETL) are vital for data engineers.
- Google Cloud Platform (GCP): Services such as BigQuery, Dataflow, and Dataproc are commonly used.
- Azure: Familiarize yourself with services like Azure Data Lake, Azure HDInsight, and Azure SQL Data Warehouse.
Data Warehousing Solutions:
When considering data warehousing solutions, a variety of platforms emerge as frontrunners in the industry. Snowflake stands out as a cloud-native data warehousing solution that offers scalability and flexibility. In contrast, Teradata functions primarily as an RDBMS and is typically chosen for crafting large-scale data warehousing applications. Another notable mention in this realm is Google BigQuery, a fully-managed and serverless data warehouse offering from Google Cloud that streamlines big data analytics.
Infrastructure as Code & Deployment Tools:
As businesses and developers move towards more consistent and reproducible environments, tools facilitating infrastructure as code and deployment are gaining traction. Docker is at the forefront of this revolution, ushering in an era of containerization that allows developers to encapsulate their applications in standardized environments. Once you have containers, managing them, especially at scale, becomes the next challenge. This is where Kubernetes comes into play. As an orchestration tool, it aids in efficiently handling containerized applications across a cluster. Complementing these technologies, Terraform emerges as an essential Infrastructure as Code (IaC) tool. With Terraform, developers can define and set up data center infrastructure using a declarative configuration language, ensuring infrastructure consistency and reliability.
Version Control:
In the modern era of software development, version control is paramount. Git serves as the backbone for many developers, offering robust code management and collaboration capabilities. While Git provides the underlying versioning mechanism, platforms like GitHub and GitLab elevate the experience by furnishing collaborative platforms. These platforms allow teams to host, review, and work together on Git repositories, ensuring seamless code integration and team collaboration.
Remember, you don’t need to be an expert in all of these tools and technologies. The key is to have a foundational understanding of a broad spectrum and then specialize in the tools and frameworks that are most relevant to your specific role or industry.
What experience do I need to have to smooth the transition?
Transitioning from a data analytics role to data engineering demands a foundational understanding in several key areas to adeptly navigate the intricacies of building reliable data systems. A good starting point is an advanced proficiency in SQL, which goes beyond the usual analytics purview. This includes optimizing complex queries, having a grasp of execution plans, and understanding the nuances of table design and indexing for optimal performance. Additionally, a familiarity with the core tasks of database administration such as backups, replication, and scaling is invaluable.
Venturing further into the field, a data engineer’s role is closely tied to the creation and management of data pipelines. This encapsulates the design, deployment, and upkeep of ETL (Extract, Transform, Load) processes. Hands-on experience with Big Data technologies, especially within frameworks like the Hadoop ecosystem and Spark, is indispensable. The growing reliance on cloud services in contemporary data operations underscores the importance of gaining practical experience with platforms like AWS, GCP, or Azure. This extends to the provisioning and administration of data-centric services on these platforms. Additionally, a foundational understanding of container technologies, such as Docker, and orchestration tools like Kubernetes, offers a competitive edge. Equally pivotal is the ability to collaborate and communicate with a gamut of data professionals and stakeholders, ensuring that the data infrastructure is in sync with overarching business goals.
Case Study
Two people are looking to transition to data engineering:
Priya worked in a small startup as a data analyst, mainly handling a traditional relational database. Her main tasks revolved around data extraction using SQL for reports. She had occasional exposure to query optimization but with limited, smaller datasets.
Carlos, in contrast, was a data analyst in a larger corporation that used both relational databases and a cloud data warehouse. He frequently interacted with extensive datasets and honed his skills in SQL, not just for extraction but for performance optimization as well. Carlos also had hands-on experience with basic ETL processes and occasionally collaborated with the cloud solutions team.
In transitioning to a Data Engineering role:
- Priya, due to her startup experience, would have an edge when it comes to agility and adaptability. However, she might need to quickly ramp up her understanding of the complexities of Big Data technology, advanced optimization techniques, ETL processes, and cloud platforms.
- Carlos, with his experience in a more complex data ecosystem, has already worked in foundational elements of data engineering, especially in performance optimization and ETL processes. With some focused training on distributed systems and perhaps an in-depth understanding of container technologies, he would be well-poised to transition smoothly into a data engineering role.
How to choose the projects that I work on?
Choosing the right projects to work on, especially when transitioning or building expertise in data engineering, should be a strategic decision. Firstly, reflect on your current industry. If you’re aiming to leverage your existing domain knowledge, select projects that address specific challenges or gaps in that sector. For instance, if you’re coming from healthcare analytics, projects related to electronic health record (EHR) integrations or patient data anonymization can be leveraged. This approach allows you to blend your data engineering skills with industry-specific knowledge, creating a niche expertise that can be a potent differentiator.
Conversely, if you’re looking to pivot to a new industry, familiarize yourself with its unique data challenges and trends. Research prominent companies in the target sector, and identify the technological stacks they employ or the data problems they face. If you aim to join the finance sector, projects that delve into real-time transaction processing, fraud detection, or financial forecasting using vast datasets could be insightful. Tailoring your projects to simulate or solve real-world issues in your desired industry not only boosts your portfolio’s relevance but also showcases your proactive approach to potential employers.
Where do I get them from?
Interview Query’s blogs offer a vast selection of carefully curated datasets and projects that might help you get started with your data analytics portfolio. For example, you can try reading through these SQL project ideas article or try building your own pipeline with some of the takehomes we have to offer.
Here are some sample takehomes for you to do:
1. Invitae: Twitter Sentiment on Cryptocurrency
In the rapidly evolving world of cryptocurrency, understanding the relationship between market prices and public sentiment is crucial for informed decision-making. Historical Correlation serves as a foundational analysis method, enabling data engineers to draw connections between these two critical factors. By utilizing the provided data from historical_coin_data.txt and historical_sentiment_data.txt, one can perform a detailed correlation analysis, uncovering patterns and insights that link sentiment expressed on social media with actual market movements. This initial exploration sets the stage for more sophisticated analytics, paving the way for a potential shift from batch-based processing to a real-time streaming architecture, enhancing the system’s responsiveness and accuracy in capturing market dynamics.
2. Nextdoor: KPI Dashboard Design
As digital platforms grow and data becomes more complex, understanding user behavior and engagement metrics is crucial. User Data Analysis provides the foundation for extracting insights from this data, starting with basic queries to uncover key metrics such as the total number of users, the month with the highest sign-ups, and identifying the most-followed users. Once these insights are in place, the focus shifts to planning a robust KPI Dashboard. This dashboard will track critical metrics, including the number of users, daily new users, week-over-week changes, and engagement statistics like average photos per user and follower distribution. To accommodate the potential scale of a large dataset, designing an efficient set of tables is essential, ensuring that data is structured to support both real-time and historical analysis. Finally, implementing daily queries to populate these tables will ensure that the dashboard remains up-to-date, providing accurate and actionable insights for decision-making.
How do I approach these projects?
Let’s look at one of the most fundamental data engineer skill: ETL. The extract-transform-load process is one of, if not the most, quintessential data engineering task, allowing data engineers to provide automated data flows to data marts and data lakes. We have a blog article made specifically for ETL and data engineers, the ETL Interview Questions blog.
Approaching data engineering projects, especially those centered on ETL, begins by understanding the scope and objectives of the task. First, identify the data sources and their formats, then assess the quality of the data. Next, determine the desired output or end state and understand any transformations the data must undergo. Using tools and frameworks best suited for the job, design a data pipeline that extracts from the source, transforms as necessary, and loads into the target system, whether it be data marts or data lakes. It’s essential to consider scalability, efficiency, and error handling in your design.
Once you think that your portfolio is buffed enough and showcases different skills necessary for a DE position (SQL, ETL, System Design, etc.), you should start applying for jobs that align strongly with what you think are your most honed skillsets. However, keep your options open and know that it’s perfectly fine to learn on the job! Nobody expects an applicant to know every single thing in a job position. In fact, quite the contrary. It is common to have no single member understand the entire data pipeline thoroughly (especially in huge projects). As such, feel confident in applying to these jobs and prepare yourself thoroughly.