
Jane Street Machine Learning Engineer Interview Guide (2026)


Introduction
Jane Street is a global trading firm best known for its quantitative research, real-time market expertise, and even its unusual choice of OCaml as a core programming language. Lately, the firm has been leaning more into data science and machine learning, using these tools to boost trading efficiency and spot opportunities that weren’t visible before.
It’s part of a much bigger shift—financial firms everywhere are pouring resources into AI-driven trading systems, with McKinsey noting in 2024 that these investments are accelerating across the industry. Against this backdrop, Jane Street’s machine learning engineers play a huge role: they’re the ones building fast, reliable models that pull signal from massive datasets and plug directly into production trading systems.
In this guide, we’ll walk through what the role looks like, how Jane Street’s culture shapes the interview process, and preparation tips that can help you stand out. Let’s dive in!
Role Overview & Culture
Machine learning engineers at Jane Street operate at the intersection of statistical learning, real-time systems, and trading strategy. On a day-to-day basis, you’ll design and train low-latency models, analyze large-scale data streams, and deploy machine learning tools directly into production systems that use OCaml and Python. Your work might involve fine-tuning time series models, building online learning frameworks, or evaluating experimental features in a live trading environment.
Jane Street’s engineering culture is deeply collaborative. Pair programming is the norm, and ideas are refined through data and discussion, not titles. There’s minimal hierarchy, and mentorship happens naturally through tight-knit project teams and feedback-driven development. Every model you build is meant to be interrogated, improved, and reworked in a culture that values precision, adaptability, and experimentation.
Day-to-Day Responsibilities
- Design, train, and optimize low-latency machine learning models.
- Analyze massive real-time data streams to uncover predictive signals.
- Deploy ML tools directly into production trading systems built in OCaml and Python.
- Work on tasks such as fine-tuning time series models, building online learning frameworks, and testing experimental features in live environments.
Culture
- Highly collaborative, with pair programming as a standard practice.
- Data and discussion drive decision-making rather than titles or hierarchy.
- Emphasis on precision, adaptability, and continuous experimentation.
Team Setting
- Small, tight-knit project teams with close feedback loops.
- Mentorship occurs naturally through collaboration rather than formal programs.
Expectations
- Models are expected to be interrogated, stress-tested, and iteratively improved.
- Engineers are encouraged to refine and rework their approaches continuously.
Unique Perks
- Exposure to both cutting-edge machine learning and real-time trading systems.
- Opportunity to work with a unique functional programming stack (OCaml) rarely used at scale elsewhere.
- Flat structure that lets you contribute meaningfully from day one.
Why This Role at Jane Street?
If you’re excited about solving hard problems with direct market consequences, this role offers the chance to apply advanced ML in a setting where every millisecond and every decision counts. You’ll get access to state-of-the-art infrastructure, support from experienced researchers, and the opportunity to see your models go from idea to production rapidly.
Beyond the technical challenge, Jane Street offers one of the most rewarding compensation packages in the industry, along with a thoughtful approach to work-life balance, learning, and long-term career development. If you’re ready to dive in, let’s explore how the interview process works and how you can prepare for each stage.
What Is the Interview Process Like for a Machine Learning Engineer Role at Jane Street?
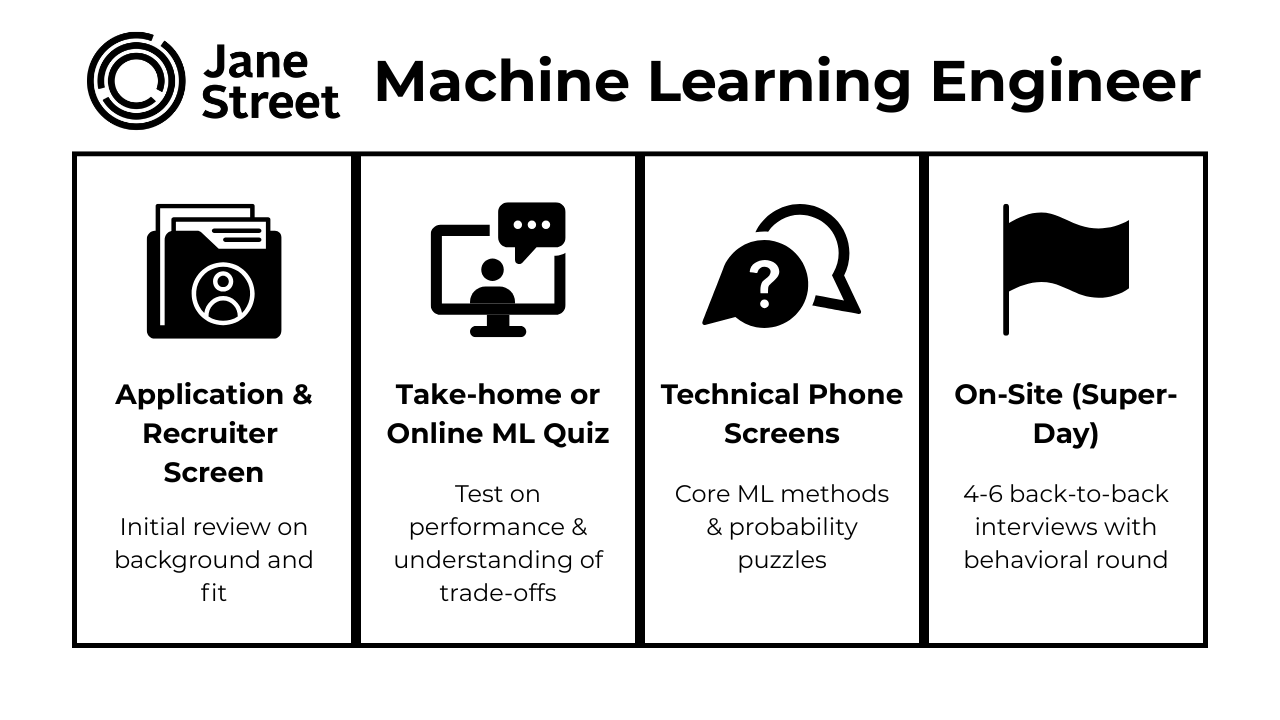
Overview of the Interview Process
Jane Street ML interview process is one of the most rigorous in the industry, designed to test both deep theoretical understanding and applied problem-solving across statistics, machine learning, and systems design. Candidates can expect a series of structured rounds that evaluate not only their ability to develop models but also their capacity to collaborate, code fluently, and adapt ideas to real-time constraints. The process favors depth over breadth; a single ML topic might evolve into a 30-minute deep dive, and strong communication is just as critical as technical precision.
Candidates frequently describe the interview journey as challenging yet rewarding. Each stage is purposeful and mirrors the day-to-day at Jane Street: fast-paced, collaborative, and curious. While the process is competitive, interviewers are typically friendly and conversational, often nudging candidates toward better solutions or asking them to reflect on trade-offs, much like a real working session with colleagues.
Application & Recruiter Screen
The process begins with a recruiter screen after your application is reviewed. The recruiter may ask about your academic background, ML project experience, and programming comfort with Jane Street’s stack (Python, OCaml, C++, etc.). This is not a technical evaluation but rather a fit screen to understand your interests and trajectory. It’s also a good opportunity for you to ask questions about the role and team structure.
Tips:
- Have a clear story about your ML background and why you’re drawn to Jane Street.
- Show awareness of their trading + research culture and technical stack.
- Prepare smart questions (team setup, role scope) to demonstrate genuine curiosity.
Take‑home or live coding/ML quiz
Depending on the team and location, you may be given a take-home problem or an online technical screen. For ML roles, this could include coding a simple predictive model under constraints, analyzing a toy dataset, or designing a model for a simulated decision-making task. Candidates have reported being asked to reason through things like signal-to-noise ratios, online learning setups, or to sketch out experiments to validate a model hypothesis.
While this is somewhat similar to machine learning assessments at other tech companies like Meta or Stripe, where understanding trade-offs in model selection, evaluation metrics, and feature importance is key, Jane Street places greater emphasis on how your reasoning aligns with real-time systems and trading latency constraints. The focus is not only on performance but on how you reason about modeling trade-offs and interpret your results.
Tips:
- Practice with small-scale ML problems under time pressure: correctness + clarity matter more than fancy models.
- Emphasize reasoning trade-offs: interpretability vs. performance, latency vs. accuracy.
- Brush up on statistics + probability: Jane Street favors statistical rigor over “black-box” solutions.
- Be ready to explain your process in plain language, not just code.
Technical Phone Screens
If you pass the initial screen, you’ll typically move on to two or more technical phone interviews. These interviews dive into machine learning fundamentals, such as Bayesian inference, overfitting/underfitting, generalization, or time series modeling. Many candidates are also asked probability brainteasers or statistics puzzles—not to test trivia, but to see how you think through uncertainty and edge cases.
For example, one candidate was asked to explain the differences between logistic regression and decision trees in the context of latency, interpretability, and feature interaction.
Compared to interviews at companies like Google or OpenAI, which may emphasize deep learning architectures and large-scale neural networks, Jane Street’s process is more statistically grounded. Deep learning is part of the toolkit, not the starting point. Jane Street’s ML team clearly states that “we believe deep learning is the future of quantitative trading,” and they build neural network models running on thousands of GPUs. However, interviewers expect you to first show mastery of interpretable, efficient models, especially under noisy or non-stationary conditions. Deep learning knowledge is a valuable complement, not the core.
You’ll be expected to demonstrate fluency in classical machine learning methods. Think linear models, decision trees, ensemble methods, and Bayesian techniques — and how to apply them to noisy, dynamic data. While familiarity with deep learning is a plus, most questions focus on interpretable models, probabilistic reasoning, and how well you understand performance trade-offs in real-time or data-scarce environments.
You may also be asked to sketch pseudocode for a model pipeline or compare two models’ performance using confidence intervals. Some sessions are whiteboard-style, while others might involve collaborative coding in an online editor.
Tips:
- Revisit core ML methods: linear/logistic regression, trees/ensembles, Bayesian models.
- Practice probability puzzles + inference questions — focus on reasoning, not memorization.
- Be prepared to discuss model evaluation metrics and why you’d choose one over another.
- Think in terms of real-time constraints: how does inference speed affect feasibility?
- Expect to whiteboard pseudocode for simple pipelines — keep it modular and clear.
On‑site “Super‑Day”
The on-site Super Day consists of 4–6 back-to-back interviews with ML researchers, engineers, and sometimes traders. One or two rounds will focus on your past machine learning project or research. While there’s no formal presentation required, you should be prepared to walk through a project in depth, as if explaining it to a technically sharp colleague. Interviewers will ask open-ended questions to explore your reasoning, such as why you chose a particular model, how you handled edge cases, and what trade-offs you considered between complexity, interpretability, and performance. You may be asked to whiteboard architecture, draw a model pipeline, or sketch out pseudocode on the fly.
They’ll focus heavily on statistical soundness, your understanding of model assumptions, and how your work holds up under constraints like latency, noisy data, or limited compute. Questions might dig into how you estimated uncertainty, validated generalization, or adapted your model to new distributions. Because many Jane Street systems operate in real time, expect questions about inference speed and how your solution could be simplified or optimized for deployment. They’re looking not just for technical correctness but for intellectual depth, adaptability, and clarity in how you reason through challenges.
Other rounds will assess your general coding and software engineering ability. These sessions often involve implementing algorithms in real time, debugging edge cases, or writing modular code under light time pressure. Interviewers might ask you to implement a data structure, simulate a statistical process, or write a utility for model evaluation — all while thinking aloud and responding to new constraints. While fluency in Python is expected, comfort with concepts like recursion, complexity trade-offs, or functional programming will be useful, especially given Jane Street’s OCaml-heavy codebase.
You may also face a systems or deployment-focused interview, which dives into how you’d integrate models into a real trading system. Here, interviewers may explore topics like distributed training, feature engineering pipelines, memory management, or model versioning. They want to see that you not only understand the modeling side but also how to scale, test, and maintain it in a live production context.
Finally, there’s typically a culture fit or behavioral round. But even this is intellectually engaging — not just about team dynamics but how you handle feedback, collaborate under ambiguity, and balance rigor with iteration. Jane Street values humility and curiosity, so this round often involves open discussion around how you’ve worked in past teams, learned from mistakes, or mentored others.
Throughout the Super Day, expect interviewers to be intellectually generous, collaborative, and curious. Many candidates describe these interviews as “working sessions,” where you’re invited to think aloud, refine your ideas, and challenge assumptions together — giving you a real preview of what working at Jane Street feels like.
Tips:
- Pick 2–3 projects you know deeply and prepare to defend every design choice.
- Show you understand statistical assumptions (stationarity, noise, uncertainty estimation).
- In coding rounds: emphasize clarity, modularity, and edge-case handling over clever hacks.
- For systems questions: review distributed training, feature stores, and versioning best practices.
- In behavioral rounds: highlight humility, curiosity, and collaboration—core Jane Street values.
- Treat each interview like a working session: narrate, adapt, and refine with your interviewer.
Committee Review & Offer
Once your interviews conclude, your full packet, including performance in each round and feedback from all interviewers, is reviewed by a hiring committee. This stage is notably collaborative and consistent with Jane Street’s flat structure: no single interviewer makes the decision, and the goal is to holistically evaluate both your technical abilities and fit within the team. If successful, you’ll receive an offer with generous compensation and sometimes a follow-up call to discuss team matching or questions about relocation.
Behind the Scenes
Candidates often highlight how smoothly the process runs. Coordinators are responsive, interviewers are thoughtful, and feedback is often timely. The technical discussions are rigorous, but also open-ended and conversational. It’s not unusual for an interviewer to pause and say, “Let’s explore that idea further,” indicating a shared exploration rather than a rigid Q&A. This dynamic gives candidates a taste of Jane Street’s pair-programming and intellectual culture in action.
Differences by Level
For more senior candidates or those with significant ML research experience, the bar for depth and originality is higher. You may be asked to critique academic papers, discuss theoretical underpinnings of algorithms, or describe how you would adapt a research idea to real-world constraints. For new grads or early-career applicants, the focus is more on strong fundamentals, curiosity, and willingness to collaborate. Jane Street has a strong culture of mentorship and often invests heavily in training junior engineers who show potential and a good learning mindset.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Jane Street?
What Questions Are Asked in a Jane Street Machine Learning Engineer Interview?
Coding/Technical Questions
In the early and on-site stages of the interview, Jane Street ML engineer candidates face technical coding rounds that test algorithmic fluency, mathematical reasoning, and ML-specific problem-solving. Unlike general software engineering interviews, the problems are tightly linked to trading contexts—involving time-series analysis, data summarization, online updates, or optimization under real-time constraints. Familiarity with Python is expected, and a working understanding of OCaml can give you an edge.
You might be asked to analyze the behavior of an exponential moving average under streaming data, or implement a resampling scheme to denoise a noisy price signal. Some rounds may also include combinatorial puzzles, data structure design, or code optimization exercises.
Example 1:
“Given a stream of timestamped prices, compute a moving z-score with a fixed-length rolling window.”
→ Requires sliding window logic and numerical stability—a test of both data handling and time-aware computation.
Example 2:
“Write OCaml-style pseudocode to implement a simple queue with constant-time min retrieval.”
→ Tests functional thinking and data structure intuition.
Example 3:
“Optimize an ML model’s prediction latency under a memory constraint.”
→ You’ll reason through preprocessing trade-offs and model simplification strategies.
Select a random number from a stream with equal probability
Now start practicing in our dashboard! In each question dashboard, you’ll see the prompt on the left and an editor to write and run your code on the right.
If you get stuck, just click the “IQ Tutor” button to receive step-by-step hints. You can also scroll down to read other users’ discussions and solutions for more insights.
Use reservoir sampling to efficiently pick a number from a stream without knowing its total length. This question tests knowledge of randomized algorithms and memory efficiency. It’s a great way to probe how well you handle probabilistic logic under constraints. Jane Street favors stream processing skills in real-time systems.
Tip: Practice implementing reservoir sampling in both Python and pseudocode, and be ready to explain why the probability stays uniform.
Format an array of words into lines of max width
This is a string manipulation problem that requires dynamic allocation of words across lines without breaking length constraints. It tests both algorithmic precision and corner-case handling. You may want to iterate with greedy logic and careful space accounting. It reflects formatting logic common in data visualization or reporting pipelines.
Tip: Pay extra attention to edge cases—single long words, trailing spaces, and exact-width lines often trip candidates up.
Find the integer removed from list X to form list Y
Efficient ways to solve this include using hashing or arithmetic summation. Focus on time and space complexity given two similar lists. This type of question checks your ability to compare datasets and isolate changes. It’s representative of debugging real-world data ingestion pipelines.
Tip: Be ready to compare multiple approaches (sum difference vs hash vs XOR) and explain their trade-offs in memory and performance.
Find the missing number from an array spanning 0 to n
Try XOR tricks or use the arithmetic sum approach to find the anomaly. You’ll demonstrate logic around complete sequences and edge case assumptions. This problem reinforces fundamentals in linear scans and math-based inference. It’s useful for designing health checks in ML pipelines.
Tip: If time is short, go with the arithmetic sum solution first—it’s simplest—then mention XOR as a more memory-efficient alternative.
Determine if string A can be rotated to match string B
Solve this by checking if B is a substring of A concatenated with itself. The trick lies in understanding cyclic behavior and efficient substring matching. Candidates must balance simplicity and correctness in implementation. This echoes transformation logic in encoding or data normalization.
Tip: Don’t reinvent substring search—most languages have efficient built-ins, so focus on explaining the intuition behind the trick.
Write a function to find the interquartile range of a dataset
Sort the dataset, then compute Q1 and Q3 before subtracting. Handle even/odd list lengths and potential duplicate values carefully. This problem tests statistical grounding and implementation edge cases. It applies directly to preprocessing steps in machine learning workflows.
Tip: Walk through a small example dataset step by step—it makes your reasoning about quartiles crystal clear to the interviewer.
Determine if a one-to-one correspondence exists between two strings
Use a hash map to verify that each character maps uniquely. You should guard against both duplicates and mismatches. It’s a test of mapping logic, data structures, and bijective reasoning. These kinds of checks are useful in tokenization and model feature encoding.
Tip: Make sure to check both directions: A→B and B→A—to guarantee the mapping is truly one-to-one.
System/Product Design Questions
Jane Street machine learning engineers often work at the intersection of modeling and system-level implementation. In this session, you’ll be asked to design end-to-end components that support real-time ML use cases — especially in latency-sensitive, high-throughput environments. You’re expected to consider performance, resilience, data consistency, and ease of deployment.
A common prompt might be: “Design a real-time feature store for intra-day trading signals.”
You’ll need to walk through ingestion from multiple data sources, data freshness guarantees, deduplication strategies, caching layers, and how to safely update features mid-day. Interviewers may push further:
- “What happens when a feed goes stale?”
- “How would you roll back a corrupted signal?”
- “Where would you put monitoring and alerting hooks?”
Success in this round comes from balancing clean design with practical deployment — and being able to justify trade-offs under pressure.
Design a classifier to predict the optimal moment to show a commercial break
Start by framing this as a binary classification problem using streaming data. Incorporate user attention signals, content segmentation, and engagement metrics. Consider latency constraints and how real-time inference would work. This is highly relevant for real-time ad-serving systems in finance or media firms like Jane Street.
Tip: Emphasize how you’d align model predictions with strict latency requirements—e.g., sliding windows or online learning—to avoid disrupting the user experience.
Describe the process of building a restaurant recommender system
You’ll need to decide between collaborative filtering, content-based methods, or a hybrid approach. Incorporate context like location, cuisine preferences, and time of day. Be ready to discuss cold start issues and evaluation strategies. This question reflects the kind of contextual personalization common in product machine learning roles.
Tip: Have a ready framework for cold start: use content-based filtering first, then gradually shift to collaborative methods as more user data accumulates.
Design a recommendation algorithm for Netflix’s type-ahead search
Consider latency and autocomplete architecture alongside personalized ranking. Use user history, trending items, and semantic similarity as features. Prioritize memory efficiency given rapid request rates. Jane Street ML engineers may not build search engines, but thinking in real-time constraints is crucial.
Tip: Mention caching strategies and prefix trees (tries) for sub-millisecond autocomplete performance. Tie ranking logic to personalization for added depth.
Create a recommendation engine for rental listings
You’ll combine structured data (price, location) with unstructured features like text and images. Explore ranking models and feedback loops using clicks or saves as implicit signals. Balance precision with diversity. This model system-wide trade-offs when optimizing for utility versus novelty.
Tip: Discuss balancing relevance with diversity by using re-ranking methods (e.g., MMR – Maximal Marginal Relevance) to avoid repetitive results.
Design a podcast search engine with transcript support
First, build a pipeline that processes and indexes audio transcripts. Then work through how you’d rank episodes by relevance, freshness, and user preference. Consider noisy data and multi-language support. This challenges your ability to architect NLP-heavy systems at scale.
Tip: Highlight preprocessing with ASR confidence scores and multilingual embeddings, and explain how you’d handle noisy or low-confidence transcript segments.
Design a machine learning system to minimize wrong order deliveries
Start with labeling errors and identifying signal features that correlate with fulfillment failures. Model prediction tasks like packaging error risk and driver reliability. Add real-time alerts and A/B testing pipelines. This use case is logistics-based but reflects predictive operations optimization.
Tip: Mention using anomaly detection or risk scoring for proactive flagging, and stress the importance of tight feedback loops with fulfillment teams.
Design a YouTube video recommendation system
Now start practicing in our dashboard! In each question dashboard, you’ll see the prompt on the left and an editor to write and run your code on the right.
If you get stuck, just click the “IQ Tutor” button to receive step-by-step hints. You can also scroll down to read other users’ discussions and solutions for more insights.
[Need a screenshot for the correct question: YouTube recommendation system]
Break it down into candidate generation and ranking stages. Use user engagement, watch time, and video metadata as inputs. Incorporate freshness and serendipity signals while handling adversarial creators. It’s a classic example of large-scale personalized content recommendation.
Tip: Talk about the importance of balancing short-term engagement (CTR, watch time) with long-term satisfaction, and include adversarial mitigation strategies like de-duplication and quality checks.
Design a real-time feature store for intra-day trading signals
Begin by describing how trading signals are generated and ingested into a central pipeline. Focus on streaming architecture using message queues and low-latency storage like Redis or Cassandra. Include mechanisms for feature freshness, versioning, and backfilling. This problem tests your ability to design scalable machine learning infrastructure in a high-frequency trading context.
Tip: Highlight trade-offs explicitly—e.g., Redis for speed vs Cassandra for persistence—and mention how you’d monitor feature freshness with time-to-live (TTL) or watermarking. This shows you’re thinking about both system design and reliability under real-time constraints.
Behavioral or “Culture Fit” Questions
While Jane Street is best known for its technical depth, its interview culture also prioritizes intellectual honesty, adaptability, and collaboration. The behavioral interview explores how you approach teamwork, mentorship, research iteration, and real-world modeling setbacks.
This round is less about pre-rehearsed STAR answers and more about your ability to reflect, stay curious, and show a mindset aligned with Jane Street’s experimental and feedback-driven culture. Candidates who thrive here are often those who can explain not just their decisions, but the thought process behind evolving them.
Describe a time when you had to collaborate with a team under tight deadlines. How did you balance quality and speed?
Focus on a scenario where deadlines were strict but high standards were still expected. Highlight how you communicated clearly with teammates, prioritized tasks, and addressed trade-offs between experimentation and delivery. Mention any creative approaches or tools you used to maintain momentum. This shows your ability to thrive in high-pressure, high-impact environments like Jane Street.
Example:
“In a class project, our team had only a week to deliver a real-time anomaly detector. We divided tasks quickly. I owned feature engineering, and we agreed to first ship a simple threshold-based baseline to guarantee delivery. At the same time, I added lightweight tests and logging so we could swap in a more robust model later. Clear communication and staged delivery let us meet the deadline without sacrificing correctness.”
Tell me about a time when your machine learning model failed in production. What did you learn from it?
Choose a situation where the model underperformed or broke after deployment. Describe the debugging process, communication with stakeholders, and how you adapted your testing or monitoring pipelines. Emphasize humility, curiosity, and willingness to learn from errors. Jane Street values introspective, data-driven learners who don’t shy away from mistakes.
Example:
“During an internship, I deployed a recommendation model that degraded quickly because seasonality wasn’t captured. Once alerts flagged the issue, I worked with the data team to debug input drift and added monitoring dashboards with distribution checks. I learned to never assume training and production data stay aligned, and to always build monitoring into pipelines.”
Have you ever had to push back on a team member or stakeholder about a rushed decision?
Explain how you advocated for a more rigorous or principled approach despite external pressure. Focus on communication skills and how you offered alternatives backed by data or experimentation. Discuss how the situation was resolved and what you learned. This illustrates your ability to balance research integrity with pragmatic delivery.
Example:
“A teammate wanted to skip cross-validation to meet a demo deadline. I explained the risks of overfitting and offered a compromise: run a faster k-fold with fewer splits. This kept rigor without blocking delivery. The demo succeeded, and the model generalized better than expected. I learned how to balance pragmatism with principled work.”
How do you prioritize learning new technical skills in a fast-paced environment?
Describe your strategies for staying updated—e.g., deep work sessions, reading papers, attending internal talks, or pairing with experts. Share an example where self-driven learning directly impacted your team’s success. Acknowledge trade-offs when learning while executing. Jane Street’s ML engineers are expected to be intellectually self-directed and fast learners.
Example:
“I set aside focused blocks each week to study papers or experiment. For example, I self-taught PyTorch Lightning while working on a time-series project. It initially slowed me down, but within two weeks, it boosted training efficiency for the whole team. I see learning as an investment with compounding returns.”
Talk about a time you changed your approach based on model evaluation metrics or failure analysis.
Walk through how initial assumptions gave way to unexpected results—perhaps due to data leakage, class imbalance, or real-world misalignment. Explain how you iterated and improved your model or process. This shows openness to feedback and an evidence-based mindset. It reflects the firm’s emphasis on rigor and continuous improvement.
Example:
“In one project, my classifier showed high accuracy but poor recall due to class imbalance. After reviewing precision-recall curves, I adjusted the sampling strategy and applied class-weighted loss. This improved recall by 15% with minimal precision loss. It taught me to always validate metrics against business goals, not just headline numbers.”
How do you handle ambiguity when designing a machine learning system from scratch?
Start with how you clarify goals with stakeholders or product teams. Talk through the iterative process of defining success, identifying bottlenecks, and measuring outcomes. Explain how you navigate between too much upfront design and too little planning. This aligns with Jane Street’s preference for engineers who can self-direct and think systemically.
Example:
“When asked to build a churn model, I first clarified success with stakeholders: was it prediction accuracy or actionable insights? Once defined, I scoped the MVP around simple features and a logistic regression baseline, leaving room to iterate. By breaking the problem into smaller milestones, I avoided analysis paralysis and delivered value quickly.”
What’s a recent model or paper you read that influenced your thinking?
Pick one with implications for real-world tradeoffs—such as interpretability, fairness, or scalability. Explain what you learned, why it mattered, and how it shaped your approach. Being able to link abstract research to concrete decisions demonstrates curiosity and applied intelligence—traits that resonate with Jane Street’s culture.
Example:
“I recently read about diffusion models and their application to time-series generation. The idea of using stochastic processes for structured outputs changed how I think about modeling uncertainty. It made me more open to exploring generative techniques for financial signals where traditional models struggle with volatility.”
How to Prepare for a Machine Learning Engineer Role at Jane Street
Preparing for a Jane Street machine learning engineer interview requires a blend of statistical depth, system-level thinking, and clear communication. Unlike other ML roles that focus heavily on deep learning frameworks or pre-trained models, Jane Street’s process emphasizes Bayesian reasoning, streaming data intuition, and real-time model behavior. Your ability to write clean code, defend modeling trade-offs, and engage in open-ended problem solving is what sets you apart. Here’s how to build a high-confidence prep strategy:
Master Functional & Probabilistic Programming
OCaml basics
Jane Street’s codebase is written primarily in OCaml, a statically typed functional programming language known for its speed, safety, and expressiveness. While you don’t need to be production-ready in OCaml before your interview, a strong conceptual grasp of functional programming is essential.
This includes working fluency with recursion, higher-order functions, immutability, algebraic data types, and pattern matching. You may be asked to interpret OCaml-like pseudocode, reason about control flow without mutable state, or restructure an algorithm using pure functional idioms. Practicing with OCaml basics or similar paradigms in Haskell, Scala, or even functional Python can help build intuition.
Why does this matter? Because Jane Street’s ML models are often integrated directly into their trading stack — meaning the interface between model logic and infrastructure must be both safe and efficient. Your ability to write clean, modular code in a functional style reflects how well you’ll collaborate with systems engineers and deploy ML tools reliably.
Probability deep dive
On the modeling side, Jane Street leans heavily into Bayesian thinking and uncertainty-aware decision-making. This isn’t just about knowing Bayes’ theorem — you should be comfortable reasoning through posterior distributions, designing priors that reflect real-world constraints, and computing confidence or credible intervals for model outputs. Topics like Thompson sampling, Kalman filtering, Gaussian processes, and Bayesian logistic regression are particularly relevant.
Causal inference
You may also encounter inference concepts like Monte Carlo methods, variational approximation, or conjugacy, especially if your project discussions involve dynamic, non-stationary settings.
In short, Jane Street wants to see that you not only know how to fit a model, but that you understand the epistemic structure behind it — how the model represents belief under uncertainty, how those beliefs update with new data, and how that translates into decision-making under risk. This depth is what sets their ML interviews apart from standard ML model API calls or out-of-the-box pipeline usage seen at other companies.
Rehearse 45‑min Coding + ML Concept Mix
In Jane Street’s interviews, especially during the technical phone and Super-Day rounds, machine learning engineer candidates will often encounter hybrid problems that require both strong coding fluency and deep modeling insight. These are not isolated Leetcode-style puzzles, nor are they abstract ML theory questions — they’re integrated scenarios that mirror how Jane Street approaches real-world signal extraction, model deployment, and statistical reasoning.
A typical prompt might involve implementing a time-series predictor (like a rolling average, exponentially weighted mean, or streaming quantile estimator), followed by questions about its bias, variance, memory use, latency, or how it behaves with drift and outliers. You’ll need to show that you not only can write fast, bug-free code—but also that you understand what the code is doing statistically and when it might fail.
You’ll be expected to reason through:
- Numerical stability: How does your calculation handle floating-point errors or large/small values over time?
- Windowing logic: Does your code update online? Is it sublinear in memory? Can it be parallelized?
- Signal degradation: What happens when noise increases or your target distribution changes? How quickly does your estimator adapt?
After implementation, interviewers often pivot into modeling concepts and trade-offs. You may be asked to discuss:
- Why you’d use a log-loss vs. hinge loss vs. cross-entropy for classification.
- When AUC is appropriate (and when it hides class imbalance).
- How to assess calibration, perhaps using Brier score or reliability diagrams.
- What confidence intervals actually tell you about model stability under resampling or real-time drift.
You may also be asked to:
- Write a function that compares the online performance of two models using rolling metrics.
- Discuss the computational complexity of updating a model in real time.
- Sketch the gradient update rules for a simplified version of your algorithm.
At Jane Street, this mix of programming + modeling isn’t just about interview structure, it reflects how ML engineers actually work there. You’re expected to own your pipeline end-to-end: from writing the data ingestion logic to debugging probabilistic failures to adapting your estimator to new conditions. This means your mental model of model behavior must be sharp, not just “train and score”, but why does this work, when does it break, and how do I know?
Think Out Loud & Clarify Assumptions
Jane Street interviewers place a premium on clarity of thought, not just the correctness of your final answer. They understand that many of the problems you’ll face, both in the interview and on the job, don’t have clean, obvious solutions. What they’re evaluating is your ability to engage with complexity: can you take an open-ended or under-specified problem and begin to shape it through careful questioning and logical structuring? Do you surface your assumptions early, break the problem into solvable subcomponents, and articulate trade-offs between competing solutions? In many ways, your thought process is the product.
You’re not expected to get everything right on the first try, in fact, backtracking, refining, and adapting your approach is part of what Jane Street wants to see. Strong candidates will pause to ask thoughtful, clarifying questions, propose hypotheses before committing to a solution path, and narrate their reasoning clearly so the interviewer can follow their line of thinking. This style of problem-solving reflects the firm’s real-world expectations: models evolve, assumptions change, and production constraints emerge. You’re being assessed on how well you navigate those shifts, not just on your technical precision.
This approach also mirrors Jane Street’s collaborative engineering culture, where pair programming is deeply embedded in daily work. During interviews, you’re encouraged to treat the interviewer less as an examiner and more as a technical partner, someone with whom you’re jointly exploring a solution space. Interviewers may push back on your reasoning, pose alternative directions, or invite you to challenge your own assumptions. Your willingness to engage in that dialogue, to remain intellectually open, self-aware, and rigorous, is often what separates top candidates from the rest. In short, Jane Street isn’t just hiring you for what you know, they’re hiring you for how you think.
Show Path From Baseline to Optimised Model
Begin with the baseline
Even if that’s a naive average or a basic logistic regression, your ability to justify starting simple demonstrates maturity and methodological discipline. Explain how you chose that initial model—was it for interpretability, speed, or as a reference for further experimentation? Then walk through your evaluation framework in detail: how did you assess performance? Did you use out-of-sample validation, bootstrapping, or time-based cross-validation? Were you measuring accuracy, calibration, log-loss, or tail risk?
Provide model feedback
Next, narrate how the model failed. Was it underfitting rare edge cases? Overreacting to volatility? Struggling with drift or missing features? Jane Street wants to see that you didn’t treat modeling as a static task, but rather as a dynamic process of feedback and adaptation. How did you revise your assumptions in response? Did you move to a tree-based ensemble to capture nonlinear interactions? Introduce regularization to stabilize weights? Simplify the model to reduce overfitting under high-frequency conditions?
Quantify every “why”
Crucially, quantify the why behind each iteration. Was the shift to gradient boosting justified by a measurable increase in AUC? Did it compromise inference speed or add complexity that had to be reined in downstream? Could you trace how each decision traded off between accuracy, latency, and interpretability? This isn’t just about listing techniques — it’s about demonstrating that you approached modeling as a rigorous, hypothesis-driven process.
Mock Super‑Day Simulations with peers/ex‑JS interviewers
Practicing back-to-back technical and behavioral interviews can help build endurance and sharpen your storytelling. Seek out former Jane Street candidates or peers with similar roles to simulate a full Super Day. Ask them to challenge your modeling decisions, push on edge cases, or question your trade-offs — this will build the reflexes you’ll need for the real thing.
FAQs
What Is the Average Salary for a Machine Learning Engineer at Jane Street?
Compensation for machine learning engineers at Jane Street is among the highest in the industry.
- Entry-Level / New Grad (L1)
- Base Salary: $200K–$220K
- Total Compensation: $350K–$400K (Levels.fyi)
- Structure: Base + performance bonus + profit-sharing
- Mid-Level (L2 – 2–4 YOE)
- Base Salary: $220K–$240K
- Total Compensation: $400K–$500K (Levels.fyi)
- Structure: Profit-sharing makes up a large portion of upside
- Senior (L3/L4 – 5+ YOE)
- Base Salary: $240K–$250K+
- Total Compensation: $500K–$600K+ (Levels.fyi)
- Structure: Annual bonus + profit-sharing often exceeds base
Compared to other roles at the firm, the machine learning engineer pay band is similar to that of software engineers, with some overlap. However, MLEs may receive additional upside due to their direct impact on trading systems and signal research. Data engineers also earn well, with comp in the $300K–500K range, but typically with a narrower variance. Overall, the compensation of machine learning engineer Jane Street is on par with top-tier hedge funds and trading firms, and well above most big tech roles.
Are There Open Machine Learning Engineer Roles Right Now?
Yes! Jane Street regularly hires for machine learning engineering positions across its New York, London, and Hong Kong offices. While not always listed as “MLE” on job boards, these roles often appear under titles like “Machine Learning Researcher,” “Quantitative Engineer,” or “ML Infrastructure Engineer.” To stay updated on live openings, visit the Interview Query Job Board and subscribe to role alerts tailored to your interests. This ensures you’re among the first to know when a new machine learning engineer Jane Street listing goes live.
Conclusion
Succeeding in the Jane Street machine learning engineer interview takes more than technical skill; it demands strong statistical thinking, clear communication, and the ability to solve real-time problems under constraints. Each step, from OCaml fundamentals to probabilistic modeling and system design, tests how you think, adapt, and build.
Deliberate practice is key. Rehearse complex problem-solving out loud, challenge yourself with probabilistic puzzles, and simulate the full Super-Day experience with peers or mentors. To accelerate your prep, consider using Interview Query mock interview to walk through real scenarios and get feedback on your approach.
If you’re curious about adjacent roles, be sure to check out our guides on the Software Engineer and Data Engineer Interview at Jane Street — many concepts and expectations overlap, and each can offer unique prep insights.
Jane Street Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
Probability | Medium | |
Data Structures & Algorithms | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences