
Jane Street Data Engineer Interview Guide (2025)


Introduction
Jane Street is a global trading firm that has built its reputation on quantitative research, cutting-edge technology, and a highly collaborative culture. In recent years, the firm has been doubling down on its data capabilities, recognizing that speed, accuracy, and reliability in data pipelines can make all the difference in real-time markets.
This shift mirrors a wider industry trend, with Deloitte’s 2024 insights noting that financial institutions are investing heavily in modern data engineering to power analytics and trading decisions at scale. Within Jane Street, data engineers play a critical role by designing and maintaining the pipelines that feed market, internal, and reference data into trading systems with near-zero latency. It’s a role that sits right at the heart of the firm’s infrastructure, bridging technology and trading impact.
In this blog, we’ll walk through the responsibilities of the role, Jane Street’s unique culture, and the interview process, while sharing tips to help you succeed. Keep reading to learn how to approach each stage with confidence.
Role Overview & Culture
So what does life as a Jane Street data engineer actually look like? Beyond the buzzwords, it’s a mix of building, collaborating, and constantly improving. Here’s a closer look at what you’ll be doing day to day, the culture you’ll be stepping into, and a few perks that make the role stand out.
Day-to-Day Responsibilities
- Build and maintain low-latency streaming pipelines to deliver market, internal, and reference data in real time.
- Use OCaml and Python to develop tools for data ingestion, transformation, and distribution.
- Optimize performance of distributed systems while ensuring data integrity and reliability.
- Support trading and research teams by enabling seamless access to high-quality data.
Culture
- Flat hierarchy where engineers are empowered to take initiative and make decisions.
- Strong emphasis on collaboration, with pair programming as a standard practice.
- Feedback loops are intentionally short, fostering fast iteration and improvement.
Team Setting
- Engineers work closely with traders, researchers, and infrastructure teams.
- Shared code ownership encourages mentorship and learning across teams.
- Small, focused groups where knowledge exchange and peer learning are constant.
Expectations
- Engineers are expected to combine strong coding skills with a deep understanding of real-time data needs.
- Every system is stress-tested, optimized, and continuously improved.
- Ownership of projects from design to deployment is the norm, not the exception.
Unique Perks
- Opportunity to work with OCaml, a functional programming language rarely used at scale.
- Close integration with trading desks, giving direct exposure to financial markets.
- A culture that blends technical rigor with genuine intellectual curiosity and mentorship.
The mix of technical rigor, flat teamwork, and constant collaboration makes it a pretty unique place to grow as an engineer. So the next question is, why choose this role at Jane Street in particular? Let’s dig into what makes it stand out.
Why This Role at Jane Street?
Working as a data engineer at Jane Street means you’re right in the middle of the action, where every pipeline you build and every millisecond of latency can influence trading decisions and profitability. It’s a role that combines the precision of engineering with the fast pace of financial markets, creating an environment that’s as challenging as it is exciting.
What makes the Jane Street data engineer position stand out is how much technical depth and real-world impact it offers—you’ll get to work in a unique functional programming ecosystem with tools like OCaml, collaborate daily with traders and researchers, and see the direct results of your work play out in live markets. On top of that, the compensation is among the most competitive in both tech and finance, a reflection of just how critical this role is to the firm’s success. Next, let’s walk through the interview process so you’ll know exactly what to expect.
What Is the Interview Process Like for a Data Engineer Role at Jane Street?
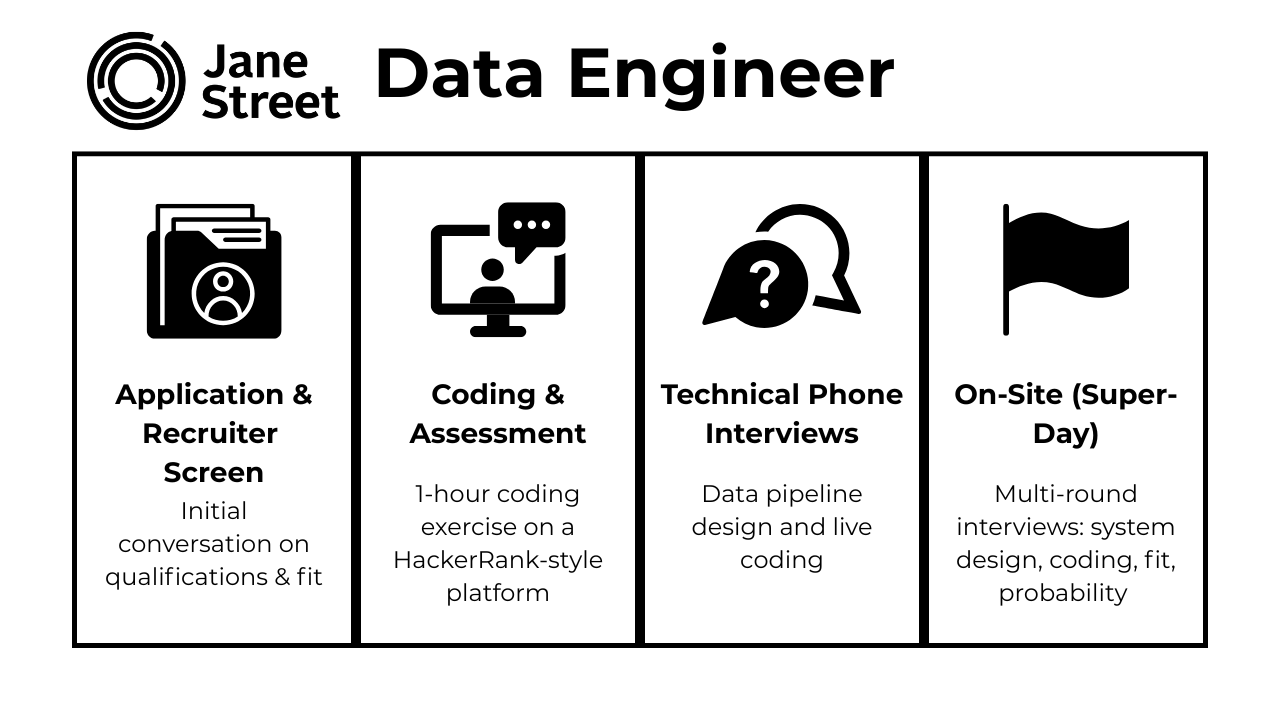
The hiring process for a data engineer at Jane street is rigorous, fast-moving, and highly collaborative. It is designed to mirror the environment you’d be working in. Let’s take a closer look at what happens in each stage:
Application & Recruiter Screen
The process typically begins with an online application or referral, followed by a recruiter screen. In this call, the recruiter reviews your résumé to confirm basic qualifications and fit. Expect questions about your programming background, particularly if you’ve worked with OCaml or Python, as well as your general interest in data engineering and Jane Street’s work. To strengthen your résumé, highlight programming languages (OCaml, Python, SQL), data infrastructure experience (pipelines, distributed systems), and projects showing problem-solving, optimization, and analytical rigor.
Emphasize both technical depth and collaborative impact, as recruiters look for candidates who can bridge strong coding skills with business or research needs. If you align well with the role, scheduling moves quickly. Candidates often report receiving study resources and guidance soon after the call, allowing time to prepare effectively for the technical rounds.
Coding & Data Assessment
The next stage is a 60-minute online coding assessment that evaluates your practical data skills. Delivered in a HackerRank-style platform, the test includes questions on SQL queries, array manipulation, and stream joins. One or two questions may simulate log stream joins or memory-efficient transformations on large datasets. The best approach is to work methodically: talk through your thought process, write clean code, and be mindful of time and space complexity. Communication is valued just as much as correctness here.
Tips:
- Practice SQL window functions, joins, and conditional aggregations.
- In Python, get comfortable with iterators, generators, and memory-efficient loops.
- Always start with a brute-force solution, then optimize if time permits.
- Narrate complexity trade-offs aloud—interviewers value reasoning over silence.
Technical Phone Interviews
If you pass the assessment, you’ll proceed to two 45-minute technical phone interviews. The first usually involves a data pipeline design question, where you’re asked to reason through a streaming data architecture, think about latency bottlenecks, and communicate trade-offs. The second focuses on live coding in your preferred language, with Python being widely accepted, even if the backend stack includes OCaml. In both rounds, clear reasoning and concise explanations are critical. Feedback is typically submitted internally within 24 hours, and the bar for both logic and clarity is high.
Tips:
- For design questions, break the problem into ingestion, processing, and serving layers.
- Mention real-world challenges like watermarking, back-pressure, and deduplication.
- For coding, choose a language you’re fastest in; correctness and clarity matter most.
- Summarize trade-offs (latency vs reliability, throughput vs consistency) as you go.
On‑site (Virtual Super‑Day)
The Super-Day is the final and most intensive round. Conducted virtually, it typically includes four interviews:
- Systems Design: Design a scalable, real-time data processing system
- Coding Exercise: Solve complex logic or data challenges
- Culture Fit Interview: Assess communication style and collaboration mindset
- Probability Puzzle Round: Reason through stochastic or combinatorial logic problems
Senior candidates might be invited to a fifth session focused on architecture-level design. Throughout, expect collaborative problem-solving, interactive dialogue, and a strong emphasis on clean thinking.
Tips:
- Systems Design: Use a whiteboard framework. Inputs, transformations, outputs; highlight failure handling and scaling.
- Coding Exercise: Think aloud, start with brute force, then refine; don’t over-optimize prematurely.
- Culture Fit: Share STAR stories that highlight ownership, teamwork, and humility.
- Probability Puzzle: Practice classic probability puzzles (balls-and-bins, conditional probability, random walks). Show your reasoning, not just the answer.
- For Senior Candidates: Emphasize trade-offs in architecture (throughput vs fault tolerance, consistency vs latency).
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Jane Street?
What Questions Are Asked in a Jane Street Data Engineer Interview?
Jane Street data engineer interview digs deep into your ability to design robust, real-time data systems and communicate your thought process clearly under pressure. Each question category tests a distinct skill: from technical implementation and systems thinking to how well you collaborate in high-stakes environments. Below, we break down the major types of questions you’re likely to face with examples, strategies, and common themes drawn from past candidate experiences.
Coding/Technical Questions
Coding questions at Jane Street go beyond conventional algorithmic puzzles. As a data engineer in a trading firm, you’re not just solving for correctness—you’re solving for performance under pressure. These questions are rooted in the realities of high-frequency data environments, where each millisecond matters and each decision affects the firm’s edge in the market.
Expect challenges involving stream joins on time-series data, late-arriving events, and windowing logic—all within the context of real-time market data ingestion. You’ll be tested on your ability to handle memory constraints, streaming semantics (event-time vs. processing-time), and on designing code that gracefully degrades or recovers.
Understanding how financial systems handle delayed messages, schema drift, or out-of-order events is core to the job. This role demands fluency in SQL or Python with a deep understanding of system behavior, because bugs in production can mean lost trades or inaccurate valuations. You’ll be evaluated not just on code quality, but your reasoning under uncertainty.
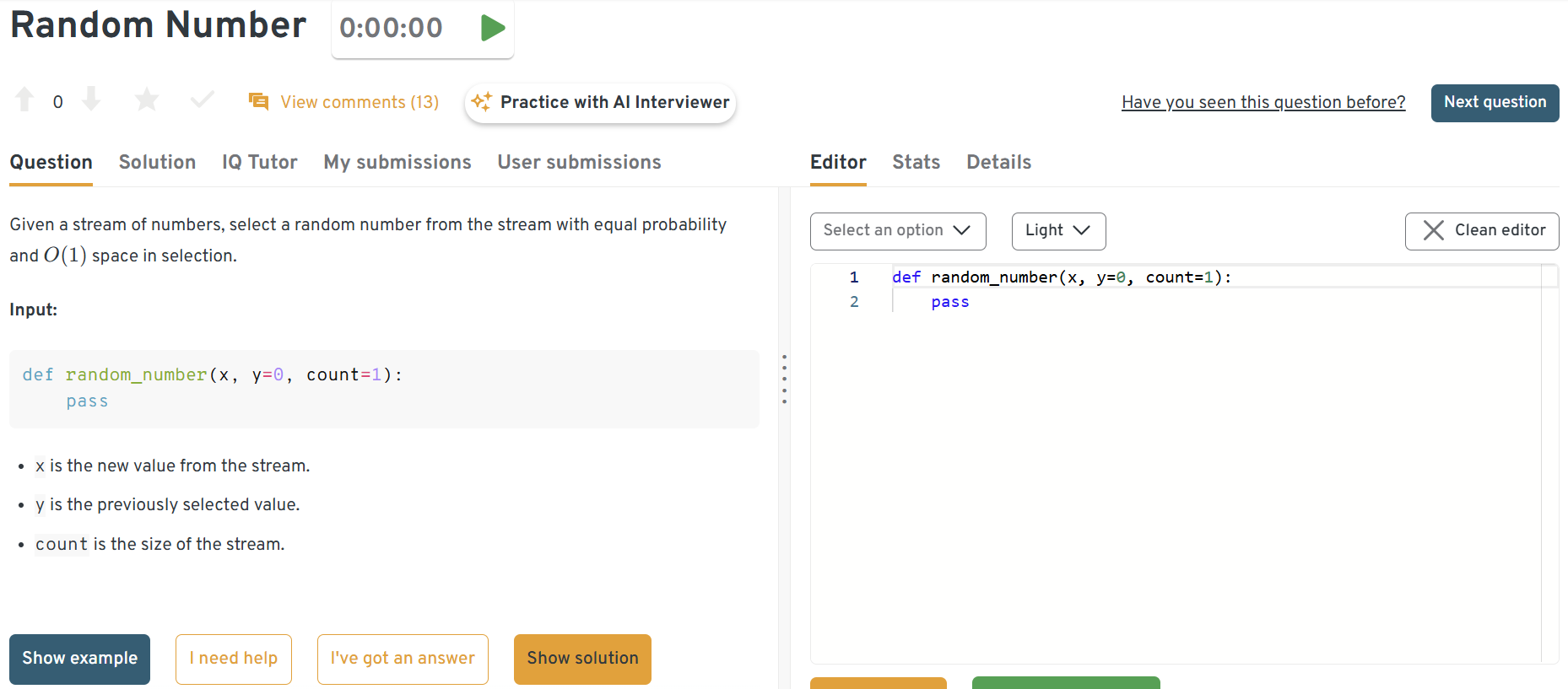
Select a random number from a stream with equal probability
Select a random number from a stream with equal probability. This problem is a classic test of reservoir sampling, particularly when the stream length is unknown or very large. A well-structured Python generator or stateful stream function works well here. It’s directly relevant to stream processing at Jane Street.
Tips:
- Know the reservoir sampling algorithm: at the i-th element, keep it with probability 1/i.
- Be able to prove uniformity of the probability—Jane Street values the math behind the logic.
- Show awareness of memory constraints: why storing the whole stream isn’t feasible.
- If coding in Python, a generator with state is often clean and efficient.
Group sequential timestamps into weekly lists starting from the first timestamp
Group a list of sequential timestamps into weekly lists starting from the first timestamp. You’ll need to use date arithmetic and maintain rolling windows, ideally with Python’s
datetimeand list manipulation features. Candidates often solve this by chunking based on time intervals. Jane Street may ask this to assess your understanding of time-indexed datasets.Tips:
- Use Python’s
datetimeandtimedeltato avoid manual date arithmetic errors. - Treat the first timestamp as the anchor—weeks should roll forward from that, not from Sunday/Monday.
- Carefully test with edge cases: spanning year boundaries, daylight savings, and uneven week lengths.
- Highlight sliding-window logic: useful in finance where rolling intervals matter.
- Use Python’s
Count users who made additional purchases within 7 days of their first transaction
Write a query to count users who made additional purchases within 7 days after their first. This is a strong test of event-time joins, which requires correct filtering and timestamp manipulation with SQL window functions. It’s especially important in time-sensitive financial analytics. Jane Street values precise control over time-based queries.
Tips:
- Think SQL window functions:
MIN(transaction_date)per user, then join/filter against subsequent purchases. - Watch for off-by-one errors in the 7-day window (
BETWEEN 1 AND 7vs<= 7). - Consider users with multiple purchases—do you count them once or multiple times? Clarify assumptions.
- Demonstrate precision with time zones and timestamp formats, which are critical in trading/finance.
- Think SQL window functions:
Replace words in a sentence with their shortest dictionary stem
Stem words in a sentence using the shortest root form from a dictionary. This tests your ability to implement Trie-like matching structures or prefix searching in Python. It’s a great example of data normalization which comes up in ETL pipelines. Demonstrates your skill in efficient preprocessing logic, often required in production systems.
Tips:
- Implement with a Trie or prefix tree for efficiency; avoid scanning the whole dictionary per word.
- Handle ties and overlapping roots carefully—shortest match usually wins.
- Consider performance: O(n·m) dictionary lookups won’t scale.
- Explain how this mirrors ETL preprocessing, where data normalization impacts downstream models.
Identify the integer removed when transforming list X into list Y
Find the integer removed from list X to form list Y. This tests your attention to state changes between dataset versions — a key trait in debugging and monitoring pipelines. It requires efficient comparison strategies like hashing or summation. Very aligned with understanding changes across data streams.
Tips:
- Quick approaches:
- Summation: difference between sums of X and Y.
- Hashing/sets: find the element with mismatched frequency.
- Be cautious about duplicates—sum trick fails if multiple identical values exist.
- Think about time complexity—linear solutions are expected.
- Relate to change detection in streams/logs—show awareness of practical applications.
- Quick approaches:
Design a stream join with event-time and watermarking
Use SQL or Python to join two time-series streams while handling late-arriving data. Explain how watermarking ensures correctness and prevents memory overload. Mention how tools like Flink or Kafka Streams manage this in real-time. This is critical for high-frequency trading or order book alignment at Jane Street.
Pseudocode Solution:
# Assume two input streams: trades_stream, quotes_stream # Each event has: {symbol, price, timestamp} # Define watermark to handle late arrivals watermark = event_time - allowed_lateness # e.g., 5 seconds # Assign event-time and watermark for event in trades_stream: assign_event_time(event.timestamp) assign_watermark(event.timestamp - 5s) for event in quotes_stream: assign_event_time(event.timestamp) assign_watermark(event.timestamp - 5s) # Join logic with event-time alignment joined_stream = trades_stream.join( quotes_stream, key = "symbol", condition = trades.timestamp BETWEEN quotes.timestamp - 2s AND quotes.timestamp + 2s, on_event_time = True, watermark = watermark ) # Output joined records for downstream trading logic emit(joined_stream)Key ideas to explain:
- Watermarking tells the system “we’ve seen all data up to this time minus lateness.”
- Prevents memory overload by discarding state for very late events.
- Tools like Flink and Kafka Streams manage watermarks and state cleanup automatically.
7. Design a fault-tolerant ETL pipeline with exactly-once semantics
Talk through how you’d design retry logic, checkpoints, and deduplication to ensure data correctness. Use Apache Kafka, Flink, or Airflow patterns in your explanation. Idempotency and transactional guarantees are core to Jane Street’s reliability requirements. Show how you’d log failures and recover gracefully.
Pseudocode Solution:
# Input: Raw market data stream # Output: Cleaned, deduplicated stream to downstream DB with StreamProcessor("MarketETL") as job: # Step 1: Consume from Kafka with offset tracking raw_stream = kafka_consumer(topic="market-data", enable_idempotence=True) # Step 2: Deduplicate based on unique event_id deduped_stream = raw_stream.filter(remove_duplicates(event_id)) # Step 3: Transform data transformed_stream = deduped_stream.map(transform_function) # Step 4: Checkpointing for recovery job.enable_checkpoint(interval=30s, backend="RocksDB") # Step 5: Sink with transactional guarantees kafka_producer( topic="cleaned-data", enable_idempotence=True, transactional=True, checkpoint=job.checkpoint ).write(transformed_stream) # Step 6: Retry + failure logging try: commit_transaction() except Exception as e: log_failure(e, event_id) rollback_transaction() retry_event(event_id)Key ideas to explain:
- Use idempotent writes + transactional producers to ensure exactly-once.
- Checkpoints let you restart without duplicating data.
- Deduplication on
event_idavoids double processing. - Failures are logged, retried, and recovered gracefully.
System/Product Design Questions
System design at Jane Street is tightly bound to the needs of trading speed, correctness, and scale. Unlike typical backend roles, where latency is a performance metric, here it’s a competitive advantage. Designing a “real-time trade-feed ingestion pipeline” isn’t a theoretical prompt—it reflects Jane Street’s actual engineering challenges.
Candidates are expected to think through partitioning strategies for market data feeds, checkpointing mechanisms for fault-tolerance, and exactly-once delivery semantics under high-throughput constraints. Knowledge of Kafka, Flink, or similar distributed stream processing frameworks is useful, but what matters more is your mental model for how data moves through a system and how to fail safely without dropping or duplicating records.
Interviewers look for design intuition in scenarios like merging asynchronous exchange data feeds, handling back-pressure, and evolving message schemas without disrupting live trading pipelines. In this environment, your decisions can directly impact PnL, so precision and foresight are critical.
Now start practicing in our dashboard! In each question dashboard, you’ll see the prompt on the left and an editor to write and run your code on the right.
If you get stuck, just click the “I need help” button to receive step-by-step hints. You can also scroll down to read other users’ discussions and solutions for more insights.
Design a classifier to predict optimal commercial break insertion points in a video
Design a classifier to predict the optimal moment to insert a commercial break during a video. This system requires feature extraction from video content and user engagement signals. You’ll need to consider real-time model scoring and latency constraints. It tests your ability to architect an ML system with low-latency inference pipelines, relevant to media optimization and financial visualization at Jane Street.
Tips:
- Break the problem into feature extraction (scene changes, sentiment, engagement drop-off) and modeling (classification or ranking).
- Emphasize latency-aware inference: precompute features offline, score online in milliseconds.
- Consider user experience trade-offs: breaks that maximize ad revenue but don’t hurt retention.
- Show awareness of evaluation metrics (A/B testing, retention vs. revenue balance).
Build a type-ahead search recommendation system with prefix matching and ranking
Design a recommendation algorithm for Netflix’s type-ahead search. This involves building prefix trees (tries) and applying collaborative filtering or ranking models based on real-time user interaction. It balances fast retrieval with relevance scoring, which reflects Jane Street’s emphasis on speed and precision in search and query response systems.
Tips:
- Start with prefix data structures (Trie or DAWG) for efficient lookups.
- Layer on ranking models (popularity, personalization, CTR history).
- Discuss caching and latency constraints—users expect instant results.
- Mention freshness handling: how new queries and terms are integrated in real time.
Develop a hybrid restaurant recommendation engine using content and collaborative filtering
Describe the process of building a restaurant recommendation engine. The question pushes candidates to consider hybrid models—combining content-based and collaborative filtering. It’s a great opportunity to show understanding of model serving, offline training, and real-time personalization. Jane Street may assess how you balance cold-start issues with interpretability in a production setting.
Tips:
- Explain both sides: content-based (menu, location, cuisine) and collaborative filtering (user–user or item–item).
- Address the cold-start problem: fallback to content-based for new users/items.
- Talk through model serving: batch training + real-time reranking.
- Highlight interpretability—why a recommendation was made matters in production.
Design a podcast search engine with transcription and semantic relevance ranking
Design a podcast search engine with transcript ingestion and semantic relevance ranking. This is a test of full-stack ML deployment—from transcription (ASR) to semantic embedding and indexing using something like FAISS. You should consider multilingual models, freshness, and indexing latency. The question is relevant for evaluating your grasp of retrieval-augmented generation (RAG) and vector search.
Tips:
- Outline pipeline stages: speech-to-text (ASR) → embedding generation → vector index.
- Mention tools like FAISS, Annoy, or ElasticSearch with dense retrieval.
- Handle multilingual and domain-specific vocab challenges.
- Discuss indexing latency and keeping transcripts fresh for new episodes.
- Show awareness of RAG-style retrieval for advanced query relevance.
Create a rental listings recommendation system with user–item embeddings
Create a recommendation engine for rental listings. This involves embedding user profiles and listing features into a shared latent space and optimizing for click-through or conversion. The system must also handle stale listings and inventory churn. Jane Street could use this to assess how you think about relevance under evolving data constraints and optimization targets.
Tips:
- Define features for users (budget, location, history) and for listings (price, location, amenities).
- Map into a shared embedding space (matrix factorization, neural embeddings).
- Account for inventory churn: stale or expired listings should be pruned fast.
- Optimize for click-through → conversion while balancing fairness/exposure.
- Think about real-time reranking when inventory shifts rapidly.
Design a real-time trading data ingestion pipeline
Outline how to collect, deduplicate, and normalize high-frequency trade and quote data. Include message brokers (like Kafka), backpressure handling, and schema evolution. This is a direct parallel to the type of systems Jane Street runs to support trading desks. Your answer should emphasize low-latency ingestion and fault tolerance.
Tips:
- Show a clear flow: exchange feeds → Kafka (or equivalent) → stream processors → normalized DB.
- Emphasize deduplication, ordering, and schema enforcement—critical in trading.
- Address backpressure handling to avoid dropped messages under peak load.
- Low-latency is key: highlight microsecond-level ingestion goals.
- Mention fault tolerance (replication, failover, monitoring).
Design a fault-tolerant, horizontally scalable logging ingestion system
Describe how you would build a system to collect, compress, and index logs from thousands of services. Discuss shard management, ingestion bottlenecks, and real-time alerting. Use technologies like Fluentd, ElasticSearch, and S3 or cold storage. Jane Street values candidates who can scale internal telemetry and debug tooling systems reliably.
Tips:
- Start with log collectors (Fluentd/Logstash/Vector) → queue → storage/index.
- Cover horizontal scaling via sharding, partitioning, or topic-based routing.
- Optimize storage with compression + tiered storage (hot in ElasticSearch, cold in S3).
- Include real-time alerting: stream processors push anomalies to monitoring dashboards.
- Stress reliability: retries, idempotency, schema evolution, monitoring dashboards.
Behavioral & Culture‑Fit Questions
The behavioral portion of the interview zeroes in on how well you operate in Jane Street’s flat, feedback-rich, and high-stakes environment. Data engineers here don’t just write code—they partner directly with traders, researchers, and infra teams to deliver fast and reliable systems. That means you’re expected to be intellectually curious, humble enough to accept feedback mid-project, and sharp enough to defend your decisions when stakes are high.
Culture-fit questions often probe how you’ve handled fast-moving production incidents, complex migrations, or overnight fixes to unblock trading teams. They’re looking for engineers who thrive in ambiguity, enjoy pairing, and don’t silo themselves from business impact. You’ll likely be asked about a time you had to prioritize conflicting requests or worked with a domain you didn’t fully understand—because at Jane Street, technical skill matters, but so does collaborative ownership and clarity under stress. Your answers should show that you’re not just a good coder, but a thoughtful teammate in a mission-critical environment.
To prepare, practice structuring your answers with the STAR method (Situation, Task, Action, Result). This framework helps you organize your stories clearly: set the context, outline your responsibility, walk through the decisions and trade-offs you made, and end with the concrete impact. Using STAR not only keeps you concise but also highlights how your thought process and teamwork directly led to measurable outcomes.
Tell me about a time you identified a data quality issue in a pipeline.
How did you detect it, what steps did you take to fix it, and how did you ensure it wouldn’t happen again?
Example:
“In my previous role, I noticed sudden spikes in null values coming from a vendor feed. I traced the issue to schema drift where a field type had silently changed. I set up a schema validation step in the pipeline to catch future mismatches early and built an alert system to flag anomalies in near real time. This reduced similar issues by 80% and increased trust in our downstream dashboards.”
Tell me about a situation where you had to refactor a data model overnight.
Explain the context of the urgency—was it to support a trading desk or resolve a schema conflict? Describe your prioritization process, how you ensured downstream compatibility, and how you communicated with stakeholders. Highlight your ability to ship under pressure while maintaining correctness. This demonstrates agility and accountability, both valued traits at Jane Street.
Example:
“We had an urgent request from the trading desk to add new instrument attributes for overnight analysis, but the schema conflicted with existing joins. I prioritized core fields first, implemented a temporary compatibility layer to avoid breaking downstream queries, and documented changes clearly to the team. By morning, the desk had the data they needed, and we rolled out a fuller refactor the next week.”
Describe a situation where you had to balance speed and reliability in delivering a data pipeline.
What trade-offs did you make, and how did you communicate those decisions to your team or stakeholders?
Example:
“For a market-data feed migration, the desk needed the pipeline live in two weeks. I chose to deliver an MVP that handled core tick data first, even though enrichment and validation layers were lighter than I’d prefer. I made sure stakeholders understood the trade-offs, and we scheduled a follow-up release to add reliability features. This approach unblocked trading while keeping long-term quality on track.”
What motivates you to work in a quantitative trading environment?
Discuss your passion for data, curiosity about systems under real-world constraints, or interest in market dynamics. You could also reference intellectual rigor and the feedback loop from immediate trading impact. This allows you to show cultural alignment with Jane Street’s mission and pace.
Example:
“I love working in environments where the feedback loop is immediate—if the pipeline is fast and correct, it directly impacts trading performance. The intellectual rigor and real-time problem-solving in trading match my curiosity for systems under pressure. I’m motivated by building tools that traders and researchers can trust every millisecond.”
Describe a time you owned a system end-to-end.
Detail how you scoped the system, interfaced with stakeholders, monitored reliability, and iterated on feedback. Highlight autonomy and responsibility over performance or correctness. Jane Street values engineers who take full accountability for systems that power real-time decisions.
Example:
“I led the design of a new ETL job that ingested and normalized alternative data sets. I gathered requirements from analysts, built the ingestion pipeline, set up monitoring, and iterated based on feedback. Owning it fully meant I was accountable not only for correctness but also for performance. That experience taught me how to balance autonomy with communication.”
Have you ever failed to deliver a project on time? What did you learn?
Be honest but focused on growth—discuss misestimation, lack of coordination, or missed complexity. Emphasize how you improved planning, communication, or testing in the aftermath. Jane Street appreciates humility paired with improvement mindset.
Example:
“Yes—once I underestimated the complexity of migrating a pipeline to handle nested JSON inputs. We missed the initial delivery by a week. I learned to prototype early, surface risks sooner, and build more buffer into estimates. Since then, I’ve become much more transparent about uncertainty in planning.”
How do you stay grounded when things break in production?
Describe a production incident, how you diagnosed and triaged it, and how you handled pressure or blame. Reinforce the value of composure, logging, alerting, and team transparency. This shows your ability to thrive in Jane Street’s high-reliability environment.
Example:
“During a production outage caused by a corrupted Kafka topic, I focused on quick triage—rerouting critical data to a backup topic while we investigated. I kept the team updated every 15 minutes, documented each step, and made sure we captured postmortem notes for process improvements. Staying calm and methodical helped us recover in under an hour.”
How to Prepare for a Data Engineer Role at Jane Street
The interview process for a data engineering position at Jane Street is unlike those at traditional tech companies. While many companies assess for general backend aptitude, Jane Street expects you to think like an infrastructure architect, a systems engineer, and a trader-support technologist all at once. Preparing effectively means sharpening your coding skills and learning how to reason through system-level challenges in a real-time data environment. Below are strategies tailored specifically to this context.
Master Functional & Streaming Paradigms
Jane Street’s tech stack is rooted in functional programming, particularly OCaml—so understanding immutability, recursion, and higher-order functions will help you align with their engineering mindset. Even if you’re more fluent in Python, practicing with generators, iterators, and tools like itertools can mirror how streaming pipelines behave. If you’ve dabbled in Rust, that’s a bonus—it shares Jane Street’s emphasis on correctness and control over memory and concurrency.
In addition to language proficiency, embracing the mindset behind functional programming is key. That means thinking in terms of data transformation pipelines rather than imperative steps. Practice breaking problems down into pure functions that are stateless and composable—skills that mirror how you’d build ETL or real-time ingestion systems at Jane Street.
Also, get comfortable reasoning about types. OCaml is a strongly-typed language with powerful type inference, and engineers at Jane Street often design around the type system to catch errors early and enforce correctness. Even if you’re interviewing in Python, being able to talk through how you’d model data flows using types, pattern matching, or algebraic data types (ADTs) shows deeper understanding.
If you’re unfamiliar with OCaml, you don’t need fluency—but reading a few Jane Street blog posts, solving a couple of problems in the Real World OCaml book, or understanding the OCaml ecosystem (like Async for concurrency) will set you apart from other candidates.
Tips:
- Try re-implementing a simple ETL job in a functional style (e.g., map/filter/reduce) instead of loops.
- Read the Real World OCaml book and practice 2–3 small exercises.
- In Python, experiment with
functoolsanditertoolsto mimic functional pipelines. - Practice designing schemas with strong typing—e.g., enforce constraints in code instead of relying only on downstream validation.
Mock the Time‑Boxed Coding Assessment
Jane Street’s coding assessments and technical interviews are intentionally tight on time. It gives candidates often just 45 to 60 minutes to solve problems that test both depth and speed. This simulates the environment you’ll work in: where fast, accurate decisions on data infrastructure can affect trading outcomes in real time. Here’s how to handle that pressure strategically:
- Prioritize clarity over cleverness. A correct, well-structured brute-force solution is better than an incomplete “smart” one. Start with something working, even if slow, then optimize if time allows.
- Establish a base case early. In stream joins or pipeline transformations, define your inputs, outputs, and basic logic as soon as possible. This gives you a safety net if time runs out.
- Narrate trade-offs as you code. Don’t stay silent! Talk through time/space complexity, assumptions (e.g., ordering, deduplication), and edge cases. Jane Street interviewers assess your reasoning as closely as your syntax.
- Use sketching techniques. If the solution is long, verbally sketch a structure or write out function stubs to show your direction even if you don’t finish implementation.
- Keep a mental timer. Allocate 25% of time to understanding and modeling the problem, 50% to coding the initial solution, and leave 25% to test and iterate. Don’t spend more than 5 minutes stuck on a single approach. You always want to pivot and explain why.
Tips:
- Practice narrating every coding session out loud—it trains you to “show your work” under pressure.
- Have a stopwatch handy: train your brain to sense when 5 minutes is too long on one idea.
- Get used to writing pseudo-code quickly before jumping into full code.
Think Out Loud
Strong communication is just as important as technical correctness in a Jane Street data engineer interview. You’re not expected to have all the answers immediately, but you are expected to think aloud in a clear, structured way. Start by restating the problem in your own words to confirm understanding, then walk through your plan step by step before diving into code.
Use specific terminology: talk about latency bottlenecks, back-pressure, or exactly-once delivery semantics instead of vague phrases like making it faster or cleaning the data. As you implement, explain your choices and trade-offs—why you’re using a windowed aggregation instead of a full table scan, or why partitioning by a timestamp field improves performance.
If you hit an unexpected edge case or bug, narrate your debugging logic. This shows resilience, systems thinking, and the ability to handle uncertainty. When wrapping up, summarize what you’ve built, what assumptions you made, and what improvements you’d make with more time.
Remember, at Jane Street, engineers don’t work in silos. Showing that you can reason precisely, communicate with empathy, and make your thought process accessible to teammates (even non-engineers) is a core part of what interviewers look for.
Tips:
- Always restate the problem first—it buys time and ensures alignment.
- Use concrete examples (“say we get a trade at 12:01:05 with latency X…”) to illustrate logic.
- Avoid filler words; structure your reasoning in steps: “First, I’d…, then I’d…, finally I’d…”
- Treat the interviewer like a teammate—invite feedback as you code.
Brute Force → Optimize
Jane Street interviewers appreciate seeing how you evolve your thinking. Start with an obvious or unoptimized approach like a nested loop join or full table scan and then iterate toward a smarter solution using windowed aggregations, indexing, or pre-filtering strategies. This approach demonstrates not only knowledge, but growth mindset under constraint. To build this habit and sharpen your skills further, complete our Data Engineer Learning Path for structured practice and interview prep.
Tips:
- Always get a working solution down before refining.
- Label your code sections as “first pass” and “optimized pass” so the interviewer sees your thought evolution.
- Mention complexity out loud: “This is O(n²), but if I pre-sort, I can get to O(n log n).”
- Even if you don’t finish the optimization, showing awareness is a big plus.
Peer Mock Interviews
If possible, connect with ex–Jane Street engineers or those with experience in quant finance. Their feedback can surface blind spots, particularly around time-sensitive edge cases and streaming behaviors under production load. Practice explaining how you’d design idempotent data ingest systems or recover from partial pipeline failures.
FAQs
Is a data engineer a high paying job?
Yes. Data engineering is one of the highest-paying tracks in tech due to its direct impact on analytics, machine learning, and business-critical systems. According to Glassdoor, median salaries for data engineers in the U.S. often exceed $120K, with top firms like Jane Street offering compensation packages well above industry averages. To put this into perspective, see the general salary report for understanding and compare across roles and industries.
Is data engineering hard to get into?
Breaking into data engineering can be challenging since it requires both software engineering skills and strong knowledge of databases, distributed systems, and data pipelines. However, consistent practice in SQL, Python, and frameworks like Spark or Kafka, along with project experience, can make you competitive.
Do data engineers get laid off?
Like any role, data engineers are not immune to layoffs, but the role is considered highly resilient. Because nearly every modern company depends on reliable data infrastructure, demand for skilled data engineers tends to stay strong even in downturns. To dive deeper into how the market is evolving, see our job report to know the trend and where data opportunities are growing.
What is the hardest part of data engineering?
The hardest part is often balancing correctness, scalability, and reliability. Engineers must account for late-arriving data, schema changes, system failures, and performance bottlenecks. At firms like Jane Street, the added challenge is ultra-low latency requirements in real-time trading.
Does Jane Street offer a hiring bonus to data engineers?
Jane Street is known for highly competitive compensation packages, which typically include base salary, performance bonuses, and sometimes hiring bonuses. While specifics aren’t public, many candidates report that Jane Street’s overall pay structure is among the best in finance and tech.
Does Jane Street use Python?
Yes. While Jane Street is famous for its OCaml-based systems, Python is also widely used, especially for data analysis, prototyping, and pipeline tooling. Engineers often move between OCaml for production systems and Python for quick iterations or research tasks.
What is the average salary for a data engineer at Jane Street?
The Jane Street data engineer salary is among the highest in both tech and finance, reflecting the role’s direct impact on trading outcomes. Entry-level data engineers in New York typically earn a base salary around $150K–$175K, with annual bonuses and profit-sharing often pushing total compensation to $250K–$400K+. More experienced engineers—especially those with trading infrastructure exposure—can see figures well beyond that.
- Entry-Level (L1 – New Grad/0–1 YOE)
- Base: $150K–$175K
- Total Comp (bonus + profit sharing): $250K–$300K+ (Indeed)
- Mid-Level (L2 – 2–4 YOE)
- Base: $175K–$225K
- Total Comp: $300K–$400K+ (Levels.fyi)
- Senior (L3/L4 – 5+ YOE, trading infra exposure)
- Base: $225K–$300K
- Total Comp: $400K–$500K+ (Levels.fyi)
Are there current data engineer openings at Jane Street?
Yes! Jane Street regularly hires for data engineer roles across multiple offices. Visit Interview Query job board or the Jane Street careers page to explore open listings. To stay ahead of new postings, we recommend signing up for the newsletter job alerts to be notified as soon as roles open.
Conclusion
The Jane Street data engineer interview is unlike any other—it blends deep technical rigor with industry-specific challenges around real-time systems, data integrity, and performance under pressure. Success in this process requires more than coding chops; it demands a systems-thinking mindset, a clear communication style, and a curiosity for how data fuels trading decisions.
To recap, we’ve walked through the full hiring process, reviewed the most common question types, and outlined preparation strategies tailored to Jane Street’s high bar. If you’re serious about landing the offer, scheduling a 1:1 mock interview for targeted feedback.
Interested in other roles at Jane Street? Check out our in-depth guides for the Machine Learning Engineer Interview Guide and Software Engineer Interview Guides to expand your prep and explore adjacent pathways into the firm.
Jane Street Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
SQL | Medium | |
Data Structures & Algorithms | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences