
IBM Data Engineer Interview & Coding Assessment Guide


Introduction
Landing a Data Engineer role at IBM means joining a global leader in cloud computing, AI, and enterprise data solutions. As an IBM Data Engineer, you’ll work on scalable data pipelines, build infrastructure for analytics and AI, and solve real-world challenges with cutting-edge tools.
This guide walks you through the IBM Data Engineer interview process, what to expect in the coding assessment, and sample interview questions to practice. If you’re preparing for the role in 2025, this is your go-to resource.
Why this Role in IBM?
At IBM, data engineers do more than just build pipelines—you help power how the business makes decisions. You’ll own the systems that move data across products, teams, and clouds (and yes, IBM has a lot of clouds).
Your day-to-day might involve writing PySpark jobs, tuning SQL queries for performance, or debugging a data flow that broke across three environments. You’ll often work with data scientists, analysts, and architects to define schemas or optimize joins. It’s collaborative, but you’ll also spend heads-down time in Airflow or terminal windows solving gnarly data issues.
What Is the Interview Process Like for an IBM Data Engineer?
The interview process for the IBM Data Engineer role involves a well-thought-out and structured hiring procedure. Here’s a step-by-step guide on what you can expect:
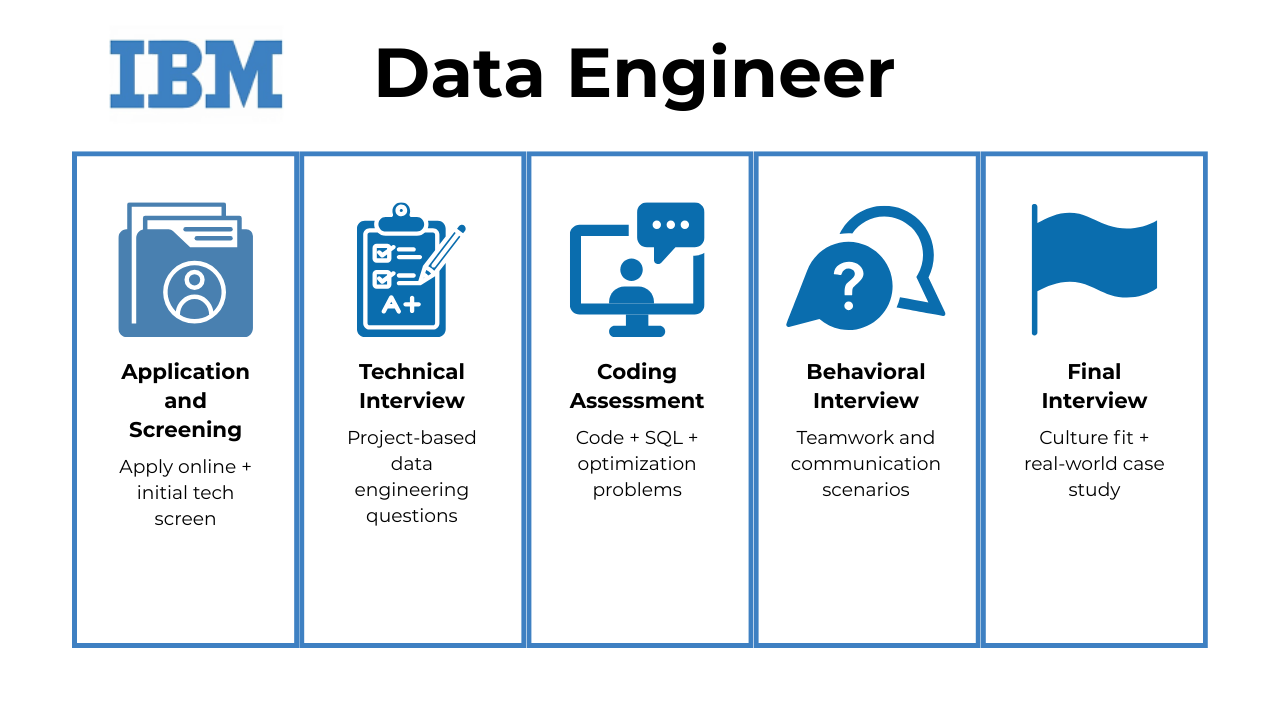
Application and Screening
The first step is to submit your application online at the IBM careers portal. IBM always recommends that you join their Talent Network when applying for a role.
The hiring team will carefully review your application, focusing on your data engineering expertise and if your application stands out. If you get the green light, you’ll be contacted by the hiring team for an initial technical screening to assess your data engineer proficiency, your background, and experience.
Technical Interview
Next up, you’ll have a technical interview where you can expect a dynamic and hands-on evaluation of your data engineering skills. Be prepared to discuss your past technical projects. You’ll be assessed on how you would approach challenges commonly faced in data engineering projects.
Coding assessment
This round is designed to assess your coding proficiency. You may be asked to write code to manipulate and analyze data, implement algorithms, or optimize code for efficient data processing. Also expect questions related to SQL queries, database design, and optimization.
Behavioral Interview
In this round of the Data Engineer Interview process at IBM, anticipate a discussion focused on your experiences, teamwork skills, and problem-solving approaches within a collaborative setting. You’ll be assessed based on your ability to work collaboratively within a team, your communication skills, and how you overcome challenges.
Final Interview
In the final round, the hiring team will assess you based on how your personal values align with the vibrant culture at IBM. You’ll be asked questions about collaboration, teamwork, and your approach to innovation.
This round might involve in-depth discussions and collaborative exercises tailored specifically to data engineering challenges. Expect real-world scenarios, case studies, or team activities that mirror the dynamic environment at IBM.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Ibm?
What Questions are Asked in a IBM Data Engineer Interview?
Landing a Data Engineer role at IBM means showing you can not only write rock-solid code but also think strategically about how data powers products and collaborate effectively within cross-functional teams. The interview is split into three core sections—Coding, Product Sense, and Behavioral—to assess your end-to-end capabilities. You’ll move from hands-on algorithmic challenges to scenario-based product discussions, and finally into conversations that probe how you work, learn, and lead in a complex enterprise environment.
Coding / Technical Questions
Here you’ll tackle real-world data problems—writing Python or Java routines, crafting optimized SQL for large tables, and sketching out data-warehouse schemas or ETL pipelines. Expect to demonstrate algorithmic efficiency (O-notation), sound handling of edge cases, and clean, maintainable code. These exercises mirror tasks like batching time-windowed aggregations in Cloud Pak for Data or merging high-velocity streams in InfoSphere.
-
Attribution modeling is a core part of marketing analytics and customer behavior analysis, key areas for IBM’s data engineering teams working on retail or ecommerce platforms. This problem involves joining large event logs with session-to-user mappings to identify the initial marketing channel that led to a conversion. Mastery of efficient joins, filtering, and aggregation across big datasets reflects a data engineer’s role in enabling accurate ROI analysis and marketing effectiveness measurement.
-
This problem evaluates your capacity to craft an efficient, scalable algorithm—a core expectation for IBM’s software engineering culture. By using a hash map (dictionary) to track seen values and their indices as you traverse the array, you can check for the complement (target minus current element) in constant time and thus achieve linear overall runtime. This pattern reflects the kinds of data-intensive challenges you’d face at IBM, where optimizing for both speed and clarity is paramount.
-
This problem assesses your understanding of streaming algorithms and space-efficient data processing—essential for real-time analytics and large-scale data ingestion pipelines common at IBM. Implementing reservoir sampling or similar techniques ensures uniform random selection from a potentially unbounded data stream using minimal memory. Data engineers at IBM frequently work on streaming data scenarios where such algorithms help maintain performance and accuracy without prohibitive resource costs.
-
To solve this, join the
customersandshipmentstables oncustomer_id. Then, check if theship_datefalls betweenmembership_start_dateandmembership_end_dateto determine the value ofis_member. Given two sorted lists, write a function to merge them into one sorted list.
This classic merging problem tests your understanding of pointer-based algorithms, which is directly applicable to IBM’s ETL and data integration platforms (e.g., DataStage or InfoSphere). By iterating through both input lists with two indices and appending the smaller current element, you achieve an optimal O(n + m) runtime and minimal additional memory overhead. Such a routine underpins merge-sort implementations and real-time stream joins in enterprise pipelines. Robust solutions also handle edge cases like empty inputs or lists of unequal length, reflecting the resilience expected in IBM’s production systems.

System / Product Design Questions
In this section, you’ll architect end-to-end data systems—such as streaming ingestion pipelines, data marts, or analytics platforms—sketching high-level diagrams and justifying trade-offs around scalability, reliability, and security. Expect to discuss component selection (e.g., Kafka vs. IBM MQ, Db2 vs. Cloud Object Storage), failure handling strategies, and data partitioning schemes. Clear, modular designs and well-reasoned technology choices reflect the demands of IBM’s enterprise-grade solutions.
Design a real-time event processing pipeline to ingest and transform clickstream data for user behavior analytics.
You’ll need to outline how to use IBM Event Streams (Kafka-based) for ingestion, IBM Streams or Cloud Pak for Data for real-time transformations, and appropriate storage such as Cloud Object Storage or Db2. Discuss windowing strategies and partitioning to scale horizontally, plus exactly how you’d handle failures and replay scenarios to guarantee data integrity. Highlight trade-offs around latency, throughput, and operational complexity to show enterprise-grade design thinking.
Architect an enterprise data warehouse that supports both transactional and analytical workloads for multiple business units.
Explain how you’d leverage IBM Db2 Warehouse or Netezza for storage, choose between star and snowflake schemas, and orchestrate ETL with DataStage. Detail partitioning and indexing strategies to optimize mixed OLTP/OLAP workloads, and how you’d enforce concurrency controls and workload isolation to prevent resource contention. Cover schema evolution, data retention, and governance policies to ensure long-term maintainability.
Design a data monitoring and alerting framework to detect anomalies and failures in ETL workflows.
Propose using IBM Cloud Pak for Data Operational Insights or embedding custom metrics in DataStage jobs, combined with alerting integrations (e.g., PagerDuty, Slack). Describe which KPIs you’d track—throughput, latency, error rates—and how you’d set thresholds, implement retry logic, and trigger automated failover. Discuss strategies for reducing alert noise and integrating incident management practices to uphold data quality and uptime.
Create a self-service analytics platform that enables non-technical stakeholders to run ad-hoc reports while maintaining data governance.
Show how you’d build a metadata catalog and access controls via IBM Watson Knowledge Catalog, expose governed data assets, and surface them through Cognos Analytics or Watson Studio dashboards. Address authentication/authorization, data lineage, and versioning to satisfy compliance requirements. Balance UI simplicity, query performance, and centralized governance to drive adoption and trust across business teams.
Architect a global, multi-region data replication strategy to ensure high availability and disaster recovery for critical data services.
Outline how you’d use IBM Cloud Object Storage georeplication or Db2 HADR to synchronize data across regions. Compare synchronous vs. asynchronous replication models, discussing RPO/RTO trade-offs and network latency considerations. Specify failover mechanisms, cross-region bandwidth costs, and regular recovery drills to validate your DR plan under real-world conditions.
Behavioral & Product-Sense
This combined segment assesses how you translate data into product value and how you work within IBM’s collaborative culture. You’ll define key metrics for new features, prioritize data-driven enhancements, and outline reporting dashboards, then switch to STAR-style behavioral prompts (“Tell me about a time…”) on topics like resolving data discrepancies or leading process improvements. Demonstrating product empathy, clear storytelling, and quantifiable outcomes shows you can drive both technical and organizational impact.
-
Discuss various analytical methods such as user funnel analysis, path analysis, cohort analysis, and usage metrics. Explain how these analyses can identify user drop-off points, common user paths, and trends over time. Mention the importance of validating findings through A/B testing or user surveys.
Describe a data project you worked on. What were some of the challenges you faced?
In an IBM Data Engineer role, you might inherit a complex ETL pipeline built on DataStage and InfoSphere that processes both on-prem Db2 data and cloud-native sources. Walk through how you diagnosed schema mismatches, performance bottlenecks, or governance gaps—perhaps by adding metadata-driven validations or re-partitioning jobs in Cloud Pak for Data. Explain how you collaborated with data stewards, QA, and business analysts to build automated checks and ensure end-to-end lineage.
-
One strength could be your ability to translate high-level business goals into detailed technical designs, leveraging your expertise in Kafka integrations or Db2 performance tuning to deliver scalable solutions. You might also highlight your proactive approach to building self-service data platforms, empowering analysts through governed access in Watson Knowledge Catalog.
Tell me about a time you discovered a significant data discrepancy in an enterprise reporting pipeline. How did you identify it and what steps did you take to resolve it?
In large-scale environments like IBM DataStage or InfoSphere, even small anomalies can cascade into misleading business insights. Describe how you first detected the issue—whether through automated data checks, anomaly-detection scripts, or stakeholder feedback—and detail your systematic root-cause analysis. Explain how you collaborated with engineering, QA, and business teams to implement corrective actions. Finally, share any metrics or outcomes that demonstrate how your intervention improved data accuracy and rebuilt stakeholder trust.
Tell me about a time you persuaded cross-functional partners to adopt your data-driven recommendation. How did you build consensus and measure success?
Aligning engineering, analytics, and business stakeholders at IBM requires clear communication and empathy for different priorities. Describe the context of your recommendation—whether it was a new dashboard, schema redesign, or performance optimization—and how you tailored your presentation to each audience’s needs. Explain the techniques you used (e.g., interactive demos, visual storytelling, data-backed proposals) to address concerns and secure buy-in.
How would you define the key metrics for monitoring the health of a real-time data ingestion pipeline in IBM Cloud Pak for Data?
Effective monitoring in Cloud Pak for Data balances operational detail with business relevance. Start by selecting metrics such as end-to-end latency, throughput (records/sec), and error counts (parse failures, timeouts), then describe how you’d present them in a unified dashboard. Discuss strategies for dynamic thresholding or anomaly detection to reduce false positives while ensuring timely alerts. Finally, explain how you’d integrate these metrics into incident management workflows.
A business unit requests ad-hoc reporting on historical sales data via Cognos Analytics. How would you prioritize, scope, and roll out this capability?
Delivering ad-hoc reports in Cognos Analytics requires balancing immediacy with long-term governance. Outline how you’d gather detailed requirements by interviewing end users about report complexity, data latency needs, and access patterns. Map these insights to technical tasks—data modeling, metadata cataloging, and performance tuning—and estimate effort versus impact to sequence quick wins (e.g., template reports) alongside foundational work (security policies, lineage tracking).
Design a customer-churn insights dashboard in IBM Watson Studio. Which visualizations and interactions would you include to drive data-led decisions?
A churn dashboard in Watson Studio should make complex retention insights accessible to non-technical users. Begin with cohort retention curves and funnel analyses to pinpoint dropout stages, then add filters for dimensions like region, subscription tier, or engagement frequency. Integrate predictive churn scores and feature-importance visuals from your ML models to help teams prioritize high-risk segments. Finally, discuss interactive elements—threshold-based alerts, drill-downs, and exportable reports—to ensure the dashboard supports both strategic reviews and real-time interventions.
How to Prepare for a Data Engineer Role at IBM
Landing a data engineer role at IBM means showing more than just coding chops. You’ll need a solid grasp of systems thinking, the ability to design scalable pipelines, and the communication skills to explain your work clearly (even to non‑technical teammates). Here’s how to prepare with intention:
Understand IBM’s Data Stack and Strategy
Start by digging into the job description—note what’s emphasized. Is it ETL design? Real-time systems? Cloud architecture?
Then zoom out. Learn how IBM’s data engineers contribute to products like Cloud Pak for Data, Db2, or DataStage. These aren’t just buzzwords—they signal how IBM handles massive, enterprise-grade data infrastructure.
Drill the Fundamentals—But With Depth
IBM interviews go beyond trivia. You’ll be expected to reason through data modeling trade-offs, design schemas, and write SQL that scales.
Revisit core concepts like database normalization vs. denormalization, data warehousing design, and building ETL pipelines. And don’t neglect your coding fluency—Python or Java often show up in technical rounds.
Show You Can Solve Real Problems
Interviewers want to know: can you take a messy data problem and structure a smart solution Practice talking through problems out loud. Clarify assumptions. Optimize where it counts. And if you’ve worked with legacy systems or reworked brittle pipelines before, bring those stories to the table. Yes, they’ll ask you to design schemas. You should know how to build from requirements using ER diagrams or similar modeling techniques. Interviewers often care less about tools and more about your design logic.
Don’t Sleep on Behavioral Rounds
Mock interviews help you tighten your delivery and identify gaps. Pair up with a peer or use a platform to simulate the pressure. It’s also worth staying current—IBM cares about engineers who learn continuously.
FAQs
What is the Average Salary for a Data Engineer Role at IBM?
Average Base Salary
Average Total Compensation
Where Can I Read More Discussion Posts on IBM’s Data Engineer Role Here in Interview Query?
Explore these IBM Data Engineer question posts that include valuable community comments and insights:
Are there any Job Postings about the IBM Data Engineer Role here at Interview Query?
You can always visit our job board to explore the latest IBM Data Engineer openings as they become available.
Is the IBM coding assessment on HackerRank?
Yes, IBM often uses HackerRank or similar platforms to assess coding and SQL skills. The test is timed and includes both coding challenges and scenario-based questions.
Conclusion
At Interview Query, we aim to provide you with not just insights, but a comprehensive toolkit for success in your interviews.
Don’t forget to check out the main IBM Interview Guide for other data-related roles such as Data Analyst, Data Scientist, Machine Learning Engineer, and Software Engineer. This guide offers overarching tips and strategies to enhance your overall interview preparation.
To deepen your prep, explore our Data Engineering Learning Path, get inspired by Alex Dang’s success story, and review real IBM data engineer interview questions to sharpen your approach.
With grit, perseverance, determination, and a little help from this guide, your success at IBM will be well within reach.
Ibm Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
Data Structures & Algorithms | Medium | |
SQL | Easy | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences