
Goldman Sachs Machine Learning Engineer Interview Guide


Introduction
Preparing for the Goldman Sachs machine learning engineer interview means stepping into one of the most technically rigorous hiring processes in finance. As Goldman Sachs accelerates its use of artificial intelligence across risk modeling, fraud detection, trading analytics, and digital banking, machine learning engineers now sit inside some of the company’s highest impact teams.
Goldman Sachs evaluates how candidates reason about data quality, regulatory constraints, and statistical robustness in high stakes financial systems. Interviews consistently prioritize mathematical depth, clarity of thought, and the ability to design interpretable, well governed machine learning solutions that can be trusted in production.
This guide outlines each stage of the Goldman Sachs machine learning engineer interview, highlights common questions, and shares proven strategies to help you stand out and prepare effectively with Interview Query.
Goldman Sachs Machine Learning Engineer Role Overview and Culture
The Goldman Sachs machine learning engineer role highlight responsibilities such as designing real-time inference pipelines, managing model registries and monitoring frameworks, and developing large-scale feature and training pipelines within the firm’s internal machine learning platform.
The GS engineering culture emphasizes precision, accountability, and strong engineering fundamentals. Machine learning engineers are expected to design solutions that balance innovation with stability, interpretability, and long-term governance. Success in the role depends on:
- End-to-end ownership of model development and deployment
- Cross-functional collaboration across engineering, product, risk, and compliance
- Building ML systems that are stable, auditable, and aligned with governance and performance standards
This culture values thoughtful tradeoff decisions and clear communication, especially when ML systems influence financial risk or regulatory obligations.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Goldman Sachs?
Why the Machine Learning Engineer role at Goldman Sachs
A Goldman Sachs machine learning career places you at the center of high-impact systems that shape how the firm measures market risk, detects fraud, supervises trading activity, and personalizes digital banking experiences. With billions of transactions moving through Goldman Sachs infrastructure each day, engineers work at a scale that demands rigorous statistical thinking, careful model governance, and a deep understanding of operational risk.
Pursuing ML at Goldman also means joining teams at the forefront of GS AI initiatives, including research into accelerated model training, real-time inference systems, and next-generation data platforms.
Goldman Sachs Machine Learning Engineer interview process
The Goldman Sachs ML interview process follows a structured sequence designed to evaluate technical depth, mathematical reasoning, and your ability to design reliable, well-governed systems for financial environments.
Based on recent candidate experiences, they favor interview loops with back-to-back rounds, real-time coding in CoderPad, and focused discussions on system reliability, error analysis, and the rationale behind modeling choices.
1. Recruiter screen
The recruiter call validates your background in machine learning, familiarity with Python and system design fundamentals, and interest in Goldman Sachs teams. Recruiters often listen for candidates who understand that ML in finance demands more rigor in monitoring, explainability, and documentation than consumer-facing contexts.
You can subtly highlight any experience working within policy or regulatory constraints, even if outside finance.
2. Technical phone screens
These interviews blend coding, probability, linear algebra, error analysis, and structured model design. Many candidates note that engineers use collaborative editors without autocomplete and expect clean reasoning aloud. What is unique here is the emphasis on precise mathematical justification, such as variance decomposition or stability checks, even during coding-heavy rounds.
For this round, explain not only what you would do but why the approach is robust under imperfect or sparse data.
3. Onsite interviews (4–5 rounds)
The onsite loop includes applied ML, coding, mathematical fundamentals, and system design for scalable deployment. Interviewers frequently conduct sessions back-to-back, mirroring the pace of production issues and time-sensitive risk reviews. A quietly distinctive feature of the onsite is the attention to model governance; candidates are often asked how they would detect drift, handle model overrides, or manage sensitive audit trails.
When discussing evaluation metrics, tie your choices to risk mitigation and long-term monitoring rather than accuracy alone.
4. Hiring manager interview
This conversation centers on ownership, cross-functional collaboration, and your ability to work with researchers, product teams, engineering, and compliance. Hiring managers often probe how you respond when a model that works well offline behaves unpredictably in production, reflecting the firm’s real-world complexity.
Don’t forget to share an example where you diagnosed a production issue through disciplined investigation and cross-team coordination.
5. Offer and team matching
Candidates are matched to risk modeling groups, digital banking teams, surveillance analytics, or trading-focused ML teams. Matching conversations often highlight the unique model lifecycles of each vertical, from real-time surveillance to slow-moving credit models that require strict governance.
Tip: Articulate which model environments you thrive in: fast-feedback loops, deeply governed pipelines, or long-term research cycles.
Across these stages, Goldman Sachs consistently tests problem solving under constraints, comfort with ambiguity, and clarity of communication.
Goldman Sachs Machine Learning Engineer Interview Questions
Machine Learning & Modeling Interview Questions
These questions focuses on how Goldman Sachs tests your depth in machine learning fundamentals, interpretability, and statistical reasoning across real financial use cases. Each question evaluates whether you can justify modeling choices, diagnose data issues, and connect model behavior to risk, governance, and long-term reliability.
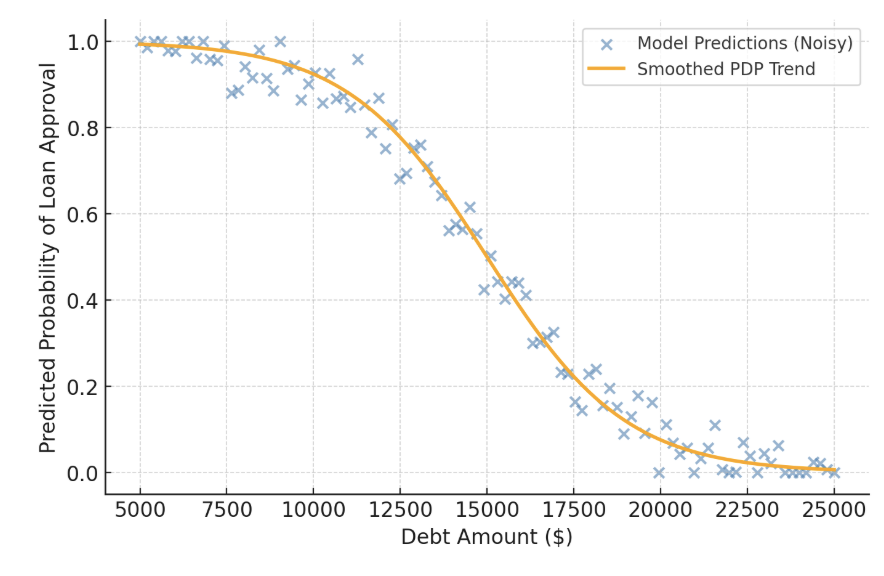
Explain Loan Rejections from a Black-Box Model Without Feature Weights
This question probes how you would justify individual loan rejections when the model does not expose explicit feature weights. It evaluates your ability to use interpretability techniques that remain compliant in regulated lending environments where clear reasoning is required even for black-box systems.
Encode a High-Cardinality Categorical Feature for Modeling
This question assesses how you convert a categorical variable with thousands of categories into a representation that trains efficiently and avoids overfitting. Interviewers want to see your understanding of sparsity tradeoffs, leakage risks, and how different encoding choices influence model transparency.
Explain the Bias–Variance Tradeoff When Choosing a Loan-Approval Model
This question evaluates whether you can articulate the balance between underfitting and overfitting when selecting between simple and complex models for loan decisions. The goal is to see if you can explain how model complexity affects generalization and stability in high-stakes, regulated financial settings.
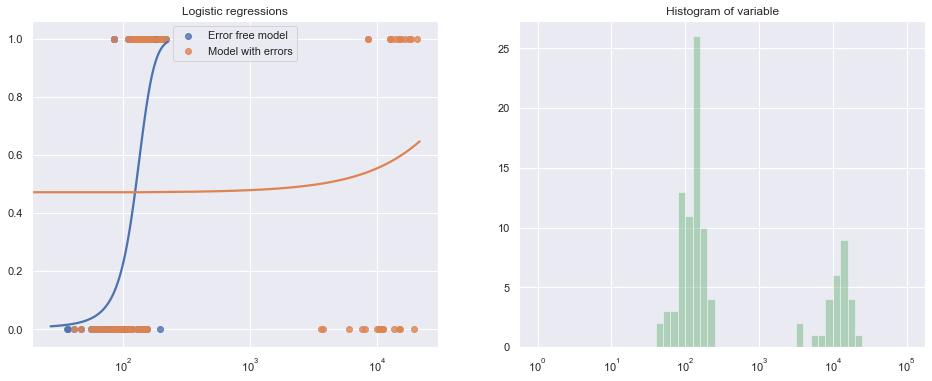
Is a Logistic Model Still Valid After a Decimal-Shift Data Error?
This question tests your understanding of how a major data quality issue affects logistic regression. You must reason through how shifting a feature by an order of magnitude distorts scaling, coefficients, and predictive behavior, especially when the affected feature is highly influential.
How Do You Prevent Overfitting in Tree-Based Models?
This question is designed to see whether you understand why tree-based models often memorize noise and how you control that tendency. It focuses on your ability to use hyperparameters and regularization techniques to manage the bias–variance balance in practical modeling work.
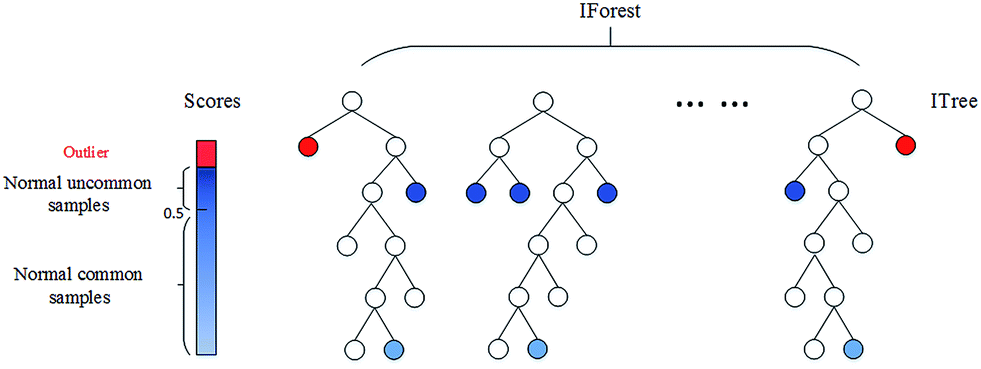
Detect Anomalies in Univariate vs. Bivariate Data
This question asks you to contrast anomaly detection strategies for single-feature data versus two-feature data. Interviewers assess whether you understand when simple statistical rules suffice and when joint distributions or multivariate techniques are required.
Evaluate and Compare Credit Risk Models for Personal Loans
This question looks at your ability to treat loan approval as a classification problem and evaluate competing models over the full loan lifecycle. You must connect metrics like AUC, precision and recall, calibration, and confusion matrices to real credit outcomes such as defaults and long-term profitability.
Coding & Algorithms Interview Questions
This section highlights Goldman Sachs’ focus on strong algorithmic thinking and efficient coding under pressure. Each problem tests whether you can reason clearly about data structures, optimize for time and space, and implement production-ready solutions without relying on built-in shortcuts.
Compute the Amount of Rainwater Trapped in a 2D Terrain
This question measures whether you can compute trapped water using efficient O(n) logic. It checks your understanding of boundary reasoning, prefix and suffix maxima, and how to avoid inefficient brute-force solutions.
Find the Shortest Transformation Sequence Between Two Words in a Given Word List
This question frames the problem as finding the shortest path in an implicit graph where edges connect words differing by one character. It evaluates your grasp of graph traversal, adjacency relationships, and search strategies that handle exponential branching.
Compute the New Median When a Single Value Is Inserted Into a Sorted Data Stream
This question tests whether you can update a median efficiently without recomputing the full distribution. It checks your knowledge of ordered data structures and how to manage time and memory tradeoffs in streaming contexts.
Merge Multiple Sorted Lists Into One Globally Sorted List Without Using Built-In Sort Functions
This question checks whether you can leverage the sorted nature of each list to build a more efficient merge process. Strong answers use pointers or a priority structure to repeatedly select the minimum element across lists.
Implement an LRU Cache With O(1) Get and Put Operations
This question evaluates your ability to design a cache that combines a hash map and a linked list to guarantee constant-time access and eviction. Interviewers want to see clean reasoning around both data structure interactions and API design.
Example:
cache = LRUCache(2)
cache.put("sample", 55)
cache.get_if_exists("sample") # returns 55
cache.get_if_exists("key") # returns None
cache.put("hello", 10)
cache.put("sample", 9)
cache.put("world", 5)
cache.get_if_exists("hello") # returns None
System Design Interview Questions
This section emphasizes Goldman Sachs’ expectation that machine learning engineers think like systems architects who can design reliable, traceable, and scalable infrastructure. Each question assesses whether you can connect modeling requirements with real-world engineering constraints, governance standards, and the operational demands of high-stakes financial environments.
-
This question measures your ability to design a full pipeline that ingests external APIs, standardizes and enriches the data, and exposes reliable features for modeling teams. It highlights the operational and governance demands of ML systems in finance.
Design a Low-Latency Type-Ahead Recommendation System
This question tests whether you can architect a predictive search system that responds in milliseconds. You must combine fast prefix lookup, ranking logic, and ML-powered relevance while satisfying strict latency guarantees.
Design a Distributed Facial-Recognition System for Employee Time Tracking and Secure Access
This question evaluates whether you can integrate a facial-recognition model with identity management, enrollment workflows, and a distributed backend. The focus is on scalability, security, and consistent access control.
-
This question asks you to build a cross-modal retrieval system using shared embeddings, vector search, offline indexing, and online query encoding. The interviewer wants to see your understanding of how to combine retrieval and re-ranking components effectively.
Automate Retraining and Deployment of a Goldman Sachs Production Risk Model With Minimal Downtime
This question focuses on ML Ops in a regulated environment. You must design a pipeline that retrains models on schedule, deploys versions safely, monitors performance, and supports rapid rollback without interrupting critical systems.
How Would You Build a Stripe-to–Goldman Sachs Revenue Warehouse ETL Pipeline?
This question evaluates your ability to design a secure, governed ETL flow for payment data. It tests how you think about ingestion, schema design, transformation, lineage, auditability, and the reliability required for financial reporting.
SQL Questions
This section highlights Goldman Sachs’ emphasis on precise, business-aware SQL that can support compliance, risk monitoring, and analytics. Each question tests whether you can translate real financial workflows into accurate queries that handle dates, duplicates, window logic, and imperfect data with discipline and clarity.
Find Goldman Sachs Customers Active on Every Day in a Period
This question tests whether you can convert a time-based business requirement into SQL. It requires filtering by date, grouping activity at the customer-day level, and identifying users who appear consistently throughout the window.
bank_transactionstableColumn Type user_idINTEGER created_atDATETIME transaction_valueFLOAT idINTEGER Output:
Column Type number_of_usersINTEGER Identify Goldman Sachs Customers Who Transacted on Every Day in a Given Window
This question evaluates your ability to handle date filtering, grouping, and distinct day counts to answer a business query about daily activity. It checks whether you can write efficient SQL that remains correct when customers transact multiple times per day.
Write a Query to Return Only Duplicate User Records
This question checks whether you can identify and return only rows that appear more than once based on id, name, and created_at. Interviewers are looking for careful use of grouping or window functions to define what counts as a duplicate.
Compute a 3-Day Weighted Rolling Average of New Users With Missing Dates
This question tests whether you can compute a weighted metric across three days even when some dates are absent from the table. You must reconstruct the date sequence, join appropriately, apply weights, and normalize the result.
Query the Last Daily Transaction for Each Goldman Sachs Client Account
This question assesses whether you can use window functions or grouping techniques to extract the final transaction per account per day. It emphasizes building clean daily snapshots needed for risk reporting and analytics.
SELECT
created_at,
id,
transaction_value
FROM bank_transactions
WHERE created_at IN (
SELECT
MAX(created_at)
FROM bank_transactions
GROUP BY DATE(created_at)
)
ORDER BY created_at;
Behavioral & Cross-Functional Scenarios
This section focuses on how Goldman Sachs evaluates collaboration, communication, and decision-making in high-stakes environments. Each question reveals whether you can operate with ownership and clarity while navigating ambiguity, cross-functional dependencies, and the rigor expected in a regulated financial institution.
Why Do You Want to Work at Goldman Sachs?
This question reveals whether you understand Goldman Sachs’ culture and what motivates you about the environment. Interviewers want responses grounded in rigor, accountability, and long-term impact rather than generic reasons for joining a large company.
How Would You Explain Technical Insights to Non-Technical Stakeholders?
This question evaluates your ability to turn complex analytics or model outputs into clear guidance tailored to decision makers such as traders or compliance teams. Strong answers show clarity, precision, and an understanding of business context.
How Would You Prepare Imbalanced Data for a Goldman Sachs Machine Learning Model?
This question examines how you handle skewed class distributions in domains like fraud or credit risk. Interviewers expect you to discuss resampling, weighting, and the downstream effects of misclassification on risk and model governance.
Tell Me About a Project in Which You Had to Clean and Organize a Large Dataset
This question looks at how you approach inconsistent or fragmented datasets, which are common in large financial systems. It evaluates your ability to design a structured cleaning process and produce data that downstream teams can rely on.
Describe a Data Project You Worked On. What Were Some of the Challenges You Faced?
This question assesses whether you can navigate constraints such as messy upstream feeds, governance rules, and cross-team dependencies. Interviewers want to see methodical problem solving, clear communication, and awareness of operational risk.
Preparation guide for Goldman Sachs machine learning interviews
Effective Goldman Sachs ML interview preparation requires a balance of mathematical rigor, disciplined engineering practice, and clear communication. The firm evaluates how candidates build reliable machine learning systems for regulated, high-stakes environments, so your preparation should mirror the precision expected in production. Use the following areas to structure your study plan and align your approach with Goldman Sachs expectations.
Master statistics, probability, and linear algebra for financial modeling
Focus on distribution properties, hypothesis testing, variance decomposition, matrix operations, and optimization. These topics appear frequently in credit scoring, anomaly detection, and risk forecasting.
Tip: Be able to justify your choice of statistical tests or transformations in terms of stability and compliance requirements.
Review ML models with emphasis on interpretability and risk
Expect discussion of tree-based models, logistic regression, clustering, time-series approaches, and regularization. Interviewers look for understanding beyond mechanics, including why a model is appropriate in a risk-sensitive context.
Tip: Highlight techniques that improve clarity, such as feature importance validation, SHAP reasoning, or monotonic constraints.
Build familiarity with Goldman Sachs engineering culture and fintech products
Review how teams within risk, platform engineering, and digital banking use machine learning. Understanding the Marquee ecosystem, transaction-banking analytics, and fraud monitoring workflows provides valuable context during system design and behavioral conversations.
Tip: Reference specific GS product domains to demonstrate intent and alignment.
Prepare behavioral stories using measurable impact
Behavioral rounds emphasize ownership, communication, and integrity. Structure your responses around quantifiable results, cross-team coordination, and lessons learned when dealing with ambiguity or production issues.
Tip: Prepare 5–7 STAR stories with metrics that highlight end-to-end execution and accountability.
Goldman Sachs ML Engineer interview FAQs
1. What does the Goldman Sachs ML interview FAQ tell me about the overall difficulty?
The Goldman Sachs machine learning engineer interview is consistently rated as one of the more rigorous processes in finance. You can expect back-to-back rounds with real-time CoderPad exercises, detailed follow ups on modeling choices, and deep questions on model governance, drift detection, and data quality. The bar is high because machine learning systems at Goldman Sachs often support risk, fraud, and supervisory analytics where mistakes have real financial and regulatory impact.
2. How long does the interview process usually take?
Timelines vary by role and location, but most candidates can expect several weeks from initial recruiter outreach to final decision. A typical path includes a recruiter screen, one or two technical phone screens, an onsite loop of 4 to 5 interviews, then a hiring manager conversation and team matching. Scheduling, holidays, and headcount approval can extend the process, so it is normal to see pauses between stages.
3. What salary range can Goldman Sachs ML engineers expect?
Most machine learning engineer roles align to the software engineer ladder. Based on Levels.fyi data for Goldman Sachs software engineers in the United States, total annual compensation typically ranges from around 120,000 dollars at the analyst level to more than 220,000 dollars at the vice president level, with higher ranges in major hubs like New York. Packages usually include base salary, annual bonus, and restricted stock units that vest over three years.
4. What skills are most important to succeed in the GS ML interview questions?
The interview focuses on three pillars: strong Python and algorithms skills, solid machine learning and statistics fundamentals, and systems thinking for production ML. You should be comfortable with probability, linear algebra, model evaluation, drift detection, and feature engineering under constraints, as well as designing low latency pipelines that are traceable and easy to monitor. Behavioral rounds emphasize ownership, communication, and integrity.
5. Is the Goldman Sachs ML engineer role hybrid or fully in office?
Work arrangements depend on the specific team and office. Many engineering and machine learning teams are centered in major hubs like New York, Dallas, Bengaluru, London, and Warsaw, with a strong in office culture and some teams offering hybrid flexibility a few days per week. Remote only roles are less common for core engineering positions, especially those tied to trading or risk systems.
6. How can I stand out compared to other Goldman Sachs ML candidates?
You stand out by pairing strong fundamentals with clear awareness of how machine learning works in a regulated financial environment. That means talking concretely about monitoring, documentation, and model governance, not just accuracy. Candidates who can connect models to real risk, fraud, or personalization use cases at Goldman Sachs tend to make a stronger impression, especially when they back it up with well structured STAR stories.
Conclusion: Start your Goldman Sachs interview prep today
You now have a complete guide to begin your Goldman Sachs ML interview prep with clarity and direction. This resource outlines every stage of the process, explains the technical depth Goldman Sachs expects, and provides a structured way to strengthen your coding, modeling, and communication skills.
Take inspiration from Jerry Khong’s path. Before landing his machine learning engineer role, Jerry interviewed at more than 50 companies, refined his SQL and modeling abilities, and used Interview Query’s practice materials to improve his performance. His persistence shows how structured preparation can change outcomes. You can read his full story in the Jerry Khong success story.
To accelerate your own preparation, explore the Modeling and Machine Learning Learning Path, which offers guided modules, practice questions, and real interview patterns designed to help you build mastery in the areas Goldman Sachs evaluates. Pair it with mock interviews to simulate real sessions and build confidence.
Goldman Sachs Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Machine Learning | Easy | |
Let’s say we’re comparing two machine learning algorithms. In which case would you use a bagging algorithm versus a boosting algorithm? Give an example of the tradeoffs between the two. | ||
Probability | Hard | |
Data Structures & Algorithms | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences