
eBay Data Engineer Interview Guide: Process, Sample Questions & Preparation


Introduction
Joining as an eBay data engineer means operating at one of the largest data scales in global commerce. From ingesting terabytes of marketplace interactions to optimizing distributed pipelines for fraud detection and real-time recommendations, data engineers at eBay are core to how the platform runs—and evolves.
Role Overview & Culture
A day in the life of an eBay Data Engineer involves owning end-to-end data infrastructure—from writing Spark and Flume jobs to managing Kafka topics and deploying Flink-based real-time analytics layers. Teams ingest massive volumes of behavioral and transactional data across buyers, sellers, listings, and logistics. Engineers collaborate cross-functionally with ML teams, Product Analysts, and infra stakeholders to ensure data accuracy, latency, and scalability.
Culturally, eBay is rooted in customer-first thinking, continuous experimentation, and bottom-up ownership. This shows up in how data teams are structured—small, empowered pods that make infrastructure choices to match business needs, not the other way around.
Why This Role at eBay?
The scale of impact is huge—billions of events flow through the platform each day. You’ll work with a modern tech stack that includes Snowflake, Apache Flink, Airflow, and Kafka, supporting everything from dashboarding to real-time user segmentation. The data engineer career path at eBay is well-defined, moving from DE II to Senior and eventually to Staff, where you may own multi-org platform initiatives.
To land the job, you’ll face a multi-stage eBay data engineer interview focused on ETL design, big-data coding, and cross-team collaboration.
What Is the Interview Process Like for a Data Engineer Role at eBay?
The eBay data engineer interview process is built to test your ability to code at scale, architect robust pipelines, and communicate clearly across teams. Expect four core stages, each with distinct focus areas.
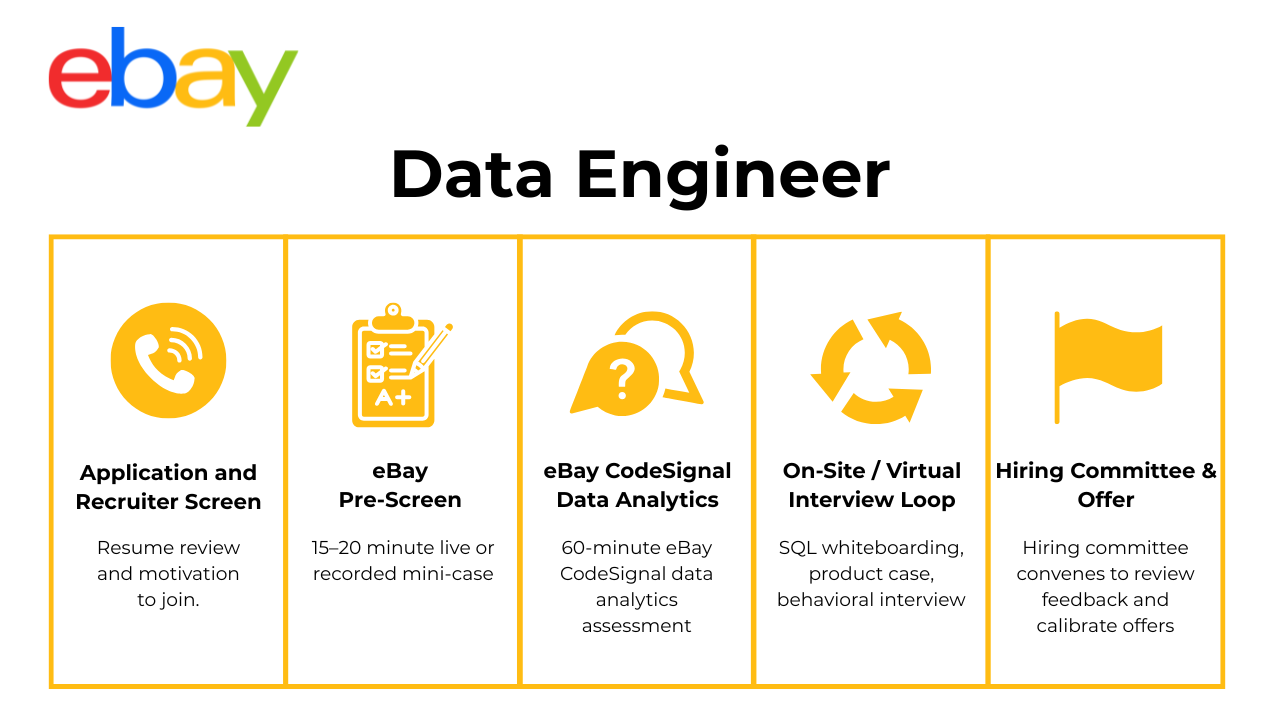
Application & Recruiter Screen
The process begins with a recruiter screen where your background, resume fit, and compensation expectations are discussed. You may also get early insight into the specific domain (e.g., Risk, Ads, Infrastructure) you’re being considered for.
Technical Screen
This round is typically a 45-minute virtual interview involving a Python or Scala coding problem and a set of SQL queries. Questions often mimic Spark or BigQuery-style data processing. You might be asked to manipulate nested JSON, filter large event logs, or join multi-partition datasets with performance constraints in mind.
On-Site / Virtual Loop
The main interview loop includes:
- A live coding round focused on distributed systems
- A system design interview where you’ll sketch a pipeline from ingestion to storage
- A behavioral panel evaluating collaboration and communication
- A hiring manager conversation to align on expectations and growth trajectory
During this stage of the eBay data engineer interview, interviewers are especially attentive to your understanding of data trade-offs: latency vs. throughput, partitioning strategies, schema evolution, and debugging edge cases in production.
Feedback & Hiring Committee
After the loop, eBay gathers feedback from all interviewers within 24 hours. A hiring committee then meets to evaluate your performance, determine level calibration (e.g., E4 vs. E5), and finalize offer terms.
Behind the Scenes: eBay uses structured feedback forms and bar-raiser interviewers to ensure consistency and fairness in decision-making.
Differences by Level: Junior engineers typically skip the leadership interview and focus more on core coding and SQL. Senior candidates are expected to handle platform-scaling design and communicate roadmap-level thinking.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Ebay?
What Questions Are Asked in an eBay Data Engineer Interview?
eBay’s technical interview questions are designed to test your engineering depth and system design intuition under real-world data constraints.
Coding / Technical Questions
A typical prompt might be: “Write a Spark job to deduplicate and aggregate seller events by hour.” These questions test your comfort with distributed joins, window functions, and handling high-volume data efficiently. Strong answers walk through brute-force logic first, then discuss optimizations like partitioning, bucketing, or using broadcast joins. Expect to justify trade-offs for memory, I/O, and scalability.
This is where eBay data engineer candidates often shine or stumble—clean, modular code that scales is a must.
-
Explain two production-safe patterns: (a) if
idvalues are dense, generateFLOOR(RANDOM()*max_id)and grab the first row ≥ that id with an indexed lookup, or (b) use a pre-materialized “reservoir” table that’s refreshed nightly with 1 M random keys so the online query is justORDER BY RANDOM() LIMIT 1. Stress whyORDER BY RANDOM()on the base table forces a full sort and will lock up a live replica. Mention hash-mod sharding for MySQL Aurora orTABLESAMPLE BERNOULLI(0.0001)in Redshift, noting their caveats. Tie the use case to eBay: product-photo moderation teams often need random listing slices for QA without slowing the main commerce cluster. Retrieve the last transaction of each day, returning its id, timestamp, and amount.
Demonstrate
ROW_NUMBER() OVER (PARTITION BY DATE(created_at) ORDER BY created_at DESC) = 1, then order the result ascending bycreated_at. Highlight indexing(created_at DESC)to turn the window sort into a range scan, critical when the finance ledger hits billions of rows. Discuss why date-truncing in the partition key is safer than string casting when the warehouse stores UTC. This pattern powers end-of-day cash-balance snapshots feeding eBay’s revenue reconciliation jobs.Report total distance traveled by each user, in descending order.
Join
userstorides, sumdistanceperuser_id,COALESCEmissing rides to zero, and sort. Call out that pre-aggregating ride data into a partitioned fact table speeds nightly ETL and prevents hot-key scans on heavy users. Mention adding anINDEX(user_id, distance)or clustering onuser_idfor columnar stores. The resulting mileage feeds loyalty-tier logic or carbon-offset calculators.Identify customers who placed > 3 orders in both 2019 and 2020.
Aggregate orders by
customer_idandYEAR(order_date), filterCOUNT(*) > 3, pivot years withHAVING SUM(year=2019)>0 AND SUM(year=2020)>0. Alternatively use anINTERSECTof two subqueries for readability. Emphasize why a composite(customer_id, order_date)sort key accelerates the grouping. This cohort query seeds retention dashboards and recommendation-model training.-
Apply
DENSE_RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC)and filterrank <= 3. Discuss memory trade-offs of window-function spill when departments are skewed and suggest pre-sorting withDISTKEY(dept_id)in Redshift. Note that for compliance reporting eBay masks PII: build the full name at query time rather than storing it denormed. -
Generate a numbers table (0-N) with
generate_series, left-join to aggregatedCOUNT(*)results, and default missing counts to zero. Explain why storing pre-calculated histograms in a metrics table speeds BI dashboards. Also touch on log reprocessing to ensure comment deletions are back-filled; otherwise the “0” bucket is inflated. Select the second-highest salary in Engineering, skipping ties at the top.
Use
DISTINCT salarythenORDER BY salary DESC OFFSET 1 LIMIT 1, orDENSE_RANK()whererank = 2. Point out why sub-queries onsalaryavoid accidentally picking two co-workers who share rank 1. Such queries often power compensation-band analytics during talent-market benchmarks.Determine if there is a path through a maze grid from start to target, returning a Boolean.
Describe BFS with a queue of
(x,y)positions and a visited set; the algorithm isO(rc)and detects reachability without requiring the shortest path. Emphasize memory efficiency for large grids by storing visited as a bitset. Data engineers building ETL state-machines sometimes face analogous graph-reachability checks on DAG dependencies.Find the minimum time steps to exit a building grid where each room has exactly one unlocked door.
Because out-degree = 1, the building forms a directed graph of edges; BFS still works, but you can prune by noting that revisiting a cell means a loop, so terminate early. Return −1 if the southeast corner is unreachable. Explain why a sparse adjacency list is more cache-friendly than a full 2-D matrix on very large buildings.
-
Show a Python or SQL window solution: assign linear weights
1…n, computeSUM(salary*weight)/SUM(weight), and round to two decimals. Note numerical-overflow guards when salaries are high andnlarge. This pattern generalizes to time-decayed CTR features in eBay’s recommendation pipelines. Find the top five paired products most frequently bought together.
Self-join
transactionsonuser_idwhereproduct_id₁ < product_id₂, group by the pair, count co-occurrences, and order byCOUNT(*) DESC LIMIT 5. Stress creating a compound index(user_id, product_id)to avoid the quadratic blow-up, and pre-filter to users with ≤ 100 items per checkout to keep the join tractable. The resulting association rules feed cross-sell banners.Given slope-intercept tuples, find which lines intersect within a specified x-range.
Iterate pairs, solve
m₁x + b₁ = m₂x + b₂, test whether x lies in range, and collect intersecting pairs. Highlight floating-point tolerance and avoid redundant pair checks via combination indexing. While algorithmic, similar geometry checks appear in eBay’s image-processing ETL (e.g., bounding-box overlaps).Select a random element from an unbounded number stream with equal probability using O(1) space.
Outline reservoir-sampling: keep
choiceand incrementcount; for each new element generaterand < 1/countto decide replacement. Prove uniformity via induction. Stress how this feeds unbiased validation slices for continuous-integration model retraining without storing full logs.
System / Pipeline Design Questions
Design questions assess how you think about architecture. You might be asked, “Design a near-real-time pipeline to enrich fraud signals.” Interviewers want to hear your reasoning around ingestion frameworks (Kafka vs. Flume), processing modes (Flink vs. Spark Streaming), and storage choices (Parquet, Delta, etc.). Highlight your ability to balance processing guarantees (exactly-once vs. at-least-once), manage schema evolution, and deliver on SLA constraints.
-
Model addresses as a slowly changing dimension: a surrogate
address_idtable stores the immutable street data, and a fact-likeaddress_historytable capturescustomer_id,address_id,move_in_date, andmove_out_date(NULL if current). Add a unique constraint on (address_id,move_in_date) to prevent overlaps and a forward pointer (next_tenant_customer_id) if you need fast “who moved in after” look-ups. Index{customer_id, move_in_date DESC}for latest-address queries, and partition the history table yearly once it grows. This design supports time-travel analytics, legal audits, and simple joins back to the customer dimension without duplicating street strings. Design a relational schema for a ride-sharing app that records trips between riders and drivers.
Core tables:
riders,drivers,vehicles, andtrips. Thetripsfact holds foreign keys to rider, driver, vehicle, pick-up / drop-off geohash, fare, status, and timestamps (requested, accepted, completed). A many-to-manydriver_availabilitytable stores driver status windows to support dispatch queries. Use composite indexes on(pickup_geo, requested_ts)for surge heat-maps and(driver_id, status)for driver-utilization dashboards. Soft-delete flags plus append-only write patterns keep historical data intact for ML ETA training.-
Separate metadata and binary content: store video files in object storage (S3/GCS) with deterministic keys, and keep a lightweight
videos_metatable in a columnar or row store (title, uploader_id, upload_ts, duration, content_type). Create covering indexes on(uploader_id, upload_ts DESC)and full-text search ontitleto keep UI queries fast. Leverage tiered storage: cold videos live on infrequent-access buckets while hot-cache thumbnails sit in CDN. Blob URLs include an MD5 checksum to guarantee integrity; the database stores only the checksum and the signed URL, reducing row size. Sketch a star-schema data warehouse for a new online retailer.
Fact table:
sales_factwith keys todate_dim,customer_dim,product_dim,store_dim, and measures like revenue, quantity, discount. Dimensions carry slowly changing attributes—e.g.,product_dimtracks price_effective_from / to, category hierarchy. Index fact on composite(date_key, product_key)for top-seller reports; partition bydate_keyfor fast roll-ups. Offload clickstream into a separatesession_factthat can later join viacustomer_key. This star model simplifies Tableau cubes while supporting granular funnel analysis for eBay-style merchandising.-
Build a two-phase pipeline: first, offline blocking rules cluster candidates using text normalization (lowercase, stemming, model number regex), brand match, and category. Second, apply a pairwise similarity model (TF-IDF cosine or Siamese BERT) and threshold to flag duplicates. Store clusters in a
product_canonical_maptable withcanonical_idandconfidence. Expose an admin tool for manual review of borderline cases. Downstream queries join throughcanonical_id, ensuring inventory counts and search facets collapse duplicates without deleting seller listings. Design a schema to capture client click data for web-app analytics.
Emit each click as an event into Kafka, land in Parquet partitions by UTC date-hour, and stream into a
click_eventstable: (event_id,user_id,session_id,element_id,page_url,ts,device,referrer). Keep a surrogatesession_dimtable to roll clicks into page-view metrics quickly. Use big-int surrogate keys forelement_idto avoid long CSS selectors in the fact. Add a low-cardinalitycountry_codecolumn encoded with ZSTD to speed geo aggregation; Bloom filters onuser_idaccelerate user replay.-
Foreign keys enforce referential integrity, catch orphan inserts early, and allow cost-based optimizers to infer join cardinality. They can also cascade deletes but should be used cautiously: employ
ON DELETE CASCADEfor true child-records (order_items) where a parent delete must remove children; preferON DELETE SET NULLwhen history should remain (e.g.,user_idon reviews after account deletion). Disable FK checks on bulk loads but re-enable afterward for ongoing safety. Design a blogging-platform schema with users, posts, comments, and tags.
Tables:
users(PKuser_id),posts(post_id,author_id FK,title,body,published_ts),tags(tag_id,name UNIQUE),post_tags(post_id,tag_idcomposite PK), andcomments(comment_id,post_id,author_id,parent_comment_id NULL,body,created_ts). Apply a self-referencing FK oncomments.parent_comment_idfor threading, and a partial indexWHERE published=trueonpostsfor feed queries. Text-search GIN index onbodyaccelerates search. Soft-deleteis_deletedallows GDPR wipe without breaking FK chains.Design a relational schema optimized for a Tinder-style swiping app.
Core tables:
profiles,swipes(swiper_id,swiped_id,direction [LIKE/SKIP],ts), andmatches(user1_id,user2_id,matched_ts). Create a composite unique constraint on matches to avoid duplicates (LEAST(),GREATEST()trick). Hot-path reads— “who should I see next?”—query a Redis cache keyed byswiper_idthat stores candidate queues prefiltered by geo and preferences, refreshed via Spark pipelines every few minutes. Indexswipeson(swiper_id, ts DESC)for fast history scans and on(swiped_id, direction)to compute likes-received counts.-
userstable stores profile info;restaurantsholds location, cuisine, owner_id, andavg_ratingcached for quick sort.reviews(review_id,user_id FK,restaurant_id FK,rating 1–5,body,created_ts,updated_ts) with a unique (user_id,restaurant_id) constraint ensures one review per user.review_photoslinks multiple images to a review viaphoto_url, andrestaurant_tagssupports facet search. AddCHECK rating BETWEEN 1 AND 5andON UPDATE CASCADEso edited reviews recompute aggregates through triggers. Partitionreviewsby restaurant_id hash for write scalability, while secondary indexes on(restaurant_id, created_ts DESC)power paginated review feeds.
Behavioural / Culture-Fit Questions
eBay places high value on collaboration and ownership. Behavioral questions often center on how you resolved an incident, ensured data quality, or partnered with downstream ML or analytics teams. Expect prompts like “Tell me about a time you caught a silent data bug in production” or “Describe a situation where misaligned schemas caused downstream failures.” Use STAR format and emphasize impact—especially where your work unblocked others.
Describe a data project you worked on. What were some of the challenges you faced?
Pick a pipeline that moved from batch to streaming—for example, migrating seller-event logs to Kafka + Flink. Call out a technical hurdle (late-arriving events caused watermark skew) and an organizational hurdle (marketing needed hour-level metrics while finance needed day-level ledger locks). Explain how you solved both with schema-versioning and tiered aggregate tables, then share the impact (20 % fresher dashboards, 40 % less re-processing cost).
What are effective ways to make data more accessible to non-technical people?
Discuss semantic layers in Looker, data-quality badges, and self-serve notebooks that read from governed Iceberg tables. Mention autogenerated data dictionaries and Slack bots that field SQL snippets. Highlight how these tools lowered ad-hoc ticket volume by half and empowered category managers to pull GMV by seller tier without engineering help.
What would your current manager say about you—strengths and areas to improve?
Choose strengths that map to eBay’s scale—e.g., “obsession with idempotent backfills” and “proactive cost-tracking on Redshift clusters.” Offer one growth area such as “delegating terraform changes,” then describe concrete steps you’re taking (pair-review checklists, runbooks). Back claims with metrics (zero failed backfills in two quarters).
Talk about a time you had trouble communicating with stakeholders. How did you overcome it?
Use a STAR story where product wanted near-real-time analytics but SRE warned of CPU spikes. Explain how you visualized cluster utilization, proposed micro-batching, and wrote an RFC everyone signed off on. Result: latency cut from 24 h to 30 m with no pager alerts.
Why do you want to work with us?
Tie your passion for marketplace data and petabyte-scale warehousing to eBay’s mission. Reference eBay’s adoption of open-table formats (Iceberg) and how your experience optimizing S3 + Athena costs can accelerate the Ads and Payments data domains.
How do you prioritize multiple deadlines and stay organized?
Describe an impact-versus-effort matrix tied to quarterly OKRs, Jira swim-lanes color-coded by SLA risk, and daily stand-ups that surface blockers. Mention automated Airflow DAG health checks and Terraform plans that gate prod merges. Give an example where this system surfaced a P1 schema drift while still hitting a GDPR export deadline.
Tell me about a time you caught a data-quality issue before it hit production dashboards. What safeguards did you have in place?
Interviewers want defenses in depth: perhaps Great Expectations tests on row counts, plus Canary queries that diff new partitions against yesterday’s. Explain how the alert let you roll back a faulty CDC stream and prevented incorrect GMV from reaching the CFO’s report.
Describe how you mentored a junior engineer or analyst—what was the challenge and the outcome?
Maybe you guided an intern through building a partition-evolution script; detail code reviews, architecture white-boarding, and how the mentee’s PR went live reducing scan costs 15 %. Emphasize multiplying team capacity and fostering a culture of learning—highly valued in eBay’s collaborative data org.
How to Prepare for a Data Engineer Role at eBay
Preparing for the eBay data-engineering interview means sharpening both your technical depth and architectural judgment. It’s not just about writing performant code—it’s about building resilient systems at scale and articulating your decisions clearly.
Master eBay’s Scale Numbers
Before jumping into prep, ground yourself in eBay’s scale. Think in gigabytes-to-terabytes per day, partitioning schemes, event latency budgets, and SLA targets for downstream consumers. Many design prompts will assume this level of context—especially in real-time analytics or fraud detection domains.
Practise the Question Mix
Most candidates encounter roughly 50% coding (PySpark, SQL, data-structure questions), 30% design (streaming vs. batch, data models), and 20% behavioral (ownership, communication, incident response). Focus your time accordingly, and treat each practice session like a simulation of the real process.
Mock the Technical Screen
The technical screen is a performance gate—prepare with 45-minute timed IDE sessions using LeetCode (medium-to-hard) and Spark playgrounds like Databricks or AWS Glue Studio. Practise deduping, joins, window functions, and writing memory-aware transformations with comments. Clean code = a strong first impression.
Think Out Loud
Interviewers care as much about how you think as what you build. Always articulate your partitioning logic, fault tolerance plan, and monitoring considerations. Highlight trade-offs like shuffle cost vs. reusability, or throughput vs. consistency. These nuances elevate you above brute-force problem solvers.
Collect Feedback Early
When practicing system design questions, show your diagrams to a peer, mentor, or coach. Clarity, pacing, and diagram structure matter—especially when describing data lineage, backfills, or Kafka-Flink-Snowflake flows under a time constraint.
FAQs
What Is the Average Salary for an eBay Data Engineer?
Average Base Salary
Average Total Compensation
The eBay data engineer compensation package typically includes base salary, performance bonus, and equity through RSUs. While eBay doesn’t publicly break down salaries, benchmark data suggests that total comp ranges vary significantly by level—expect higher packages for Senior and Staff-level roles with cross-team platform scope.
How Much Spark vs. SQL Appears in the Interview?
Expect a healthy mix. While foundational SQL skills (joins, CTEs, aggregates) are tested in all loops, Spark questions dominate the coding and design rounds. Candidates should prepare to write PySpark transformations, explain execution plans, and optimize partitioning and memory use. Familiarity with UDF pitfalls and broadcast joins can also come up.
Conclusion
The key to success in the eBay data engineer interview is pairing distributed systems design expertise with sharp, confident communication. Whether you’re optimizing Spark jobs or whiteboarding a Flink-to-Snowflake ingestion pipeline, your ability to explain trade-offs and drive resilient decisions is what sets you apart. For next steps, visit our broader eBay Interview Questions & Process hub, or explore role-specific guides for Machine Learning Engineers and Data Analysts.
Want to simulate the pressure? Book a mock interview, try our AI Interviewer, or challenge yourself with the Data Engineer Learning Path. And don’t miss Simran Singh’s success story—after 4,200 job applications, she landed her dream role with the help of Interview Query. Let this be your breakthrough moment.
Ebay Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Data Structures & Algorithms | Easy | |
Given two sorted lists, write a function to merge them into one sorted list. Bonus: What’s the time complexity? Example: Input: Output: | ||
A/B Testing | Medium | |
SQL | Hard | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences