

Amazon Machine Learning Engineer Interview: Complete Preparation Guide (2026)


Introduction
Preparing for the Amazon machine learning engineer interview means getting ready for one of the most challenging and rewarding hiring processes in tech. Amazon builds machine-learning systems that power everything from Alexa’s speech recognition to Prime’s product recommendations and robotics automation across its fulfillment network. According to the company’s recent workforce update and public hiring goals, Amazon continues expanding ML roles as part of a broader scaling strategy. With thousands of new ML-engineer positions now live globally, the opportunity is significant, and the bar for technical depth and problem-solving remains high.
In this guide, you’ll learn exactly how the interview works, the core machine learning and coding concepts to master, what Amazon looks for in system design and leadership questions, and how to prepare with confidence. Whether you’re targeting teams in AWS AI, Ads, or Alexa, this guide will give you a clear, practical roadmap to stand out and perform at your best.
What Does a Machine Learning Engineer Do at Amazon
As an Amazon machine learning engineer, you’re building systems that power products millions of people use every day. Your work sits at the intersection of modeling, engineering, and large-scale deployment. On any team, whether Alexa, AWS AI, Ads, Robotics, or Prime, your job is to turn data and experimentation into reliable, customer-facing ML solutions.
Core responsibilities include:
- Design, train, and optimize ML models for tasks like ranking, forecasting, NLP, speech, or vision.
- Build and maintain scalable data pipelines that support model training, evaluation, and experimentation.
- Deploy models in production using services like AWS SageMaker, internal platforms, or real-time inference systems.
- Evaluate model performance with robust metrics, error analysis, and continuous monitoring.
- Collaborate with scientists, data engineers, and product teams to translate ambiguous business problems into measurable outcomes.
- Improve system reliability and latency, especially for customer-facing real-time workloads.
- Drive experimentation and A/B testing, validating model impact before large-scale rollout.
- Document decisions and communicate trade-offs clearly to cross-functional partners.
Tip: As you prepare, match your own project experiences to these responsibilities. Interviewers want to see that you can own the full lifecycle of an ML system, not just training a model.
Why This Role at Amazon
The machine learning engineer role at Amazon gives you the chance to solve problems at a scale few companies in the world operate at. Instead of building isolated models, you work on systems that must be reliable, efficient, and adaptable across massive data streams and global products. Amazon’s ML engineers own their work end-to-end, from problem definition to deployment and collaborate deeply with applied scientists, product teams, and engineering leaders.
The breadth of domains you can impact, from e-commerce and logistics to cloud infrastructure and security, means your career can evolve in multiple directions without ever leaving the company. Combine that with Amazon’s culture of ownership, experimentation, and long-term thinking, and you get one of the strongest environments for an ML engineer to grow, innovate, and lead.
Amazon Machine Learning Engineer Interview Process
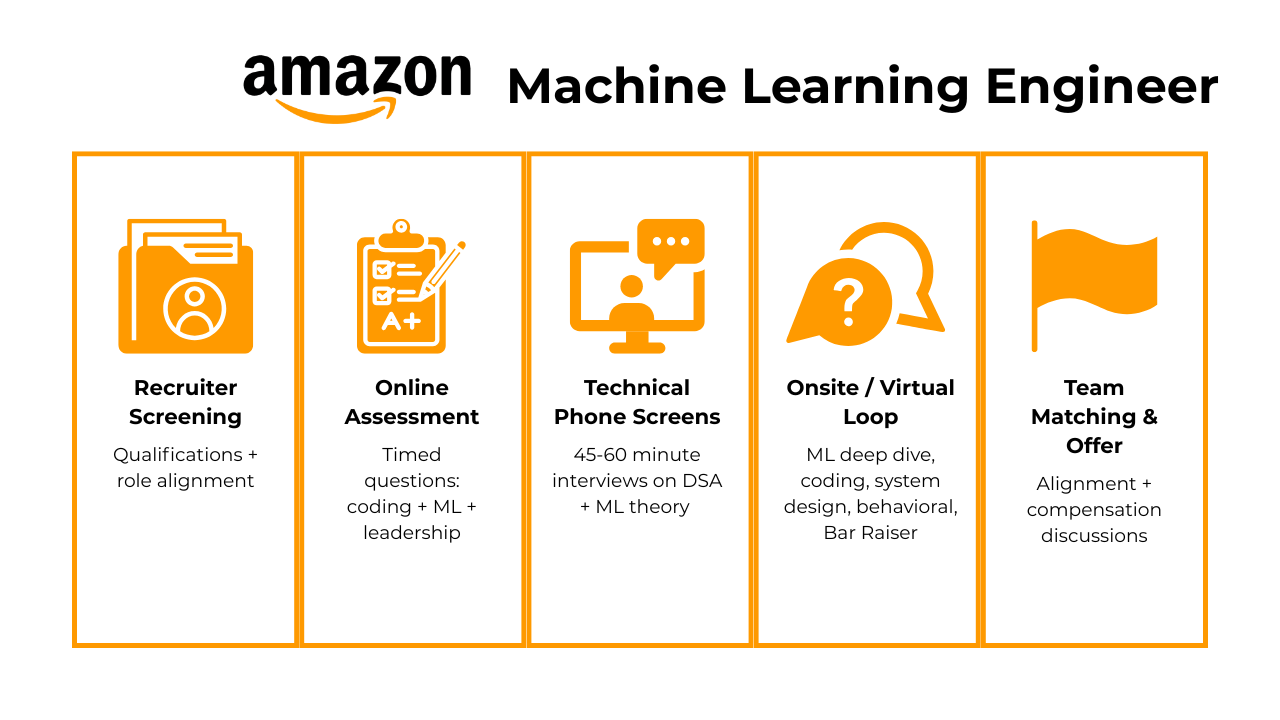
The interview process for machine learning engineers at Amazon is rigorous, multi-faceted, and designed to assess both technical depth and alignment with Amazon’s Leadership Principles. You’ll move through several stages that evaluate coding, machine learning fundamentals, system design, and behavioral problem-solving. While each team varies slightly, most candidates experience the following sequence.
Read more: Google Machine Learning Engineer Interview Guide
Recruiter Screening
This initial conversation is an opportunity for the recruiter to evaluate your basic qualifications and overall alignment with the role. Topics include:
- Your background in machine learning, software development, and system design
- Proficiency in programming languages (typically Python)
- Exposure to AWS or scalable ML solutions
- Preferred teams, project interests, and work authorization
While this is not a technical interview, it sets the tone for the rest of the process.
Tip: Use this opportunity to express enthusiasm for specific ML domains at Amazon (e.g., Alexa, AWS, Ads) and briefly mention impactful projects to generate early interest.
Online Assessment (OA)
The OA is usually administered via a timed online platform and may include:
- Coding problems focused on algorithms, strings, trees, dynamic programming, or arrays
- ML-related multiple-choice questions on topics like model evaluation, overfitting, or types of learning
- Leadership scenario simulations that evaluate decision-making aligned with Amazon’s principles
This round is especially common for early-career and university candidates.
Tip: Practice LeetCode Medium-level problems under time constraints and review Amazon’s Leadership Principles to prepare for situational judgment scenarios.
Technical Phone Screen
This 45–60 minute virtual interview focuses on evaluating hands-on technical skills. Expect:
- 1–2 coding problems involving core data structures and algorithms
- Follow-up questions on time and space complexity
- Light discussion of ML theory or past projects, depending on the interviewer
You will be expected to code live using a shared editor and explain your thought process clearly.
Tip: Speak out loud while solving, Amazon values candidates who communicate their reasoning and adapt based on feedback or hints.
On-Site or Virtual On-Site Interviews
This is the most comprehensive phase and typically includes four to five technical and behavioral rounds, each lasting about 60 minutes. These interviews may take place virtually or on-site depending on the role and location.
Structure:
- ML Technical Deep Dive: An in-depth discussion of ML systems you’ve built, including model selection, feature engineering, metrics, and trade-offs.
- Algorithms & Coding: Complex data structure problems with multiple parts. Expect follow-ups that test edge cases, optimization, and clean implementation.
- ML System Design: Design a scalable ML pipeline or system, from data ingestion to model deployment and monitoring. Interviewers assess how well you handle ambiguity, scalability, and latency constraints.
- Behavioral / Leadership Principles Interview: Assessing ownership, problem-solving, collaboration, and customer obsession through real-world experiences.
- Bar Raiser Round: Conducted by a trained senior interviewer. This round focuses on cross-functional excellence, leadership alignment, and long-term impact.
Each round is independently scored, and interviewers take detailed notes for post-interview debriefs. Interviewers will challenge your assumptions and expect structured, reasoned responses supported by relevant experience.
Tip: Use the STAR format (Situation, Task, Action, Result) consistently in behavioral rounds, and structure system design answers with components, trade-offs, and constraints clearly outlined before diving into solutions.
Team Matching (Varies by Role)
For certain roles, particularly within Alexa, AWS AI, or Prime, candidates may enter a team matching phase after passing the technical interviews. Hiring managers from different teams evaluate your interview feedback and portfolio to determine team alignment.
Tip: If given a choice, express interest in teams where your previous work aligns closely with their mission. This improves both offer strength and long-term role satisfaction.
Offer and Negotiation
Candidates who receive a final recommendation undergo compensation discussions. Amazon’s ML offers typically include:
- Competitive base salary
- Signing bonuses (year 1 and 2)
- RSUs (Restricted Stock Units) with a standard 4-year vesting schedule
- Relocation assistance and benefits package
Tip: Amazon expects negotiation. Do your research on compensation benchmarks (e.g., Levels.fyi) and be prepared to explain the value you bring, especially if you have competing offers or unique domain expertise.
Want to master Amazon ML interview questions? Start with our Machine Learning Question Bank to drill through real coding, algorithm, and framework-based questions.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Amazon?
Technical Interview: Core Machine Learning Topics to Master
Amazon’s ML technical interviews focus on how well you understand the fundamentals and how comfortably you can apply them to real, production-level problems. Instead of memorizing formulas, you’ll need to reason through trade-offs, diagnose model issues, and explain why your solution works under real constraints like scale, latency, and noisy data.
Key ML Topics You Should Be Ready For
- Supervised vs. unsupervised learning: Be able to walk through common algorithms, when to use them, and how you evaluate success. Interviewers often ask you to compare models or justify your choices for a specific scenario.
- Model evaluation and metrics: Expect questions on precision/recall trade-offs, ROC curves, AUC, calibration, cross-validation, and how you’d evaluate models in imbalanced or high-noise settings.
- Feature engineering: Explain how you would clean, transform, and encode real-world data. Amazon cares about your ability to identify high-signal features and reduce complexity without losing performance.
- Regularization and preventing overfitting: Be ready to discuss L1/L2, dropout, early stopping, and how to identify overfitting in the first place. Interviewers often ask how you’d debug a performance gap between training and validation sets.
- Hyperparameter tuning: You should know grid search, random search, Bayesian optimization, and practical tuning strategies for tree-based models and neural networks.
- Bias–variance trade-off: Amazon loves questions that test whether you understand why a model is underperforming, not just how to fix it.
- ML interpretability: SHAP, feature importance, partial dependence, and the trade-offs between accuracy and transparency often come up, especially for Ads and Fraud teams.
- Data quality and ML debugging: You may be asked to walk through diagnosing label leakage, data drift, or unexpected spikes in error metrics after deployment.
Tip: Practice explaining ML concepts using concrete examples from your own past projects. Amazon values clarity, not jargon.
Coding & Algorithm Questions in Amazon ML Engineer Interviews
Amazon treats coding as a core skill for machine learning engineers. Even if you’re strong in modeling, you still need to write clean, production-ready Python and reason through data structures and algorithms under time pressure. The coding rounds evaluate whether you can solve problems efficiently, communicate your thinking, and avoid pitfalls that lead to brittle or slow ML systems.
Read more: Top 9 Machine Learning Algorithm Interview Questions
What These Rounds Usually Cover
| Topic | What These Rounds Focus On |
|---|---|
| Python fluency | Implementing functions, manipulating core data structures, and writing clear, correct logic without heavy libraries. |
| Data structures and algorithms | Working with lists, dictionaries, sets, heaps, queues, trees, and graphs while explaining time and space complexity and common patterns. |
| Real-world ML coding scenarios | Tasks like implementing evaluation metrics, preprocessing steps, or optimizing slow code to reflect real ML engineering workflows. |
| Edge case reasoning | Handling corner cases, validating inputs, and considering large-scale performance implications. |
| Testing your own code | Demonstrating the habit of running simple tests or examples before finalizing a solution. |
Tip: Practice writing code in a plain text editor without autocomplete. This simulates Amazon’s interview environment and forces you to rely on fundamentals, not tooling.
Most Asked Interview Question and Answers:
When would you choose bagging over boosting in machine learning, and what are the trade-offs?
This question evaluates your understanding of ensemble learning and when different strategies shine. Bagging reduces variance by training many independent models on bootstrapped samples, making it ideal for high-variance algorithms like decision trees and noisy datasets. Boosting, by contrast, reduces bias through sequential training but can overfit when noise is high. In an Amazon interview, you should explain the goal, stabilizing predictions vs. improving accuracy, and highlight practical trade-offs like training time, sensitivity to noise, and interpretability.
Tip: Tie your answer to a real example—e.g., “I used bagging when I needed stable predictions for a noisy demand dataset.”
How would you design a recommendation algorithm for Netflix’s type-ahead search?
This question tests your ability to combine ML intuition with system constraints like latency, personalization, and ranking. A strong answer mentions blending autocomplete signals, search embeddings, historical interactions, and lightweight models to rank suggestions in real time. You’d describe precomputing embeddings, using approximate nearest neighbors for fast lookup, and applying contextual signals such as trending content or user preferences. Amazon asks variants of this to see if you can design fast, scalable ML systems that balance relevance with inference speed.
Tip: Always emphasize latency, type-ahead systems often require <50ms responses.
Head to the Interview Query dashboard to practice Amazon-style ML, coding, and system design questions. With built-in Python execution, performance analytics, and AI-guided feedback, it’s one of the fastest ways to sharpen your skills for Amazon’s MLE interviews.
How would you merge two sorted lists into one sorted list, and what’s the time complexity?
Interviewers use this question to confirm your foundational coding and algorithmic strength. The correct approach is to use two pointers, one for each list, and append the smaller element while advancing the corresponding pointer until all elements are consumed. This yields a clean, linear-time solution with O(n + m) time complexity and O(n + m) space. Amazon asks this because MLEs often optimize data pipelines, streams, or pre-sorted batches where such patterns are common.
Tip: Mention edge cases like empty lists or unequal lengths, Amazon values thoroughness.
-
This question tests your ability to explain core ML concepts clearly. Logistic converts a real-valued input into a probability for binary classification, while softmax generalizes this idea to multi-class problems by producing a normalized probability distribution across all classes. In an interview, highlight when each is used, how gradients behave, and why softmax ensures probabilities sum to one. Amazon asks this to ensure you understand the mathematical building blocks behind classification models, not just how to call them in libraries.
Tip: Keep explanations intuitive, avoid heavy math, and use practical examples like fraud (binary) vs. product category prediction (multi-class).
-
This question checks your grasp of classic graph algorithms and how you apply them under realistic constraints. A strong answer references using BFS for unweighted grids or Dijkstra’s algorithm for weighted ones, maintaining a priority queue of nodes and updating distances until reaching the target. You’d also mention handling obstacles, visited sets, and ensuring the design scales to large grids. Amazon uses questions like this to test problem-solving approach, code clarity, and your ability to reason about runtime and memory.
Tip: Always state the complexity—e.g., Dijkstra’s is O(E log V) and relate it back to scalability.
System Design Interview Questions For Amazon ML Engineers
Amazon’s ML system design interviews evaluate how well you can build scalable, reliable, and cost-efficient ML solutions end-to-end. Instead of diving into model math, these rounds focus on data flow, architecture trade-offs, latency constraints, and how your design would behave under real Amazon-scale traffic. You’ll need to break problems down clearly, justify decisions, and show that you understand the lifecycle of an ML system beyond just training a model.
Read more: Top 50 Machine Learning System Design Interview Questions
AWS Services to Know
Since Amazon ML Engineers often work on AWS-native systems, familiarity with the following is strongly recommended:
- Amazon SageMaker (model development, training, deployment)
- Amazon Kinesis/Firehose (streaming data)
- AWS Lambda (serverless model inference or feature pipelines)
- Amazon S3 (data lake)
- CloudWatch (logging, monitoring)
- Step Functions (orchestration)
Tip: In system design interviews, demonstrating practical AWS architecture knowledge can differentiate you from other candidates, especially when you can map ML workflows directly onto real services.
What Amazon Expects You To Demonstrate
| Expectation | What Amazon Wants to See |
|---|---|
| Clear problem framing | Candidates who clarify metrics, constraints, prediction frequency, and failure modes before proposing solutions. |
| End-to-end architecture thinking | Ability to outline ingestion, storage, feature computation, training, deployment, and monitoring in a cohesive ML system. |
| Designing scalable ML pipelines | Understanding of batch vs streaming, feature stores, orchestration, and strategies to reduce pipeline fragility at scale. |
| Real-time inference | Approaches for low-latency serving, caching, load balancing, model versioning, and handling customer-facing workloads. |
| Retraining and continuous improvement | Handling data drift, automating retraining, and using shadow or canary deployments to validate updates safely. |
| A/B testing and experimentation | Ability to measure model impact, design large-scale experiments, and avoid issues like contamination or low power. |
| Operational reliability | Strong monitoring, alerting, fallback logic, and clear thinking about system behavior during partial failures. |
Tip: Practice describing your designs using simple, modular components. Amazon isn’t testing diagram artistry, they’re testing whether you can communicate architecture clearly and think through the real constraints of a production ML system.
Most Asked Interview Question and Answers:
-
This question evaluates your ability to compare models based on data characteristics, bias–variance trade-offs, and business metrics rather than intuition alone. You’d describe framing the problem first, then training both models using consistent preprocessing, cross-validation, and error metrics like RMSE or MAPE. You’d analyze residuals, feature importance, and robustness to nonlinearity or outliers to determine which model generalizes better. Amazon asks questions like this to see whether you approach model selection systematically and justify your decisions with evidence, not assumptions.
Tip: Always connect evaluation to business impact, predicting prices inaccurately affects revenue, availability, and user trust.
-
This question tests your ability to design scalable, reliable data pipelines under realistic constraints. The goal is to outline a flow where raw payment events land in a storage layer (S3), are validated and transformed with Spark or Lambda jobs, enriched with metadata, and then loaded into Redshift or Snowflake for analytics. You’d emphasize idempotency, schema evolution, partitioning, and monitoring for late or duplicated events. Amazon asks this because ML engineers frequently build systems that depend on clean, timely data, and they want to see if you understand operational reliability end-to-end.
Tip: Call out failure handling, like retry policies, dead-letter queues, and data quality checks show strong engineering maturity.
-
Here, interviewers assess your ability to build normalized, query-efficient schemas under real-world constraints. You’d explain core entities like songs, artists, albums, genres, and user interactions, defining primary keys, foreign keys, indexes, and relationships to avoid redundancy while supporting fast lookups. Considerations include handling many-to-many mappings (e.g., artists ↔ songs), ensuring scalability via sharding or read replicas, and supporting metadata updates without breaking referential integrity. Amazon asks this to evaluate how well you apply data modeling principles that underpin reliable ML pipelines and search systems.
Tip: Mention access patterns, and designing tables around common queries shows thoughtful, customer-obsessed engineering.
How would you build an end-to-end text-to-image retrieval system for product search at Amazon?
This question checks whether you can blend ML modeling with scalable architecture. You’d outline using text and image encoders (e.g., CLIP or dual-encoder transformers) to map both modalities into a shared embedding space, storing vectors in a similarity search index like Faiss or OpenSearch, and enabling fast retrieval through ANN algorithms. Your solution should cover data ingestion, feature extraction, offline training, online indexing, and monitoring for drift and retrieval quality. Amazon asks this because multimodal search is central to e-commerce, requiring engineers who understand both modeling and infrastructure.
Tip: Emphasize latency since customers expect instant search results, so discuss caching, batching, or hardware acceleration.

Head to the Interview Query dashboard to practice Amazon-style ML, coding, and system design questions. With built-in Python execution, performance analytics, and AI-guided feedback, it’s one of the fastest ways to sharpen your skills for Amazon’s MLE interviews.
-
This question evaluates your understanding of entity resolution at scale, a recurring challenge in Amazon’s massive catalog. You’d describe combining rule-based heuristics (e.g., string similarity, brand match, UPC/ASIN signals) with ML models that learn product embeddings from text, images, and attributes to classify duplicates. The workflow includes blocking to reduce pairwise comparisons, scoring candidate pairs, merging or flagging confirmed duplicates, and maintaining audit logs for reversibility. Amazon asks this because catalog quality directly affects search relevance, customer experience, and downstream ML systems.
Tip: Highlight evaluation metrics, since precision, recall, and human-review loops are essential for high-stakes catalog decisions.
Watch next: Machine Learning System Design Interview: YouTube Recommendations
In this ML system design walkthrough, Sachin, a senior data scientist, tackles a common Amazon-style question: how would you architect YouTube’s homepage recommendation system? You’ll learn how to approach real-time vs. offline recommendation pipelines, handle user context, optimize for different devices, and incorporate metrics like NDCG and MRR, ideal for Machine Learning Engineers preparing for design rounds at Amazon.
Amazon Behavioral Questions (Leadership Principles in Action)
Amazon treats behavioral interviews as seriously as the technical rounds. Every question, no matter how simple it sounds is designed to test how well you embody the company’s 16 Leadership Principles. For ML engineers, this means showing that you can take ownership of ambiguous problems, collaborate across teams, dive deep into messy data, and deliver high-impact results. You’ll use the STAR method to walk interviewers through your reasoning, actions, and measurable outcomes.
What to Expect In Behavioral Rounds
| What to Expect | Description |
|---|---|
| Leadership Principles woven into every question | Behavioral prompts map directly to Amazon principles like Ownership, Dive Deep, Invent and Simplify, and Deliver Results. |
| Specific, high-detail stories | Interviewers look for examples with metrics, constraints, and real stakes rather than vague summaries. |
| Ambiguity-heavy scenarios | You may be asked about unclear requirements, shifting priorities, or making tough trade-offs with limited information. |
| Collaboration and disagreement handling | Expect questions on working with scientists, PMs, and engineers and how you communicate decisions or resolve conflict. |
| Bias for action and ownership | Amazon values initiative, like stories about improving pipelines, redesigning metrics, or uncovering hidden issues resonate strongly. |
Common themes for ML engineers
- Pushing a model from prototype to production
- Debugging unexpected performance drops
- Leading experiments with conflicting stakeholder priorities
- Simplifying overly complex pipelines or processes
- Challenging assumptions using data
- Learning a new tool or framework quickly to unblock progress
Tip: Prepare 6–8 STAR stories in advance. Reframe each story to highlight a different Leadership Principle so you can adapt on the fly, no matter how the interviewer phrases the question.
Example Question and Answers
Explain why you want to work at Amazon and why you would be a good fit for the company.
Hiring managers want to see whether your motivations align with Amazon’s mission and whether you can thrive in a high-ownership, fast-moving ML environment. As an ML engineer, you’ll be expected to build scalable systems, collaborate across science and engineering teams, and dive deep into ambiguous data problems, so your answer should reflect both passion and capability.
Example answer: “I’m excited about Amazon’s scale and culture of customer obsession. I’ve always enjoyed building ML systems that directly impact millions of users, and Amazon’s focus on scalable, real-world machine learning matches my strengths. In my previous role, I built a real-time ranking model that improved recommendation relevance by 12%, and I’m eager to bring the same ownership and experimentation mindset to Amazon’s ML teams.”
Tip: Mention one or two teams you’re genuinely interested in (Alexa, Ads, AWS AI) to show thoughtful motivation.
-
Amazon values ML engineers who can translate complex model behavior and experimental results into actionable decisions for PMs, operations, or leadership. They want to know whether you can simplify technical details without losing accuracy, earning trust across teams.
Example answer: “I start by explaining the business impact before diving into model details. For example, when presenting model drift findings to a product manager, I framed it as ‘users are getting less relevant results,’ then showed a simple trend chart and recommended actions. By focusing on clarity and next steps, the team understood the issue and prioritized retraining immediately.”
Tip: Use visuals or simple metrics (e.g., precision drop from 0.82 → 0.68) to make model behavior intuitive for non-technical audiences.
Discuss your strengths and weaknesses and how they relate to your performance at Amazon.
Amazon screens for self-awareness and whether you demonstrate Ownership, Bias for Action, and the ability to improve continuously. Your response should show that you understand your impact and know how to adapt in a fast-paced ML environment.
Example answer: “One strength is my ability to break down ambiguous ML problems into clear steps, I recently led an initiative to redesign a flaky feature pipeline that reduced data latency by 40%. A weakness I’m improving is over-focusing on model optimization early; I’ve learned to validate data quality and baselines first, which has improved project velocity and reliability.”
Tip: Pick weaknesses tied to real ML workflows (e.g., debugging, prioritization, over-tuning) rather than generic traits.
Head to the Interview Query dashboard to practice Amazon-style ML, coding, and system design questions. With built-in Python execution, performance analytics, and AI-guided feedback, it’s one of the fastest ways to sharpen your skills for Amazon’s MLE interviews.
Tell me about a time you debugged a complex ML system issue under time pressure.
This question targets Dive Deep, Ownership, and Deliver Results. Amazon wants to see whether you stay structured when production models misbehave—especially during spikes, outages, or unexpected performance drops.
Example answer: “Our anomaly detection system suddenly started flagging thousands of false positives. I traced the issue to a silent schema change in upstream data. I quickly wrote a temporary transformation patch, restored normal operations within two hours, and coordinated with data engineering to prevent similar issues. Later, I added automated schema drift alerts to our monitoring pipeline.”
Tip: Emphasize clear steps—diagnose → isolate → fix → prevent. Amazon loves candidates who implement long-term safeguards.
Domain-specific and Applied ML Questions
Amazon loves to see how you think about real-world machine learning problems. Beyond theory, these questions test whether you can turn messy data, unclear requirements, and large-scale constraints into practical solutions. You’ll walk through modeling choices, metrics, failure modes, and trade-offs for domains that Amazon works in every day, like recommendations, NLP, computer vision, anomaly detection, forecasting, and optimization.
Read more: 80+ Python ML Interview Questions
What these Questions Typically Explore
| Topic | What These Questions Explore |
|---|---|
| Recommendation systems | Collaborative filtering, ranking models, embeddings, relevance metrics, cold-start handling, and scaling to millions of products. |
| NLP and language understanding | Tokenization, transformers, intent classification, embedding models, error analysis, and comparing classical NLP to LLMs under latency or memory constraints. |
| Computer vision workflows | CNNs, object detection, augmentation strategies, and managing class imbalance in vision datasets. |
| Anomaly and fraud detection | Unsupervised methods, threshold tuning, precision–recall trade-offs, rare-event modeling, and reasoning about interpretability or false-positive costs. |
| Forecasting and demand modeling | Seasonality, trend decomposition, multivariate time-series approaches, and evaluation with rolling windows. |
| Optimization and decision-making | Designing constraints, reward functions, and approximate solutions when exact optimization is computationally expensive. |
What Interviewers are Actually Looking For
- Your ability to compare models and justify trade-offs
- How you choose evaluation metrics based on business goals
- How you’d debug poor performance or unexpected behavior
- Your understanding of scale, latency, and noisy real-world data
- Whether you can communicate decisions clearly to non-ML partners
Tip: Use examples from your own work when explaining domain problems. Real stories show depth and make your reasoning more convincing than abstract explanations.
If you want to master applied ML interview questions, here is a resource: start with Interview Query Machine Learning Question Bank to drill through real coding, algorithm, and framework-based questions.
Example Question and Answers
-
This question evaluates your ability to design ML systems in high-risk environments where false positives disrupt customers and false negatives enable fraud. A strong answer explains using techniques like stratified sampling, SMOTE, cost-sensitive learning, or anomaly detection to address imbalance, while comparing models that balance bias–variance—such as logistic regression for interpretability versus gradient boosting for nonlinear patterns. You’d emphasize metrics like precision, recall, ROC, and financial cost. Amazon cares about whether you can think through real-world risks and design controlled, explainable systems.
Tip: Always discuss the business cost of errors, since fraud modeling is about impact, not just accuracy.
How would you design a chatbot that returns the closest FAQ answer using machine learning methods?
This question tests your ability to combine NLP modeling with scalable retrieval. You’d frame the problem as embedding text using transformers or sentence encoders, storing those embeddings in a vector search index, and returning the closest FAQ based on cosine similarity. You’d also discuss fallback strategies like keyword matching, thresholding to avoid irrelevant responses, and monitoring drift when FAQs change. Amazon asks this to assess your comfort with embedding-based retrieval and productionizing NLP systems.
Tip: Mention latency constraints, Alexa and customer support systems require very fast inference.

Head to the Interview Query dashboard to practice Amazon-style ML, coding, and system design questions. With built-in Python execution, performance analytics, and AI-guided feedback, it’s one of the fastest ways to sharpen your skills for Amazon’s MLE interviews.
How would you explain what a p-value is to someone who is not technical?
This question checks your ability to simplify statistical concepts for non-ML partners like PMs or operations teams. A good explanation is that a p-value measures how surprising your observed result would be if there were no real effect—a tool for judging whether results could be due to chance. You’d avoid jargon, use an accessible analogy, and reinforce that p-values don’t measure effect size. Amazon asks this because MLEs must communicate experiments clearly, especially during A/B testing.
Tip: Use concrete examples like “If we ran this test 100 times, how often would this result happen by chance?” to anchor understanding.
How would you build a real-time product recommendation system for Amazon during peak traffic (e.g., Prime Day)?
This question probes your applied reasoning around recommender systems under heavy scale and latency pressure. You’d describe precomputing item embeddings, using approximate nearest neighbor search for fast retrieval, applying lightweight ranking models online, and using caching to handle bursty traffic. You’d emphasize cold-start handling, freshness of signals, and monitoring for drift. Amazon asks this because real-time ranking is core to search, detail pages, and personalization.
Tip: Always mention fallback logic—e.g., “If embedding service fails, fall back to popularity-based ranking.”
How would you design an anomaly-detection system for monitoring Amazon warehouse sensors or delivery metrics?
This question tests your ability to design unsupervised or semi-supervised pipelines with noisy, high-volume data. You’d discuss using statistical baselines, autoencoders, clustering, or forecasting models to detect deviations, combining them with alerting thresholds tuned for operational tolerance. You’d also describe streaming ingestion, detection windows, and how to reduce false positives to avoid alert fatigue. Amazon asks this because reliability in operations and logistics is critical to customer trust.
Tip: Always tie anomalies to operational workflows—what happens after detection is as important as the model.
How to Prepare for the Amazon ML Engineer Interview
Preparing for the Amazon ML engineer interview is a multi-step process. You’re expected to demonstrate strong coding fundamentals, a deep understanding of machine learning, and clear alignment with Amazon’s Leadership Principles. The best preparation focuses on balanced, consistent practice across coding, ML fundamentals, system design, and behavioral storytelling.
Read more: Google Machine Learning Engineer Interview Guide
Here’s how to prepare with Amazon’s expectations in mind.
Build strong coding fundamentals
Spend most of your early prep time strengthening Python fluency and core data-structures knowledge. Practice solving problems in a plain text environment without autocomplete, since Amazon’s interview tools are intentionally minimal. Focus on medium-difficulty problems that combine logic, arrays, strings, maps, trees, and graph traversal. After each solution, rewrite it for clarity and test against edge cases.
Tip: Solve each coding problem twice, once for correctness, once for clarity. Amazon interviewers value clean, readable code.
Revisit ML fundamentals and applied intuition
Block time for reviewing supervised learning, regularization, evaluation metrics, feature engineering, and debugging techniques. Prioritize understanding why methods work, not just how to implement them. As you study, connect concepts to real projects: think about how you diagnosed overfitting, improved recall, or selected the right evaluation strategy.
Tip: Teach a concept out loud as if explaining to a peer. If you can explain it simply, you understand it well enough for the interview.
Study ML system design patterns
Review common patterns for scalable pipelines, feature stores, real-time inference, retraining strategies, and monitoring. Practice explaining how you’d design systems that are reliable at Amazon scale. Use structured frameworks: describe the problem, propose the architecture, call out bottlenecks, and walk through real-world trade-offs like cost, latency, and data quality.
Tip: Practice with a whiteboard or blank document, Amazon expects clear, structured communication, not perfect diagrams.
Prepare strong STAR stories
Write 6–8 detailed stories that reflect Amazon’s Leadership Principles. Focus on Ownership, Dive Deep, Invent and Simplify, Deliver Results, Bias for Action, and Earn Trust. Each story should include clear context, your reasoning, the actions you took, and measurable business impact. Practice saying these out loud so they come out naturally during interviews.
Tip: Turn each story into a “headline” you can recall quickly, like Fixed critical data pipeline outage in under 12 hours. It helps you pivot fast during the interview.
Hands-on practice and mock interviews
Run at least one full interview simulation before your onsite. Practicing under realistic conditions helps you iron out pacing, communication, and stress management.
Want to simulate real interview pressure? Use Interview Query’s Mock Interviews to test your skills live in a coding environment with real feedback.
Tip: Simulate the real interview environment, with no autocomplete, no external references, just a shared doc or plain text editor.
Build a structured prep plan
A typical prep plan looks like:
- Weeks 1–2: Coding + ML refresher
- Weeks 3–4: ML system design + domain deep dives
- Weeks 5–6: Leadership Principles + mock interviews
- Final week: Light review and story polishing
Tip: Treat your prep plan like a training schedule, set achievable weekly goals and track your progress so you stay consistent.
5 Tips to Create Amazon ML Engineer Project Portfolio
A strong machine learning project portfolio can quickly set you apart in Amazon’s interview. Your goal is to show that you can own end-to-end machine learning work, communicate impact clearly, and tie technical decisions to business results. Recruiters and hiring managers should immediately see how your projects demonstrate ownership, depth, and practical engineering ability.
Highlight Full End-To-End Machine Learning Ownership
Show projects that cover the full lifecycle: defining the problem, gathering data, building features, training the model, evaluating performance, deploying it (or preparing it for deployment), and monitoring results. Amazon’s ML teams want engineers who can move beyond experimentation and build production-ready systems.
Example:
Instead of “Built a churn prediction model,” elevate it to something like:
“Developed and deployed churn model using XGBoost, improving recall on high-risk users by 22% and enabling targeted retention interventions.”
Tip: Start each project with a one-sentence “problem → solution → impact” summary so reviewers see the value upfront.
Showcase Datasets, Problem Constraints, And Real-World Challenges
Instead of just summarizing the solution, explain the context: why the problem mattered, how the data was structured, and what challenges you faced (missing values, skew, drift, latency requirements, ambiguous labels). Amazon values engineers who can dive deep into messy reality, not idealized data.
Tip: Include a mini-section titled “Challenges & constraints” under each project to show engineering maturity.
Demonstrate Strong Model Evaluation And Experimentation Rigor
Detail the metrics you used and why. Amazon teams want to see that you understand how evaluation ties to business impact. Mention baselines, experiment design, error analysis, and how you iterated.
Examples:
- “Ran 3-stage experiment process with offline evaluation → shadow testing → live A/B test, ensuring the model met 50ms latency and 99.9% SLA.”
- “Used recall@K, calibration, and cohort analysis to evaluate performance across rare classes.”
Tip: Use comparison tables or small charts to make improvements easy to skim.
Include Deployment, Reproducibility, And Engineering Depth
Amazon heavily values MLEs who can ship. Showcase production-minded thinking: infrastructure choices, monitoring systems, versioning, CI/CD, and rollback strategies.
Examples of what hiring managers love:
- Dockerization of models
- Serving models via SageMaker endpoints or FastAPI
- Feature store integration
- Canary deployments or shadow testing
- Model versioning and experiment tracking (MLflow, SageMaker Experiments)
Tip: Add a small architecture diagram for each project. It instantly signals real-world engineering skills.
Keep Your Presentation Clean, Structured, And Easy to Skim
Hiring teams often skim portfolios in 60–90 seconds. Use clear sections: problem, approach, architecture, metrics, impact, challenges, and next steps. Consistent formatting signals professionalism and attention to detail.
Tip: Start each project page or slide deck with a 3–5 bullet overview summarizing scope, model type, scale, and impact.
Looking to prep like top candidates at FAANG? Explore our Machine Learning System Design Interviews covering pipelines, scalability, and production-ready reasoning.
How to Build your ML resume & LinkedIn profile for Amazon
Your resume and LinkedIn profile are often the only signals Amazon recruiters see before deciding whether to advance you. For ML engineers, your goal is to highlight technical depth, large-scale engineering experience, measurable impact, and subtle alignment with Amazon’s Leadership Principles. Every line should show that you can build, own, and ship ML systems that matter.
Quantify your results and scope: Amazon places a premium on metrics, scale, and clear business outcomes. Replace vague statements with quantifiable achievements that reflect the size and impact of your work.
Weak Statement Strong Statement Built ML model to classify user behavior Developed LightGBM classifier improving F1 by 19%, enabling targeted workflows for 6M+ monthly users Improved recommendation system accuracy Boosted recommendation CTR from 2.4% → 3.8% using transformer-based embeddings, driving $1.1M annual incremental revenue Worked on data pipeline Designed and productionized a real-time feature pipeline processing 120M events/day with 99.99% uptime If you cannot share quantified impact for confidentiality reasons, state the scale: “Processed 40M+ transactions across 12 markets using streaming ETL workflows.”
Tip: Every bullet should contain at least one number—accuracy, latency, scale, revenue impact, dataset size, or user impact.
Highlight key ML engineering and infrastructure skills: Amazon ML engineers operate across modeling, data engineering, and large-scale deployment. Make your skills immediately visible by placing a Technical Skills section near the top of your resume.
Recommended categories:
- Programming: Python (strongly preferred), SQL, Java, Scala
- ML Frameworks: PyTorch, TensorFlow, scikit-learn, XGBoost, LightGBM
- Cloud & Distributed Systems: AWS SageMaker, Redshift, S3, EMR, Kinesis, Lambda
- Big Data: Spark, Hadoop, Beam, Databricks
- Deployment & MLOps: Docker, Kubernetes, MLflow, Airflow, CI/CD, feature stores
- Evaluation & Experimentation: A/B testing, causal inference basics, metric design
- Monitoring: CloudWatch, Prometheus, model drift detection
Emphasize AWS where relevant, many Amazon teams rely heavily on SageMaker, feature stores, and internal MLOps platforms.
Tip: Order your skills by relevance to ML engineering (not alphabetically) so the most strategic tools appear first.
Demonstrate cross-functional collaboration: Amazon’s ML engineers rarely work alone. Recruiters want to see that you can collaborate with applied scientists, PMs, software engineers, and operations teams.
Example resume bullets:
- Partnered with applied scientists to design new loss functions for ranking models, improving NDCG by 12% across key surfaces.
- Worked with data engineering to redesign ETL pipeline, reducing processing time from 6 hours to 45 minutes.
- Influenced product roadmap by presenting ML-driven insights to directors across Ads and Retail teams.
Use verbs like partnered, led, coordinated, aligned, influenced, and presented to imply high collaboration without sounding forced.
Tip: Amazon loves examples where you influenced outcomes without formal authority, this signals strong leadership in a matrixed environment.
Align with Amazon’s Leadership Principles naturally: You don’t need to mention Leadership Principles explicitly, but your language should reflect them.
Examples:
- Ownership: “Owned end-to-end deployment of anomaly detection service affecting 20M daily events.”
- Dive Deep: “Investigated spike in model drift, identifying latency bottleneck and resolving root cause within 24 hours.”
- Invent and simplify: “Rebuilt feature pipeline as a modular DAG, reducing code complexity by 40%.”
- Deliver results: “Shipped MVP of ranking model in 8 weeks, accelerating launch of Prime merchandising feature.”
Avoid keyword stuffing. Instead, let your accomplishments demonstrate the principles.
Tip: Review each bullet and ask: Does this show ownership or impact? If not, refine it.
Fine-tune your LinkedIn profile for Amazon visibility
Amazon’s recruiting team actively sources ML engineers on LinkedIn. Optimize these areas:
- Headline: State your role + strengths (e.g., “Machine Learning Engineer | Large-scale ML systems, MLOps, AWS”).
- About section: Use 3–5 sentences summarizing your end-to-end ML experience, scale, and technical focus.
- Experience section: Mirror your resume’s strongest quantified bullets.
- Skills & endorsements: Pin your top ML + cloud skills, LinkedIn search favors these.
- Projects: Add links to public repos or portfolio pages if available.
Tip: Recruiters skim for scale, impact, and AWS experience. Make sure these appear within the first 3–4 lines of your profile.
Need a structured roadmap? Dive into Interview Query’s ML Learning Path covering everything from NumPy and pandas fundamentals to advanced MLOps concepts, to prep smarter for your Amazon interview.
Salary Negotiation And Career Growth At Amazon
Amazon machine learning compensation model is built around performance, level, and opportunity for long-term growth. Machine learning engineers, in particular, see strong compensation upside through stock grants, performance bonuses, and fast-moving internal mobility across high-impact teams like AWS AI, Alexa, Ads, Robotics, and Prime. Your total compensation depends on your level (L4–L7), location, and the business unit you join. Most hires fall between L4 and L6, with L7 reserved for senior ICs or technical leaders driving large-scale ML initiatives.
Tip: Confirm your target level with your recruiter early. At Amazon, leveling (L4–L7) directly determines compensation bands, expectations, scope, and long-term career trajectory.
Average Amazon ML Engineer Salary Bands (2025–2026)
Below are aggregated estimates based on 2025-2026 data from Levels.fyi, Glassdoor, and TeamBlind. Actual offers vary by team, performance, and cost of living (Seattle, NYC, and Bay Area tend to be on the higher end).
| Level | Typical Role Title | Total Compensation Range (USD) | Breakdown |
|---|---|---|---|
| L4 | Machine Learning Engineer I (Entry-level) | $160K – $220K | Base $115K–$145K + Annual Bonus + RSUs |
| L5 | Machine Learning Engineer II / Mid-level | $210K – $310K | Base $140K–$175K + Bonus + RSUs |
| L6 | Senior Machine Learning Engineer | $300K – $475K | Base $170K–$210K + Bonus + High RSUs |
| L7 | Principal / Lead ML Engineer | $450K – $700K+ | Base $190K–$240K + Substantial RSUs + Annual Bonus |
Note: Amazon compensation often skews heavily toward equity. RSUs can fluctuate based on AMZN stock performance, which makes long-term planning crucial.
Tip: Always compare equity refreshers and vesting schedules, these often represent the majority of total compensation for L6+ roles.
Average Base Salary
Average Total Compensation
How Amazon Structures Compensation
Amazon’s total compensation consists of four main components. Understanding each helps you evaluate offers more clearly:
| Compensation Component | Description |
|---|---|
| Base salary | Capped within a level-based range and typically less negotiable than stock. Competitive overall but often lower than some other FAANG companies. |
| Sign-on bonus (Year 1 & 2) | Structured bonuses paid monthly or quarterly to offset Amazon’s slower early RSU vesting schedule. Guaranteed and commonly used for mid-to-senior roles. |
| Restricted Stock Units (RSUs) | Vest on Amazon’s unique schedule: 5% in Year 1, 15% in Year 2, and 40% in both Years 3 and 4. Creates significantly higher earnings in later years. |
| Annual performance bonus | Smaller portion of comp relative to Big Tech peers, typically 5–15% depending on level and team. |
Tip: Don’t compare Year 1 compensation across companies. Amazon’s comp is back-loaded, so your long-term earnings (Year 3–4) can be much higher than competitor
Negotiation Tips That Work For Amazon
Negotiating at Amazon is most effective when you come prepared with data, clear reasoning, and competing offers when possible. Recruiters expect candidates to understand their market value.
| Negotiation Tip | How to Apply It | Example |
|---|---|---|
| Clarify your level early | Levels heavily influence compensation, so confirm your level at the start of the process. | “Can we confirm whether this role is scoped for L5? My experience aligns strongly with L5 expectations.” |
| Use verified salary data | Reference trusted sources and cite specific comp ranges to anchor your negotiation. | “Levels.fyi shows L5 ML Engineers at $250K–$300K total comp. Where does my offer fit in that range?” |
| Leverage competing offers professionally | Present other offers factually while showing genuine interest in Amazon. | “I have a competing offer at $X total comp. Amazon is my preferred choice if we can align on level and compensation.” |
| Lead with scope and impact | Highlight high-impact engineering work rather than years alone. | “I deployed a real-time recommendation engine serving 3M MAU with 50ms latency.” |
| Ask about location-based adjustments upfront | Clarify that your offer reflects the correct pay band for your location. | “Is this offer aligned with Seattle compensation bands or adjusted for remote?” |
Tip: Amazon is flexible on sign-on bonuses and RSUs. If base salary is capped, shift your negotiation to equity or Year 1 and Year 2 sign-on.
Evaluating Your Amazon Offer Holistically
Before accepting your offer, evaluate your compensation over the full vesting schedule—not just the first year. Look at equity growth, expected refreshers, team stability, and internal mobility opportunities across AWS, Ads, Robotics, and Prime Video. Senior ML engineers often see substantial equity refreshers once they prove long-term impact.
When comparing offers, ask your recruiter for:
- A year-by-year breakdown (base, RSUs vested, bonuses, sign-ons)
- Expected equity refresh ranges for your level
- Whether the team historically offers early promotions (L4→L5 or L5→L6)
Tip: Request two versions of your compensation breakdown, “minimum guaranteed” and “expected.” It helps you compare Amazon fairly against more front-loaded companies.
Top 5 Mistakes to Avoid in the Amazon ML Engineer Interview
Many strong ML engineers stumble in Amazon interviews, not because they lack skills, but because they overlook what Amazon consistently evaluates: clarity, ownership, trade-off reasoning, and practical ML engineering experience. Avoiding these mistakes can dramatically improve your performance across coding, ML fundamentals, system design, and behavioral rounds.
| Mistake | Why It Hurts | How to Avoid It |
|---|---|---|
| Skipping clarifying questions and jumping into solutions | Amazon values structured problem-solving and diving deep before building. Rushing often leads to incomplete or incorrect solutions. | Restate the problem, ask about constraints, metrics, data assumptions, and confirm expectations before you begin. |
| Over-indexing on theory instead of practical ML intuition | Knowing formulas isn’t enough, Amazon wants to see how you build and debug ML systems in production. | Use real examples from past projects, discuss trade-offs, and explain how you diagnose model issues. |
| Weak ML system design skills | System design is heavily weighted for MLEs. Focusing only on modeling signals you’re not ready for production-scale impact. | Practice end-to-end architecture thinking: feature pipelines, deployment, monitoring, drift detection, and A/B testing. |
| Unstructured or vague behavioral answers | Leadership Principles drive hiring decisions. Vague stories or missing metrics make you seem unfocused or low ownership. | Use the STAR method with clear stakes, actions, and measurable results that reflect Ownership, Dive Deep, and Deliver Results. |
| Not quantifying metrics or impact | Amazon is a metrics-driven company. Generic statements hide the value of your work. | Add numbers to every answer—accuracy, latency, throughput, revenue impact, dataset scale, or user impact. |
Tip: Treat every interview question, technical or behavioral, as an opportunity to show clear reasoning, measurable results, and ownership. At Amazon, clarity and depth matter more than speed.
Need 1:1 guidance on your interview strategy? Explore Interview Query’s Coaching Program that pairs you with mentors to refine your prep and build confidence.
FAQs
What are the main technical topics in Amazon’s ML Engineer interview?
Expect a blend of machine learning fundamentals (model evaluation, feature engineering, regularization), coding in Python, ML system design, and applied problem-solving. Amazon evaluates whether you can reason about real-world constraints, like latency, data quality, and scale.
How many interview rounds are there for Amazon ML roles?
Most candidates go through a recruiter screen → online assessment (for many L4/L5 roles) → one or two technical phone screens → a final onsite or virtual loop of 4–5 interviews, including coding, ML deep dive, system design, and behavioral rounds. One of these interviews is led by a Bar Raiser.
Does Amazon focus more on ML theory or practical implementation?
Heavily on implementation. Amazon wants engineers who can build, deploy, and maintain ML systems at scale. You should still understand core concepts, but the emphasis is on applied intuition, trade-offs, debugging, and evaluating models in messy real-world environments.
How can I prepare for ML system design questions?
Study end-to-end ML pipelines: data ingestion, feature stores, offline/online training workflows, deployment strategies, monitoring, drift detection, and A/B testing. Practice describing architectures clearly and explaining why you chose specific components given cost, latency, or data constraints.
Which AWS services should I know as an ML engineer?
Familiarity with SageMaker, S3, Lambda, Kinesis, Redshift, EMR, and CloudWatch is helpful. You don’t need to be an AWS expert, but you should understand the role these tools play in scalable ML systems.
What Leadership Principles are most tested in ML interviews?
Ownership, Dive Deep, Deliver Results, Invent and Simplify, and Bias for Action show up the most. Amazon wants engineers who take initiative, debug thoroughly, communicate clearly, and make data-informed decisions.
How do I showcase ML projects effectively during interviews?
Focus on end-to-end ownership: the problem, the data, your modeling choices, metrics, challenges, deployment details, and measurable impact. Include scale—dataset size, inference load, latency targets—to demonstrate engineering depth.
What are the most common mistakes candidates make?
Jumping into solutions without clarifying assumptions, leaning too heavily on theory, giving unstructured behavioral answers, or neglecting ML system design. Another frequent pitfall is failing to quantify results with concrete numbers.
What’s the typical career progression for ML engineers at Amazon?
Many ML engineers start at L4 or L5, progress to L6 Senior ML Engineer, and then move into L7 Principal roles driving long-term ML strategy. Others transition into Applied Scientist, Manager, or Architect roles depending on interest and performance. Internal mobility across AWS, Ads, Robotics, and Alexa is common.
Ready to Nail Your Amazon Machine learning Interview?
Preparing for the Amazon machine learning engineer interview is a challenging but highly rewarding journey. By building strong coding fundamentals, sharpening your applied ML intuition, practicing system design, and developing crisp STAR stories that reflect Amazon’s Leadership Principles, you’ll walk into every round with confidence. Remember, Amazon looks for engineers who can think clearly, dive deep into problems, and deliver measurable impact at scale, skills you can strengthen with consistent, structured practice.
Leverage Interview Query for Your Amazon Interview Prep
Explore Amazon specific problems and real candidate insights in our full machine learning question bank. Then sharpen your approach through practice with mock interviews, build confidence with the Modeling and Machine Learning Interview Learning Path, and get 1:1 coaching from mentors for targeted, personalized guidance on your resume, portfolio, and ideal team fit. Start small, stay consistent, and you’ll be ready to take on the Amazon ML interview with purpose and precision.
Amazon Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Brainteasers | Medium | |
When an interviewer asks a question along the lines of:
How would you respond? | ||
Brainteasers | Easy | |
Analytics | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences