
Top 10 Music Machine Learning Projects & Datasets for 2025


Introduction
According to The Business Research Company’s research report on the music streaming market, artificial intelligence and machine learning in music streaming devices are key trends in the music streaming market. With 524 million music streaming subscribers, industry giants like Spotify, Pandora, and Apple Music are showing their commitment to machine learning by acquiring various predictive analytics startups.
Want to be part of this ongoing revolution in the music industry and join the booming music machine learning market? Here are 10 Music Machine Learning data science projects with different levels of difficulty to familiarize you with the field.
Audio Beat Tracking With Recurrent Neural Networks
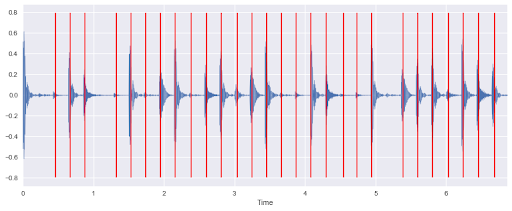
Audio beat tracking is defined as determining the instances in a recording at which a human listener is likely to tap their foot to the music. The goal of automatic beat tracking is to identify the location of every beat in a collection of sound files and output the beat onset times for each file. Although this is a basic music information retrieval task, researchers have created various approaches over the years to improve its accuracy at detecting tempo and other features in music files.
This project examines 2 of the most common approaches to automatic audio beat tracking: employing onset detection with dynamic programming and using an ensemble of recurrent neural networks (RNNs) coupled with dynamic Bayesian networks.
How You Can Do It: Follow this tutorial by JalFaizy Shaikh, which compares the 2 approaches and explains how to extract features and build, train, and fine-tune RNN models using madmom Python library. You can find the source code of the project here.
Music Genre Classification Project Using Machine Learning Techniques
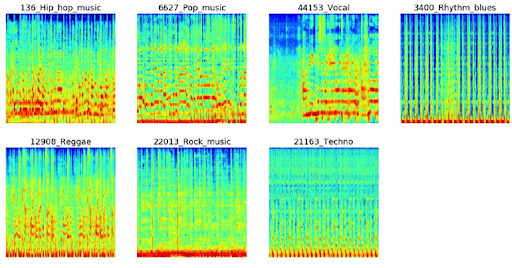
Music streaming makes up 84% of the U.S. music industry’s revenue, with Spotify as the reigning music streaming platform. It currently has a database of millions of songs and claims to have the right music for everyone. Spotify’s Discover Weekly service has become popular with millennials, and machine learning is at the core of how they classify different music genres automatically to try to provide each customer with more music that matches their taste. This process is known as music genre classification, which aims to classify audio files into the sound categories to which they belong.
The idea of this Data Science project is to use one or more machine learning algorithms, such as multi-class support vector machine, k-means clustering, or convolutional neural networks, to automatically classify different musical genres from audio files. Often, this classification is done through the filtering of audio files using their low-level frequency and time-domain features.
How You Can Do It: In his tutorial, Raghav Agrawal uses the GTZAN genre collection dataset, a popular audio collection dataset that contains approximately 1,000 audio files that belong to 10 different classes.
Automatic Music Generation Project Using Deep Learning
This project, unlike the previous ones, does not categorize music but instead generates it. Automatic music generation is a process in which a system composes short pieces of music using different parameters such as pitch interval, notes, chords, and tempo. One approach to generating music is through deep learning.
In this music machine learning project you will create an automatic music generation model using long short-term memory (LSTM) that will fetch notes from all music files and feed them into the model for prediction. These predicted notes will allow you to create a MIDI file. The project requires these Python libraries: music21, NumPy, scikit-learn, and TensorFlow.
How You Can Do It: You can follow this tutorial by Dataflair in which the project is broken down into 3 steps:
- Input Representation - Choose the Classical Music MIDI dataset, since it is easier to modify and manipulate, then filter and classify chords and notes to further simplify the generator.
- Model Architecture - Use 2 stacked LSTM layers to build and train the model.
- Sampling - Use the trained model to predict the notes.
Spotify Wrapped: Data Visualization and Machine Learning on Your Top Songs
Every year, Spotify likes to celebrate December by sending each user a playlist of their top songs from the year. For every user, this playlist features the 100 songs they listened to most during that year. While this is a fun function, you can use data science to obtain further insight and visualization.
In this project, you will explore and visualize data from 6 years (2016–2021) to examine trends such as the top 10 artists based on the number of songs in your end-of-year playlist, the number of songs per artist, the number of times a song is repeated over multiple years, who released the songs, and when songs on your playlist were released.
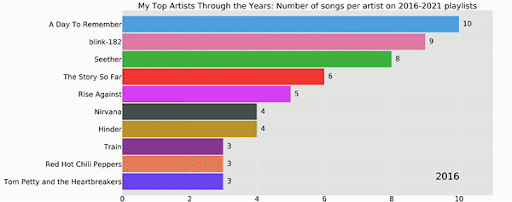
This project will allow you to practice different machine learning algorithms such as logistic regression, k-nearest neighbors, linear vector machine, decision tree, and random forest in different applications.
How You Can Do It: This step-by-step tutorial by Adam Reevesman explores the musical features offered by Spotify API to experiment with different machine learning algorithms to build a model that can predict music taste. You can find the complete project code on his GitHub Repository.
Building A Music Recommendation System Using Spotify API
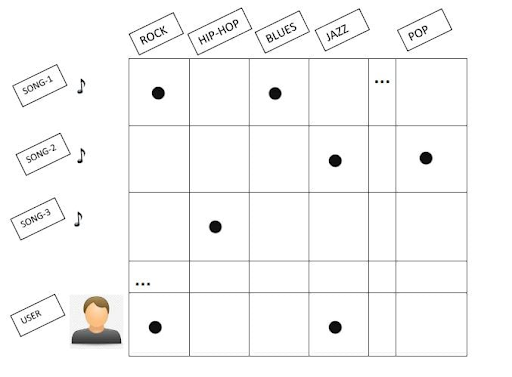
Streaming services compete to provide you with music recommendations that fit your taste. To accomplish this, they use different machine learning-based recommendation systems.
Broadly, their algorithms are categorized into two classes used in a recommendation system:
- Content-based Filtering - Uses characteristic information that recommends new items/products to a user based on their past actions or explicit feedback.
- Collaborative Filtering- Uses user-item interactions to generate recommendations. In other words, this algorithm uses similarities between users and items simultaneously to provide recommendations.
How You Can Do It: In this project, you will employ content-based filtering using the cosine similarity metric, making this a great introduction to recommender systems and a beginner-friendly project. All you need is basic knowledge of Python libraries like pandas, NumPy, scikit-learn, and the basics of vector algebra.
Follow this tutorial by Tanmoy Ghosh, which will walk you through how to use Spotify library to access Spotify Web API and a basic recommender using your Spotify data. You can find the full project code in his GitHub repository.
You can also practice how to build a collaborative-filtering recommendation engine using this tutorial by Ajinkya Khobragade on Medium. Additionally, you may want to watch this video on creating TreeMaps in Tableau.
Million Song Dataset Challenge

The Million Song Dataset Challenge by Kaggle is one of the best offline evaluations of creating a music recommendation system. The challenge is to use half of the listening history for 100,000 users from the million-song dataset (the full listening history for 1 million users) to predict the other missing half.
For a more technical introduction to the Million Song Dataset Challenge, see our AdMIRe paper.
How You Can Do It: You can review this project report from a team at Cornell University in which they use the k-nearest neighbors machine learning algorithm, user-based and item-based recommendation strategies, and a multi-faceted prediction algorithm to build a recommender model.
However, the winning submission for the challenge is Fabio Aiolli’s, who published a paper explaining his winning approach using model-based collaborative filtering. He also published the code for the project on his website. If you need a simpler approach to the project, you can go to the MSDS tutorials page for alternative ways to perform various tasks needed for this challenge.
KKbox’s Music Recommendation Challenge

Another way to practice machine learning algorithms and manipulate music datasets is the KKbox Music Recommendation Challenge by Kaggle. The challenge is to build a model that will predict whether a user will re-listen to a song by evaluating given features of songs and the user.
The dataset for the challenge is provided by KKbox, which is Asia’s leading music streaming service, holding the world’s most comprehensive Asian pop music library with over 30 million tracks. They currently use a collaborative filtering-based algorithm with matrix factorization and word embedding in their recommendation system but believe new techniques could lead to better results.
In this project, you will convert this problem into a classification problem and can apply various classification algorithms, evaluate the results, and choose the best-performing approach.
How You Can Do It: This tutorial by Khushali Vaghani lays out a step-by-step process on how to explore the data, process it, and apply feature engineering to extract features from raw data to improve the machine learning algorithm’s performance. The tutorial then teaches you how to build models using 9 different algorithms before comparing the results and concluding which approach yields the most accurate results.
Speech Emotion Recognition With Librosa

Speech emotion recognition is the act of attempting to recognize human emotion and affective states from speech, which is tough because emotions are subjective, and annotating audio is challenging. However, such a system has a wide range of application areas like interactive voice-based-assistant or caller-agent conversation analysis.
This project uses librosa, a Python library for analyzing audio and music, and the RAVDESS dataset to build a model to recognize emotion from speech.
This dataset has 7,356 files rated by 247 individuals 10 times on emotional validity, intensity, and genuineness. You might also want to review data sources like the LSSED or this list of emotion recognition datasets.
How You Can Do It: This tutorial by Analytics Vidhya explains how to build the model using MLPClassifier. You can find the source code for the project here.
For another approach, this tutorial walks you through using a convolutional neural network to examine RAVDESS data.
Music Transcription With Python
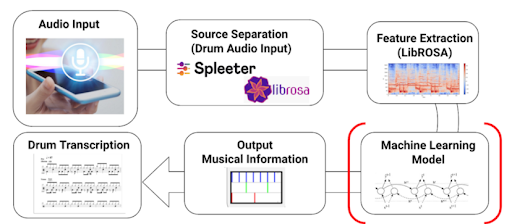
Music transcription is the process of converting user-provided audio into a musical notation through mathematical analysis. It is a complex problem, especially for polyphonic music. Currently, existing solutions yield results of approximately 70% or less accuracy.
In this project, you will solve a simpler version of the issue by processing user-provided audio using open-source Python libraries and generating onset predictions for up to 13 instruments common to drum sets and musical percussion.
The project is divided into 3 stages:
- Audio Transformation (Preprocessing): Transfer audio to short-time-fourier transform (STFT) spectrogram then to an array that represents the frequency level and amplitude.
- RNN (Keras LSTM & Bidirectional LSTM [BiLSTM] model): Feed concatenated STFT spectrogram into RNN, then LSTM model to solve the vanishing gradient problem, and finally into the Bidirectional LSTM (BiLSTM) model, which further improves model performance.
- Event Segmentation (Peak Picking method): Apply the peak picking method to detect the onset for each instrument so the model provides accurate onset detection for 3 common instruments (kick drum, snare drum, and hi-hat).
How You Can Do It: You can follow this capstone project tutorial by Yue Hu in which she explains how her team implemented this project in Python using librosa and details building and testing the model.
Chord Recognition using Librosa

Chord recognition is the act of attempting to recognize and label chords in a piece of music. This is a challenging task due to the complexity of harmonic structures and the variability in musical compositions. However, chord recognition has significant applications in music transcription, education, and automatic accompaniment systems.
This project uses librosa, a Python library for analyzing audio and music, and the Isophonics dataset to build a model to recognize chords from music.
This dataset includes chord annotations for various songs, providing a valuable resource for training and evaluating chord recognition models. You might also want to review data sources like the The Beatles dataset.
How You Can Do It: This tutorial on Medium explains how to build the model from scratch and making your own data set. You can find the source code for the project here.
Learn More With Interview Query
You can also check out these helpful resources from Interview Query: