
How to Start a Data Analytics Project (Updated in 2025)


How to Start a Data Analytics Project
Data analytics is integral to most businesses and organizations as raw data is generated at exponential rates, and businesses develop more time-critical decision-making structures. Continuing to expedite the need for analytics is that as new data is generated, business insights that rely on historical data will need to process more and more elements as the organization grows.
Essentially, as the demand for data in decision-making increases, the effort needed to keep up with the same deliverables increases drastically as a company matures. What data analytics does is clear the abstraction between the data and the stakeholders, making it easier to understand and build decisions from the raw data inputs.
One question we often get at Interview Query is: how to start a data analytics project? An overview of the processes involved in starting a data analytics project can be integral for tracking your progress without focusing too much on tasks that don’t matter. Below, we list the steps:
- Determine a hierarchy of urgency: Define the questions you want to answer, and select an idea based on the hierarchy of urgency.
- Collect the data: Identify integral data, know what type of data to use, and gather datasets.
- Cleaning the data: Remove redundancies and fill in the missing information.
- Enriching your data: Generate more data from what is available.
- Utilize machine learning: Create data-driven decisions.
- Visualize the data: Visualize your data, and determine which data visualization tool to use.
- Share and iterate: Introduce your data to stakeholders and learn from past mistakes.
No data analytics background? Check out how to become a data analyst without a degree.
1. Determine a Hierarchy of Urgency

Before you can start a data analytics project, one of the most essential things to do is to define the questions you want to answer. Of course, defining questions is not limited to finding problems and creating projects with each inquiry.
In an organization, there will always be multiple problems to handle and tangents that need to be sorted out. However, as a data analyst, it is best to create a project that speaks to the highest urgency of the organization.
To find the right questions to ask when starting a data analytics project, one must consider the following:
- Know the hierarchy of urgency.
- Develop a hypothesis that makes sense.
- Plan out data sources and test viability.
The Hierarchy of Urgency
There are many ways to determine the issues that are of utmost urgency within an organization. Getting updated by company newsletters is one way to identify big-ticket initiatives. You can also speak with stakeholders in other departments to know the looming problems within a company.
You should prioritize data analytics projects that are both important and urgent. Nevertheless, following the guide above can help you understand the hierarchy of urgency.
For example, if an organization spends a major portion of its budget on an ambitious marketing effort, the highest priority projects should be ones that analyze the effectiveness of the marketing strategies employed.
On the other hand, for companies that are experiencing a loss in subscriber count after changes in pricing were made, a good data analytics project to start would be one that analyzes how the new pricing scheme affected user behavior.
Although the hierarchy of urgency highly depends on an organization and what it would constitute as urgent and essential, several models can help you get a starting point with developing your personal hierarchy. Below, we utilize Dwight D. Eisenhower, The 34th U.S. President’s model, as popularized by Stephen Covey and his book, “The Seven Habits of Highly Effective People.”
- Important: activities that can help us reach our goals. They are integral and are the driving force as to why you are planning a data analytics project in the first place.
- Urgent: Although not necessarily aligned with your personal goals, urgent matters are things that have immediate consequences.
Eisenhower’s Hierarchy of Urgency
- Important and urgent
- Important but not urgent
- Not important but urgent
- Not important and not urgent
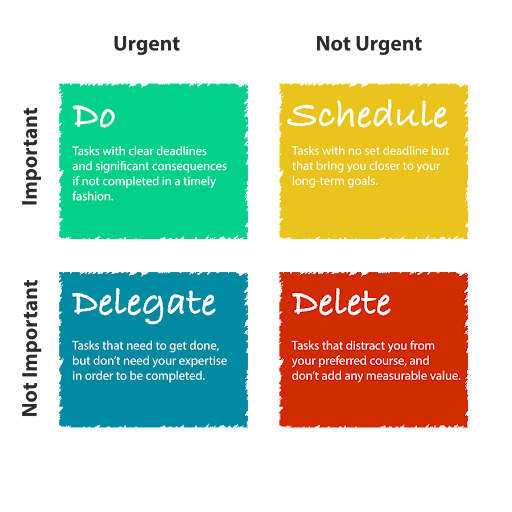
You should prioritize data analytics projects that are both important and urgent. Nevertheless, following the guide above can help you understand the hierarchy of urgency.
Crafting A Hypothesis That Makes Sense
One of the most critical steps in making a data science project is developing a hypothesis. Many data analysts go through this process without knowing that they have already formed a hypothesis. Other data analysts simply fail to do this step and skip it completely in their rush to start executing the project.
To the end-users and stakeholders, the hypothesis does not matter. However, to the data analyst, which in this case is you, the hypothesis provides structure to your overall project, giving it a sense of direction.
A hypothesis is an educated guess that tries to answer why a problem exists or an approach to how to solve a specific problem. It is called an “educated guess” due to the statement being based on available data or knowledge.
By the end of a project, you should be able to prove or disprove a hypothesis. Basically, most or all of your steps should circle around your hypothetical statement. If you encounter crossroads within your project, the first question should be, “Does doing this help prove or disprove my hypothesis?”
Plan Out Data Sources and Test Viability

Now that you have determined your hypothesis and have chosen the best question to develop a data analytics project on, you should focus on doing a mini-feasibility study. A data analytics project must be feasible, which means that you must plan out where you should gather your data, how to process it, and evaluate if your approaches are doable in an appropriate amount of time.
To plan out where to get your data, look for internal datasets that are available. Moreover, you can try looking at websites on the internet that specialize in storing datasets that might help create a more robust data analytics project.
You will also need to determine what type of data to gather. Do you need social media datasets? Do you need qualitative or quantitative data, discrete or continuous?
Knowing the answer to these questions should help you transition to the next step smoothly.
2. Collect Your Data

Now that you have planned out the hypothesis and the data types needed, it is time to start collecting the data. Harnessing the correct data sources, managing multiple datasets, and utilizing each one is incredibly tiresome. This step will potentially be the most challenging and time-consuming but is also considered the most crucial.
How do you get started with data collection and management? Below are some tips that you might consider:
- Use multiple datasets and merge them.
- Utilize internal data.
- Make use of secondary data sources.
- Use APIs.
Using Multiple Datasets
Many data analysts make the mistake of using one dataset for everything and building their inferences from there. However, the best data analytics projects are those that utilize multiple datasets.
Multiple datasets are intimidating to look at but are rewarding when used correctly. Essentially, numerous datasets allow you, the data analyst, to view the situation from different angles. This, in turn, will enable you to generate more accurate insights that better represent reality as you repeatedly reference and cross-reference your results.
Utilize Internal Data
Primary sources or internal company data are always the best sources for datasets as these tend to be pre-curated to your needs, presenting the most relevant data available. Moreover, they contain private information unavailable anywhere else.
In addition to that, these sources allow you to unlock the potential to observe a particular behavioral pattern that affects business sales or employee turnover specific to the company you are interested in or are currently working for, thus making it more relevant.
Know The Proper Sources, Collect Secondary Data
Secondary data does not have as good of a reputation as primary data, mainly due to concerns regarding its authenticity. Mostly, this reduced trust in secondary sources is warranted, as many variables can compromise the quality of a dataset, such as internal biases, inappropriate collection methods, and tampering.
Another issue with secondary datasets is that they are not tailor-made for your specific needs, which might not help supplement your data analysis project.
For example, when trying to find out the salary rates for employees within your company, secondary data sources will be unable to provide accurately or, even worse, relevant results.
However, when mixed and matched with other datasets, secondary sources can be enough for you to start your data analytics project. Moreover, secondary datasets are excellent for supplementing a primary dataset, making your inferences much stronger.
When in doubt, you can use the following mediums to obtain secondary dataset sources:
- Google Dataset Search
- Data.world
- Data.gov
- Kaggle
- UCI Machine Learning Repository
- Stanford SNAP
Utilize APIs
APIs are a godsend for data scientists and data analysts, especially when you start building your data analytics project. APIs allow you, the data analyst, to access information from services (i.e., weather, interaction information, statistics) of a specific service, commonly web services.
An API, or an Application Programming Interface, can help you grab information quickly, especially data not locally available in your databases and that require constant updates (i.e., weather data changes by the hour). For example, when assessing the performance of a marketing campaign, it might be helpful to use APIs offered by social media networks and analyze the engagement numbers in real-time.
Many web services offer APIs, and it would be a waste not to utilize them. A great thing about APIs is that they are flexible, meaning that even if a website changes its format, APIs will still enable you to gather the information accurately. This kind of flexibility is advantageous, especially when contrasted to web scrapers that rely on format consistency and depend on the fact that the information they need is publicly viewable.
3. Cleaning Data
After ensuring the highest quality data possible and mixing and matching any other datasets, it is now the best time to sit back and analyze your approach for said data. One of the most ingenious approaches is making sense of all the data available as quickly as possible. Below, we explain the thought process required in this step.
Making Sense of All the Data
When trying to understand the data, keep in mind that this process should not be focused on making the most accurate observations but on giving you an eagle’s eye view of the whole dataset situation.
Take notes as much as possible, especially about the patterns you notice, the definition of the fields and columns, and any other relevant information. Be careful not to spend too much time trying to decrypt the information you have in hand.
For secondary sources, read the documentation available. Do not try to “hack and slash it” until you finally understand what you are working with. While this trial and error of mind crunching might feel satisfying, in the end, it could just be a five-minute lookup on the dataset document. Alternatively, you may reach a conclusion that you think is a correct interpretation but is in fact quite a bit off the mark.
On the other hand, for primary datasets, ask questions to those behind the data, those involved more generally, and others associated with its generation. For example, while analyzing a marketing campaign’s effectiveness, talking to the social media manager, the marketing team and the public relations team could help significantly.
Remember that data analytics is not a one-person job, and data cleanup can be extremely taxing and time-consuming. Efficiency is critical here, so going in with a plan will help cut down on time and cost immensely.
Cleaning Up Data: Finding Mistakes
Data cleaning is one of the most intensive processes in a data analytics project. Although one can do data cleaning with automation (such as anomaly detection for identifying outliers), there are still tasks that mandate the manual use of tools.
Massaging the data can be extremely troublesome, such as looking for duplicates, filling in missing data, and finding the appropriate and unnecessary fields that can clog up a pipeline. However, one of the biggest problems that can make it hard for data analysts to clean data is knowing what is wrong in the first place.
Keep your head grounded and analyze the data thoroughly. Although the data may not seem wrong at first, there is a possibility that you will miss red flags due to stress, mishandling, or negligence. Take your time on things that matter, and use less time for things that do not.
4. Enriching Data
Now that we have gathered, cleaned, and prepared your data, we need to enrich it by employing tools and critical analysis. Enriching your data is the process whereby one makes new data out of currently available sets, making the most of what is now available and creating new windows for developing insights.
One way to enrich your data is to cross-reference datasets from each other, generating new information describing the relationship between the two. For example, when you want to analyze the employee turnover rate, you can cross-reference the number of resignations approved against the results of an employee satisfaction survey over time.
You will not be creating inferences or insights; instead, you will make a new data set from said values. For example, you can generate data that shows the ratio between employee satisfaction and approved resignations. You are not necessarily “making up” data, but instead creating new data based on what is already available.
Another method of enriching data is by using machine learning algorithms. Let’s take a quick look at machine learning.
5. Utilizing Machine Learning
Machine learning can be a valuable tool when developing data analytics projects. However, employing it all the time is not integral as this may require a lot of resources for not a lot of relevant data. We should know when and where to utilize machine learning for our data analytics project.
One of the problems with machine learning is its sheer complexity. Implementing models will require you to talk to many people, understand how these values work in tandem, understand the use cases, talk with business people, anticipate edge cases, and more.
Nevertheless, we have prepared a quick guide to determine whether machine learning is the appropriate approach to your data analytics project:
- A critical factor in determining whether or not one should employ machine learning is when looking at the predictability of your dataset. If your dataset has concrete, easy-to-follow patterns, then machine learning should (in most cases) be forgone.
- On the other hand, the less predictable the data is, the more inclined we should be to use machine learning models. These datasets contain patterns that are not visible, and machine learning, through heavy computation, can help massage and analyze data to help enrich your current datasets.
When opting to use machine learning to make predictions, there are a few things to consider. We have put them in a small list below:
- Know what machine learning models to use for your specific data analytics project.
- Shape and massage your data accordingly.
- Know how to balance accuracy and performance. For example, a machine learning algorithm does not have to predict all labels with 100% accuracy. Instead, it should correctly tag data spaces that matter to your project. Trying to predict all labels accurately may consume more resources while having only an asymmetrical (tiny) gain in output.
- Massage and shape your data according to the available resources.
User Profiling
Another way to enrich your data is to develop a user profile that gathers all data from one user and creates inferences from said profile. For example, assembling a user’s IP address and email accounts along with APIs and data scrapers help to develop a strong user profile that can assist you with your data analytics project.
However, be sure to source your data ethically. When dealing with sensitive information that may hurt or endanger a user (i.e., marginalized communities such as LGBTQ, HIV+, POC, etc.) or those that store political affiliation, it is best to censor/anonymize them. Doing so can help reduce biases not only among yourself but also those who are directly involved in your data analytics project.
6. Visualizing the Data
Machine learning is not the end-all, be-all option when it comes to predicting the outcome of a dataset or generating insights on a data analytics project. As stated earlier, ML algorithms will use a lot of resources, not only in computing but also in time, human effort, and involvement.
In addition, machine learning can utilize different departments and will take weeks to months to develop and train before it becomes remotely usable. As such, we should consider another option, one more accessible when compared to machine learning: data visualization.
Something we need to stress is that machine learning and data visualization are not mutually exclusive from each other. A data analyst can use data visualization alongside models to create a superior data analytics report than if taken individually.
Where Data Visualization Wins
Machine learning models allow you to create a data-driven analysis, but visualizations will enable you to quickly explore data, which is useful for making decisions.
Data visualization typically requires fewer resources, does not involve a lot of time in development or deployment and requires less involvement from other parties within an organization. Moreover, the process is much more streamlined than crafting a ML solution.
To conduct data visualization, you can utilize the following as your tools:
- Python with data visualization libraries.
- R with data visualization libraries.
- Microsoft Excel.
- Visual design tools such as Adobe Photoshop.
Data analytics is not only less resource-heavy, but it also wins in another category: presentation. Machine learning models and concepts, especially when paired with raw data, can be highly challenging for stakeholders outside data analytics or even your project group to follow.
Business decisions require multiple facets of opinions before one can deduce an informed conclusion. Many of those involved in the decision-making process may even still be unfamiliar with the industry jargon, and one can dilute the overall impact of data due to sheer confusion.
Data visualization can help provide your data analytics project with a more immediate and lasting impact on stakeholders. Moreover, creating understandable and easily digestible data can produce a more conducive result (project buy-in).
Methods of Data Visualization
There are many ways to present your data to the stakeholders. Before presenting them, it is best to analyze which data visualization method is the best for your specific data analytics project.
- The bar chart is perfect for comparing two or more values over time. However, when too many categories or value types exist, the chart can get quite complex and difficult to read.
- A histogram is similar to a bar chart but better for displaying a particular event’s frequency. For example, you can check how many times an ad campaign from your organization has been clicked through a histogram.
- The pie chart is great for showing percentages or comparing the values of different variables. Unlike the bar chart, which can show growth over time, the pie chart captures data by the moment and sees which variable exerts more dominance than the other.
- A heat map can show the transition of frequency through color. What makes heat maps excellent is that the data visualization is typically very fluid and shows transitions from cool to hot areas of the chart, making it easy to observe patterns.
- The box and whisker plot is a data visualization technique that shows the median, the quartiles, and the outliers. It can show you the symmetry and anomalies of data.
- Timelines and the Gantt chart are great options for showcasing time.
- Lastly, line graphs are great for showcasing small changes and trends over time. Bar graphs, in comparison, are great for showcasing more significant changes that occur over a long period of time.
7. Sharing and Interpreting Results

Now that you have prepared a visual method of presenting your data and machine learning models to help predict trends, the next step should be creating data-guided business decisions. Simply put, this final step is the end goal of your data analytics project.
After observing trends and creating practical ways for data presentation, stakeholders and the decision makers of an organization should be brought to the attention of what you have found out after your project.
Note that business decisions do not have to be elaborate. Your data analytics project is still successful, whether the conclusion is to change the current approaches implemented within an organization or if it suggests maintaining the contemporary ideologies embedded within a company.
Remember the hypothesis you made earlier? This stage of the project should be where, through data-driven inferences, you can now reject or accept the hypothesis.
Learning From Experience
Now that you have shared your data analytics findings with the appropriate people, it is best to make it available to other data analysts, scientists, and engineers within your company for future reference.
Moreover, you can use this part of the project to reiterate and improve your current machine learning models or to use your project as a template. You can redo your data analytics project annually, monthly, or on a per-case basis. A baseline template can be great to build on to make future similar projects easier to stand up and eventually more elaborate.
Are you looking for more data analytics projects that you can practice with? Check out our Marketing Analytic Projects article!