
Thomson Reuters Machine Learning Engineer Interview Guide (2025)


Introduction
Thomson Reuters is a global leader in trusted news and professional information, serving legal, tax, finance, and media industries worldwide. Beyond its legacy as one of the most respected news organizations, the company has been doubling down on artificial intelligence to power legal research tools, financial analytics platforms, and real-time news delivery.
As a machine learning engineer at Thomson Reuters, you’ll be working at the intersection of cutting-edge AI and high-stakes professional domains. You’ll contribute to building systems that process massive volumes of legal documents, financial market feeds, and global news in real time. What sets this opportunity apart is the chance to apply advanced ML techniques like NLP, deep learning, and graph-based reasoning to proprietary datasets. The demand for ML engineers has been steadily growing, with LinkedIn reporting it among the top emerging jobs worldwide, making this role both timely and impactful.
In this blog, we’ll walk you through what it’s like to work as an ML engineer at Thomson Reuters, covering responsibilities, culture, and interview prep tips to help you succeed. Keep reading to see how you can position yourself for this exciting opportunity.
Role Overview & Culture
Machine learning engineers at Thomson Reuters are embedded within interdisciplinary teams that design, build, and scale intelligent systems for products like Westlaw, Reuters News, and risk intelligence platforms. A typical day may involve training transformer models for legal document summarization, deploying pipelines that power real-time news tagging, or optimizing fraud detection algorithms using streaming data. The company’s culture is rooted in its Trust Principles—emphasizing transparency, data integrity, and public accountability—which gives engineers autonomy in building models that are both robust and ethically sound.
Why This Role at Thomson Reuters?
What makes this role particularly exciting is the scale and impact of the work. Thomson Reuters maintains some of the world’s richest proprietary datasets covering legal opinions, regulatory filings, real-time financial transactions, and multilingual news feeds, which offer unmatched opportunities for applied machine learning. Additionally, the company’s AI and data science teams are expanding rapidly, providing strong internal mobility and long-term career development in artificial intelligence.
With that in mind, let’s take a closer look at what the day-to-day responsibilities, team culture, and expectations actually look like in this role.
- Day-to-day responsibilities
- Train transformer models for legal document summarization and search relevance.
- Build and deploy ML pipelines that power real-time news tagging and classification.
- Optimize fraud detection algorithms using streaming financial and regulatory data.
- Culture
- Grounded in the company’s Trust Principles, emphasizing transparency, independence, and accountability.
- Strong commitment to ethical AI development, ensuring models are unbiased and trustworthy.
- Team setting
- Embedded within interdisciplinary groups that bring together engineers, data scientists, legal experts, and financial analysts.
- Collaboration across product lines like Westlaw, Reuters News, and risk intelligence platforms.
- Expectations
- Deliver scalable, production-ready ML solutions that can handle global datasets in real time.
- Balance cutting-edge experimentation with the reliability required in high-stakes industries.
- Unique perks
- Access to proprietary, large-scale legal, financial, and media datasets is rarely available outside Thomson Reuters.
- Opportunity to work on socially impactful projects, including advancing legal access, financial transparency, and unbiased journalism.
Excited about the impact this role can have? Let’s walk through the step-by-step interview process you can expect as a machine learning engineer at Thomson Reuters.
What Is the Interview Process Like for a Machine Learning Engineer Role at Thomson Reuters?
The Thomson Reuters machine learning engineer interview process is structured to evaluate both your technical depth and your ability to build real-world ML systems that operate at scale. Candidates report a rigorous but fair progression through technical assessments and case-based discussions, with an emphasis on applied machine learning, data engineering foundations, and communication skills.
Whether you’re interviewing for an entry-level MLE or a senior position, expect a blend of algorithmic coding, end-to-end ML pipeline design, and behavioral evaluations focused on collaboration and impact. Below is a breakdown of each stage in the process.
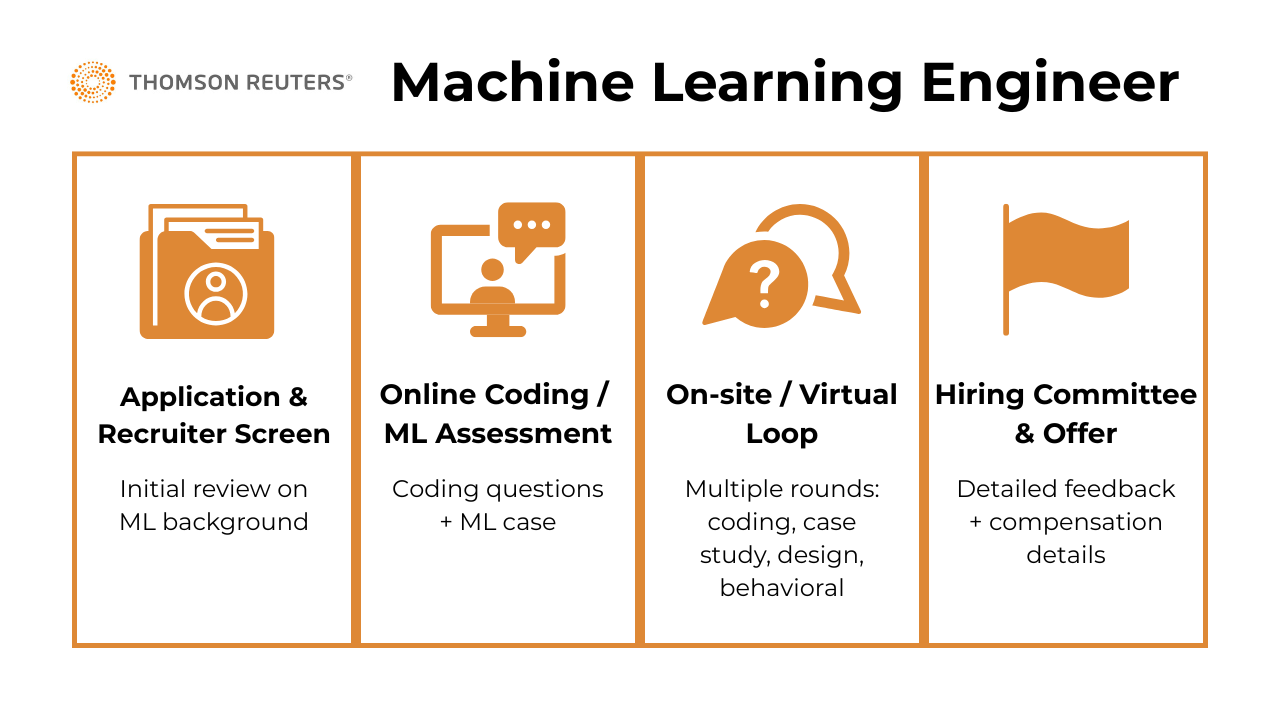
Application & Recruiter Screen
Once you submit your application, a recruiter will reach out if your experience shows strong alignment with ML fundamentals—particularly in areas like NLP, real-time data processing, or production-grade model deployment. Candidates say having projects that show full model lifecycle ownership (from data ingestion to monitoring) helps get past this screen. The recruiter may ask a few high-level questions about your recent projects and motivation for applying.
Tips:
- Highlight projects that show end-to-end ML ownership, not just model training.
- Emphasize familiarity with production ML tools (e.g., Airflow, Docker, cloud ML services).
- Prepare a concise “why Thomson Reuters + why ML” pitch.
Online Coding/ML Assessment
If you pass the initial screen, you’ll receive Thomson Reuters machine learning engineer assessment, usually hosted on HackerRank or a similar platform. The test consists of 1–2 coding questions (often involving Python and data structures) and one machine learning case, such as implementing a basic recommender system, performing model evaluation, or selecting features from noisy data. Candidates report the difficulty as medium and more focused on correctness and clarity of thought than trickiness.
Tips:
- Practice medium-level LeetCode problems in Python (lists, dicts, streaming).
- Review common ML coding challenges: logistic regression, KNN, simple recommenders.
- Write clean, well-documented code—clarity counts as much as correctness.
On‑site / Virtual Loop
The main interview loop typically spans 3–4 rounds:
Coding Round: You’ll solve DS/Algo problems in Python, often emphasizing data transformation, streaming data, or dictionary-based logic.
Tips: Focus on efficient data manipulation, test your code with edge cases, and explain your thought process as you code.
ML Case Study: Interviewers present a product or business scenario (e.g., fraud detection or real-time classification) and ask how you would model the problem end-to-end—data handling, model choice, evaluation metrics, deployment, and monitoring. Tips:
- Learn the different types of machine learning case studies and how to approach them.
- Structure your answer: problem understanding → data → model → metrics → deployment.
- Show trade-off reasoning rather than just naming models.
System Design for ML: Candidates are asked to design scalable ML pipelines or describe how to serve models in production. Emphasis is placed on trade-offs in latency, retraining frequency, and infrastructure choices (e.g., batch vs real-time, cloud orchestration).
Tips:
- Know ML system design patterns (feature store, batch vs streaming, A/B testing).
- Discuss scaling strategies and failure handling.
- Use diagrams or step-by-step explanations if possible.
Behavioral Interview: This round explores your collaboration style, how you learn from failure, and how you’ve handled ambiguous or high-stakes projects. Be ready to discuss past projects using the STAR framework.
Tips: Prepare 3–4 STAR stories (conflict, failure, leadership, innovation). Reflect not just on what you did, but what you learned and how it applies here.
Hiring Committee & Offer
Post-interview, your performance is reviewed by a hiring committee, which may include individuals who did not personally interview you. These panel members rely on detailed written feedback from your interviewers to assess your overall alignment with the technical and cultural expectations of the role. This “bar-raiser” or calibration-style approach ensures consistency in hiring standards across teams. If consensus is reached, the recruiter will follow up with verbal feedback and compensation details. Offers typically include a base salary, bonus eligibility, and equity components.
Behind the Scenes
Interviewers are encouraged to submit written feedback within 24 hours to ensure accuracy and fairness. Thomson Reuters reportedly uses a bar-raiser style calibration process, where at least one interviewer is responsible for assessing cultural and technical bar alignment independent of team fit.
Differences by Level
Senior MLEs face an additional architecture round and leadership behavioral panel.
For senior machine learning engineer candidates, an additional architecture/system design round is included, focusing on how to build robust, scalable ML infrastructure across teams. You’ll also face a leadership-oriented behavioral panel that assesses cross-functional influence, mentorship, and long-term technical vision. Junior candidates are evaluated more on learning potential, clarity of thought, and hands-on skill.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Thomson Reuters?
What Questions Are Asked in a Thomson Reuters Machine Learning Engineer Interview?
Thomson Reuters machine learning engineer interviews are designed to assess not just your technical ability, but also your understanding of real-world ML system deployment and your alignment with the company’s values around data integrity and product responsibility. Below are the key categories of questions you’re likely to encounter, along with examples drawn from candidate reports.
Coding / Technical Questions
Expect a mix of classic algorithmic questions and applied ML tasks during the technical rounds. These questions often reflect the kind of problems Thomson Reuters machine learning engineers face in production, particularly around large-scale data handling and model optimization. You may be asked to implement a trigram model to predict the next word in a corpus, write Python code to optimize a feature pipeline for latency under streaming conditions, or even build a basic version of a gradient-boosting model from scratch. The emphasis here is on clean, correct, and scalable code—along with a clear explanation of your design choices.
Group a list of sequential timestamps into weekly lists starting from the first timestamp
Approach this with date arithmetic and slicing in Python. You want to iterate through the list while maintaining buckets that restart every 7 days. Pay attention to edge cases like timezone-aware timestamps or gaps. This question tests your ability to structure time-series data and is great for data processing roles.
Tips: Use
datetime.timedelta(days=7)for grouping, watch for off-by-one issues, and test with irregular gaps or daylight saving shiftsPredict the next word with a trigram model given a large corpus
Build a trigram language model by counting occurrences of word triplets and estimating conditional probabilities. During prediction, use the last two words as context to suggest the most likely next word. Handle unknown word sequences with smoothing techniques (e.g., Laplace or backoff). This tests your grasp of NLP fundamentals and statistical language modeling.
Tips: Preprocess text carefully (lowercasing, tokenization, punctuation handling). Implement smoothing to avoid zero probabilities. For efficiency, store counts in nested dictionaries or
defaultdict.Write a function to return the top N frequent words in a sentence
Count frequencies using Python’s
collections.Counterand sort by count. Be mindful of ties and how you handle punctuation and case. Use heaps if you want optimal performance on large datasets. Word frequency analysis is often an early step in NLP pipelines.Tips: Normalize input by removing punctuation and converting to lowercase. Use
Counter.most_common(n)for simplicity. For big inputs, rely on a heap (heapq.nlargest).Write a function to check if one string is a subsequence of another
Iterate through both strings using two pointers. Move the pointer in the source string only if characters match. Return true if all characters of the subsequence are found in order. This is a basic yet essential question to understand string traversal and pattern validation.
Tips: Walk through examples to avoid pointer missteps. Consider empty subsequence (always true) and subsequence longer than source (always false). Time complexity should be linear.
Implement gradient boosting from scratch
Start with a base learner (like decision stumps) and iteratively add models that correct residual errors. Focus on computing gradients of the loss function and updating weights accordingly. Pay attention to shrinkage/learning rate and regularization to prevent overfitting. This problem measures your depth of understanding in ensemble learning methods.
Tips: Begin with squared error loss before tackling others. Show the math for residual updates. Keep code modular to illustrate iterative fitting. Mention trade-offs like speed vs. accuracy.
Select a random number from a stream with equal probability
Use reservoir sampling to ensure uniform probability without knowing stream length. Keep one selected value and update it probabilistically as new values come in. Make sure the algorithm works for both small and large streams. This shows your understanding of efficient algorithms under memory constraints.
Tips: Memorize the key step: replace with probability
1/iat the i-th item. Test with small streams to confirm uniform distribution. Be prepared to explain why this guarantees fairness.Optimize a streaming feature pipeline for latency
Consider a real-time feature store where incoming events must be transformed and served to models with low latency. Break down bottlenecks such as serialization, joins, or external lookups. Propose optimizations like batch windows, caching, or asynchronous writes. This question evaluates your understanding of ML systems design under production constraints.
Tips: Think in terms of end-to-end latency budget. Mention in-memory caching (Redis), parallelism, and feature pre-computation. Show awareness of trade-offs between consistency and speed.
System / Product Design Questions
In this session, the focus shifts to architecture and end-to-end thinking. You’ll be asked to design full ML systems that mirror the company’s core applications like processing and classifying real-time news topics. These questions test your ability to think through the full ML lifecycle: from ingesting unstructured data and choosing model architectures, to designing A/B rollout strategies and ensuring model monitoring post-deployment. Thomson Reuters values candidates who can balance engineering constraints with product reliability and interpretability.
Design a classifier to predict the optimal moment for commercial breaks
Break the problem down into a time-series classification task using user engagement data. Define features such as pause frequency, skip rate, and watch completion to train the model. Consider balancing business goals (ad revenue) with user satisfaction. This scenario mimics real-world challenges in digital streaming platforms.
Tips: Focus on defining the target variable clearly (e.g., “engagement drop-off point”). Discuss trade-offs between short-term revenue vs. long-term retention. Mention real-time feature engineering challenges.
Describe the process of building a restaurant recommender system
Start with collaborative filtering or content-based filtering based on user preferences, ratings, and metadata like cuisine and price. Explore hybrid systems for better personalization. Ensure cold-start issues and scalability are addressed. Restaurant recommendations simulate local recommendation systems used in delivery apps.
Tips: Mention strategies for new users/restaurants (cold-start). Highlight personalization beyond ratings, such as time of day or group size. Compare online vs. offline recommendation updates.
Design a recommendation algorithm for Netflix’s type-ahead search
Combine autocomplete algorithms with a personalized ranking model. Prioritize response time using trie-based lookup and update ranking dynamically based on session history. Use click-through and search success metrics to train relevance models. This mirrors high-performance, real-time system challenges in media platforms.
Tips: Stress latency requirements (<100ms). Mention fallback strategies when no results are found. Discuss ranking signals like popularity vs. personalization.
Create a recommendation engine for rental listings
Segment the problem into listing ranking, personalization, and real-time updates based on user behavior. Use embeddings for location, price, and property features to match preferences. Consider dynamic factors like availability and seasonal demand. Real-estate marketplaces commonly use such architecture.
Tips: Highlight the importance of freshness (new listings). Discuss balancing long-tail vs. popular properties. Think about fairness—don’t overexpose only top listings.
Design a podcast search engine with transcript-based queries
Ingest podcast transcripts and apply NLP to extract topics and named entities. Implement vector-based search using sentence embeddings and retrieval models. Combine metadata and episode popularity for relevance scoring. This problem demonstrates practical use of semantic search and audio processing.
Tips: Discuss transcript noise/ASR errors. Mention hybrid retrieval (sparse + dense). Talk about evaluating relevance with metrics like NDCG or recall@k.
Design a machine learning system to generate Spotify’s Discover Weekly
Blend collaborative filtering with content and behavioral models to rank unseen tracks. Use batch pipelines to refresh models weekly and optimize for playlist diversity. A/B test different generation algorithms to evaluate listener retention. This is a classic example of personalized ML product design at scale.
Tips: Stress diversity vs. personalization trade-offs. Discuss offline evaluation (MAP, precision@k) vs. online testing. Mention user feedback loops to prevent echo chambers.
Summarize how to create a machine learning model that labels raw input data automatically
Frame it as a weak supervision or semi-supervised learning problem, using heuristics, distant supervision, or pretrained models to auto-label. Combine multiple label sources with a noise-aware model like Snorkel. Ensure consistent validation to prevent error amplification. This system reduces manual annotation costs in high-volume pipelines.
Tips: Explain label model + generative model separation. Talk about label quality metrics. Mention active learning to refine labels over time.
Design an end-to-end real-time news-topic classifier
Start with how you would collect and stream news articles or transcripts into an ingestion pipeline. Explain preprocessing for language detection, tokenization, and embedding generation. Then describe a scalable serving layer (e.g., Kafka + online feature store + low-latency model API) and how you would structure A/B rollout for new models. This question highlights your ability to balance accuracy with speed in production ML.
Tips: Talk about throughput and latency SLAs. Include monitoring for drift and breaking news topics. Suggest shadow testing before rollout.
Behavioral / Culture‑Fit Questions
Behavioral rounds at Thomson Reuters often center on ownership, data ethics, and collaborative problem-solving. You may be asked to describe a time you defended a model’s explainability to stakeholders or how you managed trade-offs between experimentation speed and data quality. These questions aim to uncover how you align with the company’s Trust Principles, including transparency, independence, and a strong user-first mindset. Interviewers are particularly interested in how you communicate with non-technical teams, resolve ambiguity, and learn from past failures.
Tell me about a time you had to defend model explainability
Share a situation where stakeholders were skeptical about a model’s predictions. Describe how you communicated the reasoning behind the model’s outputs, perhaps using SHAP values, LIME, or decision tree visualizations. Emphasize how you adapted your explanation to your audience’s technical level. This question evaluates your ability to advocate for responsible AI in business settings.
Example:
“I would model this as a binary classification problem where the label indicates whether engagement drops within the next 60 seconds. Features could include skip rate, pause frequency, and session duration. I’d start with logistic regression for interpretability, then scale up to gradient boosting for performance, while running A/B tests to measure both ad revenue and churn impact.”
How do you balance experimentation speed with data accuracy?
Start by acknowledging the trade-off between speed and rigor, especially in agile environments. Talk about your prioritization strategy—e.g., running quick A/B tests to filter ideas before deep dives. Share how you set guardrails to ensure data quality doesn’t suffer under speed. This shows your understanding of both engineering efficiency and statistical validity.
Example:
”I’d begin with collaborative filtering using user–restaurant ratings and complement it with content-based features like cuisine and location. To solve cold-start for new restaurants, I’d use embeddings based on metadata. I’d also run online updates with implicit feedback such as clicks or time-on-page to keep recommendations fresh.”
Describe a time when you had to collaborate closely with product or engineering teams
Explain how you coordinated across roles to translate business needs into a deployable ML solution. Highlight communication of metrics, iteration cycles, or how you handled differing priorities. Emphasize empathy and structured collaboration. This reveals how well you operate in cross-functional environments.
Example:
“I’d build a trie-based prefix search for speed and then layer on a ranking model that blends global popularity, personalization from user history, and contextual session signals. To meet latency SLAs, I’d pre-compute embeddings offline and cache frequent queries. Evaluation would use click-through and search-to-play conversion.”
How do you respond when your model underperforms in production?
Mention your first step: monitoring and alerting systems to detect drift or performance drops. Describe how you isolate issues through retraining, feature analysis, or data freshness checks. Talk about stakeholder updates and recovery timelines. This speaks to your operational maturity and resilience under pressure.
Example:
“I’d represent listings with embeddings that capture price, location, and features, then rank them with a learning-to-rank model. To handle freshness, I’d boost new listings slightly. The system would log user interactions for personalization and use real-time updates so users see current availability. Evaluation would balance CTR with fairness metrics.”
Tell me about a time you learned from a failed experiment or deployment
Frame the failure briefly—what the hypothesis or deployment was and why it missed. Then shift to what you discovered and how you applied that learning to a better solution. Include technical fixes and process improvements. This showcases humility, adaptability, and a growth mindset.
Example:
“I’d use a hybrid search approach—BM25 for keyword matching and sentence embeddings for semantic similarity. Preprocessing would include cleaning transcripts and handling ASR noise. Ranking would combine semantic relevance with metadata like episode popularity. Evaluation would rely on NDCG@10 and manual human checks for quality.”
How to Prepare for a Machine Learning Engineer Role at Thomson Reuters
Success in the Thomson Reuters machine learning engineer interview requires more than just strong coding skills—it demands the ability to build scalable ML systems, communicate clearly with cross-functional teams, and uphold the company’s values around data integrity and transparency. Preparation should focus equally on hands-on practice, theoretical grounding, and structured storytelling. Below are key areas to concentrate on, based on candidate feedback and the structure of the Thomson Reuters machine learning engineer assessment.
Replicate the Assessment Environment
To prepare for the Thomson Reuters machine learning engineer assessment, simulate the test setting with timed practice on platforms like Kaggle, HackerRank, or LeetCode (ML-tagged problems). Prioritize logic and correctness first, but work toward clean, complete solutions under time pressure. You’ll be expected to write production-ready Python code that’s both efficient and easy to understand.
Aim for structured thinking, clear assumptions, and defensive coding—not just speed. Many successful candidates mention that explaining their logic well mattered more than solving every problem perfectly.
Tips:
- Set a timer and practice solving 2–3 problems in one sitting to mimic test conditions.
- Focus on writing readable code with comments and edge-case handling.
- Review common Python DS/Algo patterns (dict operations, sliding window, streaming).
- Practice explaining your code aloud—it’s good prep for later interviews.
Review ML Theory
Interviewers often probe your understanding of fundamental ML concepts. Make sure you can clearly explain the trade-offs in model complexity, interpret precision-recall vs. F1 score, and reason through why a model might underperform on edge cases or skewed datasets. Knowing when and why to apply certain algorithms matters more than memorizing APIs. Focus on classic topics like:
- Vectorized data processing with Pandas and NumPy
- Probability and statistics (especially distributions and Bayes’ rule)
- Feature engineering under noisy or incomplete data
- Basic model implementation (logistic regression, decision trees, k-means)
- Evaluation techniques (ROC, AUC, precision-recall on imbalanced data)
Tips:
- For a structured way to cover these essentials, check out our machine learning interview learning path.
- Practice explaining trade-offs in plain language—interviewers often value clarity over jargon.
- Use small, concrete examples when describing metrics (e.g., a medical test for precision vs. recall).
- Revisit probability basics like conditional probability and Bayes’ rule—they come up frequently.
- Don’t just learn models—know their assumptions, strengths, and failure cases.
Mock Design Interviews
System design is a core part of the interview loop. Practice by selecting a prompt (e.g., “design a real-time fraud detection system”) and whiteboarding or talking through the architecture aloud—ideally with a peer or mentor who can challenge your assumptions. Walk through each layer: data ingestion, processing, feature storage, model training and retraining, serving infrastructure, and monitoring. Focus especially on low-latency use cases like streaming pipelines and real-time prediction services, which are core to Reuters’ news and risk products.
To evaluate your skills, ask:
- Did you clearly define the problem and its constraints?
- Did you justify trade-offs in model complexity, storage, and latency?
- Did you account for data drift, model retraining, and scaling strategies?
Use feedback or self-review to refine your approach. Tools like Excalidraw or Miro can help you visually map out architectures, and reviewing past ML system design questions from interviews can reveal recurring patterns. Strong candidates show structured thinking, awareness of production challenges, and the ability to communicate design decisions clearly under ambiguity.
Tips:
- Practice “think-aloud” explanations to make your reasoning transparent.
- Use structured frameworks (data flow → model pipeline → serving → monitoring).
- Review common ML system patterns (batch vs streaming, feature store, A/B testing).
- Practice with peers—simulating pushback will prepare you for real interview dynamics.
STAR Stories
Prepare 3–5 STAR-format stories (Situation, Task, Action, Result) that highlight your integrity in model design, handling ambiguous requirements, and collaborating with global teams or stakeholders. Strong examples often come from:
- Experiences where you prioritized fairness, explainability, or transparency in your ML models—especially when facing pressure to ship quickly
- Moments where you navigated cross-cultural communication challenges, such as working with offshore teams, translating business requirements across time zones, or resolving conflict in a diverse group
- Projects in regulated industries (finance, healthcare, legal) where you had to consider compliance, auditability, or user trust
- Times when you spoke up or challenged assumptions to ensure data quality or model integrity
Since Thomson Reuters operates across legal, financial, and media domains, these types of experiences signal your alignment with the company’s Trust Principles—emphasizing independence, objectivity, and ethical responsibility. Even if you come from academia or a different sector, any story where you made thoughtful, principle-driven decisions in ambiguous situations can resonate well with their culture.
Tips:
- Prepare at least one STAR story for each theme: fairness, ambiguity, compliance, collaboration.
- Keep answers concise—2 minutes per story is a good benchmark.
- Practice weaving in metrics or outcomes (e.g., “reduced false positives by 15%”).
- Rehearse transitions like, “One example that comes to mind is…” to sound natural.
Stay Current
Familiarizing yourself with Thomson Reuters’ recent machine learning initiatives—such as legal NLP, multilingual news classification, or AI-driven financial analysis—can give you a valuable edge. Reading their research blogs, open-source repositories, and product case studies helps you understand the domain constraints, ethical considerations, and data scale they work with.
During the interview, you can blend this context into your answers naturally. For example, if you’re asked to design a text classification system, you might mention, “Given that this could be used in a legal product like Westlaw, I’d prioritize explainability and model versioning due to compliance risks.”
You can also refer to their past ML papers or tools when discussing your own projects, or ask questions that reflect your domain awareness—such as how they evaluate fairness in multilingual data. This kind of thoughtful integration shows not only technical readiness, but also genuine alignment with the company’s mission and product reality.
Tips:
- Follow Thomson Reuters Labs for research updates and AI initiatives.
- Browse their official AI blog for case studies.
- Review relevant open-source contributions on GitHub.
- Prepare one or two “informed questions” to ask interviewers, tying their recent initiatives back to your skills.
FAQs
What Is the Average Salary for a Machine Learning Engineer at Thomson Reuters?
The average machine learning engineer salary at Thomson Reuters typically falls between $110,000 and $150,000 USD annually, depending on experience level and location. Senior-level candidates or those working in high-cost regions like New York or Toronto may see offers on the higher end of that range. Compensation packages may also include performance bonuses and equity components for select roles, particularly in enterprise AI or platform teams. (Glassdoor)
- Entry / Early ML Engineer (0-2 yrs): ~$122,000–$145,000 USD/year total compensation.
- Mid-level ML Engineer (~3-5 yrs): Around $145,000 USD median total compensation.
- Higher / Senior ML Engineer: Could reach ~$170,000 or more, depending on bonus and location.
Are There Open ML Engineer Roles at Thomson Reuters on Interview Query?
Yes! New listings for machine learning engineer positions at Thomson Reuters are frequently updated on the Interview Query job board. You can also visit the official Thomson Reuters Careers page for a broader look at open roles in AI, engineering, and data science. Be sure to sign up for job alerts or the Interview Query newsletter to stay informed about new openings.
Conclusion
Preparing for a machine learning role at Thomson Reuters requires more than technical know-how—it demands clear thinking, ethical awareness, and a strong grasp of real-world ML applications. By deliberately practicing each part of the Thomson Reuters machine learning engineer assessment and understanding the nuances of the interview loop, you’ll significantly boost your chances of standing out as a well-rounded candidate.
For further preparation, dive into our machine learning question banks, explore our other Thomson Reuters interview guides by role, and mock interview with other peers to simulate the real experience and get expert feedback.
Thomson Reuters Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Machine Learning | Medium | |
Imagine you are asked to build a machine learning model to decide new loan approvals for a financial firm. You ask the data department in the company for a subset of data to get started working on the problem. The data includes different features about applicants such as age, occupation, zip code, height, number of children, favorite color, etc. You decide to build multiple machine learning models to test out different ideas before settling on the best one. How would you explain the bias-variance tradeoff with regards to building and choosing a model to use? | ||
Machine Learning | Medium | |
AI & Agentic Systems | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences