
Thomson Reuters Data Engineer Interview: Process, Questions & Salary Guide


Introduction
Thomson Reuters is a global content-and-technology leader, supplying trusted information to legal, financial, media, and tax professionals. Lately the company has been pushing hard into AI-driven automation and intelligent workflow solutions. For example, it recently acquired Additive, a startup that uses AI to automate tax document processing, and launched CoCounsel Legal, AI-enhanced Legal Tracker, and other “agentic AI” workflows to streamline tax, compliance, and legal work.
In that context, the data engineer role at Thomson Reuters is more important than ever: you’ll be designing and maintaining scalable pipelines for large volumes of structured & unstructured data covering financial markets, news feeds, documents, ensuring data integrity, enabling real-time processing, and supporting AI and analytics teams.
The market for data engineering remains strong — demand continues to grow, salaries are competitive, and more companies are seeking engineers who can work across cloud platforms, big-data tools, streaming frameworks, etc. According to a recent outlook, there are now over 150,000 data engineering professionals in North America and 20,000+ new hires in the past year alone.
This blog is going to walk you through what the data engineer role involves at Thomson Reuters: we’ll cover day-to-day responsibilities, what culture is like there, plus a detailed look at the interview process. You’ll also get concrete tips so you can succeed if you’re going after this role. Keep reading to find out how to position yourself and shine.
Role Overview & Culture
Data engineers at Thomson Reuters don’t just manage pipelines—they safeguard the flow of trusted, real-time information that fuels legal, financial, and media products worldwide. Beyond the technical challenges, the role offers exposure to a mission-driven culture and the chance to work at the intersection of global news, finance, and cutting-edge AI initiatives.
Day-to-Day Responsibilities
- Build and maintain large-scale ETL and ELT pipelines for structured and unstructured data.
- Optimize workflows for speed, accuracy, and cost efficiency, especially for real-time news and financial feeds.
- Ensure data quality, governance, and compliance with strict regulatory standards.
- Support analytics, AI, and product teams by enabling access to clean, well-structured data.
Culture
- Strong alignment with the Trust Principles: accuracy, independence, and integrity.
- Innovation-focused, with a push into AI and cloud-based platforms.
- Emphasis on responsible data practices and ethical technology use.
Team Setting
- Multicultural and cross-border teams spanning North America, Europe, and Asia.
- Collaboration between data engineers, software developers, and data scientists.
- Agile environment with continuous integration and delivery practices.
Expectations
- Ability to handle high-volume, real-time data streams without compromising reliability.
- Strong knowledge of distributed systems, cloud platforms, and big-data frameworks.
- Proactive communication across teams and willingness to mentor junior colleagues.
Unique Perks
- Hybrid work flexibility and wellness stipends.
- Competitive salary with bonuses and Restricted Stock Units (RSUs).
- Exposure to global news and financial data systems not found in most tech companies.
Why This Role at Thomson Reuters?
Choosing a data engineer role at Thomson Reuters means joining a company where data is not just a resource—it’s the product. Engineers have the rare opportunity to work with petabytes of multilingual, real-time news and financial data, building systems that power insights for governments, corporations, and legal institutions worldwide.
Beyond the technical scale, Thomson Reuters is known for its strong internal mobility, allowing employees to pivot across roles, teams, and even continents as their careers evolve. The company’s hybrid work policy promotes flexibility and work-life balance, while competitive compensation is bolstered by generous equity packages and performance-based incentives. Let’s walk through the interview process so you can land the role!
What Is the Thomson Reuters Data Engineer Interview Process?
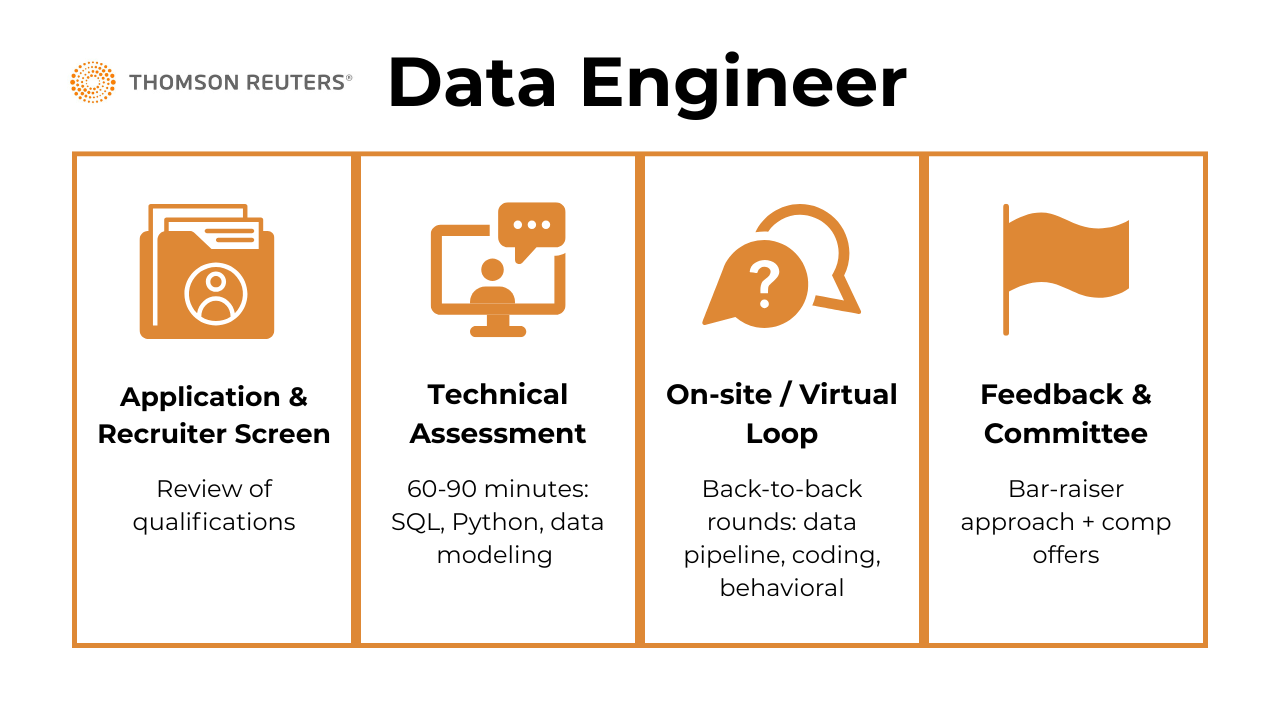
The interview process for a data engineer at Thomson Reuters is thoughtfully designed to assess both your technical depth and your ability to operate in a collaborative, data-driven environment. It typically spans multiple rounds and can take between two to four weeks from initial contact to final offer, depending on the role level and scheduling. The structure is consistent across teams, with slight variations based on whether you’re applying for a junior, mid-level, or senior position.
Application & Recruiter Screen
Candidates begin by submitting an application that highlights relevant experience—especially working with large-scale, production-grade data systems. The recruiter screen aims to validate alignment with the role’s scope, tech stack familiarity (like Spark, SQL, Python, Airflow, cloud platforms), and team needs.
Tips:
- Be clear on fundamentals: Expect straightforward questions about ETL/ELT processes, distributed computing, and cloud environments—so review your basics.
- Emphasize impact: Show how your work improved performance, reduced costs, or enabled downstream analytics rather than just listing technologies used.
- Know the company focus: Be ready to connect your skills to Thomson Reuters’ mission of delivering timely, trusted information, especially in financial and legal contexts.
Technical Assessment
The technical assessment at Thomson Reuters is designed to mirror the day-to-day challenges a data engineer might face—evaluating not only coding skills but also data intuition and architectural thinking. Candidates typically receive a time-boxed virtual assessment, often completed within 60 to 90 minutes, covering three major components: SQL, Python, and data modeling.
SQL
The SQL portion includes complex queries that go beyond simple SELECT statements. You might be asked to rank the top-performing entities by category, calculate rolling averages using window functions, or join large datasets efficiently. These problems test both correctness and performance, often with follow-up prompts asking how you would optimize your queries for speed or scalability.
Tips:
- Practice advanced queries using
ROW_NUMBER(),RANK(), andWINDOWfunctions. - Focus on query optimization—think indexing, avoiding unnecessary subqueries, and using CTEs wisely.
- Time yourself solving practice problems to simulate real assessment pressure.
- Practice advanced queries using
Python
The Python section assesses your ability to write clean, functional code for data manipulation. Typical tasks involve parsing structured files like CSVs or JSONs, cleaning messy fields, implementing deduplication logic, or writing scripts to transform logs into summary metrics. Efficient use of libraries like
pandasis encouraged, but candidates should also demonstrate strong understanding of core data structures and I/O handling.Tips:
- Refresh fundamentals like lists, dictionaries, and sets, since efficient data structures often matter more than heavy libraries.
- Practice cleaning messy data—write scripts that handle nulls, inconsistent formats, and duplicates.
- Show good coding habits: modular functions, meaningful variable names, and handling edge cases.
Data Modeling & Pipeline Design
A third key component—sometimes included directly in the assessment or reserved for the on-site interview—is a data modeling or pipeline design prompt. Here, you might be asked to design a system that ingests financial data streams, stores them reliably for historical analysis, and surfaces daily aggregated views to downstream consumers. The goal is to evaluate your familiarity with modern data architecture, such as separating raw, staging, and serving layers, using tools like Kafka, Spark, and cloud data warehouses like BigQuery or Redshift. You’ll be expected to justify decisions around file formats, partitioning strategies, schema evolution, and how you’d monitor and test the pipeline.
Tips:
- Study common design patterns like Lambda and Kappa architectures.
- Be ready to explain tradeoffs (batch vs. streaming, JSON vs. Parquet, lake vs. warehouse).
- Don’t just describe tools—explain why you’d choose them and how you’d monitor/scale them.
- Sketch out layers (raw → staging → serving) when thinking aloud; clarity counts.
Altogether, this stage tests whether you can write production-quality code, reason about systems at scale, and apply engineering judgment to ambiguous problems—all crucial traits for succeeding as a data engineer at Thomson Reuters.
On‑site / Virtual Loop
The on-site or virtual loop at Thomson Reuters is the most intensive stage of the hiring process, usually consisting of three to four back-to-back rounds. Each round probes a different aspect of what it takes to succeed as a data engineer at scale.
Data Pipeline Design Interview
One core component is the data pipeline design interview, where you’re presented with an open-ended business scenario—such as building a system to process global news alerts or market data in real time—and asked to walk through a complete end-to-end architecture. Interviewers expect you to talk through data ingestion methods (e.g., Kafka, APIs), transformations using tools like Spark or Python, storage decisions (e.g., data lake vs. warehouse), and how you’d serve the processed data to downstream analytics or dashboards. You’ll also be expected to touch on schema versioning, partitioning strategies, batch vs. streaming tradeoffs, and how you would ensure data consistency and observability with logging, alerting, and testing frameworks.
Tips:
- Practice sketching out data pipelines quickly, either on paper or using a whiteboarding tool.
- Be ready to justify tradeoffs: why streaming over batch, why Parquet over JSON, why warehouse over lake.
- Emphasize monitoring and testing; showing you think about reliability often scores extra points.
Live Coding (Python & SQL)
Another round typically involves live coding, conducted in a shared coding environment like CoderPad or Google Docs. Here, you’ll solve real-world data manipulation tasks using Python and SQL, often under time pressure. For example, you might be given a simulated log of user activity and asked to write a function that outputs session metrics or generates time-based aggregates. Emphasis is placed on writing clean, efficient, and readable code that can handle edge cases. You’ll also be encouraged to explain your reasoning as you go, demonstrating not just correctness, but thoughtfulness and communication—a crucial trait for engineers working across cross-functional teams.
Tips:
- Brush up on handling edge cases like nulls, duplicates, time zones in both SQL and Python.
- Narrate your approach clearly—interviewers want to hear your thought process, not just see the output.
Behavioral & Culture-Fit Interview
Finally, the loop concludes with a behavioral and culture-fit interview, where interviewers assess your collaboration style, communication skills, and how you’ve handled challenges in past roles. Questions often explore your experiences working with ambiguous data requirements, responding to incidents or outages, or navigating disagreements with stakeholders about pipeline design or data priorities. The bar is high—especially for mid-to-senior level roles—and interviewers are looking for candidates who can demonstrate ownership, resilience, and a proactive mindset when it comes to quality and innovation. While technical excellence is key, candidates who show curiosity, adaptability, and alignment with Thomson Reuters’ Trust Principles tend to stand out.
Tips:
- Prepare 3–4 STAR stories that highlight ownership, adaptability, and collaboration.
- Tie your answers back to Thomson Reuters’ values of trust, accuracy, and integrity.
- Be honest about challenges you’ve faced, but emphasize what you learned and how you grew.
Feedback & Committee
After all interviews are complete, the interviewers submit structured feedback—usually within 24 hours. Thomson Reuters uses a bar-raiser model, meaning at least one interviewer ensures hiring standards remain consistently high. Comp offers, including the Thomson Reuters data engineer salary bands, are finalised only after committee sign-off.
Behind the Scenes
The hiring committee at Thomson Reuters plays a key role in maintaining quality and fairness. Interviewers independently submit feedback before seeing others’ notes, helping eliminate bias. One interviewer often acts as a “bar-raiser” to ensure the candidate meets or exceeds the company-wide performance bar.
Differences by Level
Junior candidates are evaluated primarily on correctness, efficiency, and collaboration during coding rounds. For senior roles, there’s greater emphasis on system architecture, observability practices, and the ability to lead project scoping across teams. Expect deeper questioning around data modeling decisions, scalability trade-offs, and operational excellence.
Now that you know the flow, here’s what they’ll ask.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Thomson Reuters?
What Questions Are Asked in a Thomson Reuters Data Engineer Interview?
Thomson Reuters’ interview process tests a broad range of competencies—technical depth in SQL and Python, systems thinking in pipeline design, and alignment with the company’s collaborative and trust-based culture. Below is a breakdown of typical questions across each category, including why they’re asked and how to approach them effectively.
Coding / Technical Questions
This section evaluates your ability to extract insights, manipulate data, and write maintainable code. Expect questions centered on joins, window functions, aggregations, and real-world data transformations in SQL or Python.
- Write a SQL query to return the top 3 customers by transaction value per country.
- Why they ask it: To test your grasp of
RANK()orROW_NUMBER()and ability to filter results within partitions. - How to answer: Use a CTE to rank each customer within their country using
ROW_NUMBER(), then filter where row number ≤ 3. - Example Answer:
WITH ranked_customers AS (
SELECT customer_id, country, total_spent,
ROW_NUMBER() OVER (PARTITION BY country ORDER BY total_spent DESC) AS rank
FROM transactions
)
SELECT * FROM ranked_customers WHERE rank <= 3;
2. Given a CSV file of clickstream logs, parse and return session-level metrics in Python.
Why they ask it: To evaluate your ability to clean and group event-level data into user sessions.
How to answer: Use
pandasto read the CSV, sort by timestamp, and apply session window logic (e.g., 30-min inactivity).Example Answer:
Use
groupbyand a timedelta comparison to segment sessions, then aggregate metrics like session length or click count.
3. Write a SQL query to calculate the rolling 7-day average of daily sales.
- Why they ask it: To test time-series manipulation and use of window functions.
- How to answer: Apply
AVG(sales)over a 6-dayROWS BETWEENwindow with ordering by date. - Example Answer:
SELECT order_date,
AVG(sales) OVER (ORDER BY order_date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS rolling_avg
FROM orders;
4. Remove duplicate user records in Python based on email, keeping the latest timestamp.
- Why they ask it: To assess data deduplication logic, often needed in ingestion pipelines.
- How to answer: Use
groupby('email')andidxmax()to filter to the most recent entry. - Example Answer:
latest_records = df.loc[df.groupby('email')['timestamp'].idxmax()]
5 . Write a function to return the top N frequent words in a text corpus
Use a dictionary or collections.Counter to count word frequencies. Then sort and return the top n items. This problem tests core skills in text parsing and frequency-based filtering. Relevant to log processing, search indexing, or NLP pre-processing tasks.
Tips:
- Normalize case (e.g., lowercase) and strip punctuation for consistency.
- Consider ties—decide what happens if multiple words share the same frequency.
- Optimize for large inputs by using a heap (
heapq.nlargest) instead of sorting
6 . Write a function to remove stop words from a sentence
Split the sentence into tokens and filter based on a predefined stop word list. Preserve word order in the output. This checks your handling of basic token filtering in Python. A common preprocessing step in any data pipeline involving text.
Tips:
- Use a
setfor stop words to get O(1) lookup time. - Be mindful of case sensitivity; align your stop word list to match your tokenization approach.
- Preserve punctuation or not? Clarify assumptions if unspecified.
7 . Write a query to retrieve the latest salary for each employee given an ETL error
Use ROW_NUMBER() or MAX(timestamp) in a subquery to isolate the latest salary entries. Ensure you’re selecting by employee ID and filtering rows accordingly. This tests your ability to deal with real-world data inconsistencies. Perfect for showcasing how to correct flawed batch loads in a production environment.
Tips:
- Practice both approaches (
ROW_NUMBER()window function andMAX()subquery) since interviewers may prefer one over the other. - Watch out for duplicate timestamps—decide how to break ties.
- Always alias your subquery/CTE and write clean, readable SQL for maintainability.
System / Pipeline Design Questions
Design questions test your ability to handle scale, reliability, and trade-offs in data infrastructure. You’re often presented with high-volume ingestion or transformation scenarios.
1 . Design an S3‑to‑Redshift ingestion flow for 10 TB/day
Begin with S3 as the raw data landing zone, partitioned by date or source to enable parallel processing. Use AWS Glue or Spark to transform and validate the data, saving it in Parquet format to optimize for columnar queries. Load the processed data into Redshift using COPY with manifest files to ensure transactional integrity. Be ready to explain trade-offs between latency (e.g., batch vs. streaming), cost (e.g., managed Glue vs. self-hosted EMR), and auditability.
Tips:
- Emphasize partitioning and compression (Parquet, ORC) to reduce costs and query times.
- Be ready to compare Redshift Spectrum vs. COPY loads.
- Always mention monitoring and alerting for failed loads at this scale.
2 . Design a pipeline to process real-time financial transactions with schema drift
Use Kafka for ingestion to decouple producers and consumers. Apply schema validation and versioning at the processing layer using tools like Schema Registry or Protobuf. Store raw and clean versions in cloud storage (e.g., S3) and serve analytics via Redshift or BigQuery. This design ensures resilience to evolving data and supports Thomson Reuters’ emphasis on data accuracy and lineage.
Tips:
- Highlight the importance of schema evolution strategies (backward vs. forward compatibility).
- Mention data lineage tracking for audits.
- Discuss failover plans if schema changes unexpectedly break downstream jobs.
3 . Build a fault-tolerant ETL pipeline for global news ingestion
Start with distributed ingestion via Kafka from regional APIs or RSS feeds. Introduce retries and DLQs (dead letter queues) for malformed events. Use Airflow to orchestrate transformations and validate multilingual content using language-detection libraries. This question evaluates how you design for robustness and timeliness in a real-world, globally distributed data environment.
Tips:
- Emphasize retries + DLQs to show you anticipate imperfect data.
- Mention latency SLAs and how you’d measure “timeliness.”
- Highlight monitoring dashboards for error rates by region/source.
4 . Design a data lake architecture that supports legal document versioning
Use a layered approach: raw (immutable), staging (validated), and serving (normalized). Implement object versioning in S3 and maintain metadata tracking in a catalog (e.g., Glue Data Catalog). Allow downstream consumers to query historical versions or latest snapshots. Expect to justify how this architecture supports regulatory requirements and Thomson Reuters’ trust-first mission.
Tips:
- Always tie back to compliance and auditability—legal data has strict requirements.
- Explain how metadata catalogs and governance tools (Lake Formation, Apache Atlas) help.
- Bring up cost-control strategies (e.g., lifecycle policies for archived versions).
5 . Build a scalable pipeline to calculate customer churn from activity logs
Ingest logs daily, apply sessionization in Spark, and aggregate churn features (e.g., last seen date, activity gaps). Feed data into a warehouse and expose metrics via dashboards. Discuss how you’d monitor for gaps in logging and automate anomaly detection. This tests your ability to deliver trustworthy metrics with operational visibility.
Tips:
- Be explicit about defining churn—show you think carefully about metrics.
- Mention feature store options for feeding ML models.
- Cover observability: data quality checks, alerting for missing logs, anomaly detection.
Behavioral or Culture‑Fit Questions
These assess how well you align with Thomson Reuters’ values: trust, transparency, and global collaboration. Data engineers here often work across continents and business units, so integrity and communication are key. The best way to approach them is by using the STAR method (Situation, Task, Action, Result), which helps you structure responses with clear context, actions you took, and the impact you delivered.
1 . Tell me about a time you caught a critical data error before it impacted stakeholders
Walk through a situation where you noticed a data issue—perhaps due to schema changes, misconfigured jobs, or unexpected null values—and how you resolved it. Emphasize how you validated your suspicion, communicated it clearly to affected teams, and implemented a long-term fix. This shows your ownership and focus on data integrity, which is essential at Thomson Reuters where trusted data drives legal and financial decisions.
Example:
“In my previous role, I noticed that one of our ETL jobs had started producing unusually high volumes of null values after a schema update in the source system. I verified the issue by checking downstream tables and quickly confirmed that dashboards pulling from this data were showing incomplete results. I alerted the product team, paused the affected pipeline, and implemented a validation script to catch similar anomalies in the future. By acting quickly, we avoided sending flawed reports to clients and strengthened our monitoring process.”
2 . Describe how you’ve supported or coordinated a pipeline handoff across global teams
Share an example where you worked on a data pipeline or ETL process that required collaboration across different time zones. Highlight tools or practices you used (e.g., asynchronous documentation, dashboards, or code reviews) to keep progress transparent. Thomson Reuters relies heavily on cross-border teams, so this shows your adaptability and ability to engineer with global coordination in mind.
Example:
“While working on a data ingestion pipeline that fed into a shared warehouse, our U.S. team was responsible for building transformations while the Asia team handled reporting. Because of the time zone gap, I created detailed documentation in Confluence, set up Airflow dashboards for visibility, and left asynchronous updates in Slack. We also agreed on a one-hour overlap meeting each week. This approach ensured smooth handoffs, fewer miscommunications, and on-time delivery despite the geographic spread.”
3 . Give an example of a time you pushed back on a fast-moving request to protect data quality
Talk about a situation where a product or business team wanted a quick data solution, but you identified quality or validation concerns. Explain how you diplomatically communicated the risks, suggested an alternate timeline, or implemented safeguards. This showcases integrity and judgment—key to the company’s trust-first culture.
Example:
“A product manager once asked me to release a quick customer metrics feed for a pilot project without full validation. After reviewing the request, I explained that skipping validation risked misreporting key metrics. I suggested a phased approach—delivering a smaller verified dataset first, then expanding once we had confidence in the pipeline. The manager agreed, and the pilot launched successfully with trusted data, reinforcing the importance of balancing speed with accuracy.”
4 . Tell me about a time you made a data decision with limited information
Focus on how you assessed the risks, consulted available logs or proxies, and documented assumptions transparently. Mention how you followed up to improve the pipeline once more data was available. This illustrates how you handle ambiguity responsibly, a common challenge in Thomson Reuters’ dynamic, information-rich environment.
Example:
“During an outage, I was tasked with estimating churn metrics even though several log sources were unavailable. I relied on partial data from our mobile app logs, used proxy measures such as session counts, and documented all assumptions. I clearly flagged the estimate as interim and followed up by re-running the analysis once the full logs were restored. This allowed the business to move forward with a reasonable approximation while maintaining transparency around limitations.”
5 . Describe a moment when you improved a legacy data process
Choose an example where you refactored an unreliable job, standardized naming conventions, or added monitoring to a critical but brittle pipeline. Emphasize the impact—fewer failures, faster debugging, more trust from downstream users. This speaks to your initiative and long-term thinking, both highly valued in Thomson Reuters’ data teams.
Example:
“I inherited a nightly ETL job that frequently failed due to inconsistent file naming from an external vendor. To fix it, I refactored the script to dynamically detect file patterns, added retry logic, and implemented alerting through Airflow. The job went from failing two to three times a week to running reliably for months. This not only reduced manual intervention but also gave downstream analysts more confidence in the data.”
How to Prepare for a Data Engineer Role at Thomson Reuters
Landing a data engineer role at Thomson Reuters requires more than just technical fluency—it calls for thoughtful communication, system-level thinking, and a clear understanding of the company’s values. Here’s how to prepare strategically.
Study the Role & Culture
Start by familiarizing yourself with Thomson Reuters’ Trust Principles, which emphasize independence, integrity, and accuracy—not just in journalism, but in every system that delivers or processes data. Data engineers here play a foundational role in ensuring the correctness and lineage of high-stakes information, whether for financial clients or legal researchers. Understand that your work is not just about performance metrics—it’s about enabling reliable decisions through responsible data design. Reviewing recent product case studies and platform architecture blogs can help you internalize this mindset.
Tips:
- Skim Thomson Reuters’ blog weekly to connect your prep with current company priorities.
- Practice explaining one of your past projects in terms of data trust (not just speed or scale).
- Memorize the Trust Principles and be ready to cite how your work aligns with them in answers.
Practice Common Question Types
Expect most of your interview time to center on SQL and Python tasks (around 50%), reflecting Thomson Reuters’ emphasis on data integrity and reliable, repeatable transformation logic. These questions often simulate real-world scenarios like log parsing, deduplication, and time-window aggregations—all of which are critical in systems powering real-time financial and legal insights. Be sure to practice with multi-step SQL challenges that use ROW_NUMBER(), PARTITION BY, or rolling average calculations. For Python, focus on data wrangling using pandas, file parsing, and writing robust functions that handle malformed or edge-case inputs—since ensuring clean and trustworthy pipelines is central to their mission.
Another 30% of the interview will test your ability to design scalable and maintainable pipelines, especially for batch ingestion, stream processing, and serving analytics-ready datasets. Here, Thomson Reuters is looking for engineers who can weigh latency vs. traceability, explain why certain cloud tools were chosen (e.g., Kafka, Glue, Redshift), and articulate how they’d enforce schema stability or data versioning. To prepare, sketch out ingestion flows with clear raw-to-staging-to-serving layers, and practice diagramming pipelines out loud, even on virtual whiteboards. Focus on making your design defensible and auditable, not just fast—this aligns with the company’s emphasis on data stewardship and compliance.
The final 20% is behavioral, where you’ll be evaluated on ownership, cross-timezone collaboration, and how you handle ambiguity in stakeholder requests or shifting requirements. Practice answers where you caught a critical data bug, pushed back on risky design choices, or worked with teammates across regions to resolve latency or data quality issues. Thomson Reuters values those who show integrity in communication, clarity in escalation, and the courage to prioritize data correctness over convenience.
Tips:
- Use Interview Query or LeetCode to drill SQL problems that involve window functions and joins.
- Practice Python challenges in a Jupyter notebook so you get used to debugging quickly.
- For design prep, record yourself explaining a pipeline aloud—this builds confidence in live interviews.
- Keep 3–4 behavioral STAR stories ready, focused on data quality, collaboration, and incident response.
Think Out Loud & Clarify
During interviews—especially in pipeline or system design rounds—it’s essential that you don’t just write code or draw diagrams silently, but actively narrate your thinking. Interviewers are looking for engineers who can not only execute but also communicate how they ensure accuracy, resilience, and ethical data usage. For instance, when designing a pipeline, explain why you chose S3 over HDFS (e.g., lower operational overhead, built-in lifecycle management), or why you opted to denormalize a schema (e.g., for analytical performance in Redshift) while acknowledging the trade-offs in write complexity or data duplication.
Be proactive in asking clarifying questions before diving into solutions—such as:
- “Are we optimizing for low latency or cost efficiency?”
- “Will this pipeline be consumed by regulatory teams or internal analysts?”
- “Do we expect late-arriving data or schema drift?”
These questions show maturity and demonstrate that you’re designing not in a vacuum, but in context of real data consumers and compliance constraints—a key trait for any data engineer at Thomson Reuters.
Tips:
- Practice whiteboarding while speaking; don’t wait until you finish writing to explain.
- Develop a mental checklist: ingestion → transformation → storage → serving → monitoring.
- Always state your assumptions if the prompt is ambiguous—interviewers will often guide you.
Brute Force, Then Optimize
If you’re stuck on a performance problem, start with a working brute-force solution. Once it runs, walk through how you’d optimize it—adding WHERE clauses early, applying DISTINCT intelligently, or introducing indexing and partitioning in the storage layer. In system design, explain how caching, late-arrival handling, or job parallelization might improve throughput. They’re looking for engineers who can get things done and scale them.
Tips:
- Don’t panic if your first approach isn’t perfect—interviewers care more about iteration.
- Label each optimization step explicitly (“First, I’d add indexing… Next, I’d partition…”).
- In SQL, test your optimizations on smaller sample data so you can explain trade-offs quickly.
- Remember: correctness comes first, optimization comes after.
Mock Interviews & Feedback
Finally, practice how you explain data architecture and trade-offs to people outside of engineering—like product managers or legal analysts. Use analogies if needed (e.g., “Think of Redshift like a warehouse optimized for fast shelf access”). Thomson Reuters values engineers who can bridge the gap between raw data and real business insight, so storytelling and stakeholder framing can make a huge difference.
FAQs
What Is the Average Salary for a Data Engineer at Thomson Reuters?
Average Base Salary
Average Total Compensation
The Thomson Reuters data engineer salary typically falls within a competitive range, especially when factoring in the company’s global footprint and the high-impact nature of its data infrastructure roles. For mid-level data engineers in the U.S., base salaries generally range from $110,000 to $135,000, with performance bonuses around 10–15% of base. Stock-based compensation (equity or RSUs) may add another $10,000 to $25,000, depending on level and tenure.
In major tech hubs like New York or Toronto, total compensation is often higher to reflect cost-of-living adjustments, while roles in regional offices may trend slightly lower. Senior-level engineers or those in leadership roles can expect total compensation to exceed $160,000 or more, especially when managing core data infrastructure projects. (Glassdoor)
Entry / Early-Mid Level Data Engineer (1–3 years experience)
~ $95,000–$140,000 total compensation (base + bonus) in the U.S.
Typical base salary around $90,000–$133,000, with bonuses or additional pay of several thousand dollars.
Mid-Level / Senior Data Engineer (4–7+ years)
~ $137,000–$183,000 total pay (includes base + bonus/other compensation) in the U.S.
Median base is ~$147,000; median additional pay ~$10,000–$15,000.
Lead Data Engineer / Higher Seniority / Leadership
~ $138,000–$190,000 total across base + bonus etc.
Base often in the ~$150,000 range, with additional pay (bonus, stock or other) bringing up the top‐end.
Are There Job Postings for Thomson Reuters Data Engineer Roles on Interview Query?
Yes! Explore open Thomson Reuters data engineering roles on the Interview Query job board, where you can filter by location, level, and domain. For the most up-to-date listings, also check the Thomson Reuters careers page. New roles are posted frequently, especially in key locations like Toronto, New York, Bangalore, and Minneapolis.
Conclusion
Mastering the technical prep, interview structure, and salary expectations outlined here will put you in a strong position to land your Thomson Reuters data engineer role. Whether you’re navigating SQL challenges, designing trustworthy pipelines, or demonstrating your alignment with the company’s Trust Principles, every step you take builds toward making a meaningful impact on real-world data systems.
Looking to explore adjacent paths? Check out our guides for the Software Engineer and Machine Learning Engineer roles at Thomson Reuters.
For your next step, signing up for our newsletter for weekly role-specific tips and attending mock interview session to sharpen your strategy and storytelling before the real thing.
Thomson Reuters Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Machine Learning | Medium | |
Imagine you are asked to build a machine learning model to decide new loan approvals for a financial firm. You ask the data department in the company for a subset of data to get started working on the problem. The data includes different features about applicants such as age, occupation, zip code, height, number of children, favorite color, etc. You decide to build multiple machine learning models to test out different ideas before settling on the best one. How would you explain the bias-variance tradeoff with regards to building and choosing a model to use? | ||
Machine Learning | Medium | |
Product Sense & Metrics | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences