
Rivian Data Scientist Interview Guide: Process, Questions & Salary


Introduction
A Rivian data scientist works on problems where models influence physical systems, not just dashboards. Rivian vehicles generate billions of telemetry data points every year, spanning battery performance, software behavior, manufacturing quality, and service operations. As Rivian scales production and delivers connected EVs at volume, data science plays a direct role in predicting failures, improving reliability, and reducing operational variability across the business.
This reality shapes the Rivian data scientist interview. Interviewers are not just evaluating machine learning knowledge or statistical theory. They want to see how you break down messy, real-world problems, choose modeling approaches that work under constraints, and communicate trade-offs clearly to engineers and operators. In this guide, we break down how the Rivian data scientist interview process works, what each stage is designed to assess, and how candidates should prepare for roles where data science decisions have tangible, real-world impact.
Rivian Data Scientist Interview Process
The Rivian data scientist interview process is typically multi-stage, spanning three to five or more rounds depending on the team and seniority. The process blends behavioral evaluation, technical screening, and case-style interviews that reflect Rivian’s applied, engineering-driven data culture. Rather than testing theory in isolation, Rivian focuses on how candidates reason through problems, apply machine learning and statistics to real data, and communicate insights clearly.
Many candidates prepare by practicing applied problems from Interview Query’s data scientist interview questions and refining explanations through live mock interviews, which closely resemble Rivian’s follow-up-heavy interview style.
Interview Process Overview
Candidates usually progress from an initial recruiter conversation into technical and managerial interviews, followed by a virtual onsite composed of panel-style sessions. Compared with consumer-tech data science roles, Rivian places heavier emphasis on operational data, reliability use cases, and system-level thinking.
Some candidates rehearse this progression using case-style challenges that require defining metrics, choosing modeling approaches, and defending assumptions under ambiguity.
| Interview stage | What happens |
|---|---|
| Recruiter screen | Background, motivation, and alignment with Rivian’s mission |
| Hiring manager interview | Resume deep dive, behavioral questions, and role fit |
| Technical screen | Coding, SQL, statistics, or ML-focused assessments |
| Virtual onsite (panel) | Multiple technical, case, and behavioral interviews |
| Presentation or project deep dive | Explaining prior work or a case solution (select roles) |
Recruiter Screen
The recruiter screen is typically a 30-minute conversation focused on your background, interest in Rivian, and general fit for the data scientist role. Interviewers assess whether you understand how data science at Rivian differs from purely academic or consumer analytics roles.
Tip: Be prepared to explain why applying data science to physical systems, such as vehicles or manufacturing, is motivating for you.
Hiring Manager Interview
The hiring manager interview dives deeper into your experience, past projects, and how you approach ambiguous problems. Questions often explore collaboration style, ownership, and how you have applied modeling or analysis to influence decisions.
Tip: Anchor your answers around decisions you enabled with data, not just models you built.
Technical Screen (Coding, SQL, ML, Or Statistics)
Technical screens may be conducted live or asynchronously and often include a mix of SQL, Python coding, and machine learning or statistics questions. Depending on the team, this can range from LeetCode-style problem-solving to applied ML questions on forecasting, anomaly detection, or NLP.
Interviewers evaluate clarity of thought, correctness, and how you explain trade-offs, not just whether you arrive at the optimal solution.
Tip: Talk through assumptions, time and space complexity, and how you would validate results in a production environment.
Virtual Onsite (Panel Interviews)
The virtual onsite is the most demanding part of the Rivian data scientist interview process. Candidates typically complete four to six back-to-back panel interviews, each focused on a different dimension of applied data science. The goal is to evaluate not only technical depth, but also problem framing, communication, and ownership in an engineering-driven environment.
Candidates often prepare for this stage by practicing end-to-end case reasoning using case-style challenges, which mirror the structure and pacing of Rivian’s panel interviews.
| Panel interview | What it focuses on | What Rivian is assessing | Prep guidance |
|---|---|---|---|
| Technical coding (Python / SQL) | Live coding, data manipulation, algorithmic reasoning | Problem-solving clarity, correctness, and efficiency | Practice explaining your logic while coding; narrate assumptions and edge cases |
| Machine learning & statistics | Forecasting, anomaly detection, model evaluation, or NLP concepts (role-dependent) | Depth of ML fundamentals and ability to apply them to real data | Be ready to justify model choice, evaluation metrics, and trade-offs |
| Case study / metrics design | Defining success metrics, structuring ambiguous problems | Structured thinking and decision-oriented analysis | Start with the decision being supported, then define metrics backward |
| Project or experience deep dive | Walkthrough of a past project or case solution | Ownership, technical judgment, and real-world impact | Focus on why decisions were made, not just what you built |
| Behavioral & collaboration | Teamwork, conflict, adaptability, and leadership | Communication style and fit with Rivian’s culture | Use specific examples showing influence without authority |
| Product & mission fit | Interest in Rivian products and EV space | Motivation and long-term alignment | Research a specific Rivian system and propose data-driven improvements |
Tip: Treat the onsite as a sequence of decision-making conversations, not isolated interviews. Interviewers often probe how your answers in one session connect to earlier discussions.
Product And Mission Fit
Some interviews focus explicitly on Rivian’s products, mission, and use of data science across reliability, quality, and manufacturing. Interviewers want to see genuine curiosity about EVs and how data science improves real-world systems.
Tip: Be ready to discuss a specific Rivian product or operational area and outline how you would apply data science to improve it.
Challenge
Check your skills...
How prepared are you for working as a Data Scientist at Rivian?
Rivian Data Scientist Interview Questions
Rivian data scientist interview questions are designed to test how you think, not just what you know. Interviewers focus on structured problem-solving, modeling judgment, and your ability to explain trade-offs in environments where data is noisy and decisions affect physical systems, such as vehicles, factories, and service operations.
Technical Coding And SQL Questions
These questions test SQL fundamentals, time-series reasoning, and your ability to reason about data at scale under live interview conditions.
Calculate a rolling average over a time window.
This question evaluates window functions, partitioning, and time-based aggregation. At Rivian, similar logic is used to track reliability metrics, sensor trends, or failure rates over time.
Tip: Be explicit about window definitions and how you handle missing or irregular timestamps.
Reset cumulative metrics by period.
This tests your ability to compute cumulative values that reset monthly or quarterly, which mirrors manufacturing and production reporting.
Tip: Clearly define period boundaries before writing the query.
Identify outliers in a dataset.
This tests basic statistical reasoning and anomaly detection, often applied to vehicle telemetry or manufacturing sensor data.
Tip: Start with simple statistical baselines before proposing complex models.
Detect overlapping time intervals.
This question evaluates interval logic and data integrity checks, which are common in service scheduling, maintenance windows, or warranty coverage analysis.
Tip: Explain how you define an overlap and how you avoid double counting.
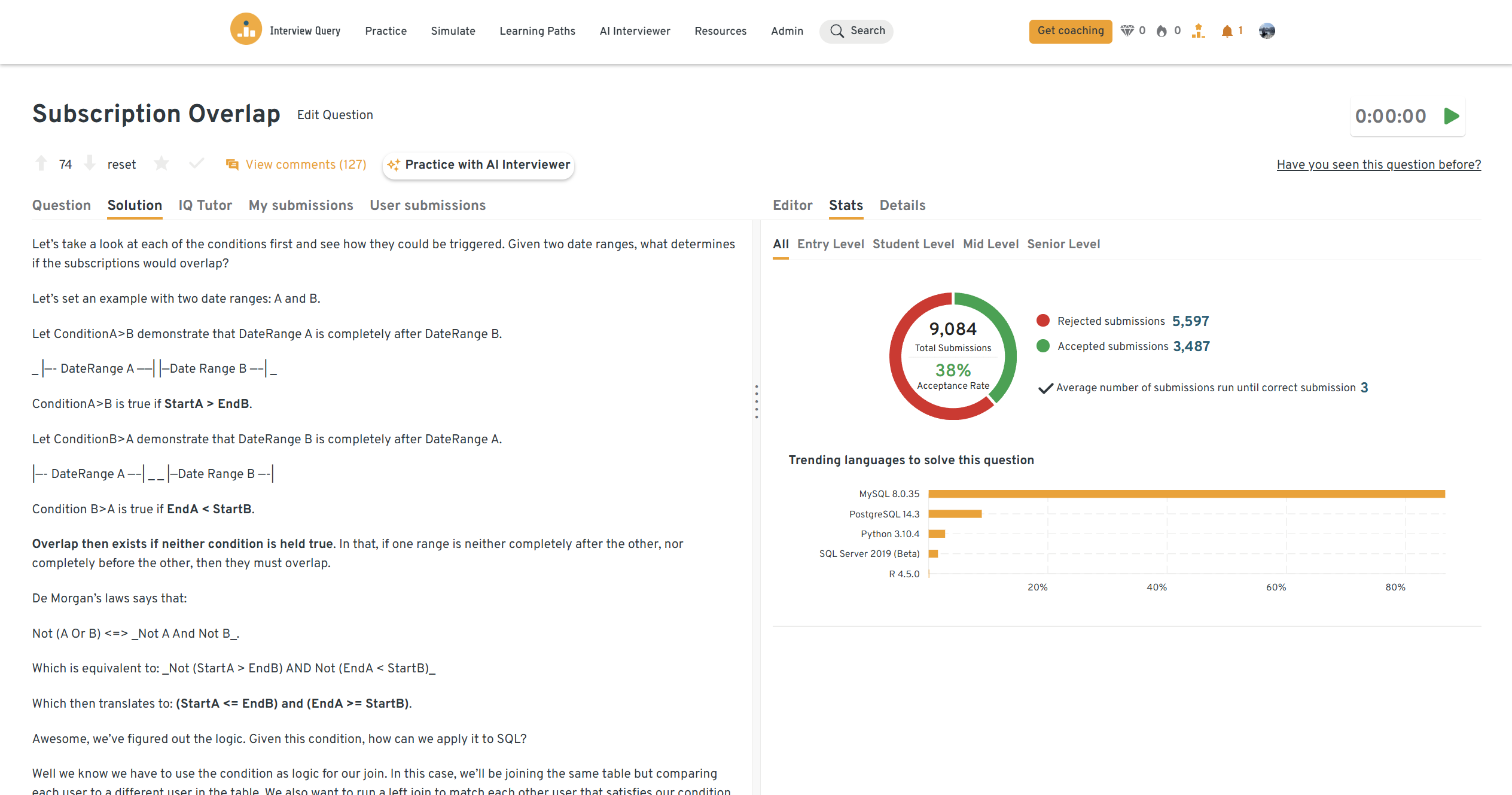
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
Machine Learning And Statistics Questions
These questions assess whether you can apply ML and statistics to real operational problems, not just describe algorithms.
How would you design an A/B test to measure product impact?
Interviewers assess experimental design, metric selection, and causal reasoning. At Rivian, similar thinking applies to software updates, process changes, or feature rollouts.
Tip: Discuss how you would control for confounding variables and rollout timing.
How would you evaluate a model when labels are limited or noisy?
This tests judgment around proxy metrics, validation strategies, and risk management in production systems.
Tip: Emphasize trade-offs between precision, recall, and operational cost.
How would you detect model drift in a production system?
While often asked without a specific dataset, this question evaluates monitoring strategy, retraining triggers, and business impact awareness.
Tip: Mention both statistical drift signals and downstream decision impact.
Case Study And Metrics Design Questions
These questions mirror Rivian’s day-to-day work, where data science supports engineering and operational decisions.
Design a KPI dashboard for operational performance.
This evaluates prioritization and clarity. Interviewers want to see whether you can identify a small set of actionable metrics.
Tip: Anchor metrics to decisions operators can make, not vanity metrics.
Investigate a sudden change in a key metric.
This tests structured problem decomposition and root-cause analysis, common in reliability and quality investigations.
Tip: Start with segmentation before jumping to explanations.
How would you measure whether a manufacturing process change improved quality?
This assesses your ability to combine metrics, experimental thinking, and operational constraints.
Tip: Explain how you would establish a baseline and handle lagging indicators.
Behavioral And Culture-Fit Questions
These questions assess ownership, communication, and alignment with Rivian’s mission-driven culture.
Why do you want to work as a data scientist at Rivian?
Interviewers look for genuine interest in EVs and applied data science.
Tip: Tie motivation to a specific Rivian product or operational problem.
Sample answer: I’m motivated by applying data science to systems where decisions affect real-world outcomes. Rivian’s focus on connected vehicles and manufacturing scale means models directly influence reliability and customer experience. That combination of technical depth and physical impact is what excites me.
Describe a time when your model or analysis was challenged by stakeholders.
This evaluates how you defend analysis without becoming defensive.
Tip: Emphasize alignment and decision impact.
Sample answer: In a prior role, an engineering team questioned a model flagging increased failure risk. I walked through assumptions, shared sensitivity analyses, and aligned on a pilot rollout. This approach helped validate the model in production and improved trust across teams.
How do you handle ambiguity when data is incomplete or noisy?
Rivian values comfort making directional recommendations.
Tip: Show how you balance rigor with pragmatism.
Sample answer: I make assumptions explicit, quantify uncertainty, and recommend the best next action while outlining what additional data would reduce risk. This keeps decisions moving without overstating confidence.
You might think that behavioral interview questions are the least important, but they can quietly cost you the entire interview. In this video, Interview Query co-founder Jay Feng breaks down the most common behavioral questions and offers a clean framework for answering them effectively.
How To Prepare For A Rivian Data Scientist Interview
Preparing for a Rivian data scientist interview means training for applied decision-making, not just technical recall. Rivian looks for data scientists who can work across modeling, engineering constraints, and business trade-offs in environments where data is imperfect and outcomes are physical.
Practice Problem Framing Before Modeling
Rivian interview questions often start with loosely defined problems tied to reliability, manufacturing, or service operations. Strong candidates clarify the decision being made, define success metrics, and surface assumptions before choosing an algorithm.
Tip: Practice articulating problem structure out loud using Interview Query’s data scientist interview questions. Train yourself to explain why a model is needed before which model you use.
Strengthen Coding And ML Fundamentals Together
Rivian data scientist interviews often blend coding and modeling. You may be asked to write Python, reason about time or space complexity, and then connect that solution to a modeling or statistical context.
Tip: Practice LeetCode-style problems alongside applied ML questions, and narrate trade-offs as you work. Interviewers care about reasoning clarity as much as correctness.
Prepare For Live Case And Metrics Discussions
Case-style interviews test whether you can define metrics, choose data sources, and propose solutions for complex, real-world systems. These often resemble internal Rivian problems rather than textbook cases.
Tip: Use case-style challenges to practice walking through metric selection, baseline definition, and validation strategy without jumping straight into modeling.
Build Behavioral Stories Around Ownership And Impact
Behavioral interviews at Rivian focus on ownership, adaptability, and cross-functional influence. Interviewers want to see how you navigated uncertainty, defended analytical decisions, and shipped solutions.
Tip: Prepare STAR stories where your work influenced engineering or operational outcomes. Refine delivery through live mock interviews, which mirror Rivian’s probing follow-ups.
Research Rivian’s Products And Data Landscape
Rivian expects data scientists to care about the product and mission. Understanding Rivian’s vehicles, manufacturing footprint, and connected systems strengthens both technical and behavioral answers.
Tip: Pick one Rivian system (vehicle reliability, manufacturing throughput, or service operations) and practice explaining how you would apply data science to improve it.
Role Overview: Rivian Data Scientist
A Rivian data scientist builds and deploys models that improve vehicle performance, manufacturing efficiency, and operational decision-making. The role combines statistical modeling, machine learning, and large-scale data processing with close collaboration across engineering and business teams.
Day to day, Rivian data scientists work with telemetry data, manufacturing signals, and operational metrics to forecast outcomes, detect anomalies, and identify root causes of issues. They build scalable data pipelines, validate models in production, and communicate insights through dashboards and presentations that guide real decisions.
Core responsibilities
- Modeling and analytics: Develop predictive models for reliability, quality, forecasting, or anomaly detection using Python and SQL.
- Data pipelines: Build and maintain scalable ELT or ETL workflows using tools such as Spark, Databricks, or Snowflake.
- Statistical analysis: Apply hypothesis testing, inference, and experimental thinking to operational and product questions.
- Visualization and monitoring: Create dashboards and monitoring tools to track model and system performance.
- Root cause analysis: Perform deep dives into quality, manufacturing, or service issues to identify drivers and solutions.
- Cross-functional collaboration: Partner with engineers, operations teams, and leaders to translate problems into analytical solutions.
- Production mindset: Monitor models, detect drift, and iterate as systems and data evolve.
Candidates preparing for this role benefit from practicing applied modeling and reasoning problems in the data scientist interview questions bank, which emphasizes real-world context and trade-offs.
Culture And What Makes Rivian Different
Rivian’s data science culture is hands-on, mission-driven, and tightly integrated with engineering and operations. Data scientists are expected to own problems end to end, from framing and modeling to deployment and impact.
What Rivian interviewers look for
- Applied judgment: Choosing models that work under real constraints, not just ideal conditions.
- Clear communication: Explaining complex analysis to engineers and non-technical leaders.
- Ownership: Taking responsibility for outcomes, not just insights.
- Adaptability: Comfort working in evolving systems and ambiguous environments.
- Mission alignment: Genuine interest in EVs, sustainability, and Rivian’s products.
Because Rivian emphasizes data-driven execution rather than research in isolation, candidates who can balance rigor with pragmatism tend to stand out.
Average Rivian Data Scientist Salary
Rivian data scientist compensation in the United States reflects a growth-stage, engineering-led pay structure with meaningful equity, especially at senior levels. Public data from Levels.fyi provides solid visibility for RIV-3, RIV-5, and RIV-6, while other levels have fewer reported submissions. The table below annualizes reported monthly figures and estimates missing levels using Rivian’s internal leveling progression and comparable EV / hardware-tech benchmarks.
| Level | Title | Total (Annual) | Base (Annual) | Stock (Annual) | Bonus (Annual) |
|---|---|---|---|---|---|
| RIV-3 | Data Scientist | $180K | $144K | $16K | $20K |
| RIV-4 | Data Scientist (Mid-level) | $195K–$205K | $150K–$155K | $22K–$26K | $20K |
| RIV-5 | Senior Data Scientist | $228K | $168K | $40K | $10K |
| RIV-6 | Staff Data Scientist | $264K | $180K | $83K | $8K |
| RIV-7 | Senior Staff Data Scientist | $290K–$310K | $195K–$205K | $90K–$105K | $10K |
| RIV-8 | Principal Data Scientist | $320K–$350K | $210K–$220K | $105K–$120K | $12K |
| RIV-9 | Distinguished Data Scientist | $360K+ | $230K+ | $120K+ | $15K+ |
What To Know About Rivian Data Scientist Compensation
- Equity is a core lever: Rivian offers substantially more stock than consulting or traditional analytics roles, particularly at Staff and Principal levels.
- Leveling matters more than titles: A one-level difference (for example, RIV-5 vs RIV-6) can translate into a $30K–$40K+ swing in annual compensation.
- Role and team variance: Compensation can vary based on domain (reliability, manufacturing, NLP/LLMs, platform), timing, and company performance.
- Growth-stage dynamics: As Rivian scales, bands may shift, making leveling discussions especially important during offer negotiation.
Average Base Salary
Average Total Compensation
If you are preparing for offer discussions, practicing senior-level ML, SQL, and case-style questions and simulating evaluation scenarios through mock interviews can be especially helpful, since Rivian’s leveling decisions often hinge on demonstrated ownership, production readiness, and system-level thinking.
FAQs
Is the Rivian data scientist interview hard?
Yes. The Rivian data scientist interview is considered challenging, especially compared with consumer-tech or dashboard-focused data science roles. The difficulty comes from the breadth of evaluation: live coding, ML and statistics depth, case-style reasoning, and behavioral judgment, often in back-to-back panel interviews. Candidates who practice explaining trade-offs and assumptions clearly tend to perform better than those who focus only on algorithms.
What technical skills does Rivian prioritize for data scientists?
Rivian prioritizes strong Python and SQL, a solid foundation in statistics, and applied machine learning. Depending on the team, this may include forecasting, anomaly detection, reliability modeling, or NLP and LLM-related work. Interviewers care less about exotic models and more about whether you can choose appropriate approaches and validate them in production contexts.
Are Rivian data scientist interviews more ML-heavy or coding-heavy?
It depends on the team. Engineering-facing or platform roles lean more toward coding and algorithmic thinking, while reliability, manufacturing, or analytics-focused teams emphasize applied ML, statistics, and case reasoning. Most candidates encounter a mix of both during the virtual onsite.
Do I need automotive or EV experience to pass the interview?
No prior automotive experience is required, but genuine interest in EVs and physical systems helps. Interviewers often ask how you would apply data science to vehicle reliability, manufacturing efficiency, or service operations. Strong candidates show curiosity about the domain and can reason through unfamiliar systems logically.
What differentiates strong Rivian data scientist candidates?
Strong candidates consistently anchor their answers around decisions and impact. They clarify the problem before modeling, make assumptions explicit, and communicate uncertainty honestly. They also demonstrate ownership, adaptability, and comfort working with noisy or incomplete data, which reflects Rivian’s fast-growing, engineering-led environment.
Turning Data Science Into Real-World Impact at Rivian
The Rivian data scientist interview is designed to test whether you can move beyond models and help teams make better decisions in complex, real-world systems. Successful candidates show they can structure ambiguous problems, apply machine learning and statistics pragmatically, and communicate insights clearly to engineers and leaders who rely on those insights.
To prepare effectively, focus on end-to-end practice, not isolated drills. Start by working through Interview Query’s data scientist interview questions to sharpen coding, ML, and statistical fundamentals. Then pressure-test your reasoning and communication through live mock interviews, where follow-up questions mirror Rivian’s panel-style interviews. Together, these steps help you walk into the Rivian interview confident, structured, and ready to turn data science into real-world impact.
Rivian Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Behavioral | Medium | |
Tell me about a data project that didn’t go the way you expected. What did you set out to do, what surprised you, and how did you handle it? | ||
AI & Agentic Systems | Medium | |
Behavioral | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences