
Citi Data Engineer Interview Guide: Process, Questions, Salary


Introduction
Citi processes more than 200 million customer accounts across 160 countries, generating billions of daily data points used for trading, risk, fraud detection, credit decisions, and regulatory reporting. Because the bank must comply with strict global regulations, Citi data engineer interview questions emphasize reliability, data quality, and scalable distributed systems.
If you are preparing for Citi data engineer interview questions or even searching for Citi Bank data engineer interview questions, this guide explains the full interview process, what Citi evaluates at each stage, and the technical areas you must master. You will learn what to expect across Spark, SQL, ETL design, cloud data architecture, and pipeline debugging.
To support your prep, you can also explore Interview Query’s data engineering interview guide, practice hands-on SQL with the SQL learning path, or try real-world scenarios in the take-home challenge library.
What does a Citi Data Engineer do?
Citi data engineers design, build, and maintain the large-scale data infrastructure that powers risk systems, regulatory reporting, fraud monitoring, and business analytics. The role combines hands-on engineering with an understanding of financial data quality, governance, and controls. Engineers work across Spark, Hadoop, Kafka, cloud platforms, and data warehousing tools to deliver reliable and scalable solutions.
Key responsibilities include:
- Designing, developing, and maintaining scalable batch and streaming pipelines using Spark, Python, Scala, or Java
- Building data lake and data warehouse solutions using cloud tools such as AWS EMR, Glue, Redshift, or Azure Data Factory
- Optimizing storage formats, partitioning, bucketing, and compute resources to reduce cost and latency
- Implementing strict data quality, lineage, and validation controls to meet regulatory expectations
- Troubleshooting failures, debugging Spark jobs, and resolving production incidents
- Working with business, risk, and operations teams to translate requirements into engineering solutions
- Ensuring compliance with data security, governance, and privacy practices across Citi systems
Citi values engineers who can balance strong technical proficiency with disciplined data controls. Many candidates are also curious about Citibank data engineering technologies used in practice; while stacks vary by team, you’ll commonly see combinations of SQL, PySpark, Kafka, cloud data lakes or warehouses, and orchestration tools like Airflow or similar schedulers.
Why this role at Citi?
Citi is one of the world’s largest financial institutions, and its data infrastructure powers critical decisions across trading, risk, consumer banking, internal reporting, and regulatory compliance. A data engineering role at Citi is a strong fit for candidates who want to solve large-scale distributed systems problems while operating in a highly regulated and global environment.
The role also aligns with Citi’s core values of integrity, ownership, and acting as a trusted partner. Data engineers contribute directly to operational resilience, client protection, and system stability. Citi invests heavily in cloud transformation and modern data technologies, giving engineers exposure to modern stack components like Spark on Kubernetes, Kafka streaming, and lakehouse architectures.
Engineers gain broad experience across ETL design, cloud migration, data governance, and pipeline optimization while working with teams across multiple regions and business lines.
Citi Data Engineer Interview Process
Citi’s data engineer interview process evaluates your technical depth, architectural reasoning, communication skills, and alignment with the firm’s values. Each stage builds toward understanding how you handle distributed systems, data quality, problem diagnosis, and collaboration. Many candidates prepare with resources like the data engineering interview guide, the SQL practice dashboard, and structured mock sessions through Interview Query coaching.
Interview stages
| Stage | Focus |
|---|---|
| Initial phone or video screen | Background, resume alignment, high-level technical fit |
| Technical assessment | SQL, PySpark, ETL logic, debugging, hands-on coding |
| Technical deep dive | Big data architecture, Spark internals, optimization strategies, cloud design |
| Behavioral interview | Collaboration, communication, crisis handling, global teamwork |
| Final managerial or case round | Strategic thinking, data governance, scenario-based problem solving |
Initial phone or video screen
This stage evaluates foundational fit. Recruiters or hiring managers confirm your experience with data pipelines, Spark, cloud tools, and your motivation for joining Citi. The focus is on communication and your ability to articulate your past engineering work clearly.
What they look for:
- Clear summaries of prior data engineering projects
- Experience with distributed systems, pipelines, or cloud platforms
- Familiarity with financial data environments or regulated industries (helpful but not required)
- High-level understanding of Spark, SQL, and ETL workflows
Tip: Prepare a concise walkthrough of one project using the structure problem, tech stack, logic, impact. You can practice with the AI interview tool to refine clarity.
Technical assessment
This assessment tests hands-on engineering skill. You may be asked to:
- Write SQL queries involving joins, aggregations, and window functions
- Transform and clean semi-structured data
- Write PySpark or Spark SQL code to build or optimize a pipeline
- Diagnose failures in ETL or Spark jobs
- Explain partitioning, bucketing, file formats, and memory management
The format may be an online test, a third-party technical screen (for example, Karat for some roles and regions), or a live coding session. Reviewing the SQL learning path and the data engineering take-home challenges helps replicate realistic tasks.
Tip: Always state the grain of your output before coding. This prevents errors in aggregation or window logic.
Technical deep dive
This interview resembles a working session with senior data engineers. You will discuss:
| Topic Area | What Citi Evaluates |
|---|---|
| Pipeline and cloud architecture design | How you design batch and streaming pipelines on AWS, GCP, or Azure. Ability to discuss ingestion layers, storage choices, IAM, networking, and reliability patterns. |
| Data storage and file formats | Your reasoning behind choosing Parquet, ORC, Delta, or other formats. Understanding partitioning, bucketing, compression, and how these affect cost and performance. |
| Spark performance and optimization | Your ability to reduce shuffles, tune partitions, manage memory, cache efficiently, and debug slow jobs. Knowledge of Spark’s execution model is critical. |
| Large-scale data ingestion and cleaning | How you handle schema evolution, deduplication, late-arriving data, and data reconciliation across systems. |
| Data quality, governance, and lineage | Familiarity with validation rules, monitoring, metadata tracking, access controls, and regulatory expectations in financial environments. |
| Real-time and streaming design | Experience with Kafka, streaming jobs, checkpointing, replay logic, and designing near real-time consumption patterns. |
| Troubleshooting and failure recovery | How you identify pipeline failures, debug logs, isolate root causes, and design systems with idempotency and retry logic. |
Interviewers want to see that your reasoning is clear, scalable, and grounded in practical experience.
Tip: Draw simple diagrams and explain tradeoffs. Structure your answer around ingestion, processing, storage, quality, and consumption layers.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Citi?
Citi Data Engineer Interview Questions
Citi data engineer interviews focus on SQL depth, distributed data processing with Spark, cloud data architecture, and the ability to troubleshoot large-scale pipelines used for regulatory reporting and real-time operations. Many of the common data engineering interview questions you’ll see at Citi center on building and maintaining trustworthy pipelines under strict governance requirements. You will also see scenario-based questions tied to governance, data quality, and secure data movement. If you want to strengthen fundamentals before diving in, explore practice problems in the SQL interview learning path or hands-on ETL scenarios in the data engineer take-home exercises.
Below are the three most relevant categories for Citi’s data engineering loop.
SQL and analytics interview questions
SQL interviews for Citi data engineer roles test your ability to manipulate large datasets, resolve messy data issues, interpret operational metrics, and write clean, reliable queries. You will work with transaction tables, event logs, pipeline metadata tables, operational risk data, and time series metrics. Interviewers want to see whether you can reason clearly about data granularity, business rules, and analytical outputs.
-
Start by filtering for transactions occurring in 2020, then extract the month and group by it. You need to count distinct users, total transactions, and sum the order amounts. Pay attention to duplicate user records or test transactions that may need to be excluded. Citi uses similar grouped reporting queries for monthly close, regulatory reporting, fraud monitoring, and operational dashboards.
Tip: Clarify whether the user count should be distinct per month or lifetime distinct.
-
You need to join the employee and department tables, compute the total employees per department, filter out those with fewer than ten employees, then calculate the percentage above the salary threshold. A window function or order by clause can then rank the resulting percentages. This question evaluates your ability to chain together grouping, filtering, and ranking. Citi often asks similar compensation and workforce reporting questions across operations and HR analytics.
Tip: State how you would handle null salaries, which can affect calculation accuracy.
How would you identify and exclude duplicate client trades caused by a system replay using SQL?
This question tests real-world banking data intuition. You must group or partition by keys such as trade id, client id, trade date, and product type. Then identify duplicates using COUNT(*) > 1 or ROW_NUMBER and keep only the canonical record. Citi uses these patterns heavily in trade reconciliation and operational risk analytics. You should also describe how you would validate that no legitimate trades are removed.
Tip: Explain at least one rule for selecting the canonical record such as earliest ingestion time.
-
You need to dedupe employees by selecting the most recent record using ROW_NUMBER or MAX based on an ID or timestamp. Partition by employee name or employee ID, then filter for the first row. The interviewer wants to see if you can diagnose upstream ETL issues and still produce clean analytical outputs. Citi places high importance on reconciliation and correcting schema inconsistencies.
Tip: Always mention how you would patch the upstream ETL pipeline to avoid repeated inserts.
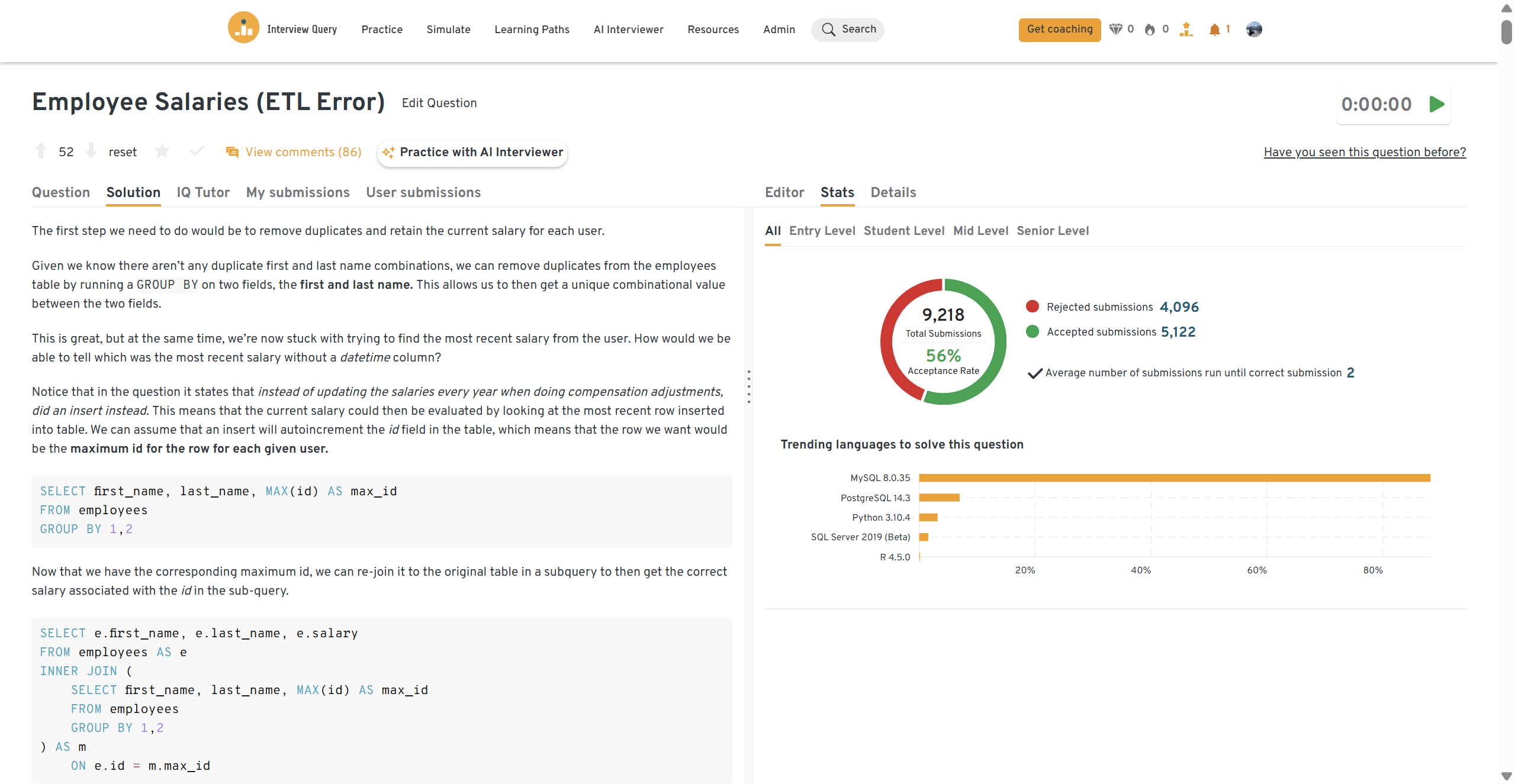
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
Spark and data pipeline interview questions
Citi data engineer interviews evaluate how well you design, optimize, and troubleshoot distributed data systems. Spark questions test your ability to reason about partitions, shuffles, memory, and job performance, while pipeline questions assess whether you can build reliable ETL/ELT flows that meet regulatory and operational requirements.
Explain how you would optimize a slow-running Spark job that processes large parquet files daily. Where would you start troubleshooting?
Start by checking the job’s physical plan for unnecessary shuffles, wide transformations, or skewed joins. You should also inspect partition sizes, the impact of file fragmentation (“small files problem”), and whether caching or predicate pushdown is being used correctly. Citi evaluates whether you understand both performance debugging and the underlying distributed execution model.
Tip: Mention at least three actionable optimizations (e.g., repartitioning, broadcast joins, file compaction).
How would you design an end-to-end ETL pipeline to process streaming transactions using Kafka and Spark Structured Streaming?
Begin by describing Kafka ingestion, schema enforcement, and checkpointing. Then explain how you would process the data using Structured Streaming with watermarking to handle late events. Citi wants to see familiarity with compliance requirements such as data lineage, audit trails, and ensuring idempotent writes. Finally, describe how you’d write outputs into a warehouse or lakehouse and monitor failures.
Tip: Highlight fault tolerance concepts like checkpointing, exactly-once semantics, and replay handling.
Your daily Spark job fails intermittently due to “ExecutorLostFailure”. How would you diagnose and fix the issue?
You should explain how to inspect executor logs, analyze memory usage, and identify shuffle-heavy stages that may be exhausting memory. Consider whether the cluster autoscaling configuration is appropriate or if skewed data is causing uneven workload distribution. Citi checks whether candidates can approach failures systematically in a regulated environment where jobs cannot silently drop data.
Tip: Note that increasing executor memory should be the last resort—fix data skew first.
How would you enforce data quality in a Spark pipeline that writes to a financial data lake?
Start with schema validation, null checks, rule-based validations (e.g., thresholds for transaction amounts), and deduplication. You should explain how to quarantine invalid rows and ensure reproducibility of results. Financial data platforms require strong governance, so describe metadata logging, lineage capture, and reconciling outputs with upstream sources.
Tip: Mention tools like Delta Lake, Iceberg, or Hudi for ACID controls, schema evolution, and time travel.
Describe how you would redesign a batch pipeline that currently takes 8 hours to run so it completes under 1 hour.
Outline systematic steps: identify bottlenecks using Spark UI, eliminate unnecessary recomputations, prune columns early, adopt incremental processing, replace cross joins, and adjust partitioning strategy. Citi wants to see your ability to modernize legacy pipelines that were not built for scale.
Tip: Emphasize incremental processing and pushdown filters—two high-impact strategies in banking systems.
Distributed systems and cloud architecture interview questions
Citi evaluates whether data engineers can design resilient, scalable systems that comply with regulatory controls. Interviewers look for clear reasoning around latency, throughput, consistency, fault tolerance, and cloud-native design patterns applicable to financial data.
How would you design a fault-tolerant data ingestion system on AWS that processes millions of daily events?
Start by describing ingestion via Kinesis or Kafka on MSK, use partition keys for even load distribution, and implement retries + dead-letter queues. For processing, describe consumer scaling, checkpointing, and replay handling. Citi wants to see that your design avoids data loss and supports auditability.
Tip: Emphasize idempotency and at-least-once processing, which are critical in regulated financial systems.
Your ETL pipeline must support data lineage, auditability, and reproducibility for regulatory review. How would you design the storage layer?
Explain using a lakehouse architecture (Iceberg/Hudi/Delta) with ACID transactions, schema evolution, and time travel. Discuss partitioning strategy, metadata logging, and immutable append-only writes. Citi is checking your understanding of compliance-driven design.
Tip: Mention catalog services (AWS Glue/Hive Metastore) for centralized governance.
How would you handle high-cardinality joins across terabyte-scale tables in a distributed system?
Begin with techniques like partition pruning, bucketing, and selecting the correct join type (broadcast vs. shuffle). Explain how to avoid data skew by salting keys or redistributing data. This question tests whether you understand distributed execution beyond basic Spark tuning.
Tip: Always explain how you would detect skew first before applying optimizations.
Describe an architecture for a real-time fraud detection system. What components would you use?
Highlight real-time ingestion (Kafka/Kinesis), stream processing (Spark Structured Streaming/Flink), feature lookup, model scoring, and low-latency storage (Redis/DynamoDB) for serving decisions. Citi wants to see whether you understand both streaming systems and ML-in-production constraints.
Tip: Distinguish real-time decisions (sub-100ms) from near-real-time analytics.
How would you migrate a legacy on-prem data warehouse to a cloud-based lakehouse without disrupting business operations?
Explain phased migration: schema + workload assessment, parallel pipelines, validation layers, and backfill strategies. Note that in financial institutions, migrations require dual-run periods for reconciliation and governance approval.
Tip: Stress data reconciliation and parallel validation across environments—essential in banks where errors have regulatory consequences.
Behavioral and stakeholder interview questions
Behavioral interviews for Citi data engineering roles assess how you communicate, collaborate across global teams, and take ownership in high-stakes environments. Citi’s culture values integrity, ownership, and being a trusted partner—interviewers want to see whether you uphold data quality, manage risk, and drive decisions with clear communication. Strong answers use STAR structure and connect your actions to business impact, operational stability, or regulatory compliance.
Describe a data pipeline or engineering project you built. What challenges did you face and how did you resolve them?
This question evaluates how you manage technical complexity, shifting requirements, and stakeholder alignment. Citi wants to understand your ability to diagnose root causes and implement solutions that improve reliability long-term.
Tip: Include both a technical challenge and a stakeholder challenge.
Sample Answer: I built a Spark ETL pipeline to standardize transaction logs across regions, but upstream schema changes caused nightly failures. I implemented schema validation, added a quarantine path for mismatched records, and coordinated with upstream teams to adopt schema versioning. The changes restored pipeline SLAs and reduced reconciliation errors.
Tell me about a time you handled a high-severity production incident. What was your response?
Citi wants evidence that you remain calm during outages and communicate clearly across global teams. Your answer should show your ability to mitigate impact quickly while also preventing recurrence.
Tip: Show how you balanced short-term mitigation with long-term prevention.
Sample Answer: A Spark job powering a regulatory dashboard failed due to extreme data skew. I applied a temporary salting strategy, reran the job with increased parallelism, and issued hourly updates to the risk team. Afterward, I added automated skew detection and optimized partitioning logic to prevent future failures.
Describe a time you influenced a technical decision across multiple teams. How did you build consensus?
Citi assesses how well you explain tradeoffs, present alternatives, and align stakeholders with different incentives. They value engineers who influence through clarity and evidence rather than authority.
Tip: Focus on the data and benchmarks you used to persuade.
Sample Answer: Teams debated storing ingestion data as CSV or Parquet. I benchmarked performance, cost, and query latency, showing Parquet would reduce compute time by 40 percent. After walking stakeholders through risks and dependencies, everyone agreed to adopt Parquet as the global standard.
Give an example of how you improved data quality or reliability in a system. What actions did you take?
Citi places heavy emphasis on auditability and accuracy due to regulatory requirements. Interviewers look for engineers who approach data quality as a system-level responsibility, not a one-off fix.
Tip: Always include both remediation and prevention.
Sample Answer: I discovered inconsistent timestamp formats across markets that caused reconciliation mismatches. I standardized ingestion to UTC, added validation rules, and documented the new conventions. Errors dropped significantly and reduced downstream escalations.
-
Citi teams operate globally with competing deadlines, so interviewers want to see structured communication and expectation management. This question assesses maturity, diplomacy, and clarity.
Tip: Show empathy and clear boundary-setting.
Sample Answer: A product manager pushed for a complex pipeline upgrade with a two-day deadline. I broke down the requirements, proposed a feasible MVP, and outlined a phased delivery plan for the full feature. Reframing the timeline around risk and value aligned expectations and improved our collaboration.
If you want deeper practice, you can explore the full set of 100+ data engineer interview questions with answers. This walkthrough by Interview Query founder Jay Feng covers 10+ essential data engineering interview questions—spanning SQL, distributed systems, pipeline design, and data modeling.
How To Prepare For a Citi Data Engineer Interview
Preparing for a Citi data engineer interview requires strong fundamentals in distributed systems, Spark optimization, SQL proficiency, and cloud-based data architecture. Citi evaluates your ability to design pipelines that are reliable, scalable, and compliant with financial industry governance standards. Interviewers also assess how well you communicate with risk, product, and global engineering teams.
To build confidence across these areas, you can use resources such as the SQL interview learning path, takehome challenges, and mock interviews to simulate real-world scenarios.
Below are seven strategies to prepare effectively.
Strengthen your Spark and distributed computing fundamentals
Citi heavily uses Spark for large-scale ETL and regulatory reporting, so you must understand partitioning, shuffle behavior, skew handling, and performance tuning. Interviewers evaluate whether you can reason about memory usage, job stages, and execution bottlenecks.
Tip: Practice diagnosing Spark jobs using sample DAGs or logs and walk through your reasoning out loud.
Review SQL patterns for analytics, ETL, and data validation
SQL remains central to Citi’s data workflows, especially for reconciling financial data, building aggregates, and validating data quality. Problems often involve window functions, complex joins, and debugging mismatched aggregates. You can practice these through the SQL interview question bank.
Tip: Before writing a query, state your assumptions and the intended table grain to avoid ambiguity.
Develop confidence in cloud architecture and pipeline design
Citi teams build pipelines on AWS, GCP, and Azure using tools like EMR, Glue, Kinesis, Airflow, and Kafka. Interviewers want to see how you think about reliability, lineage, and scalability while satisfying governance requirements. Reviewing end-to-end designs in the takehome challenges can help you practice structuring your approach.
Tip: Always mention monitoring, alerting, and idempotency when discussing pipeline design.
Prepare to walk through one end-to-end data project in detail
Citi frequently asks candidates to explain a past project, focusing on the decisions you made and the systems you built. Interviewers want specificity: which tools you used, how you optimized performance, how you resolved failures, and how your work impacted downstream stakeholders.
Tip: Keep a structured narrative: problem → design → implementation → challenges → impact.
Understand data governance, quality, and regulatory considerations
Citi operates in a highly regulated environment, so expect questions on lineage, metadata management, reconciliation processes, and GDPR or access controls. Interviewers often assess whether you understand why quality checks matter beyond correctness: they protect risk processes and audit trails.
Tip: In every technical answer, include at least one governance or data quality check.
Practice explaining technical decisions to non-technical audiences
You may collaborate with risk, operations, compliance, and product teams who rely on clear, contextual explanations. Behavioral interviews assess how well you translate latency, scalability, or schema changes into business implications.
Tip: Practice summarizing your technical reasoning in two sentences before expanding.
Simulate interviews through mock sessions and hands-on challenges
Many candidates sharpen their communication and problem-solving by using mock interviews or completing data engineering challenges. These help you practice thinking aloud, structuring answers, and responding to ambiguous prompts.
Tip: Treat every practice session as if it were a real interview and review your answer structure each time.
Average Citi Data Engineer Salaries
When candidates search for Citi data engineer salary or Citi Bank data engineer salary, most public benchmarks come from crowd-sourced sources like Levels.fyi. Citi publicly reports salary data for engineering levels C11 and C12, which represent most data engineering roles at the firm, where annual compensation typically ranges from $98K to $132K.
| Level | Role | Total Compensation (yr) | Base Salary (yr) | Bonus (yr) |
|---|---|---|---|---|
| C11 | Data Engineer | ~$98.4K | ~$97.2K | ~$1.25K |
| C12 | AVP, Data Engineer | ~$132K | ~$132K | ~$2.50K |
Note: Higher bands (C13–C16) are not shown because Citi does not publish consistent, verifiable salary data for those levels on public sources.
Average Base Salary
Average Total Compensation
FAQs
How hard is the Citi data engineer interview?
Citi’s data engineering interviews are moderately difficult, especially for roles involving Spark, cloud architecture, and large-scale data pipelines. You will be tested on SQL, ETL patterns, distributed systems, and troubleshooting real financial data scenarios. Practicing with data engineer interview questions and mock interviews can significantly improve your performance.
Does Citi ask coding questions?
Yes. Expect SQL queries, PySpark transformations, and Python coding prompts during the technical assessment and deep dive rounds. Many candidates also encounter system design questions for pipelines, including partitioning strategies and data schema choices. You can prepare using SQL interview questions and Spark case studies.
Which tools should I study for a Citi data engineer interview?
Focus on SQL, PySpark, Hadoop, Kafka, and cloud tools such as AWS EMR, S3, Glue, or GCP equivalents. Understanding data modeling and governance frameworks is equally important due to the bank’s regulatory requirements. Reviewing take home assignment guides or ETL practice problems can help.
Does Citi hire junior or entry level data engineers?
Yes. Citi hires entry level engineers through programs like C10 and C11 roles, especially in Tampa, Dallas, and global shared service hubs. Expect more emphasis on SQL and Python rather than deep Spark optimization at these levels. Early career candidates often benefit from mock behavioral interviews to prepare for teamwork and communication questions.
How important is cloud experience for Citi?
Very important. Citi continues to migrate workloads to AWS and other cloud platforms, so interviews will test your understanding of scalable ETL, storage formats, orchestration tools, and cost efficiency. You do not need to be a cloud architect, but familiarity with EMR, S3, Glue, Kinesis, or cloud-based DAG orchestration is a strong advantage.
Does Citi ask system design questions for data engineering roles?
Yes. You may be asked to design a data pipeline, stream ingestion workflow, or batch ETL system for large volumes of financial data. The interviewer will evaluate your ability to reason through scalability, monitoring, quality checks, and data lineage. Reviewing data engineer system design questions helps you understand the structure of these problems.
How can I stand out during the behavioral interview?
Tie your answers to Citi’s values such as integrity, ownership, and succeeding together. Use the STAR method and show how you handle ambiguity, work with global teams, and solve technical issues under time pressure. Reviewing behavioral interview examples or doing a mock behavioral session can improve your confidence.
Start Preparing for Your Citi Data Engineer Interview
Citi’s data engineering interviews reward candidates who can blend technical depth with clear communication and strong operational instincts. If you want to accelerate your prep, explore Interview Query’s data engineer question bank, practice with real SQL and PySpark problems, and try interactive mock interviews to sharpen your structure and delivery. Start building a preparation system that reflects how Citi evaluates talent so you can walk into each round ready to perform at your best.
Citi Interview Questions
| Question | Topic | Difficulty | ||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Medium | |||||||||||||||||||||||||||||||||||||||
Write a query to show the number of users, number of transactions placed, and total order amount per month in the year 2020. Assume that we are only interested in the monthly reports for a single year (January-December). Example: Input:
Output:
| ||||||||||||||||||||||||||||||||||||||||
Data Pipelines | Hard | |||||||||||||||||||||||||||||||||||||||
Behavioral | Medium | |||||||||||||||||||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences