
Adobe Machine Learning Engineer Interview Guide (2025): Process, Questions & Prep Tips


Introduction
Preparing for an Adobe machine learning engineer interview means stepping into a role where your work directly shapes products used by millions, whether it’s powering Photoshop’s content-aware fill or driving real-time personalization in Adobe Experience Platform. It’s one of the most competitive roles in tech, blending research, engineering, and product impact.
In this guide, you’ll learn what to expect from the Adobe ML engineer interview loop, including the technical focus on modeling fundamentals, system design, and product sense. We’ll also break down the day-to-day responsibilities of the role, explore Adobe’s culture of experimentation and innovation, and share proven strategies to help you prepare with confidence. Whether you’re targeting your first ML role or looking to scale your career, this is your roadmap to success.
Role Overview & Culture
Life as an Adobe machine learning engineer revolves around building and deploying end-to-end ML systems that sit at the heart of Adobe’s flagship products. One day you might be refining a generative model that powers image editing in Photoshop, and the next, you’re scaling personalization models inside Adobe Experience Platform to serve millions of users in real time. Engineers work across the stack, such as data pipelines, model training, inference APIs, and partner with data scientists, product managers, and software engineers to move prototypes into production.
Culturally, Adobe thrives on experimentation. Teams are encouraged to test ideas quickly, validate them through A/B experiments, and scale what works, often without layers of bureaucracy. It’s a bottom-up environment where engineers are trusted to ship features that matter. The company values technical creativity, collaboration across disciplines, and a willingness to take bold bets, making it a fertile ground for ML engineers who want their work to be both innovative and visible.
Why This Role at Adobe?
The Adobe machine learning engineer role stands out because your work doesn’t just improve internal systems; it shapes the creative tools and platforms used by over 30 million subscribers worldwide. Every model you deploy, from automated video editing to real-time personalization, influences how creators, marketers, and enterprises bring ideas to life.
Compensation reflects both the impact and demand: machine learning engineers at Adobe typically earn $167K to $245K in compensation. Beyond pay, the growth trajectory is clear. Many engineers transition into senior ML research, applied science, or product leadership within a few years, gaining exposure to projects that bridge consumer creativity and enterprise-scale data.
What makes this role unique is the combination of technical challenge and creative impact. Few companies operate at Adobe’s scale in both consumer and enterprise AI, giving you the chance to innovate in a space where your models become features that millions rely on daily.
What Is the Interview Process Like for an ML Engineer Role at Adobe?
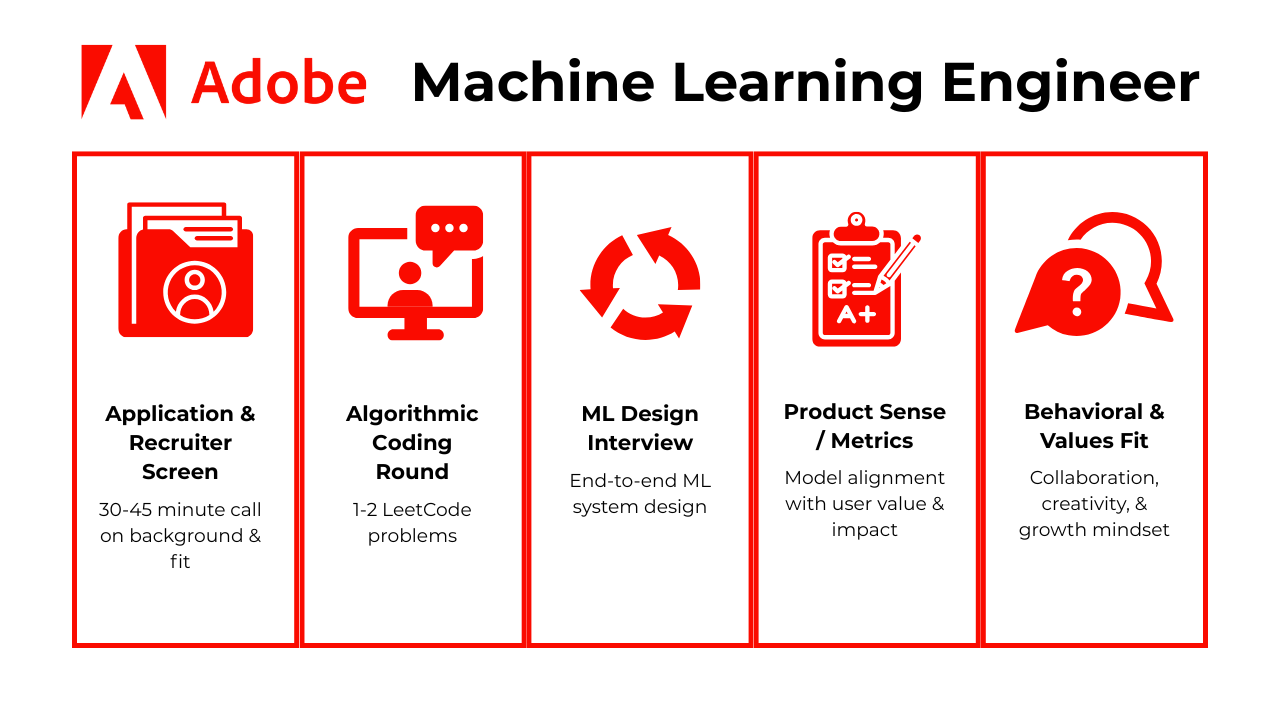
The Adobe ML Engineer interview process is designed to assess your depth in machine learning, your coding ability, and your product intuition across several calibrated rounds. Adobe looks for engineers who can not only build great models, but also ship reliable, scalable ML systems that enhance products like Photoshop, Firefly, and the Experience Platform.
Here’s how a typical Adobe ML Engineer interview unfolds:
Application & Recruiter Screen
Once you’ve submitted your resume, a recruiter will schedule a 30–45-minute call to understand your background, technical focus, and fit for Adobe. Expect them to ask about your ML stack (Python, TensorFlow, PyTorch, Spark, etc.), highlight projects where you built or deployed ML models, and probe into why Adobe appeals to you specifically. They’ll also check basics like work authorization, relocation preferences, and team alignment. While not technical, this round sets the tone. It’s your chance to show passion for ML and clarity about your career goals.
Tip: Prepare a concise 2–3 minute “career story” that ties your past projects directly to Adobe’s focus on creativity and personalization.
Algorithmic Coding Round (30 min)
This is a fast-paced session, often delivered over a shared doc or platform. You’ll get 1–2 algorithmic problems in the LeetCode medium range. Common topics include arrays, hash maps, binary search, or graph traversal. The expectation isn’t just correctness but also how you communicate: walking through edge cases, explaining time/space complexity, and adjusting your approach when prompted. The interviewer will likely nudge you to optimize or defend tradeoffs.
Tip: Practice solving problems out loud. Verbalizing your reasoning is as important as coding speed. Treat the interviewer as a collaborator, not a judge. You can review the top 9 machine learning algorithm interview questions for 2025 to help improve your skill and memorize concepts.
Machine Learning Design Interview
Here you’ll be asked to design an ML system end-to-end. Scenarios may include fraud detection for Adobe Stock, personalized recommendations in Creative Cloud, or multimodal ranking systems combining text and image data. You’ll need to scope the business problem, propose relevant models, outline data preprocessing steps, define evaluation metrics, and think about deployment constraints (e.g., latency, scalability). Interviewers want to see structured thinking: how you balance practicality with ambition.
Tip: Use a framework: start with problem definition, then walk through data, model, evaluation, deployment. It keeps you organized and signals maturity. Here are top 50 machine learning system design interview questions to help you prepare for different categories, including system design, applied modeling, recommendation systems, and case studies.
Product Sense/Metrics Round
This round bridges engineering with product. You may be asked to choose success metrics for an ML-powered feature, explain how you’d run an A/B test, or interpret why a deployed model shows drift. Adobe’s products span creativity and enterprise marketing, so the focus is on aligning models with user value and business impact. They’re testing your ability to step back from the code and think like a product owner.
Tip: Always tie metrics back to user outcomes. For example, “Instead of just tracking accuracy, I’d also measure time saved for users editing in Photoshop.” You can schedule a mock interview to get personalized feedback for your answers.
Behavioral & Values Fit
Adobe prizes collaboration, creativity, and growth mindset. In this round, you’ll face questions like “Tell me about a time you had to experiment under uncertainty” or “How did you resolve conflict on a cross-functional team?” STAR (Situation, Task, Action, Result) stories work best: show that you can adapt, lead, and learn from failures. Adobe also values people who can navigate ambiguity, since ML projects often evolve rapidly.
Tip: Prepare 4-5 strong stories ahead of time, including ownership, innovation, teamwork, failure recovery, and leadership. Reuse them flexibly depending on the question.
Hiring Committee Review & Offer
After interviews, all feedback is collected within 24 hours and reviewed in a committee that includes your potential manager, a recruiter, and sometimes a bar-raiser (an interviewer outside your team). The committee looks for consistency across rounds and balances technical depth with cultural alignment. If successful, you’ll receive an offer within 5–7 business days, including leveling and compensation package.
Tip: Keep communication lines open. If you have competing offers or timing concerns, update your recruiter early. They can often accelerate review or clarify next steps.
Behind the Scenes
Adobe uses structured feedback forms to ensure fairness and reduce bias. Interviewers write independent notes before discussing as a group, which helps prevent one strong opinion from dominating. The inclusion of a bar-raiser adds an extra layer of consistency, ensuring hires meet company-wide standards, not just team-specific ones. This process reflects Adobe’s emphasis on thoughtful, deliberate hiring. Most candidates hear back quickly, even rejections are typically shared within a week.
Tip: Don’t overanalyze silence. If you haven’t heard back after a week, it’s perfectly acceptable to politely check in with your recruiter.
Differences by Level
Not every Adobe machine learning engineer candidate is assessed the same way. The interview loop adjusts based on your experience, because what’s expected from a fresh grad is very different from a senior engineer who’s shipped production ML systems before. Here’s how it usually breaks down:
Entry-Level / New Graduate
If you’re just starting out, the emphasis is on fundamentals: data structures, algorithms, and core ML concepts (think supervised vs. unsupervised learning, bias-variance tradeoff, and evaluation metrics). Interviewers want to see strong coding fluency and the ability to explain your academic or internship projects clearly. At this level, it’s less about having run models in production and more about demonstrating you can learn quickly and collaborate well.
Tip: Practice walking through your past projects in plain English. Imagine explaining your capstone to a roommate who isn’t technical. It proves you understand your work deeply.
Mid-Level (1–4 Years of Experience)
Here, you’re expected to bridge theory and practice. That means not only coding solutions but also talking about trade-offs: why you’d choose a particular model, how you’d preprocess messy real-world data, or how you’d evaluate success for a product feature. You’ll also get questions on system design at a smaller scale (batch inference pipelines, feature stores, or basic A/B testing setups). This level is about showing you can take ownership of an ML feature end-to-end.
Tip: Bring one detailed “work story” where you took a project from data to deployment. Break it down step by step. It gives interviewers confidence you can deliver in Adobe’s production environment.
Senior-Level (MTS 2, Staff, Principal)
At the senior end, the bar shifts from execution to leadership. You’ll still get coding and design rounds, but the complexity is higher: online inference systems, scaling models to millions of users, or orchestrating experiments across multi-tenant systems like Adobe Firefly or AEP. You’re also expected to discuss team-level impact, mentoring, setting technical direction, or aligning ML goals with product strategy. At this stage, it’s as much about influence as it is about code.
Tip: In your answers, zoom out. Don’t just say how you built a system; explain the business trade-offs you weighed, the stakeholders you worked with, and the long-term impact of your decisions.
Challenge
Check your skills...
How prepared are you for working as a ML Engineer at Adobe?
What Questions Are Asked in an Adobe ML Engineer Interview?
Coding/Technical Questions
This section introduces some of the most common Adobe Machine Learning Engineer interview questions, ranging from algorithm challenges to SQL twists tailored for ML workflows.
Select the top 3 departments with at least ten employees
In this SQL challenge, you need to identify which departments have at least ten employees and then return the top three. The solution involves grouping employees by department using
GROUP BY, filtering withHAVING COUNT(*) >= 10, and then ordering the results by size before applying aLIMIT. What makes this relevant for ML engineers is that it reflects a real-world need: selecting slices of structured data to build robust features for models. In practice, clean aggregation ensures your models are trained on accurate inputs instead of noisy or incomplete data.Tip: Always check whether the filtering should happen before or after aggregation. It’s a common mistake to use
WHEREwhenHAVINGis required. You can review the group by function to avoid any common mistakes in the real interview.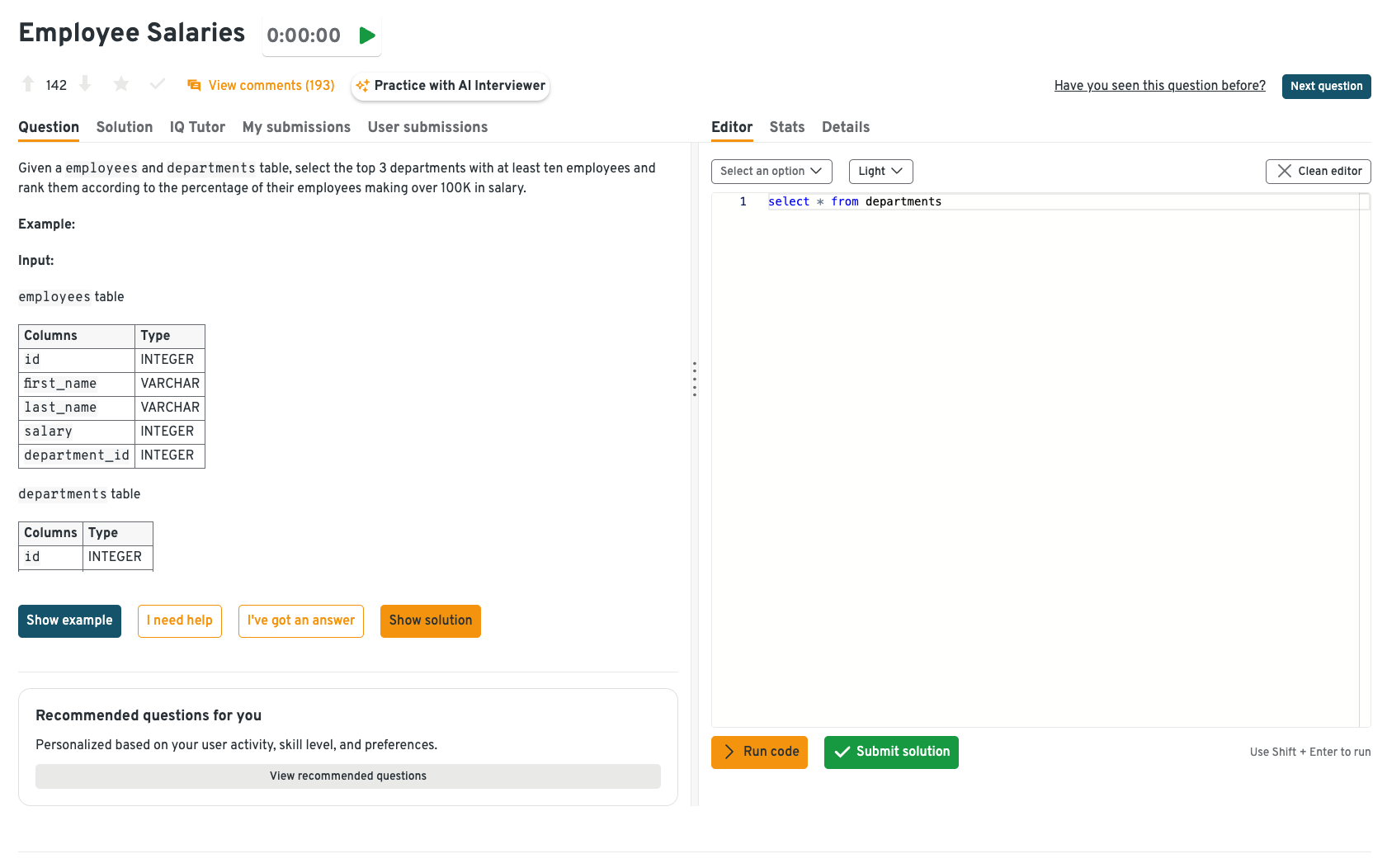
You can solve this problem on Interview Query dashboard. With schema details, input tables, and a live SQL editor with immediate feedback, this setup helps you simulate real interview conditions, including reviewing the schema, structuring queries under time pressure, and debugging on the fly. Beyond solving the problem, you also get hints, community discussions, and solutions to compare your approach against others.
Calculate the first touch attribution channel per user
This problem asks you to identify the first channel that drove a user’s interaction—an essential concept in marketing analytics. The SQL solution often uses window functions like
ROW_NUMBER()partitioned by user and ordered by timestamp, or a subquery usingMIN(event_time). For ML engineers, this is critical because attribution logic is often tied to label generation. A mistake here can cascade into biased or incorrect models, especially in personalization or recommendation systems where sequence matters.Tip: In your explanation, clarify why you chose
ROW_NUMBER()vs.MIN(). Interviewers care less about the exact syntax and more about your reasoning around event sequencing.Format an array of words into lines of maximum width
This is a classic algorithm problem, where you’re asked to take a list of words and format them into lines with a maximum width. The challenge involves spacing words correctly, justifying text, and handling tricky cases like single-word lines or uneven spacing. It tests your ability to think systematically about constraints and edge cases. For ML engineers, these skills are transferable. Data preprocessing often involves messy string manipulations or formatting steps before model training.
Tip: Talk through edge cases as you code (e.g., “What if the line only has one word?”). It shows you’re anticipating real-world complexity rather than just coding the happy path.
Find the integer removed from list X to form list Y
Here, you’re given two lists: one original, one with a single element removed. Your job is to find the missing number. The straightforward solutions include sorting and comparing, using a hash map for counts, or applying set differences. For efficiency, you can also solve it in linear time by summing both lists and subtracting, or using XOR to cancel out matching values. For ML engineers, this kind of reasoning mirrors data integrity checks, ensuring that features or labels weren’t dropped in transformation pipelines.
Tip: Highlight multiple approaches. If you first suggest sorting, mention how XOR achieves O(n) time and O(1) space. It signals awareness of trade-offs.
Find the missing number from an array spanning 0 to N
This problem gives you a sequence of integers from 0 to N with exactly one number missing. The standard solutions involve computing the expected sum of numbers (using
n*(n+1)/2) and subtracting the actual sum, or applying XOR across the full range and the given array to identify the missing element. Both approaches are efficient and elegant. In an ML context, this logic reflects real-world issues like missing indexes in one-hot encodings or mismatched categorical variables during feature engineering.Tip: Don’t just jump to code. Start by explaining the intuition: “the total sum should match unless one element is missing.” It helps interviewers see your logical process.
Compute next-day retention per user
This tests event sequencing and time logic, core to building reliable labels. Given daily login (or app open) events, compute whether a user came back the next day. Use window functions to compare each event with the next timestamp, then aggregate at the user or cohort level.
-- Postgres / BigQuery style WITH daily AS ( SELECT user_id, DATE(event_time) AS event_date FROM app_events WHERE event_name = 'login' GROUP BY user_id, DATE(event_time) ), marked AS ( SELECT user_id, event_date, CASE WHEN LEAD(event_date) OVER ( PARTITION BY user_id ORDER BY event_date ) = event_date + INTERVAL '1 day' THEN 1 ELSE 0 END AS next_day_return FROM daily ) SELECT event_date, AVG(next_day_return) AS next_day_retention_rate FROM marked GROUP BY event_date ORDER BY event_date;Tip: Always de-duplicate to one record per user per day before using
LEAD()because multiple events on the same day can inflate retention. Here’s an ultimate SQL cheat sheet to help you ace any SQL problems.7. Find the top-K frequent elements
A classic frequency problem that maps to “most common tokens,” “most used features,” or “most frequent errors” in logs. Use a hash map to count, then a min-heap to keep only the top-K in O(n log k), scalable for large datasets and interview-friendly.
from collections import Counter import heapq def top_k_frequent(nums, k): freq = Counter(nums) # O(n) heap = [] # min-heap of (count, value) for val, cnt in freq.items(): # O(m log k), m = unique items if len(heap) < k: heapq.heappush(heap, (cnt, val)) else: if cnt > heap[0][0]: heapq.heapreplace(heap, (cnt, val)) # highest frequency first return [val for cnt, val in sorted(heap, key=lambda x: (-x[0], x[1]))] # Example: # top_k_frequent([1,1,1,2,2,3,3,3,3,4], 2) -> [3, 1]Tip: After coding, explain trade-offs: heap (O(n log k)) vs. full sort (O(n log n)) vs.
Counter.most_common(k)(convenient but less explicit about complexity).
ML System and Product Design Questions
ML engineers at Adobe are expected to design scalable, low-latency systems that support personalized experiences. These questions evaluate your ability to build intelligent infrastructure involving feature stores, real-time inference, and robust experimentation pipelines. You can find more machine learning system design questions on Interview Query, where it covers questions in different categories and comprehensive solutions.
Design a classifier to predict the optimal moment to show a commercial break
This question pushes you to think about real-time engagement modeling. You’d collect training labels from user drop-off points, then design features that embed context such as show genre, ad fatigue, or user watch history. The challenge is balancing predictive accuracy with ultra-low latency: ads must trigger seamlessly without harming user experience. You’ll also need to consider feature freshness and how often retraining should occur to keep the model aligned with changing content trends.
Tip: Don’t just describe the model. Explain how you’d integrate it into the streaming pipeline with sub-second scoring guarantees. That’s the difference between a working demo and a production system.
Describe the process of building a restaurant recommendation system
Here you’re asked to design a personalized recommendation engine. A strong approach is hybrid: collaborative filtering to leverage user-item interactions, and content-based signals like cuisine, price range, and geographic location. Adobe expects you to highlight how you’d build a feature store to manage embeddings and ensure consistent serving in both training and inference. Key evaluation metrics include precision@K and recall@K, but you should also mention A/B testing for online validation.
Tip: Call out cold-start explicitly: how you’d recommend restaurants to a brand-new user. Handling this well shows depth in system design.
Design a machine learning system to minimize wrong order predictions
This scenario emphasizes cost-sensitive classification, where false positives and false negatives carry different business consequences. You’ll need to discuss strategies for labeling, monitoring live predictions, and using drift detection to spot when the model starts making more costly mistakes. A robust design would include historical feature queries to diagnose where and why errors occur. It’s less about the algorithm and more about how you build resilience into the pipeline.
Tip: Frame your solution around business impact. For example, say “a false positive costs $5 in refunds, a false negative costs $20 in churn,” and show how that shapes your loss function.
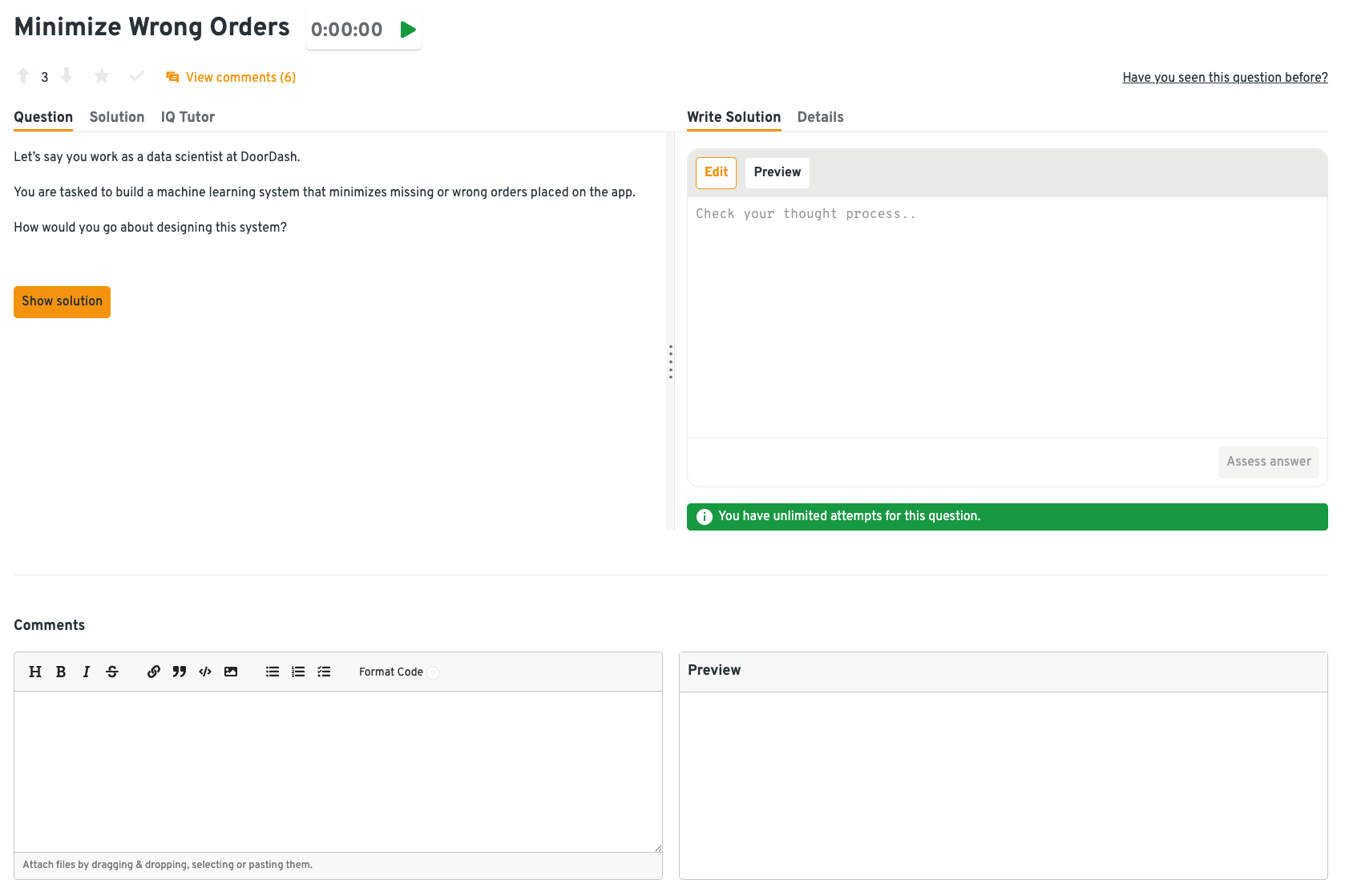
You can solve this problem using Interview Query dashboard. On the left, you can see the real interview-style prompt, while the right panel provides space to draft and refine solutions as if explaining live to an interviewer. This setup helps practice structuring answers clearly, connecting technical design to business impact, and getting feedback through peer comments.
Design a YouTube video recommendation engine
This question is a deep dive into large-scale personalization. The common approach is a two-tower architecture: one tower encodes user history, the other encodes video content. You’d describe logging pipelines for user engagement signals, continuous retraining jobs to keep embeddings fresh, and real-time inference serving millions of requests per second. Beyond accuracy, you must discuss guardrails: throttling, diversity, and frequency capping so users aren’t spammed with the same recommendations.
Tip: Emphasize feedback loops. Show how you’d monitor recommendation quality, feed new watch data back into the system, and avoid reinforcing bias (e.g., only serving viral videos).
Behavioral & Culture‑Fit Questions
Soft skills are as critical as technical skills in any Adobe Machine Learning Engineer interview. These behavioral questions are designed to evaluate your collaboration, leadership, and ownership—especially in Adobe’s cross-functional, product-driven culture.
Tell me about a time you had to convince stakeholders to trust a machine learning model.
Adobe asks this to see how you balance technical rigor with business storytelling. It evaluates whether you can translate metrics into impact, build credibility, and overcome skepticism, a core skill for driving adoption in a creative, product-first company.
Example: In a past role, I built a churn prediction model, but marketing leaders worried it was a “black box.” I ran a small pilot to prove its lift against existing heuristics and created visualizations that mapped predictions to revenue retention. Once they saw the ROI, adoption came quickly. I also added a feedback loop so stakeholders could flag false positives, which improved trust.
Tip: Industry mentors often say: “Don’t oversell the math—anchor your explanation in outcomes.” Show ROI, time saved, or improved user experience to win buy-in.
Describe a time you had to manage ambiguity in a machine learning project.
This question is about adaptability. Adobe wants engineers who can thrive when requirements aren’t clear, because ML features often evolve mid-flight. It reveals how you prioritize, experiment, and move forward without perfect information.
Example: On a personalization project, the product team initially gave only a vague goal: “make recommendations feel more relevant.” I defined a phased approach, starting with click-through as a proxy metric, then iterating toward engagement depth. By structuring small experiments and updating stakeholders weekly, we moved from ambiguity to a clear roadmap without stalling.
Tip: A proven approach is to show how you “created structure from chaos.” Walk through the frameworks or checkpoints you used to prevent drift while staying flexible.
Tell me about a time you failed and what you learned.
Failure stories test resilience and accountability. Adobe prizes engineers who take ownership, reflect, and improve, rather than those who chase perfection. It’s less about the failure itself and more about your maturity in handling it.
Example: In one rollout, my real-time scoring service slowed under unexpected traffic, causing delays in recommendations. I immediately flagged the issue, rolled back, and worked with infra to add caching and autoscaling. In the postmortem, I took responsibility and built load-testing into our pre-launch checklist. The experience made me sharper about stress-testing production systems.
Tip: Be candid. Interviewers respect honesty when paired with concrete lessons learned. As mentors often put it: “Don’t hide the failure; highlight the growth.”
Tell me about a time when you had to collaborate across teams to ship a model into production.
Adobe uses this to check how you operate in pods that include engineers, product managers, and designers. It evaluates teamwork, alignment, and your ability to navigate handoffs and dependencies.
Example: For a recommendation engine, I worked closely with data engineers to ensure data freshness and with product managers to align on success metrics. We set up shared dashboards so all teams could track performance in real time. By documenting assumptions and syncing weekly, we avoided misalignment and shipped on time.
Tip: Show that you don’t just “hand off” models. You co-own the delivery. Industry experts suggest framing collaboration as a loop: align, build, validate, iterate.
How do you handle feedback or pushback from non-technical stakeholders?
This assesses empathy and influence. Adobe wants ML engineers who can listen first, clarify misunderstandings, and adapt without being defensive. It reveals your ability to build trust with business teams.
Example: During an A/B test, product managers felt my success metric (engagement depth) was too abstract. Instead of pushing back, I asked what outcomes mattered most to them. We aligned on “average session length” as a complementary metric. By incorporating their perspective, I gained buy-in without diluting technical rigor.
Tip: Always frame feedback as “input, not opposition.” A best practice mentors share is to pause, ask clarifying questions, and reframe the conversation in shared goals.
Tell me about a time you balanced model accuracy with system performance.
Adobe ML engineers work on products like Photoshop and Firefly, where users expect real-time responses. This question evaluates whether you can weigh trade-offs between model sophistication and latency in production.
Example: In a project on real-time personalization, my gradient boosting model outperformed logistic regression but added ~200ms latency. I presented both options to product leads and recommended a hybrid, using a lightweight model for online inference and running the heavier model offline for periodic re-ranking. This balance kept latency low while preserving accuracy gains.
Tip: Always connect performance trade-offs back to user experience. Sometimes, shaving 100ms off latency can matter more than a 2% lift in accuracy.
Describe a time you had to advocate for responsible AI practices.
Adobe is vocal about ethical AI, especially with generative products like Firefly. Interviewers want to see that you understand bias, fairness, and transparency, and that you’ve taken ownership of these considerations in your work.
Example: While building a recommendation model, I noticed that results overexposed a subset of content creators. I flagged this during review and proposed adding fairness constraints. We also built a monitoring dashboard to track exposure balance. My team appreciated that this not only improved fairness but also trust in the product.
Tip: Frame responsible AI as both an ethical duty and a business advantage. Showing you can articulate both perspectives sets you apart.
How to Prepare for an Adobe Machine Learning Engineer Interview
Map Adobe Product Cases to Likely ML‑Design Prompts
Adobe interviewers often ground design questions in the company’s own products. That means you could be asked how you’d design an image generation pipeline for Firefly, a personalization system in Adobe Sensei, or fraud detection for the Experience Platform. To prepare, build a personal “case library” of 3–4 scenarios and practice walking through them end-to-end. Start with problem framing, outline the data pipeline (batch vs. streaming), discuss feature store usage, explain your modeling choices, and finish with evaluation and monitoring. The key is to show that you’re not just coding models; you’re designing production-ready systems that deliver user and business impact.
Tip: Write a one-page “design card” for each case (problem → architecture → risks → metrics) and rehearse it until you can deliver it clearly in under five minutes.
Rehearse STAR Stories
Adobe emphasizes cross-functional collaboration and bottom-up innovation. That means interviewers will press on how you’ve worked with PMs, designers, or infra engineers, and how you’ve championed new ideas. Prepare two STAR-format stories in advance: one where you led a collaborative effort to ship a model into production, and another where you drove an innovative ML solution from idea to prototype to rollout. Be specific about your role, the challenges you faced, and the measurable outcomes you achieved. This preparation ensures you can respond confidently without rambling.
Tip: Industry mentors recommend opening each STAR story with a “headline sentence” (e.g., “We cut rendering latency 25% by batching inference”). It hooks attention before you dive into details.
Dry-Run a 60-minute Design of Real-Time Inference
Mid-to-senior candidates are often asked to design low-latency ML systems that power live user experiences. Practice running through an entire 60-minute mock: data ingestion (streaming vs. batch), transformations, storing and serving features, model deployment strategies, caching (e.g., Redis), and monitoring. Be ready to discuss trade-offs like throughput vs. latency, online vs. offline learning, and cost vs. accuracy. The ability to narrate a structured design under time pressure is one of the clearest signals interviewers look for at Adobe.
Tip: Break your design session into time blocks (5 minutes clarifying scope, 15 on data/features, 20 on serving/latency, 10 on evaluation, 10 on risks). This pacing keeps you from going too deep in one area.
Practice Coding Problems that Mix DP + Graph
Every Adobe ML engineer loop includes at least one algorithm round. These often blend dynamic programming and graph-based logic, such as shortest path with constraints or scheduling tasks with dependencies. You’ll be judged on clarity, correctness, and efficiency, but also on how you communicate your thought process. Start by restating the problem, identifying edge cases, outlining your approach, and only then begin coding. Afterward, walk through complexity analysis and possible optimizations. Remember: clean, maintainable code is just as important as speed.
Tip: Practice narrating out loud. Saying, “I’ll use BFS because the graph is unweighted” shows structured thinking and helps interviewers follow your logic.
Simulate A Metrics-Driven Post-Launch Review
Adobe ML engineers aren’t just responsible for building models. They also need to measure impact after launch. Practice walking through a “mock” post-launch review: define the north-star metric (e.g., user engagement or retention), guardrail metrics (like latency or fairness), review A/B test results, and diagnose anomalies. Then propose data-driven refinements to improve the model or product experience. This demonstrates product sense and your ability to close the loop from model design to business outcomes.
Tip: Use a simple template—Hypothesis → Metrics → Results → Root Cause → Next Step, and rehearse it with one of your past projects. It shows you can think like a product owner, not just an engineer. You can practice your approach with a 1-on-1 mock interview, where you can get instant feedback from professionals to ace the real interview.
FAQs
What Is the Average Adobe Machine Learning Engineer Salary?
Average Base Salary
Average Total Compensation
Here’s what the data shows about the Adobe machine learning engineer salary in the U.S., including base, bonus, equity, and how level shift things.
- Overall: The total compensation ranges roughly from $167K to $245K per year, with a median of $201K, including 75.6% of base pay, 6.8% of bonus, and 17.6% of stock.
- Entry-level / New Grad: Total compensation ranges from $120K to $228K annually, depending heavily on location and scope of work.
Is ML Engineer an entry-level role?
Yes, some ML Engineer positions are open to entry-level candidates, but they usually require a strong foundation in computer science, statistics, and applied ML. At Adobe, entry-level roles often start under titles like Machine Learning Engineer I or Member of Technical Staff (MTS 1). Candidates are expected to demonstrate coding fluency, algorithmic thinking, and familiarity with core ML concepts, even if they don’t have years of industry experience.
Can I switch from data science to machine learning engineering?
Absolutely. Many ML engineers at Adobe come from data science backgrounds. The main shift is moving from analysis and experimentation into production systems. That means investing in software engineering skills (e.g., APIs, distributed systems, MLOps) and learning how to deploy and monitor models at scale. Adobe values candidates who can bridge the gap between modeling and infrastructure.
What does a machine learning engineer at Adobe do?
Adobe ML engineers design and deploy models that power flagship products like Photoshop (content-aware fill), Firefly (generative AI), and Adobe Experience Platform (personalization, fraud detection). The role covers data pipelines, model training, feature store integration, and real-time inference services. Engineers collaborate with product managers, designers, and data scientists to ensure models deliver measurable value to millions of users.
Is ML full of coding?
Yes, coding is a major part of the job. While data scientists may spend more time on exploratory analysis or modeling, ML engineers focus on writing production-grade code. At Adobe, you’ll be expected to implement algorithms, optimize inference pipelines, integrate with APIs, and maintain large-scale ML services. Strong skills in Python, Java/Scala, SQL, and ML frameworks (TensorFlow, PyTorch) are essential.
Is it hard to become a machine learning engineer at Adobe?
Yes, it’s competitive. Adobe receives thousands of applications, and the ML Engineer loop tests algorithms, system design, ML fundamentals, and product sense. However, it’s not impossible: candidates who show end-to-end thinking (from data to deployment) and strong collaboration skills stand out. The key is demonstrating that you can not only build models but also make them reliable, scalable, and impactful inside Adobe’s products.
Conclusion
With focused preparation, the Adobe machine learning engineer interview stops feeling unpredictable. By practicing real-time inference design, tackling DP + graph coding drills, and rehearsing STAR stories for collaboration, you’ll build the exact skills Adobe interviewers test for.
Ready to put this into practice? Start with our full Adobe interview guide hub for curated questions, strategies, and walkthroughs. Then dive deeper with our role-specific guides, like the Adobe data engineer and Adobe data scientist guides, to expand your prep. Nervous about the interview? Practice in a safe space first. Book a 1-on-1 mock interview with an expert and get feedback on your coding, design, and behavioral answers before the real thing.
Adobe Interview Questions
| Question | Topic | Difficulty | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Medium | |||||||||||||||
You’re given a table that represents search results from searches on Facebook. The Write a query to get the percentage of search queries where all of the ratings for the query results are less than a rating of 3. Please round your answer to two decimal points. Example: Input:
Output:
| ||||||||||||||||
Machine Learning | Medium | |||||||||||||||
Data Structures & Algorithms | Medium | |||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences