
Cumulative SUM in SQL: Complete Guide to Running Totals


Introduction
When analyzing data in SQL, it’s often not enough to just look at daily or transactional numbers—you also need to see how values build up over time. That’s where the cumulative sum (also called a running total) comes in. It lets you track trends like revenue growth, sales momentum, or customer engagement by continuously adding values row by row.
In this guide, we’ll break down everything you need to know about cumulative sums in SQL: what they are, why they matter in business analysis, and how to calculate them using different methods like window functions, self-joins, and subqueries. We’ll also explore advanced patterns such as partitioned totals, rolling windows, and interview-style SQL problems, along with performance tips and common troubleshooting fixes.
Whether you’re preparing for a data interview or building dashboards for real-world use cases, mastering cumulative sums will help you transform raw data into meaningful insights.
What Is a Cumulative SUM in SQL?
At its core, a cumulative sum is the total amount accumulated from the beginning of your dataset up to the current row. It shows how values build over time and is a common way to analyze trends in revenue, sales, or spend.
Think of cumulative sum formula step by step:
- Row 1 = just that row’s value.
- Row 2 = row 1 + row 2.
- Row 3 = row 1 + row 2 + row 3.
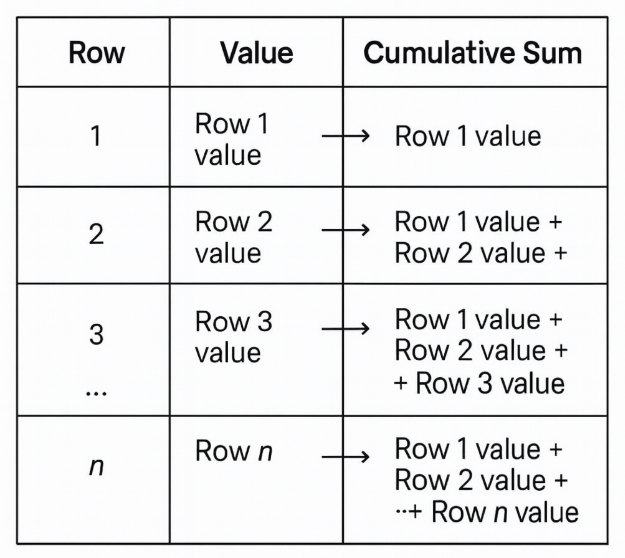
By row n, the cumulative total SQL has added everything from row 1 through row n. This is the fundamental cumulative sum meaning: it grows with each new row, reflecting the accumulated history of your data.
Differences between Cumulative Sum, Running Total, and Rolling Sum
| Term | Definition | Key Use Case |
|---|---|---|
| Cumulative Sum | Total accumulated from the first row up to the current row. Each new row adds on top of the previous total (may decrease if negatives like refunds exist). | Tracking overall growth or long-term totals. |
| Running Total | Another term for cumulative sum—calculated row by row. | Often used interchangeably with cumulative sum. |
| Rolling Sum | Considers only a fixed window of time or rows (e.g., last 7 days). As new rows enter, older rows drop out. | Spotting short-term patterns or trends. |
Why Use a Cumulative SUM? (Business Value & Use Cases)
A cumulative sum is more than just a calculation, it’s a way to reveal the bigger picture in your data. While daily or transactional numbers can be noisy, a cumulative value smooths things out and helps you see how metrics build up over time. This makes it a powerful tool for businesses scenarios that need to track growth, spending, or progress against goals.
Spotting Trends
By adding values continuously, cumulative sums highlight long-term movements that daily snapshots often hide:
- Revenue growth: Visualize how income adds up across weeks or months and compare it to targets.
- Sales momentum: Measure whether sales are accelerating, holding steady, or slowing down.
- Customer churn: Compare cumulative cancellations against new signups to monitor net retention.
- Inventory tracking: Keep a running view of stock levels and cumulative addition to anticipate shortages or oversupply.
Real-World Business Examples
- Cumulative salary in SQL: Payroll teams use it to calculate each employee’s year-to-date salary, ensuring accurate tax deductions and compliance.
- Cumulative sales in SQL: Sales and marketing teams track total sales from a product launch or campaign to measure performance.
- Cumulative spend: Procurement and finance monitor total spending with vendors to avoid budget overruns.
- Cumulative addition of users or transactions: Product managers use it to track adoption curves or transaction growth over time.
In short, a cumulative total SQL query provides continuous insight into business health. Whether it’s monitoring cumulative salary in SQL, analyzing cumulative sales in SQL, or managing cumulative spend, the cumulative approach turns raw data into actionable trends that drive smarter decisions.
Methods to Calculate a Cumulative SUM in SQL
There are several ways to compute a cumulative sum in SQL, and the best choice often depends on the database engine you’re using and the size of your data. Below are three common approaches—ranging from the modern and efficient (window functions) to more traditional methods (self-joins and correlated subqueries).
Method 1 — Window Function (SUM() OVER)
The most efficient and widely used approach is to use a SQL cumulative sum window function. With SUM() OVER, you can create a running total ordered by a specific column, such as date or transaction ID.
Basic Running Total
SELECT
order_date,
amount,
SUM(amount) OVER (ORDER BY order_date) AS running_total
FROM orders;
This query generates a window function cumulative sum across all rows in date order.
Partitioned cumulative sums
SELECT
customer_id,
order_date,
amount,
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
) AS cumulative_by_customer
FROM orders;
Here, the running total resets for each customer. This is the SQL cumulative sum group by equivalent.
Rolling 7-day windows
SELECT
order_date,
amount,
SUM(amount) OVER (
ORDER BY order_date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS rolling_7day
FROM orders;
This calculates a SQL rolling sum last 7 days, letting you analyze short-term performance rather than an all-time total.
You can also apply this logic to create a SQL cumulative count by replacing SUM(amount) with COUNT(*) OVER.
Method 2 — Self Join
Before window functions were widely supported, a self join was the go-to way to find cumulative sums.
SELECT o1.order_date,
o1.amount,
SUM(o2.amount) AS cumulative_sum
FROM orders o1
JOIN orders o2
ON o2.order_date <= o1.order_date
GROUP BY o1.order_date, o1.amount
ORDER BY o1.order_date;
This query computes the SQL cumulative sum of previous rows by joining each row with all rows before it.
- Pros: Works even in older SQL versions that don’t support window functions.
- Cons: Much slower on large datasets because every row must join to all earlier rows.
If you’re wondering how to find cumulative sum in SQL without OVER, this is the standard workaround.
Method 3 — Correlated Subquery
Another traditional approach is to use a correlated subquery, where each row calculates its cumulative sum by summing over earlier rows.
SELECT
o1.order_date,
o1.amount,
(
SELECT SUM(o2.amount)
FROM orders o2
WHERE o2.order_date <= o1.order_date
) AS cumulative_sum
FROM orders o1
ORDER BY o1.order_date;
This is often the simplest to write when learning how to calculate cumulative sum in SQL, but it’s also the least efficient for large tables.
You may see this method used in practice when quick scripts or legacy systems don’t support modern SQL features. It’s a handy way to express cum sum SQL logic without window functions.
Comparison Table of Methods
When deciding how to calculate a cumulative sum, it’s important to balance performance, readability, and compatibility. Below is a comparison of the three most common SQL cumulative sum methods.
| Method | Performance | Readability | Compatibility | Notes |
|---|---|---|---|---|
| Window Function (SUM() OVER) | Best SQL cumulative sum performance, handles millions of rows efficiently | High – concise and intuitive | Supported in modern SQL engines (Postgres, SQL Server, Oracle, MySQL 8+) | Ideal for production and analytics dashboards; recommended way to compute a SQL cumulative total |
| Self Join | Slower – O(n²) joins make it heavy on large tables | Medium – logic is clear but verbose | Works in older systems like MySQL 5.7 that lack window functions | Useful fallback when window functions aren’t available; calculates SQL cumulative total using previous rows |
| Correlated Subquery | Slowest – recalculates totals per row, expensive at scale | High – easiest to read for small queries | Universal – works in almost all SQL dialects | Handy for learning or small datasets; not recommended for production SQL cumulative sum methods |
SQL Dialect-Specific Examples for Cumulative Sum
Not every SQL engine implements cumulative sums the same way. Most modern platforms follow the ANSI SQL window function standard (SUM() OVER (ORDER BY …)), while older versions or certain vendors require dialect-specific workarounds.
The table below compares the syntax and highlights the nuances for MySQL (plus a MySQL 5.7 workaround), PostgreSQL, SQL Server, Oracle, SQLite, Snowflake, and Databricks/Spark.
| SQL Dialect | Syntax Example | Highlight/Notes |
|---|---|---|
| MySQL 8.0+ | SUM(amount) OVER (ORDER BY order_date) AS cum_sum |
Native window functions supported since 8.0 |
| MySQL 5.7 | SELECT o1.order_date, o1.amount, (SELECT SUM(o2.amount) FROM orders o2 WHERE o2.order_date <= o1.order_date) AS cum_sum FROM orders o1 ORDER BY o1.order_date; |
No window functions; use correlated subquery or user-defined variables |
| PostgreSQL | SUM(amount) OVER (ORDER BY order_date) AS cum_sum |
ANSI-compliant, clean syntax |
| SQL Server | SUM(amount) OVER (ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) |
Needs explicit frame clause |
| Oracle | SUM(amount) OVER (ORDER BY order_date) AS cum_sum |
Widely used in financial/analytics queries |
| SQLite (3.25+) | SUM(amount) OVER (ORDER BY order_date) AS cum_sum |
Older builds need self-joins or app logic |
| Snowflake | SUM(amount) OVER (ORDER BY order_date) AS cum_sum |
Cloud scalability, ideal for large analytics |
| Databricks/Spark | SUM(amount) OVER (ORDER BY order_date) AS cum_sum |
Efficient for big data pipelines |
Advanced Window Function Techniques
Cumulative sums get even more powerful when combined with window function features like PARTITION BY, rolling windows, and conditional logic. These advanced techniques are widely used in analytics dashboards, customer lifecycle reporting, and financial metrics, since they let you answer deeper business scenario questions with concise SQL.
Partitioned Totals (per customer, region, etc.)
Sometimes you don’t just want a global running total—you want it grouped by customer, product, or region. This is where PARTITION BY comes in. It effectively resets the total for each group, which is why many people call it the SQL cumulative sum group by approach. In other words, you’re creating a SQL cumulative sum partition by column.
-- Cumulative sales per customer by date
SELECT
customer_id,
order_date,
amount,
SUM(amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_sales_customer
FROM orders
ORDER BY customer_id, order_date;
This is especially useful when tracking metrics like revenue by region or spend per customer over time.
Rolling Windows (last 7 or 30 days)
While a cumulative sum keeps growing from the start of the dataset, sometimes you need a sliding window view—like the last 7 days or last 30 days. That’s where a rolling total in SQL comes in. With window functions, you can write both a SQL rolling sum by row count and a time-based SQL rolling sum last 7 days.
-- 7-row rolling sum (assumes one row per day)
SELECT
order_date,
amount,
SUM(amount) OVER (
ORDER BY order_date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS rolling_7row
FROM orders;
-- 7-day rolling sum (true time window; engine must support RANGE with INTERVAL)
SELECT
order_date,
amount,
SUM(amount) OVER (
ORDER BY order_date
RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW
) AS rolling_7day
FROM orders;
-- 30-day rolling sum
SELECT
order_date,
amount,
SUM(amount) OVER (
ORDER BY order_date
RANGE BETWEEN INTERVAL '29' DAY PRECEDING AND CURRENT ROW
) AS rolling_30day
FROM orders;
This pattern is ideal when you want to measure weekly sales, 30-day engagement, or other short-term performance instead of the all-time cumulative number.
Combining with CASE (flag thresholds like $1K spend)
Window functions can also combine with conditional logic to create more dynamic calculations. By using a CASE WHEN expression inside your cumulative query, you can introduce flags, thresholds, or conditional counters that adapt to business rules.
For example, you might track how many promo orders a customer has placed so far or flag the first time their lifetime spend crosses $1,000. This pattern is widely used in reporting because it naturally supports scenarios like a SQL cumulative count of specific events or building thresholds with a SQL CASE WHEN with cumulative sum. In practice, it lets you move beyond a simple running total and create tailored cumulative metrics that answer deeper business questions.
-- Flag the first date each customer crosses $1,000 in cumulative spend
WITH per_day AS (
SELECT
customer_id,
order_date,
SUM(amount) AS daily_amount
FROM orders
GROUP BY customer_id, order_date
),
with_cum AS (
SELECT
customer_id,
order_date,
daily_amount,
SUM(daily_amount) OVER (
PARTITION BY customer_id
ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_spend
FROM per_day
)
SELECT
customer_id,
order_date,
daily_amount,
cum_spend,
CASE WHEN cum_spend >= 1000 THEN 1 ELSE 0 END AS crossed_1k_flag
FROM with_cum
ORDER BY customer_id, order_date;
-- Conditional cumulative count: how many promo orders so far per customer
SELECT
customer_id,
order_date,
promo_applied,
SUM(CASE WHEN promo_applied = TRUE THEN 1 ELSE 0 END) OVER (
PARTITION BY customer_id
ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_promo_orders
FROM orders
ORDER BY customer_id, order_date;
This technique is powerful for customer lifecycle tracking, loyalty program tiers, or identifying the first time a customer crosses a spend threshold.
With these patterns, you can go beyond a basic running total and use window functions to build SQL cumulative sum group by, SQL rolling sum last 7 days, or even conditional SQL cumulative count metrics tailored to your business needs.
Interview-Style Examples & Practice Problems
This section presents common interview problems using cumulative sums, rolling totals, and conditional resets. Each example tests partitioning, ordering, or window logic in SQL—core skills for data analytics and data engineering interviews.
1 . Write a SQL query to calculate the cumulative sales by product and date
Use a window function for product-level running totals: pre-aggregate to one row per (product_id, date), then compute SUM(daily_sales) OVER (PARTITION BY product_id ORDER BY date) for the cumulative sum. This keeps the window lean and resets per product automatically. If multiple rows can share a date, add a deterministic tiebreaker (e.g., ORDER BY date, min_id). This is a staple SQL cumulative sum pattern testing partitioning, ordering, and data grain.
WITH daily_sales AS (
SELECT
product_id,
date,
SUM(price) AS daily_sales
FROM sales
GROUP BY product_id, date
)
SELECT
product_id,
date,
SUM(daily_sales) OVER (
PARTITION BY product_id
ORDER BY date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cumulative_sum
FROM daily_sales
ORDER BY product_id, date;
2 . Query the running total of sales for each product since the last restocking eventUse a window function with a reset flag: mark restocks, build grp = SUM(is_restock) OVER (PARTITION BY product_id ORDER BY date), then run SUM(sales) OVER (PARTITION BY product_id, grp ORDER BY date). Pre-aggregate daily sales and add a tiebreaker so resets apply correctly. This tests partitioning, ordering, and reset logic in SQL cumulative sums.
WITH last_restock AS (
SELECT product_id,
max(restock_date) AS restock_date
FROM restocking
GROUP BY product_id
)
SELECT p.product_name,
s.date,
sum(s.sold_count) OVER(PARTITION BY p.product_id, lr.restock_date
ORDER BY s.date) AS sales_since_last_restock
FROM sales s
JOIN products p ON p.product_id = s.product_id
JOIN last_restock lr ON p.product_id = lr.product_id
WHERE s.date >= lr.restock_date
ORDER BY p.product_id
3 . Write a query to calculate the daily cumulative totals that reset each day
Use a window function for monthly running totals: SUM(cnt) OVER (PARTITION BY YEAR(dt), MONTH(dt) ORDER BY dt). First pre-aggregate to daily counts to keep the window lean. Partitioning by year and month ensures the cumulative resets each month. Add a date tiebreaker if needed for same-day duplicates. This is a classic SQL cumulative sum by month interview pattern.
WITH daily_total AS (
SELECT
DATE(created_at) AS dt
, COUNT(*) AS cnt
FROM users
GROUP BY 1
)
SELECT
t.dt AS date
, SUM(u.cnt) AS monthly_cumulative
FROM daily_total AS t
LEFT JOIN daily_total AS u
ON t.dt >= u.dt
AND MONTH(t.dt) = MONTH(u.dt)
AND YEAR(t.dt) = YEAR(u.dt)
GROUP BY 1
4 . Write a query to calculate the three-day rolling sum of transactions per account
Use a rolling window join to calculate a moving average: pre-aggregate daily deposits, then self-join each day to the prior three days using date conditions. Compute AVG(total_deposits) grouped by day to get the 3-day rolling average. This pattern tests moving window logic without native window functions.This probes your understanding of rolling vs. cumulative windows in interview questions SQL cumulative sum.
WITH valid_transactions AS (
SELECT DATE_FORMAT(created_at, '%Y-%m-%d') AS dt
, SUM(transaction_value) AS total_deposits
FROM bank_transactions AS bt
WHERE transaction_value > 0
GROUP BY 1
)
SELECT vt2.dt,
AVG(vt1.total_deposits) AS rolling_three_day
FROM valid_transactions AS vt1
INNER JOIN valid_transactions AS vt2
-- set conditions for greater than three days
ON vt1.dt > DATE_ADD(vt2.dt, INTERVAL -3 DAY)
-- set conditions for max date threshold
AND vt1.dt <= vt2.dt
GROUP BY 1
5 . Calculate the 3-day rolling average of steps for each user
Use date-shift self-joins to build a 3-day window per user without window functions. Join t1 (anchor day) to t2 and t3 where their dates are 1 and 2 days earlier. Then average the three steps columns. With LEFT JOINs, missing prior days yield NULLs—use COALESCE and adjust the denominator if you want a partial-window average. The window-function alternative is AVG(steps) OVER (PARTITION BY user_id ORDER BY date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW).This variation extends the same windowing fundamentals that underpin most SQL interview cumulative sum tasks.
SELECT t1.user_id,
t1.date,
t1.steps as t1steps,
t2.steps as t2steps,
t3.steps as t3steps,
ROUND((t1.steps + t2.steps + t3.steps)/3, 0) AS avg_steps
FROM daily_steps t1
LEFT JOIN daily_steps t2
ON t1.user_id = t2.user_id
AND t1.date = date_add(t2.date, interval 1 DAY)
LEFT JOIN daily_steps t3
ON t1.user_id = t3.user_id
AND t1.date = date_add(t3.date, interval 2 DAY)
Performance Optimization Tips for SQL Cumulative Sum
Getting great SQL cumulative sum performance is mostly about feeding your window functions well with the right data shape, right indexes, right frames.
Here are simple strategies to optimize cumulative sum queries, each paired with a small SQL snippet:
Index ORDER BY and PARTITION BY columns
Indexing the columns you use in your window function makes scans faster. The first step is to make sure the columns used in your ORDER BY and PARTITION BY clauses are indexed.
For example, if you’re calculating a running total per customer by date, an index on (customer_id, order_date) allows the database to sort efficiently. Without it, you risk repeated sorts and slower execution times.
It’s also important to add a deterministic tie-breaker such as order_id when multiple rows share the same timestamp. Neglecting this detail can introduce cumulative sum errors because the results may differ depending on how the engine orders rows internally.
-- Index for customer cumulative sales by date
CREATE INDEX idx_customer_date ON orders(customer_id, order_date);
SELECT customer_id, order_date,
SUM(amount) OVER (PARTITION BY customer_id ORDER BY order_date) AS cum_sales
FROM orders;
Use Window Functions (not self-joins)
Window functions almost always outperform older approaches like self-joins or correlated subqueries. The reason is simple: a windowed cumulative sum requires only one pass over a sorted dataset, while self-joins and subqueries repeatedly rescan earlier rows, leading to quadratic performance as the table grows.
In practical terms, this means a query that runs in seconds with a window function could take minutes or hours with a self-join once the table reaches millions of rows. Modern SQL engines are also designed to parallelize window functions, making them scale far better than the alternatives.
-- Preferred (fast)
SELECT order_date,
SUM(amount) OVER (ORDER BY order_date) AS cum_sum
FROM orders;
-- Slow (avoid): self-join
SELECT o1.order_date,
(SELECT SUM(o2.amount)
FROM orders o2
WHERE o2.order_date <= o1.order_date) AS cum_sum
FROM orders o1;
Frame Your Window Carefully
Always define the frame so the database knows how far back to look.
For most cumulative totals, you can explicitly write ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. This keeps the query efficient and avoids unnecessary overhead.
For rolling windows like “last 7 days” or “last 30 days,” it’s often best to pre-aggregate your data at the daily level first and then apply the window. This reduces the amount of raw data each query needs to process and ensures the SQL rolling sum logic is applied to the correct level of granularity.
-- Cumulative from start
SUM(amount) OVER (
ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_sum
-- Rolling 7-day sum (engine must support RANGE)
SUM(amount) OVER (
ORDER BY order_date
RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW
) AS rolling_7day
Avoid Common Anti-patterns
Using user-variable hacks in MySQL 5.7 for production workloads is fragile and can give inconsistent results. Similarly, mixing granularities such as applying a cumulative sum to line-item and daily rollups in the same window creates unpredictable results. Instead, pre-aggregate to the level you actually need before applying the cumulative step.
Pre-aggregate for Rolling Windows
Aggregate to daily totals first, then compute the rolling sum.
WITH daily_sales AS (
SELECT order_date, SUM(amount) AS total
FROM orders
GROUP BY order_date
)
SELECT order_date,
SUM(total) OVER (
ORDER BY order_date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS rolling_7day
FROM daily_sales;
Add Deterministic Ordering
Tie-break rows with identical dates to avoid inconsistent results.
SELECT order_date, order_id, amount,
SUM(amount) OVER (ORDER BY order_date, order_id) AS cum_sum
FROM orders;
Avoid User-Variable Hacks (MySQL 5.7)
Instead of fragile variables, upgrade to MySQL 8.0+ and use window functions.
-- Bad (MySQL 5.7 hack)
SELECT @cum := @cum + amount AS cum_sum
FROM orders, (SELECT @cum := 0) vars;
-- Good (MySQL 8.0+)
SELECT order_date,
SUM(amount) OVER (ORDER BY order_date) AS cum_sum
FROM orders;
Quick checklist to optimize SQL cumulative sum
- Index
ORDER BYandPARTITION BYcolumns for faster scans - Use
SUM() OVERinstead of self-joins or correlated subqueries - Keep your window frame explicit (
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) - Pre-aggregate to daily or monthly levels before applying cumulative logic
- Add deterministic ordering (e.g.,
order_id) to prevent cumulative sum errors - Avoid user-variable hacks in production; prefer native window functions
By following these practices, you’ll not only improve SQL cumulative sum performance but also reduce the likelihood of subtle errors in production systems. In short, if you want to truly optimize SQL cumulative sum queries, treat them as strategic calculations, not just one-off aggregates.
Common Errors & Troubleshooting tips for SQL Cumulative Sum
Even though a cumulative sum looks simple, there are a few pitfalls that regularly trip people up. If you’ve ever run into cumulative sum errors or found your SQL cumulative sum not working as expected, chances are it’s due to one of these common issues.
1. Missing ORDER BY in OVER()
Without ORDER BY, the database doesn’t know the sequence to accumulate values and you just get the grand total on every row. This small oversight is perhaps the most common cumulative sum mistake in SQL.
-- Wrong: no ORDER BY
SELECT order_id, amount,
SUM(amount) OVER () AS cum_sum
FROM orders;
-- Fix: add ORDER BY
SELECT order_id, amount,
SUM(amount) OVER (ORDER BY order_id) AS cum_sum
FROM orders;
2. Forgetting PARTITION BY
If you need cumulative sales per customer but don’t include PARTITION BY customer_id, the query will keep one global running total instead of resetting for each customer. This leads to misleading results that can be hard to spot if you’re not careful.
-- Wrong: no partition by customer
SELECT customer_id, order_date, amount,
SUM(amount) OVER (ORDER BY order_date) AS cum_sum
FROM orders;
-- Fix: reset per customer
SELECT customer_id, order_date, amount,
SUM(amount) OVER (
PARTITION BY customer_id ORDER BY order_date
) AS cum_sum
FROM orders;
3. Confusing ROWS vs RANGE
Using ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW is usually the safest for a cumulative total, because it clearly tells the database to add everything up to the current row. If you accidentally use RANGE without intervals, the database may include rows with equal sort values in ways you didn’t intend, causing off-by-one errors in your running totals.
-- Safer: ROWS frame
SUM(amount) OVER (
ORDER BY order_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_sum
If you mistakenly use RANGE with duplicate dates, all tied rows may be counted together unexpectedly.
4. Not Handling Ties & NULLs
If multiple rows have the same timestamp and you don’t add a secondary sort key (like order_id), the cumulative sum can vary from run to run. Null values can also cause problems—depending on your SQL dialect, they may break the accumulation or simply be ignored. To avoid these headaches, coalesce nulls to zero with COALESCE(amount, 0) and always ensure you have a deterministic order.
-- Add deterministic ordering
SUM(COALESCE(amount, 0)) OVER (
ORDER BY order_date, order_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_sum
In short, if your SQL cumulative sum is not working, check for these issues first: missing ORDER BY, missing PARTITION BY, confusion between ROWS and RANGE, or unhandled ties and nulls. Most cumulative sum errors boil down to one of these patterns, and once you know them, you’ll avoid the most common mistakes in SQL cumulative sum queries.
FAQ (People Also Ask)
What’s the difference between running sum and cumulative sum?
There’s no real difference—running total and cumulative sum are two names for the same concept. Both mean adding values from the start of the dataset up to the current row. In SQL, you’ll typically use SUM() OVER to achieve this. If you’re searching online, look for both terms since guides might use difference cumulative sum vs running total interchangeably.
How do I calculate cumulative sum in MySQL < 8.0?
Older MySQL versions don’t support window functions, so you need workarounds. A common option is user-defined variables, where you increment a counter row by row. Another option is a self-join, though this is slower. For example, a MYSQL cumulative sum pre 8.0 query might look like:
SET @total := 0;
SELECT
order_date,
amount,
(@total := @total + amount) AS cum_sum
FROM orders
ORDER BY order_date;
How do I restart cumulative sum by month?
If you want the running total to reset every calendar month, you can partition by both year and month. This is the typical pattern for SQL cumulative sum by month:
SELECT
YEAR(order_date) AS yr,
MONTH(order_date) AS mon,
order_date,
amount,
SUM(amount) OVER (
PARTITION BY YEAR(order_date), MONTH(order_date)
ORDER BY order_date
) AS monthly_cum_sum
FROM orders;
Are cumulative sums slow?
Window functions are designed for efficiency, so in modern engines they’re usually fast. Performance problems happen when you use self-joins or correlated subqueries, which can cause cumulative sum performance issues on large datasets. To optimize, index your partition/order keys, aggregate data before applying the window, and use deterministic ordering.
How do I calculate a cumulative count instead of sum?
Replace SUM() with COUNT() inside the window function. This is a common pattern when you want to count rows instead of adding values, often called a SQL cumulative count:
SELECT
order_date,
COUNT(*) OVER (ORDER BY order_date) AS running_count
FROM orders;
Why do I need OVER() in SQL cumulative sum?
The OVER() clause tells SQL to treat the aggregate function as a windowed calculation rather than collapsing rows into a single result. Without it, SUM(amount) just gives one number for the whole table. With it, you get row-by-row accumulation—a proper SQL cumulative sum OVER query.
Key Takeaways & Next Steps
If you’ve followed this cumulative sum SQL tutorial, you now know that there are multiple ways to calculate running totals, but not all methods are equal. The best method depends on your SQL engine and dataset size.
In practice, window functions are the preferred modern approach. They’re fast, expressive, and supported by most major databases (Postgres, SQL Server, Oracle, MySQL 8+, Snowflake, etc.). Self-joins and correlated subqueries still work but are better reserved for legacy engines or small datasets.
To apply SQL cumulative sum best practices in your own work, remember:
- Always index
ORDER BYandPARTITION BYcolumns for performance. - Use
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWfor clarity. - Pre-aggregate to the right grain (daily, monthly) before applying cumulative logic.
- Test for edge cases like ties and nulls to avoid subtle errors.
Practice Next
Ready to nail your next SQL interview? Start with our SQL Question Bank to practice real-world scenario questions used in top interviews, questions. Sign up for Interview Query to test yourself with Mock Interviews today.
If you want role-specific SQL prep, browse tailored hubs like SQL for Data Analysts and Data Scientist SQL Questions. Pair with our AI Interview Tool to sharpen your storytelling.
Explore more SQL guides to strengthen your foundation: