
Top 10 Healthcare Data Science and ML Projects (Updated for 2025)


Overview
Neural networks and machine learning have long revolutionized how we utilize software and improved industry standards to the extent that we barely recognize its forms and end products. However, while healthcare machine-learning projects have expanded alongside other industries, they had a tough start in the medical field.
Due to restrictive data collection methods and ethical concerns, developing a healthcare machine learning project is too intimidating and challenging for many developers.
Before discussing healthcare machine learning projects, we must understand the considerations for moving forward with ethics in mind and ensure we do not alienate or reaffirm biases.
Navigate various Healthcare Data Science and ML Projects in this article:
HIPAA: Data Collection and the Healthcare Industry

While the collation of datasets is done with data privacy laws in mind, the healthcare industry faces another layer of patient data protection laws. In the United States, patient information is protected through the Health Insurance Portability and Accountability Act of 1996 (HIPAA).
Before identifying potential healthcare machine learning projects, we must ensure that the data we plan to gather complies with the HIPAA standard. HIPAA considers projects involving patient data to be covered by the guidelines. However, there are notable exceptions which you can use as leverage to gather ethically sourced patient data:
- When gathering patient history and data, one MUST inquire about the involved patient’s willingness to disclose their data and to what extent.
- There is a certain degree of leeway given to data scientists like us for research and operations.
- When gathering information for research, there are exemptions, and a patient may not need to be notified before using their data. However, there are strict limitations to follow.
- Censor user data by removing identifying and sensitive data.
As much as possible, inquire about your company’s legal team for guidance.
Mental Health Machine Learning Projects
With destigmatizing efforts laid out by various mental health groups, most communities are more open to recognizing mental health issues without pushing dangerous stereotypes that may harm the community.
As such, now that more people are talking about their mental health, it is much easier for data scientists to gather relevant social media datasets that may help develop tools to support such a marginalized community.
Below, we have the following projects:
- Generating a help bot that can help at-risk individuals
- Emotion detector using facial cues
- A machine learning algorithm for detecting at-risk individuals
1. Generating A Help Bot That Can Help At-Risk Individuals
Developing a machine learning model that answers questions to aid those in mental distress is an excellent starter project. Not only are there numerous datasets available online, but there is a lot less medical jargon required, and collecting specific patient data from third-party sources is not required.
The Models To Use
We will use this specific project’s transformer machine learning model to develop our model, which is geared explicitly toward Natural Language Processing (or NLP). Unlike LSTMs (Long Short Term Memory), transformers can take in complete sentences concurrently, making them faster and easier to train.
Moreover, due to its non-recurring nature, the transformer model can avoid common LSTM problems like exploding and vanishing gradients.
Datasets
Now that we have determined a model, readily available datasets online can help you train your neural network. The SQuAD dataset (Stanford Question Answering Dataset) contains a lot of documentation and guides while allowing for flexibility.
Another dataset to discover is Google’s Natural Questions dataset.
Project Run-through
This project develops a chatbot that answers questions for mentally distressed people, allowing them temporary support whenever an actual human is unavailable. Moreover, this question-answering bot can also provide help lines to the user, such as delivering a user a list of suicide prevention lines.
We can create answers that vary from user to user to make our answering bot more “human-like.” While incredibly hard to implement, our answering bot can also consider the context of the conversation.
For example, if the user mentions their name, the chatbot can use the user’s name whenever addressing them.
2. Emotion Detector Using Facial Cues
For this mental health machine learning project, while we may not tackle mental health in particular, this project can help determine visual cues and conclude what emotion a user is feeling. Not only does this open up many possibilities, but it can also help develop more advanced machine-learning models that tackle mental health.
The Models To Use
For this project, we will use a CNN, or a convolutional neural network, to find and identify facial cues. What makes CNN appropriate for this task is that it simplifies image processing without reducing the amount of crucial information an image has. This process is usually done through the convolutions it utilizes.
Datasets
The ASCERTAIN dataset is excellent for emotion recognition while supplying more critical variables that allow it to develop a more accurate result. This dataset considers the big five personality traits (extraversion, agreeableness, openness, conscientiousness, and neuroticism), the affective scale, and physiological features to make conclusions.
This makes this crucial because we are conducting this project to develop a more advanced mental health-related project later, accuracy should be of utmost importance.
Project Run-through
This project takes a still image of a user, analyses their facial cues, the affective scale, and the big five personality traits, and generates a result. You can extend a machine learning project like this for a more significant project that utilizes facial cues.
Machine Learning Algorithm For Detecting At-Risk Individuals

3. Machine Learning for Identifying Mentally At-Risk Individuals
Before proceeding with this project, it is integral to be very careful not to insert personal biases into the training process of your machine learning algorithm. Basing the validity, truthfulness, and falseness of the AI’s result on one’s knowledge of mental health symptoms may signal reaffirming biases. As such, we intend to develop a profile of at-risk individuals based on clinically diagnosed mental health patients.
A key factor is that we are not diagnosing patients, and instead, we are only identifying at-risk individuals.
A General Gist On The Project
This healthcare machine learning project to detect mentally at-risk individuals can be divided into four parts. These are:
- Getting the baseline: Giving the model information as to what is an “at-risk” individual through community reporting
- Identifying Features: We need to identify the features that will stand as a litmus test for our model’s operation and for the information to be represented mathematically. Identifying possible feature vectors can help us generate a profile of an “at-risk” individual.
- Compiling datasets: Gathering social media datasets of verified at-risk and not at-risk individuals.
- Testing: Testing and training how well an AI can determine an at-risk individual
By dividing our project into four phases, we can better understand the process and how we should form an angle of attack.
Getting the Baseline
When trying to assess the mental condition of individuals, primarily through limited information such as only by their digital footprint, there are a lot of idiosyncrasies that are hard to notice and determine. Moreover, deciding whether a behavior is “risky” or “alarming” is not bound by the hands of a data scientist, and trying to do so yourself is morally and ethically wrong.
How can we teach our neural network to determine which behaviors are “risky” if we do not have enough knowledge or the proper authority to do so? Well, we can capitalize on already known and verified information. As such, we will employ unsupervised learning since we do not know the patterns or behaviors to recognize beforehand.
The hardest part of this process is finding a clinically diagnosed mental health patient. However, when you do indeed find them, you can ask them for permission if you can gather data on their social media, such as Reddit, Twitter, and Facebook. With enough datasets, your neural network can now associate how a “mentally at-risk” person would behave on social media.
For easier access to these communities, you can visit subreddits focusing on mental health and their support infrastructures, where many are present.
Identifying Features
Because our previous approach was unsupervised learning, there should be no output. However, we have more context and understanding that will help us develop and identify features.
These features will help us develop a profile that constitutes an “at-risk” person. If applicable, consult a mental health professional to avoid the misinterpretation of data.
Compiling Datasets And Testing
Now that we have a proper baseline, we can now collect datasets. It would help to gather social media datasets containing Twitter, Reddit, and Facebook user behavior. However, focusing on one social media platform should be critical for ensuring a more accurate result, as we will reduce the number of variables affecting our results.
However, we would want a supervised learning approach to generate a more reliant model. The crucial thing to consider when doing supervised learning is that we must first know the mental health status of each person involved in the dataset.
We will tag each profile as either “at-risk” or “stable” (or any relevant labels). The machine learning model should run through their profiles and predict whether a person is “at-risk” or “stable.” We can cross-check the results with our tags and tweak our models accordingly.
Health Insurance Machine Learning Projects
In many sectors of businesses, machine learning remains a vital part of developing efficient systems that make services better for the end-user or for businesses to better capitalize on their demographic.
Machine learning in health insurance systems shows great potential in developing neural network-reliant software-based systems. We will tackle the following projects:
- Health insurance recommendation system
- Churn prediction project
4. Health Insurance Recommendation System
There are a lot of health insurance offerings out there, and someone opting to subscribe can get easily overwhelmed by the number of options, considerations, and prices thrown everywhere. A health insurance recommendation system designed with machine learning in mind can help provide accurate recommendations to the end user.
The Models To Use
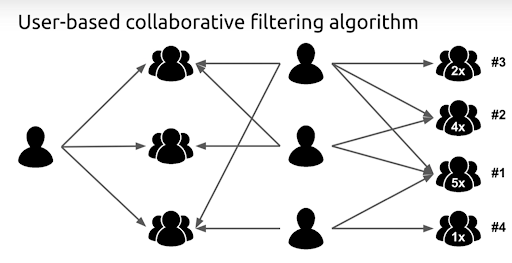
Many recommendation systems can be done without machine learning integration. For example, you can ask your users about their preferences and connect their answers to the service they will benefit from the most.
However, the problem with these systems is that as long as the user’s input remains the same, the output will always be static. As such, the algorithm does not learn and improve over time.
One of the best ways to implement machine learning in health insurance recommendation algorithms is by introducing collaborative filtering.
5. The Case With Collaborative Filtering
Collaborative filtering utilizes data from other users to generate a general profile of how a user of x preferences will fit y services more. For example, if a user is diabetic, then the machine learning algorithm can base its decisions on other diabetics and see how they select their health insurance options.
Instead of basing the recommendation on the user’s personal preferences and profile, the algorithm will use the profile to match them with related profiles and then base the conclusion on relative users.
The problem with the non-machine learning approach is that it assumes that people can properly describe themselves. Unfortunately, people are not particularly adept at representing themselves on a one-to-five survey. Personal biases, lapses in knowledge, and over (or under) estimation of oneself can particularly ruin the recommendation system’s output.
Datasets
One of the most comprehensive datasets to use for a collaborative filtering health insurance project is this dataset provided by the United States Census Bureau.
This dataset contains income information, graphs, reports, maps, and microdata and is collated along with health insurance information.
Project Run-through
Using the previous primary datasets and cross-referencing the US health insurance census information, collaborative filtering can be done to develop health insurance recommendations.
Users will input their crucial health information and preferences (i.e., income information, individual versus family floater plans preference, geographical location) and use this information to match a user with related health insurance holders or beneficiaries.
The project can also include an insurance provider satisfaction survey to improve its algorithms better rather than becoming an echo chamber.
6. Health Insurance Churn Prediction Project
While we focused on the end-user in our last project, we will emphasize the business side of health insurance ML projects in this one.
Health insurance is tricky to navigate for most consumers, and many curated offers may entice a current client to shift providers. The churning rate heavily affects business operations, as it is estimated to cost five times more to garner new clients than to retain existing ones.
This machine learning project should predict which clients risk defecting to another health insurance provider.
Datasets
We should base our datasets on private company client data, specifically historical data. Information such as age, income range, family size, marital status, and health diseases should be readily available. Communicating with the proper departments will allow you to gather more internal data that may be relevant to your project.
If you want to do a personal project, you can use the IBM Developer Platform dataset, which contains data from a fictional company called Telco. You can access the dataset in this GitHub link.
Project Run-through
A churn prediction project will predict how many clients will stop subscribing to your health insurance service through the random classification model. Using the features and how historical data correlates certain features to churning, we can determine which of the following consumers are likely to leave our service.
Healthcare Machine Learning Project Ideas
7. Good Health Practices Machine Learning Algorithm
An artificial intelligence project that uses user information to generate and recommend appropriate health practices (i.e., walk for ten minutes, get more sunlight) is a good machine learning project to start with and learn.
Datasets
An excellent comprehensive dataset for this project is the Eating & Health module, which contains information on different user eating habits, meal preparation, general health, body mass index, and miscellaneous weights. Using the values here, you can train your model to recognize the appropriate good health practice to recommend.
8. Health Dashboard

We can use information gathered from health trackers such as sleep trackers, exercise apps (i.e., Strava), and data from handheld health devices such as Fitbits to generate beautiful visualizations and dashboards for the user.
This project is an extended version of the good practices project. For example, the algorithm can use these collated datasets to create user warnings and reminders such as:
- walking activity reduced by 10% this week
- sleeping quality reduced
- snoring increased
Because these datasets are collated, it will be easier for the algorithm to cross-reference multiple datasets, such as sleeping data and exercise data, and see how they influence each other.
Datasets
There are many sample datasets to utilize for this project. We give out a list below:
- You can reuse the eating & health module dataset.
- Various datasets from sleepdata.org contain a plethora of sleep-related datasets, such as the dataset from the NCH Sleep Databank and a dataset focusing specifically on the Urban Poor in India. Request dataset access at this link.
- You can utilize a beautiful CrossFit dataset containing user information and exercise statistics to incorporate a cohesive sleep, exercise, and eating dataset. You can use these datasets to create sample profiles for your model to train.
9. Health Risks Prediction Algorithm
Like the churning algorithm, we can use the random forests model for this project. Moreover, you can also use collaborative filtering. You can make a model that asks for user data and predicts health risks using publicly available datasets.
It can correlate features such as “diabetes” and “cardiovascular diseases” to predict how likely a user is to experience a stroke. You can also incorporate BPM, blood pressure data, and lipid data.
Datasets
For this project, you can reuse the previous datasets or use the Global Health Observatory dataset collated by the World Health Organization. You can also use the CDC WONDER datasetfor a US-specific dataset
10. Healthcare Cyber Attack Analysis
![]()
We can leverage data from various healthcare sources, such as electronic health records (EHRs), patient surveys, and wearable health devices, to develop insightful visualizations and dashboards for healthcare professionals.
This initiative extends the foundational practices of healthcare data analysis. For instance, the integration of these datasets can enable the system to provide critical alerts and recommendations such as:
A significant increase in blood pressure over the past month A rise in cholesterol levels Decreased medication adherence By consolidating these datasets, the system can effectively cross-reference information from EHRs, patient feedback, and wearable data, providing a comprehensive view of patient health trends.
Datasets
There are several key datasets available for this analysis.
Health Risks Prediction Algorithm
11. Predicting Health Risks Using Random Forests and Collaborative Filtering
Like the churning algorithm, we can use the random forests model for this project. Moreover, you can also use collaborative filtering. You can make a model that asks for user data and predicts health risks using publicly available datasets.
It can correlate features such as “diabetes” and “cardiovascular diseases” to predict how likely a user is to experience a stroke. You can also incorporate BPM, blood pressure data, and lipid data.
Datasets
For this project, you can reuse the previous datasets or use the Global Health Observatory dataset the World Health Organization collates. You can also use the CDC WONDER dataset for a US-specific dataset.
Learn More About Machine Learning Algorithms
This course aims to provide you with a solid background in the fundamentals of Machine Learning Algorithms:
More Project Ideas From Interview Query
If you wish to expand your skills, try our new Takehomes, in which you answer longer problems step-by-step using notebooks from different companies.
Takehomes will assist you in developing your data science skills, such as Python, SQL, and machine learning, as well as allowing you to test projects used by top companies.
You can also browse additional data science project lists and datasets from Interview Query: