
Canonical Data Engineer Interview Guide (2025) – Questions & Prep Tips


Introduction
Canonical is a leading force in the open-source ecosystem, renowned for Ubuntu and its expanding suite of cloud and infrastructure solutions. With roots stretching back to 2004, Canonical has grown into a $251 million powerhouse by 2023, offering secure, cost-effective, open-source alternatives to enterprise software. Its technologies serve an impressive range of sectors—from aerospace to telecommunications—through partnerships with over 200,000 global contributors. As enterprises increasingly embrace cloud-native systems and open platforms, Canonical’s role in shaping the future of enterprise software continues to deepen.
In this climate of accelerating innovation, the hiring landscape for data engineers has become more rigorous than ever. The interview process now favors candidates who combine technical precision with adaptability. This shift reflects broader changes in the tech industry in 2025, where quality has overtaken quantity in hiring priorities. Canonical, too, has refined its approach, ensuring its teams are made up of professionals who thrive in high-ownership, high-impact environments. If you are preparing for a data engineering role here, you need to understand not only the technical expectations but also how to navigate Canonical’s unique culture and mission.
Role Overview & Culture
The Canonical data engineer role is centered around building, owning, and scaling data pipelines that support everything from product development to customer insights. You will be deeply embedded in Canonical’s operational core, ensuring clean, reliable data flows that power strategic decisions. This means architecting high-performance ETL pipelines, managing large-scale data transformations, and enabling data accessibility across departments. Your tools will include Python, SQL, and cloud-native services, with an emphasis on automation, monitoring, and fault tolerance.
Collaboration defines the day-to-day. You will partner with Ubuntu product teams, SREs, and business analysts to deliver end-to-end solutions. Canonical’s remote-first culture enhances this collaboration model rather than limiting it. Since its founding, over 70% of roles have been distributed globally, and the company has refined how remote work fuels innovation. Engineers are empowered with autonomy and trusted to deliver high-stakes work independently. Twice-a-year in-person sprints provide invaluable face-to-face connection, but the culture is shaped daily by shared ownership, self-motivation, and open-source values.
Why This Role at Canonical?
Joining Canonical as a data engineer means your work has real impacts. The company’s contributions to open-source software aren’t just academic or peripheral—they drive real-world infrastructure in finance, healthcare, and AI research. Your pipelines will feed models that optimize logistics for global enterprises or support public sector innovation. This is more than working on internal dashboards; it is about contributing to data systems that underpin mission-critical services worldwide.
There’s also unmatched exposure to the cloud. Canonical leads initiatives like MicroCloud and Ubuntu Pro, which depend on data workflows that you will help build. You’ll be applying your skills in a deeply cloud-centric environment, working across Kubernetes, virtual machines, and observability stacks. This translates into hands-on experience with real-world scalability, high availability, and continuous delivery. As a data engineer at Canonical, you’ll see firsthand how data transforms product strategy.
Perhaps most importantly, Canonical offers a fast track for personal growth. With structured learning budgets, a merit-based promotion system, and clear project ownership, your development is not left to chance. You’ll be recognized for your output, not tenure, and your contributions will be visible to leadership and across teams. This is the kind of role where you build not just better systems, but also a sharper, more future-ready version of yourself.
What Is the Interview Process Like for a Data Engineer Role at Canonical?
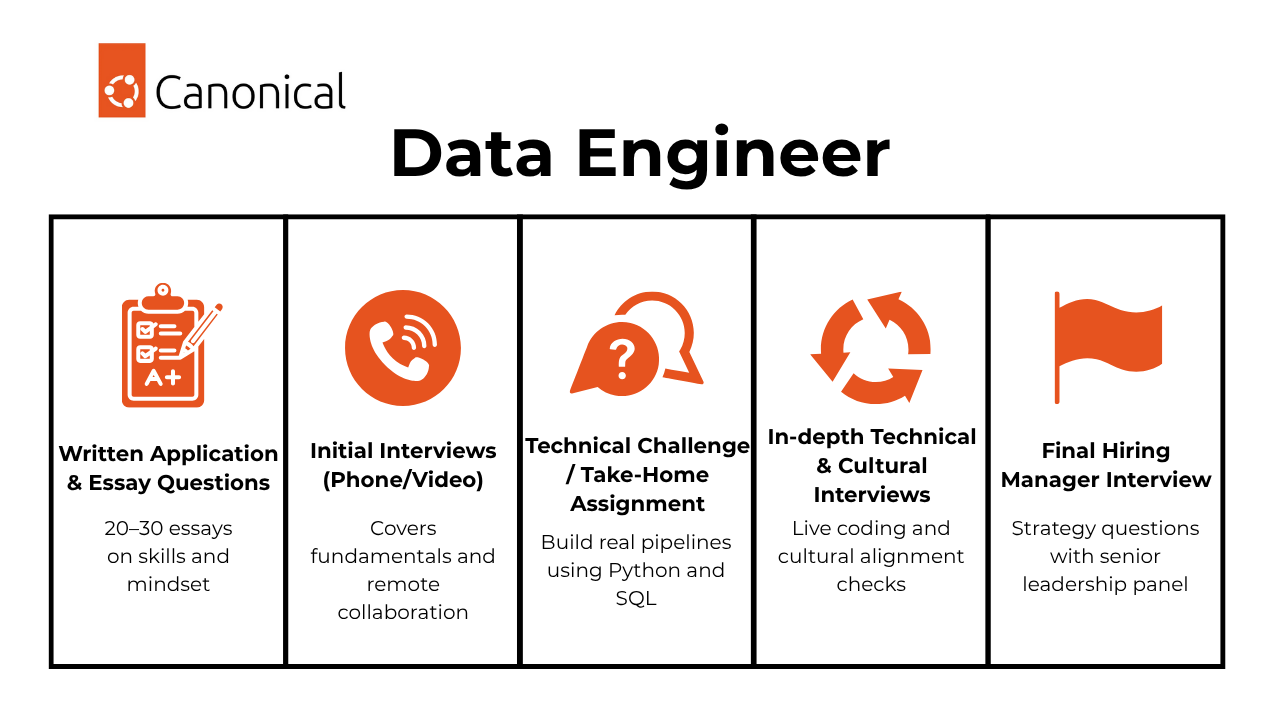
The Canonical data engineer interview process is methodical, thoughtful, and far more reflective than most industry norms. Rather than rushing candidates through a series of rapid-fire questions, Canonical deliberately structures a multi-phase evaluation that values deep thinking, remote collaboration skills, and authentic alignment with their mission. Here is how it goes:
- Written Application & Essay Questions
- Initial Interviews (Phone/Video)
- Technical Challenge / Take-Home Assignment
- In-depth Technical & Cultural Interviews
- Final Hiring Manager Interview
Written Application & Essay Questions
This first major step requires considerable time and honesty. Canonical asks you to complete a series of essay questions—often totaling between 20 and 30—that dig deep into your technical experience, motivations, and reflections on past challenges.
These aren’t generic forms. Expect to write several thousand words across the entire set, articulating not only what you did but how you think. This phase is crucial because written communication underpins how Canonical operates remotely.
Your essays help hiring teams understand how well you analyze, document, and explain technical decisions. If you’re thoughtful, organized, and candid, this stage becomes a platform to differentiate yourself from others who might only present polished code without context. Completing it well sets the tone for what follows.
Initial Interviews (Phone/Video)
Once your essays are reviewed, the next step is a set of preliminary interviews. These start with a conversation with a recruiter, where you’ll explore your motivation, understand Canonical’s culture, and clarify mutual fit.
You’ll then move on to early technical interviews, often one to three in total, with senior engineers or team leads. Here, the focus expands to your practical experience with data engineering fundamentals—topics like pipeline design, schema evolution, system reliability, and possibly even OS-level or database internals.
Importantly, you’ll also be asked to discuss collaboration patterns, asynchronous communication habits, and how you’ve worked in globally distributed teams. These conversations aren’t just screening; they are real previews of how Canonical teams work every day.
Technical Challenge / Take-Home Assignment
You’ll be given a technical assignment designed to test your engineering depth under real-world constraints. This is not a timed whiteboard task. Instead, it’s a take-home challenge where you’ll build or refine a pipeline, work with structured and unstructured data using Python and SQL, and document your approach clearly.
Canonical evaluates this work not only for correctness but also for how well your code communicates, how maintainable it is, and how thoughtfully you design your solution. This is often the most influential phase. Many candidates report spending 10 to 20 focused hours here. When done well, it’s your best opportunity to demonstrate the hands-on excellence you’d bring to the role.
In-depth Technical & Cultural Interviews
In later stages, you’ll engage in longer, more detailed sessions that test your ability to go deep technically while also navigating Canonical’s collaborative culture. These might include live coding, cloud architecture discussions, and peer code reviews.
You’ll be expected to explain complex data flows, troubleshoot distributed systems, and talk through design decisions on the spot. Equally important is your ability to respond to behavioral questions that explore ownership, asynchronous collaboration, and how you’ve handled conflicts or scaling challenges. Panel formats are common, and you may meet with engineers across different teams. These interviews aim to simulate real collaboration—so your clarity, openness, and ability to guide technical dialogue will be just as important as the technical answers themselves.
Final Hiring Manager Interview
If you reach this point, the final phase involves one or more discussions with senior leadership. This could include the hiring manager, a product or engineering director, or, in some cases, a Canonical executive. Expect to dive into broader technical vision, long-term strategy, and how your values align with Canonical’s mission.
Questions here are often open-ended. They may ask how you’d redesign a specific system for scale, how you measure the quality of data pipelines, or how you’ve helped non-technical teams use data effectively. This is also your chance to ask meaningful questions about Canonical’s future direction. Leadership will be looking for whether you can not only execute but also lead and evolve in an ever-expanding open-source ecosystem.
Challenge
Check your skills...
How prepared are you for working as a Data Engineer at Canonical?
What Questions Are Asked in a Canonical Data Engineer Interview?
In 2025, you should expect a wide-ranging mix of coding, system design, and behavioral prompts, with Canonical data engineer interview questions designed to measure not just skill, but clarity, ownership, and problem-solving depth in real-world contexts.
Coding / Technical Questions
You’ll be evaluated on your ability to write clean, scalable Python and SQL code, optimize ETL workflows, and handle real-world data scenarios using structured logic and modern data tools:
To create a cumulative distribution, first calculate the frequency of comments per user by joining the users and comments tables and grouping by user ID. Then, group by the frequency to get the histogram. Finally, use a self-join to calculate the cumulative total by summing up frequencies for all rows with a frequency less than or equal to the current row.
2. Write a query to find the top five paired products and their names
To find paired products often purchased together, join the transactions and products tables to associate transactions with product names. Use a self-join on the resulting table to identify pairs of products purchased by the same user at the same time. Filter out duplicate and same-product pairs by ensuring the first product name is alphabetically less than the second. Finally, group by product pairs, count occurrences, and order by count to get the top five pairs.
To solve this, transform the data to combine sending and receiving amounts for each user, filter transactions within the first 30 days of signup, and only include successful payments. Finally, sum the amounts for each user and count those with a total greater than 10,000 cents.
To calculate the total time in flight for each plane per day, the query uses Common Table Expressions (CTEs) to handle flights that span multiple days. It calculates the time spent on the current day and the next day separately, then combines and sums these times grouped by plane and calendar day.
5. Write a function to compute the average data scientist salary using a recency weighted average
To compute the recency-weighted average salary, assign weights to each year’s salary based on its recency (e.g., 1 for the oldest year, 2 for the next, and so on). Multiply each salary by its weight, sum the results, and divide by the total weight. Round the result to two decimal places.
6. Write a function to compute the average data scientist salary using a recency weighted average
To compute the recency-weighted average salary, assign weights to each year’s salary based on its recency (e.g., 1 for the oldest year, 2 for the next, and so on). Multiply each salary by its weight, sum the results, and divide by the total weight. Round the result to two decimal places.
7. Write a function to draw an isosceles triangle using a 2D list of 0s and 1s
To solve this, first check if the given height h and base b can form a valid isosceles triangle. Ensure b is odd and calculate the level of increase for each row using arithmetic progression. If the increase is not even, return None. Then, construct the triangle row by row, centering the 1s and filling the rest with 0s.
System / Product Design Questions
These questions assess how you approach complex architectural challenges—especially under constraints like cost, scale, or unstructured data—and how you balance open-source tools, user experience, and long-term maintainability:
8. Design a reporting pipeline using open-source tools under budget constraints
To architect a cost-efficient reporting pipeline, use Apache Airflow for orchestration, Apache Spark for data processing, PostgreSQL for storage, and Metabase for visualization. Ingest raw data from internal databases and log files, process it with Spark, and store the results in a reporting schema in PostgreSQL. Use Airflow to schedule and monitor the pipeline, and Metabase to create dashboards and deliver reports to the executive team. Ensure data quality with validation checks and optimize for scalability and security.
9. How would you design a system for a parking application?
To design the system, start by identifying functional requirements like real-time price updates, user location tracking, and cost calculation. Use a database to store parking spot details, availability, and pricing, and integrate a geolocation API to find nearby spots. Incorporate a machine learning model for dynamic pricing and ensure the system is scalable and responsive to handle high traffic.
10. How would you add a column to a billion-row table without affecting user experience?
To add a column to a billion-row table without downtime, assess the impact of downtime and database type. For non-Postgres databases, consider creating a replica table, updating it offline, and gradually migrating data while ensuring no data loss. Use phased updates to minimize user impact and ensure data consistency.
To handle unstructured video data, the pipeline involves three main steps: primary metadata collection and indexing, user-generated content tagging, and binary-level collection. Metadata collection automates gathering basic video details, while user tagging enriches the dataset, often scaled with machine learning. Binary-level collection analyzes intricate video details like colors and audio, though it is resource-intensive. Automated content analysis using machine learning (e.g., image recognition, NLP for audio) further enhances the pipeline’s efficiency and depth.
12. How would you create a schema to represent client click data on the web?
To design a schema for client click data, start by assigning each action a specific label (e.g., folder_click, login_click). Include fields like user_id, created_at, session_id, user_agent, value_type, value_id, device, url, and utm to track detailed analytics. This schema allows for efficient querying and analysis of user interactions.
Behavioral / Culture Fit Questions
The Canonical data engineer interview process places strong emphasis on communication, motivation, and cultural alignment, especially given its remote-first model and global team structure:
This is a common question during the Canonical data engineer interview process because effective remote collaboration depends on clear, adaptive communication. You might reflect on a moment where technical language created confusion with a non-technical stakeholder or where asynchronous updates led to misalignment. Canonical looks for engineers who can recognize gaps in understanding, then shift gears—perhaps by using more visual explanations or structured documentation—to ensure clarity and alignment across distributed teams.
14. How comfortable are you presenting your insights?
Canonical values engineers who can do more than just code—they must also translate complex findings into actionable business insights. This question is your chance to show how you communicate data stories with clarity and confidence, especially in fully remote meetings. Whether it’s leading a dashboard walkthrough or summarizing pipeline outcomes for Ubuntu’s product team, what matters is how you structure your message and tools to make insights meaningful and digestible.
15. How would you convey insights and the methods you use to a non-technical audience?
At Canonical, data engineers often support product teams, marketing stakeholders, and executives—many of whom may not be deeply technical. This question assesses your ability to bridge that gap by translating complex methods into actionable, easy-to-grasp insights. You’ll want to show how you distill concepts like clustering algorithms or data lineage into intuitive analogies, clear visualizations, and narrative-driven summaries that support decision-making across globally distributed teams.
16. Why Do You Want to Work With Us
This question offers a crucial moment to align your motivations with Canonical’s mission. It’s not just about admiring Ubuntu or liking open source—it’s about connecting your goals as a data engineer with Canonical’s role in shaping cloud-native infrastructure and global developer ecosystems. Show that you’ve done your homework and that you’re genuinely excited to contribute to scalable, open platforms that drive real change in industries and communities worldwide.
How to Prepare for a Data Engineer Role at Canonical
The data engineer role at Canonical in 2025 demands thorough preparation across multiple fronts. Here are five key tips to help mid-to-senior candidates prepare effectively:
Focus on core technical domains
Master the fundamentals of data engineering, such as designing scalable data pipelines, building efficient ETL processes, and managing complex data integrations. Strengthen your proficiency in Python and SQL, and develop a solid understanding of Linux systems, especially Ubuntu internals. Familiarity with Canonical’s ecosystem—including MicroCloud, Landscape, and packaging systems—will help you stand out. Knowing how Canonical builds, tests, and releases its software is often a differentiator in interviews.
Practice with mock interviews (technical and behavioral)
Simulate real interview conditions to build fluency in problem-solving and communication. Practice Python-based data challenges and system design discussions that test your ability to reason through distributed architectures or data workflows. Review your past engineering projects and be ready to walk through how you designed solutions, handled setbacks, and delivered results. Practice further with our 1:1 Coaching for more exposure. Canonical places a premium on clarity and technical depth, so practice giving detailed, structured answers to both technical and behavioral questions.
Contribute to open-source projects
Canonical values candidates with a track record in open-source collaboration. Contributing to relevant projects—whether data tools, cloud automation, or Linux systems—demonstrates your technical skill and alignment with their mission. These contributions give you concrete experiences to reference in interviews and show how you handle code quality, documentation, and collaborative tooling. Be prepared to talk about what you’ve built, reviewed, or maintained and how it improved your understanding of software development at scale.
Demonstrate remote collaboration readiness
Canonical has been remote-first since its inception. You’ll need to show that you can thrive in asynchronous, distributed environments. This includes clear written communication, independence, and the ability to manage your time across global time zones. Highlight any experience where you successfully coordinated across remote teams, used Git workflows or project trackers efficiently, or delivered technical updates through documentation or chat platforms. The interview process will assess your ability to communicate without relying on in-person cues.
Familiarize yourself with Canonical’s unique interview process and culture
Expect a structured and thorough process that includes a detailed written application, aptitude and personality assessments, coding challenges, and multiple interviews across technical and cultural dimensions. Invest serious time in the written phase—it is not a formality, and your ability to express complex technical ideas in writing matters greatly: Research Canonical’s products, open-source philosophy, and long-term vision. Be prepared to articulate why you want to work there, how your background aligns, and how you would contribute to their goals. Show not just what you’ve done, but how you think and why Canonical is the right place for your next step.
Conclusion
Preparing for a Canonical data engineer role in 2025 is a high-reward endeavor for those who bring both technical depth and open-source passion. With clear communication, thoughtful preparation, and a strong alignment with Canonical’s remote-first ethos, you can stand out in a rigorous but respectful process. Whether you’re just starting or scaling into leadership, the path ahead is rich with opportunity. For next steps, explore the data engineering learning path, read Jeffrey Li’s success story, or browse our curated data engineer interview questions collection to sharpen your edge.
Canonical Interview Questions
| Question | Topic | Difficulty |
|---|---|---|
Product Sense & Metrics | Easy | |
Let’s say that you’re the PM on Google Maps.
| ||
Analytics | Easy | |
Behavioral | Medium | |
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
Discussion & Interview Experiences