
Top 19 NumPy Interview Questions (Updated for 2025)


Overview
NumPy is a python library created specifically for modifying, creating, and processing n-dimensional arrays. Moreover, it allows for shape manipulation, selecting, sorting, and more array operations.
For job positions requiring a lot of scientific calculations, matrix observations, and financial and deep learning analysis, NumPy interview questions will almost always come up.
Below is a list of common NumPy questions, sorted based on difficulty.
What Should I Know Before NumPy Interviews?
Because NumPy is a library, you must have specific skills to help you understand and utilize the functions employed inside the library. Of course, a few related concepts may also come up in NumPy interviews.
For example, knowledge of data science concepts is not required, but NumPy is a Python library that most data scientists employ to improve their insights and analysis.
Nevertheless, below is a list of things you should at least have a background of to create more meaningful and strategic approaches toward using NumPy:
- Set theory
- Matrix operations
- Discrete Math
- Basic Arithmetic
- Python
- Data structures
Easy NumPy Interview Questions
These easy NumPy interview questions can help you identify your competency level. Typically, these questions are asked by the interviewer to determine which interviewees are worth considering.
Akin to the legendary FizzBuzz programming problems, aside from identifying how much fundamental information you have with NumPy, these questions are made to determine how you think.
Moreover, they perfectly exemplify how one approaches a problem and pinpoint which NumPy functions and utilities you are most familiar with, including the functions and functions you employ to solve a specific problem.
| Question | Topic | Difficulty | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Easy | |||||||||||||||||||||||
We’re given two tables, a Write a query that returns all neighborhoods that have 0 users. Example: Input:
Output:
| ||||||||||||||||||||||||
SQL | Easy | |||||||||||||||||||||||
SQL | Hard | |||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
1. What is NumPy?

NumPy is a Python library that delivers strong performance in array manipulation and allows matrices and n-dimensional arrays to be easily manipulated in Python. Because Python is a dynamically-typed language (i.e., variables are known at compile time), the concept of declaring variables with their respective data type is abstracted from the user. However, typecasting can help manage this feature. However, dynamic typing comes at an overhead cost, resulting in Python working slower than statically-typed languages (i.e., C++ and Java).
NumPy bridges this gap by retaining the speed of array manipulation in lower-level languages while keeping the abstraction still prevalent.
2. What is an n-dimensional array in NumPy?
The n-dimensional array is the most fundamental data structure involved in NumPy. This data structure is a more complex version of a list that involves multiple dimensions, allowing it to create matrices while retaining a smaller form factor (lower overhead) than other data structures (i.e., trees).
Like lists, sets, or tuples, the array contains data spaces stored contiguously. Moreover, NumPy arrays are identified by the following characteristics:
NumPy Arrays Definition of Terms:
The shape is the dimensions or the number of indices each element in the array has. We can calculate the maximum number of elements in an n-dimensional array by multiplying the dimensions (i.e., if the shape is 2, 3, 2, the number of elements inside the array is 12).
- An element is the data contained inside the array, and a specific element is an instance of data inside an array. Each element occupies one block of memory.
- The index is the specific tag of an element in an array to access its address easily. N-dimensional arrays use n number of indices to represent a variable.
- While a dimension may be self-understandable, it is pretty hard to define formally. Typically, a dimension is identified as the number of indices required to specify the location of an element. For example, a two-dimensional array requires two indices (i.e., array[rows][columns]), and three-dimensional arrays require three indices (i.e., array[rows][columns][depth]).
3. How does Python store data in memory?
Python’s memory management system plays a crucial role in handling data efficiently, especially when working with libraries like NumPy, which relies on the efficient storage and manipulation of large datasets. In Python, stack memory is used for function execution and managing control flow, while heap memory stores the objects, such as the n-dimensional arrays in NumPy.
NumPy arrays are stored in contiguous blocks of memory, making data access faster and more efficient. When you create a NumPy array, Python allocates memory on the heap for the array’s elements. The array itself is an object with metadata like shape and data type, which is stored in heap memory, while references to this array can be stored in the stack during function execution. Python’s garbage collector automatically manages these memory allocations, freeing up space when the objects are no longer in use. This memory efficiency is one of the reasons why NumPy is preferred for numerical computations in Python, as it optimizes both storage and access speed.
4. How do we get an element from a NumPy array?
Like primitive arrays in other languages, you can retrieve an element from a NumPy array using its index.
Input:
arr = np.array([1, 2, 3, 4])
get = arr[0]
print(get)
Output:
1
5. How can you initialize a three-dimensional array in NumPy?
Because NumPy is a library, initializing and declaring arrays may take a few more steps than using primitive arrays. For NumPy, use the following syntax to declare two-dimensional arrays:
myArray = np.array([[1, 2, 3] , [4, 5, 6] , [7, 8, 9]])
print(myArray)
#this will create a NumPy two-dimensional array named myArray
my3DArray = np.array([[[1,2,0] , [3,4,10]], [[5,6,9] , [7,9,0]]])
print(my3DArray)
#this will create a NumPy three-dimensional array
To create an n-dimensional array with all values set to zero, use the following function:
zeroArray = np.zeros(shape)
For example, to create a four-dimensional array using the np.zeros function, use the following syntax:
Input:
zeroArrays = np.zeros((2, 2, 2, 2))
print(zeroArrays)
Output:
[[[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]]
[[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]]]
6. How do you identify the datatype of a NumPy array?
Sometimes, after many array manipulations, there might be a chance we forget an array’s datatype. To identify the datatype of a NumPy array, you can do the following:
Input:
strg = np.array(['i', 'q'])
print (strg)
print("Datatype is: ", strg.dtype)
Output:
['i' 'q']
Datatype is: <U1
7. How do you identify the shape of a NumPy array?
To identify the shape of a NumPy array, you will need to use the shape function. It can be implemented through the following:
Input:
zeroArrays = np.zeros((2, 2, 2, 2))
print(zeroArrays)
#create the array
print("The shape is: ", zeroArrays.shape)
Output:
[[[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]]
[[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]]]
The shape is: (2, 2, 2, 2)
8. What are some of the NumPy aggregate functions?
Aggregate functions are mathematical functions that utilize multiple values (i.e., in this context, the values of an array) and combine (or aggregate) them into a single value instance. NumPy has built-in functions that can help with aggregating the values together.
- The np.sum() function returns the sum of all the elements along an axis of an array. You can filter values using the where parameter.
- The np.min() and np.max() functions return the minimum and maximum values of an array, respectively.
- Meanwhile, the np.argmin() and np.argmax() return the indices of the minimum and maximum values of the array, respectively.
- np.std() returns the standard deviation of a given array while the np.mean() returns the mean or average
- The cumulative aggregate functions include the np.cumsum(), which returns the cumulative sum, while the np.cumprod() produces the cumulative product of an array (do note that both functions return arrays).
9. How can we reverse a NumPy array?
Reversing a NumPy array using primitive Python functions can get tricky and utilize a lot of effort for not much work. Thankfully, NumPy has a flip function that can do this for you.
Using the np.flip function which returns a flipped array, we can do this:
Input:
array = np.array([[1, 2, 3], [4, 5, 6]])
flipped = np.flip(array)
print(array)
print("\n")
print("AFTER FLIPPING: ")
print(flipped)
Output
[[1 2 3]
[4 5 6]]
AFTER FLIPPING:
[[6 5 4]
[3 2 1]]
Intermediate NumPy Interview Questions
Intermediate NumPy interview questions tend to assess further understanding of NumPy concepts and why or how it works that way. Moreover, we also introduce more complex coding questions that can help weed out theory-only candidates.
| Question | Topic | Difficulty | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Easy | |||||||||||||||||||||||
We’re given two tables, a Write a query that returns all neighborhoods that have 0 users. Example: Input:
Output:
| ||||||||||||||||||||||||
SQL | Easy | |||||||||||||||||||||||
SQL | Hard | |||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
10. How can we reshape a NumPy array?
Reshaping a NumPy array is a function wherein one changes the shape of an array by modifying its dimensions. More precisely, a reshaping function changes the number of dimensions per array and each dimension’s size, all done without shifting or changing the integral structure, hierarchy, or order of data.
To reshape a NumPy array, use the array.reshape() function, wherein the parameters of the said function are the array dimensions, and the return value is the reshaped array.
For example:
Input:
array = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
print("Before reshape: ")
print(array)
reshaped = array.reshape(2, 5)
print("After reshape: ")
print(reshaped)
Output
Before reshape:
[1 2 3 4 5 6 7 8 9 0]
After reshape:
[[1 2 3 4 5]
[6 7 8 9 0]]
11. Why are NumPy arrays faster in terms of processing time?

Aside from being more accessible to manipulate, NumPy arrays are also faster to modify. Most NumPy arrays’ operations are relatively quicker than Python’s lists for a few reasons.
- One reason is that Python is relatively slow (not slow enough in small arrays, but is noticeable in quite sizable ones) when doing loops and function calls.
Let’s get this one case; for example, a loop that iterates through all the numbers from one to one hundred thousand and adds the indices together takes much longer to run in Python than in C (in fact, 15 seconds in Python and 1 second in C).
While the time difference may be relative to processor speed, the ratio is not. When operating with loops, we can see that Python thus runs much slower, even with differing CPUs.
- Another reason why NumPy is faster is that it utilizes C and Fortran for expensive function calls and loops.
NumPy utilizes the C-API to bridge Python and C, creating an abstracted, more straightforward programming experience without compromising on speed.
12. Why is determining the time complexity of NumPy arrays and functions hard?
Time complexity, often expressed using big O notation, is one function for determining the efficiency of an algorithm in terms of running time. While big O notation does not give precise running time values, it gives you a relative estimate of how efficient an algorithm is and how well it performs.
However, the problem with big O notation is that it assumes that all operations are in one language, and the ratios scale this way. However, because NumPy utilizes C, Fortran, and Python code, big O notation is skewed and loses accuracy.
For example, a function in linear time or O(n) using Python loops and C loops can have a starkly different running time, despite both being classified as linear time.
- The setup process in most NumPy functions is typically done in Python, which can take up a chunk of the processing time. While technically, the setup process is O(1), it can easily outweigh the functions implemented in C; even those with time complexity of O(n) or per-element processes can be faster compared to Python O(1).
- Iteration is painstakingly slow in Python’s lists, so avoid iteration functions as much as possible. Despite the iterations being O(n), NumPy’s cross-reference array iterations using C offer a significantly faster O(n) process.
- As such, Python’s O(n) != C’s O(n)
13. Given a NumPy array, count the instances of a given element
Iterating through a python list and finding matching values is quite a troublesome approach to such a simple problem. Moreover, this function is slow, clunky, and expensive. Using NumPy arrays, you can find the instances of a non-zero value in an array using the following ways:
Given that:
x = np.array([2, 2, 2, 4, 5, 5, 5, 7, 8, 8, 10, 12])
Input:
#Count the instance of one number
print(np.count_nonzero(x==2))
Output:
3
Input:
#Count the instance of two or more numbers
print(np.count_nonzero((x==2)|(x==8)))
Output:
5
Input:
#Count the instances of all elements greater than or less than a specified number
print(np.count_nonzero((x<=8)))
Output
10
Input:
#Get creative with the function with other conditions
print(np.count_nonzero((x%2==0)))
14. Explain the NumPy sort function, and determine which sorting algorithm you should use.
Array sorting is quite a complicated task for those without a strong background in algorithms and data structures. While one can implement simple sorting algorithms such as bubble sort and insertion sort relatively quickly, these functions are often slow and clunky, with time complexity of O(n^2).
While these sorting algorithms will get the job done no matter what, along with an increase in array size comes an exponential growth in processing time. Thankfully, NumPy has the numpy.sort() function.
Most implementations of the numpy.sort() typically look like this:
x = np.array([2, 2, 2, 4, 5, 5, 5, 7, 8, 8, 10, 12])
print(np.sort(x))
However, a complete implementation of the numpy.sort() function would look like the following:
x = np.array([2, 2, 2, 4, 5, 5, 5, 7, 8, 8, 10, 12])
print(np.sort(x, axis=None, kind="mergesort", order=None))
The numpy.sort() function can have up to four parameters, although only one of these parameters is required.
- The first parameter, practically the only required parameter, takes a NumPy array. This array is the array to be sorted.
- The second parameter is the axis parameter (integer). This parameter helps determine the axis to be sorted. The array is flattened and sorted if the axis is set to -1.
- The third parameter is the sorting algorithm parameter (string).
You can select which sorting algorithm to use. These algorithms are identified in the following:
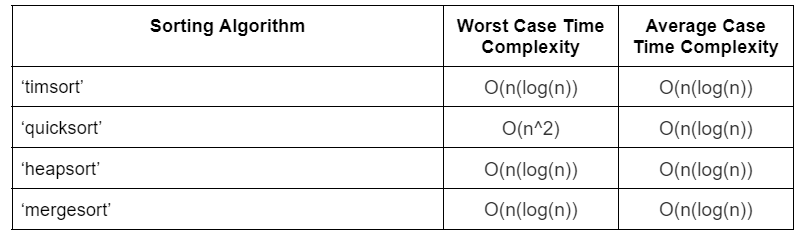
- The fourth parameter is the order parameter (string). This parameter determines which field has the highest comparison priority.
The return value of the numpy.sort() function is a sorted array.
15. Given a list of integers, write a function gcd to find the greatest common denominator between them.
Test Case 1:
int_list = np.array([8, 16, 24])
def gcd(int_list) -> 8
Test Case 2:
int_list = np.array([4, 2, 8])
def gcd(int_list) -> 2
Test Case 3:
int_list = np.array([9, 7, 2])
def gcd(int_list) -> 1
The GCD (greatest common denominator) of three or more numbers equals the product of the prime factors common to all the numbers. It can also be calculated by repeatedly taking the GCDs of pairs of numbers.
The greatest common denominator is also associative. GCD of multiple numbers: say, a,b,c is equivalent to gcd(gcd(a, b), c). Intuitively, this is because if the GCD divides gcd(a,b) and c, it must divide a and b by the definition of the greatest common divisor.
Thus, the greatest common denominator of multiple numbers can be obtained by iteratively computing the GCD of a and b, and GCD of that result with the following number.
How do we implement the actual gcd algorithm, though? We can use something called the Euclidean Algorithm. The Euclidean Algorithm for finding gcd(a,b) is as follows:
- If a = 00 then gcd(a,b)=b
- If b = 00 then gcd(a,b)=a
- Write a in quotient remainder form a = bq + r where q is the quotient and r is the remainder.
- Find gcd(b,r) using the Euclidean Algorithm since gcd(a,b)=gcd(b,r)
def compute_gcd(a, b):
while b:
r = a % b
a = b
b = r
return a
Given we now have this formula function, it’s not hard to loop through each integer in the list and compute the GCD for each integer:
def gcd(numbers):
def compute_gcd(a, b):
while b:
r = a % b
a = b
b = r
return a
g = numbers[0]
for num in numbers[1:]:
g = compute_gcd(num, g)
return g
16. How can we use NumPy and machine learning techniques to create a chatbot that finds the best answer from a list of FAQs when a user asks a question?
In building a chatbot for FAQ-based question answering, machine learning methods can be efficiently implemented using tools like NumPy, which excels in handling large datasets and complex calculations.
In a supervised approach, the system is trained on past user inquiries, with each question manually labeled to the corresponding FAQ. A classifier, potentially leveraging NumPy for efficient data handling, predicts the best match, selecting the most likely answer or defaulting to customer support if confidence is low. Intent-based retrieval can also be integrated, where both queries and FAQs are tagged with intents, using NumPy arrays to manage and process these tags efficiently.
In an unsupervised approach, methods like keyword-based search, lexical matching, or word embeddings can be implemented. NumPy can be used to create and manage keyword vectors, perform lexical matching by comparing word overlaps, or compute cosine similarity between word embeddings. NumPy’s ability to handle n-dimensional arrays and perform fast mathematical operations makes it ideal for these tasks.
Hard NumPy Interview Questions
These hard NumPy interview questions contain queries that mix and match functions and functions. While the interview questions before the ones below tackle familiarity, the grasp of theoretical concepts, and basic concept memorization, these hard questions test your logic.
| Question | Topic | Difficulty | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SQL | Easy | |||||||||||||||||||||||
We’re given two tables, a Write a query that returns all neighborhoods that have 0 users. Example: Input:
Output:
| ||||||||||||||||||||||||
SQL | Easy | |||||||||||||||||||||||
SQL | Hard | |||||||||||||||||||||||
SQL | Easy | |
Machine Learning | Medium | |
Statistics | Medium | |
SQL | Hard | |
Machine Learning | Medium | |
Python | Easy | |
Deep Learning | Hard | |
SQL | Medium | |
Statistics | Easy | |
Machine Learning | Hard |
17. Given a NumPy array of integers and an integer called num, remove all elements with an instance lower than num. As much as possible, reduce the dependence on Python loops and utilize NumPy functions.
For a problem like this, it is best to keep yourself from reimplementing functions predefined in NumPy. Not only do you risk your matrices to unchecked logic, but most often, NumPy utilizes a faster algorithm due to the intricacies involved with the compiled vs. interpreted language debate.
For all test cases, given the array:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
Test Case 1:
Enter number: 1
Before removal:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
After removal:
[2 6 8 3 1 3 6 8 2 1 2 3 4 6 8 4 3 6 3 4 6 3 1 2]
Test Case 2:
Enter number: 6
Before removal:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
After removal:
[6 3 3 6 3 6 3 6 3 6 3]
Test Case 3:
Enter number: 0
Before removal:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
After removal:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
To do the problem above, we can do the following (solution):
import numpy as np
#we implement our functions here
def main ():
arr = np.array = ([insert given array])
num = int(input("Enter number: "))
print("Before removal:\n", arr)
arr = removeLeast(arr, num)
print("After removal:\n", arr)
return
def removeLeast (arr, num):
binned = np.bincount(arr)
compared = binned[num]
for i in arr:
if binned[i] < binned[num]:
arr = np.delete(arr, np.where(arr == i))
return arr
#execution starts here
main()
Breaking down the code:
def removeLeast (arr, num)
Although the code looks pretty clunky, most of our problem’s solution lies in the removeLeast() function. The removeLeast function takes two parameters/arguments; the first argument is an array while the other is an integer that you want to see the instances of, removing all the other integers with fewer instances than the passed integer.
binned = np.bincount(arr)
compared = binned[num]
We create an array named “binned” that accepts the return value of np.bincount(arr). The function np.bincount() takes an array as a parameter and returns an array that holds the instance of a number from zero to the most significant digit inside a given array. The function then places them in their respective indices. The array returned by np.bincount(arr) has a size equal to the max integer inside the arr+1.
For example, given the array: np.array([1, 1, 2, 2, 2, 3]), the returned array will have a size equal to four and have the following values: [0, 2, 3, 1], as there are zero zeroes, two ones, three twos, and one three.
Meanwhile, we create an integer variable named compared to store the number of instances num has.
for i in arr:
if binned[i] < binned[num]:
arr = np.delete(arr, np.where(arr == i))
We iterate through all the elements inside the array arr for the following for loop. Using a control structure, we check the numbers and their instances (found in the array called binned). If the instance of a number is lower than the instance of num (represented by compared), it is then removed.
18. Given a NumPy array, starting from position n to position m, remove the ith position, in which we should remove the element from position n first.
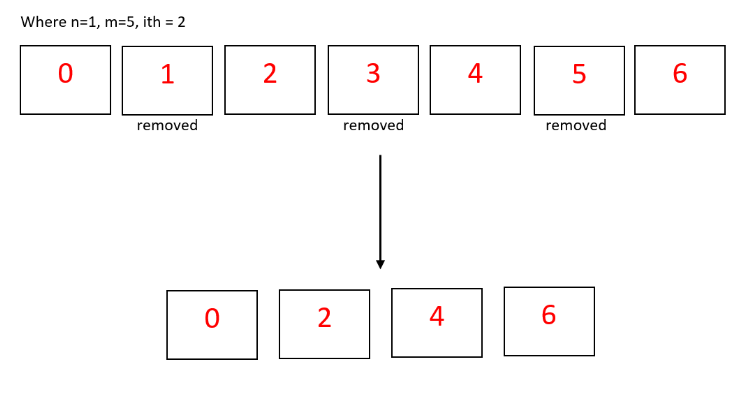
In approaching this question, we should be wary of checking the edge cases first. For example, one of the edge cases to worry about is when the arguments would want to return an empty array, and we should check those out before coding the rest.
It is highly recommended to try and solve this problem for yourself before viewing the solution below.
For all test cases, given the array:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
We can use the following test cases:
Test Case 1:
Start removal at index: 0
End removal at index: 27
Remove every: 1
Before removal:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
After removal:
[7]
Test Case 2:
Start removal at index: 0
End removal at index: 10
Remove every: 2
Before removal:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
After removal:
[6 3 3 8 2 2 3 4 5 6 8 9 4 3 5 6 3 4 6 3 1 2 7]
Test Case 3:
Start removal at index: 5
End removal at index: 25
Remove every: 5
Before removal:
[2, 6, 8, 3, 1, 3, 6, 8, 9, 2, 1, 2, 3, 4, 5, 6, 8, 9, 4, 3, 5, 6, 3, 4, 6, 3, 1, 2, 7]
After removal:
[2 6 8 3 1 6 8 9 2 2 3 4 5 8 9 4 3 6 3 4 6 1 2 7]
Use the following code below for reference (solution):
import numpy as np
#we implement our functions here
def main ():
arr = np.array = ([insert given array])
n = int(input("Start removal at index: "))
m = int(input("End removal at index: "))
ith = int(input("Remove every: "))
print("Before removal:\n", arr)
arr = skippingSteps(arr, n, m, ith)
print("After removal:\n", arr)
return
def skippingSteps (arr, n, m, ith):
#edge case for when ith = 1
ctr = int(n)
if (ith==1):
while(ctr!=m+1):
arr= np.delete(arr, n)
ctr +=1
return arr
for i in range (n, np.size(arr)-1, ith-1):
arr = np.delete(arr, i)
ctr+=ith
if (ctr>m):
return arr
#execution starts here
main()
Breaking down the code:
def skippingSteps (arr, n, m, ith):
Our skippingSteps() function takes four arguments, which are:
- the array that we will manipulate
- n or the starting index
- m or the ending index
- and ith or the every ith element to skip
ctr = int(n)
if (ith==1):
while(ctr!=m+1):
arr= np.delete(arr, n)
ctr +=1
return arr
The first program is an edge case when we want to remove every element within the n to m range (i.e., when ith is 1). We first declare a counter variable called ctr and set it to n, typecasting it along the way.
We will run our loop while our counter is not equal to m+1 and not just m since m is still included in the removal parameter, and if m is the ith Element, we will also need to remove it.
Inside the loop, we delete the element n in array arr and increment our counter ctr by one. Since every time we delete the elements, we will shift all the other elements to a lower index, we only need to remove the element at index n.
for i in range (n, np.size(arr)-1, ith-1):
arr = np.delete(arr, i)
ctr+=ith
if (ctr>m):
return arr
Using the counter we declared earlier, we will loop through our array, starting from the index n to the last index of the array (i.e., np.size(arr)-1). We will increment our i ith-1 times (since we are skipping every nth element and not skipping n elements).
We are incrementing our counter by the value of ith, since that will be the index of the next element we remove. We then check if the counter variable ctr is greater than the ending index (i.e., m) since we need to stop at the ending index. And if the if statement returns a true, we return the array.
19. There are two NumPy arrays, X and Y. Both arrays contain integers from -1000 to 1000 and are identical to each other except that one integer is removed in array Y that exists in array X. Write a function one_element_removed that takes in both arrays and returns the integer that was removed in O(1) space and O(n) time.
Test Case 1:
import numpy as np
x = np.array = ([1,2,3,4,5])
y = np.array = ([1,2,4,5])
one_element_removed(x, y) -> 3
Test Case 2:
Import numpy as np
x = np.array = ([3, 4, 5])
y = np.array = ([3, 5])
one_element_removed(x, y) -> 4
Test Case 3:
import numpy as np
x = np.array = ([3])
y = np.array = ([])
one_element_removed(x, y) -> 3
This question is a definition of a trick question, and it’s not an algorithm or a python question, but more of a brain teaser meant to give you a problem to be solved creatively.
The question asks how you figure out the number missing from array Y, which is identical to array X, except that one number is missing. We could loop through one array, create a hashmap, and figure out which element doesn’t exist, but that wouldn’t be done in O(1) time.
Before getting into coding, think about it logically - how would you find the answer to this?
The quick and straightforward solution is to sum up all the numbers in X, sum up all the numbers in Y, and subtract the sum of X from the sum of Y, giving you the missing number. Because the elements in the array are integers, it adds a different dimension to the problem in creativity rather than the typical approach of data structures and algorithms.
Use the following code below for reference (solution):
import numpy as np
def main():
import numpy as np
x = np.array = ([insert array here])
y = np.array = ([inser array here])
print(one_element_removed(x, y))
def one_element_removed(x, y):
sumx = np.sum(x)
sumy = np.sum(y)
return sumx-sumy
main()
Always ask follow-up questions when given constraints. The interviewer could hold back assumptions you would never know without asking for more clarification. Some examples would be:
- Is the list sorted?
- Is one of the lists the set of all integers from -1000 to 1000?
Learn More About Python With Our Comprehensive Learning Path
Prepare for NumPy interview questions by mastering Python fundamentals, and refining your coding skills with our comprehensive Python learning path: